回溯法有两个模板–子集树、排列树,他们有回溯法的共同特点:深度优先搜索,如果一条路走不通,再退回来(类似递归)
问题描述

八皇后问题的历史
八皇后问题最早是由国际象棋棋手马克斯·贝瑟尔(Max Bezzel)于1848年提出。第一个解在1850年由弗朗兹·诺克(Franz Nauck)给出。并且将其推广为更一般的n皇后摆放问题。诺克也是首先将问题推广到更一般的n皇后摆放问题的人之一。
在此之后,陆续有数学家对其进行研究,1874年,S.冈德尔提出了一个通过行列式来求解的方法,这个方法后来又被J.W.L.格莱舍加以改进。1972年,艾兹格·迪杰斯特拉用这个问题为例来说明他所谓结构化编程的能力。他对深度优先搜索回溯算法有着非常详尽的描述。
八皇后问题的解的个数
八个皇后在8×8棋盘上共有4,426,165,368(64C8)种摆放方法,但只有92个可行(皇后间互不攻击)的解。如果将旋转和对称的解归为一种的话,则一共有12个独立解,具体如下:

n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | .. |
U独立解 | 1 | 0 | 0 | 1 | 2 | 1 | 6 | 12 | 46 | 92 | 341 | 1,787 | 9,233 | 45,752 | .. |
D可行解 | 1 | 0 | 0 | 2 | 10 | 4 | 40 | 92 | 352 | 724 | 2,680 | 14,200 | 73,712 | 365,596 | .. |
八皇后问题解法
- 暴力解法
蛮力算法的基本思想是将女王放置在所有可能的位置,并每次检查女王是否无法相互捕获。如果没有,那么它已经找到了解决方案。由于存在大量可能的位置(N * N 表示大小为N 的表,而每行有 1 个女王),因此即使对于较小的表大小(如 N=12),此算法也不实用。
其实也可以改进:
每行只放置一个女王,每列放置一个女王后,可能的有效位置数量减少到 N!(N!=1*2*3….*(N-1)*N)。使用这种算法,与以前的方法(如 N=17)相比,我们可以找到一个更大的表大小的解决方案。
我不会在这里介绍一个实际的蛮力算法,因为它不实用(由于需要大量的资源计算,速度非常低)。
- 回溯解法
递归回溯
递归回溯法代码框架:
void backtrack (int t)
{
if (t>n)
{
output(x); //叶子节点,输出结果,x是可行解
}
else
{
for i = 1 to k//当前节点的所有子节点
{
x[t]=value(i); //每个子节点的值赋值给x
//满足约束条件和限界条件
if (constraint(t)&&bound(t))
backtrack(t+1); //递归下一层
}
}
}
我们可以明确,一行一个皇后,就是每一行皇后放置的列数不确定。于是,用一位数组就可以解决
x[i]表示第i行的皇后i放置在棋盘的第i行第j列。
皇后放置的条件是:不能同一列(x[i]==x[k]),不能同一斜线(abs(i-k)==abs(x[i]-x[k])斜率为+-1;
解决n皇后问题的时候,可以用n叉树表示解空间,用可行性约束函数剪枝,减去不满足条件的子树
用backtrack(int t)实现对整个解空间的搜索,backtrack(t)搜索第t行的解空间。
当t>n时,已经搜索到叶子,得到了一个新的满足条件,不会相互攻击的皇后放置方案,用sum计数,sum++
当t<=n时,还是解空间的内部节点,对当前扩展节点,还有子树需要搜索,搜索这一行的所有列,用一个循环来实现x[t]=i(其中,i=1,2,3,…,n),我们用可行性约束判断这个节点的可行性,如果可行,进入下一行(下一层的深度优先搜索),如果不可行,直接返回,剪去子树。
具体代码如下:(和模板很像吧)
//n皇后问题,递归回溯
#include<iostream>
using namespace std;
#define MAXN 30
int n=MAXN; //棋盘大小
int sum=0;
int x[MAXN];
//打印棋盘具体信息
