文章目录
- 1. 单链表的概念及结构
- 2. 单链表相关操作
-
- 2.1 创建节点
- 2.2 尾插
- 2.3 打印
- 2.4 头插
- 2.5 尾删
- 2.6 头删
- 2.7 查找
- 2.8 指定位置后插入
- 2.9 指定位置前插入
- 2.10 删除指定位置
- 2.11 删除指定位置后的节点
- 2.12 销毁单链表
- 3. 链表种类

1. 单链表的概念及结构
概念:链表是⼀种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
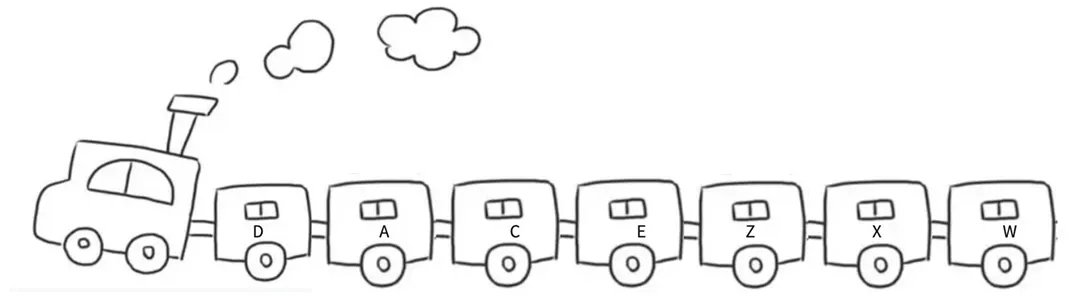
链表的结构跟火车车厢相似,淡季时车次的车厢会相应减少,旺季时车次的车厢会额外增加几节。只需要将火车里的某节车厢去掉/加上,不会影响其他车厢,每节车厢都是独立存在的。
与顺序表不同的是,链表里的每节”车厢”都是独立申请下来的空间,我们称之为“结点/节点”。节点的组成主要有两个部分:当前节点要保存的数据和保存下⼀个节点的地址(指针变量)。
为什么还需要指针变量来保存下⼀个节点的位置?
链表中每个节点都是独立申请的(即需要插入数据时才去申请⼀块节点的空间),我们需要通过指针变量来保存下⼀个节点位置才能从当前节点找到下⼀个节点。
因此链表的结构我们可以这样设计:
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data; //节点数据
struct SListNode* next; //指针保存下⼀个节点的地址
}SLTNode;
注意:
- 链式结构在逻辑上是连续的,在物理结构上不⼀定连续
- 节点⼀般是从堆上申请的
- 从堆上申请来的空间,是按照⼀定策略分配出来的,每次申请的空间可能连续,可能不连续
2. 单链表相关操作
2.1 创建节点
//创建节点
SNode* BuyNode(SLDatatype x)
{
SNode* newnode = (SNode*)malloc(sizeof(SNode));
if (!newnode)
{
perror("malloc");
return NULL;
}
newnode->data = x;
newnode->next = NULL;
return newnode;
}
2.2 尾插
- 若当前链表尾空,则插入节点就是头节点
- 不为空,先找尾,再插入
//尾插
void SListPushBack(SNode** pphead, SLDatatype x)
{
assert(pphead);
SNode* newnode = BuyNode(x);
//链表为空
if (*pphead == NULL)
{
*pphead = newnode;
return;
}
SNode* tail = *pphead;
//找尾
while (tail->next)
{
tail = tail->next;
}
//连接
