文章目录
前言
Transformer[1]最初提出是针对NLP领域的,并且在NLP领域大获成功,几乎打败了RNN模型,已经成为NLP领域新一代的baseline模型。这篇论文也是受到其启发,尝试将Transformer应用到CV领域。通过这篇文章的实验,给出的最佳模型在ImageNet1K上能够达到88.55%的准确率(先在大型数据集JFT上进行了预训练),说明Transformer在CV领域确实是有效的,尤其是在大数据集预训练的支持之下。
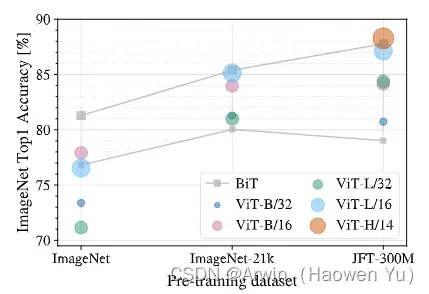
这个大数据的支持到底是多少呢?论文中作者做了相关实验,如下图所示:横轴是不同的数据集,从左往右数据集容量依次是(130万,2100万,30000万)。竖轴是分类准确率。图中两条灰色之间的性能区间是ResNet纯卷积网络能达到的性能区间;不同颜色的圆形代表不同大小的VIT模型。结果表明当数据集容量为一百万左右时,如ImageNet-1k,VIT模型的分类准确度是全面不如CNN模型的;当数据集容量为两千一百万左右时,如ImageNet-21k,VIT模型的分类准确度与CNN模型差不多;当数据集容量为30000万左右时,如JFT-300M,VIT模型的分类准确率略好于CNN模型的;
论文名称:An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale
论文下载链接:https://arxiv.org/pdf/2010.11929
论文pytorch代码实现:https://github.com/Arwin-Yu/Deep-Learning-Classification-Models-Based-CNN-or-Attention
由于文章篇幅,本篇不详细介绍Transfomer模型以及self-attention机制,但这些属于学习VIT的前置知识,望悉知。
一、Vision Transformer
在模型的设计上,尽可能地按照原始的transformer来做。目的是提供一个CV和NLP能共用的大一统算法框架,因此VIT也在后续的多模态任务上,尤其是文本和图像结合的任务中挖了一个大坑。
在这篇文章中,作者主要拿ResNet、ViT(纯Transformer模型)以及Hybrid(卷积和Transformer混合模型)三个模型进行比较。
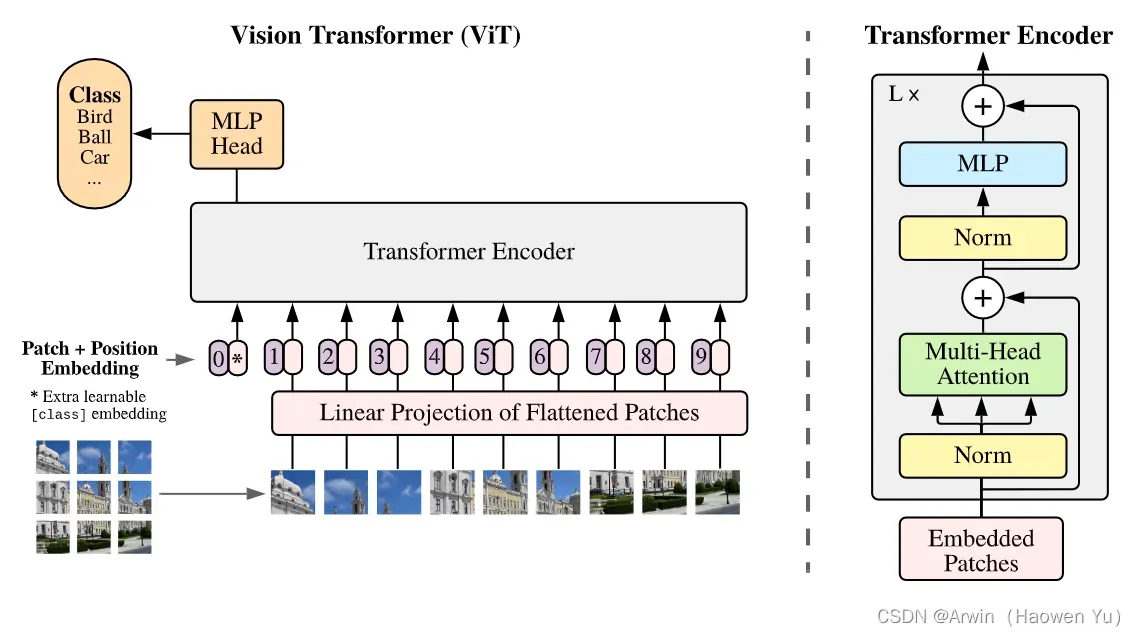
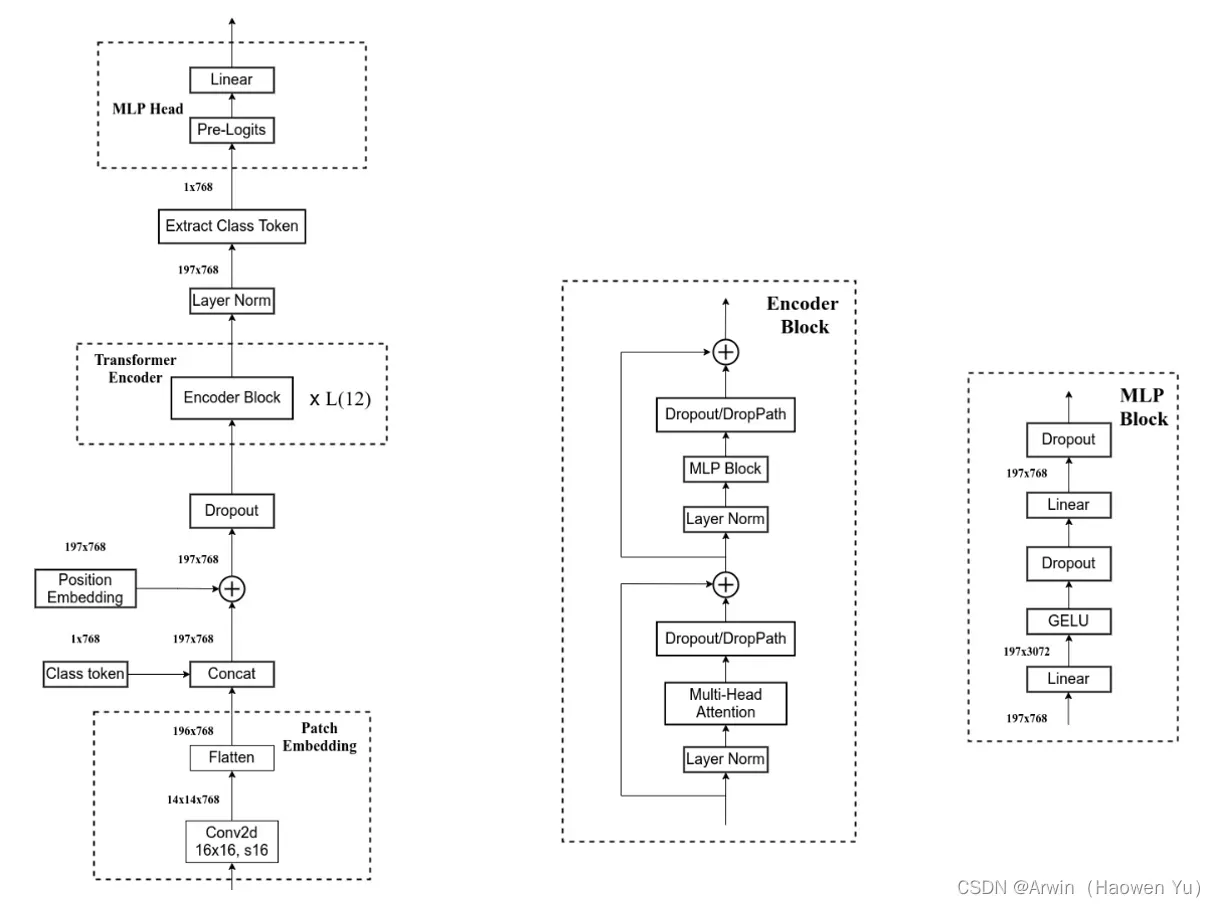
下图是原论文中给出的关于Vision Transformer(ViT)的模型框架。简单而言,模型由三个模块组成:
