HashMap(哈希表)底层到底是什么?如何扩容的?它是怎么实现的呢?它是如何扩容的?想了解就进来看看吧

- 博主简介:努力的打工人一枚
- 博主主页:@xyk:
- 所属专栏: JavaEE初阶
目录
一、哈希表的概念
二、哈希表的一些参数
默认初始容量为16
最大长度为2的30次幂
默认加载因子为0.75
当链表节点小于等于6,自动退化成链表
当链表节点大于等于8,长度大于64时进行变化成红黑树
扩容阈值,当你的hashmap中的元素个数超过这个阈值,便会发生扩容
threshold = capacity * loadFactor
2.1无参构造函数
三、哈希表扩容机制
3.1到底什么时候扩容?
3.2为什么HashMap的长度必须是2的n次幂
3.3为什么HashMap的键值可以设为null?
3.4为什么不直接取余,而要>>>16?
四、JDK1.8的新结构——红黑树
五、HashMap扩容操作是尾插还是头插?
六、HashMap是怎么解决哈希冲突的?
6.1闭散列
6.2二次探测
6.3开散列/哈希桶
一、哈希表的概念
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( log2 N),搜索的效率取决于搜索过程中元素的比较次数
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。 如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时通过该函数可以很快找到该元素
当向该结构中:
- 插入元素:Key-Value
根据待插入元素的关键码Key,以此函数计算出该元素的存储位置并按此位置进行存放
- 搜索元素:Key-Value
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置取元素比较,若关键码相等,则搜索成功Value
在JDK1.7中,HashMap数据结构为数组+链表;JDK1.8之后增加了数组+链表+红黑树变换,HashMap存储的键值对Key-Value,Key具有唯一性,采用了链地址法来处理哈希冲突,当往 HashMap 中添加元素时,会计算 key 的 hash 值取余得出元素在数组中的的存放位置。
HashMap 是线程不安全的
在 1.8 版本的中 hash() 和 resize( ) 方法也有了很大的改变,提升了性能
Key和Value都可存放null,Key只能存放一个null

二、哈希表的一些参数

//HashMap的默认初始长度16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4;
//HashMap的最大长度2的30次幂
static final int MAXIMUM_CAPACITY = 1 << 30;
//HashMap的默认加载因子0.75
static final float DEFAULT_LOAD_FACTOR = 0.75f;
//HashMap链表升级成红黑树的临界值
static final int TREEIFY_THRESHOLD = 8;
//HashMap红黑树退化成链表的临界值
static final int UNTREEIFY_THRESHOLD = 6;
//HashMap链表升级成红黑树第二个条件:HashMap数组(桶)的长度大于等于64
static final int MIN_TREEIFY_CAPACITY = 64;
默认初始容量为16最大长度为2的30次幂
默认加载因子为0.75
当链表节点小于等于6,自动退化成链表
当链表节点大于等于8,长度大于64时进行变化成红黑树
扩容阈值,当你的hashmap中的元素个数超过这个阈值,便会发生扩容
threshold = capacity * loadFactor
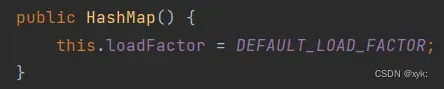
2.1无参构造函数

