论文导读:
- 论文背景: 2023年8月,AI大神何恺明在个人网站宣布,2024年将加入MIT担任教职,回归学术界。这篇论文是其官宣加盟MIT后首度与MIT师生合著的公开论文,论文一作本科毕业于清华姚班,二作为MIT电气工程与计算机科学系教授,今年的斯隆奖得主,美国科学院院士。
- 面向问题: 图像生成领域中,有条件的图像生成(基于类别标签或文本描述进行条件生成)与无条件的图像生成(完全无条件生成)之间存在很大的性能差距。无条件图像生成一直是一个更具挑战性的任务。
- 解决方法: 文章提出了一种自条件图像生成方法RCG(Representation-Conditioned image Generation)。该方法不依赖任何人工标注,而是基于一个自监督图像编码器提取的图像表示来指导图像生成过程。文章使用表示扩散模型RDM对表示空间建模并从中采样表示,然后基于采样得到的表示指导像素生成器生成图像。
- 技术亮点:
– 使用自监督对抗学习方法预训练编码器,将图像分布映射到紧凑的表示分布。
– 提出表示隐扩散模型RDM,对表示空间建模并生成表示。
– 生成的表示为像素生成器提供强有力的指导,大大提升无条件图像生成的性能。- 主要贡献:
– 提出自条件图像生成框架,使用自监督学习表示来指导生成过程, 弥合了无条件和有条件图像生成的性能差距。
– 在ImageNet 256×256 数据集上得到3.31 FID和253.4 IS,超越了之前所有无条件和大多数有条件图像生成方法。- 代码开源: https://github.com/LTH14/rcg.
- 论文地址: https://arxiv.org/abs/2312.03701
Abstract:
本文提出了一种表示条件图像生成(Representation-Conditioned image Generation,RCG)方法,这是一种简单却有效的图像生成框架,它为无类别图像生成建立了新的基准。RCG不依赖任何人工标注。相反,它依赖于一个预训练编码器映射出来的自监督表示分布(self-supervised representation distribution )。在生成过程中,RCG使用表示扩散模型(representation diffusion model,RDM)对这样的表示分布进行采样,并使用像素生成器根据采样出的表示生成图像像素。这样的设计为生成过程提供了实质性的指导,导致了高质量的图像生成。在ImageNet 256×256上测试,RCG取得了3.31的Frechet Inception Distance(FID)和253.4的Inception Score(IS)。这些结果不仅显著提高了无类别条件图像生成(class-unconditional image generation)的最新结果,而且与当前带类别条件的图像生成方法的领先成果不相上下,弥合了这两项任务之间长期存在的性能差距。
Introduction:
最近,条件图像生成方面取得了令人印象深刻的进展,利用人类标注比如类别标签或文本描述来指导生成过程[11,12,18,22,47,51]。相比之下,不带条件的图像生成由于省略了这样的条件元素,历来一直是更具挑战性的任务,通常产生的结果不那么令人印象深刻[3,18,19,39,43]。
