目录
1. 概述
2. 一键起飞
2.1 webui
2.2 基础用法
2.3 必装插件
2.4 Fooocus
2.5 diffusers
3 LoRA
3.1 原理
3.2 训练流程和准备
3.3 上手训练
4. 深入原理
4.1 使用教程
4.2 原理
4.3 训练阶段
4.4 采样阶段
4.5 采样器
4.6 大模型微调
5. 部署
显存不足应对方案
6. 商业价值
美观性、风格化和可控性是时下流行的 文成图 面临的三座大山,所谓美观性,指的是符合美学规则,不能有脸部畸变、 手指扭曲等瑕疵;所谓风格化,指的是能生成动漫、二次元等多种多样的风格;所谓可控性,指的是可以自由的控制生成图片中人物的性别、年龄、质态、种族、服装以及场景、光线等的能力. SDXL在图像生成的精细度、真实性、提示词忠实度和准确性上都有显著的提高,而且再也不需要冗长的咒语才能生成差强人意的图片;LoRA仅需要数十张目标人物的图就可以高质量的生成特定人物;ControlNet大幅提升了对于姿态、线条等的控制能力. 一批批现象级应用涌现了出来,具体参见最全盘点!2023中国诞生了哪些AIGC应用产品


1. 概述
Stable Diffusion,简称SD,通过引入隐向量空间(而不是在像素空间扩散)来解决 Diffusion 速度瓶颈,除了可专门用于文生图任务,还可以用于图生图、特定角色刻画,甚至是超分或者修复任务。文生图模型参数量比较大,基于pixel的方法限于算力往往只能生成64×64大小的图像,比如OpenAI的DALL-E2和谷歌的Imagen,然后再通过超分辨模型将图像分辨率提升至256×256和1024×1024; 而基于latent的SD是在latent空间操作的,它可以直接生成256×256和512×512甚至更高分辨率的图像。基于latent的扩散模型的优势在于计算效率更高效,因为图像的latent空间要比图像pixel空间要小,这也是SD的核心优势。Stable Diffusion不仅是一个完全开源的模型(代码,数据,模型全部开源),而且它的参数量只有1B左右,大部分人可以在普通的显卡上进行推理甚至精调模型。毫不夸张的说,Stable Diffusion的出现和开源对AIGC的火热和发展是有巨大推动作用的,因为它让更多的人能快地上手AI作画。
Note: SD对硬件要求普遍较高,即使推理最好也要有8G以上的显存,具体性价比参见常见显卡AI跑图性能、性价比表
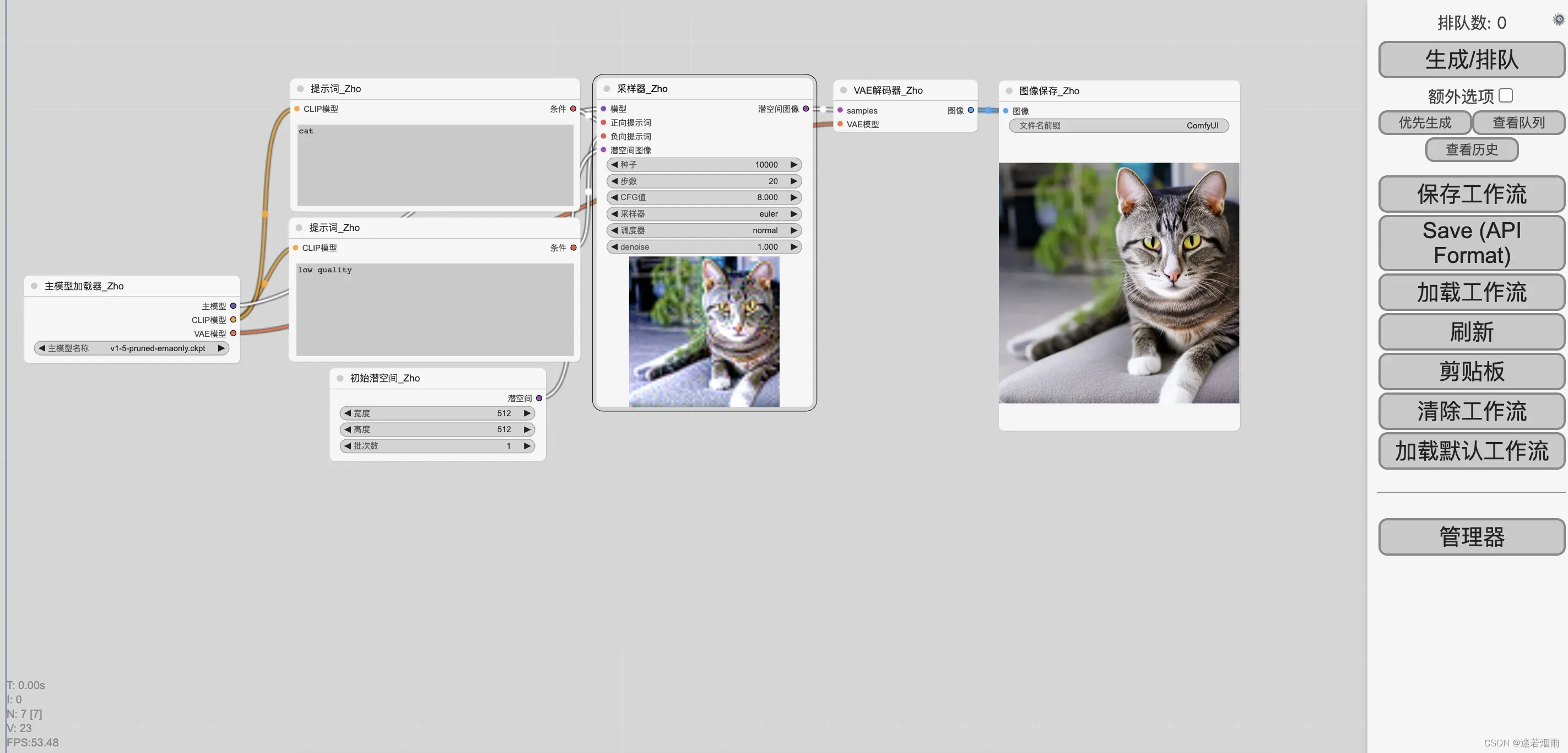
2. 一键起飞
2.1 webui
可参考浅谈【Stable-Diffusion WEBUI】(AI绘图)的基础和使用
Windows下推荐使用一键启动包 ,模型下载stable-diffusion-v1-5, 推荐模型majicMIX realistic 麦橘写实 更多模型选择参见Stablediffusion模型与模型训练背后的事
Ai绘画模型Chilloutmix详尽解说,关于模型的超详细小知识
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py310_23.3.1-0-Linux-x86_64.sh \
&& sh Miniconda3-py310_23.3.1-0-Linux-x86_64.sh -b -p /opt/conda
pip install diffusers transformers scipy ftfy accelerate
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui
cd stable-diffusion-webui
默认GPU运行
#python launch.py --listen --api --xformers --enable-insecure-extension-access
./webui.sh --listen --api --xformers --enable-insecure-extension-access
#如果没有GPU,也可以CPU运行
./webui.sh --listen --api --enable-insecure-extension-access --skip-torch-cuda-test --no-half --no-half-vae默认参数出来的效果差强人意,需要加入较多的”咒语”才能调出,可以切换到Chilloutmix-Ni-pruned-fp16-fix模型,设置如下参数,或者后面加入不同的Lora提升效果(模型下载链接参看全网Stable Diffusion WebUI Model模型资源汇总)
2.2 基础用法
通用起手式 三段式表达
第一段: 画质tag,画风tag
第二段:画面主体,主体强调,主体细节概括。(主体可以是人、事、物、景)画面核心内容
第三段:画面场景细节,或人物细节,embedding tag。画面细节内容
第二段一般提供人数,人物主要特征,主要动作(一般置于人物之前),物体主要特征,主景或景色框架等
质量词→前置画风→前置镜头效果→前置光照效果→(带描述的人或物AND人或物的次要描述AND镜头效果和光照)*系数→全局光照效果→全局镜头效果→画风滤镜
画质词:(masterpiece:1.2), best quality, highres,extremely detailed CG,perfect lighting,8k wallpaper,
真实系:photograph, photorealistic,
插画风:Illustration, painting, paintbrush,
二次元:anime, comic, game CG,
3D:3D,C4D render,unreal engine,octane render,负面词:NSFW, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)),((grayscale)), skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.5), (too many fingers:1.5), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
实例:
Prompt:masterpiece,beat quality,1girl
Negative Prompt:nsfw,blush,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name,bad feet,big head,fused body,multiple hands,multiple legs,multiple hands,multiple breast,multiple lower legs,multiple thighs,fused body,twist body
Steps: 40, Sampler: Euler a, CFG scale: 10




