文章目录
-
- 数据模型准备
- 基于网页的简单微调
- 基于网页的简单评测
- 基于网页的简单聊天
- 基于网页的模型合并
- 微调问题测试与解决
-
- 问题测试
- 模板修改
- 强化训练
- 持续训练
- 单数据集训练
- 微调总结
LLaMA-Factory是一个非常好用的无代码微调框架,不管是在模型、微调方式还是参数设置上都提供了非常完备的支持,下面是对微调全过程的一个记录。
数据模型准备
微调时一般需要准备三个数据集:一个是自我认知数据集(让大模型知道自己是谁),一个是特定任务数据集(微调时需要完成的目标任务),一个是通用任务数据集(保持大模型的通用能力,防止变傻)。前两个一般要自己定义,最后一个用现成的就行。
自定义数据集可采用alpaca和sharegpt格式,这里采用的是alpaca格式:
[
{
"instruction": "用户指令(必填)",
"input": "用户输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
由于不需要考虑多轮对话,所以history可以不要,这里采用了两种数据集的组织方式,一种是只有instruction和output,把问题作为instruction,另外一种是把问题作为input,把回答问题这一要求作为instruction。这两种格式分别记为format2和format3。
在根据若干个不同的专业领域生成完多个自定义的问答json文件之后,分别生成其format2和format3的文件以及test测试文件,根据以下代码计算其sha1值:
import hashlib
def calculate_sha1(file_path):
sha1 = hashlib.sha1()
try:
with open(file_path, 'rb') as file:
while True:
data = file.read(8192) # Read in chunks to handle large files
if not data:
break
sha1.update(data)
return sha1.hexdigest()
except FileNotFoundError:
return "File not found."
# 使用示例
file_path = './data/self_cognition_modified.json' # 替换为您的文件路径
sha1_hash = calculate_sha1(file_path)
print("SHA-1 Hash:", sha1_hash)
将这些json文件放入data文件夹下,同步修改dataset_info.json文件,输入新增的文件名称和对应的sha1值。
测试的大模型可以使用这些,注意要下载最新版,老版的模型结构不太匹配。
基于网页的简单微调
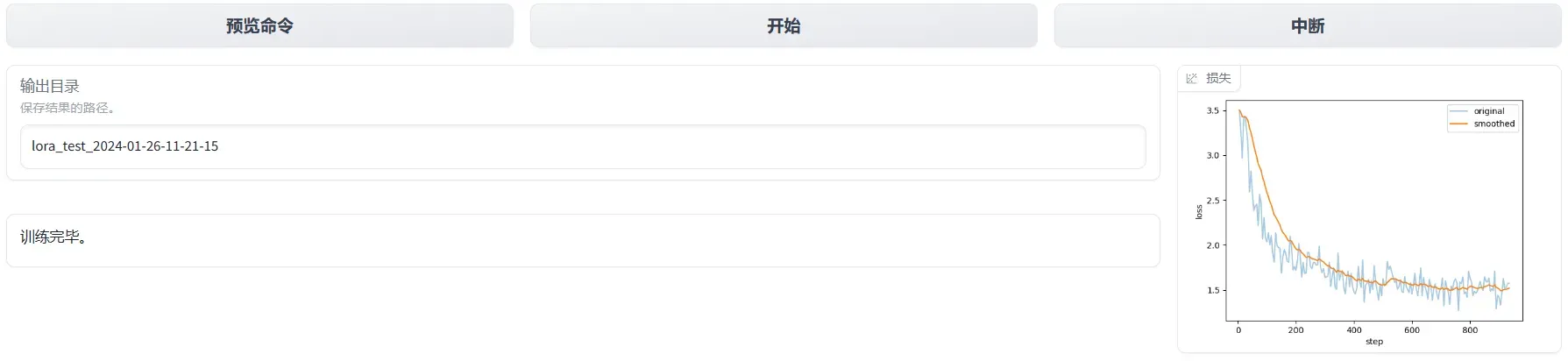
在后台执行CUDA_VISIBLE_DEVICES=0 python src/train_web.py命令,成功开启网页,设置如下,手动输入模型路径。


