哈喽,各位小伙伴们大家好,最近一直再研究人工智能类的生产力,不得不说随着时代科技的进步让人工智能也得到了突破性的发展。而小编前段时间玩画画也是玩的不可自拔,你能想想得到,一个完全不会画画的有一天也能创作出绘画作品。
熟知小编教学的小伙伴都知道,一般都是图文并茂形式进行的,一般只需要按照操作步骤进行都能学会。
一、本次学习目的
使刚接触Stable Diffusion webui的小伙伴能快速熟悉基础功能的理解及使用
二、简单介绍
Stable Diffusion是一种基于扩散过程的图像生成模型,可以生成高质量、高分辨率的图像。它通过模拟扩散过程,将噪声图像逐渐转化为目标图像。这种模型具有较强的稳定性和可控性,可以生成具有多样化效果和良好视觉效果的图像。
而且Stable Diffusion是个开源的程序,只要你有足够的配置,就可以自己部署开始玩,自己控制生成图像的特征和风格,生成不同风格的高质量图像。总之,它通过模拟扩散过程,生成高质量、高分辨率的图像,具有较强的稳定性和可控性。在多种领域,如艺术、设计、游戏等都有着广泛的应用前景。
三、演示参数
演示操作系统:Windows 10
操作系统版本:22H2
系统框架:64位
处理器(CPU):Intel(R)Core(TM)i7-9700K CPU 3.60GHz
内存(RAM):32GB
显卡(GPU):NVIDIA GeForce RTX 2060 SUPER (8 GB)
硬盘类型:西数机械4T红盘
Python版本号:3.10.11
Stable Diffusion webui 版本号:v1.3.1
模型名:xxmix9realistic_v30.safetensors
