简介
每个版本的Golang的垃圾回收都在不断优化中,而且方法和策略都在变化,因此这里只是总结出以下几个关键点:
- 什么样的数据需要GC
- 触发GC的条件是什么
- GC时发生了什么
- 能否从代码层面上提高GC的效率
GC的基本流程
Golang在确定的时间,或者内存分配到达一定程度时,进行GC。GC时,会停止STW(Stop The World),即对外的服务都会暂停,然后进行垃圾回收处理。Go1.12引入了三色标记法和write-barrier的方式;在Go1.14中,引入看了抢占式回收机制。
write-barrier机制:
假设有4个G在运行,如下图:
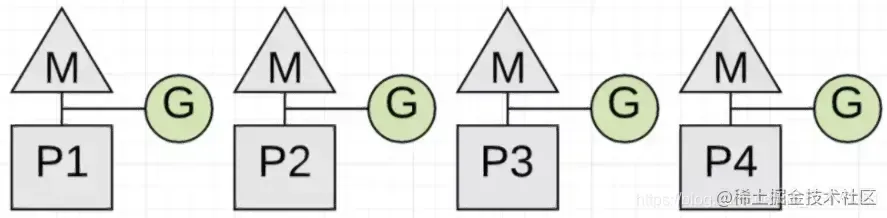
进行GC的时候,需要STW,此时的4个G都要停止工作。如果有一个没有停止工作的,则GC暂时不能发生。比如下图:
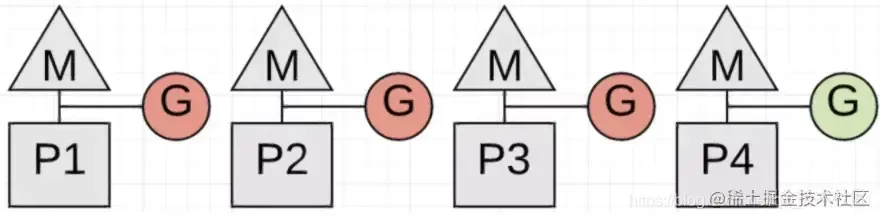
第4个G没停止工作,则GC需要等待其结束。Go1.14中,可以抢占第4个G的工作状态,保存其状态后,再进行GC
GC的时候,GC机制会征用一些G并发辅助进行工作,一般有25%的G会被征用。
整体工作流程:
- 创建白、灰和黑三个集合
- 初始化所有的待回收对象都是白色的
- 从根节点遍历对象,不递归;遍历到的白色对象放到灰色集合当中
- 之后遍历灰色集合,把灰色对象引用的对象,从白色集合中放入灰色集合,并把现在的灰色对象放入黑色集合中
- 重复上一步,知道灰色集合是空的
- 通过write-barrier检测对象的变化,重复以上操作
- 回收所有的白色对象
GC回收的对象
永远不要过早的优化程序!!!