粗略的介绍一下对于大量prompt情况下的权重控制 – 哔哩哔哩
1.权重的用法涉及到构图和添加更多元素,如果有想要调整画面元素构成比的人,一定要先在prompt配置好权重方便后续调整。
2.不要出现拼写错误,比如:(extreme detailed night sky,:1.5)
3.如果括号包含了多内容,AI只关心末尾部分prompt权重,比如(crystal_plant,flower:1.3)实际上等效crystal_plant,(flower:1.3),而并不能把他们全都包含起来一起处理,正确的块处理方式是((promptA,promptB,promptC):1.1), 用括号把他们包起来当做结构块处理。4.颜色决定了构图,所以涉及颜色的权重最好固定死 或者不要有大幅度的改动,同样的,迭代次数也会影响色彩分布,有时候低迭代和高迭代会有构图的区别。
5.取值可以稍微的不合理,但是最好合理,比如身上的可爱蝴蝶大翅膀。
6.高的权重prompt并不会替代低权重prompt,只决定了你让AI更加去注意哪点。7.prompt靠前的也会提高权重,这和输入顺序以及神经网络构成相关,并没有详细的计算等值
SD出来图的经常出现脸部畸变、手指异位、模糊等瑕疵,对于要求不高的地方还能勉强使用,对于要求高的场景需要反复调试,这很考验经验和耐心,目前总结出的一些方法如下
- Adetailer治愈脸崩
- adetailer adetailer
- stablediffusion手指修复方法 各种手势姿态调整
- Stable diffusion生成细节度拉满的超高分辨率画面
2.3 必装插件
- 双语对照 bilingual-localization、localization-zh_CN
- C站助手 Civitai-Helper
- prompts-all-in-one 自动翻译、收藏提示词

4.图片管理工具、stable-diffusion-webui-images-browser
5. animatediff 文生视频


6.controlnet,ControlNet原理解析作用就是能够控制扩散模型,生成更接近用户需求的图,可以做到对线稿的上色以及照片转二次元人物等效果


ControlNet原理就是将模型原始的神经网络锁定,设为locked copy,然后将原始网络的模型复制一份,称之为trainable copy,在其上进行操作施加控制条件。然后将施加控制条件之后的结果和原来模型的结果相加获得最终的输出。

