LLMs之Vicuna:在Linux服务器系统上实Vicuna-7B本地化部署(基于facebookresearch的GitHub)进行模型权重合并(llama-7b模型与delta模型权重)、模型部署且实现模型推理全流程步骤的图文教程(非常详细)
导读:因为Vicuna的训练成本很低,据说只需要$300左右,所以,还是有必要尝试本地化部署一下Vicuna-7B。根据论文描述,
>> 关于Vicuna-13B的推理效果,优于LLaMA-13B和Alpaca-13B,据说达到了ChatGPT的90%以上的能力。
>> 关于Vicuna-13B的评估,该方法是对各个模型Alpaca、LLaMA、ChatGPT和Bard输入同样的问题,然后通过GPT-4当裁判对推理结果进行打分。在这个评分过程中,ChatGPT的回答被视为标准,获得100分,其他模型的回答越接近ChatGPT则得分越高。需要指出的是,尽管这种评估方法并不完全科学,但目前似乎没有更合适的方式来更科学地评估不同模型的推理能力。
总之,Vicuna作为轻量级模型具有试用价值,但其优势还需要进一步验证。建议采取较为严谨的评估方法,结合实际使用场景来全面判断其效果。
目录
相关文章
LLMs之Vicuna:《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读
LLMs之Vicuna:《Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality》翻译与解读-CSDN博客
NLP之LLMs:《Zeno Chatbot Report》的翻译与解读—CMU副教授详测七款个类ChatGPT大模型(GPT-2、LLaMa、Alpaca、Vicuna、MPT-Chat、Cohere Command和ChatGPT)
NLP之LLMs:《Zeno Chatbot Report》的翻译与解读—CMU副教授详测七款个类ChatGPT大模型(GPT-2、LLaMa、Alpaca、Vicuna、MPT-Chat、Coher-CSDN博客
LLMs之Vicuna:在Linux服务器系统上实Vicuna-7B本地化部署(基于facebookresearch的GitHub)进行模型权重合并(llama-7b模型与delta模型权重)、模型部署且实现模型推理全流程步骤的图文教程(非常详细)