- Linear Projection of Flattened Patches(Embedding层,负责将子图映射成向量)
- Transformer Encoder(图右侧有给出更加详细的结构,负责对输入信息进行计算学习)
- MLP Head(最终用于分类的层结构,与CNN常用的top层设计类似)
1.Linear Projection of Flattened Patches
对于标准的Transformer模块,要求输入的是token(向量)序列,即二维矩阵[num_token, token_dim]。 对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。
以ViT-B/16为例,将输入图片(224×224)按照16×16大小的Patch进行划分,划分后会得到( 224 / 16 ) * ( 224 / 16 ) =196个Patches。接着通过线性映射(Linear Projection)将每个Patch映射到一维向量中。
至于线性映射(Linear Projection),具体来说,直接使用一个卷积核大小为16×16,步距为16,卷积核个数为768的卷积来实现线性映射,这个卷积操作产生shape变化为[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平(Flattened Patches)即可,shape变化为([14, 14, 768] -> [196, 768]),此时正好变成了一个二维矩阵,正是Transformer想要的。其中,196表征的是patches的数量,将每个Patche数据shape为[16, 16, 3]通过卷积映射得到一个长度为768的向量(后面都直接称为token)。
在输入Transformer Encoder之前注意需要加上[class]token以及Position Embedding。 在原论文中,作者使用[class]token而不是GAP(global average pooling)做分类的原因主要是参考bert,尽可能的保证模型结构与transformer类似来证明transformer在迁移到图像领域的有效性。具体做法是,在经过Linear Projection of Flattened Patches后得到的一堆tokens中插入一个专门用于分类的[class]token,这个[class]token是一个可训练的参数,数据格式和其他token一样都是一个向量,以ViT-B/16为例,就是一个长度为768的向量,与之前从图片中生成的tokens拼接在一起,维度变化为 Cat([1, 768], [196, 768]) -> [197, 768]。由于transformer block中的self-attention机制可以关注到全部的token信息,因此我们有理由相信[class]token和GAP一样都可以融合transformer学习到的全部信息用于后续的分类计算。