7.姿势编辑 openpose editor
8.真实人像写真 EasyPhoto SDWebui艺术照插件 妙鸭相机平替EasyPhoto教程
9. Additional Network对比不同LoRA模型效果
2.4 Fooocus
git clone https://github.com/lllyasviel/Fooocus.git
cd Fooocus
conda env create -f environment.yaml
conda activate fooocus
pip install -r requirements_versions.txt
python launch.py --listen浏览器打开 IP地址:端口7860(如果是本地,具体为127.0.01:7860)即可
2.5 diffusers
手写stable-diffusion – 知乎
import torch
from diffusers import StableDiffusionPipeline
#初始化SD模型,加载预训练权重
pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
pipe.safety_checker = None
pipe.requires_safety_checker = False
#使用GPU加速
pipe.to("cuda")
#如GPU的内存少于10GB,可以加载float16精度的SD模型
#pipe = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", revision="fp16", torch_dtype=torch.float16)
#接下来,我们就可以运行pipeline了
prompt = "masterpiece, beat quality, 1girl"
negative_prompt = "nsfw,blush,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name,bad feet,big head,fused body,multiple hands,multiple legs,multiple hands,multiple breast,multiple lower legs,multiple thighs,fused body,twist body"
image = pipe(prompt).images[0]
image.save("test.png", "png")LoRA Support in Diffusers
from diffusers import StableDiffusionPipeline
import torch
model_path = "sayakpaul/sd-model-finetuned-lora-t4"
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", torch_dtype=torch.float16)
pipe.unet.load_attn_procs(model_path)
pipe.to("cuda")
prompt = "A pokemon with blue eyes."
image = pipe(prompt, num_inference_steps=30, guidance_scale=7.5, cross_attention_kwargs={"scale": 0.5}).images[0]
image.save("pokemon.png")
3 LoRA
3.1 原理
LoRA(大模型的 低秩 适配器)是一种使用少量图像来训练模型的方法,它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层,极大地减少了下游任务的可训练参数的数量。不是大模型全局微调不起,只是LoRA更有性价比,教程已经准备好了,大模型参数量巨大,训练成本较高,当遇到一些下游细分任务时,对大模型进行全参训练性价比不高,同时这些下游细分任务的域比较好约束,我们可以使用SD模型+LoRA微调训练的方式,只训练参数量很小的LoRA,就能在下游细分任务中取得不错的效果. LoRA 的精妙之处在于,它相当于在原有大模型的基础上增加了一个可拆卸的插件,模型主体保持不变。LoRA 随插随用,轻巧方便。

LoRA 将权重变化的部分 ΔW 分解为低秩表示, 确切地说,它不需要显示计算 ΔW; 相反, LoRA 在训练期间学习 ΔW 的分解表示, 这就是 LoRA 节省计算资源的奥秘
如上所示,ΔW 的分解意味着我们需要用两个较小的 LoRA 矩阵 A 和 B 来表示较大的矩阵 ΔW。如果 A 的行数与 ΔW 相同,B 的列数与 ΔW 相同,我们可以将以上的分解记为 ΔW = AB。(AB 是矩阵 A 和 B 之间的矩阵乘法结果)
在使用 LoRA 时,我们假设模型 W 是一个具有全秩的大矩阵,以收集预训练数据集中的所有知识。当我们微调 LLM 时,不需要更新所有权重,只需要更新比 ΔW 更少的权重来捕捉核心信息,低秩更新就是这么通过 AB 矩阵实现的
LoRA的训练逻辑是首先冻结SD模型的权重,然后在SD模型的U-Net结构中注入LoRA模块,将其并与crossattention模块结合,并只对这部分参数进行微调训练。其是由两个低秩矩阵的乘积组成。由于下游细分任务的域非常小,所以可以取得很小,很多时候我们可以取d=1。因此在训练完成之后,我们可以获得一个参数量远小于SD模型的LoRA模型。通常来说,对于矩阵,我们使用随机高斯分布初始化,并对于矩阵使用全初始化,使得在初始状态下这两个矩阵相乘的结果为。这样能够保证在初始阶段时,只有SD模型(主模型)生效。

Step1: 冻结原模型(图中蓝色部分)
Step2: 训练微调两个小矩阵参数 A 和 B(图中橙色部分),可以理解为学习一个残差,只不过是通过矩阵分解的形式表达
Step3: 把模型参数矩阵相乘(BA)后,加到原来的模型参数上,形成新的模型
经过开源生态的持续验证,我们发现使用LoRA进行微调与SD模型全参微调的效果相差不大。LoRA成为了AIGC时代的“残差模块”,SD模型的“得力助手”,LoRA大幅降低了SD模型训练时的显存占用,因为并不优化主模型(SD模型),所以主模型对应的优化器参数不需要存储。但计算量没有明显变化,因为LoRA是在主模型的全参梯度基础上增加了“残差”梯度,同时节省了主模型优化器更新权重的过程深入浅出LoRA,完整核心基础解析, 具体代码实现参见stable-diffusion-webui源码分析(8)-Lora
LoRA具有如下优势:
- 与SD模型全参训练相比,LoRA训练速度更快,(几到几十分钟),使用少量图像(10多张),效果比较好。
- 非常低的算力要求。我们可以在2080Ti级别的算力设备上进行LoRA训练。
- 由于只是与SD模型的结合训练,LoRA本身的参数量非常小,最小可至3M左右。
- 能在小数据集上进行训练(10-30张),并且与不同的SD模型都能较好的兼容与迁移适配。
- 训练时主模型参数保持不变,LoRA能更好的在主模型的能力上优化学习。
但是需要注意
- 可以加载多个不同的LoRA模型配合不同的权重叠加使用。
- 目前SD-WEB UI还不能训练LoRA模型。
- 适合训练人物, 训练人物特征时,需要不同角度、姿态的数据20-40张就可以了,如果要训练风格或者画风,则需要150-200张风格图片,如果是训练一个抽象概念,则数据多多益善
- 通用:任何网络结构都可以利用 LoRA 的思路来进行微调
- 可移植:微调结束后,只需要让原模型参数+新矩阵乘积,即可得到新模型。并且可以通过+/-的操作,直接进行 LoRA 的迁移
- 推理性能不变:模型总参数量不变,推理性能不变(相比 ControlNet 等新增参数的结构相比)
3.2 训练流程和准备
全网罕见的真人LoRA模型的训练要诀 及参数详解_哔哩哔哩_bilibili