模型哈希值:2030eae609
演示参数方便大家以供参考
四、开始学习
1、演示数据
此数据来源:Image posted by Zyx_xx (civitai.com)
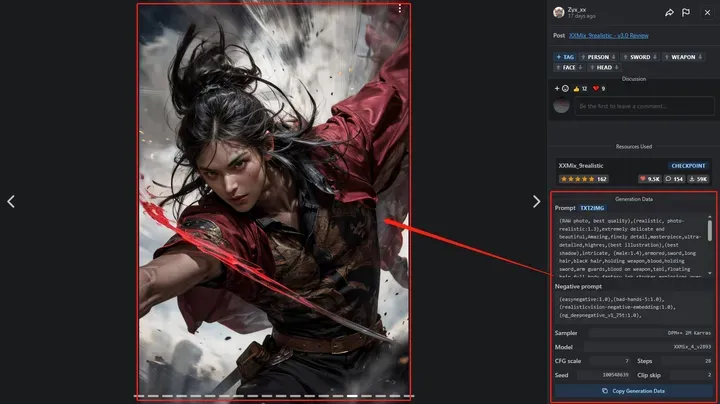
如果你能看得懂英文,想必使用起来会轻松有趣的多
下面是小编提取的图片数据,我们一起来看看吧
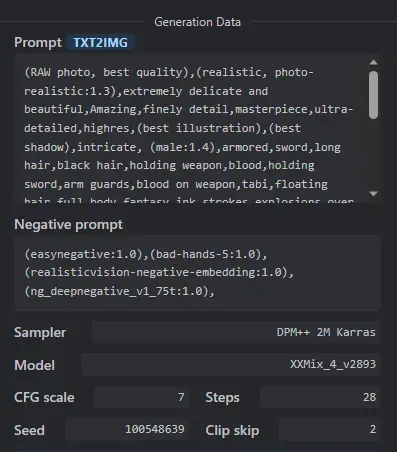
prompt(正向提示词): (RAW photo, best quality),(realistic, photo-realistic:1.3),extremely delicate and beautiful,Amazing,finely detail,masterpiece,ultra-detailed,highres,(best illustration),(best shadow),intricate,(male:1.4),armored,sword,long hair,black hair,holding weapon,blood,holding sword,arm guards,blood on weapon,tabi,floating hair,full body,fantasy,ink strokes,explosions,over exposure,((watercolor painting by John Berkey and Jeremy Mann )) brush strokes,negative space,red paint splatted,in the style