遥感多模态
参考:From Single- to Multi-modal Remote Sensing Imagery Interpretation: A Survey and Taxonomy
Keywords:multimodal remote sensing
文章目录
- 遥感多模态
Abstract
本文强调了单模态和多模态遥感影像判读之间的关键差异,然后利用这些差异来指导我们对级联结构中多模态遥感影像判读的研究。最后,对未来可能的研究方向进行了探讨和展望。
Introduction
多模态遥感图像解译(MRSII)是地球观测和计算机视觉领域的一个新兴方向。它具有挑战性,具有比单模态更大的应用价值。从特性的角度来看,至少有四个原因:
1)图像数据是多光谱的(a)和(b)是同一场景中的一对图像,( c )和(d)是同一区域来自Houston dataset
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MeUgNLHq-1673610283276)(/imgs/2023-01-05/qRSFNJX8ifBx36NS.png)]](https://aitechtogether.com/wp-content/uploads/2023/07/0ae3053d-2230-468b-8caf-24e490ef214a.webp)
2)同一区域的多模态观测提供了来自不同视角(如三维空间、距离和高度)的互补信息。对于一些地球观测应用,如城市土地规划、三维重建、森林分类等,我们需要多模态传感器从多个角度观察场景。但由于受计算资源的限制,观测角度越多,计算复杂度越大。
3)各模态尺度不一致。 表1列出了一些著名卫星的参数。由于MRSII的多尺度特性,要求系统具有处理不同分辨率图像的自适应能力。例如,在WV-3图像中,一架飞机可能会占用大约400像素,但在高分2图像中只占用150像素。这种情况给单模态模型带来了巨大的挑战,特别是当同一对象之间存在显著的尺度变化时。

4)多模态图像为地球监测提供了时间维度。多时间变化检测、数据融合、基于域适应的分割/检测等一系列具有广阔应用前景的时间任务应运而生,加速了遥感影像解译向多维度、多任务的方向发展。
Taxonomy
本文主要分为五类:即多源对齐(第3节)、多源融合(第4节)、多模态表示(第5节)、跨模态翻译(第6节)和联合学习(第7节),以应对MRSII挑战的核心技术。

1)Alignment:图像配准,遥感影像分析,图文检索和匹配
多模态对齐提供不同模态信息的对齐和匹配,旨在发现模态之间的空间和时间联系。例如,来自不同传感器的图像之间的图像配准和检索,以及图像与文本之间的检索和匹配。这些方法的重点是将不同的模式映射到统一的语义空间,并通过距离度量它们的相似性
2)Fusion:全色与多光谱图像融合再进行目标检测
MRSII中的多源融合旨在将两个或多个遥感数据或其他观测数据与相同复杂场景的互补信息结合起来。 通过结合它们的信息进行处理、分析和决策,可以获得用于目标预测(分类或回归)的更高质量的数据。例如,将高分辨率全色图像与多光谱图像融合,可使多光谱图像的空间分辨率提高数倍。
3)Representation:三维重建
一项基本任务是将图像编码到用于下游任务分析的高级特征空间中。类似地,在MRSII中 ,representation负责将多模态信息提取并抽象为高级特征向量,它利用不同模态特征之间的互补性,消除冗余,以学习更好的特征。例如,为了对城市分类和三维建筑重建进行编码,将数字表面模型(Digital Surface Model, DSM)和真正射电像相结合,送入相同的表示空间。
4)Translatioin:SAR转全色,模态的转化
一个新出现的挑战是将信息从一种形式翻译成另一种形式。该任务的方法倾向于生成模型,预测的目标是开放的或主观的。生成的模态与源模态是异构的。例如,我们使用SAR数据生成全色图像。
5)Co-learning:迁移学习
对于一些复杂的场景,一个单模态传感器可能是不足的,因此需要另一个丰富的模态来辅助它的学习。在某些需要域适应或迁移的情况下,跨模态信息可以利用联合学习来辅助学习。例如,利用资源丰富的光学图像特征进行预训练,然后对稀缺的SAR图像特征进行学习,可以提高模型的性能
一个优秀的多模态模型通常需要两种以上技术的组合。例如,多模态表示可以用作对齐或转换的骨干模型。
1. Multi-source Alignment
遥感多源对齐的目的:
将原始源与目标源进行匹配,在异构数据之间找到相应的显式和隐式关系。
例如,给定两张来自不同传感器的包含相同复杂场景的图像,我们将匹配或检索它们的子组件(sub-components)。多源对齐是MRSII的一个重要分支
相关工作包括图像配准[12-14]、变化检测[18,27 – 29]和跨模态检索[26,30,31]。
根据数据源的对齐维度,我们将多源对齐方法分为三种:1)空间对齐,2)时间对齐,3)交叉元素对齐。 表2列出了这些方法的不同。


1.1 Spatial Alignment
应用:图像配准,变化检测,土地分类,空间对齐主要是图像对齐的过程
即找到来自同一复杂场景的当前图像与参考图像之间的像素空间映射关系,从而实现不同图像源的几何同步。这些图像通常由不同的传感器在不同的时间和视点拍摄[10,11]。
根据训练样本类型的不同,空间对齐框架可分为三种类型:无监督方法、半监督方法和监督方法。
- Unsupervised methods没有任何事先训练的样本,需要直接对数据建模。它们是第一批应用于多模态对齐的方法,通过构建一系列范式并从这些范式中识别它们潜在的类规则来聚类同一类特征。
无监督方法的应用方向是图像配准以及土地覆盖分类,将不同传感器在不同时间捕捉到的同一场景的两张或多张图像对齐。 - Semi-supervised method是另一种空间对齐框架,它利用大量的未标记和标记数据来执行MRSII[37,38]。在[39]中,MAPPER被用来进行光学数据和偏振SAR数据的多重对齐,用于土地覆盖和当地气候的半监督分类。半监督研究利用半监督对齐方法从潜在空间获取具有多时间、多源、多传感器和多角度特征的图像的线性可逆变换。
Hong[40]提出了一种可学习流形对齐框架,直接从数据中学习joint graph structure。采用半监督学习方法对多模态图像进行对齐,可以减少标注人员的工作量,获得较高的对齐精度。因此,它受到了遥感界的广泛关注。 - Supervised methods根据来自标记数据集的输入和输出结果之间的关系训练一个最佳模型。在监督学习中,训练数据既有特征又有标签,通过训练,机器可以自己找到特征和标签之间的联系。
由于数据量大,一些方法[41-43]使用非深度学习架构。随着深度学习的发展,监督方法已经成为空间对齐的主流。在[44-46]中,作者设计了生成网络来生成耦合的光学和SAR图像,并使用深度匹配网络进行匹配。Zhang等和Fan等[47,48]提出了一种用于<多模态图像配准的孪生神经网络,该网络采用了使正和难负样本(hard negative samples)之间的特征距离最大化的策略。
1.2 Temporal Alignment
应用:变化检测,时间对齐主要针对长序列遥感影像分析。
与空间对齐相比,它负责寻找来自同一子实例的不同模态信息的子分支或元素之间的对应关系。如图8所示,给定来自不同传感器的系列图像,时间对齐面向场景中随时间变化的实例,并可进一步用于下游任务,如区域规划、作物、植物分类等。因此,时间对齐对算法对时间相关性和空间变化的敏感性提出了挑战。
目前的时间对齐主要是针对一对a pair of 多模态图像之间的元素对齐。 根据网络结构的对称性将方法分为:对称结构、非对称结构。
如图4对称结构中所示,不同数据源的子网络结构是相同的体系结构,各模态特征之间存在交互作用。在非对称结构中,网络结构是不对称的,每一边的编码器层和投影层都不同。
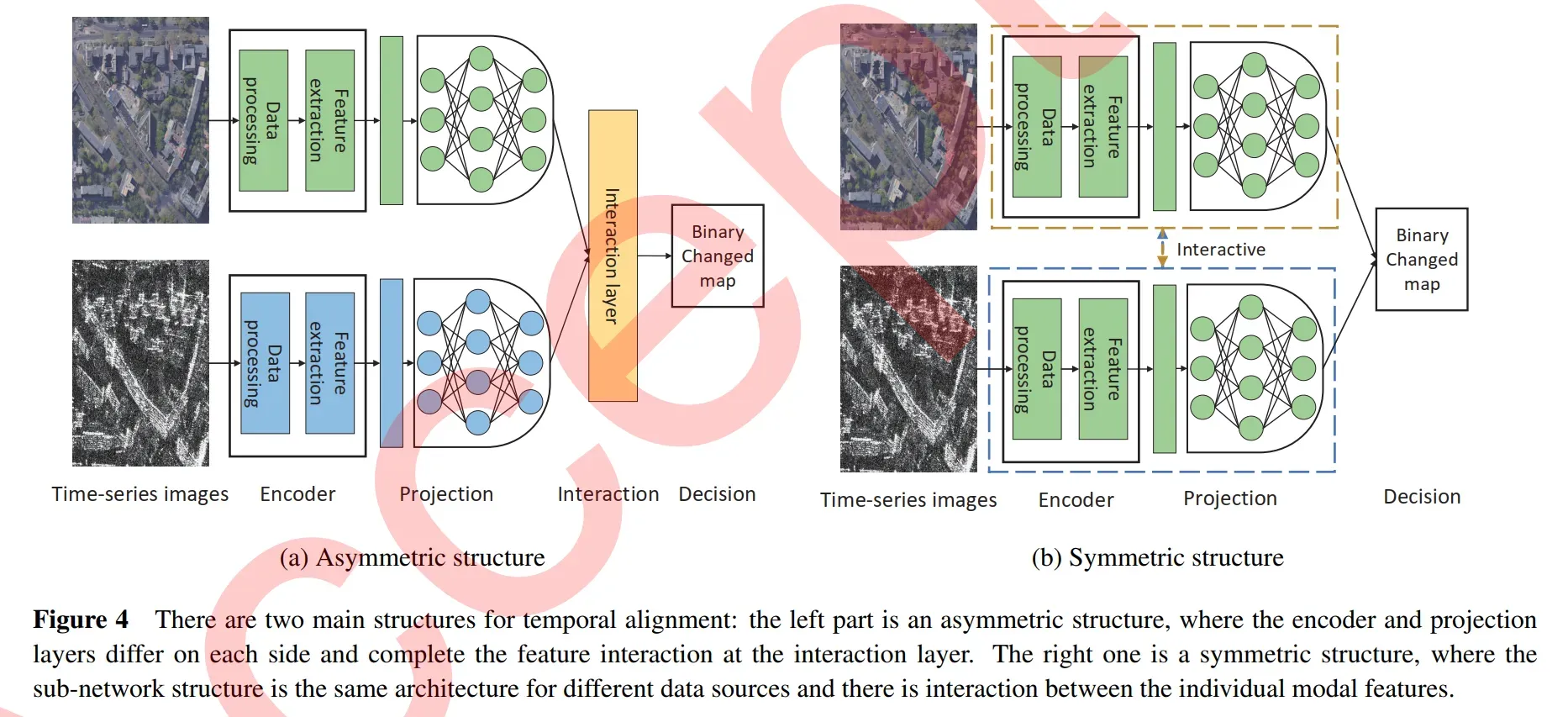
- Symmetric structures做了什么事情?
Symmetric structures更倾向于通过图网络结构学习和匹配不同模态信息之间的属性。 在[50]中,提出了一种基于图的数据融合算法,用于数据驱动的半无监督变化检测和水稻作物生物量估计。Sun等人[19-21]构造了一个鲁棒的k近邻图来学习每个图像的结构,并使用图映射来比较同一图像域中的图。Yang等[51]提出了一种用于异构图像变化检测的深度金字塔特征学习网络 - Asymmetric structures做了什么事情?
Asymmetric structures更强调不同模态信息之间的特征,用不同的编码器学习各种模态特征,然后用解码器进行融合解码[52-54]。
1.3 Cross-element Alignment
应用:建筑足迹划定、更新和城市土地利用测绘,可扩展到VQA和IR
Cross-element Alignment做了什么事情?