LoRA训练个人经验总结与复盘LORA模型训练超入门级教程
1. 确定目的 在训练LoRA模型之前,我们需要首先明确自己需要训练什么类型的LoRA,有的博主将模型分成了几个大类:人物角色、画风/风格、概念、服饰、物体/特定元素等
2. 收集素材 「大模型的选择」和「图片质量」都是收集素材的关键!在具象训练中并不是素材越多越好,一般建议20张左右即可;素材要求:不同角度,不同背景,不同姿势,不同服饰,清晰无遮挡的图片
3. 处理素材 主要包括统一素材尺寸、生成标签和优化标签
有两种生成标签的方式:BLIP即自然语言标签,比如“1个女孩在草地上开心的跳舞”;Deepbooru即词组标签(常用),比如“1个女孩,草地,跳舞,大笑”。
优化标签一般有两种方式:1)保留全部,不做删减,用此方法比较方便,但是需要用精准的关键词,才能还原想要的效果;2)删除部分特征标签,删减掉训练风格或者需要生成内容的相关。比如要生成「手绘插画」的LoRA模型,就需要保留图片素材中手绘插画风格相关的内容作为自带特征,那么就将与手绘插画相关的词语标签删除,增加触发词“shouhui或者chahua”。将“shouhui或者chahua”触发词与其风格相关的词关联,当你填写触发词后就会自带此风格
批量修改关键词的工具BooruDatasetTagManager,很多大佬推荐过,界面比较原始,好用的点是可以批量增删改查关键词,并且可以通过调整关键词位置来调整权重。当然你也可以使用VsCode,或者直接用txt调整都可以
4. 调整参数/开始训练
3.3 上手训练
脚本训练:🔗https://github.com/Akegarasu/lora-scripts
GUI训练:🔗https://github.com/bmaltais/kohya_ss
实际上都是调用的kohya_ss的sd-scripts项目,比较倾向用脚本那个项目lora-scripts来训练写配置文件反而比较简单,WEB界面在训练这块用处不大
- lora-scripts 这个项目是在sd-scripts 项目的外面包了一层,目的是让 sd-scripts 更加易用
- sd-scripts 提供了更加灵活的功能,如:训练 lora、训练 dreambooth、训练 test-embedding、指定训练 UNet 或 Text Encoder、图像生成、模型转换等多种能力
- lora-scripts 调用了 sd-scripts 中的训练 lora 训练的脚本,但是把很多的设置、参数等进行了说明和整理,且顺便带了 tensorbord 的功能,让用户能够一键完成环境配置
看一下LoRAModule的__init__函数内部,是如何创建一个 lora 的。实际上就是针对原始模型中每一个层,都创建两个全连接层(就是 lora)

LoRA训练参数解析
| 参数名 | 含义 |
| resolution | 训练时喂入网络的图片大小,默认值为512 |
| validation & save steps | 验证图片与保存中间权重的steps数,默认值为100,代表每100步验证一次图片并保存权重 |
| max train steps | 最大训练步数,默认值为800 |
| max steps per photos | 每张图片的最大训练次数,默认为200 |
| train batch size | 训练的批次大小,默认值为1 |
| gradient accumulationsteps | 是否进行梯度累计,默认值为4,结合train batch size来看,每个Step相当于喂入四张图片 |
| dataloader num workers | 数据加载的works数量,windows下不生效,因为设置了会报错,Linux正常设置 |
| learning rate | 训练Lora的学习率,默认为1e-4 |
| rank Lora | 权重的特征长度,默认为128 |
| network alpha | Lora训练的正则化参数,一般为rank的二分之一,默认为64 |
关于【SD-WEBUI】的LoRA模型训练:怎样才算训练好了?
git clone --recurse-submodules https://github.com/Akegarasu/lora-scripts
修改train.sh里面的内容
$pretrained_model :基础模型路径(最好填入WEB UI下的绝对路径,避免拷贝几个GB的数据)
$train_data_dir :训练数据集路径(预处理完成的图片和提示词存放目录)
$resolution :分辨率(需要多少预处理成多少,填写一致)
$max_train_epoches :最大训练 epoch (1个epoch是一个完整的数据集通过神经网络一次并且返回一次的过程)
$save_every_n_epochs :每几个 epoch 保存一次
$output_name :模型保存名称

4. 深入原理
全网最简单的扩散模型DDPM教程、DDPM = 拆楼 + 建楼、深入浅出理解DDPM推导过程、【diffusion】扩散模型详解!原理+代码!
前向过程(扩散)
前向过程(forward process)又称为扩散过程(diffusion process),简单理解就是对原始图片 x0通过逐步加高斯噪声变成xt,从而达到破坏图片的目的,如下图


反向过程(去噪)
反向过程就是通过估测噪声,多次迭代逐渐将被破坏的xt恢复成x0,如下图


如何训练(获得噪声估计模型)