of gritty urban realism,violent,wildlife art with a satirical twist,intense energy,(fogy:1.4),sharp focus,volumetric fog,8k UHD,DSLR,high quality,(film grain:1.4),Fujifilm XT3,black and red tone impression on background,motion blur,<lora:wuxia:0.6> <lora:Smoke:0.8>,<lora:add_detail:1>,
Negative prompt(反向提示词): (easynegative:1.0),(bad-hands-5:1.0),(realisticvision-negative-embedding:1.0), (ng_deepnegative_v1_75t:1.0),
ENSD(采样器参数,ETA噪声种子偏移): 31337,
Size(分辨率): 512×768,
Seed(随机数种子): 100548639,
Model(底模/模型): XXMix_4_v2893,
Steps(迭代步数): 28,
Sampler(采样方法): DPM++ 2M Karras,
CFG scale(提示词引导系数): 7,
Clip skip(跳过clip层数): 2,
Model hash(底模/模型哈希值): 2030eae609,
Hires steps(高分辨率修复迭代步数): 15,
Hires upscale(放大倍数): 2,
Hires upscaler(放大算法): 4x-UltraSharp,
Denoising strength(重绘幅度): 0.3
是不是看到这一大堆的英文数字已经开始头疼了呢,没关系,往下我们继续逐一解析
2、逐个解析
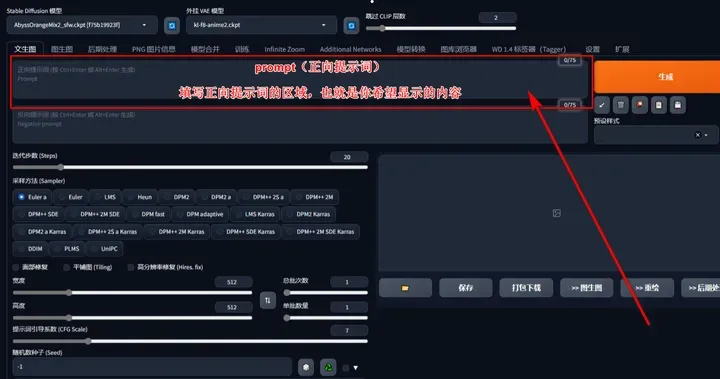
prompt(正向提示词):
这里面填写你想要显示的画面内容
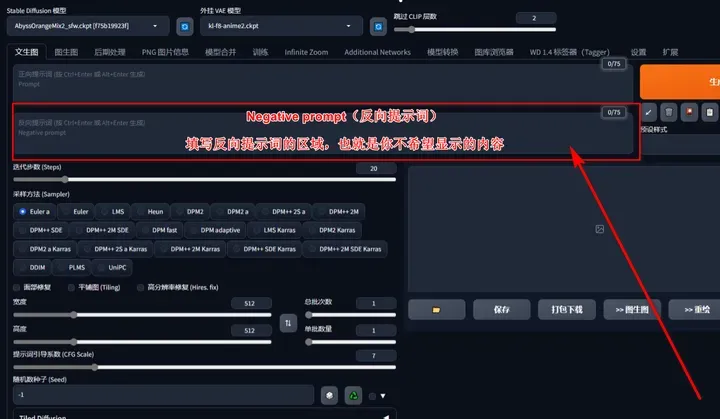
Negative prompt(反向提示词):
这里填写你不希望出现的画面内同
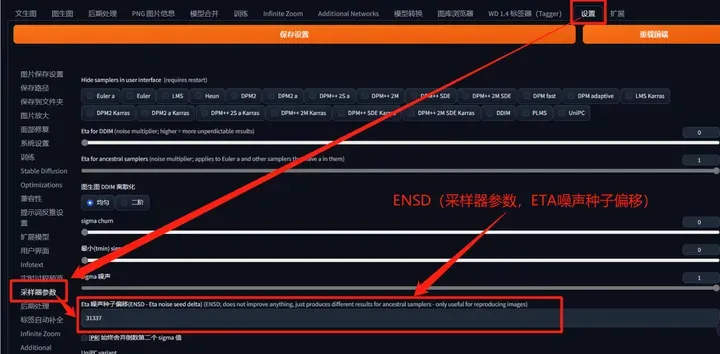
ENSD(采样器参数,ETA噪声种子偏移):
有着固定初始值的作用,是确保在还原图片时与原始图片保持一致
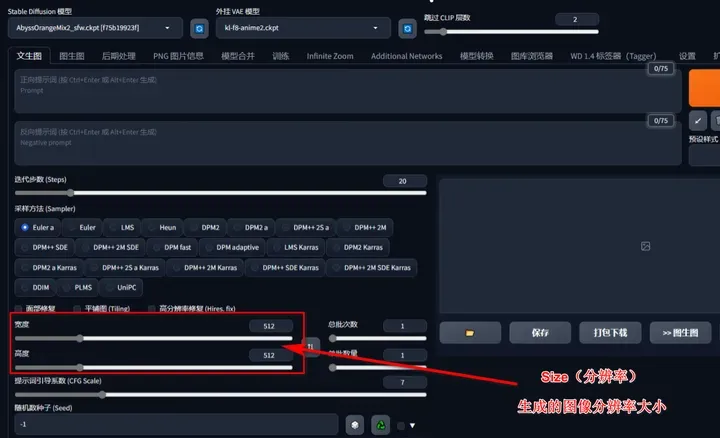
Size(分辨率):
指生成的画面分辨率大小
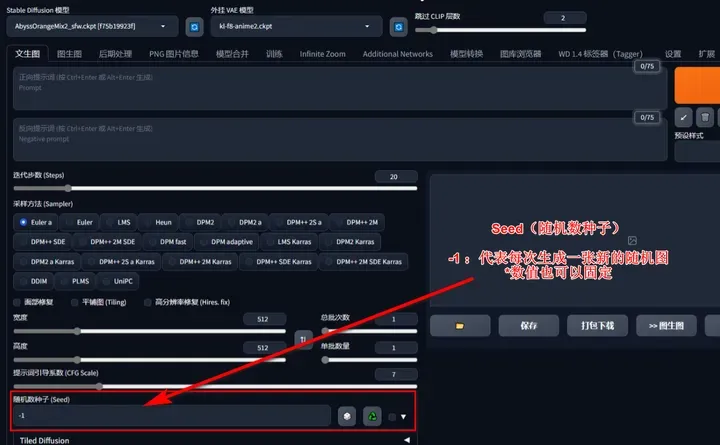
Seed(随机数种子):
Seed是用于生成数据的初始源,因此在相同的Seed下,其他参数保持不变的情况下会生成相同的图片(可以将每个种子视为不同的全噪声图片,每一步的采样都是为全噪声图片添加细节)。但要注意采样器的eta值。当eta值为-1时,每次使用随机种子,而当eta值为其他固定值时,可以通过调整提示词来微调生成的图片。当复现他人的图像时,需要使用相同的Seed值。
简单理解:”-1“值生成随机新图,“固定值”生成指定图
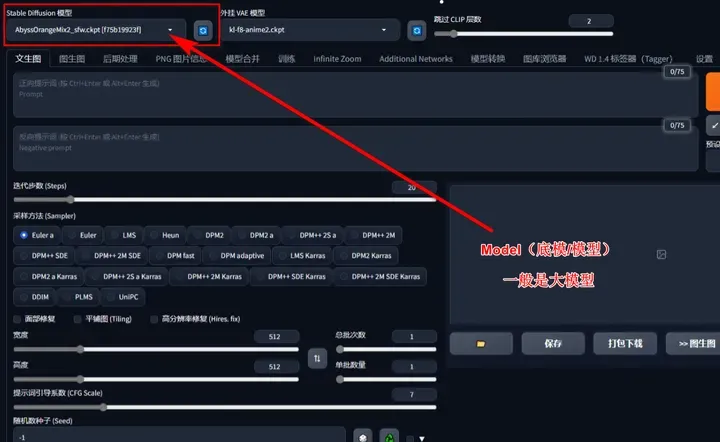
