灰常好的模型网站
LiblibAI·哩布哩布AI-中国领先原创AI模型分享社区
出图效率倍增!47个高质量的 Stable Diffusion 常用模型推荐 – 优设网 – 学设计上优设
几种模型的介绍
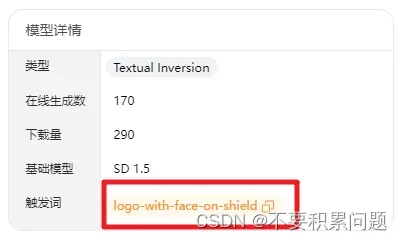
Embeddings
如果Checkpoint是个大词典,embeddings就像词典的书签。模型网站上还会有触发词,可以把它复制黏贴到正向提示词栏里。
用法:三视图、负面提示词
LoRa
如果Checkpoint是个大词典,embeddings就像词典的书签,而lora相当于一张详细的彩页。
用法:
人物角色形象
画风 / 风格
概念
服饰
物体、特定元素
Hypernetwork
是一张小卡片。主要是用来影响画风。
CGF Scale 分类器自由引导尺度
图像与提示词的一致程度,越低的值产生越有创意的结果
关键词Prompt顺序
画质
风格
主体
外表、描述
表情、情绪
姿势
背景
杂项
以上的顺序可以通过下面这个网站来调整排序↓
OPS 提示词工作室 | 可视化编辑提示词 | 一键翻译 AIGC 提示词 | Midjourney 提示词 | OpenPromptStudio made by Moonvy 月维
同时可以考虑满足以下的条件:
在描述主题时要详细和具体。
提示词越靠前权重越大,越靠后权重越低;
可以通过按住ctrl + ↑↓来快速调节权重,权重设置在0.5~2之间;
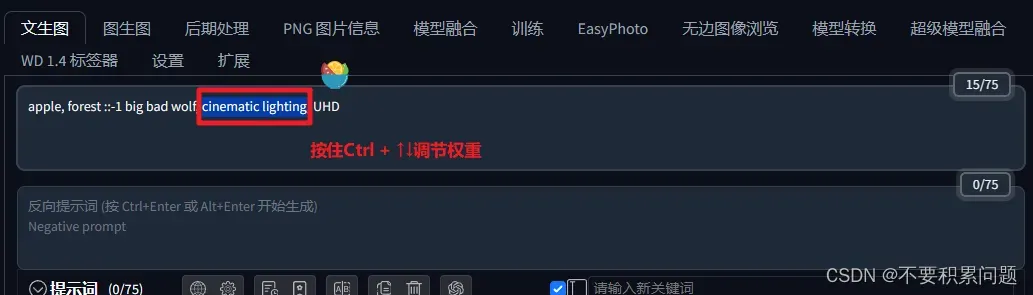
艺术家的名字是一个非常强的风格修饰符,使用的时候要知道这个是什么风格。
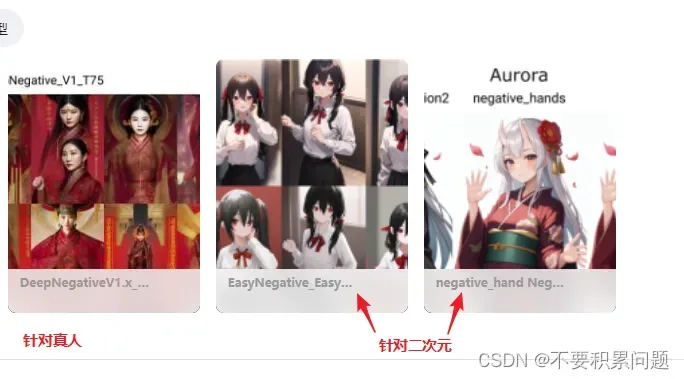
万能负面关键词
(bad-artist:1.0), (loli:1.2), (worst quality, low quality:1.4), (bad_prompt_version2:0.8), bad-hands-5,lowres, bad anatomy, bad hands, ((text)), (watermark), error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, ((username)), blurry, (extra limbs),
风格Prompt参考
film grain 胶片颗粒感/老电影滤镜
(。。。。。。罗列中)
用gpt来生成prompt
StableDiffusion是一款利用深度学习的文生图模型,支持通过使用提示词来产生新的图像,描述要包含或省略的元素。
我在这里引入StableDiffusion算法中的Prompt概念,又被称为提示符。
下面的prompt是用来指导AI绘画模型创作图像的。它们包含了图像的各种细节,如人物的外观、背景、颜色和光线效果,以及图像的主题和风格。这些prompt的格式经常包含括号内的加权数字,用于指定某些细节的重要性或强调。例如,”(masterpiece:1.5)”表示作品质量是非常重要的,多个括号也有类似作用。此外,如果使用中括号,如”{blue hair:white hair:0.3}”,这代表将蓝发和白发加以融合,蓝发占比为0.3。
以下是用prompt帮助AI模型生成图像的例子:masterpiece,(bestquality),highlydetailed,ultra-detailed,cold,solo,(1girl),(detailedeyes),(shinegoldeneyes),(longliverhair),expressionless,(long sleeves),(puffy sleeves),(white wings),shinehalo,(heavymetal:1.2),(metaljewelry),cross-lacedfootwear (chain),(Whitedoves:1.2)
仿照例子,给出一套详细描述以下内容的prompt。直接开始给出prompt不需要用自然语言描述:
批量改变图片的某个组件(脚本X/Y/Z plot)
通过一个案例,批量改变头发的风格,介绍脚本X/Y/Z plot的妙用

首先我们现有一张原图,我在哩布上找到了一张别人的成品,(顺便还可以直接拷贝里面的提示词),想要图片不崩,我觉得红框里面的东西都需要注意
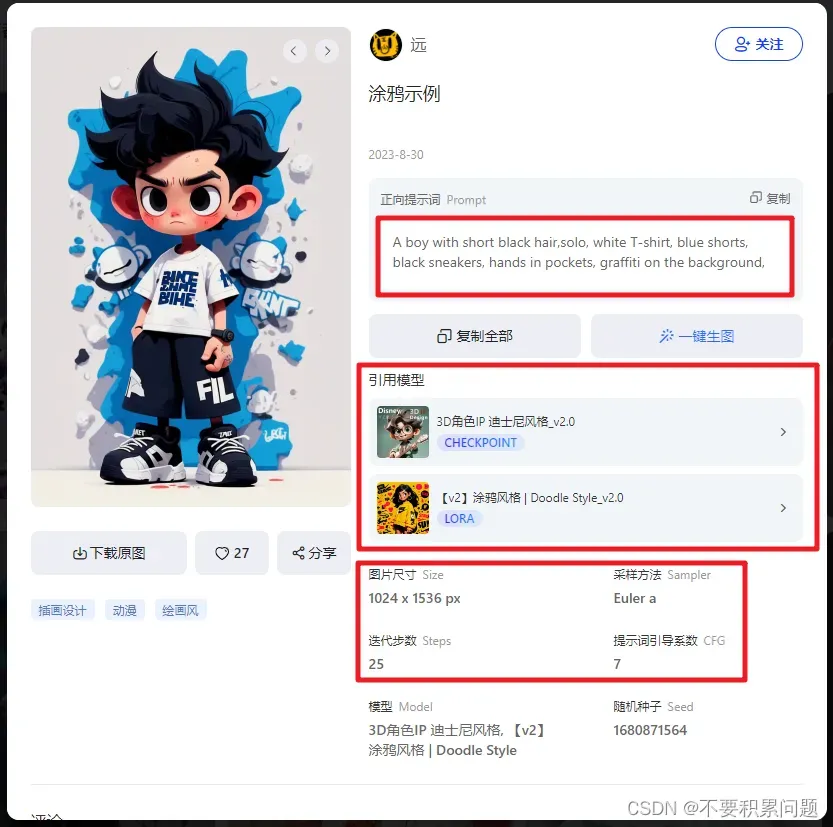
打开sd,将引用的模型和其他参数都做到尽量一致(图片可以等比例先改小一些),运用图生图的重绘功能,涂抹想要更改的部分(头发)(当然还可以选择涂抹上衣、短裤,看你想更改什么变量)