void display(){
for(int i=1;i<=n;i++){
for(int j=1;j<=n;j++){
if(x[i]==j) cout << "#" << " ";//表示第i行第j列可以放置皇后
else cout << "." << " ";
}
cout << endl;
}
}
bool Place(int k){
for(int i=1;i<k;i++){
if(x[i]==x[k] || abs(i-k)==abs(x[i]-x[k])) return false;
}
return true;
}
void backtrack(int t){
//搜索到叶子,应该返回了
if(t>n){
sum++;
cout << "------------" << sum << endl;
display();
return;
}
//还没有搜索到叶子
else if(t<=n){
for(int i=1;i<=n;i++){
x[t]=i;
//可行性约束检查
if(Place(t)) backtrack(t+1);
}
}
}
int main(){
cout << "please input n*n:" << endl;
cin >> n;
backtrack(1);
return 0;
}如果觉得50行代码太长了,还有精简版
#include <stdio.h>
#define QUEENS 8 /*皇后数量*/
#define IS_OUTPUT 1 /*(IS_OUTPUT=0 or 1),Output用于选择是否输出具体解,为1输出,为0不输出*/
int A[QUEENS + 1], B[QUEENS * 3 + 1], C[QUEENS * 3 + 1], k[QUEENS + 1][QUEENS + 1];
int inc, *a = A, *b = B + QUEENS, *c = C;
void lay(int i) {
int j = 0, t, u;
while (++j <= QUEENS)
if (a[j] + b[j - i] + c[j + i] == 0) {
k[i][j] = a[j] = b[j - i] = c[j + i] = 1;
if (i < QUEENS) lay(i + 1);
else {
++inc;//计数
if (IS_OUTPUT) {
for (printf("(%d)\n", inc), u = QUEENS + 1; --u; printf("\n"))
for (t = QUEENS + 1; --t; ) k[t][u] ? printf("Q ") : printf("+ ");
printf("\n\n\n");
}
}
a[j] = b[j - i] = c[j + i] = k[i][j] = 0;
}
}
int main(void) {
lay(1);
printf("%d皇后共计%d个解\n", QUEENS, inc);
return 0;
}书上的代码是这样的

比迭代回溯简单多了的感觉。
迭代回溯

针对N叉树的迭代回溯法代码框架:
//针对N叉树的迭代回溯方法
void iterativeBacktrack ()
{
int t=1;
while (t>0)
{
if(ExistSubNode(t)) //当前节点的存在子节点
{
for i = 1 to k //遍历当前节点的所有子节点
{
x[t]=value(i);//每个子节点的值赋值给x
if (constraint(t)&&bound(t))//满足约束条件和限界条件
{
//solution表示在节点t处得到了一个解
if (solution(t))
output(x);//得到问题的一个可行解,输出
else
t++;//没有得到解,继续向下搜索
}
}
}
else //不存在子节点,返回上一层
t--;
}
} 递归效率有时候并不是那么的高,我们可以考虑迭代回溯法。
具体思路:首先对N行中的每一行进行探测,查找该行中可以放皇后的位置。具体怎么做呢?