tail->next = newnode;
}
2.3 打印
//打印
void SListPrint(SNode* phead)
{
SNode* cur = phead;
while (cur)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}

2.4 头插
- 先将新节点指向头节点
- 新节点变为新的头节点
//头插
void SlistPushFront(SNode** pphead, SLDatatype x)
{
assert(pphead);
SNode* newnode = BuyNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
2.5 尾删
- 链表不能为空
- 找尾节点,同时记录其前驱节点
- 若只有头节点,则将头节点置空
- 多个节点,释放尾节点,将其前驱节点的next置空
void SlistPopBack(SNode** pphead)
{
assert(pphead);
//链表不为空
assert(*pphead);
//只有一个节点
if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
return;
}
//多个节点
SNode* cur = *pphead;
SNode* prev = NULL;
while(cur->next)
{
prev = cur;
cur = cur->next;
}
//释放尾节点
free(cur);
cur = NULL;
prev->next = NULL;
}
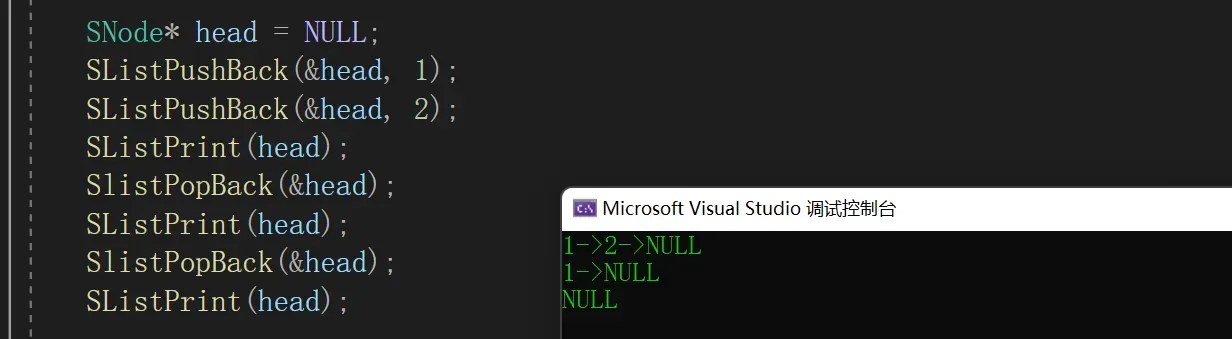
2.6 头删
- cur记录当前头节点,头节点后移
- 释放cur
void SlistPopFront(SNode** pphead)
{
assert(pphead);
assert(*pphead);
SNode* cur = *pphead;
*pphead = (*pphead)->next;
free(cur);
cur = NULL;
}
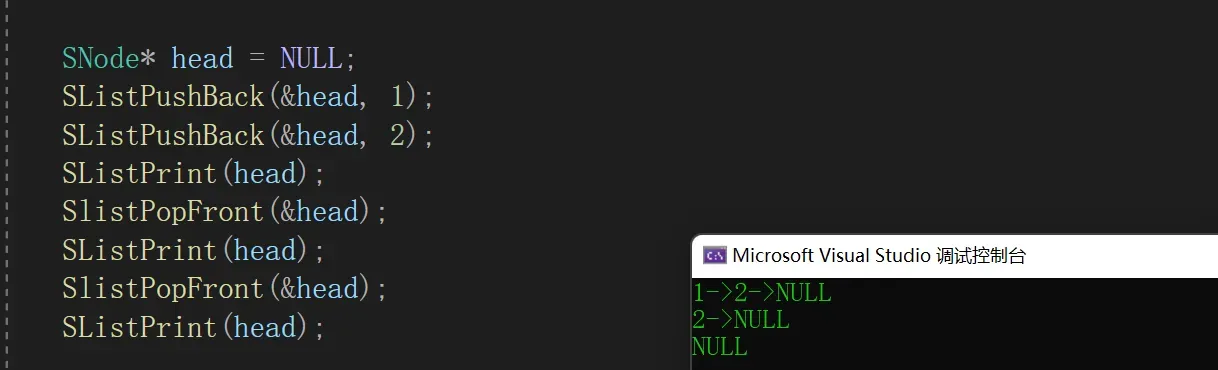
2.7 查找
找到目标,返回指向该目标的指针
//查找
SNode* SListFind(SNode** pphead, SLDatatype x)
{
assert(pphead);
SNode* cur = *pphead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
2.8 指定位置后插入
- 将新节点与pos的后继节点连接
- pos节点指向新节点
//指定位置后插入
void SListInsertAfter(SNode* pos, SLDatatype x)
{
assert(pos);
SNode* newnode = BuyNode(x);