可以看到这里只有初始化了负载因子为0.75,还没有初始化容量,阈值也为0
在第一次put时,进行第一次resize!!!
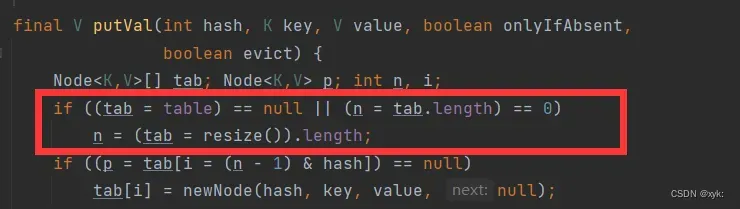
进入resize中进入分支:
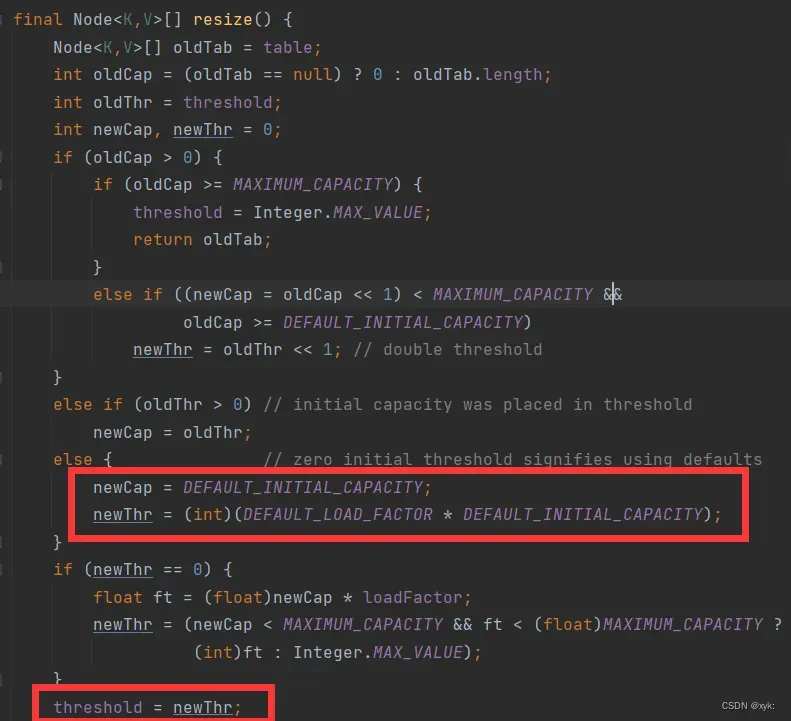
所以容量cap为默认值16,阈值threshold为 16*0.75=12。
三、哈希表扩容机制
3.1到底什么时候扩容?
其中initailCapacity是初始容量:默认值为16
在计算存入结点下标时,会利用 key 的 hsah 值进行取余操作,而计算机计算时,并没有取余等运算,会将取余转化为其他运算;当HashMap中的元素越来越多的时候,碰撞的几率也就越来越高,所以为了提高查询的效率,就要对HashMap的数组进行扩容;
那么HashMap什么时候进行扩容呢?
当hashmap中的元素个数超过数组大小*loadFactor时,就会进行数组扩容,loadFactor的默认值为0.75,也就是说,默认情况下,数组大小为16,那么当hashmap中元素个数超过16*0.75=12的时候,就把数组的大小扩展为2*16=32
- 当put时发现table未初始化时,进行初始化扩容
- 当put加入节点后,发现size(键值对数量)> threshold时,进行扩容
- 而在之后的每次扩容中,容量和阈值都变为原来的两倍
- 即两者仍然保持着0.75的比例


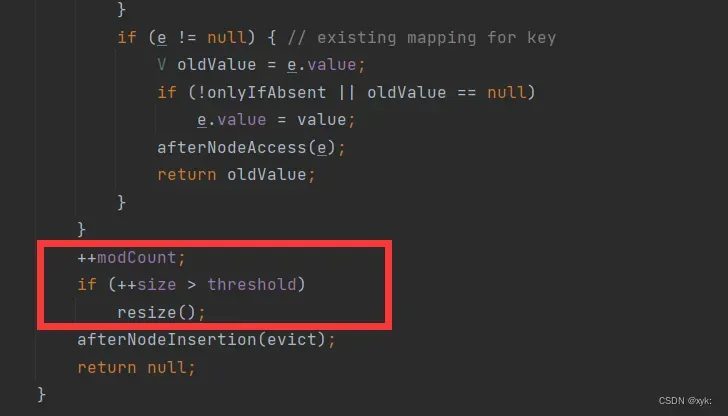
在put方法调用putVal,putVal()再次调用resize()方法
3.2为什么HashMap的长度必须是2的n次幂
1.为了避免哈希碰撞
- 可以看到HashMap在扩容时选择了位运算,向集合中添加元素时,会使用(n – 1) & hash的计算方法来得出该元素在集合中的位置;
- 这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞
2.源码解析如下:
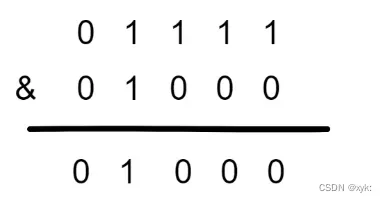
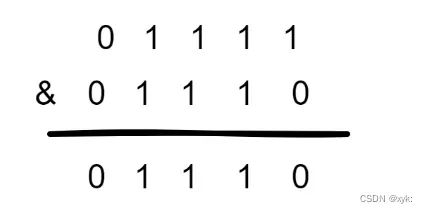
1.当HashMap的容量是16时,它的二进制是10000,(n-1)的二进制是01111;
- 不同的hash值,和(n-1)去进行&运算,得到的结果是不一样的,使得添加的元素能够均匀分布在集合中不同的位置上,避免hash碰撞;
- 如果不是2的n次幂容量,添加元素会导致生成一样的哈希值,严重hash碰撞,导致某一个链表的长度特别长,影响查询的效率;
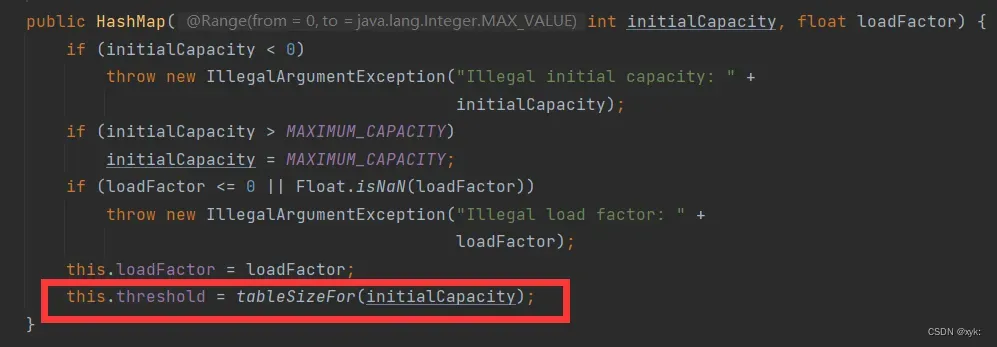
2.构造函数给定容量后进行的运算
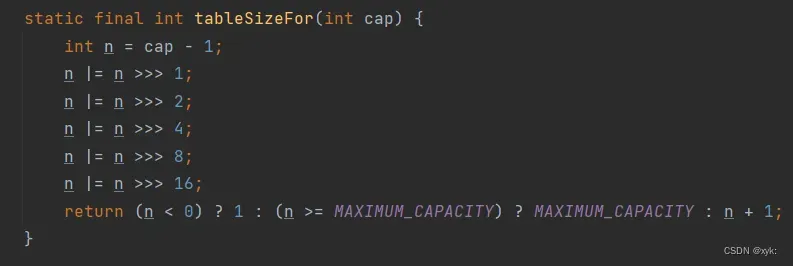
上面这个方法我来举个例子:
1.当传入的cap值为35时;
2.首先执行第一步 cap-1,得到n的值为34;
3.执行第二部:n或(n右移一位),34 二进制为:100010,n右移一位变成:010001,或操作结果为:110011;
4.n右移两位变成:001100,再与110011进行或操作,变成111111,此时n为111111;
5.n右移四位变成:000000,再与111111进行或操作,结果n仍为:111111;
6.n右移16为,再与111111进行或操作,n仍为111111;
7.n+1变成1000000,变成64;
3.3为什么HashMap的键值可以设为null?
因为hashMap在对键值为空的时候做了处理: 当key为空时,哈希值时会直接被赋值为0

