目录
一、查找的相关概念介绍
1.查找表(Search Table)
概念
查找表是由同一类型的数据元素(或记录)构成的集合
对查找表的操作
1.查询某个特定数据元素是否在查找表种
2.检索某个特定元素的各种属性
3.在查找表中插入一个数据元素
4.从查找表中删除某个数据元素
查找表的分类
1. 静态查找表:仅作查询和检索操作的查找表
2. 动态查找表: 在查找的过程中同时插入查找表中不存在的数据元素或者从查找表中删除已存在的某个数据元素
2.关键字(Key)
概念
关键字是数据元素(或记录)中的某个数据项的值,用来标识(识别)一个数据元素(或记录)
主关键字:可以识别唯一一个记录的关键字
次关键字:能识别若干记录的关键字
3.查找(Searching)
概念
查找是根据某个给定的值在查找表中确定一个其关键字等于给定值的数据元素(或记录)
查找成功:在查找表中查找到指定的数据元素(或记录)
查找失败:在查找表中没有找到指定的数据元素(或记录)
4.衡量查找算法的标准
1.时间复杂度
一个查找算法的时间复杂度越低,说明利用这个查找算法查找到对应关键字的数据元素就越快
2.空间复杂度
一个查找算法的空间复杂度越低,说明这个查找算法占用的内存空间少
3.平均查找长度(ASL)
平均查找长度为确定数据元素(或记录)在表中的位置所进行的和关键字比较的次数的平均值
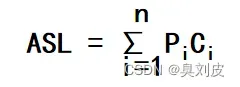
n:查找表的长度,即表中所含元素(或记录)的个数
Pi:查找到第i个元素的概率
Ci:查找第i个元素时,和各个数据元素(或记录)的关键字比较的次数
二、静态查找表
1.顺序查找
算法思路
i.从表中的最后一个数据元素开始
ii.逐个进行数据元素的关键字和给定值进行比较
iii.如果某个数据元素的关键字与给定值比较相等,则查找成功
iv.如果直到第一个数据元素都比较不相等,则查找不成功
算法举例
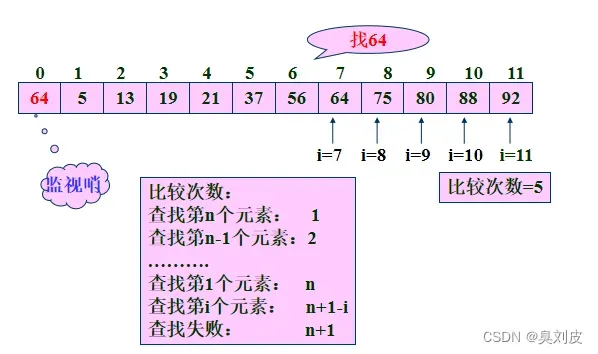
如上图所示,我们的目标是查找关键字为64的这个数据元素,因此对应的给定值就是64,我们从查找表的表尾开始查找,依次对比关键字,当比对到第7个元素的时候发现64等于第七个元素的关键字64,因此查找成功
算法性能分析
对于顺序表而言,Ci=n-i+1
在等概率查找的情况下,Pi=1/n
因此 ASL=n*P1+(n-1)*P2+……+2Pn-1+Pn=(n+1)/2
不等概率
如果被查找的记录概率不等时,取
Pn≥Pn-1≥···≥P2≥P1
若查找概率是无法事先测定的,则查找过程采取的改进方法是,将刚查找到的记录直接移到表尾的位置之上
算法特点
优点:
1.算法简单易实现
2.适应性强,对表结构无任何要求
缺点:
1.ASL(平均查找长度较大)
2.当n很大时,即为大规模数据时,查找的效率很低
算法实现
本算法的实现是基于顺序表的,因此需要先构造一个顺序表,顺序表的实现可以参考我的往期文章
顺序表的实现 当然了也可以用数组来替代,但是关键的不管是用什么结构,首元素不能存放数据,因为首元素的作用是作为哨兵存在的,因此关键数据存储于第二个位置及以后
int sqsearch(sqlist sl,int key)
{
int searchtime=0;//定义查找次数
int i=sl.length-1;//得到顺序表的长度
sl.element[0]=key;//设置哨兵
while (sl.element[i]!=key)//检查元素
{
i--;
}
searchtime=sl.length-i;//得到查找次数
if (i==0)//如果查找到了哨兵说明没查找到对应元素
{
return 0;
}
return i;//返回查找到的元素下标
}2.折半查找
算法思路
折半查找是基于有序表的查找方法,因此本算法所处理的数据是经过排序的,算法基本原理如下:
确定待查记录的范围(在前半部分或是后半部分),然后继续确定范围直到找到该元素为止
1.n个对象从小到大存放在有序顺序表ST中,k为给定值
2.设low、high指向待查元素所在区间的下界、上界,即low=1, high=n
3.设mid指向待查区间的中点,即mid=(low+high)/2
4.让k与mid指向的记录比较