栈内存分配和回收的代价远远小于堆内存。Golang的垃圾回收发生在全局的堆上和每个Goroutinue的栈上。回收栈内存只需要两个CPU指令,push和pop。然而,分配在栈内存的数据,需要在编译期间就得知道type和size。
Golang的编译器使用“逃逸分析”的方式,决定采取栈回收还是堆回收的方式。如果发生逃逸,则使用堆回收。
go build -gcflags ‘-m’命令可以分析内存逃逸的现象。
发生内存逃逸的几种情况:
- 向chan中发送数据的指针或者包含指针的值。
- 因为编译器此时不知道值什么时候会被接收,因此只能放入堆中
- 非直接的函数调用,比如在闭包中引用包外的值,因为闭包执行的生命周期可能会超过函数周期,因此需要放入堆中
- 在slice或map中存储指针或者包含指针的值。
- 比如[]*string,即使slice是在栈上,其存储的值仍然会放入堆中
- slice如果底层使用array作为容器,在使用append扩容的时候。但是,如果知道具体扩容的数量,则仍然在栈上。
- 如果在编译期间,slice知道自己的size,那么放入栈中。更多的时候,是不知道size的,比如append的时候,此时只能放入堆中。
- interface类型多态的时候调用方法,此时会发生逃逸
- 指针、slice和map作为参数返回的时候,此时肯定要发生逃逸。
总结一下发生逃逸的结论:
- 首先明确一点,Golang中所有的数据都是按值传递,这点和C语言是一样的(注意Golang中的数组名是值,和C的差别)。所谓的map、slice和chan等是引用,其本质原因是,这些结构的内部都有指针,复制的时候,内部都是复制的指针,因此表现的是传值。
- 在函数调用中,对于指针的情况,只要指向的地址的所有者只有一个,那么必然是栈回收;而一旦存在地址存在不确定变化时,则转换成堆的数据。比如slice情况,因为slice会扩容或者缩容,因此造成不确定情况。
以下使用代码示例说明:
package main
func main() {
ch := make(chan int, 1)
x := 5
ch <- x // x不发生逃逸,因为只是复制的值
ch1 := make(chan *int, 1)
y := 5
py := &y
ch1 <- py // y逃逸,因为地址传入了chan
z := 5
pz := &z // z不逃逸,因为是确定性析构
*pz += 1
}执行命令:go build -gcflags ./main.go,得到结论是y z都发生了逃逸。
# command-line-arguments
.\main.go:3:6: can inline main as: func() { ch := make(chan int, 1); x := 5; ch <- x; ch1 := make(chan *int, 1); y := 5; py := &y; ch1 <- py; z := 5; pz := &z; *pz += 1 }
.\main.go:9:2: y escapes to heap:
.\main.go:9:2: flow: py = &y:
.\main.go:9:2: from &y (address-of) at .\main.go:10:8
.\main.go:9:2: from py := &y (assign) at .\main.go:10:5
.\main.go:9:2: flow: {heap} = py:
.\main.go:9:2: from ch1 <- py (send) at .\main.go:11:6
.\main.go:9:2: moved to heap: y如果使用slice和map的模式:
package main
func main() {
var x int
x = 10
var ls []*int
ls = append(ls, &x)
var y int
var mp map[string]*int
mp["y"] = &y
}结论分析:
# command-line-arguments
.\main.go:3:6: can inline main as: func() { var x int; x = <N>; x = 10; var ls []*int; ls = <N>; ls = append(ls, &x); var y int; y = <N>; var mp map[string]*int; mp = <N>; mp["y"] = &y }
.\main.go:4:6: x escapes to heap:
.\main.go:4:6: flow: {heap} = &x:
.\main.go:4:6: from &x (address-of) at .\main.go:7:18
.\main.go:4:6: from append(ls, &x) (call parameter) at .\main.go:7:13
.\main.go:9:6: y escapes to heap:
.\main.go:9:6: flow: {heap} = &y:
.\main.go:9:6: from &y (address-of) at .\main.go:11:12
.\main.go:9:6: from mp["y"] = &y (assign) at .\main.go:11:10
.\main.go:4:6: moved to heap: x
.\main.go:9:6: moved to heap: y使用闭包捕获指针的模式:
package main
import "time"
func main() {
x := 10
go func(x *int) {
*x += 1
}(&x) // 捕获的瞬间,x没有移动到heap上,但是整个闭包移动到了heap上,因此x也跟随闭包被移动到heap上了
time.Sleep(time.Second * 2)
}结论分析:
# command-line-arguments
.\main.go:5:6: cannot inline main: unhandled op GO
.\main.go:7:5: can inline main.func1 as: func(*int) { *x += 1 }