这种差异反映了有监督学习和无监督学习之间的差异。历史上,无监督学习的表现一直落后于其有监督的对应部分。随着自监督学习(self- supervised learning,SSL)的出现,这一差距正在缩小, 因为SSL可以从数据本身生成监督信号,取得了与有监督学习相当甚至更好的结果[9,13,25–27]。
受此类比启发,我们考虑自条件图像生成问题,作为图像生成领域中对应自监督学习的问题。这种方法与传统的无条件图像生成不同,它通过从数据分布本身派生的表示分布来约束像素生成过程,如图1c所示。
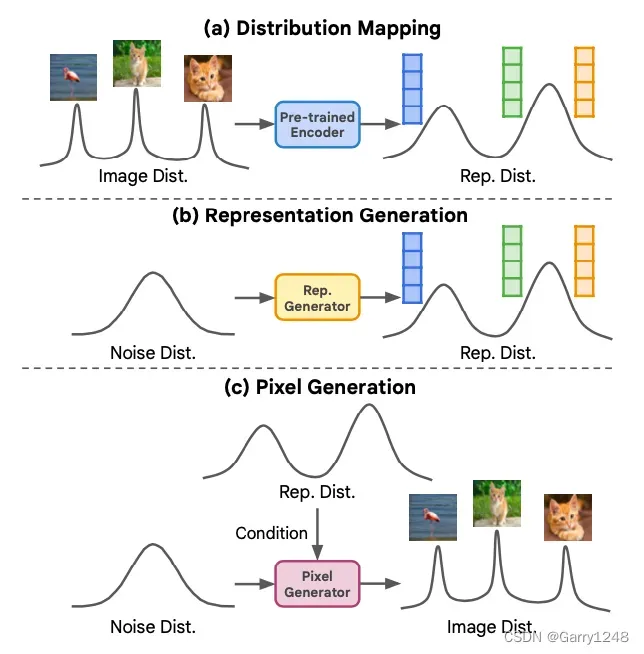
图 1. 自条件图像生成框架。 与简单地将噪声分布映射到图像分布的传统无条件图像生成方法不同,自条件图像生成由三个部分组成:(a)它使用图像编码器(例如,Moco v3)将原始图像分布映射到低维表示分布; (b)它学习表示生成器将噪声分布映射到表示分布; (c)它学习像素生成器(例如LDM [51]或MAGE [39])以将噪声分布映射到以表示分布为条件的图像分布。
自条件图像生成具有几个意义:
- 首先,表示上的自条件是无条件图像生成更为直观的方法,它模仿艺术家先构思抽象理念然后把它翻译到画布上的过程。
- 其次,与自监督学习已经超越监督学习一样,利用大量无标注数据集的自条件图像生成,有潜力超过条件图像生成的性能。
- 第三,通过省略对人工标注的依赖,自条件生成为那些超出人类标注能力的域的生成应用铺平了道路,如分子设计或药物发现。
自条件图像生成的核心在于准确建模和从图像表示分布中采样(图1b)。这样的图像表示也应保留足够的高层语义内容以指导像素生成过程。为实现这一点,我们开发了一个表示扩散模型(Representation Diffusion ModelRDM)来生成低维的自监督图像表示。该分布由自监督图像编码器从图像分布映射而来(图1a)。我们的方法提供了两个重要优势:
- 首先,RDM可以捕获表示空间基础分布的多样性,使其能够生成各种表示以方便图像生成。
- 其次,这个自监督表示空间结构化且维度低,这简化了直接的神经网络体系结构的表示生成任务。因此,与像素生成过程相比,生成表示的计算开销可以忽略。
借助RDM,我们提出了表示条件图像生成(Representation-Conditioned image Generation,RCG),这是一个简单而有效的自条件图像生成框架。RCG由三个部分组成:
- 一个自监督对比学习方法预训练的SSL图像编码器(Moco v3 [16]),将图像分布转化为一个紧凑的表示分布;
- 一个RDM来对这个分布建模并从中采样;
- 以及一个像素生成器根据表示来生成图像像素。这种设计使RCG可以与常见的图像生成模型无缝集成作为其像素生成器,从而极大地提升它们的无类别条件图像生成性能(图2)。
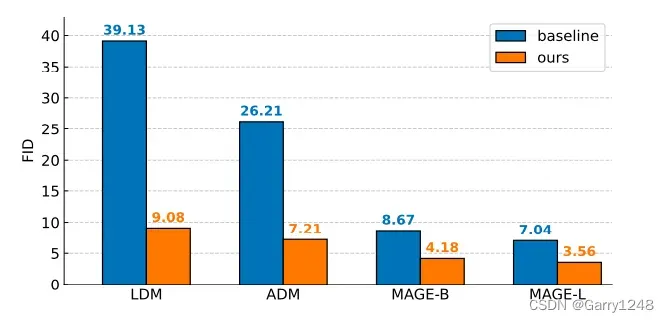