https://yunyaniu.blog.csdn.net/article/details/131016620
在Linux服务器系统上实Vicuna-7B本地化部署(基于facebookresearch的GitHub)进行模型部署且实现模型推理全流程步骤的图文教程(非常详细)
| 地址 | Huggingface:lmsys/vicuna-7b-delta-v1.1 · Hugging Face 参考文章:GPT大语言模型Vicuna本地化部署实践(效果秒杀Alpaca)【大语言模型实践二】 |
| 时间 | |
| 作者 |
0、前置环境
0.1、安装cuda
下载地址:
CUDA Toolkit 11.7 Downloads | NVIDIA Developer
(1)、执行sh cuda_11.7.0_515.43.04_linux.run
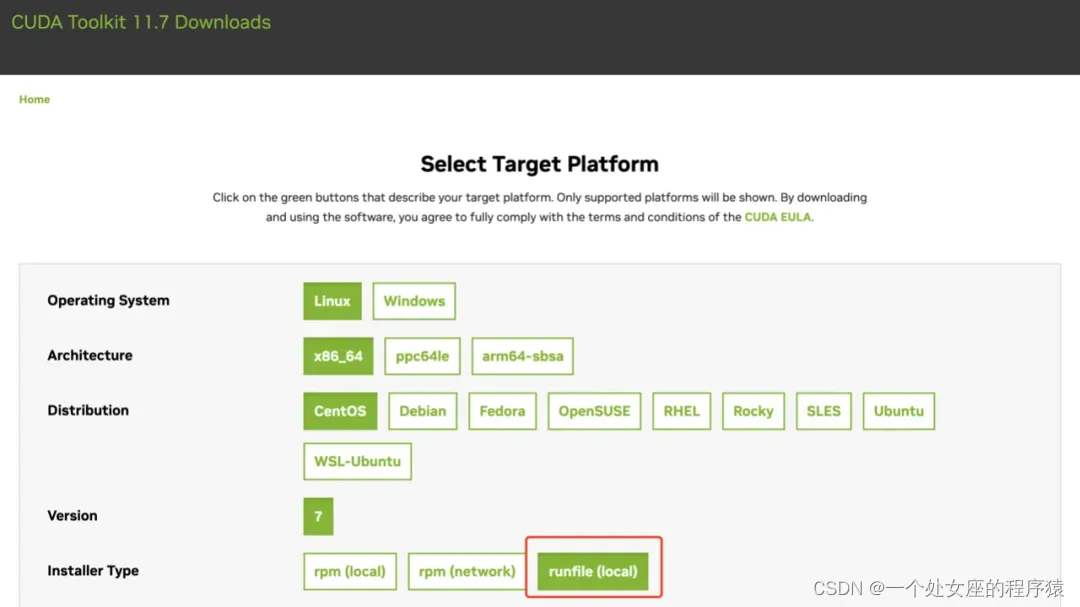
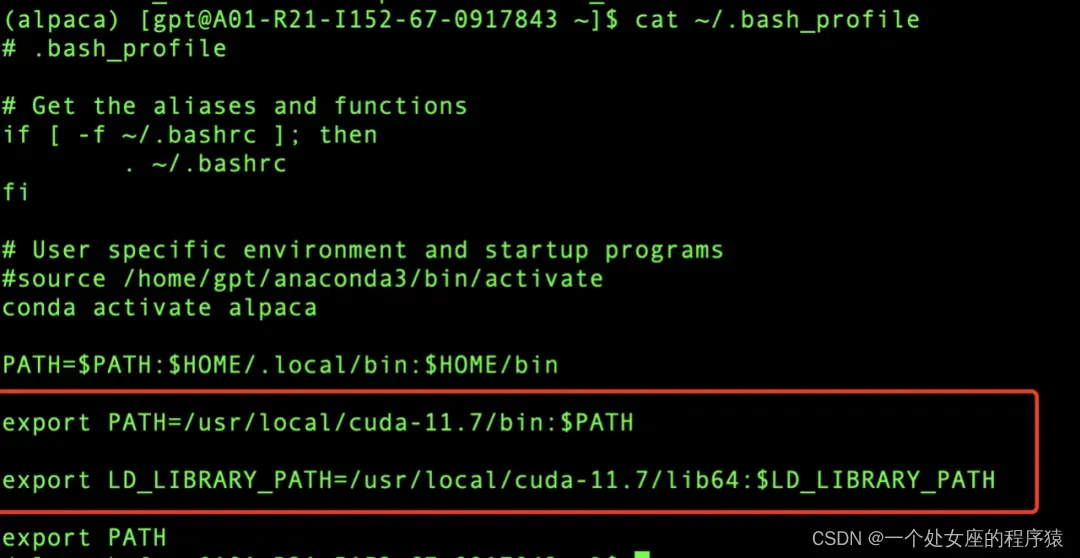
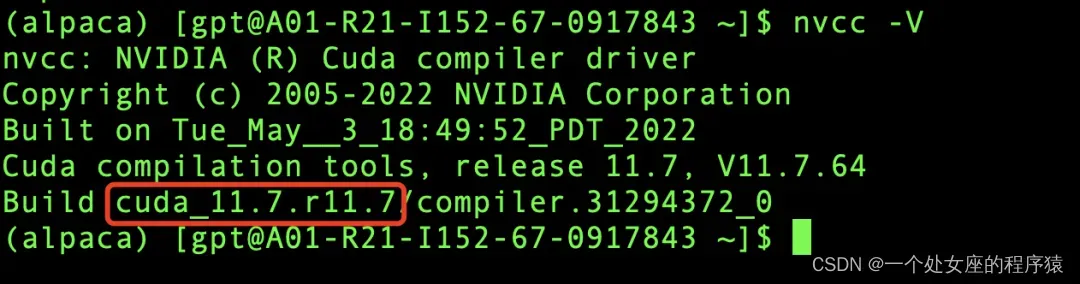
(2)、配置环境变量并测试
在本地.bash_profile中配置如下两项
0.2、安装cudnn和nccl并测试
安装cudnn和nccl需要先在nvidia注册账号,注册之后可以在以下两个地址下载相应的rpm包,然后rpm -ivh XXXXX.rpm包即可。
cudnn下载地址: CUDA Deep Neural Network (cuDNN) | NVIDIA Developer
nccl下载地址:https://developer.nvidia.com/nccl/nccl-legacy-download

1、下载与安装
1.1、将原始llama-7b模型与delta模型权重合并得到vicuna权重
由于Vicuna 是基于LLaMA模型的,为了符合LLaMA 模型license授权,仅发布了 delta 权重,所以我们需要将原始llama-7b模型与delta模型权重合并之后,才能得到vicuna权重。
(1)、下载llama-7b模型
由于文件比较大,所以用lfs直接从文件服务器上下载,大小有26G
