使用stable diffusion作图
1安装stable diffusion(Windows)
前置环境git、python10(低于此版本会导致部分py模块无法导入)
1.1 下载
stable diffusion webui (通过git clone到本地)
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
cpkt模型文件
放置在stable-diffusion -webui\models\Stable-diffusion\中
官方提供的模型文件为‘sd-v1-4.ckpt’
1.2安装
1.2.1 先确认python10已经作为环境路径,如果python10已经安装但是没有添加到系统环境路径中,可以通过修改webui-user.bat参数将python参数指向python10
@echo off
set PYTHON="D:\Environment\python310\python.exe"
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=
call webui.bat
1.2.2 运行webui-user.bat,等待系统资源下载完毕
资源大概10G+。
在于py包下载出现问题的时候,可以开启新的cmd窗口,将路径cd到 stable-diffusion-webui\venv\Scripts
执行
activate.bat
进入python10虚拟环境,通过pip命令下载或删除错误的py包
1.2.3安装成功界面
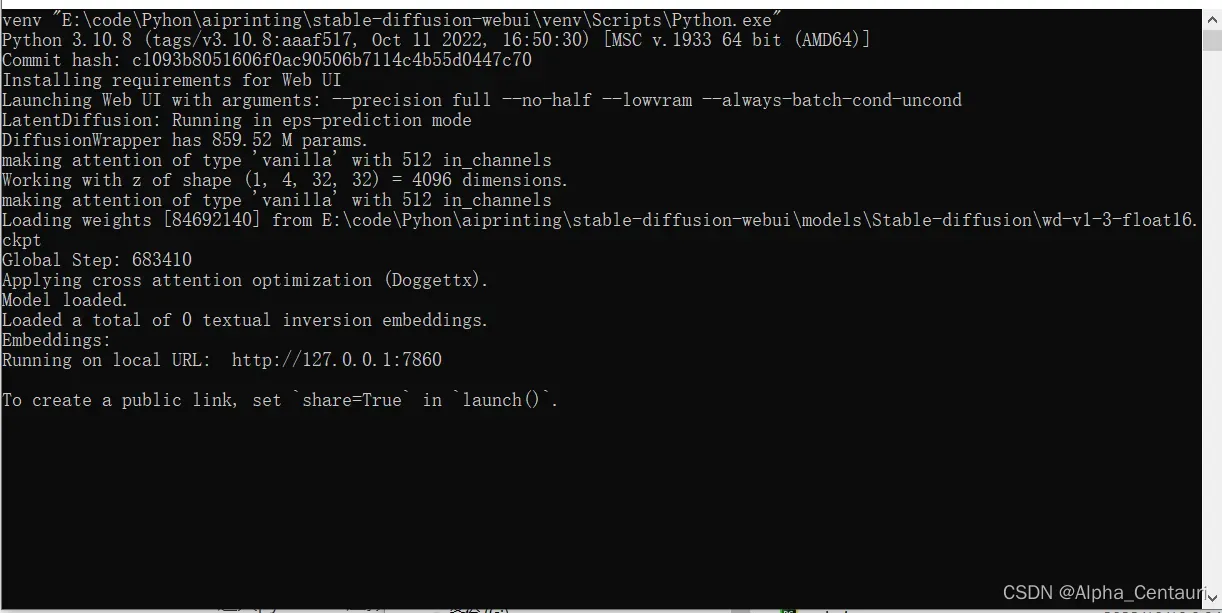
1.3 运行
1.3.1 在浏览器中输入 http://127.0.0.1:7860访问webui
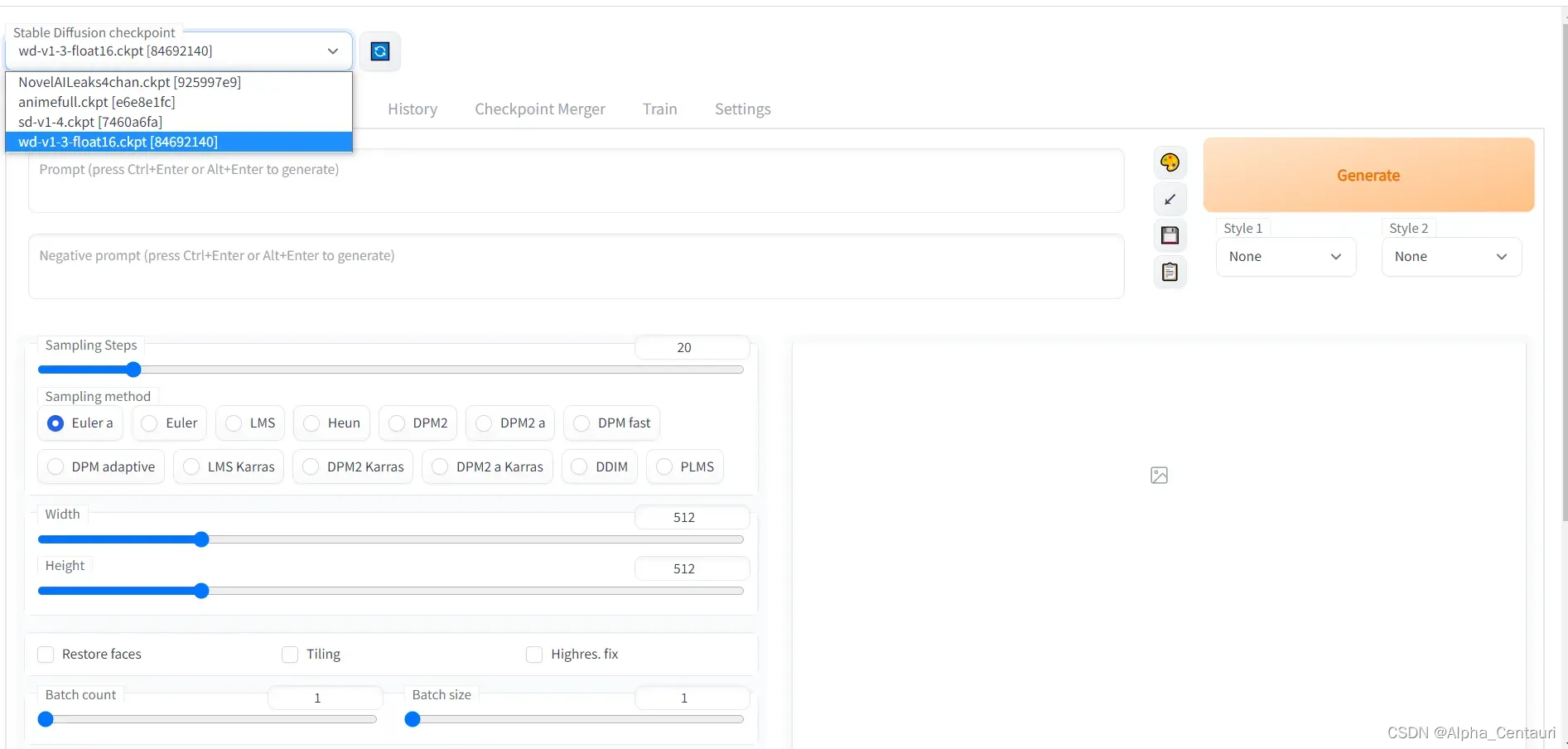
右上角为导入的cpkt模型文件选择