然后关于Position Embedding采用的是一个可训练的一维位置编码(1D Pos. Emb.),是直接叠加在tokens上的(add),所以shape要一样。以ViT-B/16为例,刚刚拼接[class]token后shape是[197, 768],那么这里的Position Embedding的shape也是[197, 768]。 自注意力是所有的元素两两之间去做交互,所以是没有顺序的,但是图片是一个整体,子图patches是有自己的顺序的,在空间位置上是相关的,所以要给patch embedding加上了positional embedding这样一组位置参数,让模型自己去学习patches之间的空间位置相关性。
在CNN里边,inductive bias(设计模型时给与模型的先验知识)是贯穿整个模型的,卷积的inductive bias是符合图像性质的,即局部相关性(localilty)和平移不变性(translationally equivalent)。对于ViT来说,只有MLP是local和translationally equivalent的,自注意力层是global的。图片的2d neighborhood structure没怎么用,只有在最开始把图片切成patch的时候用了。值得注意的是,位置编码开始的时候是随机初始化的,没有携带任何关于patch的2d的位置信息,patches之间的空间关系都必须从头开始学习。因此,ViT没有使用太多的归纳偏置,所以在中小型数据集上训练结果并不如CNN, 但是,如果有大数据的支持,VIT可以得到比CNN更高的性能,这在一定程度上反应了模型从大数据中学习到的知识要比人们给予模型的先验知识更合理。
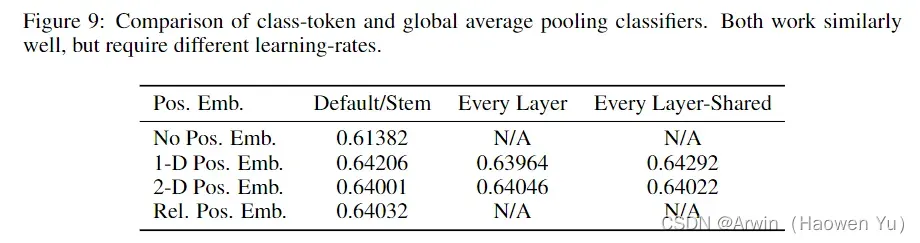
最后,作者对于不同的Position Embedding方式也有做一系列对比试验,结果如下图。在源码中默认使用的是1D Pos. Emb.,对比不使用Position Embedding准确率提升了大概3个点,和2D Pos. Emb.比起来没太大差别。作者的解释是,VIT是在patch-level上操作,而不是pixel-level。具体来说,在patch-level上,空间维度是(224/16)x(224/16),比pixel-level的小得多(224 x 224),在这个分辨率下学习表示空间位置,不论使用哪种策略,都很容易,所以结果差不多。
2.Transformer Encoder