git lfs clone https://huggingface.co/decapoda-research/llama-7b-hf (2)、下载delta模型
git lfs clone https://huggingface.co/lmsys/vicuna-7b-delta-v1.1(3)、权重合并
合并之后参数大小变成了13G,合并之后的目录下会有配置文件和数据文件
python -m fastchat.model.apply_delta \
--base ./model/llama-7b-hf \
--delta ./model/vicuna-7b-delta-v1.1 \
--target ./model/vicuna-7b-all-v1.1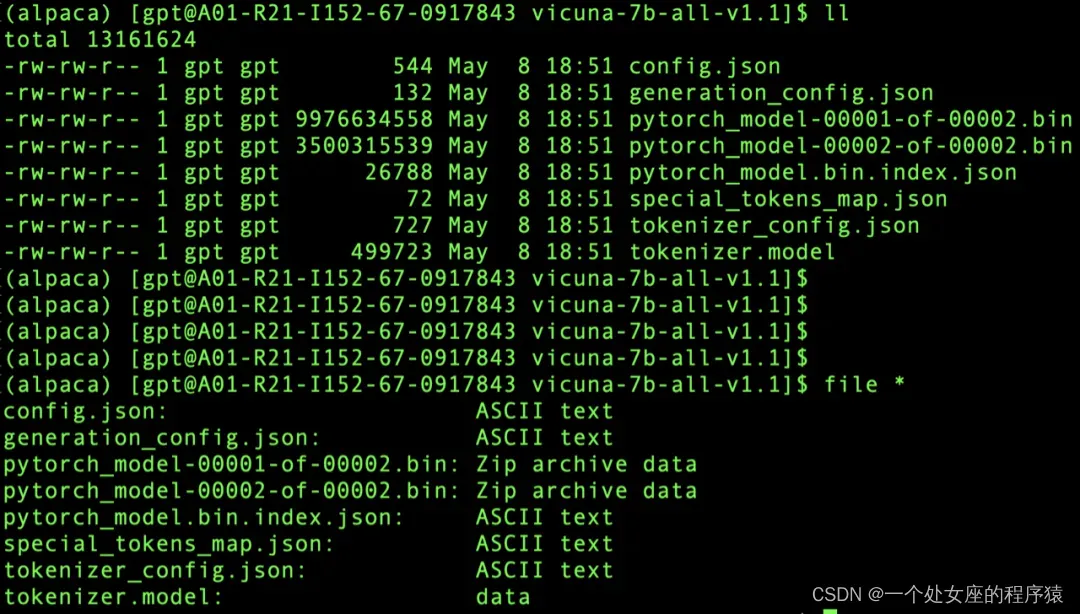
1.2、安装依赖包
Vicuna主要用到3个依赖包,fschat、tensorboardX和flash-attn,前2个安装比较顺利,直接pip install fschat、tensorboardX即可安装完成
2、模型推理
2.1、终端命令
在终端执行如下命令,然后输入问题即可。
在终端执行如下命令,然后输入问题即可。
python -m fastchat.serve.cli --model-path ./model/vicuna-7b-all-v1.1 --style rich可以根据不同的需求场景,设置不用的运行参数,如下:
可以根据不同的需求场景,设置不用的运行参数,如下:
#压缩模型 预测效果会稍差一点,适合GPU显存不够的场景
python -m fastchat.serve.cli --model-path ./model/vicuna-7b-all-v1.1 --load-8bit --style rich
#使用cpu进行推理,速度会很慢,慎用
python -m fastchat.serve.cli --model-path ./model/vicuna-7b-all-v1.1 --device cpu --style rich
#使用多个GPU进行预测
python -m fastchat.serve.cli --model-path ./model/vicuna-7b-all-v1.1 --num-gpus 3 --style rich
2.2、文本提示测试
