1 引言
霍夫曼码是一种无损编码,而且是最优的符号码。但是,它有两个缺点:(1)每个符号至少需要一个比特;(2)当符号的概率分布变化时,使用不方便。
用一个例子来看看霍夫曼编码的第一个缺点(即每个符号至少需要1个比特)。
信源从符号集中选择独立同分布的符号,概率分布为𝑃(𝑎_1 )=0.95,𝑃(𝑎_2 )=0.02,𝑃(𝑎_3 )=0.03。它的熵为0.335比特/符号。才3个符号,所以这个霍夫曼码很简单,如下所示。
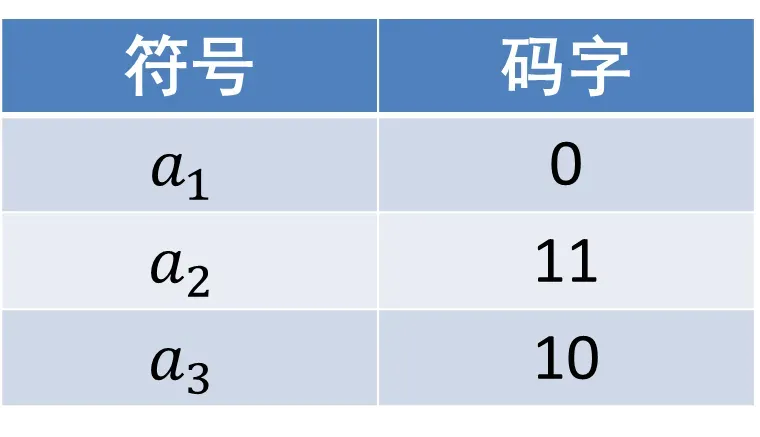
它的平均码长为1.05比特/符号,远大于熵(0.335比特/符号)。原因是符号的信息量为
比特,远小于其码长(1比特)。给
分配长度为1的码是很浪费的。
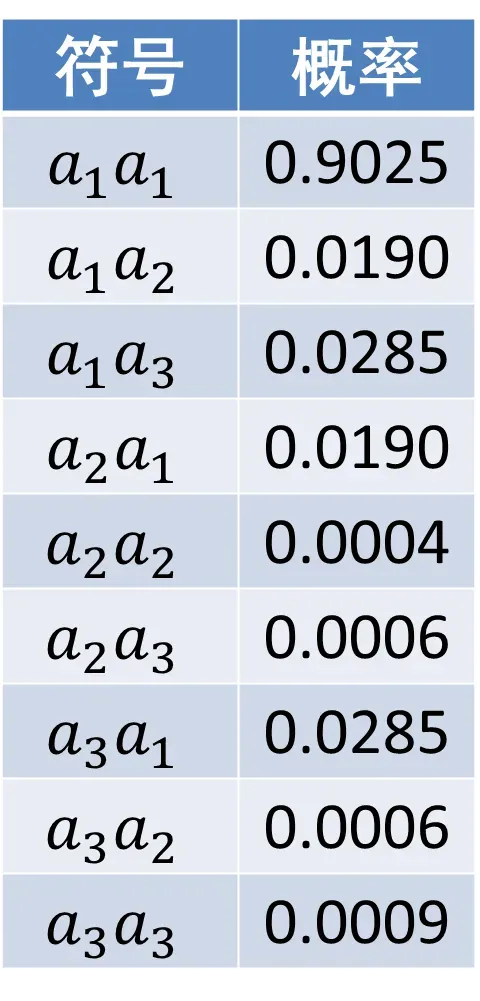
为了减小平均码长,下面将两个符号(独立同分布的)合并为一个扩展符号,进行霍夫曼编码。扩展符号的概率分布如下图。
其霍夫曼码的构造过程如下图所示。
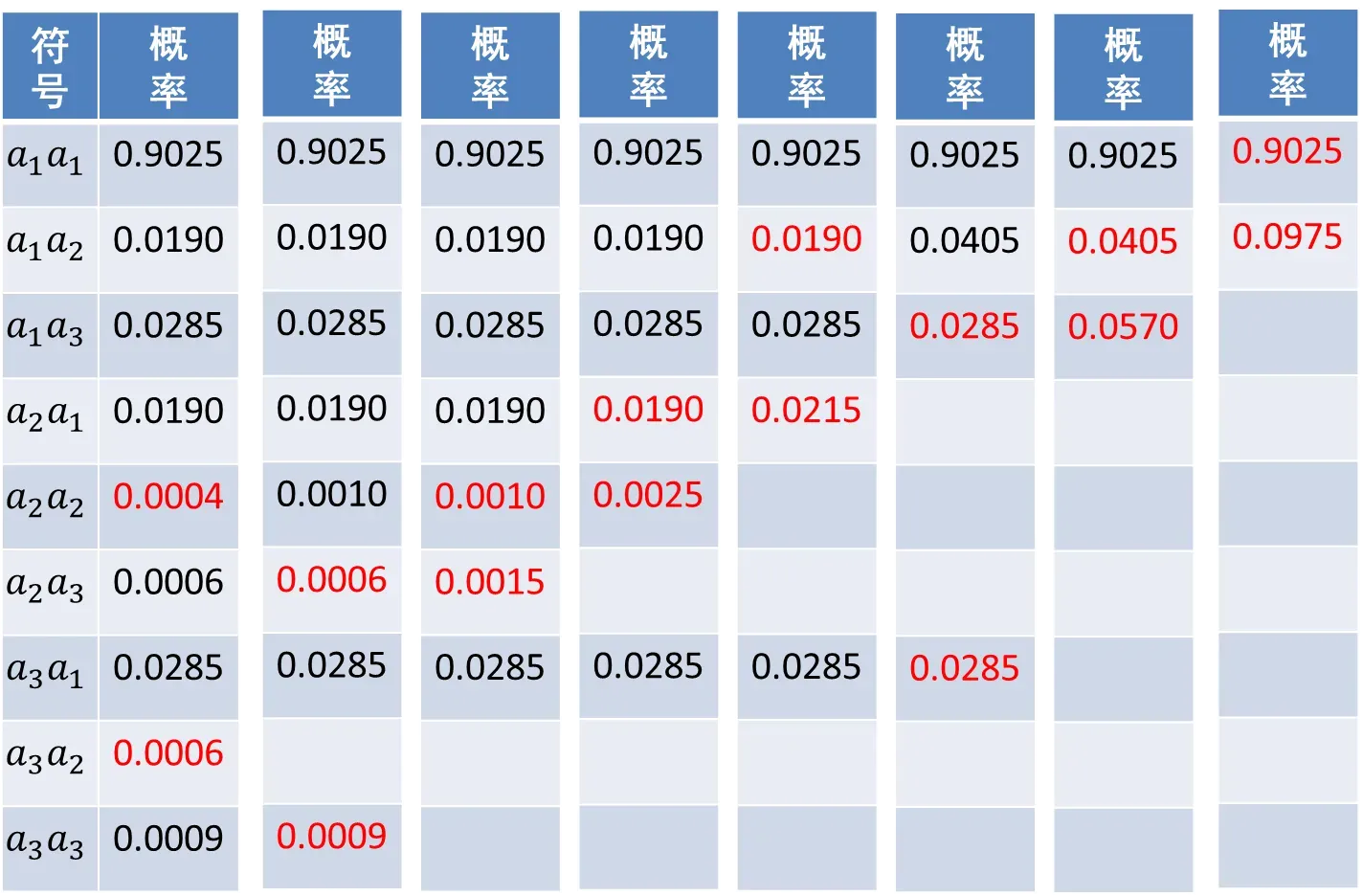