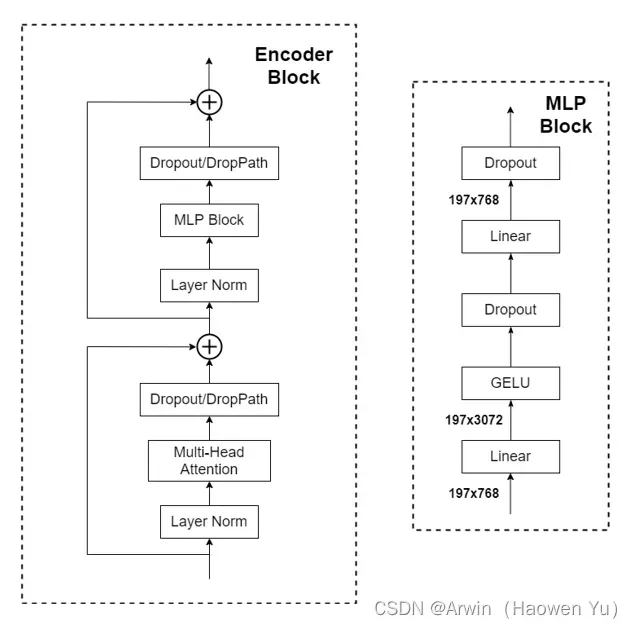
Transformer Encoder其实就是重复堆叠如下图所示的Encoder Block L次, 主要由以下几部分组成:
- Layer Norm[2],这种Normalization方法主要是针对NLP领域提出的,这里是对每个token进行Norm处理,作用类似于BN
- Multi-Head Attention,这个结构与Transfomer模型中的一模一样,这里不展开叙述了。
- Dropout/DropPath[3],在原论文的代码中是直接使用的Dropout层,在但实现的代码中使用的是DropPath(stochastic depth),可能后者会更好一点。
- MLP Block,就是全连接+GELU激活函数+Dropout组成也非常简单,需要注意的是第一个全连接层会把输入节点个数翻4倍[197, 768] -> [197, 3072],第二个全连接层会还原回原节点个数[197, 3072] -> [197, 768]
3.MLP Head
上面通过Transformer Encoder后输出的shape和输入的shape是保持不变的,以ViT-B/16为例,输入的是[197, 768]输出的还是[197, 768]。注意,在Transformer Encoder后其实还有一个Layer Norm没有画出来,下面有我自己画的ViT的模型可以看到详细结构。
这里我们只是需要分类的信息,所以我们只需要提取出[class]token生成的对应结果就行,即[197, 768]中抽取出[class]token对应的[1, 768],因为self-attention计算全局信息的特征,这个[class]token其中已经融合了其他token的信息。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
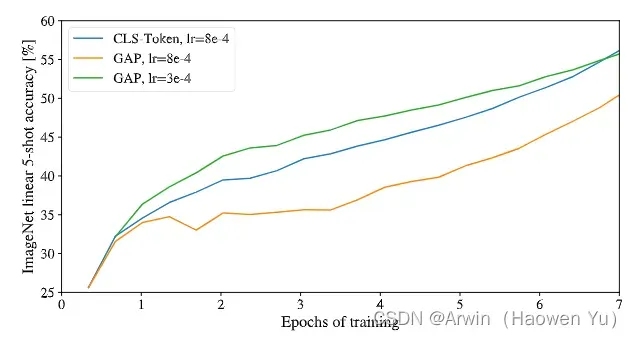
值得注意的是,关于[class]token和GAP在原文中作者也是通过一些消融实验来比较效果的,结果证明,GAP和[class]token这两种方式能达到的分类准确率都差不多,所以,为了尽可能模仿Transfomer,这里选用了[class]token的计算方式,具体实验结果如下图
4.model scaling
