目录
1、外部排序
1.1 基本概念
外部排序是指对大规模数据进行排序,其中无法将整个数据集一次性加载到内存中。因此需要将数据划分为适当大小的块,然后对每个块进行排序。在此之后,将这些排好序的块合并成更大的块,直到最终得到一个已排序的数据集。
外部排序是一种常见的数据处理技术,适用于需要对大量数据进行排序的场景,例如处理大型数据库或处理大型文件。通常采用归并排序算法来实现外部排序,其核心思想是将多个有序的子序列合并成一个有序的序列,以减少排序的时间和空间复杂度。
在外部排序中,需要考虑如何对数据进行分块、如何将块排序以及如何将排好序的块进行合并。为了提高排序效率,还需要考虑如何优化输入和输出数据的读取和写入。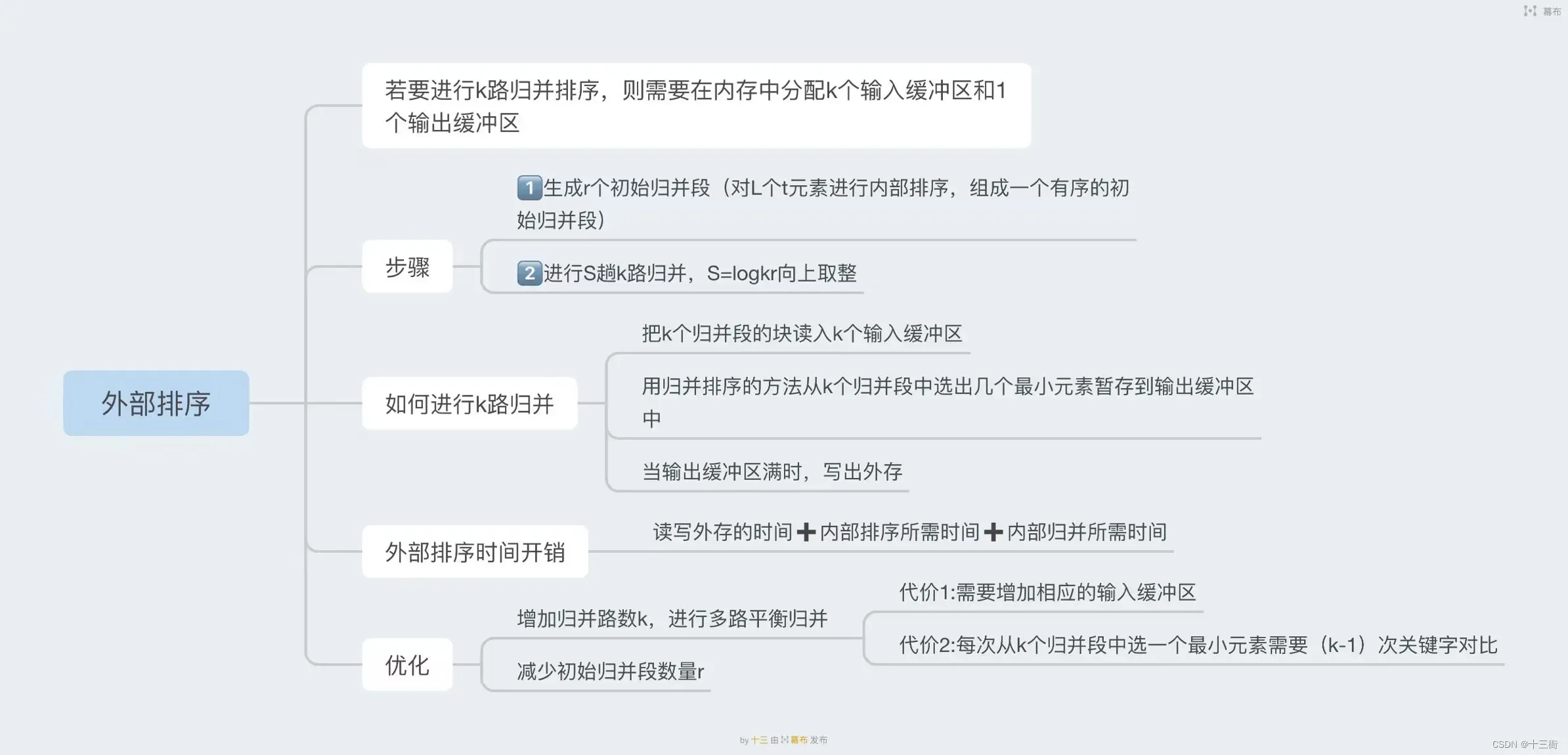
1.2 方法
外部排序是一种处理超过内存容量的数据的排序方法。以下是外部排序的几种常见方法:
-
归并排序:将大文件分成若干个小文件,排序这些小文件,再进行归并排序,将小文件合并成一个有序的大文件。
-
快速排序:将大文件分割成若干个小文件,对这些小文件进行快速排序,然后将排序好的小文件合并成一个有序的大文件。
-
