前言:
经典机器学习入门项目,使用逻辑回归、线性判别分析、KNN、分类与回归树、朴素贝叶斯、向量机、随机森林、梯度提升决策树对不同占比的训练集进行分类
原文摘要:
数据源:Iris Species | Kaggle
150行,5列,分三种鸢尾花类型,每种类型50个样本,每行数据包含花萼长度、花萼宽度、花瓣长度、花瓣宽度4个特征的信息
data:记录4个特征的信息和鸢尾花类型
target:以数值的形式记录鸢尾花的种类(0、1、2)
target_names:鸢尾花的种类名称,山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)、维吉尼亚鸢尾(Iris-virginica)
DESCR:备注信息
feature_names:鸢尾花的特征名称,sepal length (cm)、sepal width (cm)、petal length (cm)、petal width (cm),分别对应花萼长度、花萼宽度、花瓣长度、花瓣宽度4个特征
代码思路
特征相关性观察
训练模型
模型导入
字典形式引用模型
设置训练集占比
train_test_split
KFold
estimator.fit
cross_val_score
accuracy_score
可视化不同训练集比例评估各模型的得分
基础设置
画布设置
生成子图表
特征相关性观察
通过散点矩阵图观察到,鸢尾花的花瓣长度和宽度对鸢尾花类型偏正相关一点
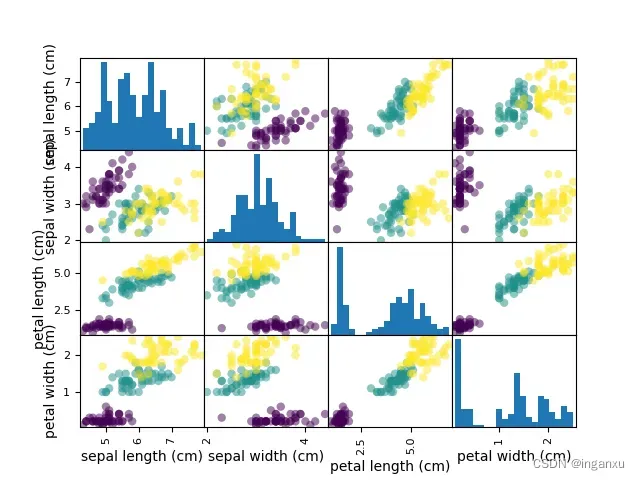
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pd
iris = load_iris()
# 散点矩阵图,看各特征之间的相关性
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
scatter_corr = pd.plotting.scatter_matrix(iris_df, marker='o', c=iris.target, hist_kwds={'bins': 20})
# plt.show()参考文章:pandas库scatter_matrix绘图可视化参数详解-CSDN博客
训练模型
模型导入
- 逻辑回归:是一种线性模型,常用于二元分类问题。
- 线性判别分析 (LDA):是一种统计模型,用于分类和判别分析。
- KNN :是一种基于实例的学习算法,在训练数据集中存储实例,并使用这些实例来进行分类。
- 决策树:是一种树形结构,使用训练数据集中的特征对实例进行分类。
- 朴素贝叶斯分类器:是一种基于贝叶斯定理的分类器,常用于文本分类。
- 支持向量机 (SVM):是一种二分类模型,通过创建一个超平面将数据划分为两个类别。
- 随机森林:是一种集成学习模型,通过构建多个决策树并取其输出的平均值来进行分类。
- 梯度提升决策树:也属于决策树的一种,通过迭代训练多个决策树并取其输出的平均值来进行分类。
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier字典形式引用模型
以字典的形式存储模型后续通过循环迭代的方式,应用每个模型在数据集中
models = {}
models["LR"] = LogisticRegression(max_iter=1000) # 逻辑回归
models["LDA"] = LinearDiscriminantAnalysis() # 线性判别分析
models["KNN"] = KNeighborsClassifier() # KNN最近邻
models["CART"] = DecisionTreeClassifier() # 分类与回归树
models["NB"] = GaussianNB() # 朴素贝叶斯
models["SVM"] = SVC() # 向量机
models["RF"] = RandomForestClassifier(n_estimators=100) # 随机森林
models["GBDT"] = GradientBoostingClassifier() # 梯度提升决策分类设置训练集占比
建立空列表是为了后续可视化的时候使用(X轴为模型名称、Y轴为模型得分)
model_score_list = [[], [], [], []] # 用来装模型在验证集上的得分
test_score_list = [[], [], [], []] # 用来装模型在测试集上的得分