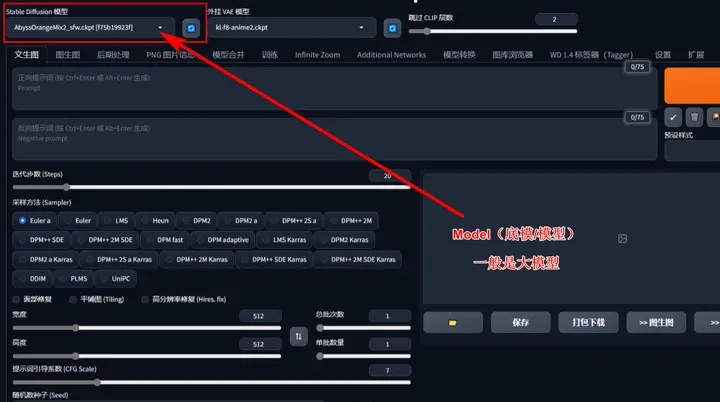
Model(底模/模型):
这里一般选择已经训练好的大模型,也称为“底模”,一般网络上有下载。
H站(抱脸):Hugging Face
C站:Civitai
若是部分网站对网络有所要求,若是进不去需优化自己的网络哦
Steps(迭代步数):
首先,AI绘画的原理是通过随机生成一张噪声图片。然后,逐步向正负tag语义靠拢,每一步都是小幅度的移动,直到达到预期的迭代步数。一般来说,迭代步数被设置为20,这样可以保证每一步的移动更小和更精确。
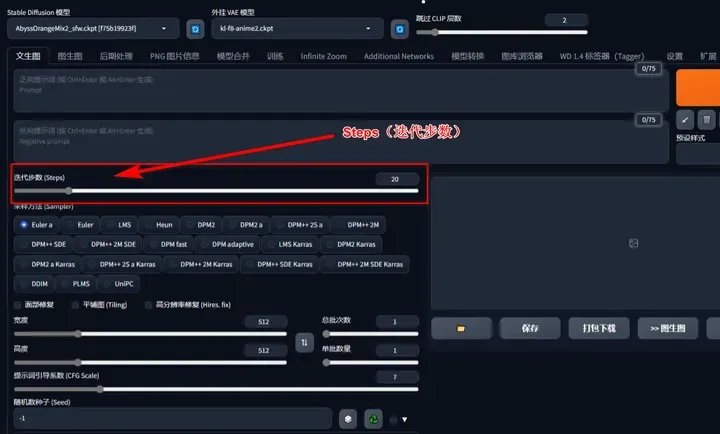
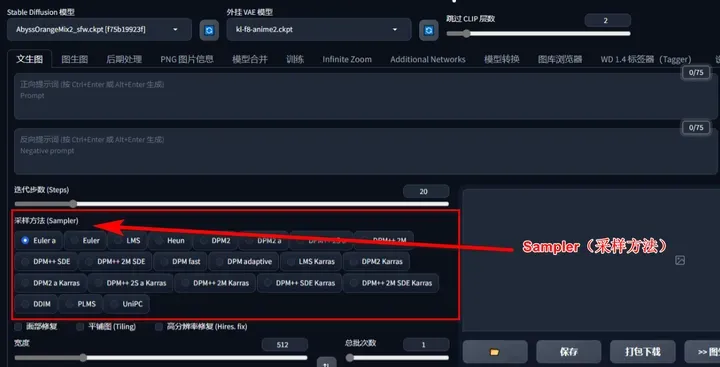
Sampler(采样方法):
是一种生成图片的算法,一般选择带“+”好的比较好,这些是经过优化过的。不过,具体的使用最好还是根据模型作者提供的建议来使用。
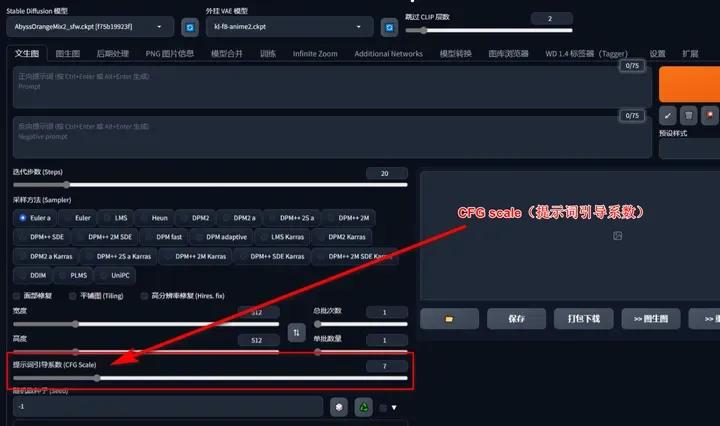
CFG scale(提示词引导系数):
CFG Scale是一个控制提示词与生成图像相关性的数值。它可以在0到30之间进行调整。根据日常出图的经验,将CFG Scale设置在5到15之间是最常见且最保险的选择。过低的CFG Scale会导致图像饱和度降低,而过高的CFG Scale则会产生粗糙的线条或过度锐化的图像,甚至可能导致图像严重崩溃。
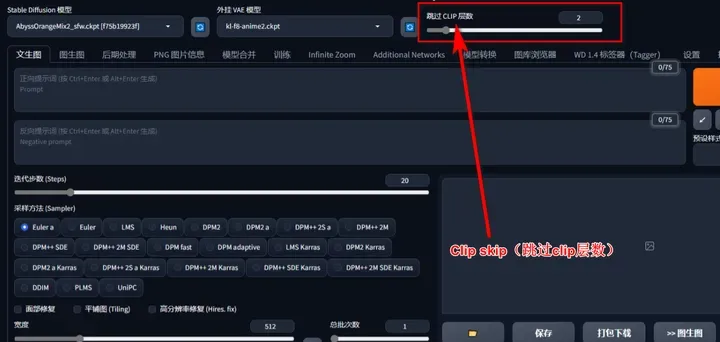
Clip skip(跳过clip层数):
CLIP过程是通过计算文本和图像之间的相关性来实现的。因此,如果跳过太多的步骤,文本对生成图像的匹配准确度会逐渐降低。