2个扩展符号的平均码长为1.222比特/扩展符号。相当于单个符号的平均码长为0.611比特,这比前面针对单个符号编码的平均码长短了许多,但是仍然很长,约为熵的2倍。
我们可以进一步扩展,当扩展为8个符号时,单个符号的平均码长与熵接近。但符号集大小为。对于许多应用,如此规模的霍夫曼码是不现实的。
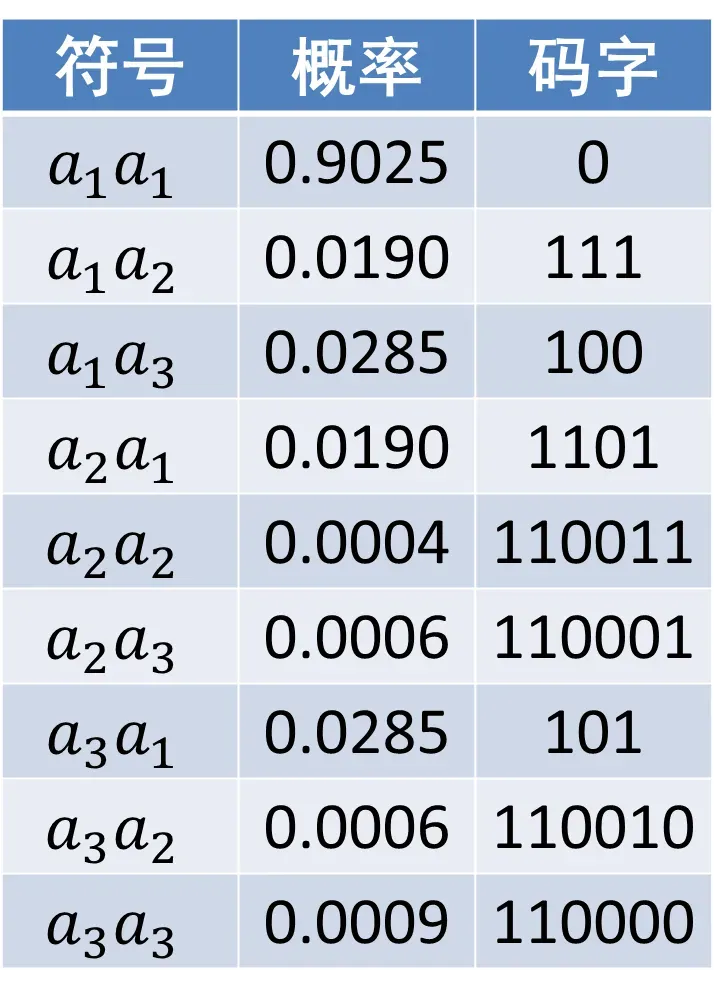
而算术编码能做到:能为特定的符号序列(当前要压缩的数据)指定码字,同时又不需要为所有的符号序列(当前数据中不出现的)指定码字。当很大时,该属性很重要。
2 算术编码
对于信源输出的符号序列,算术编码是对整个符号序列进行编码。为了实现无损编码,不同的符号序列需要映射为不同的标签(tag)。我们可以用[0,1)区间的实数(二进制形式)作为标签。由于[0,1)区间有无穷多个实数,足够给每个序列分配一个唯一的标签。那么,如何将符号序列映射为[0,1)区间的实数?利用累积分布函数(CDF)。
一个随机试验(如抛硬币、扔色子)所有可能结果组成一个基本空间Ω。 随机变量𝑋是定义在基本空间Ω上的、取值为实数的函数。 即随机试验每个可能结果都有实轴上的点与之对应。 为了统一起见和方便起见,随机变量采用下面的映射:。其中,