1.调整重绘幅度,一般可以从0.5向上递增(效果看起来0.6~0.9的还可以)


2. 批量产图,看看稳定性(头发颜色以及有没有奇怪的东西产生)

| 重绘幅度 | 成功率 |
|---|---|
| 0.6 | 0/9 |
| 0.7 | 1/9 |
| 0.8 | 4/9 |
| 0.9 | 5/9 |
得出结论可以缩小范围到0.8-0.9
3.打开脚本X/Y/Z plot
把产图重新改回1,打开脚本
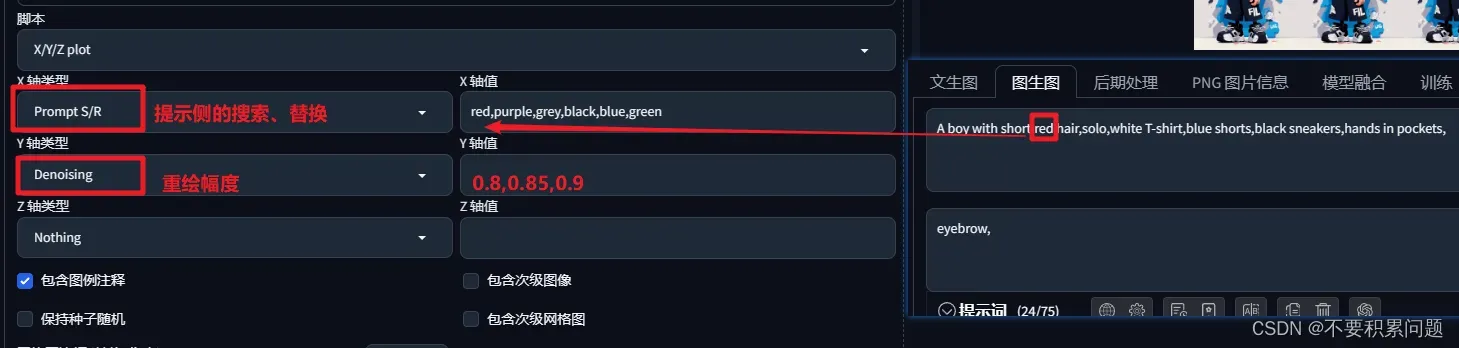
x轴选了提示词的red,y轴选择了重绘幅度
这样子,一个比较稳定的换组件工作就完成了,还是非常酷的

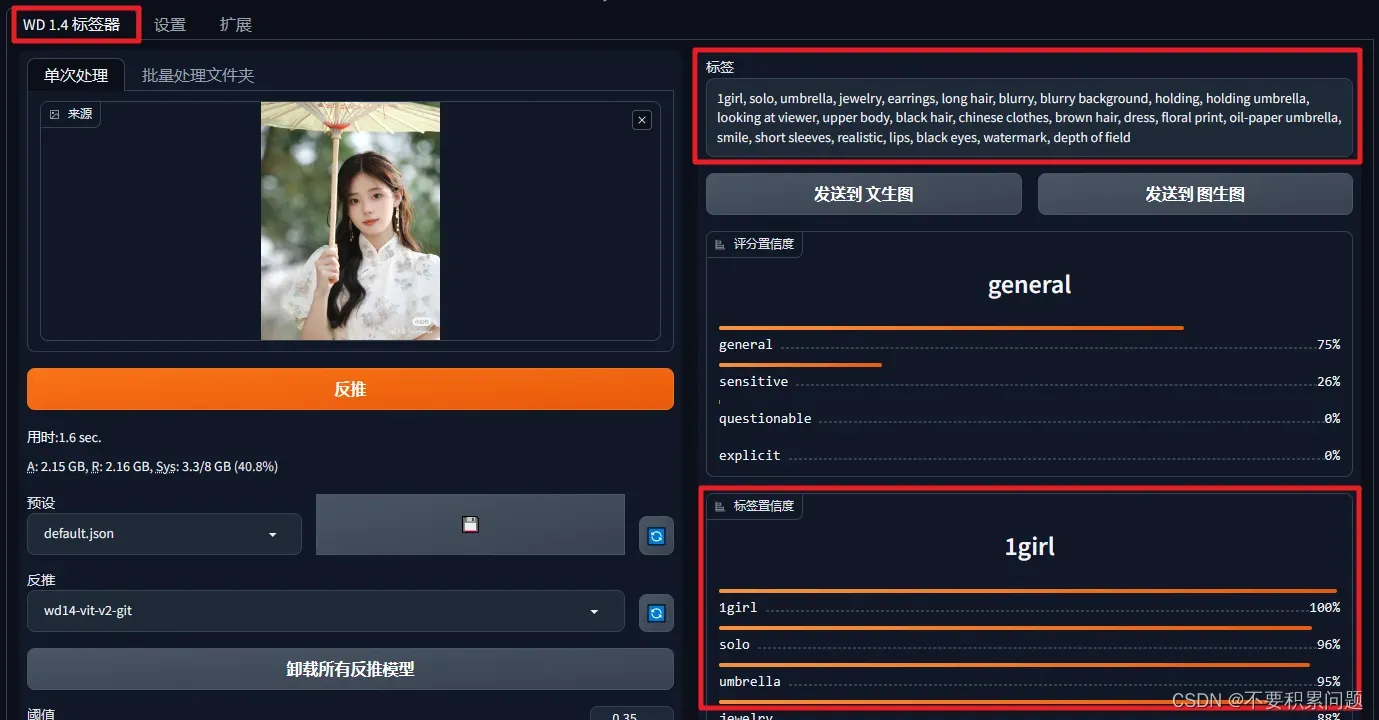
反推提示词(插件Tagger)
图生图情况下,选择反推(一般用DeepBooru反推,更快)