文字模板:(((masterpiece))),((best quality)), flat chest,((loli)),((one girl)),very long light white hair, beautiful detailed red eyes,aqua eyes,white robe, cat ears,(flower hairpin),sunlight, light smile,blue necklace,see-through,
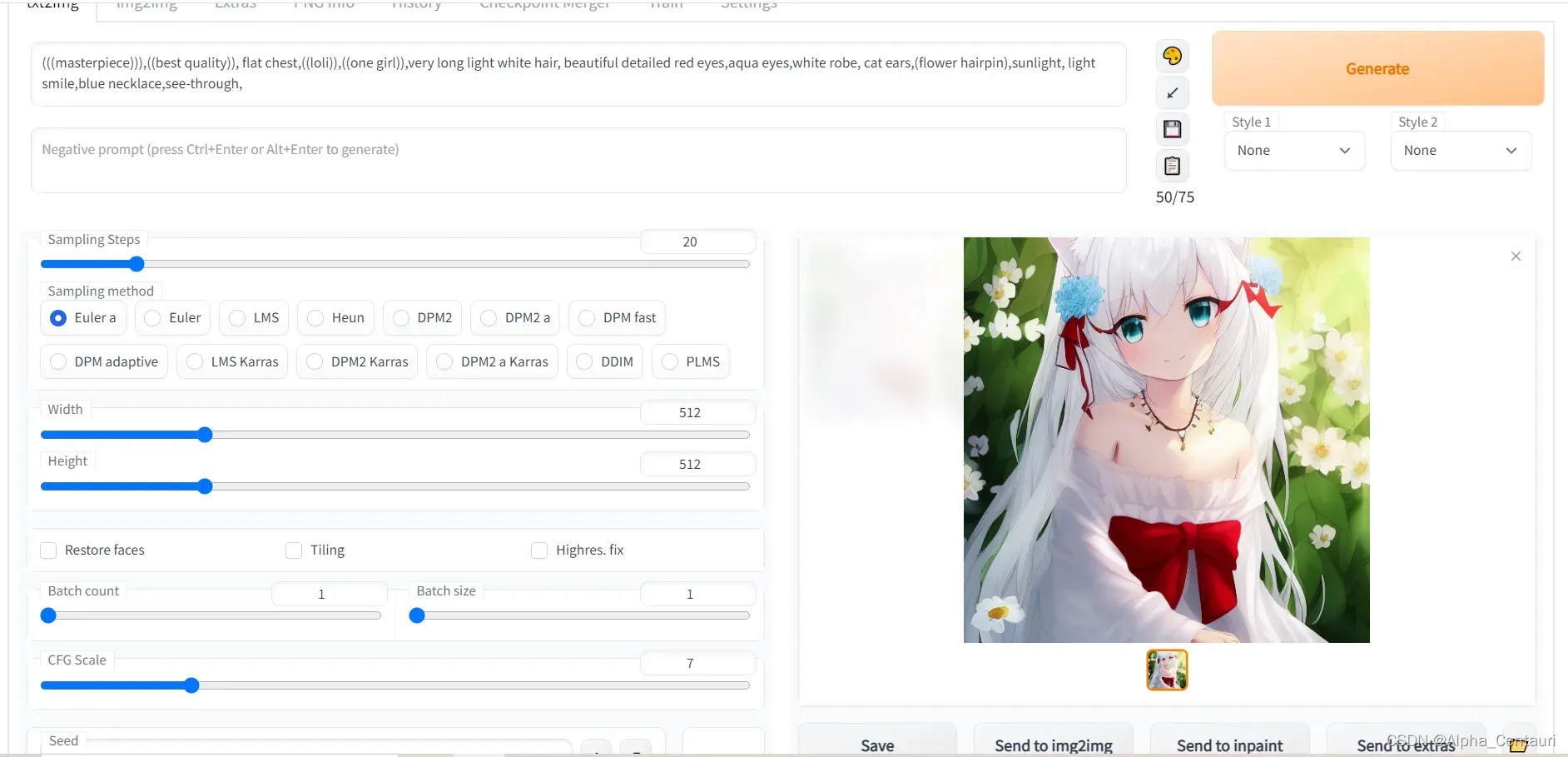
通过设置参数能够实现ai作图
1.4 参数说明
prompt 该部分主要就是对于图像进行描述,有内容风格等信息进行描述。后面的画板可以一些随机的风格、下面箭头是之前任务的参数;
Negative prompt 这个主要是提供给模型,我不想要什么样的风格;特别对于图上出现多个人的情况,就可以通过2girls等信息进行消除;
Sampling Steps diffusion model 生成图片的迭代步数,每多一次迭代都会给 AI 更多的机会去比对 prompt 和 当前结果,去调整图片。更高的步数需要花费更多的计算时间,也相对更贵。但不一定意味着更好的结果。当然迭代步数不足(少于 50)肯定会降低结果的图像质量;
Sampling method 扩散去噪算法的采样模式,会带来不一样的效果,ddim 和 pms(plms) 的结果差异会很大;
Width、Height 图像长宽,可以通过send to extras 进行扩大,所以这里不建议设置太大[显存小的特别注意];
Restore faces 优化面部,绘制面部图像特别注意;第一次使用要下载资源,比较大
Tiling 生成一个可以平铺的图像;