堆排序:利用堆的结构对数据进行排序,可以将大文件分成若干个小文件,将小文件中的数据建成堆,然后再进行堆排序。
-
多路归并排序:将大文件划分成多个子文件,每个子文件都小于内存容量,然后对于每个子文件,将其分成多个块,将每个块读入内存进行排序,最后进行多路归并。
-
分块排序:将大文件划分为若干个块,每个块都可以在内存中排序,然后将每个块中的数据合并成一个有序的文件。
这些方法都可以通过将大文件分割成小文件或块来解决内存容量不足的问题,并利用多路归并等技术来进行排序。
例子:
假设我们有一个文件,其中包含 1000 万个整数,需要对其进行排序。然而,计算机的内存只能容纳 1000 个整数,因此我们需要将该文件分成 10000 个大小为 1000 的块。
接下来,我们将这些块读取到内存中,对每个块进行排序,然后将它们写回磁盘。这是称为”归并排序”的过程。在每个块中进行排序的好处是可以优化内存中的使用,而且在每个块中进行的排序比在整个文件上进行的排序更快。
接下来,我们将排好序的 10000 个块合并成一个大的有序文件。为了合并这些块,我们可以使用归并排序的原理。我们将前两个块合并成一个块,再将第三个块与已合并的块合并,以此类推,直到所有块都被合并成一个大块。