size=[0.6,0.7,0.8,0.9] # 训练集比例train_test_split
本文用四个不同的训练集比例去评估模型的分类准确性,因此需要for循环4次
先将数据集划分为四个部分,结合for循环多次划分训练集
因为数据量较少,但每次划分有需要保留部分数据,因此结合stratify、random_state、shuffle参数在每次划分前都打乱数据,且控制随机数量和按鸢尾花种类等比划分
for i in range(4):
"""
train_size:训练集占比
stratify:按鸢尾花种类进行分层采样
random_state:控制随机数生成器的种子数量
shuffle:先打乱数据再划分
"""
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,
train_size=size[i],
stratify=iris.target,
random_state=20,
shuffle=True)KFold
在for循环训练集比例时,叠加一个for循环用以遍历各个模型
用K折交叉验证法将训练集划分出来训练模型,并用验证集去验证模型,以此评估模型参数的性能
model_list = []
for model in models:
# n_splite:K折交叉验证划分数量
kf = KFold(n_splits=5,random_state=10,shuffle=True)
"""
kf.split() 函数只传入了 X_train 作为参数。
但是,这个函数返回两个值,即训练集索引 train_idx 和验证集索引 val_idx。
这些索引可以用来从 X_train 和 y_train 中拆分训练集和验证集。
y_train_fold 和 y_val_fold 是从 y_train 中根据训练集和验证集索引拆分出来的标签集。
通过使用 train_idx 和 val_idx,可以从 y_train 中选择与训练集和验证集对应的标签,将它们赋值给 y_train_fold 和 y_val_fold。
这样就可以同时获得拆分后的数据集和标签集。
-- 文心一言
"""
estimator = models[model] # 遍历所有模型
for train_idx,val_idx in kf.split(x_train):
x_train_fold,x_val_fold = x_train[train_idx],x_train[val_idx]
y_train_fold,y_val_fold = y_train[train_idx],y_train[val_idx]estimator.fit
在每个划分出来的子数据集上训练模型
estimator.fit(x_train_fold, y_train_fold)cross_val_score
训练后,用验证集和同对应索引下的真实值对比,得出该参数下的模型的准确度
val_score_list = []
# cross_val_score:评估模型在验证集上的性能
# accuracy是准确度,precision是精确度
val_score = cross_val_score(estimator, x_val_fold, y_val_fold, cv=kf, scoring='accuracy')
val_score = [round(i, 2) for i in val_score]
val_score_list.append(val_score)accuracy_score
遍历所有模型后,回到上层训练集占比的遍历,用测试集评估该训练集占比下的
# 用测试集来评估模型性能
y_pred = estimator.predict(x_test)
test_score = round(accuracy_score(y_test, y_pred), 2)
test_score_list[i].append(test_score)可视化不同训练集比例评估各模型的得分
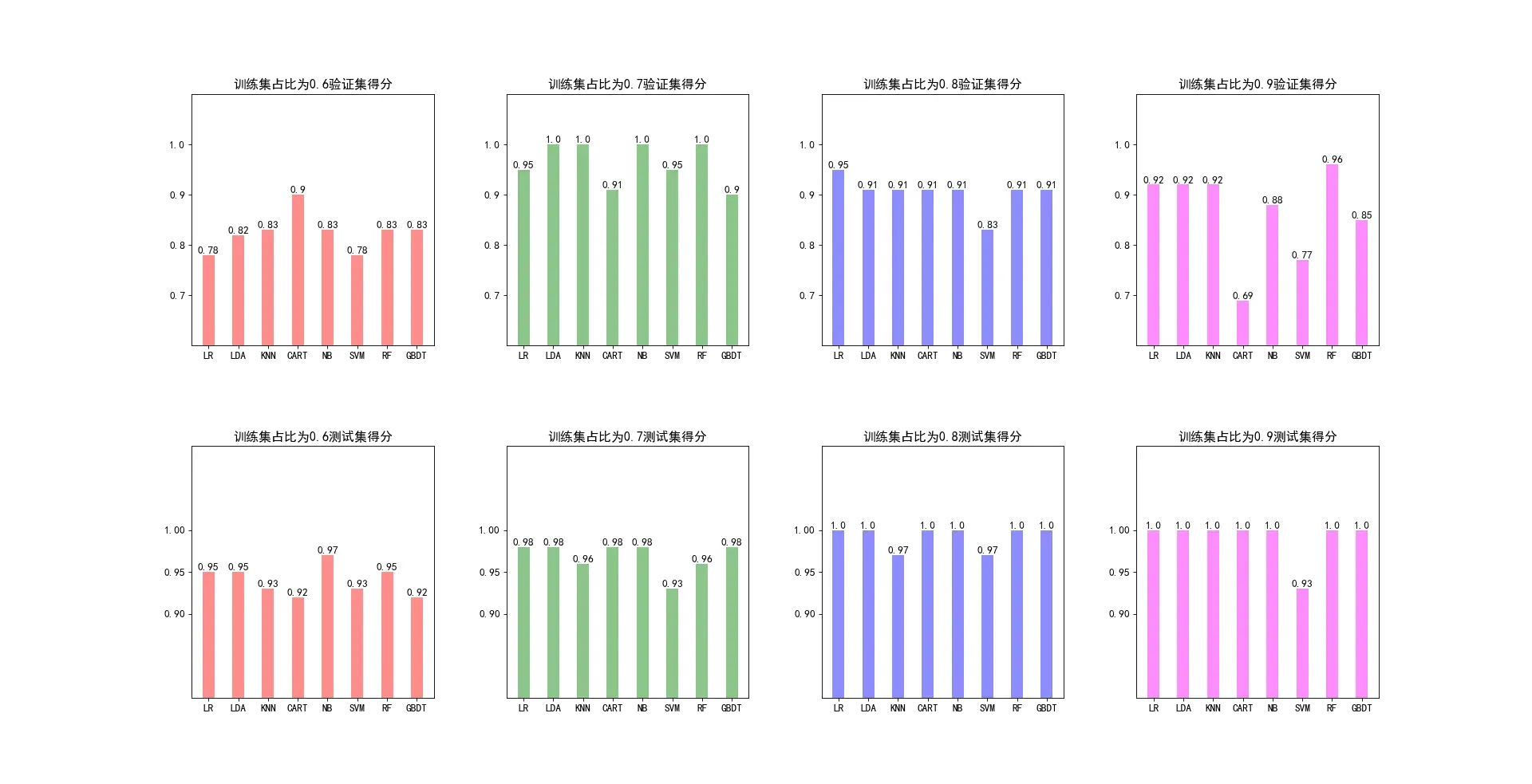
参考文章:【matplotlib】浅谈python图形可视化练习经验分享_plt.xtick-CSDN博客
基础设置
#中文显示设置
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用于显示中文
plt.rcParams['axes.unicode_minus'] = False # 用于解决保存图像是负号‘-’显示为方框的问题