跨元素对齐旨在实现遥感图像和非遥感模态之间的全局或子组件对齐。可以进一步用于图像检索和视觉问题回答任务。
根据跨元素对齐的目的,我们将其分为两类:场景增强和人机交互。
第一类是融合和对齐非观测模态,以减少观测误差,获得更全面和准确的地表数据。
第二类是通过将其他模式与图像对齐,实现协同检索,提高图像检索速度,从而更好地方便人员查询和搜索。
非观测特征可以提供遥感场景的增强表示。它们具有与空间对齐相同的目的,在模态中匹配和对齐相同区域,以用于下游任务。在[55-58]中,作者通过寻找实体之间的最佳匹配,将Openstreetmap与遥感图像相匹配,建筑足迹划定、更新和城市土地利用测绘。并且[59-62]结合了生物量、植被覆盖和全球电离层图估计的地基数据,显著提高了单模态估计的准确性和置信度。此外,许多研究人员将GNSS[63-65]、GIS[66-68]、水文气象学[69-71]和其他信息进行对齐,以实现在交通统计、地图绘制、动物行为、环境相互作用等方面的应用。
以下是CV与遥感结合的多模态
为了更好的人机交互,研究人员将语音和文本模式与遥感图像相结合。在[31,72-74]中,作者讨论了基于图像和语音的遥感标签标注之间的多标签跨模态信息检索问题,通过学习输入模态的判别共享特征空间的深度神经网络体系结构,适合于语义一致的信息检索。[24-26]设计了一系列图像-文本匹配网络,以探索遥感图像与其各自自然语言描述之间的相关性。
1.4 Related work and Challenges
传统模态对齐更侧重于跨元素对齐,检索和匹配两个或两个以上模态[9]之间实例关系的子组件,如图像+文本[75-77]、视频+音频[78-80]、视频+文本[81-83]等。
在多源对齐中,存在以下挑战:
1)图像规模过大,包含的实例子组件数量远远大于自然场景。
2)相关数据集中的数据量太小,使得有监督模型难以进行图像对齐检索,在训练过程中容易出现过拟合问题。
3)实例的子组件复杂,形状和方向任意,即使是同一区域的实例也会因为成像而产生失真或缺失。
2.Muti-source Fusion
主要是遥感影像的空间分辨率和光谱分辨率影像融合。
我们将多源数据融合细分为三个级别:1)数据级融合,2)特征级融合,3)决策级融合。 三种体系结构的概述如图5所示
数据级融合是对原始或预处理数据的直接计算处理,这些数据可以包含数据源最原始的细节。主要目的是提高数据的质量,即分辨率、对比度、完整性和其他指标。
特征级融合是在从目标场景(原始传感器数据)提取特征信息之后的步骤进行的。它融合提取的特征,生成新的特征,用于后续复杂场景的解释。
决策级融合需要从源图像中提取目标特征,并对特征进行滤波和分类,最后根据特征的类别进行融合。它主要解决不同数据的决策结果不一致的问题,从而从各种传感器数据中获得更可靠的决策知识。这三种融合策略可以联合使用,多层级融合是一个前沿的研究方向。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4mF1AWjF-1673610283279)(/imgs/2023-01-06/8RyU1ueokP815jgg.png)]](https://aitechtogether.com/wp-content/uploads/2023/07/e358a143-2a41-428a-8d34-c7211a34dd0f.webp)
本文将遥感多源融合分为三类:同质数据融合、异构数据融合和遥感与其他类型数据融合。

2.1 Homogeneous Data Fusion
同构数据融合是指来自相同成像方式的传感器之间的数据融合,如高分辨率全色图像和多光谱图像之间的数据级融合。
主要目的:提高图像的分辨率,并减轻空间、光谱和时间分辨率之间的相互(制约)联系。同时,通过数据级融合,对图像中的阴影、云层等噪声进行修复和滤波,获得最佳的时间、空间和光谱分辨率。除了全色-多光谱融合[104-106]外,还包括同模态融合[107-109]、全色-高光谱融合[110-112]、多光谱-高光谱融合[113-115]等。
Homogeneous Data Fusion分为两种方向:基于空间参考和基于时空参考。
基于空间的方法通过对图像进行空间对齐,聚焦于空间上一致的图像对,建立特征关系,实现数据融合。
基于时空的融合方法更侧重于从具有多时相的低分辨率数据推断出特定时间的高分辨率数据。该算法利用一系列时间图像构建时间和空间维度关系,利用优化约束算法实现融合。
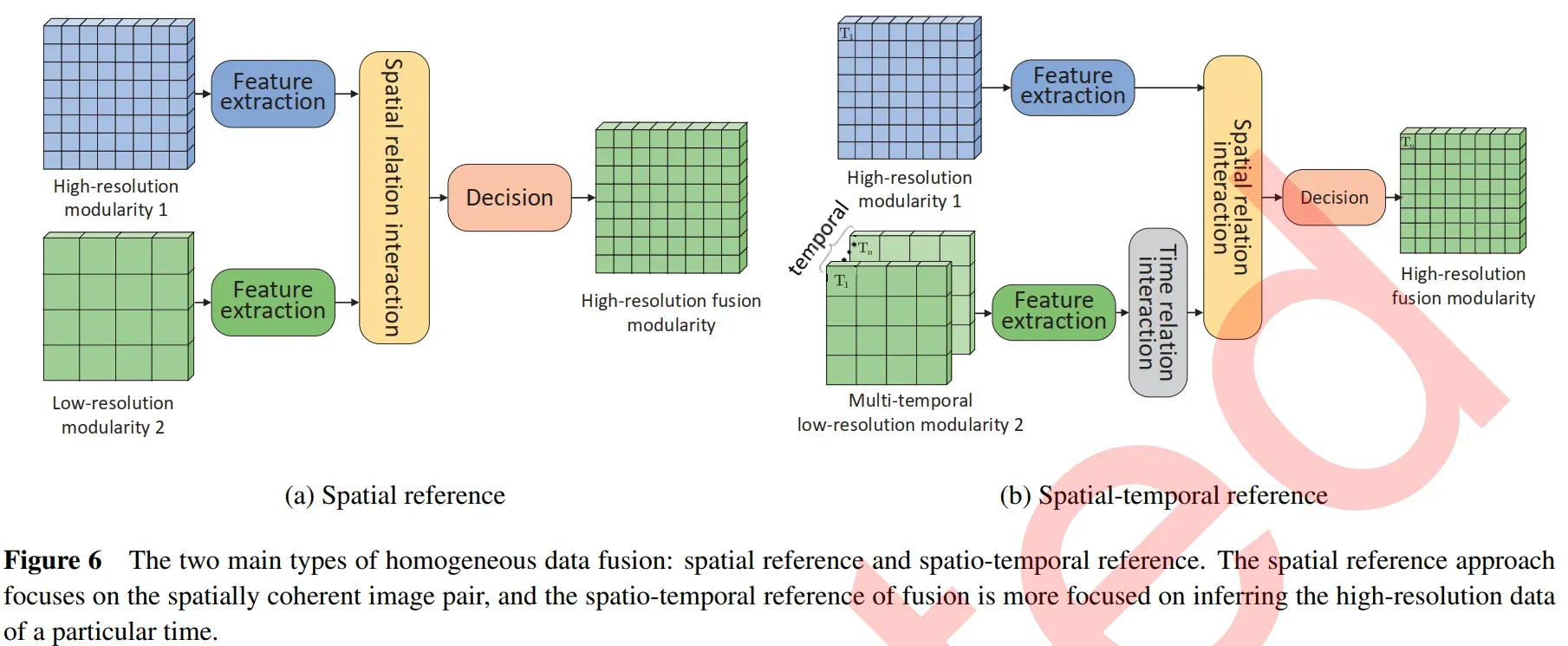
2.1.1 spatial reference
我们确定了三种类型的空间参考算法:全色锐化,线性优化和基于深度学习
(Panchromatic sharpening, Linear optimization, and deep learning-based.)