为离散信源的符号集。
例如,随机抛硬币,可能的结果有正面朝上、反面朝上两种 。当正面朝上时,取值1;当反面朝上时,
取值2。 又如,随机扔色子,所有可能结果是1点、2点、3点、4点、5点和6点,
分别取值1,2,3,4,5,6。 又如,随机从英文文本(已经过处理,只有小写字母和空格,无标点符号)中抽取字母,所有可能结果是abcd…z-,X分别取值1,2,…,27。
随机变量的概率函数为
。累积密度函数
假设没有概率为0的符号,每个符号都对应一个唯一的。可按照
对[0,1)区间切分。
如果只需对单个符号编码,那么在对应子区间随便取一个值作为标签(码字即二进制表示)。
2.1 生成标签
例如,某信源的符号集为,概率为
,
,
。
编码开始前,没有任何符号,我们只知道标签对应的是整个[0,1)区间。当收到第1个符号后,区间缩小到该符号对于的子区间。然后,按照累积分布函数对该子区间做同样的切分。当收到第2个符号后,区间缩小到子区间中的子区间。对于所有符号依次做以上区间切分,直到最后一个符号,就得到一个很小的子区间,该子区间内任何一个数字(后面讲,用哪个数字的压缩率高)都可以作为序列的标签(其二进制表示即编码结果)。