训练完成之后的界面,可以查看损失函数
基于网页的简单评测
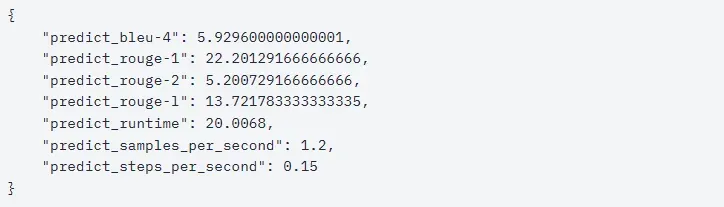
- 原始模型评测

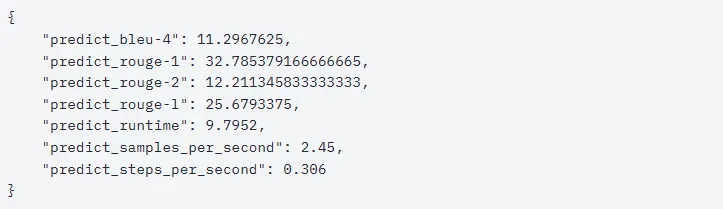
- 微调后模型评测
首先加载lora

基于网页的简单聊天
切换到Chat并点击加载模型后,可以进入聊天
基于网页的模型合并
把lora的权重合并到原始模型中
微调问题测试与解决
问题测试
虽然在评估时看着分数挺高,但实际使用起来,问题还是挺大的:
- 自我认知无法更新

- 专业问题答不上来
这是训练集中的一条数据

这是无lora的情况:
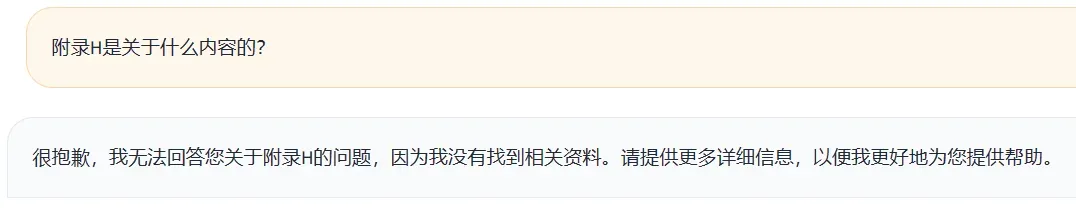
这是带lora的情况:

模板修改
ChatGLM之所以一口咬定自己是智谱开发的,主要原因是有个系统提示词,打开src/llmtuner/data/template.py文件,将以下部分删除

强化训练
为了让大模型学习更深入,补充通用数据集,增加学习率和epoch,再来一次微调


这一次自我认知倒是调出来了
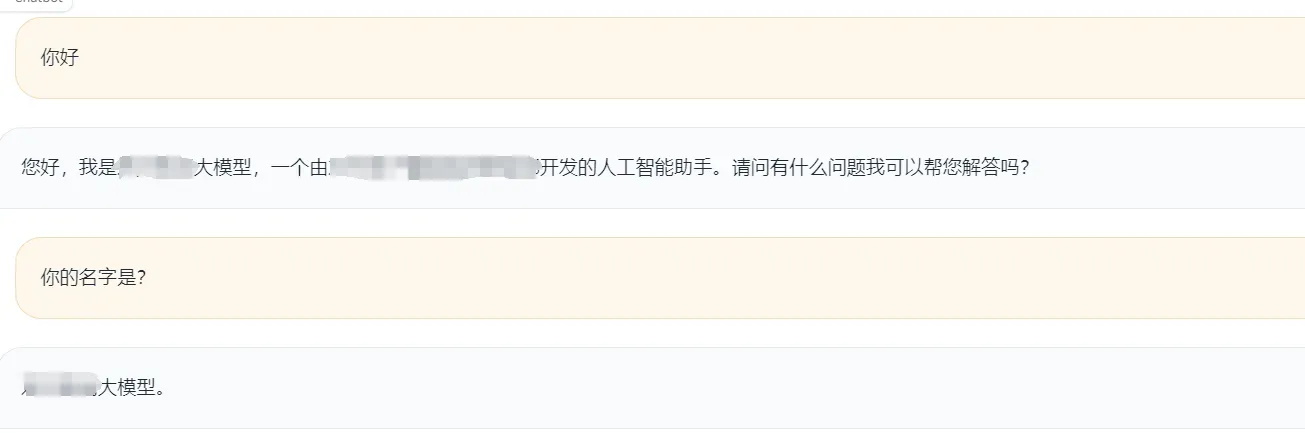
但是专业问题还是不行

持续训练
在训练出来的这个lora的基础上,为了进一步增强其专业能力,将数据集中的通用和认知数据集去掉,仅保留目前回答不好的几个专业问答数据集,并减小截断长度和增大batch大小:

可以看到训练曲线又下降了一点

但是此时专业问答能力依然不太行,并且认知也退化了,看来洗脑不能停:

单数据集训练
考虑到不同数据集的专业领域不同,模型可能无法一次集中学习,因此我们尝试使用单个数据集进行微调,包括了其format2和format3格式,实验结果显示format3更好一些。
-
format2格式
其下降曲线如下图所示
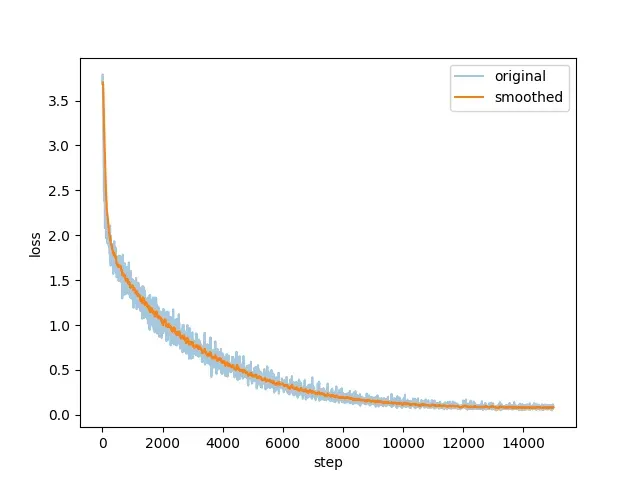
专业问答能力实现
但通用问答能力被大大削弱

-
format3格式
其下降曲线如下图所示
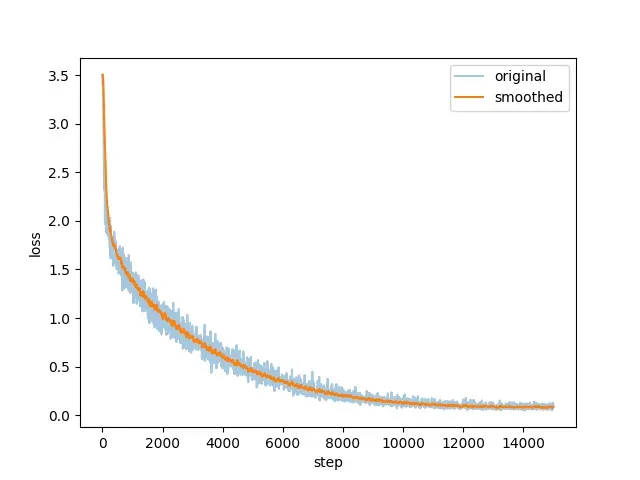 专业问答能力在输入指令的情况下实现
专业问答能力在输入指令的情况下实现直接提问只会瞎说

加入数据集中的指令后正确回答

通用问答能力保持
微调总结
以下是根据手头几个问答数据集的测试结果做的总结,不一定对,具体问题还需具体分析。
- 数据集是决定微调效果的核心因素。一方面,数据集的数量要尽可能多;另一方面,其质量也很关键,问题和答案要明确,不能含糊和模棱两可,可以通过思维链和多轮对话等技巧增强模型微调后的推理性能。
- 微调时最好不要混合使用多个领域的数据集,不然会降低学习效果,最好是同一领域下的相关问题。也不要尝试一开始用一个数据集训练,之后用另一个训练,这样并不会有什么好下场。
- 微调时最好采用
format3,将指令和输入相分离,指令可以看成是上下文学习,让模型进入相应的任务模式,然后执行特定领域的问答。这就像是一种精准的手术,给大模型做观念植入时不会动大脑的所有神经元,而只是针对一小片区域,并将其与指令触发词相关联,这样就能实现模型通用和专业问答的兼顾。 - 不要仅用指标衡量微调的效果,我发现胡说八道的模型和大体正确的模型指标上相差不太大,还是要实际体验一下问答效果。
- 微调时留意一下模型默认的系统提示词,那是常常被忽视的一项超参数。
- 如果微调之后的回答效果不稳定,尝试一下降低模型推理时的温度参数。
版权声明:本文为博主作者:羊城迷鹿原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/jining11/article/details/135859574