.\main.go:7:5: func literal escapes to heap:
.\main.go:7:5: flow: {heap} = &{storage for func literal}:
.\main.go:7:5: from func literal (spill) at .\main.go:7:5
.\main.go:7:5: from go (func literal)(&x) (call parameter) at .\main.go:7:2
.\main.go:6:2: x escapes to heap:
.\main.go:6:2: flow: {heap} = &x:
.\main.go:6:2: from &x (address-of) at .\main.go:9:4
.\main.go:6:2: from go (func literal)(&x) (call parameter) at .\main.go:7:2
.\main.go:7:10: x does not escape
.\main.go:6:2: moved to heap: x
.\main.go:7:5: func literal escapes to heap对于slice扩容的情况:
package main
import (
"os"
"strconv"
)
func main() {
ls := []int{1, 2, 3}
ls = append(ls, 4) // 确定性的,不逃逸,编译期间可以知道
var n int
n, _ = strconv.Atoi(os.Args[1]) // 输入数据后,则结果不可知,因此可能逃逸
ls1 := []int{1, 2, 3}
for i := 0; i < n; i++ {
ls1 = append(ls1, 1)
}
}interface类型的GC,涉及使用interface类型转换并调用对应的方法的时候,都会发生内存逃逸,给出代码示例:
package main
type foo interface {
fooFunc()
}
type foo1 struct{}
func (f1 foo1) fooFunc() {}
type foo2 struct{}
func (f2 *foo2) fooFunc() {}
func main() {
var f foo
f = foo1{}
f.fooFunc() // 调用方法时,发生逃逸,因为方法是动态分配的
f = &foo2{}
f.fooFunc()
}执行说明:
go-code ➤ go build -gcflags "-m" main.go
# command-line-arguments
.\main.go:9:6: can inline foo1.fooFunc
.\main.go:13:6: can inline (*foo2).fooFunc
.\main.go:13:7: f2 does not escape
.\main.go:17:4: foo1 literal escapes to heap
.\main.go:19:6: &foo2 literal escapes to heap
<autogenerated>:1: leaking param: .this
<autogenerated>:1: inlining call to foo1.fooFunc
<autogenerated>:1: .this does not escape返回slice等的情况:
package main
func foo() []int {
return []int{1, 2, 3}
}
func main() {
ls := foo() // 发生逃逸
ls = append(ls, 1)
}分析结果:
# command-line-arguments
.\main.go:3:6: can inline foo as: func() []int { return []int literal }
.\main.go:7:6: can inline main as: func() { ls := foo(); ls = append(ls, 1) }
.\main.go:8:11: inlining call to foo func() []int { return []int literal }
.\main.go:4:14: []int literal escapes to heap:
.\main.go:4:14: flow: ~r0 = &{storage for []int literal}:
.\main.go:4:14: from []int literal (spill) at .\main.go:4:14
.\main.go:4:14: from return []int literal (return) at .\main.go:4:2
.\main.go:4:14: []int literal escapes to heap
.\main.go:8:11: []int literal does not escape传值还是传指针的问题:
根据上面的分析,指针更容易出现内存逃逸的现象。而一旦发生了内存逃逸,则不可避免地对GC造成潜在的压力。有种错误的观念:传指针的代价总是比传值的拷贝代价小。这种观念只在像C语言这种没有GC的低级语言中可能适用。原因如下:
- 对指针解引用的时候,编译器会进行一些检查。
- 指针一般都不是临近地址的引用,而复制时,一般都是CPU cash中的数据,cash line内的数据的复制,速度基本和一个复制指针相等
因此,对于小型的数据,一般传值就够了。在某些情况下,需要对代码做一些重构,以消除成员变量中不必要的指针类型。slice有些情况下,可能也会造成内存逃逸,使用已知固定长度的slice,某些情况下会减少内存逃逸。nterface调用方法会发生内存逃逸,某些热点的情况下,可以考虑优化interface的情况。
几个总结
- 永远不要过早的优化,使用数据驱动优化代码
- 栈回收的代价远远小于堆回收的代价
- 指针一般情况下会影响栈回收
- 在热点代码片段,谨慎的使用interface
以上就是详解Golang的GC和内存逃逸的详细内容,更多关于Golang GC和内存逃逸的资料请关注aitechtogether.com其它相关文章!