训练过程如下图描述


4.1 使用教程
- 关于【Stable-Diffusion WEBUI】方方面面研究
- 深入浅出讲解Stable Diffusion原理,新手也能看明白
- Diffusion Model原理详解及源码解析 代码Diffusion-Models-pytorch
- 深入浅出,Stable Diffusion完整核心基础讲解
- 细数【SD-WEBUI】的模型:谁是最适合的模型&从哪里找到它们
- 喂饭级stable_diffusion_webUI调参权威指南
- Stable Diffusion WebUI 小指南 – X/Y/Z Plot
- 超细!5000字详解AI绘画图生图干货、技巧,教程、学习分享
- Stable Diffusion 模型格式及其相关知识全面指南
- 从耗时看Stable Diffusion WebUI中的采样方式
- 教会你使用AI绘画利器Stable Diffusion
4.2 原理
AI艺术的背后:详解文本生成图像模型
AE: 自编码器由编码器以及解码器组成,其首先对图像进行压缩,之后,在对压缩后的表征进行重建。在实际应用中,自编码器往往会被用于降维,去噪,异常检测或者神经风格迁移中.
VAE 不再去学习一个连续的表征,而是直接学习一个分布,然后通过这个分布采样得到中间表征去重建原图, 其假设中间表征是一个正态分布,因此,编码器部分需要将原图 映射为正态分布 ,通过重参数技巧,得到采样后的中间表征。紧接着,解码器通过中间表征 z 进行解码操作,得到原图的重建.
VQ-VAE: VAE 具有一个最大的问题就是使用了固定的先验(正态分布),其次是使用了连续的中间表征,这样会导致图片生成的多样性并不是很好以及可控性差。为了解决这个问题,VQ-VAE( Vector Quantized Variational Autoencoder) 选择使用离散的中间表征,同时,通常会使用一个自回归模型来学习先验(例如 PixelCNN 或者 Transformer)。在 VQ-VAE 中,其中间表征就足够稳定和多样化,从而可以很好的影响 Decoder 部分的输出 ,帮助生成丰富多样的图片。因此,后来很多的文本生成图像模型都基于 VQ-VAE
DALL-E 由 OpenAI 开发,是当前非常流行的文本生成图像模型之一. DALL-E 模型中的生成模块使用的是 VQ-VAE,不同的是,其先验的学习,使用的是文本到中间离散表征的映射,最大的特色是对语义的理解非常出色,以及可以生成各种非常规但是又符合语义信息的图像
GAN 由两个主要的模块构成:生成器和判别器。生成器负责生成一张图片,而判别器则负责判断这张图片质量,也就是判断是真实样本还是生成的虚假样本,通过逐步的迭代,左右互博,最终生成器可以生成越来越逼真的图像,而判别器则可以更加精准的判断图片的真假。最大优势是其不依赖于先验假设,而是通过迭代的方式逐渐学到数据的分布。GAN在训练时要同时训练生成器与判别器,所以其训练难度是比较大的
Diffusion Model 上文提到的 VQ-VAE 以及 VQ-GAN,都是先通过编码器将图像映射到中间潜变量,然后解码器在通过中间潜变量进行还原。实际上,扩散模型做的事情本质上是一样的,不同的是,扩散模型完全使用了全新的思路来实现这个目标。在扩散模型中,主要有两个过程组成,前向扩散过程,反向去噪过程,前向扩散过程主要是将一张图片变成随机噪音,而逆向去噪过程则是将一张随机噪音的图片还原为一张完整的图片
DALL-E2 是 OpenAI 最新 AI 生成图像模型,其最大的特色是模型具有惊人的理解力和创造力, 其参数大约 3.5B , 相对于上一代版本,DALL-E2 可以生成4倍分倍率的图片,且非常贴合语义信息.DALL-E2 由三个模块组成: CLIP模型,对齐图片文本表征;先验模型,接收文本信息,将其转换成 CLIP 图像表征;扩散模型,接受图像表征,来生成完整图像
Imagen 的图像生成流程和 DALL-E2 非常像,首先将文本进行编码表征,之后使用扩散模型将表征映射成为完整图像,同时会通过两个扩散模型来进一步提高分辨率。与 DALL-E2 不同的是,Imagen 使用了 T5-XXL 模型直接编码文本信息,然后使用条件扩散模型,直接用文本编码生成图像。因此,在 Imagen 中,无需学习先验模型
Stable Diffusion 是由 Stability.ai 于近期开放的文本生成图像模型,由于其交互简单,生成速度快,极大的降低了使用门槛,而且同时还保持了令人惊讶的生成效果. 它是基于之前 Latent Diffusion 模型进行改进的,上文中提到的扩散模型的特点是反向去噪过程速度较慢,其扩散过程是在像素空间进行,当图片分辨率变大时,速度会变得非常慢。而 Latent Diffusion 模型则考虑在较低维度的潜在空间中,进行扩散过程,这样就极大的减轻了训练以及推理成本

十分钟读懂Stable Diffusion运行原理
文生图模型之Stable Diffusion
SD模型的主体结构如下图所示,主要包括三个模型:
- autoencoder:encoder将图像压缩到latent空间,而decoder将latent解码为图像;
- CLIP text encoder:提取输入text的text embeddings,通过cross attention方式送入扩散模型的UNet中作为condition;采用CLIP text encoder来对输入text提取text embeddings,具体的是采用目前OpenAI所开源的最大CLIP模型:clip-vit-large-patch14,这个CLIP的text encoder是一个transformer模型(只有encoder模块):层数为12,特征维度为768,模型参数大小是123M。对于输入text,送入CLIP text encoder后得到最后的hidden states(即最后一个transformer block得到的特征),其特征维度大小为77×768(77是token的数量),这个细粒度的text embeddings将以cross attention的方式送入UNet中
- UNet:扩散模型的主体,用来实现文本引导下的latent生成。SD的扩散模型是一个860M的UNet,其中encoder部分包括3个CrossAttnDownBlock2D模块和1个DownBlock2D模块,而decoder部分包括1个UpBlock2D模块和3个CrossAttnUpBlock2D模块,中间还有一个UNetMidBlock2DCrossAttn模块。encoder和decoder两个部分是完全对应的,中间存在skip connection。注意3个CrossAttnDownBlock2D模块最后均有一个2x的downsample操作,而DownBlock2D模块是不包含下采样的