全色锐化是一种通过融合全色和多光谱图像来获得高空间和光谱分辨率图像的辐射变换。
线性优化主要是通过添加线性约束来实现同模态融合,从而获得最优解的重建图像。
- Panchromatic sharpening
Panchromatic sharpening 常用的全色锐化方法可分为两大类:成分替换和多分辨率multi-resolution。
成分替换模型将图像投影到新变换的空间中,用高空间分辨率的图像替换包含空间信息的成分,并将将其反变换到原空间,得到空间增强的数据。
多分辨率模型将原始数据分解成不同分辨率的图像进行融合,最后进行反变换得到融合后的图像。
成分替换法(CS)的先驱是IHS变换[116-119]和主成分分析(PCA)[120-123]。
IHS变换被广泛用于融合图像,因为它能够分离出RGB图像中的H和S分量中的光谱信息,同时分离出I分量中的大部分空间信息。PCA主要是通过线性变换将数据投影到新变换的空间中,第一主成分沿方差最大的方向变换,保留了原始数据的大部分信息,因此第一主成分进行替换。 这些方法的另一种替代方法是Gram Schmidt方法(GS) [124-126]。该方法的本质是Gram-Schmidt正交法,它将一元空间中的一组线性无关向量变换为一组正交向量。此外,还有Brovey变换(BT)[127, 128],张量因子分解[129,130]等。
由于CS方法能够以较低的计算成本有效地提高空间分辨率,目前仍是研究的重点。 基于GS自适应(GSA)、广义IHS (GIHS)[131]、GIHS自适应的方法(GIHSA)[124]和基于比值图像的光谱重采样(RIBSR)[132]已经被广泛研究,减弱了多光谱融合过程中的光谱失真问题。
多分辨率分析(MRA)将多模态数据分解成多个分量,当这些分量被重新组合在一起时,就会生成更高分辨率的图像。
对图像进行分解和融合以获得更高分辨率的图像是MRA的核心。 每个组成部分理想地将图像分解为物理上有意义和可解释的部分。
常用的MRA方法包括高通滤波法(HPF)[120,133]、小波变换[84,85,134]、拉普拉斯金字塔法[86,135]和曲波变换法[136-138]。
MRA方法比CS方法能更好地保持光谱信息。但是,如果多模态数据没有严格对齐,在这种情况下,在高频谱细节注入(high-pass detail injection)存在的情况下,融合产品可能会发生空间失真, 这通常是由振铃或混叠效应、原始偏移、轮廓和纹理模糊引起的[124]。
- Linear optimization
线性优化模型将数据融合问题归结为其线性最优解
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-tXEsAgmg-1673610283279)(/imgs/2023-01-12/TnnM13KtudndFePl.png)]](https://aitechtogether.com/wp-content/uploads/2023/07/d424a616-3de5-4f0f-87cf-8f4e35eab3c3.webp)
根据求解的原理,可分为光谱分解法、贝叶斯概率法和稀疏分解法(spectral demixing, Bayesian probabilistic, and sparse demixing methods)。
光谱分解将混合像素分解为一系列的组成光谱(end-members)和一组对应的分量(abundances), 并进行线性求和和重构。
贝叶斯概率理论将待融合的数据视为观测值,将融合的数据视为未观察到的真值。 它通过计算真实值在给定观测值的情况下出现的概率来求解融合过程中的参数值。该算法通过在观测值下计算真实值出现的概率并使概率最大化来求解融合过程中的参数值。
稀疏分解方法将多模态数据分解为字典矩阵(dictionary matrix)和稀疏系数矩阵,并添加稀疏约束对稀疏系数进行求解,得到融合后的数据。
- Deep learning-based
基于深度学习的算法专注于构建同一区域内不同图像之间的非线性关系。最常见的方法是基于卷积神经网络(CNN),它通过放弃全局连通性来解决权重数量极其庞大的问题[139-141]。有两个代表性的工作,Scarpa等人[142]设计了轻量级CNN和目标自适应使用方式,以确保在数据源不匹配的情况下也能获得良好的性能。在[115]中,作者提出了一种3D-CNN来融合MS和HS图像,以获得高分辨率的高光谱图像。
空间分辨率研究重点仍是成分替换,IHS用于图像融合,多分辨率分析的核心是图像的分解和融合
2.1.2 Spatio-temporal reference
基于时空的方法与基于空间的方法在空间关系构建中的方法本质上是相同的。因此,我们将研究重点放在时间关系的建构上。