在论文的Table1中有给出三个不同大小的模型(Base/ Large/ Huge)参数,在源码中除了有Patch Size为16×16的外还有32×32的。下表中的Layers就是Transformer Encoder中重复堆叠Encoder Block的次数,Hidden Size就是对应通过Embedding层后每个token的dim(向量的长度),MLP size是Transformer Encoder中MLP Block第一个全连接的节点个数(是Hidden Size的四倍),Heads代表Transformer中Multi-Head Attention的heads数。

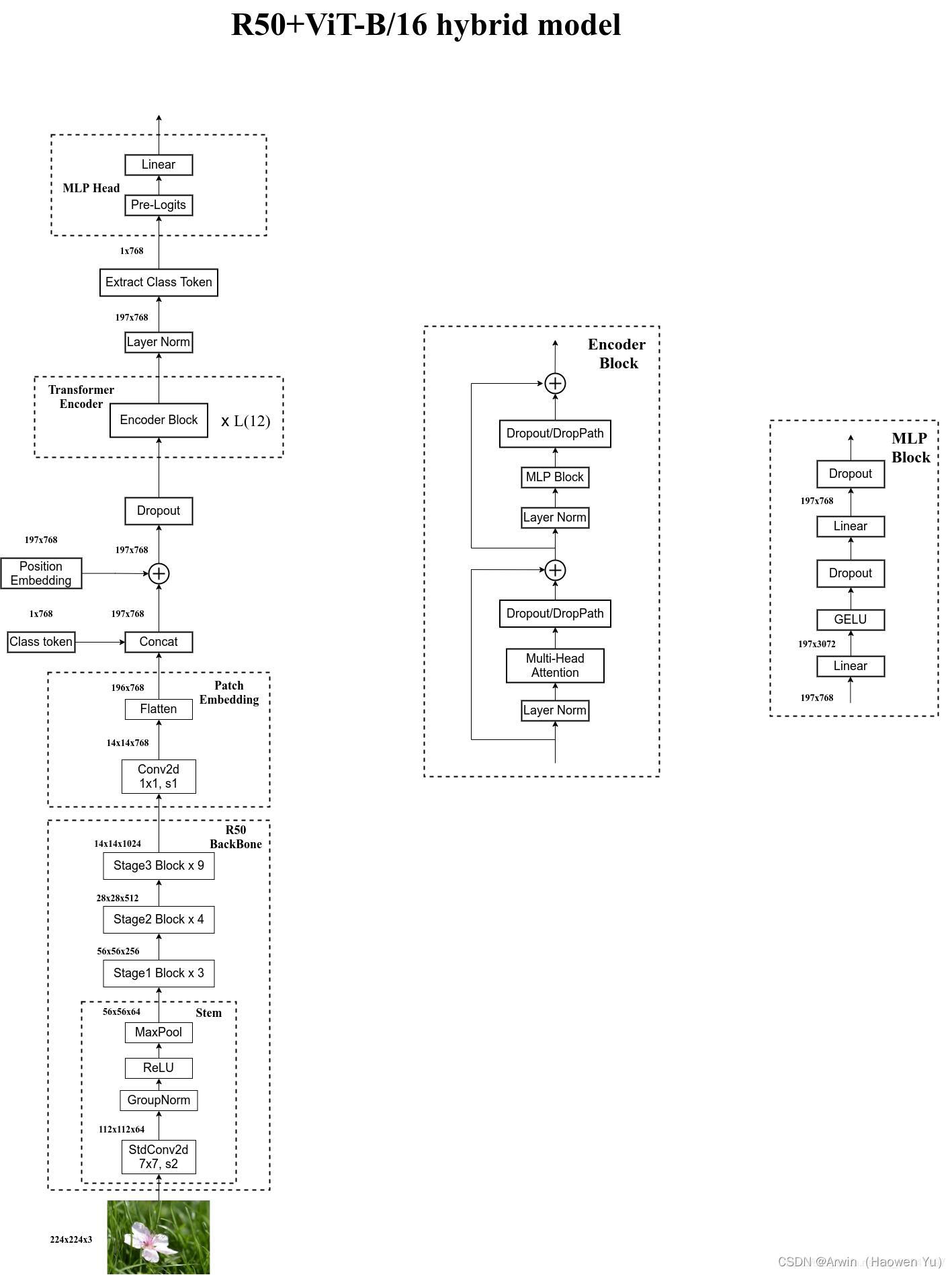
二、Hybrid Vision Transformer
在论文4.1章节的Model Variants中有比较详细的讲到Hybrid混合模型,就是将传统CNN特征提取和Transformer进行结合。下图绘制的是以ResNet50作为特征提取器的混合模型,但这里的Resnet与之前讲的Resnet有些不同。首先这里的R50的卷积层采用的StdConv2d不是传统的Conv2d,然后将所有的BatchNorm层替换成GroupNorm层。在原Resnet50网络中,stage1重复堆叠3次,stage2重复堆叠4次,stage3重复堆叠6次,stage4重复堆叠3次,但在这里的R50中,把stage4中的3个Block移至stage3中,所以stage3中共重复堆叠9次。
通过R50 Backbone进行特征提取后,得到的特征矩阵shape是[14, 14, 1024],接着再输入Patch Embedding层,注意Patch Embedding中卷积层Conv2d的kernel_size和stride都变成了1,只是用来调整channel,最后也会变成[196, 768]的shape。后面的部分和前面ViT中讲的完全一样,就不在赘述。
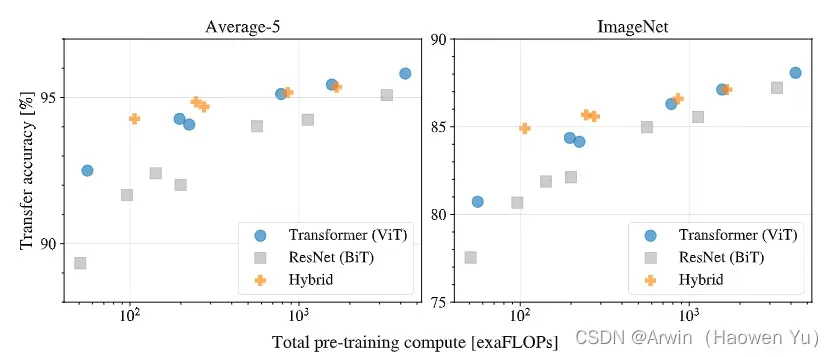
实验结果如下, 横轴表示模型的计算复杂度,即模型大小;竖轴是分类准确率,左图画的是五个数据集上的综合表现,右图画的是ImageNet数据集上的表现。结果表明,当模型较小时,hybrid-vit表现最好,这也是可以理解的,毕竟hybrid-vit综合了两个算法的优点。但是,当模型较大时,纯vit模型的效果最好,个人认为,这一定程度上说明了vit模型自己从数据集中学习到的知识比人们根据先验赋予cnn模型的知识更有意义。
三、总结
VIT这个工作的出发点是证明从NLP领域迁移过来的模型Transformer照样可以很好的处理图像数据,尤其是再大数据的支持下。这首次动摇了CNN模型在CV领域的统治地位。因此,很多学者都想弄清楚是什么让Transformer效果这么好?