3.4为什么不直接取余,而要>>>16?
- 如果使用直接使用hashCode对数组大小取余,那么相当于参与运算的只有hashCode的低位,高位是没有起到任何作用的
- (h >>> 16)是无符号右移16位的运算,左边补0,得到 hashCode 的高16位,可以使得到的 hash 值更加散列,尽可能减少哈希冲突,提升性能
- 而这么来看 hashCode 被散列 (异或) 的是低16位,而 HashMap 数组长度一般不会超过2的16次幂,那么高16位在大多数情况是用不到的,所以只需要拿 key 的 HashCode 和它的低16位做异或即可利用高位的hash值,降低哈希碰撞概率也使数据分布更加均匀
四、JDK1.8的新结构——红黑树
为了解决JDK1.7中的死循环问题, 在jDK1.8中新增加了红黑树,即在数组长度大于64,同时链表长度大于8的情况下,链表将转化为红黑树。同时使用尾插法。当数据的长度退化成6时,红黑树转化为链表。
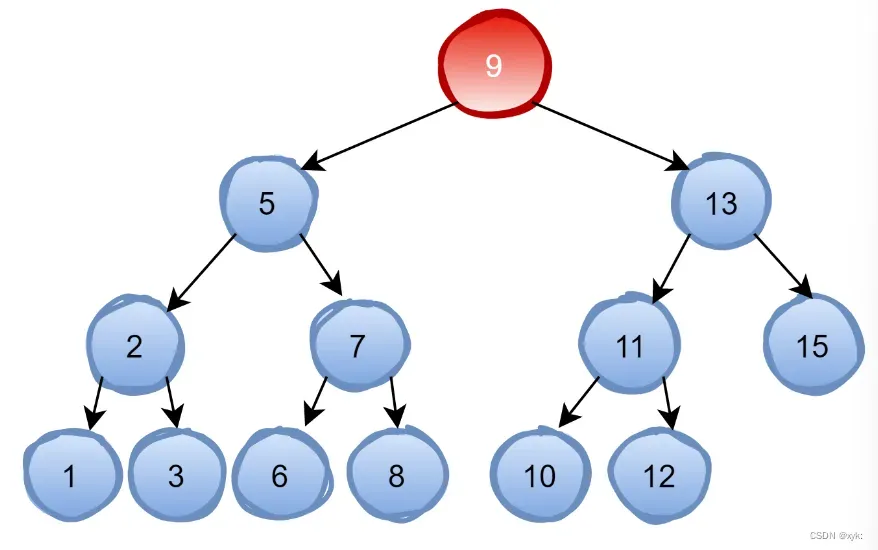
具体讲解以后会讲
五、HashMap扩容操作是尾插还是头插?
JDK1.7扩容:
条件:发生扩容的条件必须同时满足两点
- 当前存储的数量大于等于阈值
- 发生hash碰撞
- 特点:先扩容,再添加(扩容使用的头插法)
- 缺点:头插法会使链表发生反转,多线程环境下可能会死循环
- 扩容之后对table的调整:table容量变为2倍,所有的元素下标需要重新计算
JDK1.8扩容:
条件:
- 当前存储的数量大于等于阈值
- 当某个链表长度>=8,但是数组存储的结点数size() < 64时
- 特点:先插后判断是否需要扩容(扩容时是尾插法)
- 缺点:多线程下,1.8会有数据覆盖
- 扩容之后对table的调整:table容量变为2倍,但是不需要像之前一样计算下标,只需要将hash值和旧数组长度相与即可确定位置
六、HashMap是怎么解决哈希冲突的?
6.1闭散列
1.闭散列:也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表中必然还有空位置,那么可以把key存放到冲突位置中的“下一个” 空位置中去
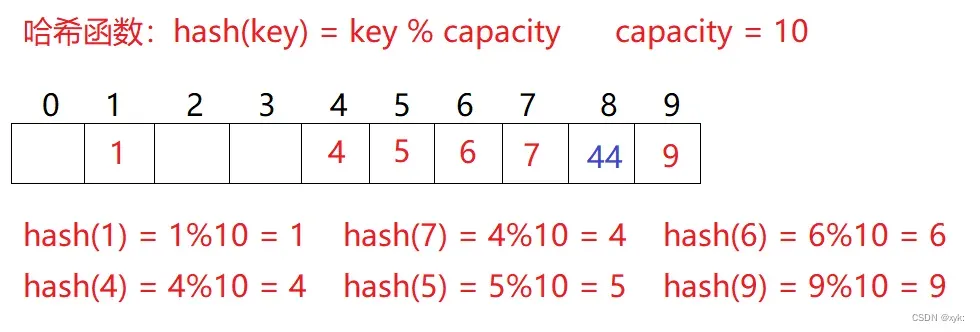
比如上面的场景,现在需要插入元素44,先通过哈希函数计算哈希地址,下标为4,因此44理论上应该插在该位置,但是该位置已经放了值为4的元素,即发生哈希冲突
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止
采用闭散列处理哈希冲突时,不能随便物理删除哈希表中已有的元素,若直接删除元素会影响其他元素的搜索。比如删除元素4,如果直接删除掉,44查找起来可能会受影响。因此线性探测采用标记的伪删除法来删除一个元素
6.2二次探测
线性探测的缺陷是产生冲突的数据堆积在一块,这与其找下一个空位置有关系,因为找空位置的方式就是挨着往后逐个去找,因此二次探测为了避免该问题,找下一个空位置的方法为:Hi = (H0 + i平方)% m 或者 Hi = (H0 – i平方)% m