Model hash(底模/模型哈希值):
一般我们下载下来的模型是可以重命名的,但是一旦重命名后就不太好区别了,这个时候可以核对哈希值来确认
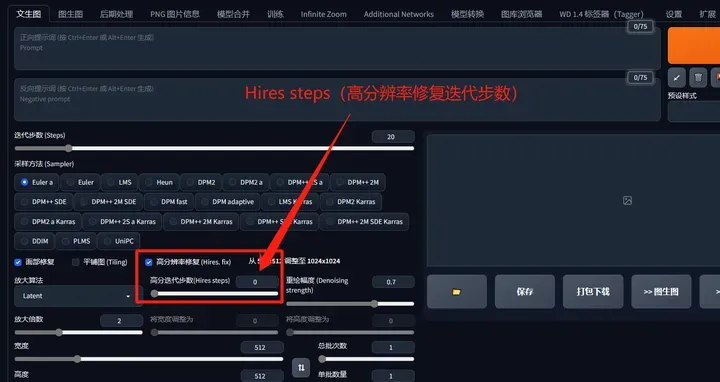
Hires steps(高分辨率修复迭代步数):
通过使用算法,AI可以首先在较低的分辨率下对图片进行部分渲染,然后将其提升到高分辨率,并在高分辨率下添加细节。可以将这个过程类比为采样迭代步数的理解,其中0表示保持原来的步数不变。
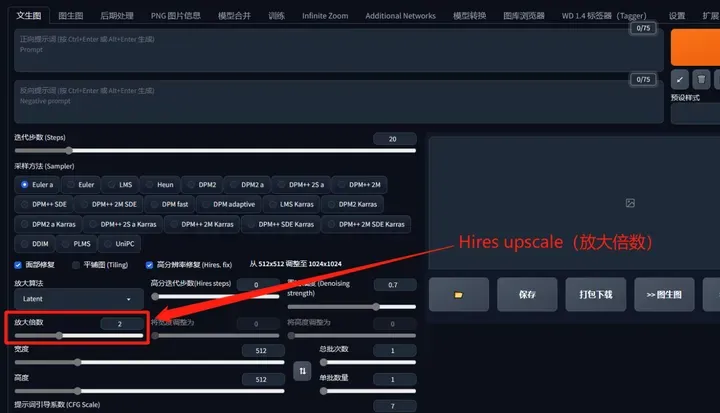
Hires upscale(放大倍数):
指在原有图像的宽度和长度上进行放大的倍数。需要注意的是,这种放大操作需要更高的显存来支持。
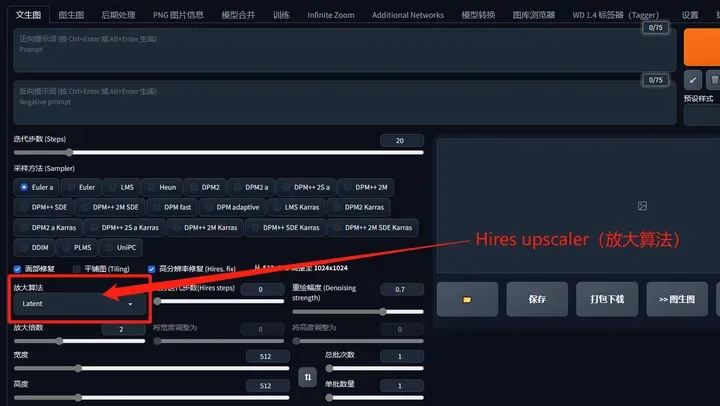
Hires upscaler(放大算法):
如果不知道选什么,一般无脑选ESRGAN_4x,各类网站都是这么说的,照做就行,哈哈
Denoising strength(重绘幅度):
放大后修改细节的程度可以通过一个从0到1的数值来表示,数值越大,AI的创意就越多,同时也会使生成的图像越偏离原始图像。
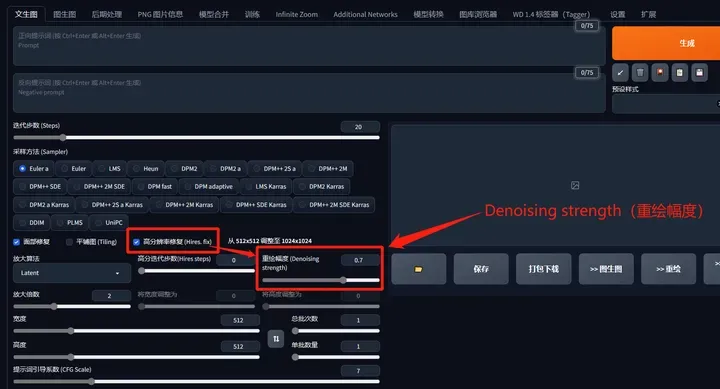
现在再去学习别人的生成参数是不是轻松了许多呢
五、下载学习
SD WEBUI传送门:
http://ai95.microsoft-cloud.cn/d/9289114-56534526-28c22a?p=ai95
(统一访问密码:ai95)持续更新……
文章出处登录后可见!