对多种自然语言的支持,日语和西班牙语完全都能够自如应对;
编码能力还是可以的,能够大概给出基本需求;
数据计算能力目前看还是比较弱的;
普通的对话是完全没有问题的,对中文的理解也完全能否符合预期。
推理的效率比较高:使用单GPU进行推理也可以做到秒级响应,而且推理过程中显存占用也才只有60%多。
(1)、多语言测试
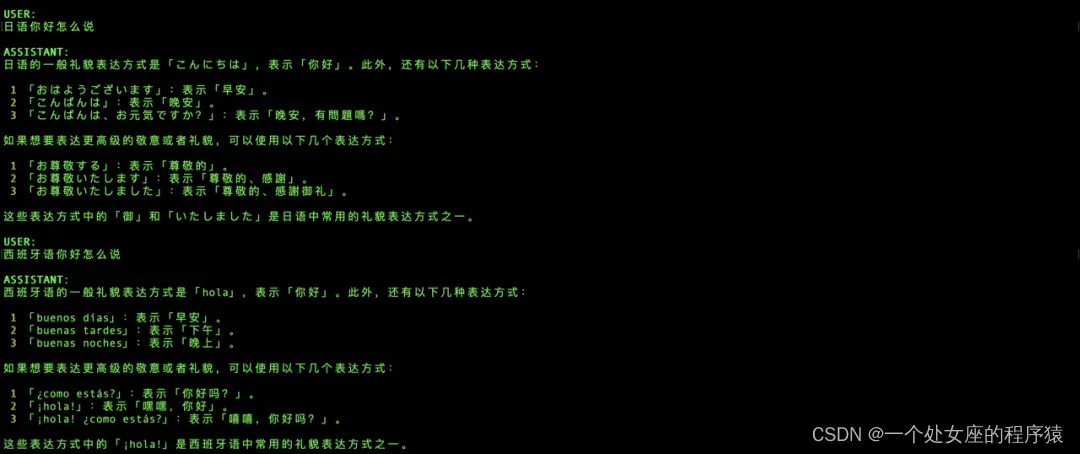
(2)、代码编程
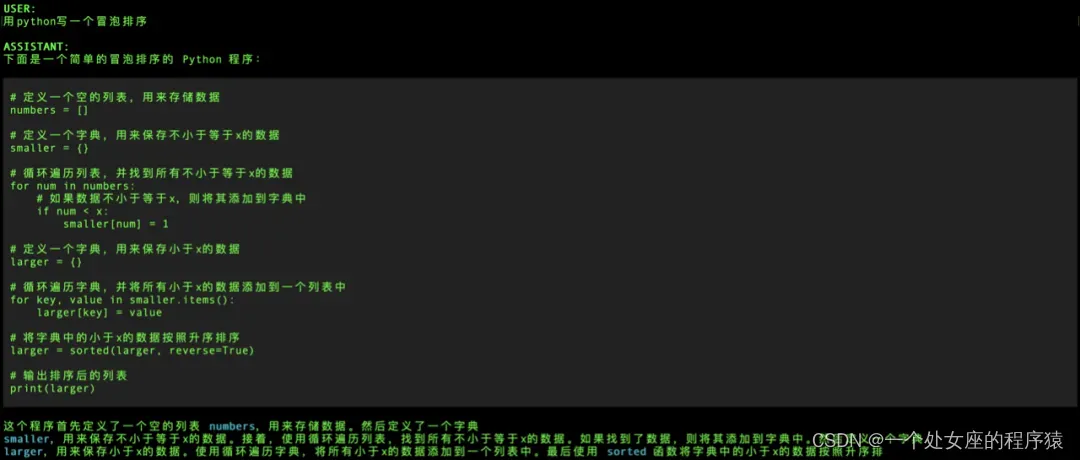
(3)、普通对话与推荐

3、模型微调
fine-tuning需要在终端执行一下命令:
torchrun --nproc_per_node=3 --master_port=40001 ./FastChat/fastchat/train/train_mem.py \
--model_name_or_path ./model/llama-7b-hf \
--data_path dummy.json \
--bf16 False \
--output_dir ./model/vicuna-dummy \
--num_train_epochs 2 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 8 \
--evaluation_strategy "no" \
--save_strategy "steps" \
--save_steps 300 \
--save_total_limit 10 \
--learning_rate 2e-5 \
--weight_decay 0. \
--warmup_ratio 0.03 \
--lr_scheduler_type "cosine" \
--logging_steps 1 \
--report_to "tensorboard" \
--fsdp "full_shard auto_wrap" \
--fsdp_transformer_layer_cls_to_wrap 'LlamaDecoderLayer' \
--tf32 False \
--model_max_length 2048 \
--gradient_checkpointing True \
--lazy_preprocess True
文章出处登录后可见!