图 2. 使用不同像素生成器在 ImageNet 256×256 上的无类别条件图像生成性能。 无论像素生成器基线的选择如何,我们的方法都极大地提高了无类别条件生成质量。
RCG展现了异常出色的图像生成能力。在ImageNet 256×256上评估,RCG取得3.56的FID和186.9的Inception Score,明显优于之前所有无类别条件图像生成方法(最接近的状态结果为7.04 FID和123.5 Inception Score [39])。通过classifier-free guidance,这些结果可以进一步提升到3.31 FID和253.4 Inception Score。值得注意的是,我们的结果与当前类别条件生成的基准相当或甚至有过之而无不及。这些结果强调了自条件图像生成的巨大潜力,预示着这一领域可能正在迎来一个新时代。
Related Work
自监督学习。
在相当长的一段时间里,有监督学习在各种计算机视觉任务中优于无监督学习[8,28,29,63]。然而,自监督学习的出现显著缩小了这一性能差距。自监督学习的最初努力集中在创建预训练任务并训练网络来预测相关的伪标签[23,44,46]。更近期的研究表明,对比学习[14,15,38,45]提供了一个稳健系统的方法来学习有效的表示,其结果几乎与有监督学习相当。研究人员还发现,掩码图像建模(masked image modeling,MIM)在自监督学习中非常有效[4,26,35,39,48]。自监督学习的这些进展引领我们探索自条件图像生成的概念。我们提出的RCG框架利用前沿的自监督学习方法将图像分布映射到一个紧凑的表示分布。
图像生成
近年来,深度生成模型在图像合成方面取得了巨大进展。一种主要的生成模型流派建立在生成对抗网络(GAN)[7,24,36,61,62]的基础之上。另一种流派基于两阶段方案[11,12,37,39,50,59,60]:首先将图像量化到隐空间,然后在隐空间中应用最大似然估计和采样。最近,扩散模型[18,31,49,51,55]在图像合成方面也取得了卓越的成果。一个相关的工作是DALLE 2 [49]生成基于CLIP的图像嵌入,这些嵌入是基于CLIP文本嵌入和图像caption的,并基于生成的图像嵌入生成图像,在文本到图像生成中展现出优异的性能。
尽管在这些模型中表现令人印象深刻,但在这些模型的条件生成和无条件生成能力之间存在一个显著的差距[3,18,19,39,43]。为弥合这一差距,之前的工作将图像分类到表示空间中的clusters,并使用这些clusters作为基础类别标签进行自条件或自引导[3,34,40]。但是,这隐含地假定数据集本应是分类数据集,并且最佳clusters数接近类别数。
另外两个相关工作是RCDM [5]和IC-GAN [10],这些方法根据从现有图像中提取的表示生成图像。尽管如此,这些方法依赖于真实图像来在生成过程中提供表示,这在许多生成应用中是不切实际的要求。