首先,对这一行的逐列进行探测,看是否可以放置皇后,如果可以,则在该列放置一个皇后,然后继续探测下一行的皇后位置。
如果已经探测完所有的列都没有找到可以放置皇后的列,这时候就应该回溯了,把上一行皇后的位置往后移一列,就相当于x[i]++。 如果上一行皇后移动后也找不到位置,则继续回溯直至某一行找到皇后的位置或回溯到第一行,如果第一行皇后也无法找到可以放置皇后的位置,则说明已经找到所有的解,程序终止。
如果该行已经是最后一行,则探测完该行后,如果找到放置皇后的位置,则说明找到一个结果,打印出来。但是此时并不能在此处结束程序,因为我们要找的是所有N皇后问题所有的解,此时应该清除该行的皇后,从当前放置皇后列数的下一列继续探测。
由此可见,非递归方法的一个重要问题时何时回溯及如何回溯的问题。
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#define QUEEN 8 //皇后的数目
#define INITIAL -10000 //棋盘的初始值
int a[QUEEN]; //一维数组表示棋盘
//对棋盘进行初始化
void init() {
int *p;
for (p = a; p < a + QUEEN; ++p) *p = INITIAL;
}
//判断第row行第col列是否可以放置皇后
int valid(int row, int col){
int i;
//对棋盘进行扫描
for (i = 0; i < QUEEN; ++i){ //判断列冲突与斜线上的冲突
if (a[i] == col || abs(i - row) == abs(a[i] - col))
return 0;
}
return 1;
}
//打印输出N皇后的一组解
void print(){
int i, j;
for (i = 0; i < QUEEN; ++i){
for (j = 0; j < QUEEN; ++j){
if (a[i] != j) //a[i]为初始值
printf("%c ", '.');
else //a[i]表示在第i行的第a[i]列可以放置皇后
printf("%c ", '#');
}
printf("\n");
}
for (i = 0; i < QUEEN; ++i)
printf("%d ", a[i]);
printf("\n");
printf("--------------------------------\n");
}
void queen() //N皇后程序
{
int n = 0;
int i = 0, j = 0;
while (i < QUEEN)
{
while (j < QUEEN) //对i行的每一列进行探测,看是否可以放置皇后
{
if(valid(i, j)) //该位置可以放置皇后
{
a[i] = j; //第i行放置皇后
j = 0; //第i行放置皇后以后,需要继续探测下一行的皇后位置,
//所以此处将j清零,从下一行的第0列开始逐列探测
break;
}
else
{
++j; //继续探测下一列
}
}
if(a[i] == INITIAL) //第i行没有找到可以放置皇后的位置
{
if (i == 0) //回溯到第一行,仍然无法找到可以放置皇后的位置,
//则说明已经找到所有的解,程序终止
break;
else //没有找到可以放置皇后的列,此时就应该回溯
{
--i;
j = a[i] + 1; //把上一行皇后的位置往后移一列
a[i] = INITIAL; //把上一行皇后的位置清除,重新探测
continue;
}
}
if (i == QUEEN - 1) //最后一行找到了一个皇后位置,
//说明找到一个结果,打印出来
{
printf("answer %d : \n", ++n);
print();
//不能在此处结束程序,因为我们要找的是N皇后问题的所有解,
//此时应该清除该行的皇后,从当前放置皇后列数的下一列继续探测。
j = a[i] + 1; //从最后一行放置皇后列数的下一列继续探测
a[i] = INITIAL; //清除最后一行的皇后位置
