功能说明
github 项目SadTalker 可以根据一张图片、一段音频,合成面部说这段语音的视频。图片需要真人或者接近真人。目前项目已经支持stable diffusion webui,可以SD出图后,结合一段音频合成面部说话的视频(抖音常见的数字人)
SadTalker安装过程
内访问速度比较慢,使用ghproxy加速,格式https://ghproxy.com/{github url}
https://ghproxy.com/https://github.com/OpenTalker/SadTalker
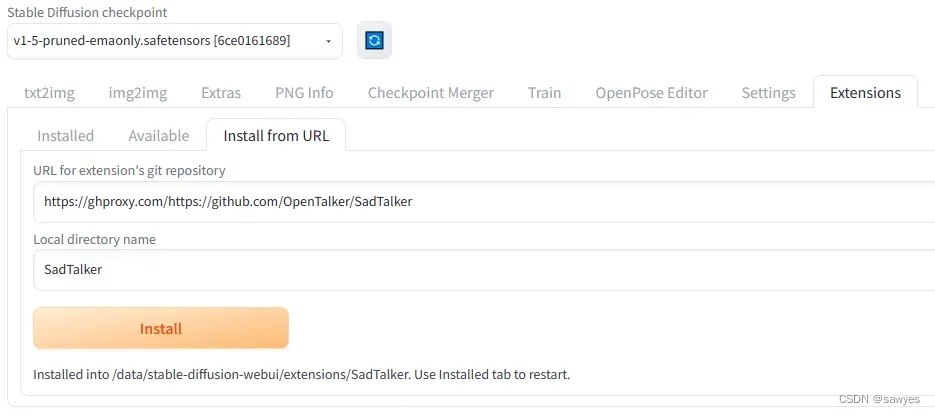
如图在extensions中填入地址,和下载后的目录名称,下载的文件将存放在{project你的项目}/stable-diffusion-webui/extensions,并且文件夹的文字和页面输入的一致SadTalker
上一步插件安装完成后,还需要继续补充两个压缩包文件,分别放到对应目录
-
根据仓库代码 download_models得知下载地址,手动下载,主要是两个目录文件
checkpoints和gfpgan -
也可以百度云盘:
- 模型checkpoints, 提取码: sadt.
- gfpgan, 提取码: sadt.
checkpoints:整个checkpoints放在 {project}/stable-diffusion-webui/extensions/SadTalker扩展目录下;
gfpgan: 解压搓来的4个文件alignment_WFLW_4HG.pth detection_Resnet50_Final.pth GFPGANv1.4.pth parsing_parsenet.pth需要放在 {project}/stable-diffusion-webui/models/GFPGAN
继续下一步环境配置
ffmpeg:视频生成需要用到(根据环境不同选择适合自己的方式),以下是centos8安装方式
dnf install epel-release
yum config-manager --set-enabled PowerTools
yum-config-manager --add-repo=https://negativo17.org/repos/epel-multimedia.repo
dnf install ffmpeg ffmpeg
ffmpeg -version
重新启动程序python3 launch.py --enable-insecure-extension-access --xformers --server-name 0.0.0.0
使用教程(一)linux下部署sdwebui,安装模型和插件的图片来试试效果,关于参数说明
- 图片,最好是大头,不然会显得不自然
- 音频文件,用SadTalker示例的音频测试
- 图片处理方式氛围,crop(剪裁), resize(重置大小), full(原图),其中
crop根据面部关键点生成的表情和动画相对逼真,前提是不要全图,看起来会很怪 - Remove head motion (works better with preprocess full) 这个选项在原图的时候很有必要,优化人物头部运动,生成的视频更加自然;这里因为用了剪裁,所以就不选择打开了
- Face enhancement,勾选上, 可以获得更好的面部质量

视频被CSDN处理过,看起来有些不自然,实际效果还是不错的
[video(video-phSCxqv2-1682868060919)(type-csdn)(url-https://live.csdn.net/v/embed/293783)(image-https://video-community.csdnimg.cn/vod-84deb4/bb37ebe0e76971edbdc60764a3fd0102/snapshots/31b790e8ec164ef291c9a86b488c4ec4-00002.jpg?auth_key=4836467687-0-0-f1e4217a71b0a2493dff06c61b65ea10)()]文本生成语音涉及太多非技术问题,就不展开了,自行看TTS-Vue项目
文章出处登录后可见!