plt.rcParams['font.size'] = '12' #用于设置中文大小
plt.rcParams['axes.labelsize'] = plt.rcParams['font.size'] # 设置坐标轴标签的字体大小画布设置
"""
figsize:画布背景颜色
dpi:清晰度
edgecolor:画布边框颜色
frameon:是否绘制画布图框
"""
fig, axes = plt.subplots(num='可视化不同训练集比例',nrows=2,ncols=4,figsize=(20, 8), dpi=80,
edgecolor=None,frameon=False)
plt.subplots_adjust(wspace=0.3,hspace=0.4) # 控制子图表之间的左右、上下间距
axes = axes.flatten() # 将n*m形式的子图表结构转换成1*m形式(因为设置了nrows的原因,只设置ncols可以不要这个)
x_label = list(models.keys()) # 获取所有模型的名称
color_list = ['r','g','b','magenta']生成子图表
for index,ax in enumerate(axes): # 循环遍历所有子图表并获得其索引下标
if index < 4:
ax.bar(x_label, model_score_list[index],width=0.4, color=color_list[index], alpha=0.45)
# 设置数据标签
for a,b in zip(x_label,model_score_list[index]):
ax.text(a,b,b, ha='center', va='bottom')
# 子图表标题
ax.set_title('训练集占比为{}验证集得分'.format(size[index]))
# Y轴刻度
ax.set_yticks([0.7,0.8,0.9,1])
# Y轴范围
ax.set_ylim((0.6, 1.1))
else:
ax.bar(x_label, test_score_list[index-4],width=0.4, color=color_list[index-4], alpha=0.45)
# 设置数据标签
for a,b in zip(x_label,test_score_list[index-4]):
ax.text(a,b,b, ha='center', va='bottom')
# 子图表标题
ax.set_title('训练集占比为{}测试集得分'.format(size[index-4]))
# Y轴刻度
ax.set_yticks([0.9, 0.95,1])
# Y轴范围
ax.set_ylim((0.8, 1.1))完整代码
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import pandas as pd
iris = load_iris()
# 散点矩阵图,看各特征之间的相关性
iris_df = pd.DataFrame(iris.data, columns=iris.feature_names)
scatter_corr = pd.plotting.scatter_matrix(iris_df, marker='o', c=iris.target, hist_kwds={'bins': 20})
# plt.show()
# ------------------------------ 使用不同训练集比例评估各模型的得分 ------------------------
import numpy as np
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split,KFold,cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import GradientBoostingClassifier
models = {}
models["LR"] = LogisticRegression(max_iter=1000) # 逻辑回归
models["LDA"] = LinearDiscriminantAnalysis() # 线性判别分析
models["KNN"] = KNeighborsClassifier() # KNN最近邻