还有一个厉害的插件可以完成这个过程
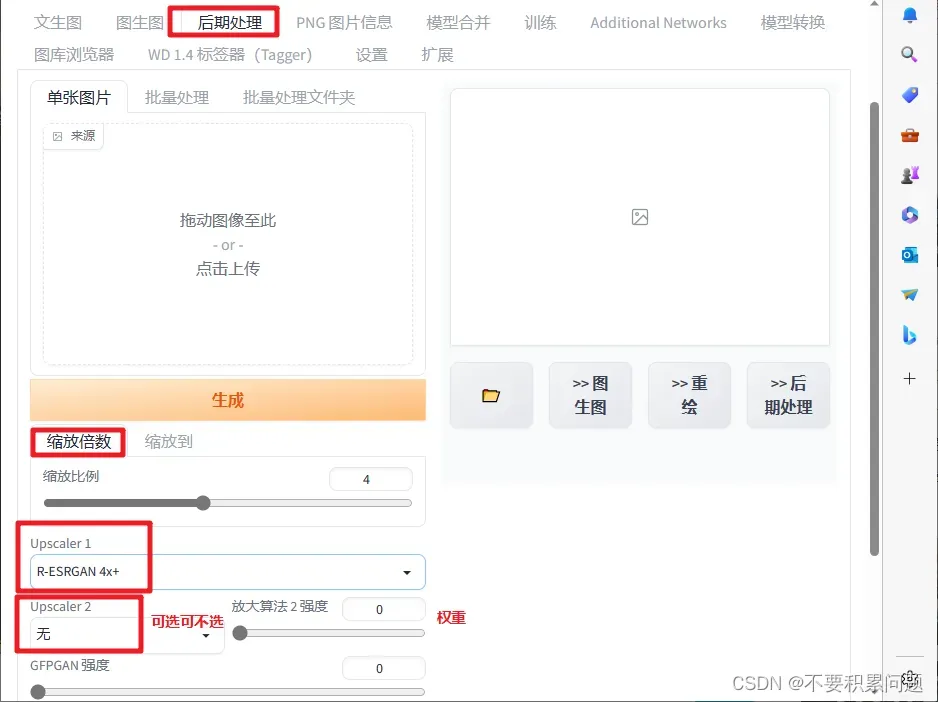
图片修复 (inpaiting)
针对文生图
可以多生成批次挑选好的种子的办法,再进行高分辨率修复↓
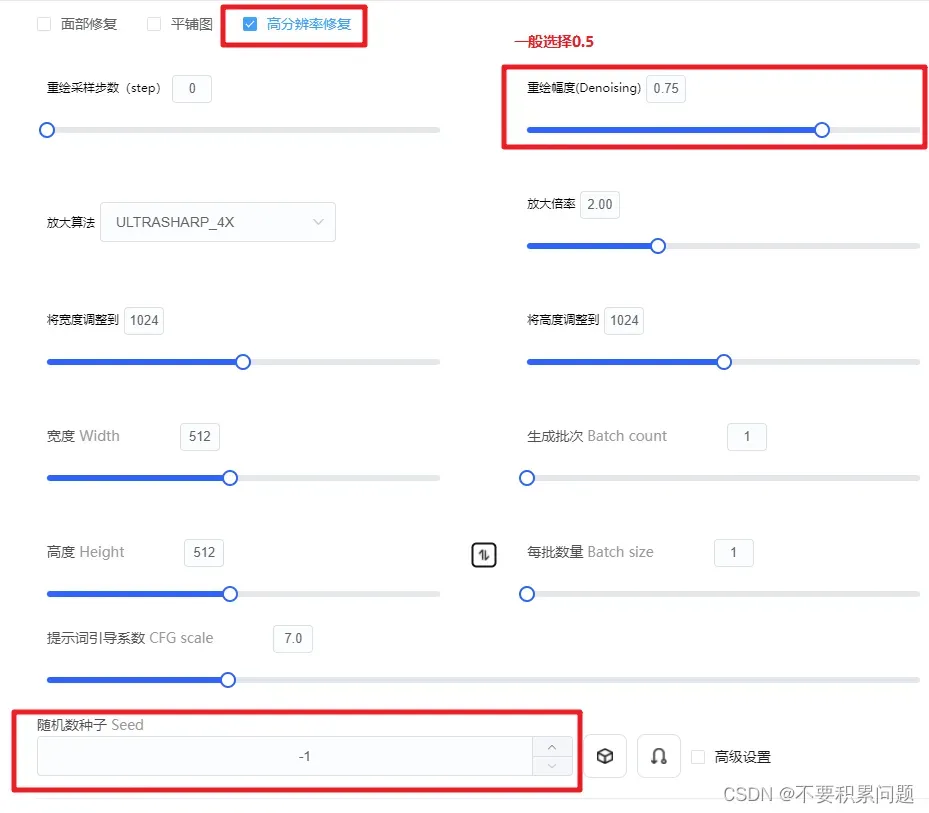
(放大算法选择R-ESRGAN比较好,动画选择R-ESRGAN+Anime6B)
方法2
- 下载inpaiting模型;
- 可以生成图片后点击send img2img,也可以自己上传到img2img;
- 用刷子进行绘制想要修改的区域,刷完之后,重新生成。
其中的一些参数:

模型记得选择SDv1.5修复模型(sd-v1-5-inpainting.ckpt)。
针对图生图
选取满意的图再点击发送到图生图,控制重绘程度为0.5,再放大尺寸