SD的训练是多阶段的(先在256×256尺寸上预训练,然后在512×512尺寸上精调),不同的阶段产生了不同的版本:
- SD v1.1:在laion2B-en数据集上以256×256大小训练237,000步,上面我们已经说了,laion2B-en数据集中256以上的样本量共1324M;然后在laion5B的高分辨率数据集以512×512尺寸训练194,000步,这里的高分辨率数据集是图像尺寸在1024×1024以上,共170M样本。
- SD v1.2:以SD v1.1为初始权重,在improved_aesthetics_5plus数据集上以512×512尺寸训练515,000步数,这个improved_aesthetics_5plus数据集上laion2B-en数据集中美学评分在5分以上的子集(共约600M样本),注意这里过滤了含有水印的图片(pwatermark>0.5)以及图片尺寸在512×512以下的样本。
- SD v1.3:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上继续以512×512尺寸训练195,000步数,不过这里采用了CFG(以10%的概率随机drop掉text)。
- SD v1.4:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512×512尺寸训练225,000步数。
- SD v1.5:以SD v1.2为初始权重,在improved_aesthetics_5plus数据集上采用CFG以512×512尺寸训练595,000步数。
其实可以看到SD v1.3、SD v1.4和SD v1.5其实是以SD v1.2为起点在improved_aesthetics_5plus数据集上采用CFG训练过程中的不同checkpoints,目前最常用的版本是SD v1.4和SD v1.5。 SD的训练是采用了32台8卡的A100机器(32 x 8 x A100_40GB GPUs),所需要的训练硬件还是比较多的,但是相比语言大模型还好。单卡的训练batch size为4,并采用gradient accumulation,其中gradient accumulation steps=2,那么训练的总batch size就是32x8x2x4=2048。训练优化器采用AdamW,训练采用warmup,在初始10,000步后学习速率升到0.0001,后面保持不变。至于训练时间,文档上只说了用了150,000小时,这个应该是A100卡时,如果按照256卡A100来算的话,那么大约需要训练25天左右。
4.3 训练阶段
- 使用 AutoEncoderKL 自编码器将图像 Image 从 pixel space 映射到 latent space,学习图像的隐式表达,注意 AutoEncoderKL 编码器已提前训练好,参数是固定的。此时 Image 的大小将从
[B, C, H, W]转换为[B, Z, H/8, W/8],其中Z表示 latent space 下图像的 Channel 数。这一过程在 Stable Diffusion 代码中被称为encode_first_stage; - 使用 FrozenCLIPEmbedder 文本编码器对 Prompt 提示词进行编码,生成大小为
[B, K, E]的 embedding 表示(即context),其中K表示文本最大编码长度 max length,E表示 embedding 的大小。这一过程在 Stable Diffusion 代码中被称为get_learned_conditioning; - 对图像的隐式表达进行不断加噪进行前向扩散过程(Diffusion Process),之后对加噪后的图像调用 UNetModel 对噪声进行预估;UNetModel 同时接收图像的隐式表达 latent image 以及文本 embedding
context,在训练时以context作为 condition,使用 Attention 机制来更好的学习文本与图像的匹配关系; - 扩散模型输出噪声 ϵθ,计算和真实噪声之间的误差作为 Loss,通过反向传播算法更新 UNetModel 模型的参数,注意这个过程中 AutoEncoderKL 和 FrozenCLIPEmbedder 中的参数不会被更新。
4.4 采样阶段
- 使用 FrozenCLIPEmbedder 文本编码器对 Prompt 提示词进行编码,生成大小为
[B, K, E]的 embedding 表示(即context); - 随机产出大小为
[B, Z, H/8, W/8]的噪声 Noise,利用训练好的 UNetModel 模型,按照 DDPM/DDIM/PLMS 等算法迭代 T 次,将噪声不断去除,恢复出图像的 latent 表示; - 使用 AutoEncoderKL 对图像的 latent 表示(大小为
[B, Z, H/8, W/8])进行 decode(解码),最终恢复出 pixel space 的图像,图像大小为[B, C, H, W]; 这一过程在 Stable Diffusion 中被称为decode_first_stage。
35张图,直观理解Stable Diffusion The Illustrated Stable Diffusion
Diffusion扩散模型学习1——Pytorch搭建DDPM实现图片生成 ddpm-pytorch
Diffusion扩散模型学习2——Stable Diffusion结构解析
Stable Diffusion 原理介绍与源码分析(一)
Stable Diffusion结构解析-以文本生成图像(文生图,txt2img)为例
4.5 采样器
stable-diffusion-webui源码分析(9)-euler a 采样器
DDPM、DDIM、PLMS算法分析
Stable Diffusion-采样器篇
- Euler采样器:欧拉采样方法。
- Heun采样器:欧拉的一个更准确但是较慢的版本。
- LMS采样器:线性多步法,与欧拉采样器速度相仿,但是更准确
名称中带有a标识的采样器表示这一类采样器是祖先采样器。这一类采样器在每个采样步骤中都会向图像添加噪声,采样结果具有一定的随机性。
带有Karras字样的采样器,最大的特色是使用了Karras论文中建议的噪音计划表。主要的表现在于噪点步长在接近尾声时会更小,有助于图像的质量提升
DPM会自适应调整步长,不能保证在约定的采样步骤内完成任务,整体速度可能会比较慢。对Tag的利用率较高,在使用时建议适当放大采样的步骤数以获得较好的效果。
DPM++是对DPM的改进,DPM2采用二阶方法,其结果更准确,但是相应的也会更慢一些
1.如果只是想得到一些较为简单的结果,选用欧拉(Eular)或者Heun,并可适当减少Heun的步骤数以减少时间
2.对于侧重于速度、融合、新颖且质量不错的结果,建议选择:
- DPM++ 2M Karras, Step Range:20-30
- UniPc, Step Range: 20-30
3. 期望得到高质量的图像,且不关心图像是否收敛:
- DPM ++ SDE Karras, Step Range:8-12
- DDIM, Step Range:10-15
4. 如果期望得到稳定、可重现的图像,避免采用任何祖先采样器