RCG的条件化与所有先前的工作不同。与之前的自条件方法生成表示空间中预计算的离散clusters集合作为条件化不同,RCG学习一个表示扩散模型来对表示空间的基础分布建模并从中生成表示。这种SSL表示的生成是通过一个简单而有效的表示扩散模型实现的。在我们所知的范围内,这是第一次探索生成低维SSL表示并将其用作图像生成的条件。这种从这样一个表示分布中建模和采样的能力允许像素生成过程在没有人类标注的情况下受到对图像的全面理解的指导。因此,这导致了与以前的方法相比在无条件图像生成中的显着更好的性能。
Method
RCG由三个关键组成部分组成:一个预训练的自监督图像编码器,一个表示生成器和一个像素生成器。每个组件的设计如下阐述:
-
图像编码器。 RCG采用一个预训练的图像编码器,将图像分布过渡到一个表示分布。这个分布特征由两个关键属性描绘:简单性以适合由一个表示扩散模型建模,以及丰富的高层语义内容以指导像素生成。我们使用通过自监督对比学习方法(Moco v3 [16])预训练的图像编码器,这些方法在ImageNet上取得了表示学习的最先进结果,同时将表示正则化到一个超球面上。我们取这些编码器在投影头后面的256维表示,每个表示经过自己的均值和标准差归一化。
-
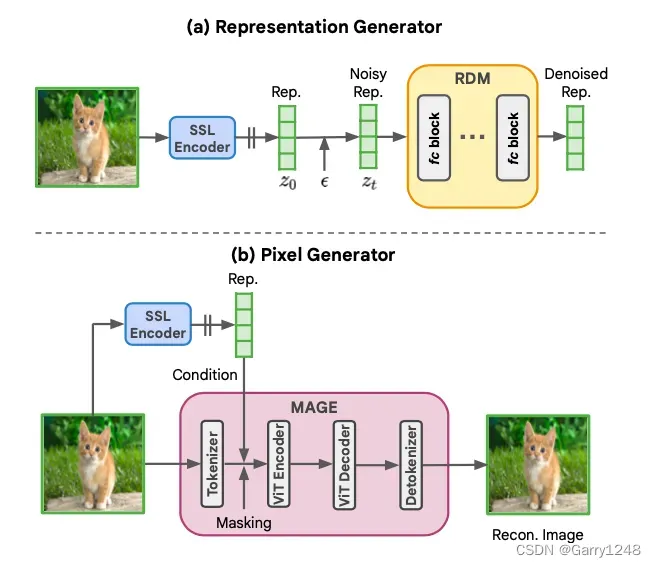
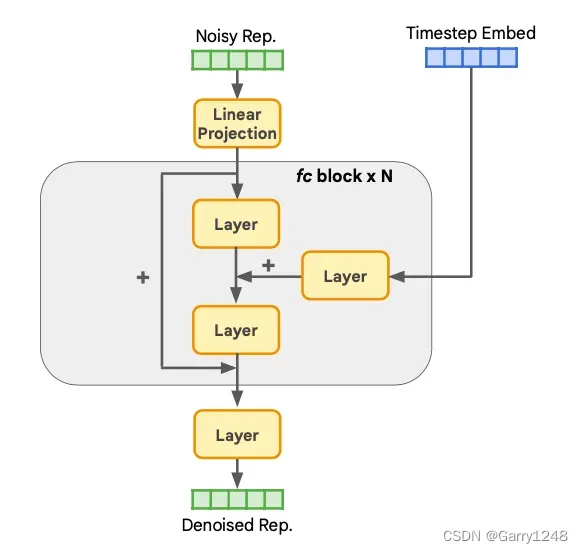
表示生成器。 RCG使用一个简单但有效的表示扩散模型(RDM)对表示空间进行采样。RDM采用一个完全连接的网络作为其骨干,包含多个残差块,如图4所示。每个块由一个输入层、一个时间步嵌入投影层和一个输出层组成,其中每个层由LayerNorm [1]、SiLU [21]和一个线性层组成。这样一个结构由两个参数控制:残差块数
和隐藏维度
。RDM遵循Denoising Diffusion Implicit Models (DDIM) [54]进行训练和推理。如图3a所示,在训练过程中,图像表示
与标准高斯噪声变量
进行混合:
。RDM骨干网络然后训练去噪
回到
-
像素生成器。 RCG中的像素生成器根据图像表示生成图像像素。概念上,这样的像素生成器可以是任何现代的条件图像生成模型,通过用自监督表示替换其原始的条件化(例如,类别标签或文本)。在图3b中,我们以MAGE [39],一个并行解码生成模型为例。像素生成器被训练以重建原始图像的一个掩码版本,条件化于同一图像的表示。在推理时,像素生成器从一个完全掩码的图像生成图像,条件化于来自表示生成器的表示。我们实验了三个代表性的生成模型:ADM [18]和LDM [51],两者都是基于扩散的框架,以及MAGE [39],一个并行解码框架。我们的实验表明,当条件化于高层表示时,所有三个生成模型都取得了更好的性能(图2和表6b)。
-
无分类器指导(Classifier-free Guidance)。 RCG的一个优势是它无缝地帮助其像素生成器实现无分类器指导。无分类器指导以前只适用于有条件的图像生成任务 [33,39]。这是因为无分类器指导本身设计为通过无条件生成来指导有条件图像生成。尽管RCG也面向无条件生成任务设计,但RCG的像素生成器条件化于自监督表示,因此可以无缝集成无分类器指导,这进一步提升了其生成性能。RCG遵循Muse [11]在其MAGE像素生成器中启用无分类器指导。在训练过程中,MAGE像素生成器以10%的概率在没有条件化于SSL表示的情况下进行训练。在每一推理步骤中,MAGE基于SSL表示预测一个logit