若k<ST[mid].key,则high=mid-1 [上半区间]
若k>ST[mid].key,则low=mid+1 [下半区间]
5.重复3,4操作,直至low>high时,查找失败
算法举例

算法分析
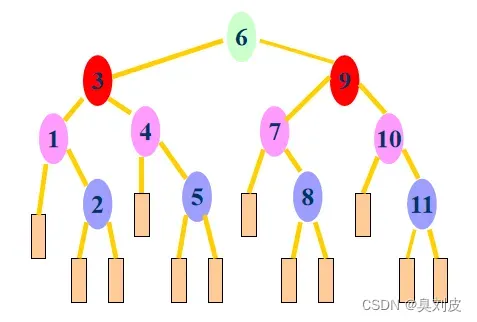
判定树
我们先不管要查找的Key是什么,我们将查找的整个过程中检查element[mid]的顺序列出来,我们就可以得到一颗描述查找过程的二叉树,我们称之为判定树,如下图所示:
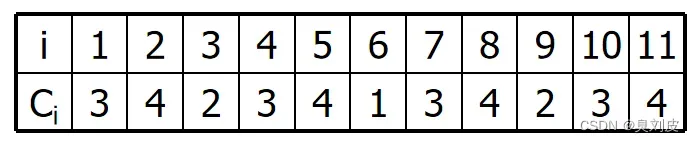
设我们有这么一个表,我们对其得到其的判定树:
性能分析(查找成功bs与查找失败bsf)
tips:以下的所有log都表示的是以2为底数的对数
我们可以知道,一个二叉树的每一层的节点最多有2^(i-1)个节点(i为层数),因此对于一个k层的二叉树,我们一共有:
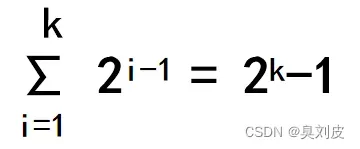
共2^k-1个节点,,因此有n个结点的判定树的深度为k=log(n+1),因此折半查找法在查找过程中进行的比较次数最多不超过log(n+1)。设有序表的长度n=2^h-1(即h=log (n+1)),则描述折半查找的判定树是深度为h的满二叉树,树中层次为1的结点有1个,层次为2的结点有2个,层次为h的结点有2^(h-1)个,假设表中每个记录的查找概率相等,则查找成功时折半查找的平均查找长度:
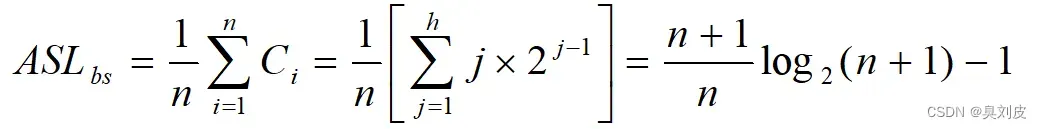
我们来对折半算法的ASL进行解析:首先我们对ASL的概念进行回顾
因为查找概率相等,因此Pi=1/n,我们将其从式子中提出来就得到了:
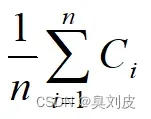
我们再对Ci的概念进行回顾:
![]()
我们可以知道,我们现在对元素的检查已经不再是像顺序查找一样一个一个进行检查了,而是像一颗树一样进行检查,且根据我们所选择的Key不同,每次从树的顶端开始走的路径都不同,且一次走一层,因此我们就可以把查找第i个元素时同给定值Key比较的次数转换为查找第j层元素时同给定值Key比较的次数,我们可以知道一个深度为h的树每层有2^(j-1)个节点,每个节点的上面都有j层,因此Ci就等于 j x 2^(j-1),我们代入ASL计算公式后就可以得到:
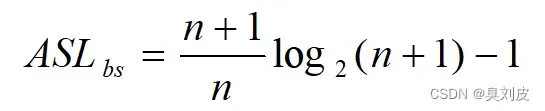
当我们查找失败的时候,也就是说我们查找到了判定树的最后一层的下一层,对此要具体例子具体计算,我在下面贴出一篇我觉得写的不错的文章,有兴趣的可以继续对ASL的计算进行了解:
ASL平均查找长度(查找失败与查找成功时的ASL计算)![]() https://blog.csdn.net/weixin_38233103/article/details/109248616?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166314104016782391812654%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=166314104016782391812654&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~hot_rank-4-109248616-null-null.142%5Ev47%5Econtrol_1,201%5Ev3%5Econtrol_2&utm_term=%E6%8A%98%E5%8D%8A%E6%9F%A5%E6%89%BE%E7%9A%84%E5%B9%B3%E5%9D%87%E6%9F%A5%E6%89%BE%E9%95%BF%E5%BA%A6&spm=1018.2226.3001.4187