早期的工作集中在线性优化模型。时空自适应反射率融合模型(STARFM)是Gao等人[143]提出的一种预测时空融合的有效方法。基于STARFM,一系列时空参考算法陆续被提出,如ESTARFM [144],STRUM[145],USTARFM[146]等。Xue等人[147]提出了一种组合时间序列中的时间相关信息的贝叶斯统计算法,他们将融合问题视为具有最大后验(MAP)估计量的估计问题来获取融合图像。在基于深度学习的算法中,主要是寻找空间中的非线性关系,构建时间关系相对较少。
2.2 Heterogeneous Data Fusion
异构遥感数据融合是指来自不同成像方式的传感器之间的融合,如光学-雷达、SAR-多光谱、SAR-高光谱数据融合等。由于不同传感器之间的成像机制差异过大
异构数据融合更适合于特征级、决策级的融合,如特征分类、变化检测、参数反演等
根据优化方法的不同,异构数据融合我们将其分为基于特征堆叠的方法Feature stacking-based、基于子空间的方法subspace-based和基于深度学习的方法。
在基于特征堆叠的方法中,我们将辅助传感器提取的信息叠加到图像的每个像素上,得到包含所有模态信息的特征向量。
基于子空间的方法将所有信息投射到一个低维子空间中,然后进行特征融合。
基于深度学习的方法学习系统输入和输出之间的非线性关系。这些方法能够较好地刻画不同分辨率图像之间的非线性关系,具有很强的可移植性。
2.2.1 Feature stacking-based
基于特征堆叠的方法是异构融合最简洁的实现。
如何实现?该策略在相同的结构中过滤和堆叠各种源数据。例如,将从LiDAR数据中提取的高度和强度特征叠加到多/高光谱图像的光谱波段中,并对复杂场景中的每个像素形成扩展的特征向量
形态学轮廓、属性轮廓和消光轮廓被广泛应用于特征提取和过滤,以充分利用异构数据中有辨识度的特征信息。这些方法[149-151]概念简单,计算效率高,通常用于异构数据融合,并提供高质量的融合结果。
缺点:样本的特征维数增多和高计算复杂度
2.2.2 Subspace-based
基于子空间的方法避免了后续分类任务的维数灾难,提高了计算效率。它们将异构数据中的特征表示为低维子空间中的特征,以减轻后续任务的压力。在原始的子空间模型中,子空间的基准和融合特征都是未知的,如何估计它们是子空间模型的核心问题。
许多基于子空间的方法的早期工作使用了经典的IHS变换[152]或PCA方法[153,154]。这些方法可以有效降低特征维数,提高信噪比,减少计算量,提高异构数据融合问题的分类精度。
2.2.3 Deep learning-based
深度学习提取的特征一般不受样本的非线性分布的影响,对复杂场景具有鲁棒性,可以获得更好的融合结果和分类精度。
缺点:通常需要大量的标记样本进行训练,且遥感场景的标记样本通常难以获取,这在一定程度上限制了深度学习方法在异构数据融合中的应用。
2.3 Remote Sensing And Other Type Data Fusion
将遥感数据与全景采集数据、景观图像以及陆地、大气、水文等数据进行融合,为大规模复杂场景的数据感知提供了更精确的观测。
遥感数据可以为场景提供更精确的初始观测和边界条件,然后自动连续地将它们和其他数据进行调整,从而将模拟误差降低到高精度、空间连续的地表数据。这种融合方法是当前发展的一个重要趋势。
遥感和地面观测是获取对地观测数据的两种重要途径。遥感可以提供大尺度的区域观测,但由于其成像过程复杂,易受环境干扰,观测精度往往难以保证。地面观测质量高,但观测点稀疏,难以获得全面的观测。
因此,遥感与地面观测数据的融合 引起了众多研究者的关注[90-93]。同时,遥感数据与大气数据、流体动力数据的融合可以进一步降低模拟误差,可用于水文气象[155,156]、植被[157,158]和大气信息[159,160]的协同分析。
Remaining problems
在多模态融合中,同构数据融合技术已经非常成熟,异构数据融合有待继续研究,存在的问题具体如下:
1)数据来源不同
需要解决数据对齐和保留有效信息的同时去除冗余信息
2)观察角度不同
在与遥感图像融合时,需要解决数据特征对齐
3)不同分辨率
需要解决不同分辨率的问题,特别是在异构数据的融合中,由于数据类型的巨大差异导致了这一问题更加突出。
4)未知观测场景
需要解决提高鲁棒性来应用于更多的场景。
遥感场景是不可预测的,现有模型往往只适用于单一场景,如城市、森林、沙漠、海洋等。由于观测场景往往存在未知情况,因此提高模型的鲁棒性以应用于未知的观测场景是未来的发展方向之一。
3.Mutimodal Representation
Representation做什么?
使用机器学习方法将原始数据转换为计算机可以识别和处理的数学表示,进一步提取有用信息,以便用于分类或其他预测任务
遥感场景的多模态表示学习存在的问题?