最后,我们将这个大块写回磁盘,即得到了完全排好序的文件。这个过程可能会涉及到多次读取和写入磁盘,但是外部排序的好处是可以处理非常大的文件,而不需要太多的内存。
2、多路平衡归并与败者树
2.1 K路平衡归并
K路平衡归并是一种归并排序的变体,它将一个大文件分成K个子文件并对每个子文件进行排序,然后将它们合并成一个大文件。它的主要目的是在内存有限的情况下对大型数据集进行排序。
K路平衡归并的基本思想是将输入文件分成K份,每份放入磁盘上的一个块中,然后针对每个块进行排序。排序后,每个块中的第一个元素被放入一个最小堆或多个最小堆中,堆的大小为K。从堆中选择最小元素,将其放入输出缓冲区中,并且从所属块的下一个元素中选择一个元素来取代刚刚被放入输出缓冲区的元素。重复此过程,直到所有输入文件中的元素都被放入输出缓冲区中。输出缓冲区的元素可以按顺序写入输出文件。
K路平衡归并的时间复杂度为O(n log n),其中n表示输入文件的大小。它需要的额外空间取决于K和块的大小,通常情况下可以控制在几兆字节的范围内。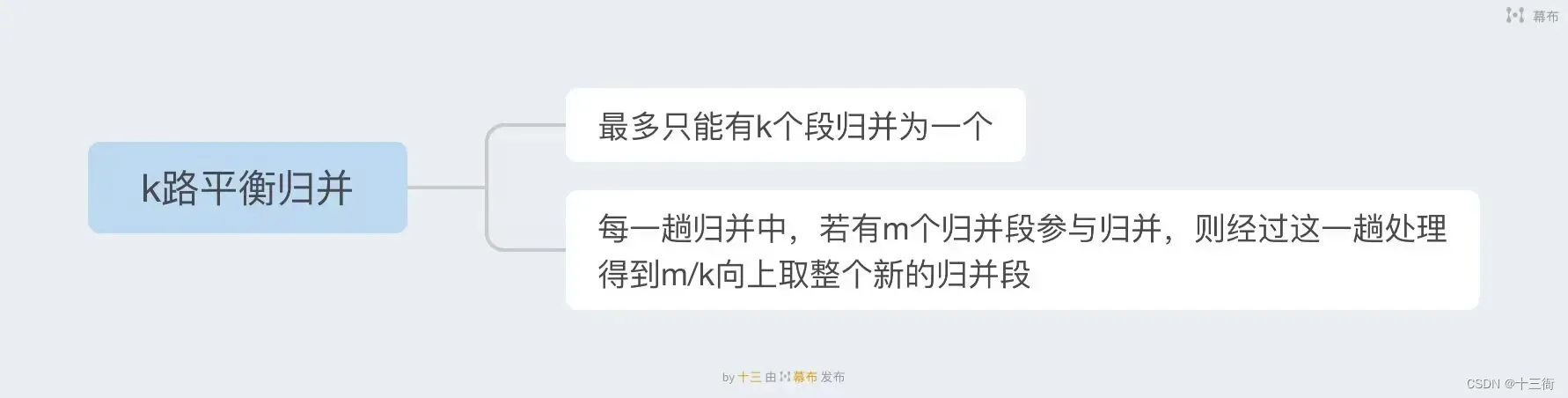