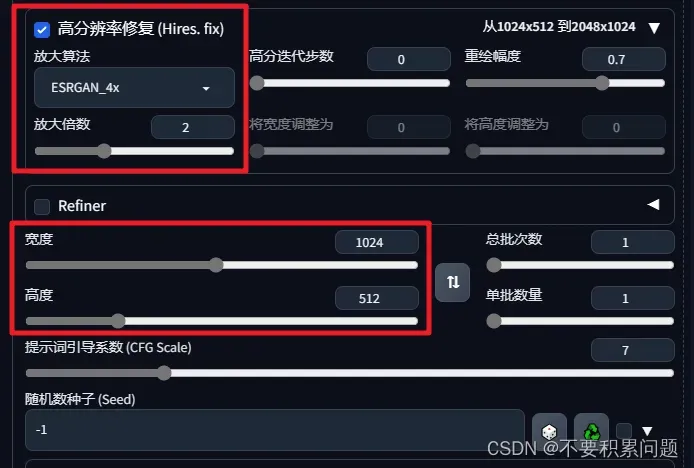
超分辨率 Hires.fix
文生图的时候,高分辨率的图反而会产生非常怪异的图像。Hires.fix使得ai先在较低的分辨率下部分渲染你的图片,在通过算法提高图片到高分辨率,然后在高分辨率下再添加细节。
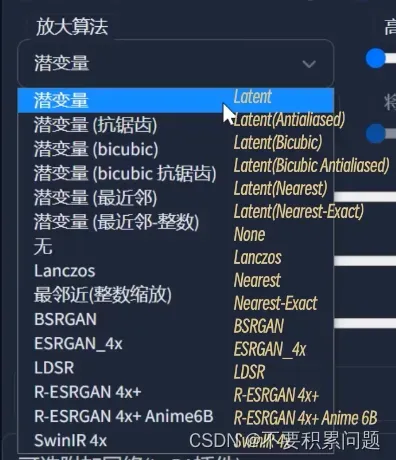
- 放大算法无脑选择R-ESRGAN
- 重绘幅度
- Upscale by:拉高这个参数需要更高的显存;数值2可以解决放大算法和controlNet的冲突
放大脚本 (upscale)
(放大算法选择R-ESRGAN比较好,动画选择R-ESRGAN+Anime6B)
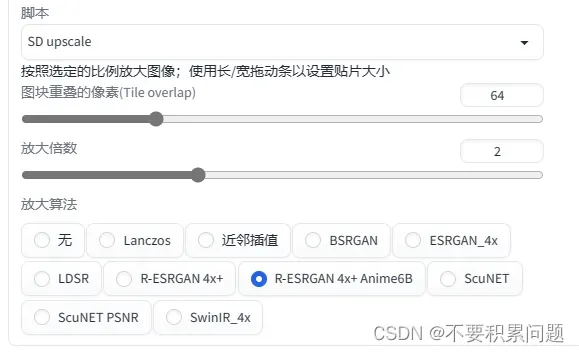
*后期处理的放大方法
比较快,但是效果不如图片修复和放大脚本好
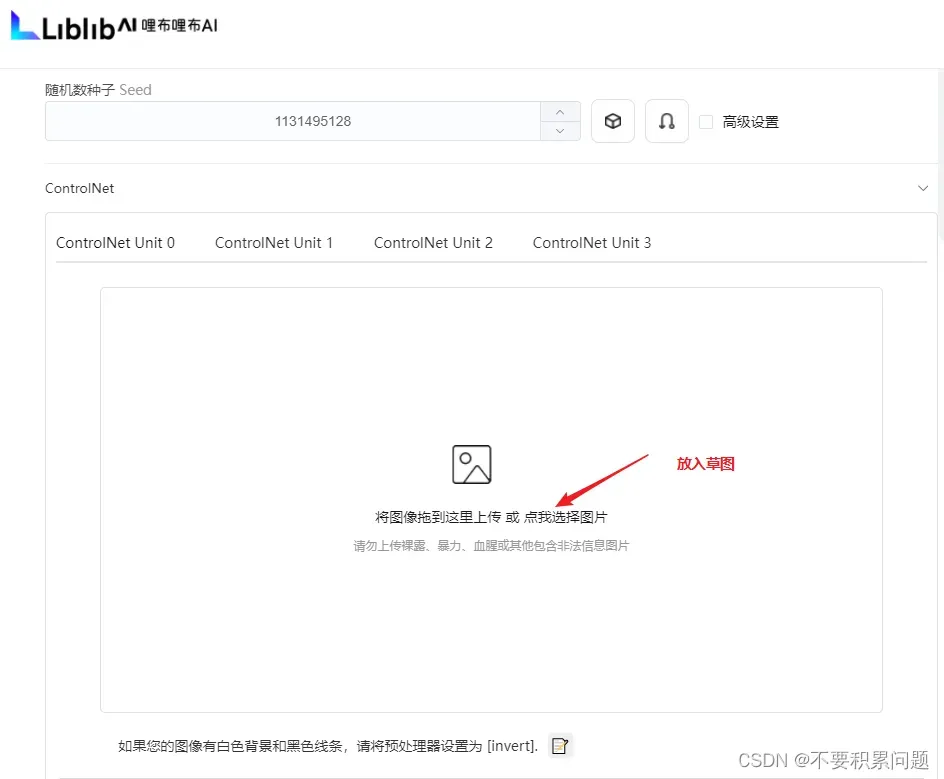
草稿出3D图教程
1.拿到一张非常随意的草图
2.文生图模式,选好checkpoint(NyanMix)和lora(AnimeLineart/Manga-like),主要用来优化草图;在正负提示词写上描述词,主要描述草图里的东西;放入草图
(canny low threshold识别暗部,canny high threshold识别亮部。两者降低都能提高细节)
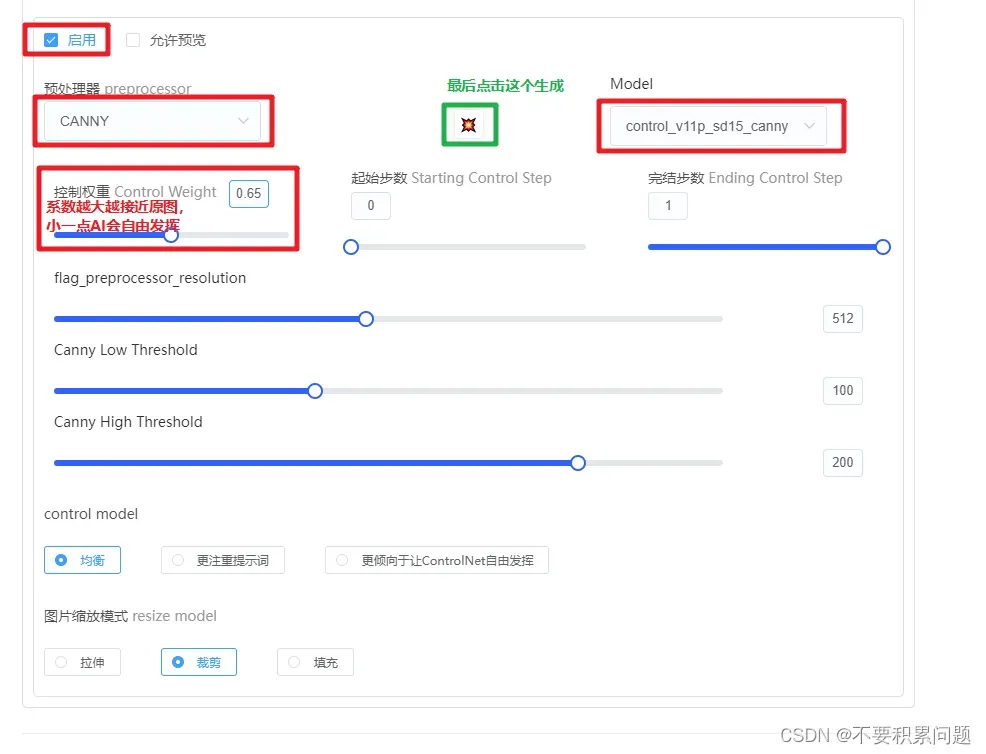 最后点击生成图片
最后点击生成图片
3.文生图模式,选好checkpoint(RevAnimated)和lora(blindbox),主要用来优化草图;在正负提示词写上描述词,主要描述草图里的东西;放入上面优化过的草图

注:白底黑线的canny用invert的形式

插件子安装地址教程
插件安装位置

VAE用来控制滤镜。通常一般的Checkpoint都会调好滤镜,个别Checkpoint也会在提示适合什么VAE模型,下载下来的时候可以命名成和大模型Checkpoint相同的名字,(checkpoint的名字)+(.VAE)+(.pt)