1. 如何抑制来自不同传感器的不可控噪声
2. 如何组合来自异构数据源的小样本数据
3. 如何处理不同数据源之间的成像透视图
4. 如何解决某些模态下的缺失数据
多模态表示学习主要分为三类:
- 联合表示
- 协同表示
- 编码器-解码器表示

常用遥感图像的表示学习主要是基于CNN,利用在自然场景(如LeNet[174])上进行了预先训练的模型例如VGGNet [7], GoogleNet[175]和ResNet[6],从而获得比从零开始训练更好的性能来进行迁移学习。
使用Transformer 与其他模态数据一起进行训练(例如,文本数据的word2vec[165]、Glove[166]和BERT[167]以及wav2vec[168]、PASE[182]和Mockingjay[183]),通过使用来自其他模态的表征学习模型进行训练,可以大大提高多模态表征学习的性能。
3.1 Joint Representation
联合表示旨在将各种单模态特征投射到一个共享的语义子空间中,以减少模态之间的异质性,挖掘特征之间的互补性,从而学习更好的特征表示
相关的算法将来自不同传感器的图像以及其他模态信息表示为特征向量(张量),缩小异质性差距,获得互补的特征表示。
后期简单看一下这部分论文
- Detection部分:
Manish Sharma等[184]和Yang等[185]通过学习红外传感器的特性,扩展RGB图像的表征能力,提高了遥感和无人机图像在各种天气条件下的目标检测精度。Flynn等[186]和Oliveira等[187]通过光学图像与红外或热成像图像的联合表示,使用航空视频进行人员检测和随时间的跟踪检测,获得了较高的检测精度。Breckon等人[188]引入了一种实时多模态目标检测算法,该算法结合了来自多个自主平台(地面和空中)部署网络的可见光波段、热波段和雷达图像,自动检测人和车辆。 - Classification部分:
Audebert等人[189,190]研究了激光雷达和多光谱数据的早期和晚期联合表示,发现早期融合允许更好的联合特征学习,但代价是对缺失源的灵敏度更高,而晚期融合使得从模糊源恢复错误成为可能。Li等人[191]提出了一种多模态双线性融合网络来提取光学和SAR图像的深度语义特征图,并对联合表示进行双线性集成。Poliyapram等[2]提出了一种基于深度学习的端到端点式激光雷达和光学图像多模态融合网络,通过整合航空图像特征对航空点云进行三维分割。Jeong等人[192]提出了一种基于多模态传感器的语义三维映射系统,该系统使用三维激光雷达与光学相机相结合的数据。
后期简单看一下这部分论文 - 多分辨率同构数据的联合特征学习也是联合表示的一个重要研究方向。在不同分辨率的图像中,同一物体具有不同的尺度和感知场,并且由于不同传感器的成像方法不同,同一物体内存在色差,这对模型的适应性和鲁棒性提出了更大的挑战。多分辨率联合学习在作物分类[193,194]、目标识别[195,196]、土地覆盖分类等任务中具有广泛的应用和研究价值。
3.2 Coordinated Representation
协同表示旨在每个模态单独学习其单独的表示,然后通过统一的约束来协调它们。
这类算法更强调不同模态元素的相似性和互补性。它试图在协调子空间中学习每个模态的独立但有约束的表示。
协同表示主要分为两类:complementary methods 和 similarity methods
互补方法主要关注模态之间的差异和互补信息,通过比较差异信息来补充和增强复杂场景信息的表示。
相似度法更关注不同模态之间的相似度,期望同一语义相关模态之间的距离尽可能小,不同语义之间的距离尽可能大。
3.2.1 Complementary methods
互补方法使得协调空间能够发现多模态变异性,以补充融合表示
如何互补?
多光谱和雷达的特征拼接和互补,例如,提取多光谱图像和Lidar特征,在更高维度上拼接和相互作用,获得互补的融合特征,用于土地覆盖分类[88]。在[1]中,作者将来自谷歌地图的俯视图和来自谷歌街景的每个城市对象的地面图像(侧视图)结合起来,以获得与城市对象相关的互补视觉信息,以增强对城市土地利用的理解。
3.2.2 Similarity methods
除了学习互补性外,利用相似度方法协调学习子空间中各模态相同元素的相似度也是协调表示的一个重要分支。
如何相似度匹配?
使用局部和全局特征进行度量。
Ye等人[41,200]通过基于SAR图像与激光雷达数据的全局和局部特征的特征表示进行相似性度量来进行图像配准。
看一下
在[201]中,Uss等人训练了一个双通道的patch matching CNN检测图像块之间的相似性,并测量它们的相互位移。通过对真实遥感图像的测试,该模型具有较高的识别力和较高的定位精度。
Zhu等[202]的一种基于深度学习的匹配方法是通过光学和红外图像的比较,在目标图像的搜索窗口中搜索和参考图像中给定点对应的点。
3.3 Encoder-decoder Representation
编码器-解码器表示利用了translation的概念。
编码解码工作原理:它首先将信息从一个模态转换为另一个模态的特征表示,然后将它们投影到相同的向量子空间。
例如,给定一幅光学图像,我们的目标是生成相应的SAR特征,或者给定SAR图像生成相应的光学特征。
该方法主要用于某模态的数据比较复杂、有噪声、数据量小或缺失的情况。大多数多光谱图像都受到云的影响,利用SAR图像生成相应的光学特征来恢复受影响区域是当前多模态表示学习中的一个热点[203-205]。在/cite gao2020cloud中,为了重建损坏区域,必须建立生成对抗网络将SAR图像与模拟光学图像相结合。Dai等[206]研究了多时相图像,实现了自训练和门控卷积层,以区分浑浊像素和干净像素,弥补了普通卷积层区分能力的不足。
编码器-解码器的应用:
土地覆盖分类、模态变换、目标检测等。
如何消除多模态的差距?