continue;
}
++i; //继续探测下一行的皇后位置
}
}
int main(void)
{
init();
queen();
system("pause");
return 0;
}书上的迭代回溯代码是这样滴

分析结束。
我在这个网站上面,还看到了点好东西,做个笔记
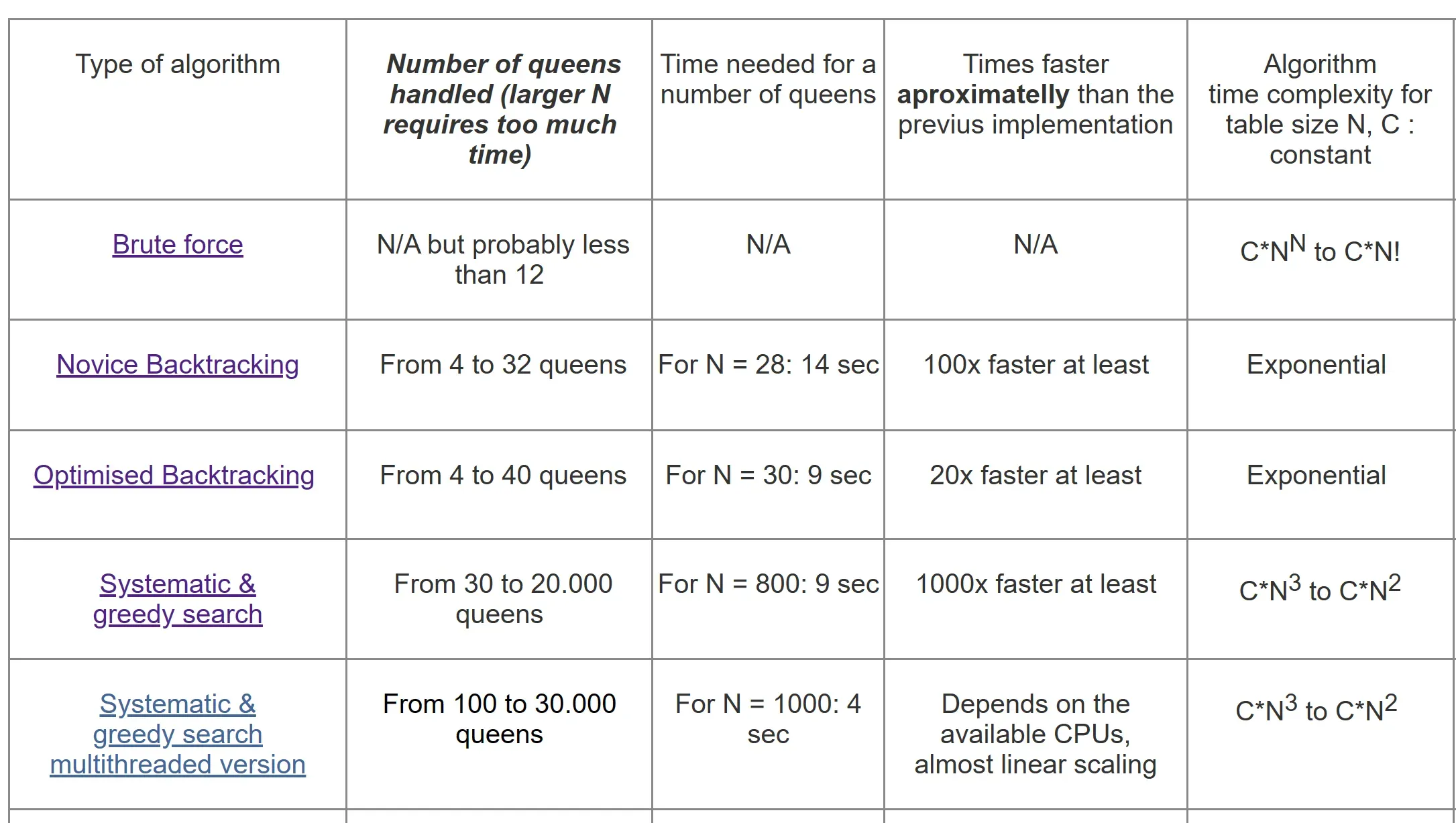
3)系统搜索和贪婪算法
基本思路:
这种搜索算法的基本思想是通过在每次场合/处理行中将皇后放置在最佳位置来找到解决方案(因此贪婪命名)。
这意味着它也可能将女王放置在无效的位置。皇后需要在移动之前进行初始化,并确保每行只有一个。调整起始位置可以随机完成,也可以按照某种模式(例如将所有皇后放在同一行/列中)来完成。
算法步骤:
在以下几行中,我将详细解释此搜索算法。更具体地说,此算法从第一行(上行)到最后一行(下行)选择要处理的皇后。除非另有说明,否则算法的步骤按执行顺序列出。
初始化皇后起始位置。在我的版本中,所有皇后都放在同一行/列中,如果算法找不到解决方案,皇后将被移动到下一行/列。女王也可以随机放置,但最多只能有一个女王占据一条线。如果没有剩余的行/列,请停止。找不到解决方案。
保存女王初始放置的攻击位置(这可能会在放置期间完成)。
对于每个女王(从第一行(上行)到最后一行(下行)),执行步骤 4 到 6:
在受到最少数量蜂王攻击的线路中找到适当的位置(如果有几个这样的位置,请选择其中一个)。
将女王移到那个位置。
保存被攻击的位置。
检查是否有剩余的攻击。如果没有,算法已经找到了解决方案。
将计数器增加 1。如果计数器大于预先定义的值(我使用 15 到 12 来最大化速度并确保我们没有错过解决方案),请转到步骤 1。
转到步骤 3。
所呈现的算法不能立即在结构化程序中转换。但唯一需要这样做的是添加一个无限循环,其中包含所有步骤,并且可以在步骤 1 中停止。
详:
要计算一个点的攻击次数,只需将来自同一列和对角线中的女王的攻击相加即可。
正如您可能在我的算法版本的步骤 1 中注意到的那样,如果所有 N 个皇后都重新初始化 N 次,那么就没有更多的可用起始行/列了。我在测试中发现,这种情况(对于 > 20 的表格大小)仅适用于 700×700 (N = 700)。这真的很奇怪,我没有很好的解释。你可以在这里找到(在标题“详细信息”下)我用来保存受攻击位置的方式(它与回溯算法相同,只是位字段不能用于大表大小)。因此,对于系统搜索,唯一可以成功应用的方法就是第二种方法,因为第一种方法会随着 N(表大小)的增加而遭受指数时间增加(因为此算法旨在处理的大表大小)。您可以在此处下载此算法的版本,该版本可在下载部分找到。
此外,该算法的时间复杂度为 C*N3,而 C 是一个常数。另外值得一提的是,该算法的执行时间是相当不可预测的,因此给定的时间复杂度是指最坏的情况。对于 N = 2800 的考试,我的程序需要 31 秒,但对于 N = 2000,它需要 196 秒。发生这种情况是因为有时在少量尝试中找到解决方案,有时在非常多的尝试中找到解决方案,具体取决于 N。
与其他方法相比的优势:
这种系统搜索和贪婪算法在N(表大小变大)时寻找解决方案方面比任何回溯算法具有很大的速度优势。但它失去了找到所有可能的解决方案的能力。由于目前对于大 N(表格大小)的可用标签计算机无法做到这一点,因此这并不重要。此外,人们可以很容易地生成该算法的并行版本,从而只需启动具有不同 queens 初始位置的多个线程即可将速度提高数倍。
其他想法:
这种搜索算法比回溯算法效率高得多,因此可以找到 N > 1.000 的解决方案。此外,该算法可以在GPU或多核CPU上轻松实现(每个线程将获得不同的初始女王位置)。您可以在此处查看多线程版本。但是,对于大于 50.000 – 80.000 的数字,它无法在逻辑时间(几天)内找到任何解决方案,因为随着 N(表大小)的增长,所需时间会迅速增加。它可以进一步优化,但到目前为止,我的大多数 effords 都失败了。这就是为什么对于较大的表大小,需要另一种方法。
文章出处登录后可见!