由于Transformer的论文中力推self-attention机制,所以以后的很多年中,人们先入为主的认为self-attention在Transformer中起到了重要作用,但是最近的一些工作证明了事实并非如此。有人将VIT中Transformer Encoder中的mutil head self-attention操作换成了MLP,模型照样可以获得不错的性能,这个工作证明了self-attention不是Transformer中的必要操作。值得注意的是,当把mutil head self-attention操作换成了MLP,整个VIT模型其实变成了一个纯MLP模型,又发展回深度学习的起点算法了—- 神经网络算法,甚至形成了 CNN, Transformer,MLP三足鼎立的事态。
另外,有些激进的学者直接将Transformer中的self-attention替换成了没有可学习参数的pooling层,结果模型照样可以有不错的性能,因此,他们认为,Transfomer成功的关键是整体的模型框架设计,他们把这个框架称之为MetaFormer。因此,到底是什么让Transmer这么有效?这个问题在学术界依然没有同一的答案,有人说self-attention is all you need;有人说 MLP is all you need;有人说patch is all you need,也有人说 MetaFormer is all you need。但是,我觉得,Transfomer效果好的前提是大量训练数据的支持,训练这些数据需要大量的计算资源,所以答案是 Money is all you need!(开玩笑的哈,别当真)。
在CV中,深度学习算法最初从MLP发展到CNN, 又从CNN发展到Transfomer,如今看上去又回到了MLP,但是,需要注意的是现在的MLP模型,如mlp-mixer,跟最初代的MLP是不一样的,是有改进的。历史上,技术的发展总是螺旋上升的,我很期待经过Transfomer和MLP的冲击,CNN是否回厚积薄发,重夺在CV中的统计地位。
四、引用
[1] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.
[2] Ba J L, Kiros J R, Hinton G E. Layer normalization[J]. arXiv preprint arXiv:1607.06450, 2016.
[3] Huang, G., Sun, Y., Liu, Z., Sedra, D., & Weinberger, K. Q. (2016, October). Deep networks with stochastic depth. In European conference on computer vision (pp. 646-661). Springer, Cham.
文章出处登录后可见!