“UGC不存在了”——借鉴自《三体》
ChatGPT 的横空出世将一个全新的概念推上风口——AIGC( AI Generated Content)。
GC即创作内容(Generated Content),和传统的UGC、PGC,OGC不同的是,AIGC的创作主体由人变成了人工智能。
xGC
PGC:Professionally Generated Content,专业生产内容
UGC:User Generated Content,用户生产内容
OGC:Occupationally Generated Content,品牌生产内容。
AI 可以 Generate 哪些 Content?
作为淘宝内容线的开发,我们每天都在和内容打交道,那么AI到底能生成什么内容?
围绕着不同形式的内容生产,AIGC大致分为以下几个领域:
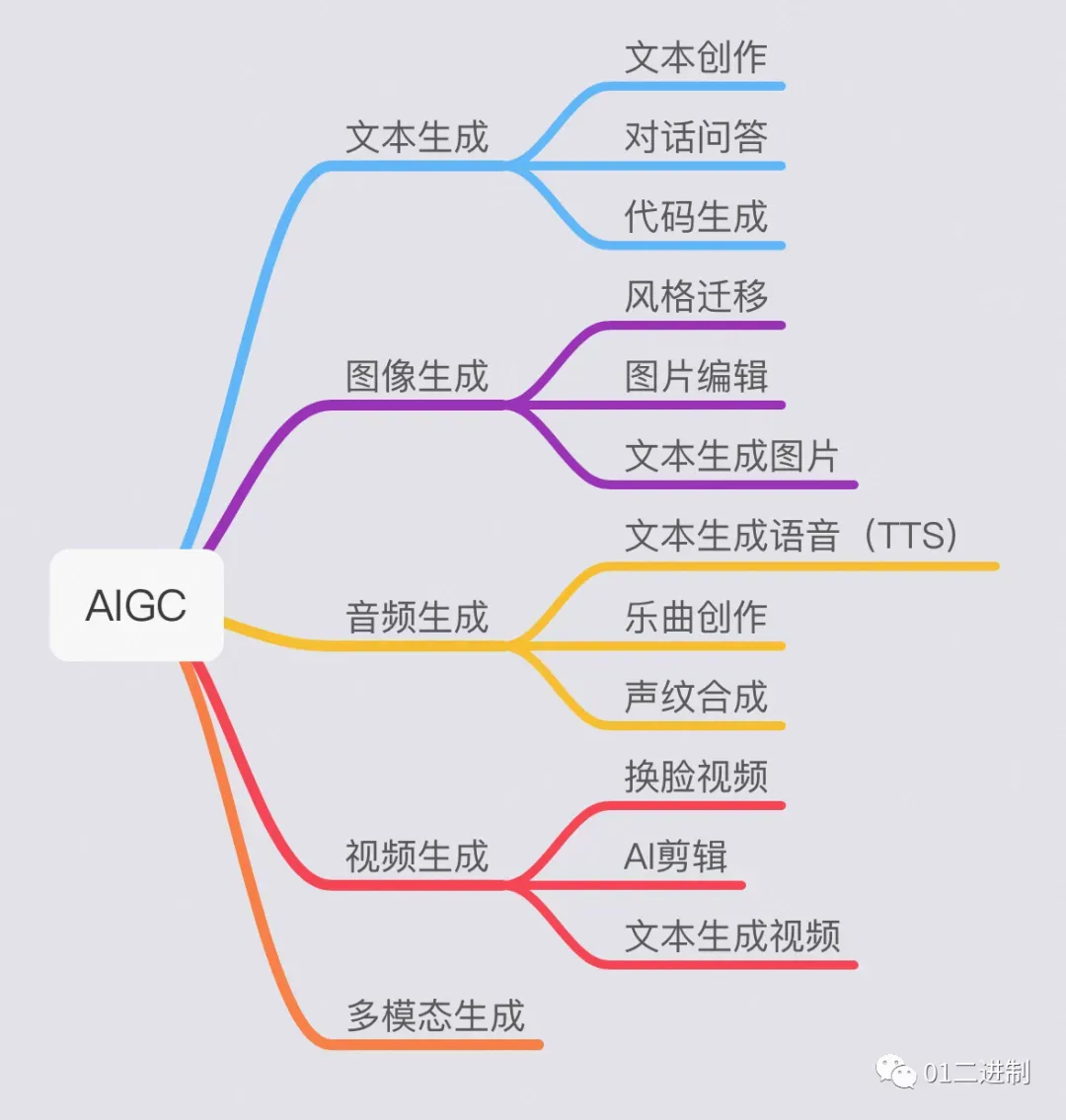
文本生成
基于NLP的文本内容生成根据使用场景可分为非交互式文本生成与交互式文本生成。
非交互式文本生成包括摘要/标题生成、文本风格迁移、文章生成、图像生成文本等。
交互式文本生成主要包括聊天机器人、文本交互游戏等。
【代表性产品或模型】:JasperAI、copy.AI、ChatGPT、Bard、AI dungeon等。

图像生成
图像生成根据使用场可分为图像编辑修改与图像自主生成。
图像编辑修改可应用于图像超分、图像修复、人脸替换、图像去水印、图像背景去除等。
图像自主生成包括端到端的生成,如真实图像生成卡通图像、参照图像生成绘画图像、真实图像生成素描图像、文本生成图像等。
【代表性产品或模型】:EditGAN,Deepfake,DALL-E、MidJourney、Stable Diffusion,文心一格等。

音频生成
音频生成技术较为成熟,在C端产品中也较为常见,如语音克隆,将人声1替换为人声2。还可应用于文本生成特定场景语音,如数字人播报、语音客服等。此外,可基于文本描述、图片内容理解生成场景化音频、乐曲等。
【代表性产品或模型】:DeepMusic、WaveNet、Deep Voice、MusicAutoBot等。

视频生成
视频生成与图像生成在原理上相似,主要分为视频编辑与视频自主生成。
视频编辑可应用于视频超分(视频画质增强)、视频修复(老电影上色、画质修复)、视频画面剪辑(识别画面内容,自动场景剪辑)。
视频自主生成可应用于图像生成视频(给定参照图像,生成一段运动视频)、文本生成视频(给定一段描述性文字,生成内容相符视频)。
【代表性产品或模型】:Deepfake,videoGPT,Gliacloud、Make-A-Video、Imagen video等。
多模态生成
以上四种模态可以进行组合搭配,进行模态间转换生成。如文本生成图像(AI绘画、根据prompt提示语生成特定风格图像)、文本生成音频(AI作曲、根据prompt提示语生成特定场景音频)、文本生成视频(AI视频制作、根据一段描述性文本生成语义内容相符视频片段)、图像生成文本(根据图像生成标题、根据图像生成故事)、图像生成视频。