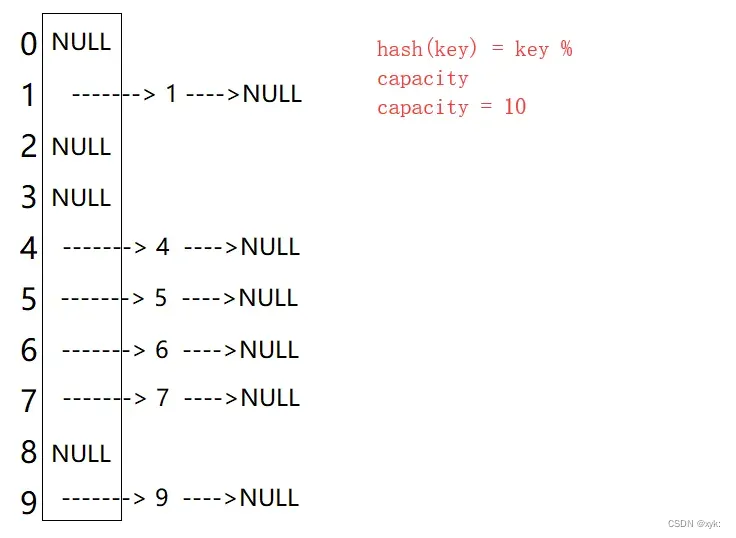
6.3开散列/哈希桶
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中
版权声明:本文为博主作者:xyk:原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/asad21654864/article/details/129972009