引言
最近的文本到图像Stable Diffusion (SD)模型已经证明了使用文本提示合成新颖场景的前所未有的能力。这些文本到图像的模型提供了通过自然语言指导创作的自由。然而,它们的使用受到用户描述特定或独特场景、艺术创作或新物理产品的能力的限制。很多时候,用户被迫行使她的艺术自由来生成特定的独特或新概念的图像。此外,使用新数据集为每个新概念重新训练模型非常困难且昂贵。
论文《An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion》提供了一种简单的方法来允许这些创作自由。在这篇博文中,我们正在讨论一种将我们自己的猫变成一幅画的方法,或者想象一种基于我们最喜欢的玩具使用SD的新产品。我们可以通过冻结文本到图像模型的嵌入空间中的新“单词”,仅使用对象或样式的 3-5 个图像来学习这些用户提供的新概念。

textual inversion工作机理
在我们之前关于SD的博客中,我们看到文本编码器模型将任何输入提示转换为嵌入,这些嵌入被馈送到扩散模型作为指导或调节。我们还可以在图 1 中看到,此过程涉及将输入提示tokenize为一组tokens,这些tokens是某些预定义字典中的索引,然后将这些tokens通过文本编码器传递以获取嵌入。每个token都链接到一个唯一的嵌入向量,可以通过基于索引的查找来检索该嵌入向量。
这些文本嵌入与潜在图像输入和 t 一起传递到下游 UNet 模型作为指导。我们还可以更改一个对象的token嵌入,并将其替换为另一个对象的token嵌入,以获得不同的图像。同样,我们可以学习特定对象或概念的新token嵌入。
在 textural inversion中,我们选择这个嵌入空间作为反演的目标。“ textural inversion”背后的想法是使用一些示例图像向文本模型教授一个新单词,并训练其嵌入接近某些视觉表示。这是通过向词汇表添加新token并使用一些代表性图像进行训练来实现的。因此,我们尝试找到代表我们新的特定概念的新嵌入向量。 textural inversion可用于将经过训练的标记添加到词汇表中,并将其与预训练的SD模型一起使用。
因此,我们指定一个占位符字符串,我们将其称为伪词,用 S* 表示,如图 1 所示,来表示我们希望学习的新概念。我们干预嵌入过程,并用新学习的嵌入 v* 替换与tokenized字符串相关的向量。因此,我们能够将新概念注入我们的词汇中。然后像任何其他单词一样对待这个伪单词,并且可以用来为生成模型组成新颖的文本查询或新句子。因此,人们可以要求“一张S在海滩上的照片”,“一幅S挂在墙上的油画”,甚至可以组成两个概念,例如“一幅S1的S2风格的画”。 ”。在此过程中我们没有对生成模型进行任何更改,因此基本生成模型可以用于我们的新概念。