,以及一个无条件的logit
,针对每个掩码token。最终的logit
通过
:
。然后MAGE根据
对剩余的masked tokens进行采样以填充。关于RCG无分类器指导的更多实现细节在附录B中提供。
实验结果
实验设置
我们在ImageNet 256×256数据集上评估RCG,这是一个常用的图像生成基准数据集。我们生成5万幅图像,并报告Frechet Inception Distance (FID)和Inception Score (IS)作为标准指标来衡量生成图像的保真度和多样性。FID基于ImageNet验证集测量。在RCG像素生成器的训练过程中,图像被重新调整大小,使得较短边长度为256,然后随机翻转和裁剪为256×256。 输入到SSL编码器的图像进一步调整大小为224×224以匹配其位置嵌入大小。 在我们的主要结果中,RCG-L使用Moco v3预训练的视觉Transformers (ViT-L)作为图像编码器,一个具有12个块和1536个隐藏维度的网络作为RDM的主干,并使用MAGE-L 作为图像生成器。 RDM训练200个epoch,学习率保持不变,MAGE-L训练800个epoch,使用余弦学习率调度。 更多实现细节和超参数在附录B中给出。
无类别条件下的生成
在表1中,我们将RCG与最先进的生成模型在ImageNet 256×256上的性能进行了比较。 由于传统的无类别条件下的生成既不支持分类器也不支持无分类器指导,表1中的所有结果都未使用此类指导报告。
如图5和表1所示,RCG可以生成保真度和多样性都很高的图像,实现3.56 FID和186.9 Inception Score,这明显优于以前的无类别条件下的图像生成的最新结果。 此外,这种结果也优于以前的有类别条件下的生成的最佳结果(CDM达到4.88 FID),消除了历史上有类别条件生成和无类别条件生成之间的差距。 我们在附录A中进一步显示,我们的表示扩散模型可以毫不费力地促进有类别条件的表示生成,从而使RCG也可以熟练执行有类别条件的图像生成。 这些结果证明了RCG的有效性,并进一步强调了自条件化图像生成的巨大潜力。

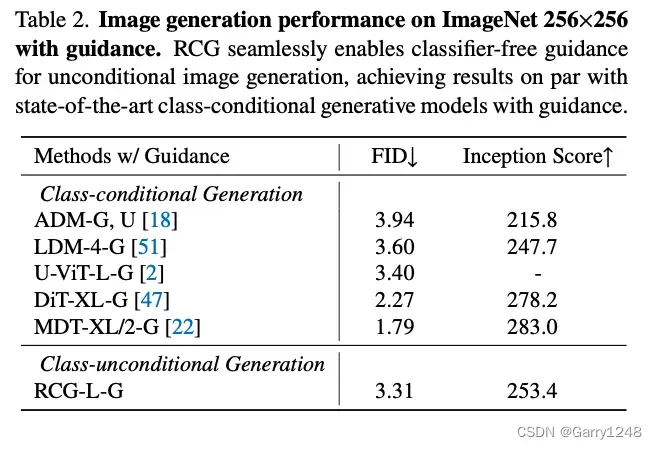
无分类器指导
传统的无类别条件图像生成框架既缺乏在没有类别标签的情况下使用分类器指导的能力,也与无分类器指导不兼容,因为指导本身来自无条件生成。 RCG的一个重要优势在于它可以将无分类器指导集成到其像素生成器中。 如表2所示,无分类器指导显著提高了RCG的性能,达到了与领先的有类别条件图像生成方法利用指导相当的水平。 我们还对无分类器指导尺度进行了ablation study,如表3所示。
可以同时改善FID和IS,更大的
继续提高Inception Score。
Ablation study
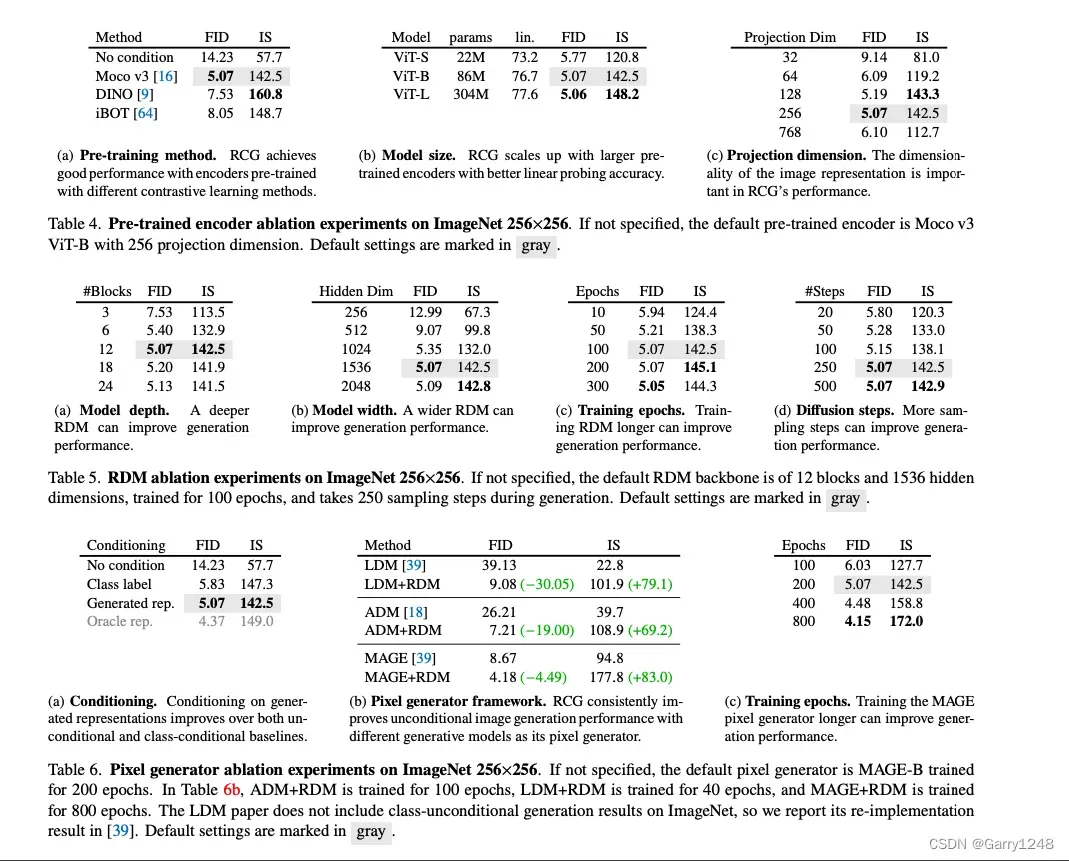