Highres. fix 使用两个步骤的过程进行生成,以较小的分辨率创建图像,然后在不改变构图的情况下改进其中的细节,选择该部分会有两个新的参数 Scale latent 在潜空间中对图像进行缩放。另一种方法是从潜在的表象中产生完整的图像,将其升级,然后将其移回潜在的空间。Denoising strength 决定算法对图像内容的保留程度。在0处,什么都不会改变,而在1处,你会得到一个不相关的图像;
Batch count、 Batch size 都是生成几张图,前者计算时间长,后者需要显存大;
CFG Scale 分类器自由引导尺度——图像与提示符的一致程度——越低的值产生越有创意的结果;
Seed 种子数;
Just resize、 Crop and resize、 Resize and fill 这三种模式保证图输出效果;
1.5 部分说明
16系显卡黑图和爆显存
解决方法:更改webui-user.bat文件中的set COMMANDLINE_ARGS= 的参数
4G显存:–precision full –no-half –lowvram –always-batch-cond-uncond
6G显存:–precision full –no-half –medvram
低于5G显存:–medvram
低于3G显存:–lowvram –always-batch-cond-uncond
cision full –no-half –medvram
低于5G显存:–medvram
低于3G显存:–lowvram –always-batch-cond-uncond
ai作图不是万能的,他只能根据预先训练出来的模型来作画。
stable diffusion只是工具,而不同的训练模型才是核心。
版权声明:本文为博主作者:Alpha_Centauri原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_45450338/article/details/127435343