局部重绘

局部重绘和选取范围有关,与颜色无关;涂鸦重绘和涂上去的范围、颜色都有关系。
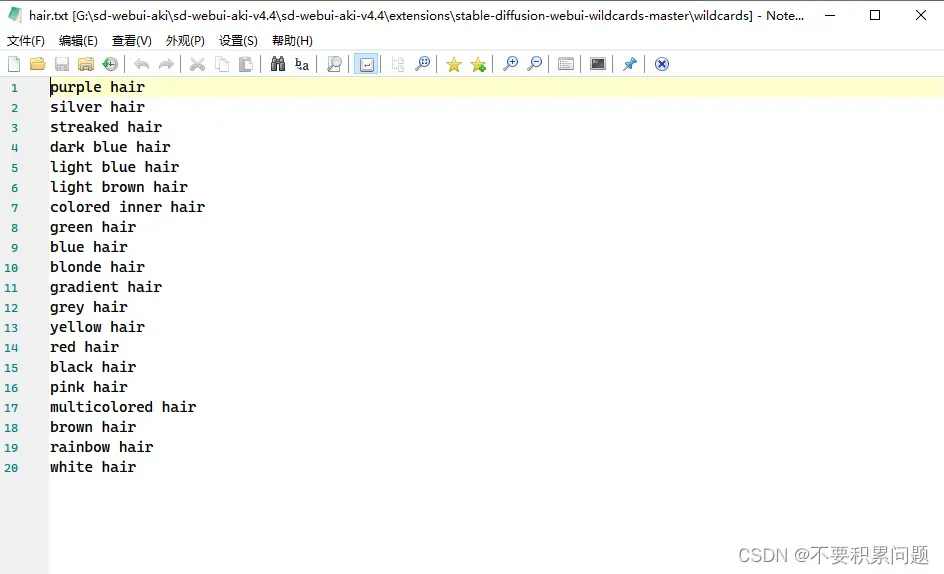
插件Wildcards 按照自己的编写好的词条随机抽卡
首先安装好插件
Wildcards插件GitHub仓库地址: https://github.com/AUTOMATIC1111/stable-diffusion-webui-wildcards
在插件的文件夹里安排好自己想要的词条记事本
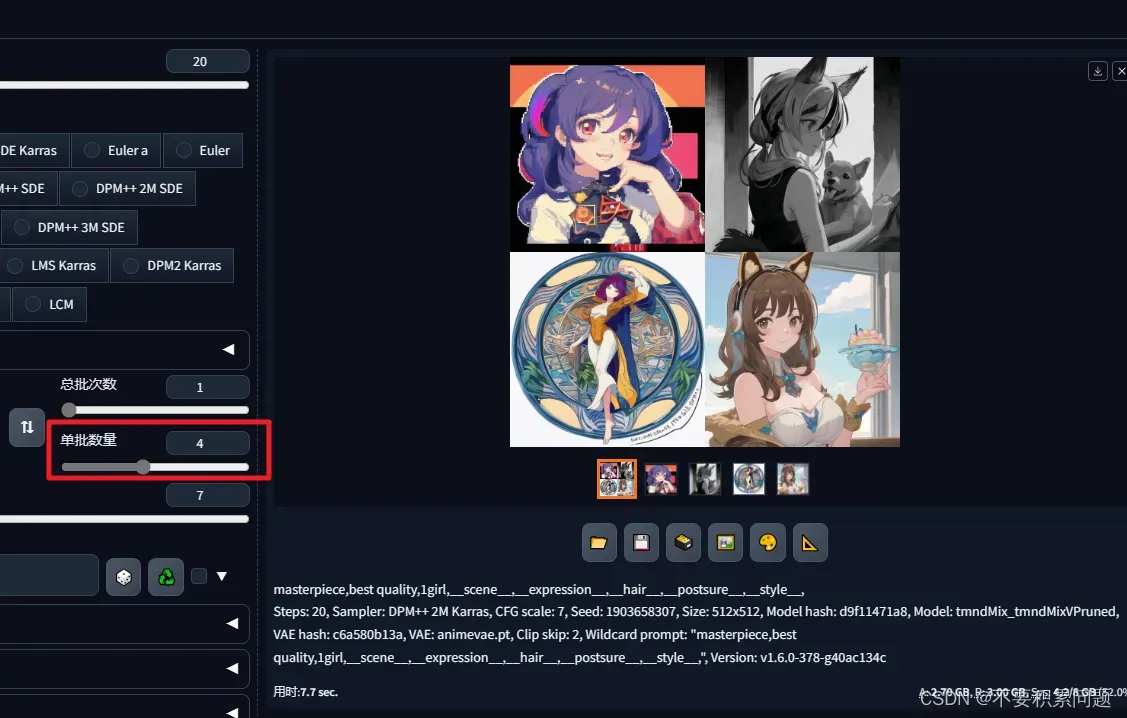
 文生图调用(这里的意思就是,场景面部表情等等,会在我们准备好的记事本里随机抽取一个词条来跑图)
文生图调用(这里的意思就是,场景面部表情等等,会在我们准备好的记事本里随机抽取一个词条来跑图)
 并且增加单批数量,每张图的限定词都会随机一下
并且增加单批数量,每张图的限定词都会随机一下
三视图案例
结合上面的Wildcards 和 CharTurner LoRA和controlNet来实现三视图
CharTurner LoRA的权重设置为0.2~0.4之间;三视图的关键词有:(simple background, white background:1.3),multiple multiple views,