本节对RCG的三个核心组件进行了全面的ablation study。 我们的默认设置使用Moco v3 ViT-B作为预训练图像编码器,RDM具有12个块和1536隐藏维度的主干,并将MAGE-B像素生成器训练200个epoch。 除非另有说明,否则在每个组件的单独ablation study期间,所有其他属性和模块均设置为默认设置。
预训练编码器。 表4探索了不同的预训练图像编码器设置。 表4a比较了使用各种SSL方法(Moco v3、DINO和iBOT)训练的图像编码器,强调它们相对于无条件基线的重大改进。 此外,使用DeiT以监督方式训练的编码器也表现出令人印象深刻的性能(5.51 FID和211.7 IS),表明RCG适用于有监督和自监督预训练方法。
表4b评估模型大小对预训练编码器的影响。 更大的模型具有更好的线性探测精度,一致地提高了生成性能,尽管较小的ViT-S模型(22M参数)仍然取得了不错的结果(5.77 FID和120.8 IS)。
我们进一步分析了图像表示维度对性能的影响,使用具有不同输出维度的Moco v3 ViT-B模型。表4c显示过低或过高维表示都不理想——过低维会损失重要的图像信息,而过高维则对表示生成器提出了挑战。
表示生成器。表5 ablation表示扩散模型。 RDM的体系结构由全连接块组成,网络的深度和宽度分别由块数和隐藏维数决定。表5a和表5bablation这些参数,表明12个块和1536个隐藏维度之间达到了最佳平衡。 此外,表5c和表5d表明RDM的性能在约200个训练周期和250个扩散步骤时饱和。 尽管只带来很小的计算成本,但RDM证明在生成SSL表示方面非常有效,如表6a所示。
像素生成器。表6 ablationRCG的像素生成器。表6a使用无类别条件、有类别条件和自条件化MAGE-B实验不同的条件。如果没有任何条件,则为200 epoch训练的无条件MAGE-B只产生14.23 FID和57.7 IS。 另一方面,当基于生成的表示进行条件化时,MAGE-B实现了5.07 FID和142.5 IS,这不仅明显优于无类别条件基线,而且在FID方面也优于有类别条件基线。 这表明表示可能比类别标签提供更多指导。 这也很接近“上限”,上限在像素生成过程中使用ImageNet真实图像中的参考表示进行条件化,这证明了RDM在生成真实SSL表示方面的有效性。
过去的自我条件化图像生成工作主要集中在将图像表示空间内的图像分类为clusters,并使用这些clusters作为伪类条件。我们还评估了RCG中基于聚类的条件的性能,使用Moco v3 ViT-B表示空间内的k-means形成1000个clusters。 这种条件得到6.60 FID和121.9 IS,低于基于生成表示的条件结果。 这是因为这样的离散簇中包含的信息有限,不足以为像素生成过程提供详细的指导。 还需要注意的是,这种聚类方法依赖于对总类别数的先验知识,而这在一般无标签数据集中通常是不可用的。