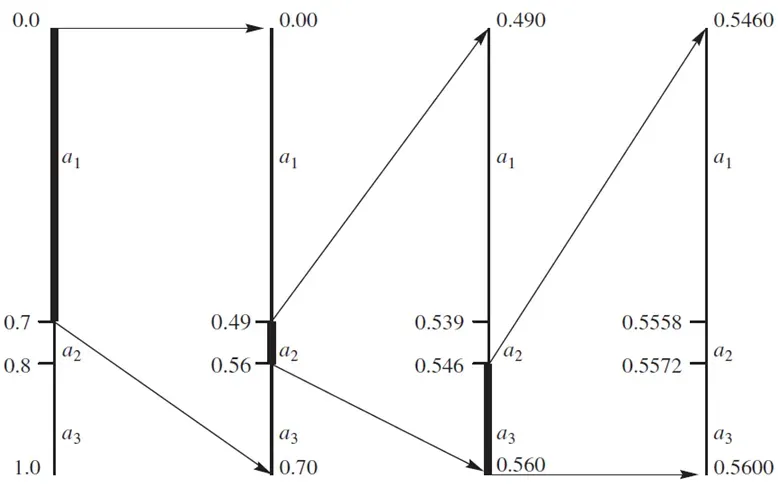
前面对确定符号序列的标签所在区间,做了直观解释。下面给出具体的计算公式。假设取区间的中点作为标签。先考虑单个符号。 符号的标签为
下表为掷色子时单个符号的标签。

长为𝑚的符号序列的标签为
其中,
是排在
之前的等长序列。
以色子为例,𝑚=2。序列的排序方法如下:11,12,13,14,15,16,21,22,23,…,64,65,66。例如,色子序列13的标签为
如果序列很长,求和项包含的序列非常多(指数增长)。上述式子不适合计算。
对于序列,可用递归的方法计算区间的上下限。
下限
上限
标签为上下限的中点。
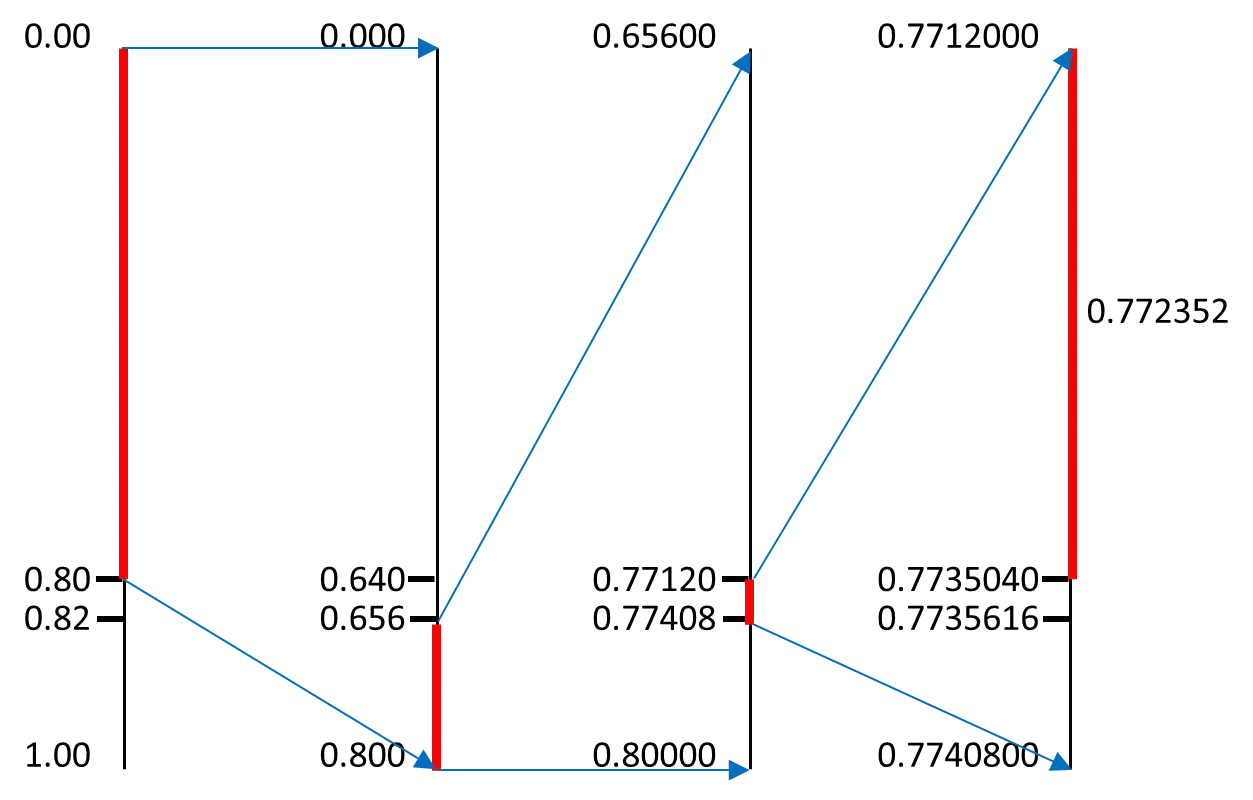
例如,,概率为
,
,
。
对于序列𝟏𝟑𝟐𝟏,计算其标签。
,
,
,
标签为
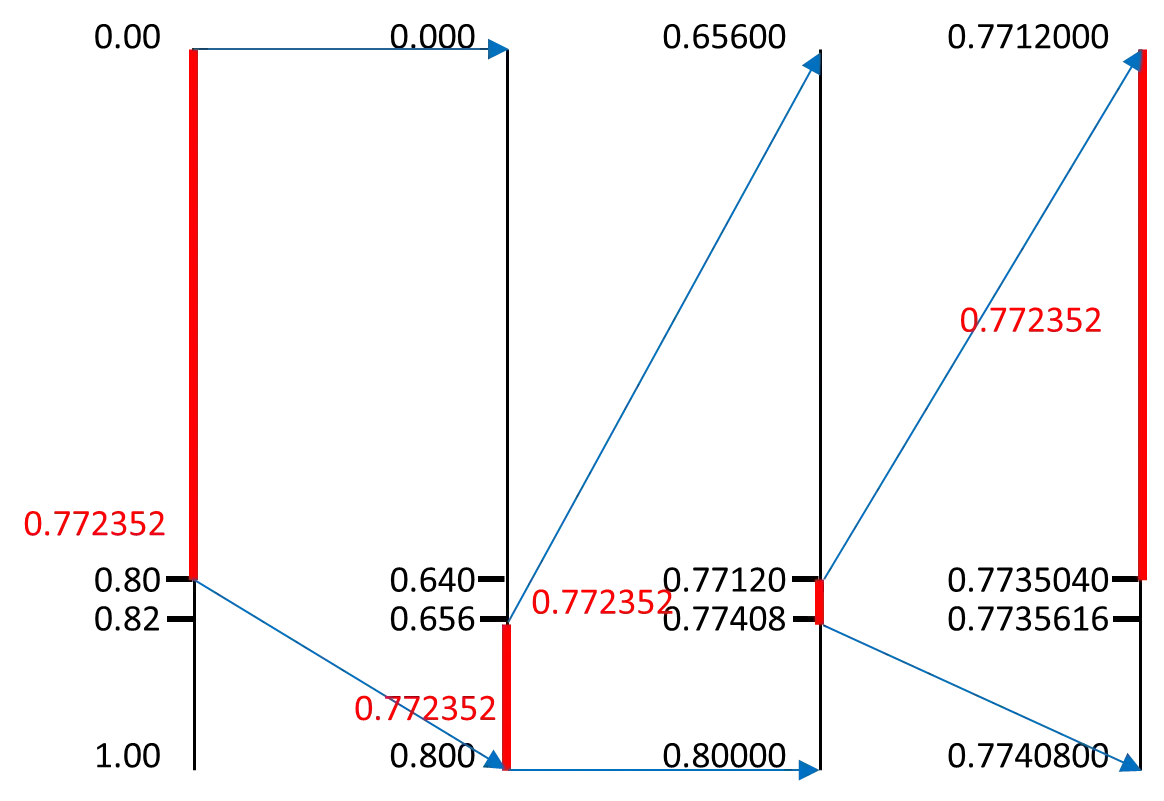