2.2 败者树
败者树是一种用于外部排序的数据结构,它基于树形结构,常用于对大量数据进行排序,尤其是当内存无法容纳所有待排序数据时。败者树的思想在于通过比较已排序的子序列中最小的元素来确定最终的排序顺序。
在败者树中,首先构建一棵初始的完全二叉树,其中每个节点存储一个元素。初始时,将每个需要排序的子序列的第一个元素放入这棵二叉树的最底层叶子节点。接下来,从叶子节点开始向上进行比较,每次比较两个叶子节点中的较小值,并将较小值向其父节点传递。这样,最终得到的顶部节点就是已排序的所有元素中的最小值。
在外部排序中,每次从磁盘中读取一定数量的数据块并进行排序,然后将每个数据块的最小值放入败者树中,以确定整体排序的顺序。当一个数据块中的所有元素都已被取出并放入败者树中时,将从该数据块中读取下一个元素,直到整个排序过程结束。
败者树的主要优点是它只需要常数级别的额外内存空间,并且可以对任意大小的数据集进行排序。它的主要缺点在于实现比较复杂,需要一定的算法知识和技巧。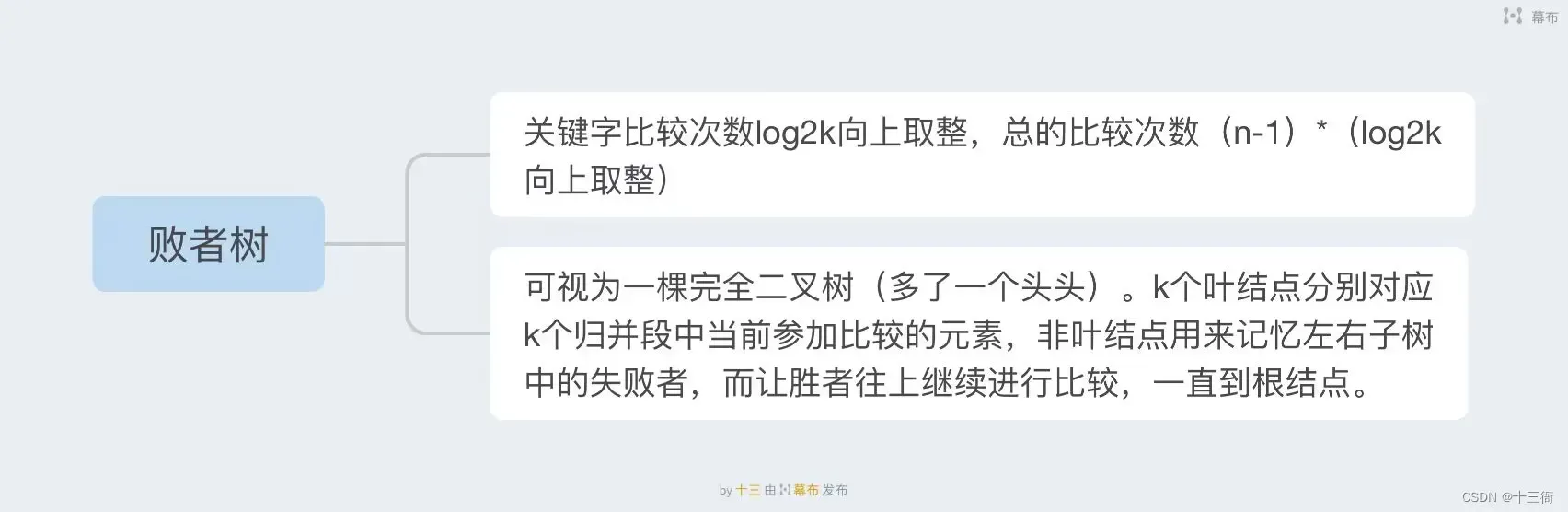
3、置换-选择排序(生成初始归并段)