打开controlNet,放入三视图骨架图,
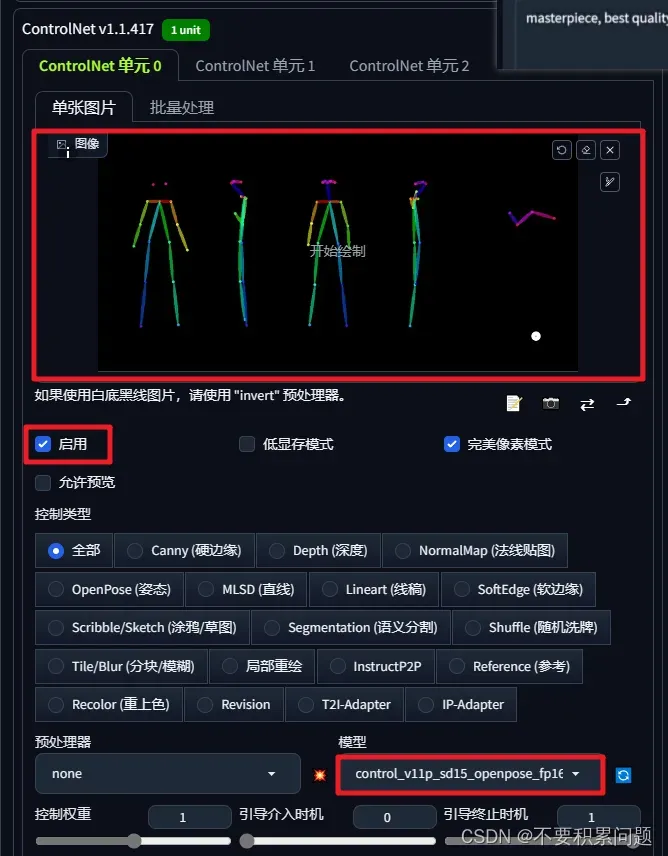
效果图很酷


手部控制方案
stable diffusion最全手部控制方案,案例实操教程|手指|手势|姿势控制|分层控制|embedding|LyCORIS|3D openpose_哔哩哔哩_bilibili
方法一、emdding负面提示词+提示词矩阵
1.大模型和其他参数都选好之后,首先将embedding的几个词都写入负面提示词栏,用 | 隔开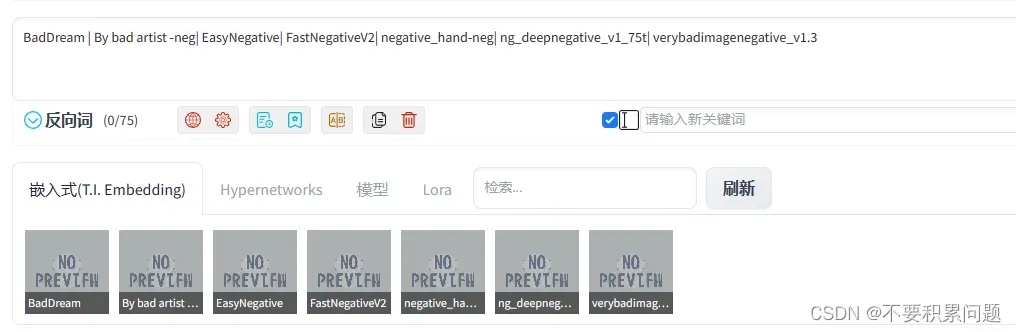
2.
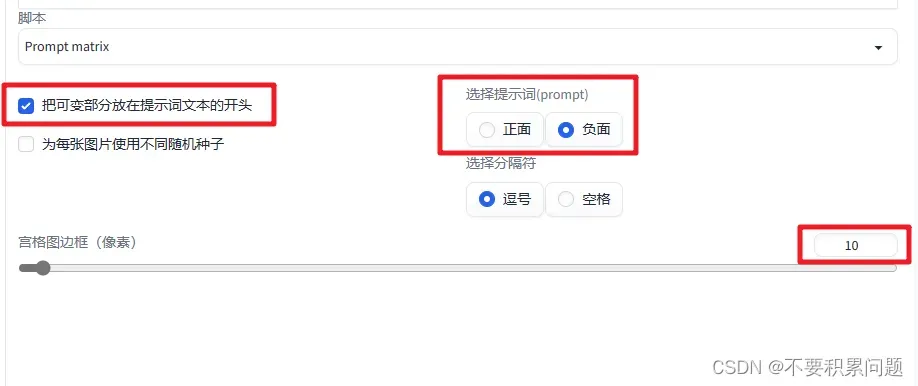
3.导出的图除去差异太大的行(hang),留下差异不大的行(hang)
方法二、Open Pose Editor + Depth Library插件
待补全
方法三、3D openpose(有插件版、在线版)
网页版:https://zhuyu1997.github.io/open-pose-editor/
点击下面的图可以下载需要的图(我们下载骨架图和手部canny图)
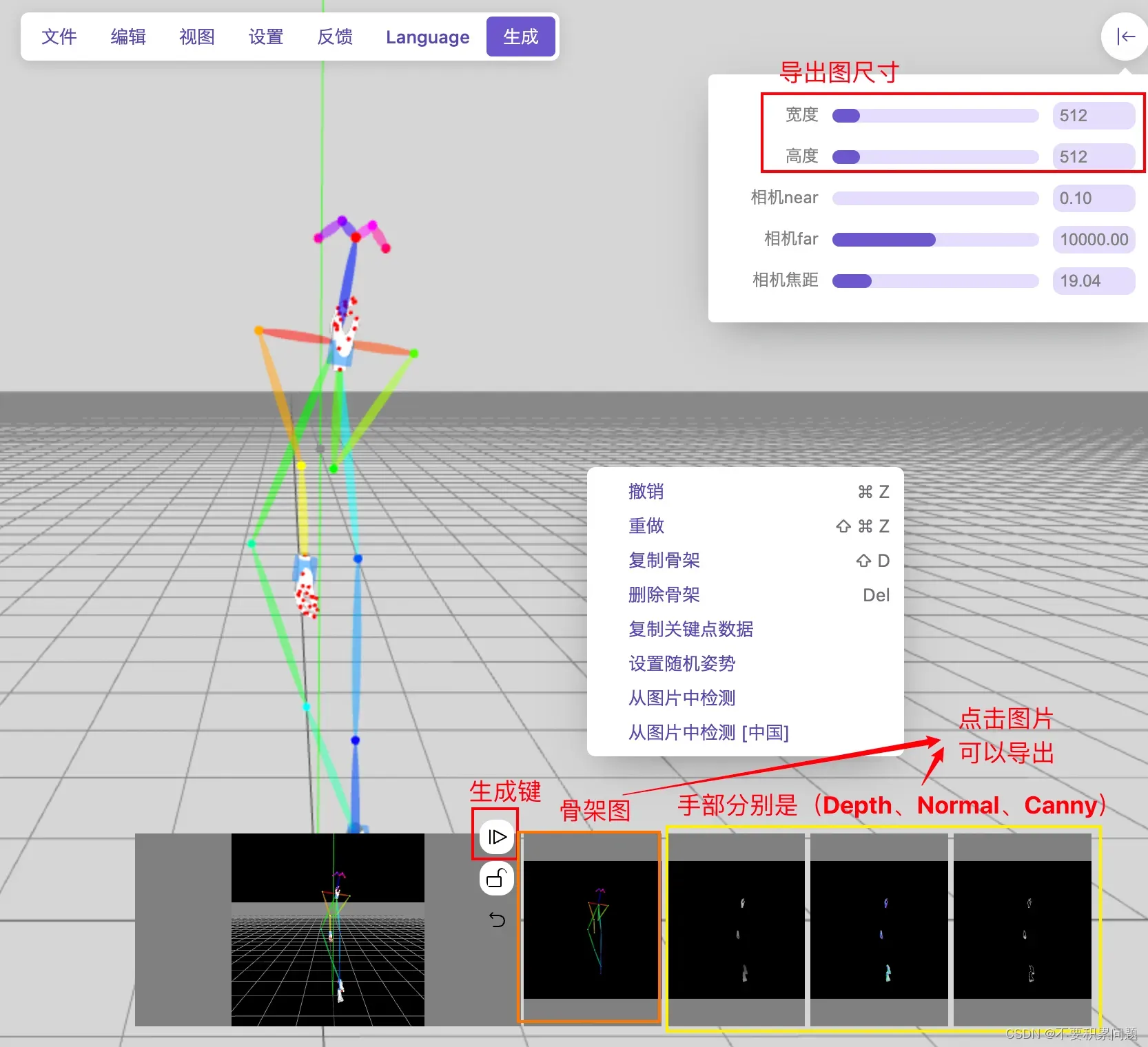
第一框(ControlNet Unit0)填pose骨架图,第二框(ControlNet Unit1)填手部Canny图
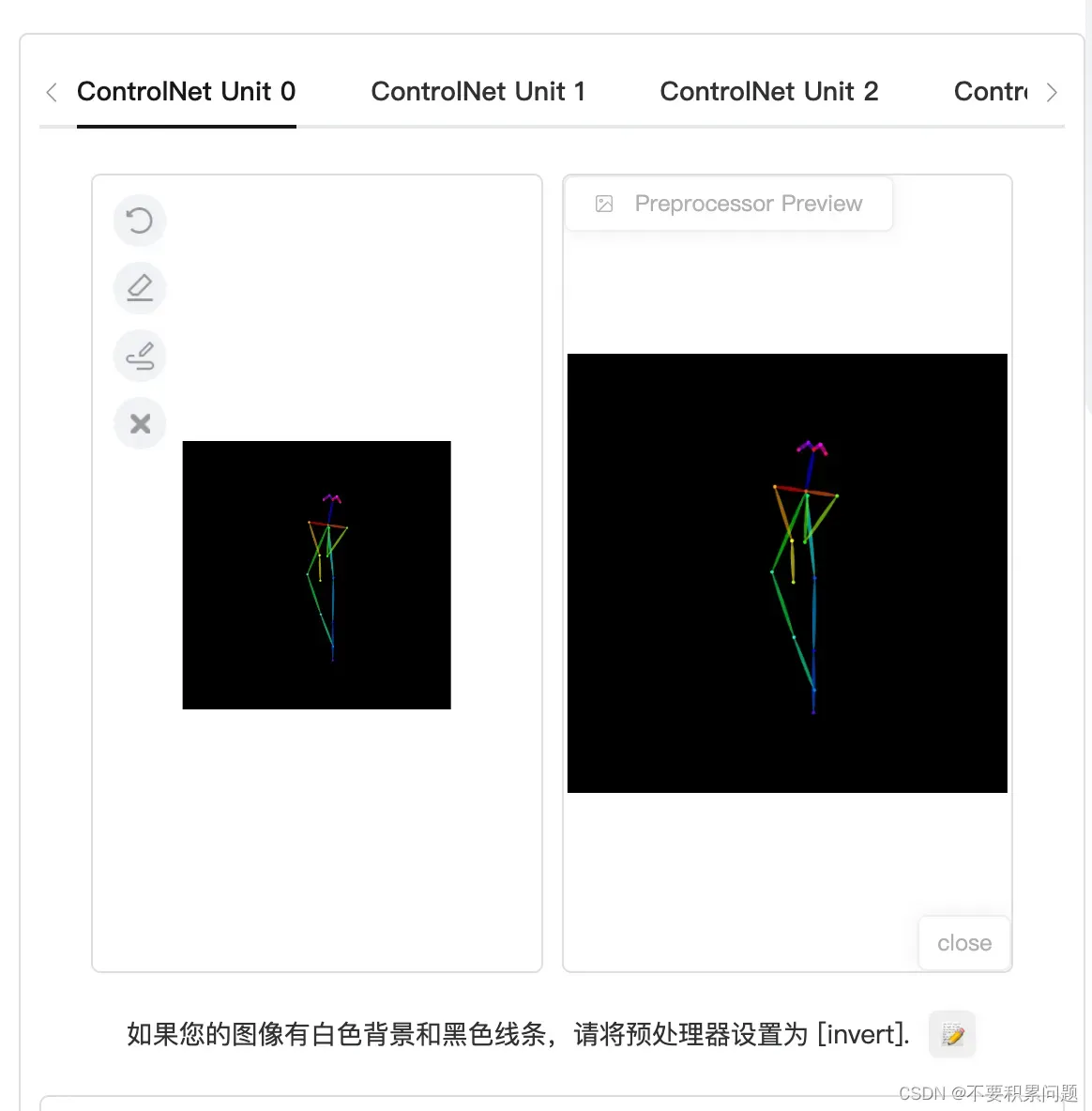
骨架选Open Pose的选项,手用canny选项