在[207]中,Hong等人进一步改进了土地覆盖分类的性能,分别使用self-GANs模块和mutual GANs模块学习对扰动不敏感的特征表示,并消除多模态之间的差距,以产生更有效和更健壮的信息传递。
看一下
Liu[208]提出了一种模态转换模型,将稀疏模态的信息转化为丰富模态的特征空间,为多时相图像解译任务提供了坚实的基础。
3.4 Discussion
多模态表示学习分为联合表示,协同表示,编码解码器表示。
- 联合表示更适合不同模态数据均衡,推理过程中需要模态交互共同预测的情况。
- 协调表示中,各模态相互独立但又相互协调,更倾向于评估过程中缺少数据或单模态输入的情况。
- 编码器-解码器表示更关注具有不平衡样本或需要额外模态辅助学习的任务。

4. Cross-modal Translation
由于遥感场景的复杂性和传感器的多变性,遥感跨模态翻译比自然场景的类内(不同图像模态之间)和类间(图像与其他模态之间)翻译更具挑战性。遥感跨模态翻译是遥感领域的一个新兴课题。随着深度学习算法和计算机硬件的发展,在场景图像翻译 sence
image translation[209-212]、遥感图像描述 remote sensing image caption[213-215]等方面都取得了进展。
根据模态的类内和类间关系,我们将跨模态翻译分为跨传感器翻译cross-sensor translation和跨元素翻译cross-element translation两个分支
跨传感器翻译主要是指图像在不同传感器之间的翻译,如全色和多光谱。
跨元素翻译是指图像与其他类型模态之间的翻译。

4.1 Cross-sensor translation
跨传感器翻译存在的问题:
- 很大一部分数据受到云、雾等大气因素的干扰,这些不可控因素大大降低了遥感图像的利用率,增加了处理和训练的难度。例如,在Landsat ETM+数据[216]中,约35%的陆地区域被云覆盖,而海洋区域的情况更糟。
- 一些模态图像的数据量相对较小
- 特定时间阶段(季节),可能会出现遥感数据缺失的情况。
因此,在遥感中,对特定时期的特定地点进行成像仍然存在困难。
早期的工作关注的是超分辨率重建(SRR),即从低分辨率(LR)图像中获取超分辨率(SR)图像。
目前流行的SRR方法主要是基于传统算法和基于学习的算法。
我们将标准算法分为基于插值和基于稀疏的表示方法。
虽然基于插值的方法,如双线性或双三次往往生成过于平滑的图像,带有较为明显的人工痕迹,但由于其实现简单,仍然被广泛使用。[217-219]通过引入一系列具有先验知识的优化策略,提高了模型的性能。
基于稀疏的方法增强了线性模型从先验知识中恢复高频信息的能力,如小波变换[220]、耦合稀疏自编码器[221]和外部字典[222],但这些方法计算复杂,需要大量的计算资源。
基于学习的模型试图捕捉图像块之间的共现先验(co-occurrence prior)。深度学习是一种基于学习的基本方法。它通过构建端到端神经网络,如CNN[223-225]、GAN[226-228]、注意力网络[229-231]等,学习并拟合LR和HR图像之间的映射关系。由于它的非线性特性,可以在不需要大量计算资源的情况下恢复高频信息。因此,基于深度学习的SRR成为研究热点。
基于多模态信息的遥感图像去噪方法是一个新的热门课题,它将不同模态的无噪声参考图像作为先验知识纳入去噪目标函数[232,233]。此外,研究人员还对自然气候图像的去噪进行了一系列的研究。在这方面,云的去除已经变得越来越复杂。云的存在是造成光学图像信息缺失的主要因素之一,如何通过其他模态图像生成缺失的信息是一个值得关注的问题。Huang等人[203]提出了一种基于稀疏表示的删除方法来恢复缺失的高分辨率信息。随着GAN网络的发展,越来越多的研究人员采用GAN进行云雾去除,并取得了显著的改进,重建图像更加自然和真实[204,205,211]。
很自然,跨传感器翻译在解决数据稀缺问题时有着广泛的应用。
跨传感器翻译主要有两个方向:跨传感器(模态转换)和跨区域(数据增强)。
跨传感器意味着生成不容易通过资源丰富的数据源访问的数据。[234-236]将SAR转换为光学,用于全天候观测,同时简化SAR图像的观测条件。
跨区域是指从区域的一种风格生成到区域的另一种风格,以达到数据增强的目的。Ji等人[237]提出了一种基于域适应的GAN的方法进行土地覆盖分类。Peng等人[238]设计了一种用于建筑物提取的新型FDANet。
4.2 Cross-element translation
将遥感图像翻译成其他模态信息,或利用其他模态信息对遥感图像的语义信息进行配图并总结图像内容,在跨模态检索[31,72,74]、智能生成[213,239,240]和场景问答等许多领域发挥着重要作用[241 – 243]。跨元素翻译需要模型充分理解复杂的场景,识别出场景的关键组成部分,通过对高层次语义信息的理解和分析,生成标准化、简洁、全面的模态信息来表示场景。
看一下
Huang等人[247]从多尺度特征融合的角度考虑了大尺度场景导致特征缺失或遗漏的问题。Wang等人提出了一种新的词句框架[248],从图像中提取有价值的词,生成格式正确的句子。
4.3 The challenges and differences from nature scenes
多模态翻译的挑战主要体现在两个方面:遥感数据的复杂性和评价指标。
遥感图像往往具有大尺度、高密度和大纵横比的特点。在跨模态翻译过程中,经常会出现信息丢失的问题。因此,它包含的信息比自然场景图像多几倍甚至几十倍。特别是在跨元素翻译中,模型很难保证场景中的所有信息都被描述出来。此外,该问题面临的主要挑战是如何对图像中的关键信息进行过滤和确定,并对其进行精确提取,同时对其进行清晰详细的描述。
另一个挑战是对模型性能的评估。由于模态翻译是一个生成问题,很难通过评价指标自动评价模型的生成质量,甚至利用人工判断也会造成一定程度的主观性。同时,与自然场景不同的是,进行跨传感器的翻译,例如从光学图像到SAR图像或Lidar数据的翻译,需要专业人员进行评估,这进一步增加了评估的难度。
未来可关注的方向点:
- 多模态信息的遥感去噪
- remote sensing image caption
- sence image translation
- 如何通过其他模态图像生成缺失的信息
- 如何对图像中的关键信息进行过滤和确定,并对其进行精确提取,防止大尺度图像信息丢失问题
5.Co-learning
协同学习包括迁移学习,联合训练,小样本学习
帮助一个模态从一个资源丰富的模态过渡到另一个模态,特别是当另一个模态的信息有限或缺乏标记数据、输入有噪声、具有不可靠的标记[9]时。
