chatGPT带来了几个月的AIGC热度,文本图像生成模型大行其道,但AI在视频生成任务上尚没有较好的开源仓库,并受限于“缺那么几百块A100″的资源问题,大多数人无法展开视频生成的研究。好在目前有不少针对视频生成的相关paper,也有不少开源实现,事实上缺的是一个完整的训练+推理+Pretrained模型,本文要解决的就是这个问题。
1. Stable Diffusion以及其中Unet结构,下图摘自论文: High-Resolution Image Synthesis with Latent Diffusion Models
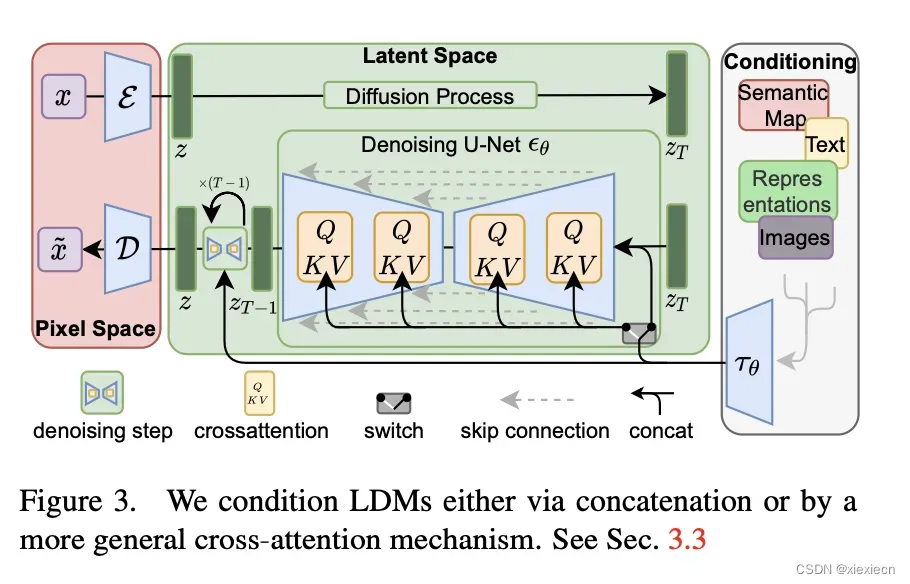
为了支持视频生成,需要对Unet结构中的部分模块进行改造,包括2d卷积以及Self-Attention和Cross-Attention。在许多的Stable Diffusion开源实现中,Tune A Video这篇论文的代码较为干净简洁,在利用Stable Diffusion V1-4权重作为pretrained,参考Make A Video利用3d伪引入空间信息,并且保留Tune A Video中关于Sparse Cross Attention的修改。
2. 3d伪卷积引入时空相关信息,图片摘自Make A Video
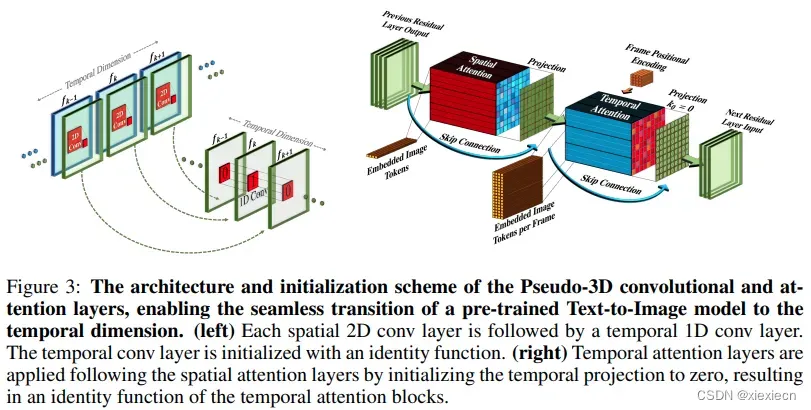
代码实现引用lucidrains的make-a-video-pytorch,并且加入关于时空的Position Embedding部分。
3. Sparse Casual Attention
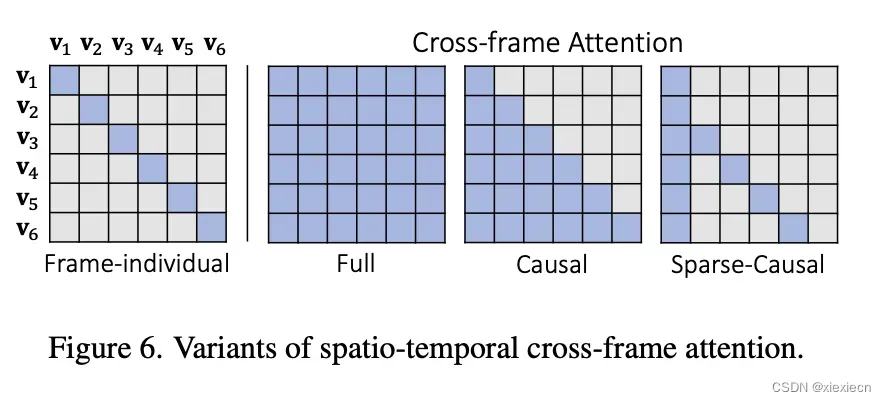
出于节省运算量的目的,当前帧跟第一帧和当前帧的前一帧做Cross Attention,这个只是运算上的调整,Cross Attention结构并无修改。
4. 3090如何训练
大多数论文,训练视频生成都是采用8张A100做微调,或者利用成百上千的GPU进行大规模训练。对于咱穷人来说,只有两块3090,训练方法分步骤进行:
a. 128×128
b. 256×256,batch size单卡为4,grad accumulation设置为100
5. 数据集
视频数据集webvid, hdvila100m
图片数据集laion400m
我简单实验下来,加上图片数据集混合训练文本生成效果会更好一些。
文章出处登录后可见!