说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。

1.项目背景
竞争性自适应重加权采样法(competitive adapative reweighted sampling, CARS)是一种结合蒙特卡洛采样与PLS模型回归系数的特征变量选择方法,模仿达尔文理论中的 ”适者生存“ 的原则(Li et al., 2009)。CARS 算法中,每次通过自适应加权采样(adapative reweighted sampling, ARS)保留PLS模型中 回归系数绝对值权重较大的点作为新的子集,去掉权值较小的点,然后基于新的子集建立PLS模型,经过多次计算,选择PLS模型交互验证均方根误差(RMSECV)最小的子集中的波长作为特征波长。
本项目通过竞争性自适应重加权采样法进行特征选择来构建LightGBM回归模型。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
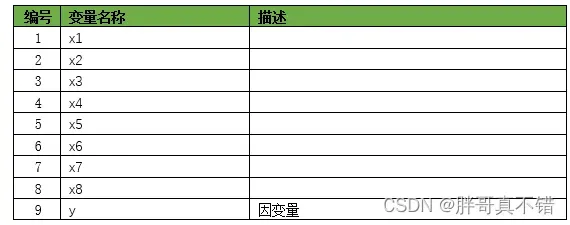
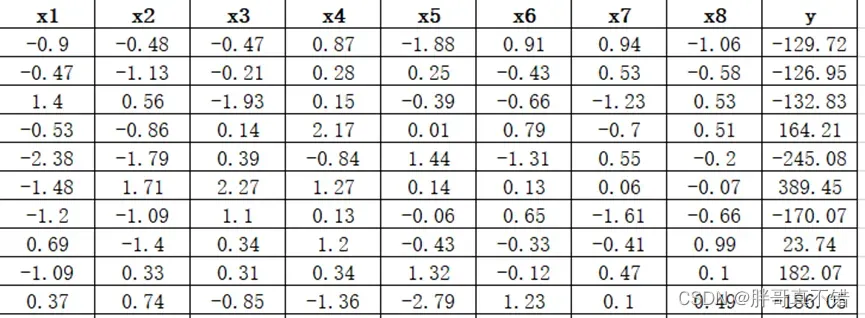
数据详情如下(部分展示):
3.数据预处理
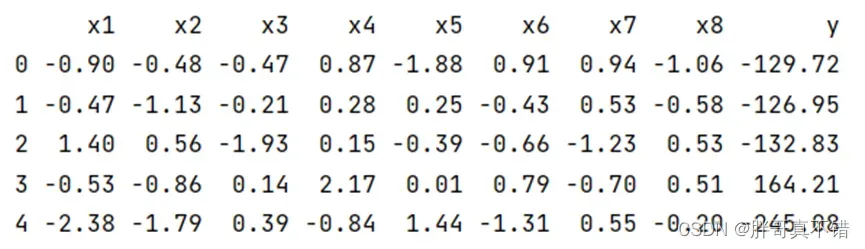
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:
关键代码:

3.2 数据缺失查看
使用Pandas工具的info()方法查看数据信息:
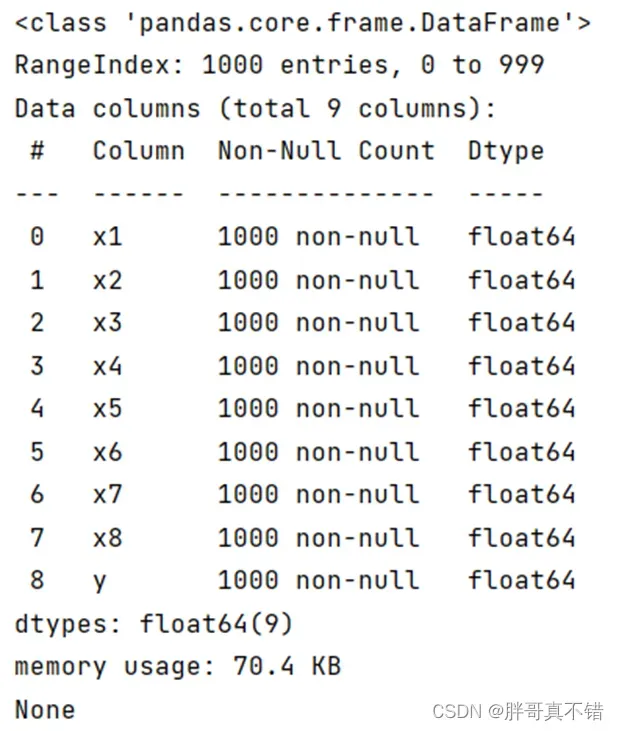
从上图可以看到,总共有9个变量,数据中无缺失值,共1000条数据。
关键代码:

3.3 数据描述性统计
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
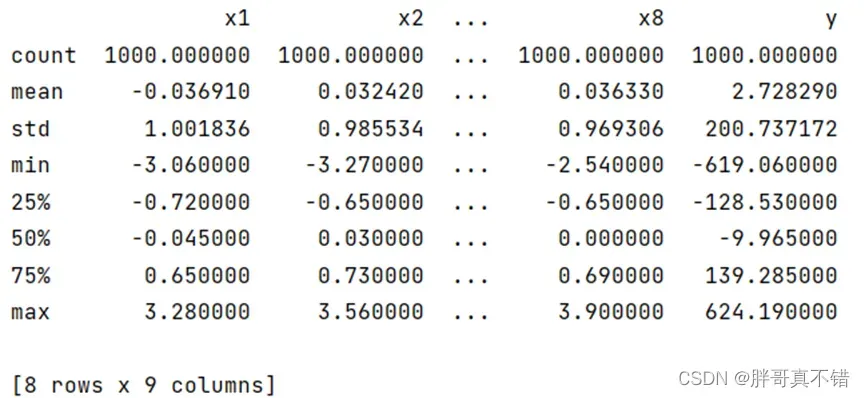
关键代码如下:

4.探索性数据分析
4.1 y变量直方图
用Matplotlib工具的hist()方法绘制直方图:
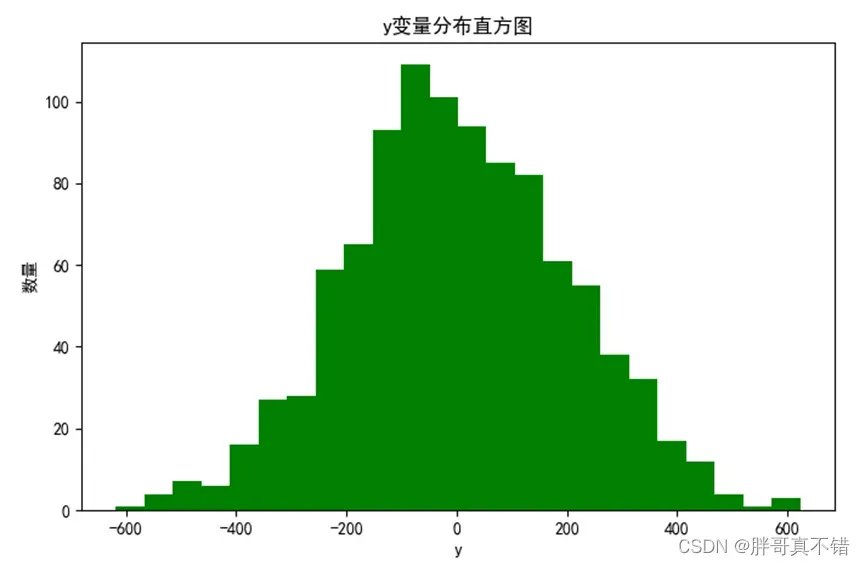
从上图可以看到,y变量主要集中在-400~400之间。
4.2 相关性分析
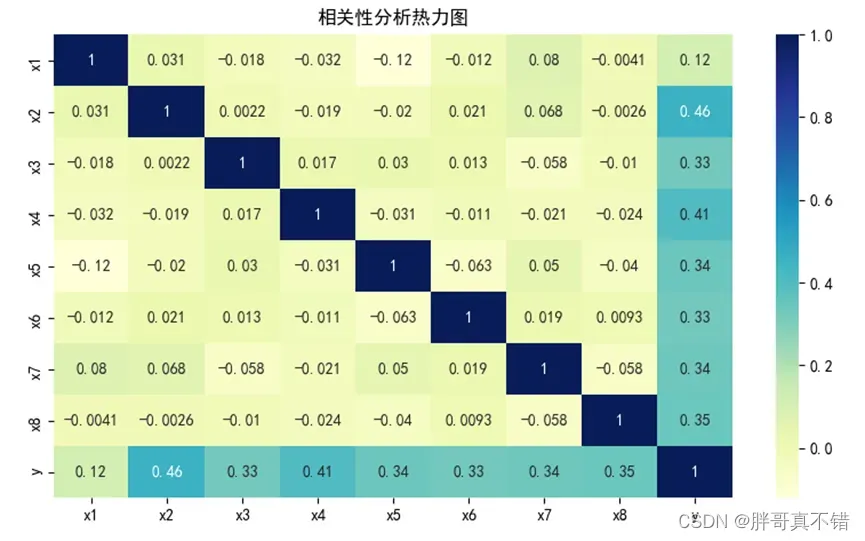
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 CARS进行特征选择
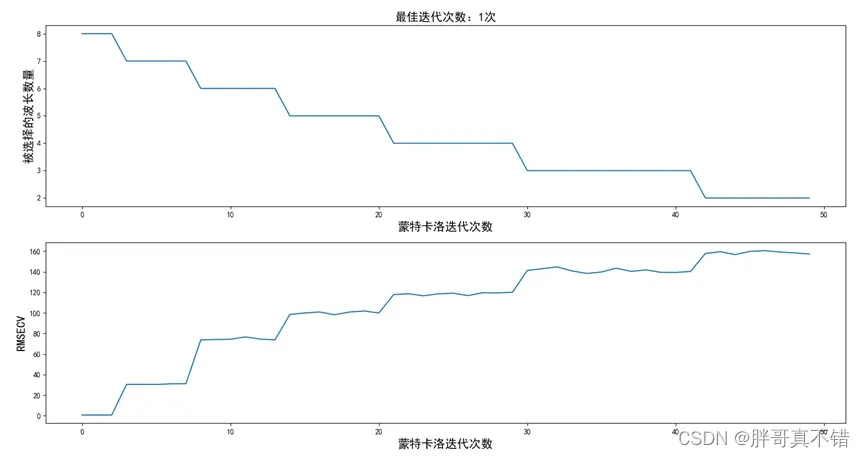
获取的特征数:
![]()
特征选择后的数据进行部分展示(数据保存到Excel中的):
5.3 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:

6.构建LightGBM回归模型
主要使用LightGBM回归算法,用于目标回归。
6.1 构建模型

7.模型评估
7.1 评估指标及结果
评估指标主要包括可解释方差值、平均绝对误差、均方误差、R方值等等。
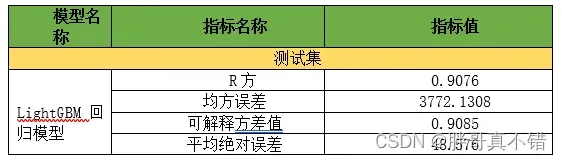
从上表可以看出,R方0.9076,为模型效果良好。
关键代码如下:

7.2 真实值与预测值对比图
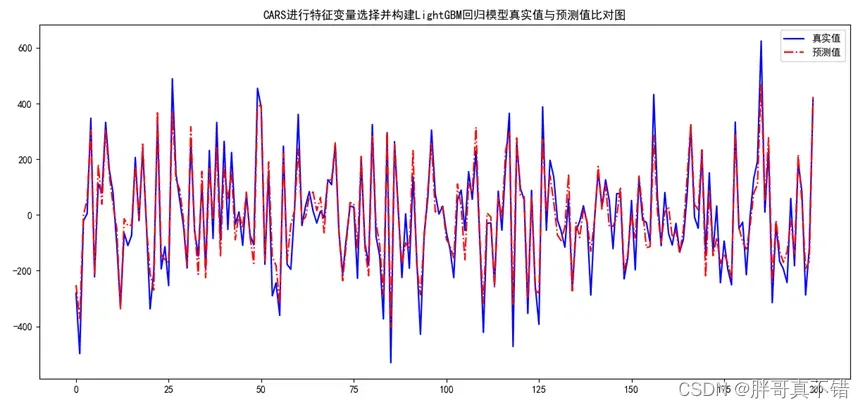
从上图可以看出真实值和预测值波动基本一致,模型拟合效果良好。
8.结论与展望
综上所述,本文采用了竞争性自适应重加权采样法进行特征变量选择来构建LightGBM回归模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。
# 本次机器学习项目实战所需的资料,项目资源如下:
# 项目说明:
# 链接:https://pan.baidu.com/s/1Xcn-VBBA_F4TB3N5rnO2RQ
# 提取码:bysh更多项目实战,详见机器学习项目实战合集列表:
机器学习项目实战合集列表_机器学习实战项目_胖哥真不错的博客-CSDN博客
项目代码咨询、获取,请见下方公众号。
版权声明:本文为博主作者:胖哥真不错原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_42163563/article/details/132269827