controlnet精确控制
文生图controlnet的图像需要导入(一张图来控制姿势等等),图生图默认将原图作为参照来运行control计算,所以control那一栏可以空着。
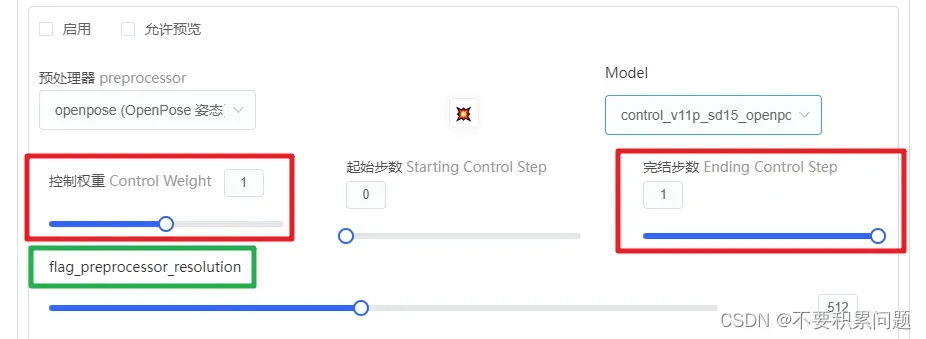
control weight和ending control step的提高可以提高control 的控制强度,绿框的分辨率在碰到canny、lineart、depth等对精度有一定要求的模型时,可以把分辨率开到和原来的图一样
1.openpose动作姿势
2.depth深度
3.canny边缘检测(线稿)
4.softedge(柔和边缘)=hed
5.scribble(涂鸦乱画)
6.inPaint模型:局部重绘
7.Tile模型:放大、增加细节
8.Refernce Only:用于固定细节
9.seg:语义分割
【AI绘画】强大的构图工具:Seg(ControlNet)语义分割控制网络_哔哩哔哩_bilibili
-
*运用1.一键换背景
图生图的模式,放进去一张想要换背景的图,在打开control net,选择depth,放入相同的照片
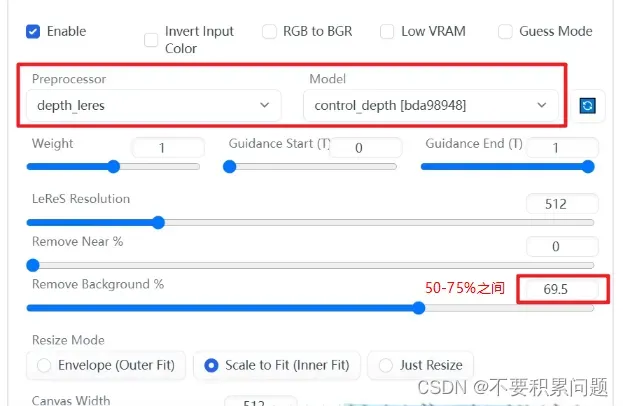
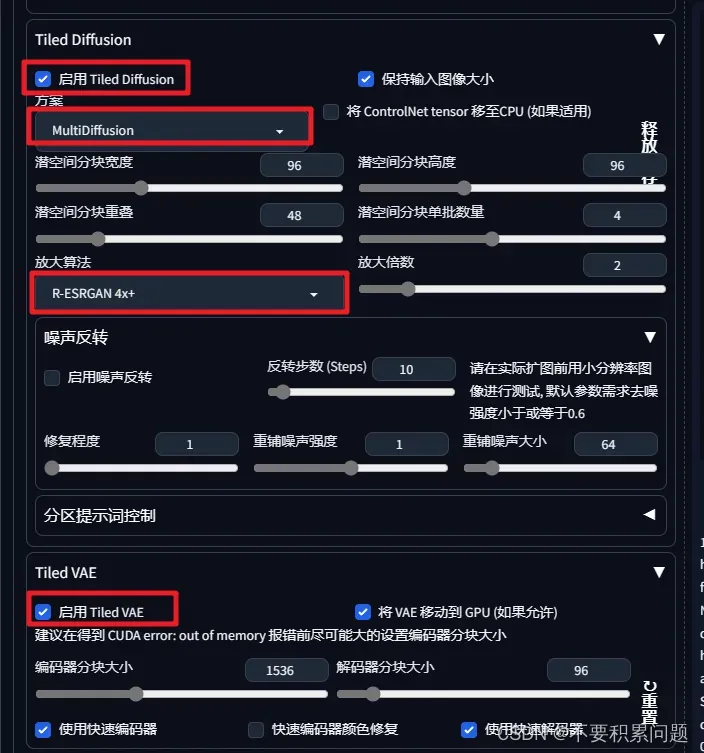
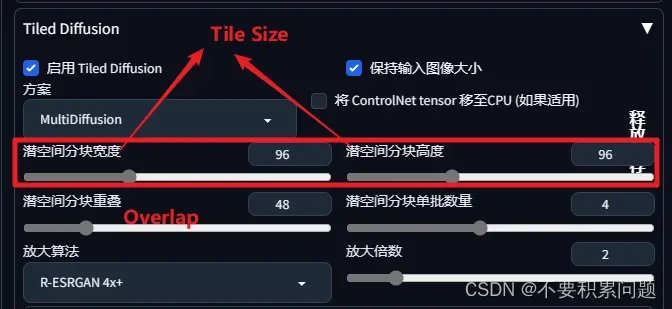
(好用)Tiled Diffusion放大
这两个都要打开↓