https://blog.csdn.net/weixin_38233103/article/details/109248616?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522166314104016782391812654%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fall.%2522%257D&request_id=166314104016782391812654&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~first_rank_ecpm_v1~hot_rank-4-109248616-null-null.142%5Ev47%5Econtrol_1,201%5Ev3%5Econtrol_2&utm_term=%E6%8A%98%E5%8D%8A%E6%9F%A5%E6%89%BE%E7%9A%84%E5%B9%B3%E5%9D%87%E6%9F%A5%E6%89%BE%E9%95%BF%E5%BA%A6&spm=1018.2226.3001.4187
算法实现
int binarysearch(sqlist sl,int key)
{
int left,mid,right ;
left=0;//初始化三个标志位
right=sl.length-1;
mid=(left+right)/2;
while (sl.element[mid]!=key)//当未查找到时就一直进行查找
{
if(left<=right)//当left<=right意味着还能继续查找
{
if (key>sl.element[mid])
{
left=mid+1;
mid=(left+right)/2;
}
else
{
right=mid-1;
mid=(left+right)/2;
}
}
else//当left>right说明已经越界了,也代表着查找失败
{
cout<<"查找失败!"<<endl;
break;
}
}
if (sl.element[mid]==key)//最后对结果进行检查并返回对应值
{
cout<<"查找成功!"<<endl;
return mid;
}
else
{
return -1;//查找失败就返回-1
}
}3.分块查找
算法介绍
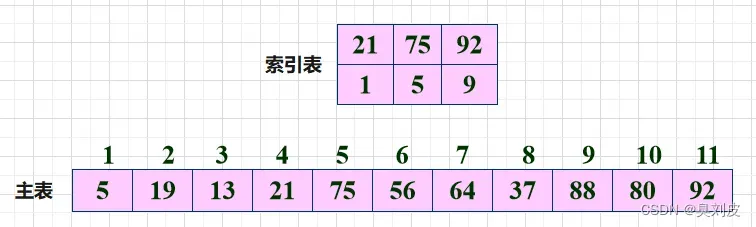
分块查找是一种索引顺序表(分块有序表)查找方法,索引顺序表(分块有序表)将整个表分成几块,块内无序,块间有序,所谓块间有序是指后一块表中所有记录的关键字均大于前一块表中的最大关键字
分块查找包含两个表:分别是主表和索引表
主表:用数组存放待查记录,每个数据元素包含关键字
索引表:用链表存放每个结点,每个节点含有本块的最大关键字和本块第一个结点下标
算法思想
1.我们将所有元素放入数组中,我们称之为主表
2.我们由数组的长度length来自己规定块长n,得到索引表的长度为length/n
3.我们对每个块进行遍历找出最大关键字,并将该块的首元素下标与最大关键字存入索引表中
4.以此类推直到所有块被操作完毕
5.我们对索引表按照最大关键字的大小进行排序
6.然后我们利用顺序查找对索引表进行操作
7.找到不小于key值得块我们对该块进行顺序查找我们的key
8.找不到我们就对下一个块进行顺序查找来找我们的key
9.以此类推直到查找到key或查找失败
算法举例
我们将一组数据存入主表,我们根据数据的数量11,我们设定分块长度为4,由此我们可以得到索引表的长度为11/4=3,然后我们对主表进行分块,得到三块,将每块的首元素索引以及最大关键字存储入索引表中并对索引表依据最大关键字进行排序就得到了下图:
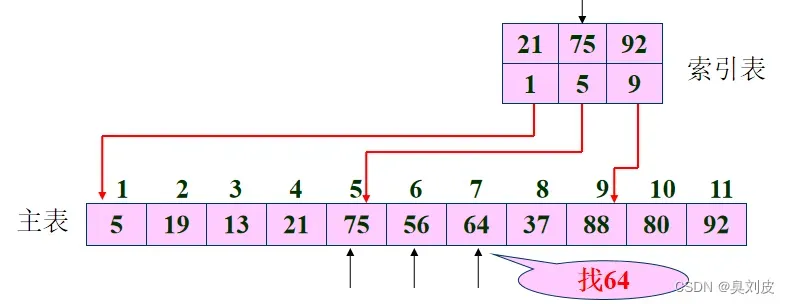
采用折半查找方法在索引表中找到块[第2块],用顺序查找方法在主表对应块中找到和key值对应的元素,即第三元素,我们返回这个元素的下标作为查找结果
算法实现
链表类及链表相关操作
class node
{
public:
int maxkey;
int firstindex;
node *next;
};
//创建链表,因为创建一个链表一定要有一个头节点,这个头节点是没有数据的
node* createlist()
{
node* head=(node*)calloc(1,sizeof(node));//使用calloc为指针分配内存
if(head==NULL)//并且要注意,在c++中,calloc和malloc返回的是void,因此要通过q‘强制转换才能继续使用