【代表性产品或模型】:DALL-E、MidJourney、Stable Diffusion等。
本文接下来将会着重讲述文本类AIGC和图像类AIGC。
文本类AIGC
RNN → Transformer → GPT(ChatGPT)
最近势头正猛的ChatGPT就是文本类AIGC的代表。
ChatGPT(Chat Generative Pre-trained Transformer),即聊天生成型预训练变换模型,Transformer指的是一种非常重要的算法模型,稍后将会介绍。
其实现在的用户对于聊天机器人已经很熟悉了,比如天猫精灵、小爱同学或是Siri等语音助手。那为什么ChatGPT一出现,这些语音助手就显得相形见绌呢?
本质上是NLP模型之间的差异。
在自然语义理解领域(NLP)中,RNN和Transformer是最常见的两类模型。
循环神经网络(recurrent neural network)
RNN,即循环神经网络(recurrent neural network)源自于1982年由Saratha Sathasivam 提出的霍普菲尔德网络。下图所示是一个RNN网络的简易展示图,左侧是一个简单的循环神经网络,它由输入层、隐藏层和输出层组成。
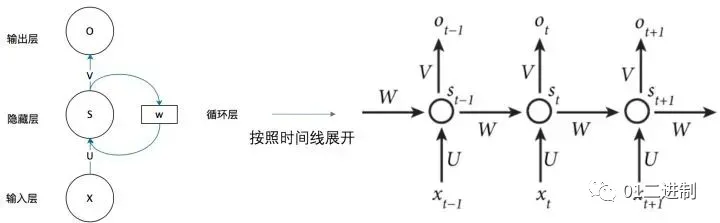
RNN 的主要特点在于 w 带蓝色箭头的部分。输入层为 x,隐藏层为 s,输出层为 o。U 是输入层到隐藏层的权重,V 是隐藏层到输出层的权重。隐藏层的值 s 不仅取决于当前时刻的输入 x,还取决于上一时刻的输入。权重矩阵 w 就是隐藏层上一次的值作为这一次的输入的权重。由此可见,这种网络的特点是,每一个时刻的输入依赖于上一个时刻的输出,难以并行化计算。
从人类视角理解RNN 人类可以根据语境或者上下文,推断语义信息。就比如,一个人说了:我喜欢旅游,其中最喜欢的地方是三亚,以后有机会一定要去___,很显然这里应该填”三亚”。 但是机器要做到这一步就比较困难。RNN的本质是像人一样拥有记忆的能力,因此,它的输出就依赖于当前的输入和记忆。
Transformer
而Transformer模型诞生于2017年,起源自《Attention Is All You Need》。这是一种基于Attention机制来加速深度学习算法的模型,可以进行并行化计算,而且每个单词在处理过程中注意到了其他单词的影响,效果非常好。
!](https://cdn.ytools.xyz/uPic/202303211936538.png)
Attention机制:又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术。通俗的讲就是把注意力集中放在重要的点上,而忽略其他不重要的因素。 其中重要程度的判断取决于应用场景,根据应用场景的不同,Attention分为空间注意力和时间注意力,前者用于图像处理,后者用于自然语言处理。
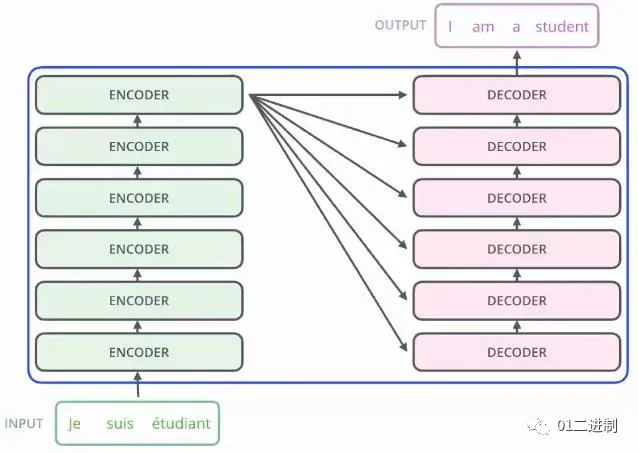