从概念上讲,RCG的像素生成器可以与各种生成模型集成。 我们通过测试ADM、LDM和MAGE作为像素生成器来验证这一点。 如表6b所示,基于表示进行条件可以显着提高所有三种生成器的无类别条件生成性能。 此外,表6c表明进一步扩展培训周期可以提高性能,这与现有研究结果一致。 这些结果表明RCG是一个通用的自条件化图像生成框架,与不同的现代生成模型相结合可以显着提高无类别条件下的生成性能。
计算成本
在表7中,我们详细评估了RCG的计算成本,包括参数数量、训练成本和生成吞吐量。 训练成本使用64个V100 GPU集群测量。 生成吞吐量在单个V100 GPU上测量。 由于LDM和ADM在单个NVIDIA A100上测量其生成吞吐量,我们通过假设A100相对于V100具有2.2倍的加速来将其转换为V100吞吐量。
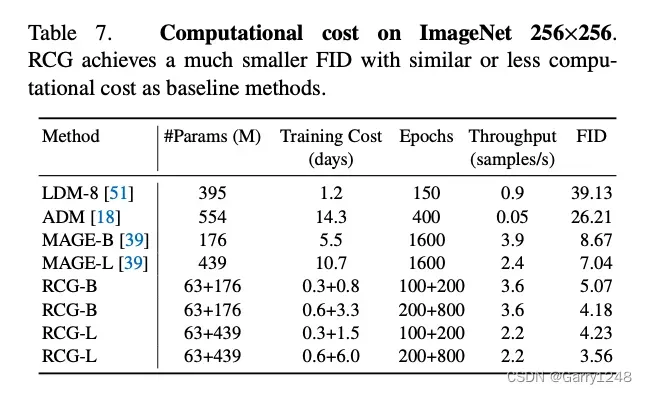
RCG-L使用预训练的Moco v3 ViT-L编码器,具有12个块和1536隐藏维度的RDM,以及MAGE-L像素生成器。 训练阶段涉及RDM的200个epoch和MAGE-L的800个epoch。 在生成过程中,RDM经历250步扩散,而MAGE-L执行20步并行解码。 我们还报告了RCG-B的计算成本和FID,其中使用较少的训练成本和更小的参数数量(Moco v3 ViT-B作为图像编码器,MAGE-B作为像素生成器)。 考虑到Moco v3 ViT编码器是预先训练的,在生成中不需要,因此其参数和训练成本被排除在外。 如表所示,RDM模块相对于像素生成器增加的成本很小。 这证明了RCG与现代生成模型的兼容性,突出了其通过最小的计算负担增强生成性能的能力。
定性结果
表示重建。图6说明了RCG根据给定表示生成与语义一致的图像的能力。我们使用ImageNet 256×256中的示例提取SSL表示。 对于每个表示,我们通过改变生成过程的随机种子来生成各种图像。 RCG生成的图像在具体细节上有所不同,但始终捕获了原始图像的语义本质。 这个结果突出了RCG利用图像表示中的语义信息来指导生成过程的能力,而不会损害无条件图像生成中多样性的重要性。

表示插值。 利用RCG对表示的依赖性,我们可以通过线性插值两幅图像各自的表示在语义上在两幅图像之间过渡。 图7展示了ImageNet图像对之间的这种插值。 插值图像在不同的插值率下保持逼真,它们的语义内容平滑地从一幅图像过渡到另一幅图像。 这表明RCG的表示空间既光滑又语义丰富。 这也证明了RCG在低维表示空间中操纵图像语义的潜力,为控制图像生成提供了新的可能性。

讨论
计算机视觉已经进入了一个新的时代,在这个时代中,从广泛的无标注数据集中学习变得越来越常见。尽管如此,图像生成模型的训练仍主要依赖于标注数据集,这可能归因于有条件和无条件图像生成之间的巨大性能差距。 我们的论文通过探索自条件化图像生成来解决这个问题,我们将其提出为有条件和无条件图像生成之间的纽带。 我们证明,通过基于SSL表示生成图像并利用表示扩散模型对表示空间进行建模和采样,可以有效地弥合这一长期存在的性能差距。 我们相信,这种方法有望解放图像生成对人类标注的限制,使其能够充分利用海量无标注数据,甚至可以推广到超出人类标注能力范围的模态。
文章出处登录后可见!