{
return NULL;
}
return head;
}
//创建节点
node* createnode(int maxkey,int firstindex)
{
node* newnode=(node*)calloc(1,sizeof(node));
if(newnode==NULL)
{
return NULL;
}
newnode->maxkey=maxkey;
newnode->firstindex=firstindex;
return newnode;
}
//添加元素:把数据从尾部插入
void pushback(node *head,int maxkey,int firstindex)
{
node* newnode=createnode(maxkey,firstindex);
node* curnode=head;
while(curnode->next!=NULL)
{
curnode=curnode->next;
}
//插入数据
curnode->next=newnode;
}
void print(node*head)
{
node* curnode=head->next;
while (true)
{
if(curnode->next!=NULL)
{
cout<<"当前节点maxkey:"<<curnode->maxkey<<" 当前节点firstindex:"<<curnode->firstindex<<endl;
curnode=curnode->next;
}
else
{
cout<<"当前节点maxkey:"<<curnode->maxkey<<" 当前节点firstindex:"<<curnode->firstindex<<endl;
break;
}
}
}
node* find(node* list,int num)
{
node* ptr=list;
for (int i = 0; i < num; i++)
{
ptr=ptr->next;
}
return ptr;
}分块查找
int blocksearch(int arr[],int arrlength,int key)
{
//创建索引表
node* list=createlist();
//得到索引表
cout<<"数组的长度为:"<<arrlength<<" 请输入块长:"<<endl;
float blocklength;
cin>>blocklength;
float blocknumber1=arrlength/blocklength;
int blocknumber2=arrlength/blocklength;
int blocknumber;
blocknumber=blocknumber1>blocknumber2?blocknumber2+1:blocknumber2;
int sllength=arrlength;
int start=0;
int length;
for (int i = 1; i <=blocknumber; i++)
{
int max=0;
sllength-=blocklength;
//cout<<"当前sllength:"<<sllength<<endl;
if (arrlength>blocklength)
{
length=blocklength;
}
else
{
length=sllength;
}
//cout<<"当前start:"<<start<<endl;
//cout<<"当前length:"<<length<<endl;
for (int j = start; j < start+length; j++)
{
if (arr[j]>max)
{
max=arr[j];
}
}
//cout<<"索引表加入start:"<<start<<" max:"<<max<<endl;
pushback(list,max,start);
start+=blocklength;
}
//打印索引表
cout<<"===============索引表================"<<endl;
print(list);
cout<<"===================================="<<endl;
