目录
1. 主成分分析概念:
主成分分析算法(PCA)是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的信息量最大(方差最大),以此使用较少的数据维度,同时保留住较多的原数据点的特性。一般来说,当研究的问题涉及到多变量且变量之间存在很强的相关性时,我们可考虑使用主成分分析的方法来对数据进行简化。
降维具有的优点:
- 使得数据集更易使用
- 降低算法的计算开销
- 去除噪声
- 使得结果容易理解
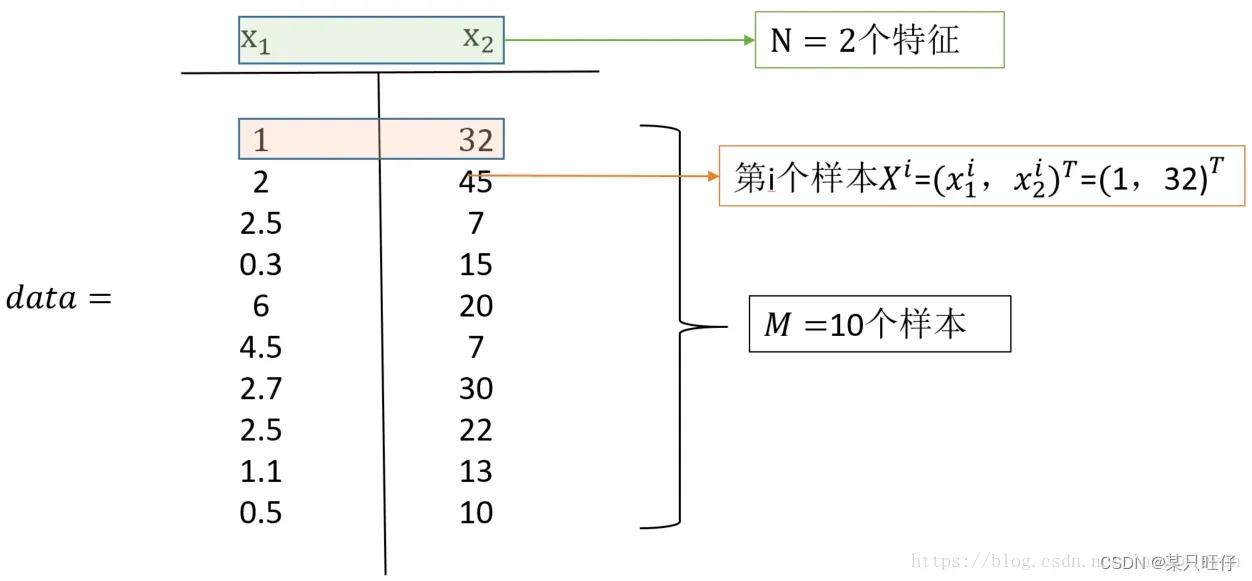
假设有n个样本,p个指标,则可构成n*p的样本矩阵x:

例如:此图中有10个样本,2个指标,可以构成10*2的样本矩阵
2. 主成分分析法步骤:
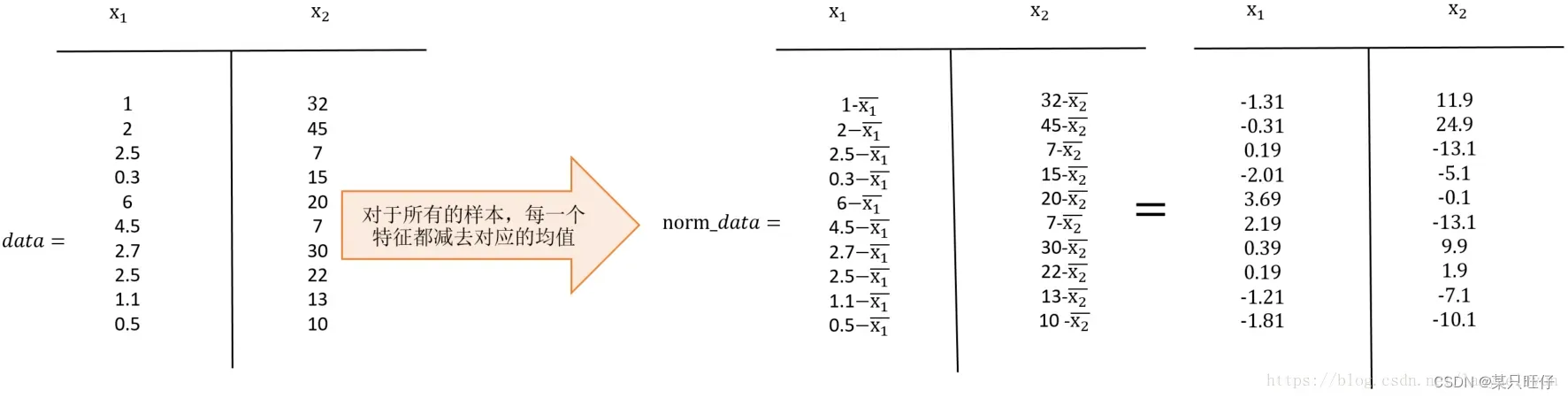
第一步:对所有特征进行中心化:去均值
求每一个特征的平均值(按列求取),然后对于所有的样本,每一个特征都减去自身的均值。
第二步:求协方差矩阵C
求协方差矩阵
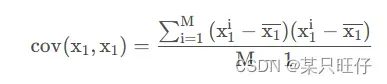
第三步:求协方差矩阵C的特征值 和相对应的特征向量
和相对应的特征向量
求协方差矩阵C的特征值和相对应的特征向量
特征值 λ 会有 N个,每一个 λ 对应一个特征向量 u,将特征值 λ 按照从大到小的顺序排序,选择最大的前k个,并将其相对应的k个特征向量拿出来,我们会得到一组 { ( λ 1 , u 1 ) , ( λ 2 , u 2 ) , . . . , ( λ k , u k ) } 。本例中原始特征只有2维,我在选取 λ 的时候,令 k = 1,选择最大的 λ 1 和 其 对 应 的 u 1 和其对应的u1。
第四步:将原始特征投影到选取的特征向量上,得到降维后的新K维特征
选取最大的前k个特征值和相对应的特征向量,并进行投影的过程,就是降维的过程。对于每一个样本 ,原来的特征是
,投影之后的新特征是
,新特征的计算公式如下:
主成分分析法的原理分析在此处不涉及,感兴趣的友友可以看这一篇文章:
PCA:详细解释主成分分析_lanyuelvyun的博客-CSDN博客_pca
3. 主成分分析法MATLAB实现:
data1部分原数据:
| 省份 | 食品 | 衣着 | 家庭设备 | 医疗 | 交通 | 娱乐 | 居住 | 杂项 |
| 北京 | 2959.19 | 730.79 | 749.41 | 513.34 | 467.87 | 1141.82 | 478.42 | 457.64 |
| 天津 | 2459.77 | 495.47 | 697.33 | 302.87 | 284.19 | 735.97 | 570.84 | 305.08 |
| 河北 | 1495.63 | 515.9 | 362.37 | 285.32 | 272.95 | 540.58 | 364.91 | 188.63 |
| 山西 | 1406.33 | 477.77 | 290.15 | 208.57 | 201.5 | 414.72 | 281.84 | 212.1 |
| 内蒙古 | 1303.97 | 524.29 | 254.83 | 192.17 | 249.81 | 463.09 | 287.87 | 192.96 |
| 辽宁 | 1730.84 | 553.9 | 246.91 | 279.81 | 239.18 | 445.2 | 330.24 | 163.86 |
| 吉林 | 1561.86 | 492.42 | 200.49 | 218.36 | 220.69 | 459.62 | 360.48 | 147.76 |