Transfer learning通过使用在大规模自然场景中训练的预训练模型作为解译模型的骨干。2010年,Yao等人[249]引入了MultiSource-TrAdaBoost和TaskTrAdaBoost,用于从多个来源转移知识。Liu等人[250]提出了一种新的域适应方法用于多模态数据的无监督迁移学习——多核联合域匹配。
Co-training and few-shot learning联合训练和小样本学习也是联合学习的主要研究领域。在[252]中,Hu等人设计了一种联合训练分类方法来处理不明确的观察样本。Qiu等人[253]结合Sentinel-2和Landsat-8图像,以及Global Urban Footprint、OSM和Nighttime Light数据,研究了它们的相关关系以区分不同LCZ分类。对于小样本学习,Rostami等[3,254]将知识从Electro-Optical domains转移到SAR域,以消除对于大量标记SAR图像的需求。Ying等人[255]提出了一种有效的轻量级CNN,可以有效地将先验知识从光学、混合光学和非光学领域迁移到SAR图像的目标识别任务中。
未来可关注的方向点:
- 联合学习面向目标数据较少或缺失的情况,主要体现在数据源缺失和区域缺失两个方面。利用丰富的源数据与目标数据进行辅助或共同学习,是遥感领域的研究热点。
6. Datasets of MRSII

Spatial Dataset
空间数据集中的图像是相互分离的,这些工作的算法更关注基本的计算机视觉任务,例如,分类[6,162,263],目标检测[264-266],分割[267-269],和图像检索[270-272]。
Temporal Dataset
时间数据集更多关注同一区域的时间演化,现有的工作包含两幅图像的比较,关注特定的对象实例。例如,LEVV-CD[258]和HRSCD[259]是变化检测的基本驱动。CRC[260]和SITSC[261]促进了作物分类和覆盖的发展。相应的,Emelyanova等[273],Zeebruges[274]和WUDAPT[275]促进了数据融合的发展。这些数据集为时间分析开创了先例。
Cross-element Dataset
跨元素数据集主要关注RS图像与其他类型数据的交互和转换,如图像/音频[30,72,244]、图像/文本[26,214,239]和图像/大气数据[262,276]。RS图像描述[214,239,277]、跨模态检索[26,30,72,244]和大气数据观测[262,276]都依赖于这些数据集。由于RS图像的规模大,包含的内容太多,其他类型的数据往往很难描述和对齐整个场景的关键信息。因此,当前跨元素数据集的主要问题仍然是如何将不同元素之间的信息以一种有效、同构的表示方式进行合理、详细的表示。
7. Applications
7.1 Land use classification

不同的土地覆被可以从三个方面增强它们:1)分辨率;2)光谱;3)时间。高光谱分辨率提高了光谱维度信息的保真度和准确性;时间信息被不同时间序列中土地覆盖类型的不同特征进一步补充。
Chen等人[278]将Landsat-8数据与MODIS、HJ-1A和ASTER DEM数据融合,以提高土地覆盖分类精度。一项研究应用Sentinel-1、Sentinel-2和Landsat-8数据解决了由于云层覆盖导致的空间不连续的问题[279]。在[280]中,作者进一步研究了融合数据的不同级别(数据级、特征级和决策级)的效果比较。
7.2 Urban Planning

数据的多模态提供了多角度观察城市变化和发展的可能性,通过对历史数据的观察,可以有效地规划和预测城市的发展
在[281]中,作者提出了一种基于两幅异构图像提出了一种无监督深度卷积耦合网络用于变化检测。最近的一项研究探索了使用卷积自编码器和通用自编码器来消除两个异构图像(光学和SAR)中的大部分冗余,以获得更一致的特征表示[282]。另一项研究设计了一个边缘保存神经网络(edge-preservation neural network, EPUNet),它用极少的人工干预就可以将现有的建筑数据库自动更新到它们的最新状态[54]。
7.3 Agriculture and Ecology
Garnot等人[22,23]提出使用基于自注意力机制的定制神经体系结构提取时相特征,并为大规模农业地块分类设计了轻量级的时间自注意力。一项研究通过整合多时相和多光谱遥感数据,研究了一种用于大规模动态玉米和大豆制图的DeepCropMapping方法[285]。He等人[286]结合细颗粒物(PM2.5)浓度、地表温度(LST)和植被覆盖(VC)的遥感数据,在国家的尺度、城市群之间和快速城市化地区评估了城市环境变化。Hilker等[287]和Tran等[288]使用STAARCH融合Landsat和MODIS反射率数据来绘制森林扰动图。

8 Future Directions
- Multimodal Image Restoration
与单模态图像恢复不同,该任务更倾向于从异构图像中获取互补信息进行图像恢复,这需要对不同模态之间的依赖关系进行适当建模。该领域在去噪任务如去除云层[204,289,290]中具有非常重要的作用。
- 3D Scene Reconstruction and Multi-view Interpretation
在复杂遥感场景建模时,需要从多个角度观察场景,同时涉及到各种数据源的分析。这一课题最近几年才出现,Huang等人[291,292]构建了一系列相关数据集,并将位姿估计方法应用到重构算法中,取得了很大的突破和进展。
- Land Use Classification and Detection
大多数方法缺乏鲁棒性和通用性,而且它们都是针对特定类别和数据集进行了过度设计,削弱了对其他更通用场景的适用性。如何提高方法的鲁棒性和通用性是当前任务的热点课题。
- Heterogeneous Image Time Series Change Detection
异构图像变化检测任务只考虑双时相遥感图像而在实际应用中,我们往往需要通过对一系列长时间序列图像的分析
5. Scene Prediction and Complementary
场景预测与互补是一个新兴的研究方向。它通过对场景长时间序列的特征提取和建模,预测场景的未来发展或补充中间时刻的元素。这项任务为区域发展预测和历史分析提供了可能性。
- Cross-element analysis
该任务的关键是提取复杂场景中的关键实例,并将它们与其他模态对齐或转换。因此,本课题主要涉及多源对齐(第3节)和跨模态翻译(第6节)相关内容,主要涉及遥感图像-语音(文本)对齐、遥感场景描述、遥感场景问答等研究方向。
Related:
1.遥感领域多模态综述论文翻译
文章出处登录后可见!