models["CART"] = DecisionTreeClassifier() # 分类与回归树
models["NB"] = GaussianNB() # 朴素贝叶斯
models["SVM"] = SVC() # 向量机
models["RF"] = RandomForestClassifier(n_estimators=100) # 随机森林
models["GBDT"] = GradientBoostingClassifier() # 梯度提升决策树
model_score_list = [[], [], [], []] # 用来装模型在验证集上的得分
test_score_list = [[], [], [], []] # 用来装模型在测试集上的得分
size=[0.6,0.7,0.8,0.9] # 训练集比例
for i in range(4):
"""
train_size:训练集占比
stratify:按鸢尾花种类进行分层采样
random_state:控制随机数生成器的种子数量
shuffle:先打乱数据再划分
"""
x_train,x_test,y_train,y_test = train_test_split(iris.data,iris.target,
train_size=size[i],
stratify=iris.target,
random_state=20,
shuffle=True)
model_list = []
for model in models:
# n_splite:K折交叉验证划分数量
kf = KFold(n_splits=5,random_state=10,shuffle=True)
"""
kf.split() 函数只传入了 X_train 作为参数。
但是,这个函数返回两个值,即训练集索引 train_idx 和验证集索引 val_idx。
这些索引可以用来从 X_train 和 y_train 中拆分训练集和验证集。
y_train_fold 和 y_val_fold 是从 y_train 中根据训练集和验证集索引拆分出来的标签集。
通过使用 train_idx 和 val_idx,可以从 y_train 中选择与训练集和验证集对应的标签,将它们赋值给 y_train_fold 和 y_val_fold。
这样就可以同时获得拆分后的数据集和标签集。
-- 文心一言
"""
estimator = models[model] # 遍历所有模型
for train_idx,val_idx in kf.split(x_train):
x_train_fold,x_val_fold = x_train[train_idx],x_train[val_idx]
y_train_fold,y_val_fold = y_train[train_idx],y_train[val_idx]
# 在每个折叠的子数据集上训练模型
estimator.fit(x_train_fold, y_train_fold)
val_score_list = []
# cross_val_score:评估模型在验证集上的性能
# accuracy是准确度,precision是精确度
val_score = cross_val_score(estimator, x_val_fold, y_val_fold, cv=kf, scoring='accuracy')
val_score = [round(i, 2) for i in val_score]
val_score_list.append(val_score)
val_mean_score = round(np.mean(val_score_list), 2)
model_score_list[i].append(val_mean_score)
model_list.append(val_score_list)
# 用测试集来评估模型性能
y_pred = estimator.predict(x_test)
test_score = round(accuracy_score(y_test, y_pred), 2)
test_score_list[i].append(test_score)
print("训练集比例为{}的{}模型在验证集上的得分为{}".format(size[i], model, val_mean_score))