4、最佳归并树
4.1 理论基础
4.2 构造方法 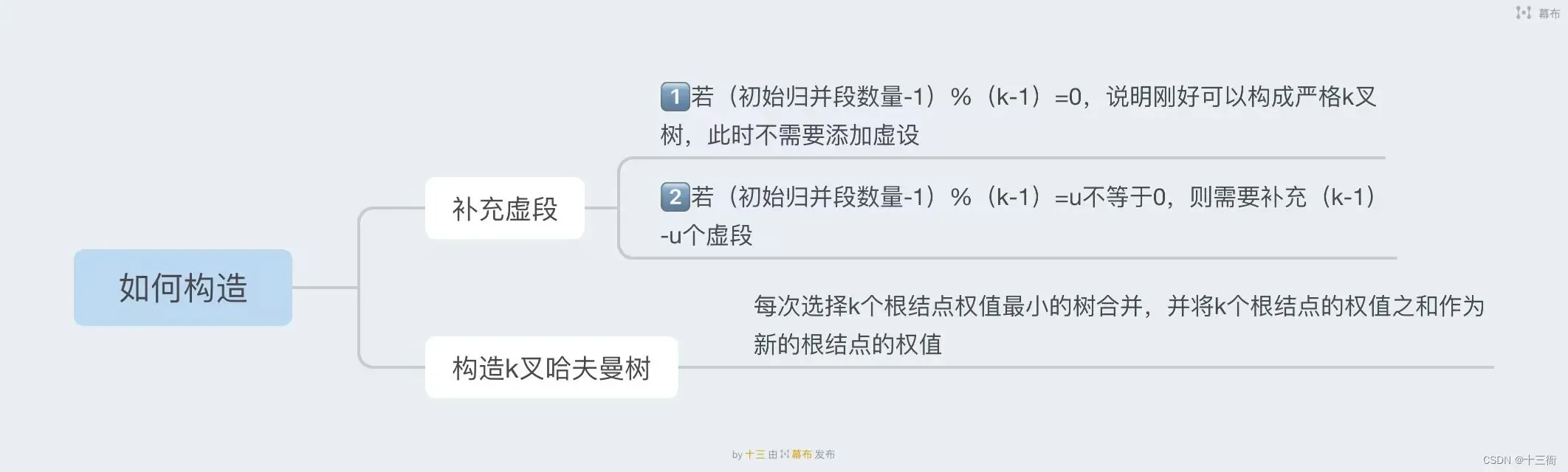
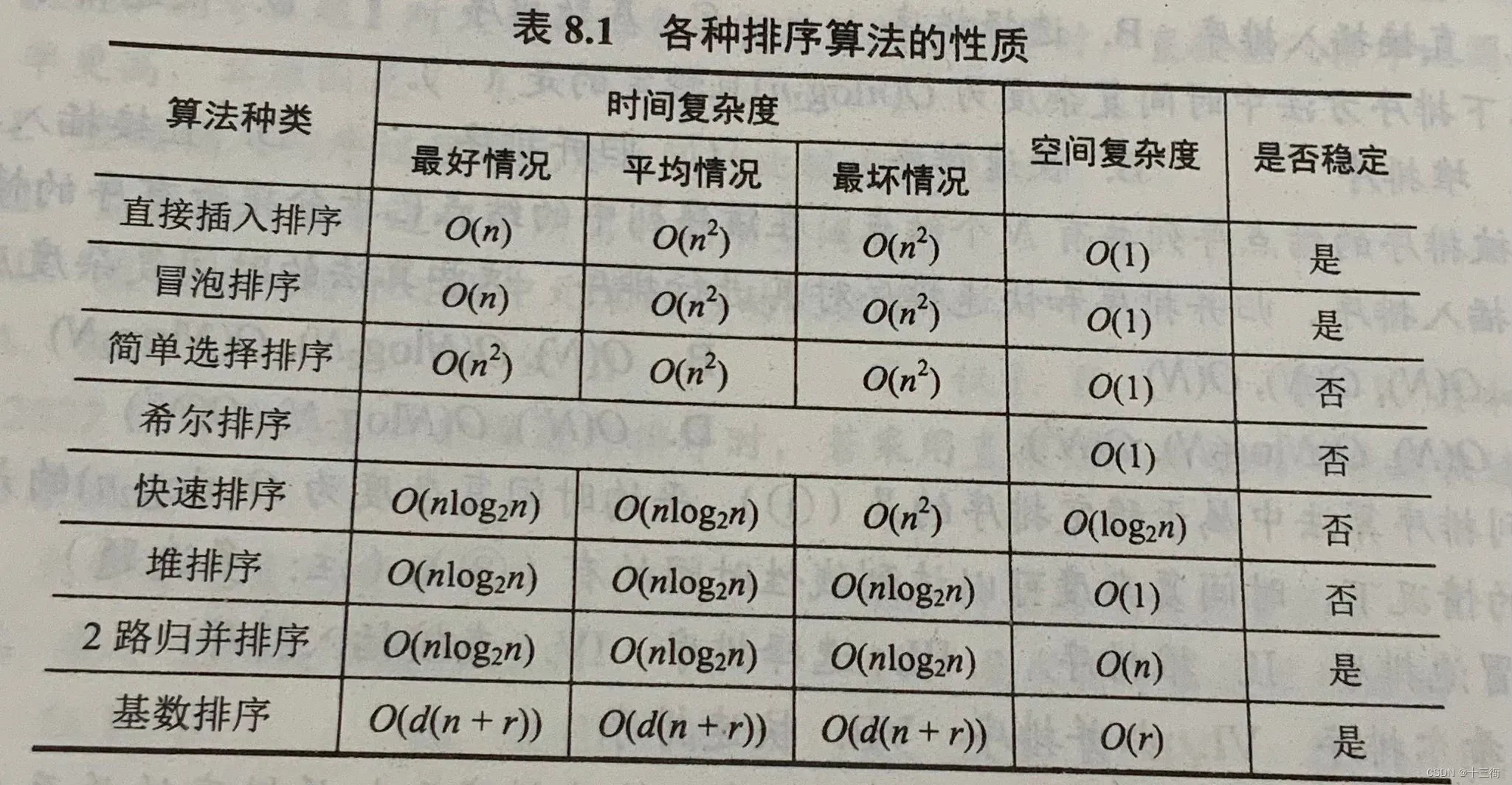
5、各种排序算法的性质
1. 冒泡排序:稳定,平均时间复杂度O(n^2);
2. 选择排序:不稳定,平均时间复杂度O(n^2);
3. 插入排序:稳定,平均时间复杂度O(n^2);
4. 快速排序:不稳定,平均时间复杂度O(nlogn);
5. 归并排序:稳定,平均时间复杂度O(nlogn);
6. 堆排序:不稳定,平均时间复杂度O(nlogn);
7. 希尔排序:不稳定,平均时间复杂度O(nlogn);
8. 基数排序:稳定,平均时间复杂度O(d(n+k)),其中d是数字的最大位数。
稳定性指的是排序后相同元素之间的相对位置是否改变;时间复杂度指的是排序算法在最坏情况下的时间复杂度。
版权声明:本文为博主作者:十三衙原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_52442214/article/details/133392259