cout<<endl;
//建新表对索引表进行排序
node* newlist=createlist();
node *curnode=list->next;
cout<<"一共有"<<blocknumber<<"个块"<<endl;
for (int j = 0; j < blocknumber; j++)
{
int min=999;
int mini=0;
int i=0;
int temp;
while (curnode->next!=NULL)
{
i++;
//cout<<"curnode的maxkey为:"<<curnode->maxkey<<endl;
if (curnode->maxkey<min)
{
min=curnode->maxkey;
mini=curnode->firstindex;
temp=i;
}
//cout<<"curnode"<<curnode->maxkey<<"变为"<<curnode->next->maxkey<<endl;
curnode=curnode->next;
}
//最后一个节点还要再操作一遍
i++;
//cout<<"curnode的maxkey为:"<<curnode->maxkey<<endl;
if (curnode->maxkey<min)
{
min=curnode->maxkey;
mini=curnode->firstindex;
temp=i;
}
node* ptr=list;
for (int k = 0; k < temp; k++)
{
ptr=ptr->next;
}
cout<<"找到的最小node的maxkey为:"<<ptr->maxkey<<endl;
ptr->maxkey=1000;
curnode=list->next;
pushback(newlist,min,mini);
//cout<<"索引表加入min:"<<min<<" mini:"<<mini<<endl;
//cout<<"当前索引表最小maxkey为:"<<min<<endl;
}
//打印新索引表
cout<<"===============新索引表================"<<endl;
print(newlist);
cout<<"===================================="<<endl;
cout<<endl;
//对新索引表进行顺序查找
int startindex=1;
while (startindex<=blocknumber)
{
int target= find(newlist,startindex)->firstindex;
for (int i = target; i < target+blocklength; i++)
{
if (key==arr[i])
{
return i;//查找到并返回下标
}
}
startindex++;
}
return -1;//未查找到
}main函数
int main()
{
cout<<"请输入数组长度:"<<endl;
int arrlength;
cin>>arrlength;
int arr[arrlength];
for (int i = 0; i < arrlength; i++)
{
cout<<"请输入arr["<<i<<"]:";
cin>>arr[i];
}
cout<<"请输入key值:"<<endl;
int key;
cin>>key;
blocksearch(arr,arrlength,key);
return 0;
}代码执行结果
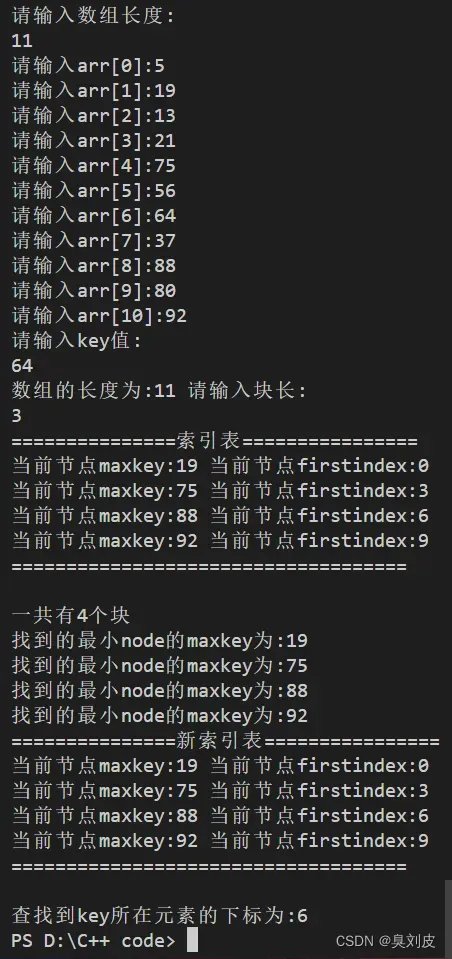
三、总结
本文对查找进行了介绍,并且有对ASL平均查找长度进行讲解和举例计算,重点为三种算法的介绍和实现,其中顺序查找作为最基本的查找算法是一定要掌握的,折半查找作为效率最高的算法尤其应该予以重视,分块查找是介于顺序查找和折半查找效率的一个算法,实现起来较麻烦,但是也需要掌握,如果喜欢本文的话希望可以点一个赞,你的肯定是我进步的动力!!!
👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍👍
文章出处登录后可见!