超高分辨率升级
基础操作
将生成的低分辨率的图发送到图生图里面,打开Tiled Diffusion和Tiled VAE,参数设置如下
建议把“使用快速编码器”取消勾选
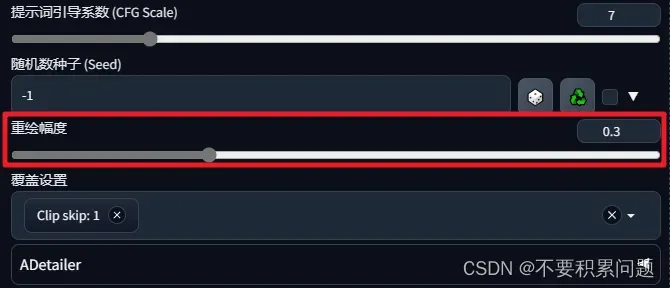
重绘尺寸里说的保持原样 是指原图片尺寸
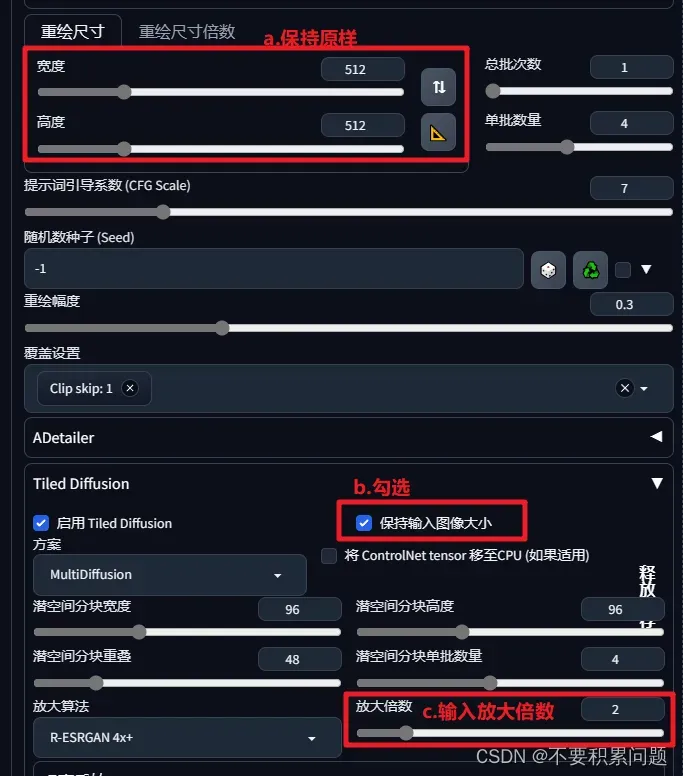
再点击生成就可以放大了
参数分析
建议把“使用快速编码器”直接取消勾选,因为开起来颜色会变灰
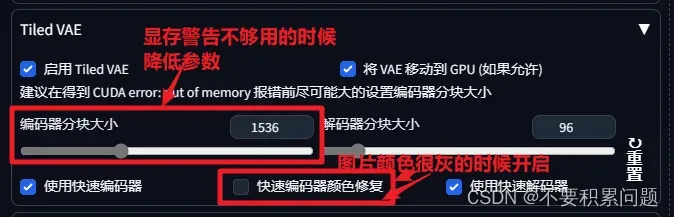
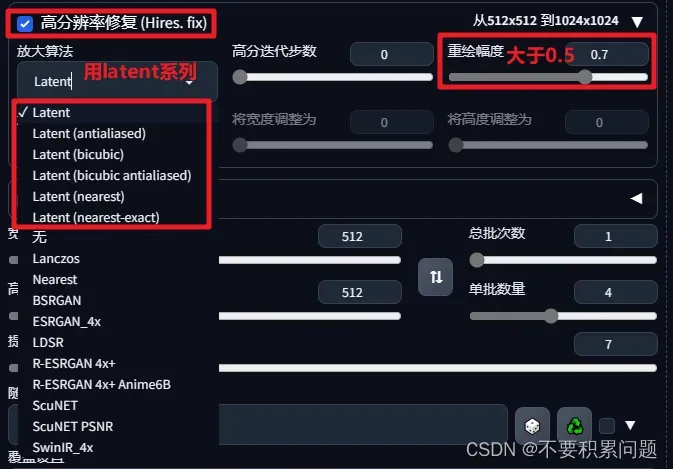
 进阶用法
进阶用法
在刚开始文生图的时候就开启高清修复,参数如下。进行第一次生图。
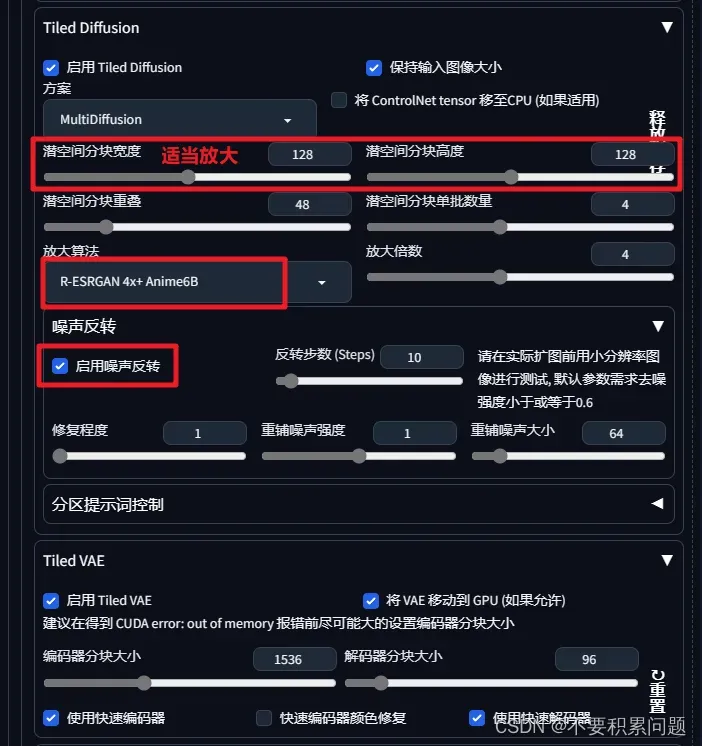
打开Tile Diffusion和Tiled VAE,参数设置如下。这里放大图像大小为4倍,然后第二次生图。
建议把“使用快速编码器”直接取消勾选,因为开起来颜色会变灰
用AI生成360VR全景图
(AI绘图)怎样用AI生成360VR全景图_哔哩哔哩_bilibili
全景图LORA下载:https://civitai.com/models/10753/latentlabs360
免费360全景图下载:https://pixexid.com/search/360-panorama
360测试网站:https://skybox.blockadelabs.com/
文章出处登录后可见!