euler和euler a采样器实现上的区别
4.6 大模型微调
要训练自己数据最直观的方法,就是把自己的图片加入模型迭代时一起训练。但会带来两个问题,一个是过拟合,另一个是语言漂移(language drift)。而Dreambooth的优势就在于能避免上述的两个问题
- 可以用一个罕见的词来代表图片的含义,保证新加入的图片对应的词在模型中没有太多的意义
- 为了保留类别的含义,例如上图中的“狗”,模型会在狗的类别基础上微调,并保留对应词的语义,例如给这只狗取名为”Devora”, 那么生成的”Devora”就会特指这只狗。
区别于textual inversion方法,Dreambooth使用的是一个罕见的词,而textual inversion使用的是新词。Dreambooth会对整个模型做微调,而textual inversion只会对text embedding部分调整
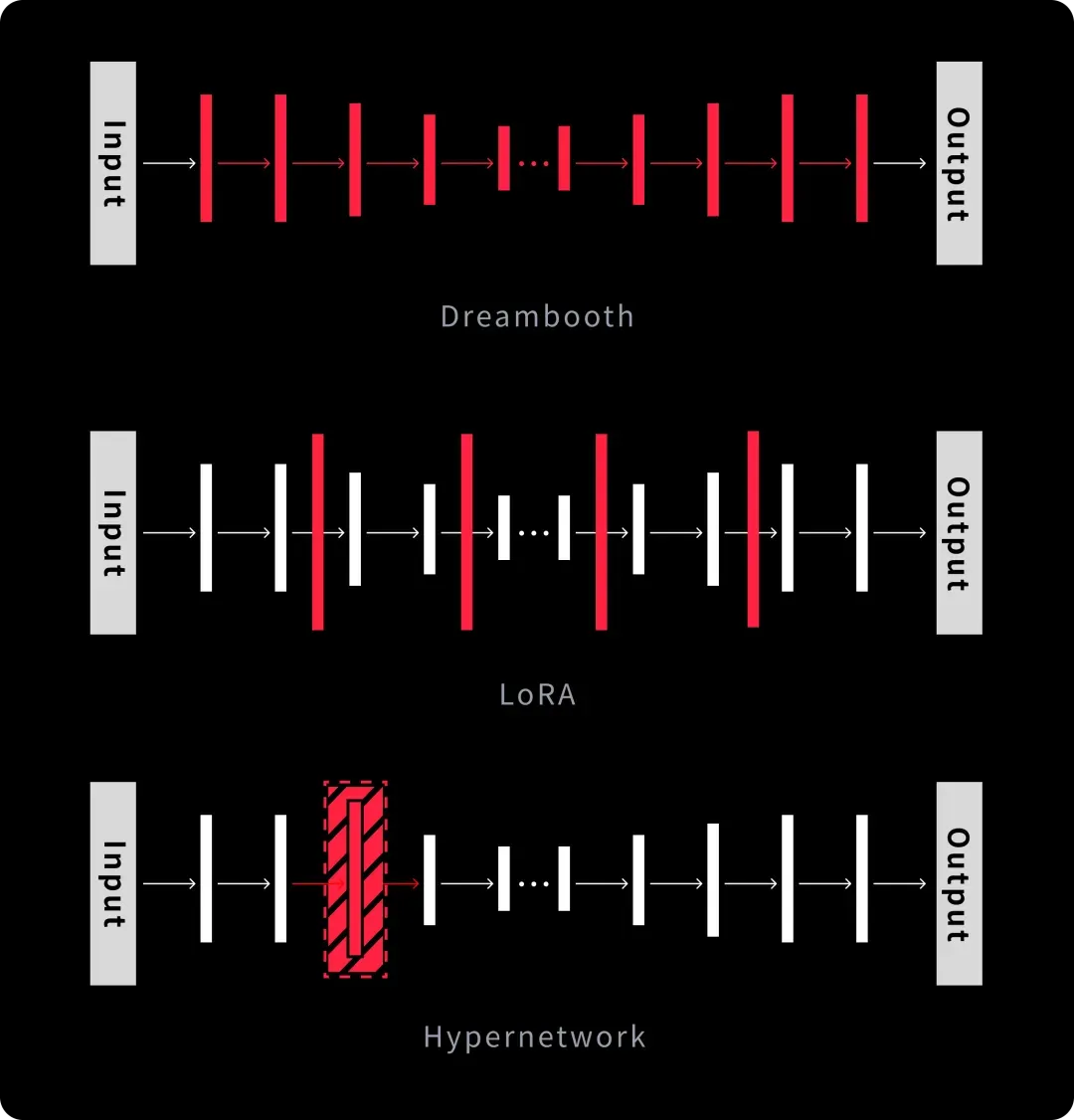
常见的大模型微调技术就是以下这四个:LoRA vs Dreambooth vs Textural Inversion vs Hypernetworks
| 训练方式 | 输出大小(MB) | 所需最小显存(GB) | 训练用时(分钟) |
|---|---|---|---|
| Dreambooth | 2000 | 8.0 | 45 |
| Hypernetwork | 114 | 8.0 | 70 |
| Textual Inversion | 0.0013 | 8.0 | 60 |
| LoRA | 145 | 7.0 | 15 |
google在2022年8月提出的一种新的图像算法,其方法可以完整的获得你想要的模型的视觉特征,它的提出既不是为了训练人物也不是为了训练画风,而是为了能在少量训练图像的基础上完美的还原细节特征。 Dreambooth要求我们在训练过程中,“特征词+类别”和“类别”成对出现,解决过拟合的问题,虽然叫大模型微调技术,但是他调得一点都不微,他基本把UNET算法的每一层内部参数都调了一遍
Dreambooth优点是:可以将视觉特征完美融入;
Dreambooth缺点是:需要调整UNet所有内部参数,训练时间长,模型体积大。
数据
- 3-10张图片, 最好是不同角度,且背景有变化的图片
- 独特的标识符(unique identifier)
- 类的名字(class name)