| 黑龙江 | 1410.11 | 510.71 | 211.88 | 277.11 | 224.65 | 376.82 | 317.61 | 152.85 |
| 上海 | 3712.31 | 550.74 | 893.37 | 346.93 | 527 | 1034.98 | 720.33 | 462.03 |
| 江苏 | 2207.58 | 449.37 | 572.4 | 211.92 | 302.09 | 585.23 | 429.77 | 252.54 |
| 浙江 | 2629.16 | 557.32 | 689.73 | 435.69 | 514.66 | 795.87 | 575.76 | 323.36 |
| 安徽 | 1844.78 | 430.29 | 271.28 | 126.33 | 250.56 | 513.18 | 314 | 151.39 |
| 福建 | 2709.46 | 428.11 | 334.12 | 160.77 | 405.14 | 461.67 | 535.13 | 232.29 |
| … | … | … | … | … | … | … | … | … |
clear;clc
load data1.mat % 主成分聚类
[n,p] = size(x); % n是样本个数,p是指标个数
R = corrcoef(x);
disp('样本相关系数矩阵为:')
disp(R)
[V,D] = eig(R); % V 特征向量矩阵 D 特征值构成的对角矩阵
%%计算主成分贡献率和累计贡献率
lambda = diag(D); % diag函数用于得到一个矩阵的主对角线元素值(返回的是列向量)
lambda = lambda(end:-1:1); % 因为lambda向量是从小大到排序的,我们将其调个头
contribution_rate = lambda / sum(lambda); % 计算贡献率
cum_contribution_rate = cumsum(lambda)/ sum(lambda); % 计算累计贡献率 cumsum是求累加值的函数
disp('特征值为:')
disp(lambda') % 转置为行向量,方便展示
disp('贡献率为:')
disp(contribution_rate')
disp('累计贡献率为:')
disp(cum_contribution_rate')
disp('与特征值对应的特征向量矩阵为:')
% 注意:这里的特征向量要和特征值一一对应,之前特征值相当于颠倒过来了,因此特征向量的各列需要颠倒过来
% rot90函数可以使一个矩阵逆时针旋转90度,然后再转置,就可以实现将矩阵的列颠倒的效果
V=rot90(V)';
disp(V)
%% 计算我们所需要的主成分的值
m =input('请输入需要保存的主成分的个数: ');
F = zeros(n,m); %初始化保存主成分的矩阵(每一列是一个主成分)
for i = 1:m
ai = V(:,i)'; % 将第i个特征向量取出,并转置为行向量
Ai = repmat(ai,n,1); % 将这个行向量重复n次,构成一个n*p的矩阵
F(:, i) = sum(Ai .* X, 2); % 注意,对标准化的数据求了权重后要计算每一行的和
end参考:清风数学建模
版权声明:本文为博主作者:某只旺仔原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_54543084/article/details/128356788