论文作者将 textural inversion过程的示意图如下所示。
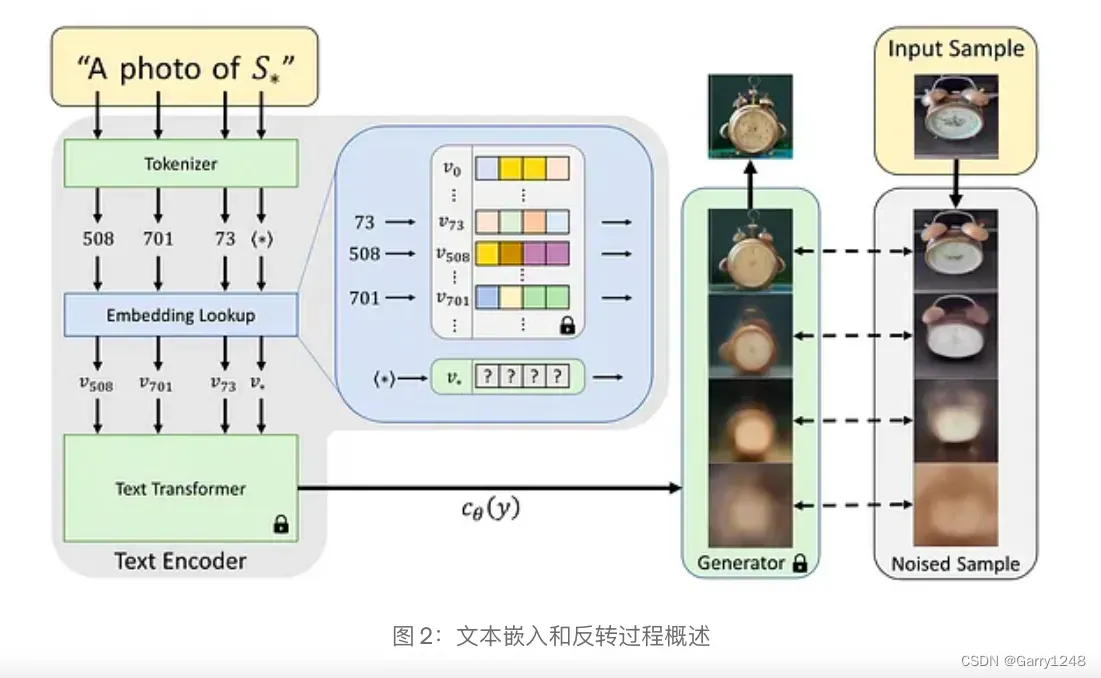
我们可以看到,我们可以从提示“A photo of S*”中获取图像,其中 S* 是一个新对象或新样式,就像我们从提示“A photo of cat”中获取图像一样。
文本嵌入
找到这些伪词的嵌入的任务被定义为反转任务之一。在这里,我们使用固定的预训练文本到图像模型和一小组描述该概念的图像。我们的目标是找到一个单词嵌入,这样“A photo of S*”形式的句子将导致从我们的小集合中重建图像。这种嵌入是通过优化过程找到的(图 4),我们将其称为“Textual Inversion”。
在Latent Diffusion Models领域,inversion是通过向图像添加噪声然后通过网络对其进行去噪来执行的,但此过程会显着改变图像内容。在文本转换中,我们反转用户提供的概念并将该概念表示为模型词汇表中的新伪词。新标记的嵌入存储在一个小型 PyTorch pickled 字典中,其密钥是经过训练的新文本token。由于我们pipeline中的编码器不知道该术语,因此我们需要手动添加它。
训练
Textual Inversion的目的是能够快速引导生成新的、用户指定的概念。我们尝试将这些新颖的概念编码为预训练的文本到图像模型的中间表示。因此,我们寻求在文本到图像模型所使用的文本编码器的词嵌入阶段表示这些概念。人们发现这个嵌入空间的表现力足以捕获基本的图像语义。
Textual Inversion是通过一类名为Latent Diffusion Models的特定生成模型以及最近引入的一类在自编码器的隐空间中运行的去噪扩散概率模型 (DDPM) 来实现的。LDMs 由 2 个核心组件组成:
- 自编码器:编码器学习将图像 x 映射到空间潜在代码 z = E(x)。随后,解码器 D 将潜在映射回图像,使得 D(E(x)) = x
- 扩散模型——经过训练可以对正态分布变量进行去噪。扩散模型可以以类标签、文本、语义图或其他图像到图像翻译任务为条件。令
为将条件输入 y 映射到条件向量的模型。LDM 损失由下式给出:

其中 t 是时间步长, 是到时间 t 降噪的隐图像表示,
是未缩放的噪声样本,
是去噪网络。我们的目标是正确去除添加到图像潜在表示中的噪声。训练时,
和
联合优化以最小化 LDM 损失。我将在未来的博文中提供用于训练和推理的代码。
Textual Inversion
为了找到这些新的嵌入,我们使用一小组图像(通常是 3-5 张),它们描述了跨多种设置(例如不同的背景或姿势)的目标概念。我们通过直接优化找到 v*,通过最小化从小集合中采样的图像的 LDM 损失(如图 3 所示)。我们随机抽取中性上下文文本,如“S* 的照片”、“S* 的演绎”等来调节生成。
我们的优化目标可以定义为:

这个目标是通过重新使用与原始隐扩散模型相同的训练方案来实现的,同时保持 和
固定。这是一项重建任务,学习到的嵌入有望捕获新颖概念特有的精细视觉细节。
Textual Inversion的应用
Textual Inversion可用于一系列应用,主要包括以下内容:
- 图像多样化
- 文本引导合成
- 风格转移
- 概念合成
- 偏差减少
- 下游应用
我们将在下一节中讨论这些应用程序及其用例:
图像多样化

文本引导合成
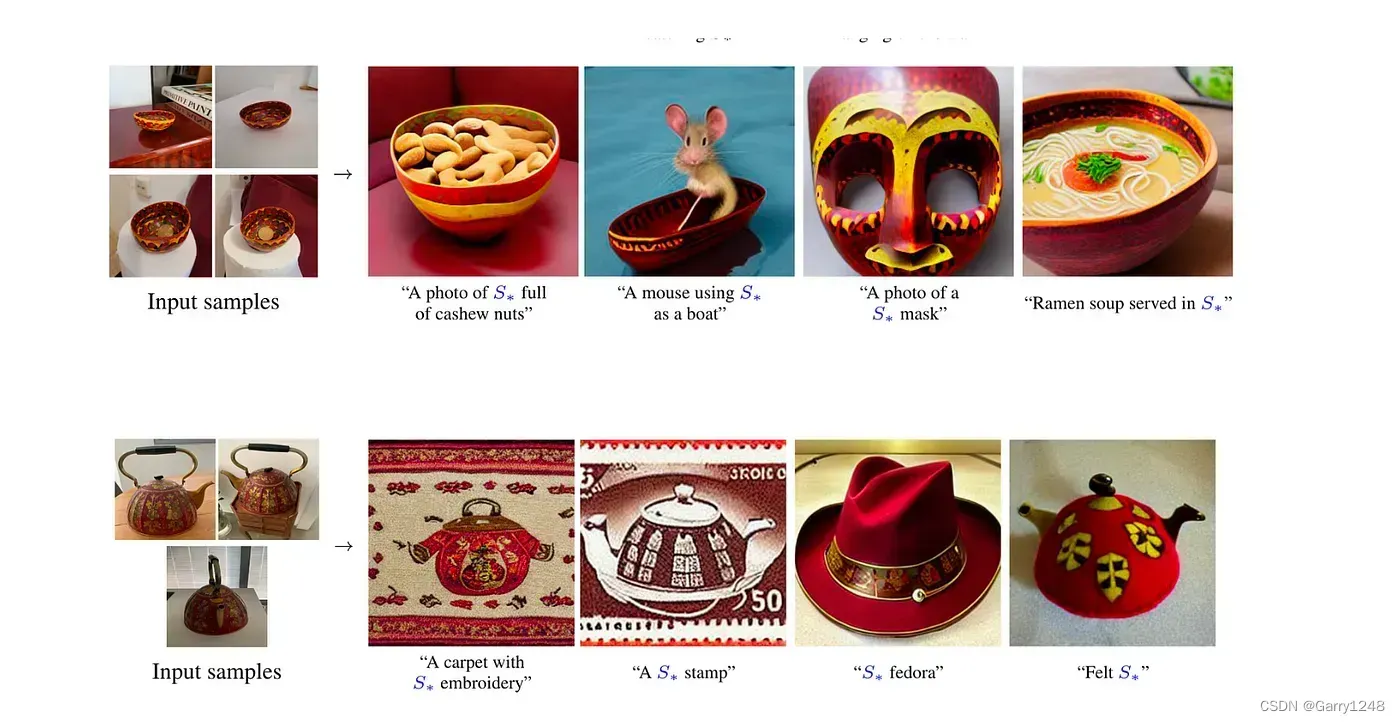
Textual Inversion可用于通过将学习的伪词与新的条件文本结合起来来创建新颖的场景。从图 6 中生成的图像中我们可以看到,可以利用伪词和新条件文本中的语义概念来创建新场景。由于该模型是使用预先训练的大规模文本到图像合成模型构建的,因此单个伪词可以重复使用多代。
风格迁移

概念合成

偏差减少

从文本到图像生成的图像由于用于训练它们的训练数据而存在偏差。因此,这些偏差也可以在生成的样本中看到,如图 9 所示。可以看出,Textual Inversion可以通过合并更具包容性的数据集来减少训练数据集中的偏差,从而产生更具包容性的生成。
下游应用

Textual Inversion的概念很重要,原因有以下两个:
- 我们可以通过在自然语言指令的指导下合成用户提供的概念的新颖场景来生成个性化文本到图像。
- 生成模型背景下的“Textual Inversion”的想法旨在在文本编码器的嵌入空间中找到新的伪词,该伪词可以捕获新概念的高级语义和精细视觉细节。
注: 博文中的大部分图片均取自原始论文。
参考
- Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A. H., Chechik, G., & Cohen-Or, D. (2022). An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618.
- https://huggingface.co/docs/diffusers/
文章出处登录后可见!