print("训练集比例为{}的{}模型在测试集上的得分为{}".format(size[i], model, test_score))
print('\n', '-' * 100, '\n')
test_score_list.append(test_score_list[i])
print(model_score_list)
print(test_score_list)
# ------------------------------ 可视化不同训练集比例评估各模型的得分 ------------------------
#中文显示设置
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用于显示中文
plt.rcParams['axes.unicode_minus'] = False # 用于解决保存图像是负号‘-’显示为方框的问题
plt.rcParams['font.size'] = '12' #用于设置中文大小
plt.rcParams['axes.labelsize'] = plt.rcParams['font.size'] # 设置坐标轴标签的字体大小
"""
figsize:画布背景颜色
dpi:清晰度
edgecolor:画布边框颜色
frameon:是否绘制画布图框
"""
fig, axes = plt.subplots(num='可视化不同训练集比例',nrows=2,ncols=4,figsize=(20, 8), dpi=80,
edgecolor=None,frameon=False)
plt.subplots_adjust(wspace=0.3,hspace=0.4) # 控制子图表之间的左右、上下间距
axes = axes.flatten() # 将n*m形式的子图表结构转换成1*m形式(因为设置了nrows的原因,只设置ncols可以不要这个)
x_label = list(models.keys()) # 获取所有模型的名称
color_list = ['r','g','b','magenta']
for index,ax in enumerate(axes): # 循环遍历所有子图表并获得其索引下标
if index < 4:
ax.bar(x_label, model_score_list[index],width=0.4, color=color_list[index], alpha=0.45)
# 设置数据标签
for a,b in zip(x_label,model_score_list[index]):
ax.text(a,b,b, ha='center', va='bottom')
# 子图表标题
ax.set_title('训练集占比为{}验证集得分'.format(size[index]))
# Y轴刻度
ax.set_yticks([0.7,0.8,0.9,1])
# Y轴范围
ax.set_ylim((0.6, 1.1))
else:
ax.bar(x_label, test_score_list[index-4],width=0.4, color=color_list[index-4], alpha=0.45)
# 设置数据标签
for a,b in zip(x_label,test_score_list[index-4]):
ax.text(a,b,b, ha='center', va='bottom')
# 子图表标题
ax.set_title('训练集占比为{}测试集得分'.format(size[index-4]))
# Y轴刻度
ax.set_yticks([0.9, 0.95,1])
# Y轴范围
ax.set_ylim((0.8, 1.1))
plt.show()
参考文章:
机器学习-鸢尾花(Iris Flower)分类_鸢尾花 机器学习_超级干饭王的博客-CSDN博客
鸢尾花的分类(四种方法)_鸢尾花数据集分类-CSDN博客
KFold.split的使用-CSDN博客
cross_val_score的用法-CSDN博客
【Python学习】 – sklearn学习 – 数据集分割方法 – 随机划分与K折交叉划分与StratifiedKFold与StratifiedShuffleSplit_sklearn 数据集划分-CSDN博客
版权声明:本文为博主作者:inganxu原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_46159679/article/details/133685307