2.2 解码
还是上面的例子。对于标签0.772352,解码原序列。按顺序一次确定一个符号。那么何时解码结束?已知序列长度或者使用特殊的结束符。
2.3 为什么可以压缩?
前面为了容易理解,用十进制小数表示标签;而具体实现时,用二进制表示。许多小数需要无限长二进制表示(如0.1,0.2),不能实现压缩。在⌈log 1/(𝑃(𝑥))⌉+1处截断,数字仍在同一区间内,所以仍唯一可译。
为什么数字仍在同一区间内?因为原始数字是区间的中点,区间的大小是𝑃(𝑥),截断误差2^(−(⌈log 1/(𝑃(𝑥))⌉+1) )≤0.5𝑃(𝑥)。假设信源为i.i.d.随机变量𝑋,𝑚个符号所构成序列的信息量log 1/(𝑃(𝑥))=𝑚𝐻(𝑋) ⌈log 1/(𝑃(𝑥))⌉+1≤𝑚𝐻(𝑋)+2。即𝑚个符号压缩为至多𝑚𝐻(𝑋)+2比特。
3 具体实现问题
3.1 比例调整
实际实现时,还有一个问题需要考虑。随着符号数增加,区间会越来越小,小数点后的数字越来越多。如何在计算机上存储极高精度的数字?用办法:比例调整编码时,按照一定规则对数字进行放大。解码时,用同样规则进行缩小即可。
3.2 自适应算术编码
算术编码可以是静态的或是自适应的。在静态算术编码中(前面介绍的),信源符号的概率是固定的。但是很多时候事先不知道精确的信源符号概率。需要自适应算术编码,根据编码时符号出现的频繁程度,动态修改符号概率。在编码期间,估算信源符号概率的过程叫建模(modeling)。
每来一个符号,符号概率进行更新,区间切分随着概率的变化而变化。编码和解码的概率更新方法保持一致,即可正确解码。
4. 对比算术编码与霍夫曼编码
假设用两种编码方法对长度𝑚的符号序列进行编码,假设使用扩展符号(𝑚个符号)进行霍夫曼编码。算术编码码率范围为:。霍夫曼编码码率范围为:
。相比之下,霍夫曼编码的上限更低。但是,对于算术编码,序列长度𝑚可以取很大;而霍夫曼编码的𝑚不能很大。因此,算术编码可以实现更高的压缩比。但是,算术编码的不足是算法复杂、专利多。因此,实际中二者的应用都很多。
版权声明:本文为博主作者:minutiae原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/minutiae/article/details/129468658