1. 给训练图片添加n步噪声,使其变成较为嘈杂的图片(测试图左侧的噪声图)。【即正向Diffusion过程,详见Stable Diffusion原理简介】
2. 另外再给训练图片添加较少一点的噪声(n-1),使其成为一张校准图片(测试图右侧的图片)。
3. 然后我们来训练SD模型以左侧较嘈杂的图片作为输入,再加上特殊关键词指令的输入,能输出右侧较为清晰的图片。
4. 一开始,由于模型可能根本就不识别新增的特殊关键词SKS,他可能输出了一个不是很好的结果。此时我们将该结果与目标图片(右侧较少噪声的图片)进行比较,得出一个loss结果,用以描述生成图像与目标图像的差异程度。
5. 接着Dreambooth会做一步被称为Gradient Update的事情。有关Gradient Update的事情实在是过于复杂了,你可以简单理解为,如果Loss高的话它将惩罚模型,如果Loss低的话它将奖励模型。
6. 当训练重复了一段时间后,整个模型会逐渐认识到:当它收到SKS的词语输入时,生成的结果应该看起来比较像训练者所提供的柯基犬的图片,由此我们便完成了对模型的调校
综上所述
Dreambooth相当于是把unet里的每一层函数都要进行微调,所以我们说它计算量大,训练时间长,模型体积大。但是LoRA就不同了,LoRA旨在减少模型的训练参数,提升模型训练效率;LoRA建议冻结预训练模型的权重,并将训练参数注入到Transformar函数架构的每个层中,他的优点就是不破坏原有模型,即插即用。
正因为LoRA他的插入层较少,他相较于Dreambooth,可以把训练参数降低1000倍,对CPU的要求也会下降三倍,所以训练出来的LoRA模型就会非常小,一般大家在C站下载过就知道,往往他们只有几十m,而一个大模型往往有几个g,所以他在我们日常工作中变得非常常用。可以简单理解Lora是在原有模型上添加一个“滤镜”,让这个底模往我们期望的效果走
Dreambooth调整了整个UNET的函数和参数,所以他体积最大,适用范围最全,但是训练难度和训练耗时和成本最大。
LoRA只将训练参数注入到了部分Transformar函数中,所以他不改变原模型,即插即用,模型大小也可控,是我们后续学习的重点。
而Hypernetwork是新建了一个单独的神经网络模型,插入到原UNet模型的中间层。在训练过程中,冻结所有参数,只训练插入部分,从而使输出图像与输入指令之间产生关联关系,同时只改变原模型的一小块内容, 这种方法更适合用于训练某种画风.
5. 部署
stable-diffustion-webui 超网络模型训练经验
第一步:制作训练集
搜集素材
首先需要准备合适的素材作为训练数据。你需要:
搜集尽可能高质量的图片(质量非常关键!)
剔除有文字、上色不佳、质量不佳、风格不统一等任何问题的图片。
剔除任何存在不想要的元素的图片,或者可以修一下图
图片的分辨率不要低于训练分辨率(也就是 512×512,长宽都不能低于这个值)
最终的素材集不需要很大,只要有几十到一百来张图就足够训练了。这是整个训练过程中最繁琐和费劲的工作,但不要偷懒哦(否则根本就炼不出好模型)。预处理
这一步要将素材图片裁成 512×512 分辨率的方形图片用作训练数据。不要使用其他任何分辨率,那样会增加失真(这个我没有验证)
Gradio:轻松实现AI算法可视化部署
waifu-diffusion 多卡推理+界面优化
stable-diffusion-webui源码分析
显存不足应对方案
显卡跑图慢,等待时间长,一直是众多AI绘画玩家的“痛点”。 这次,老黄亲自下场,用自家强大的TensorRT推理库,给Stable Diffusion WebUI打了一剂强心针 TensorRT扩展地址:WebUI-TensorRT 显卡速度翻3倍,AI绘画进入“秒速时代”?Stable Diffusion究极加速插件,NVIDIA TensorRT扩展安装与使用全方位教程
TensorRT在使用上的主要特点是用降低精度的办法来提升推理速度。TensorRT不局限于显卡的次代,40系、30系、20系、10系、V100、A5000等都可以用,但由于TensorRT是NVIDIA开发团队的作品,A卡用户请直接划走。目前TensorRT可以在精度丢失不大的前提下,大幅提高推理速度,带来的最直接好处就是可以海量出图;但从TensorRT的工作机制上来说,它的缺点在于,要使用TensorRT加速,就需要先对原模型进行“重新编译”,生成TensorRT模型(简称TRT模型),而且,它针对的每一个打算使用的模型,即一个SD模型对应一个TRT模型。尽管TRT模型生成成功后是一劳永逸的(跨硬件设备不行),但是在生成过程中经常会报错,无法顺利转化为TRT模型(比如缺少特定的节点算子)。结论:就当前形势来说,对于出图速度很慢的用户(如10系、20系显卡用户)、需要海量出图的用户、爱折腾新工具的用户,建议可以尝试TensorRT的加速功能,对于热衷模型训练、Lora生成、以及仍在用提示词探索模型出图效果等用户,建议再等等使用TensorRT工具。
本来100张50秒,是正常速度,为什么现在大家就觉得快了呢?
这就是NV搞的一个极为恶心的操作,整个事情在github的SD webui讨论区置顶就有。
具体就是在你升级NV驱动531.61之后的版本,会发现生成速度大幅降低了,原因是NV增加了AI绘图进程中显存不足时对虚拟显存(内存)的调用。玩过3D渲染的应该都知道,同样一张渲染,不爆显存1分钟,爆显存之后半小时都很正常。这就是因为显卡和内存之间的带宽还是低了,数据交互全卡在这个瓶颈了。
更恶心的是这个操作增加了显存的占用,让原来不会爆显存的生成也爆显存了。
NV这么做必然是出于某种商业目的(比如对于多卡的服务器来说),但跟咱们玩家用SD webui应该没有太大关系。
tensorRT在处理大型并发生成上有优势,但对于主要瓶颈是显存的个人电脑,相比xformer等已经存在的corss-attention解决方案并没有任何优势。
AI绘画⌈奇巧淫记⌋——低显存也能制作高清美图 – 知乎
6. 商业价值
AIGC图像生成的原理综述与落地畅想
浅谈一些AIGC赚钱赛道
1. AIGC一定是历史的必然节点。因为它提升了信息生产的效率,让内容的创作变得简单和无门槛
2. 商业机会并不在技术本身,而在于依托于技术基础之上的人、社会、生态和模式。技术起到的是一个将红利自动化、规模化的杠杆作用3. AI作画对艺术界产生了巨大冲击,也催生出了AI辅助创作这一新兴领域的发展
如何优雅的下载huggingface-transformers模型
版权声明:本文为博主作者:迷若烟雨原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/minstyrain/article/details/130289285