Transformer是完全基于自注意力机制的一个深度学习模型,有关该模型的介绍,详情可参考下面这篇文章👇
人工智能 LLM 革命前夜:一文读懂横扫自然语言处理的 Transformer 模型
由于Transformer的存在加速了深度学习的效果,基于海量数据的进行样本训练便有了可能。至此,LLM正式从幕后走向台前。
LLM,Large Language Model 即大型语言模型。这个大不仅仅指数据集的“大”,同样也是指算法模型的“大”。一般来说,在训练数据足够充足的情况下,往往是模型越大效果越好。在某种程度上说,甚至只要样本足够,哪怕模型“稍微简单”一些,也是可以取得不错的结果的。
笔者在2019年时曾翻译过一篇文章👇
这篇文章的主要观点便是“AI竞争本质上就是数据之争”,所有希望创建有影响力、有价值的AI应用都应该认识到以下三点:
差异化数据是这场AI游戏成功的关键
有意义的数据比全面的数据好
起点应该是自己所擅长的东西
以ChatGPT为例,其本质是基于GPT3的一种变体,而GPT又是基于Transformer模型的一种演化。从模型参数上来说,GPT3共使用了1750亿个参数训练而成,而ChatGPT只使用了15亿个参数,但其数据集是却是整个互联网和几百万本书大概3千亿文字。哪怕是这样,却也是对一众使用RNN的NLP程序造成了降维打击。
GPT
这篇文章写到一半的时候GPT-4发布了,现在作为小插曲来扩展一下
笔者在和朋友的日常交流中发现大家总是将ChatGPT和GPT混为一谈,其实这是两个不同的东西。让我们来问一下New Bing这两者的区别。
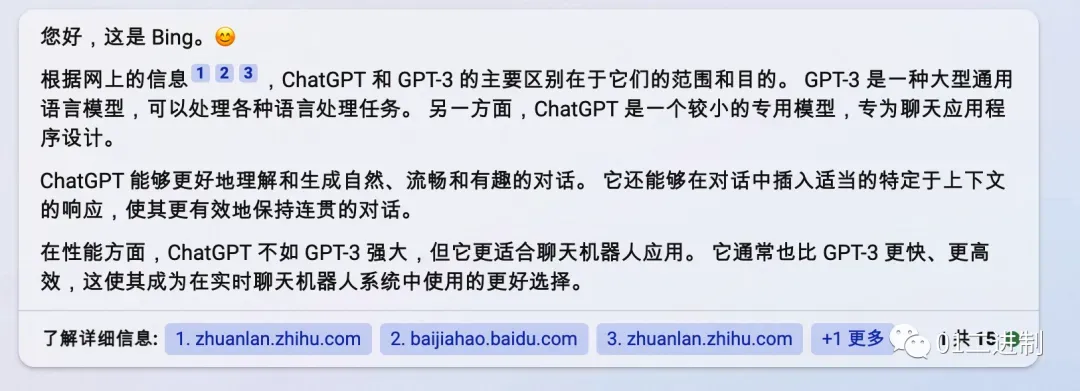
很显然,从Bing给我的回答看来,为了让对话更加生动和有趣,ChatGPT是一个专为聊天设计的专业模型,而GPT则是一个通用语言模型。GPT4就是这个模型发展到第四代的模样,相较于GPT3,GPT4可以做的事情变得更多了。
GPT-4 是一个更大的模型,网传拥有约 1000 万亿个参数,这意味着它能够处理更多的数据,学习更多的知识和技能。
GPT-4 能够接受多模态的输入,例如文本、图像、音频和视频,并生成相应的输出。这使得它能够处理更复杂和丰富的任务,例如图像描述、语音识别和视频生成。
类ChatGPT
在国内一直都有一句调侃的话,叫做“国外一开源,国内就自主研发”。那既然算法模型是公开的,代码也已经开源了,那在国内,那些类ChatGPT的模型是不是应该如“雨后春笋”般涌现了呢?
事实上并没有,本质上还是因为LLM的扩展和维护是相当困难的。主要来源于以下几点:
漫长的训练时间
高昂的费用开支
海量的训练数据
稀缺的高端人才
时代的眼泪
2017 – Attention is all you need
2023 – Money is all you need
以复旦大学开源的类ChatGPT应用MOSS为例,虽然不知道具体的模型参数数量,但其负责人表示相较于ChatGPT少了一个数量级,再加上简中互联网作为其训练样本,训练质量可想而知。
点此体验👉https://moss.fastnlp.top/

文章出处登录后可见!