newnode->next = pos->next;
pos->next = newnode;
}
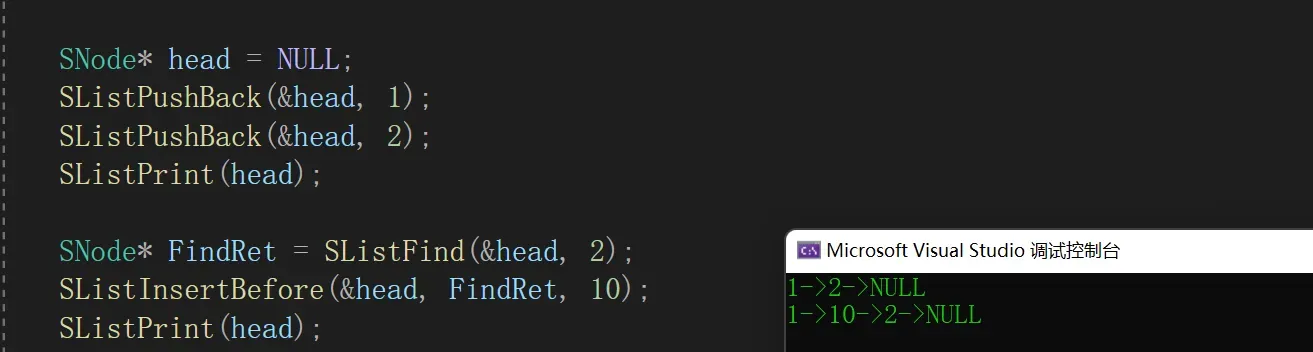
2.9 指定位置前插入
- 若指定位置为头节点,则选择头插
- 找到pos位置的前驱节点,与新节点相连
void SListInsertBefore(SNode** pphead, SNode* pos, SLDatatype x)
{
assert(pphead);
assert(pos);
//指定位置为头节点,执行头插
if (pos == *pphead)
{
SlistPushFront(pphead, x);
return;
}
//找pos位置的前驱
SNode* cur = *pphead;
while (cur->next != pos)
{
cur = cur->next;
}
SNode* newnode = BuyNode(x);
cur->next = newnode;
newnode->next = pos;
}
2.10 删除指定位置
- 若指定位置为头节点,执行头删
- 前驱节点指向后继节点,释放当前节点
void SListDelePos(SNode** pphead, SNode* pos)
{
assert(pphead);
assert(pos);
//指定位置为头节点,执行头删
if (pos == *pphead)
{
SlistPopFront(pphead);
return;
}
SNode* cur = *pphead;
while (cur->next != pos)
{
cur = cur->next;
}
cur->next = pos->next;
free(pos);
pos = NULL;
}
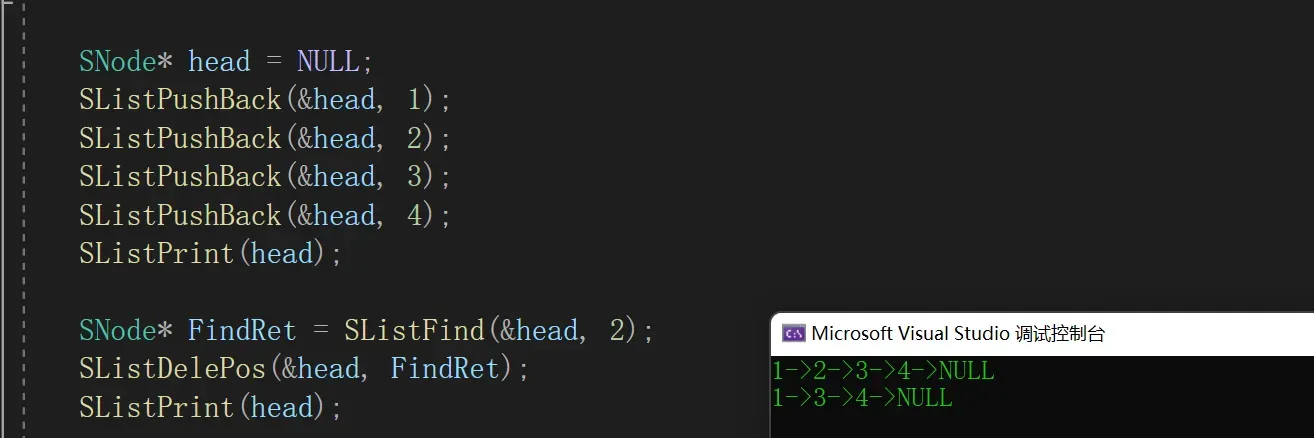
2.11 删除指定位置后的节点
- 指定位置后必须有节点
- 记录指定位置后的节点
- pos指向指定位置后的后继节点
- 释放指定位置后的节点
void SListDeleAfter(SNode* pos)
{
assert(pos);
//后面得有元素
assert(pos->next);
SNode* dele = pos->next;
pos->next = dele->next;
free(dele);
dele = NULL;
}
2.12 销毁单链表
- 先记录后继节点,再销毁当前节点
void SListDestroy(SNode** pphead)
{
assert(pphead);
assert(*pphead);
SNode* next = NULL;
while (*pphead)
{
next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
}
3. 链表种类
链表的结构非常多样,以下情况组合起来就有8种(2x2x2)链表结构:
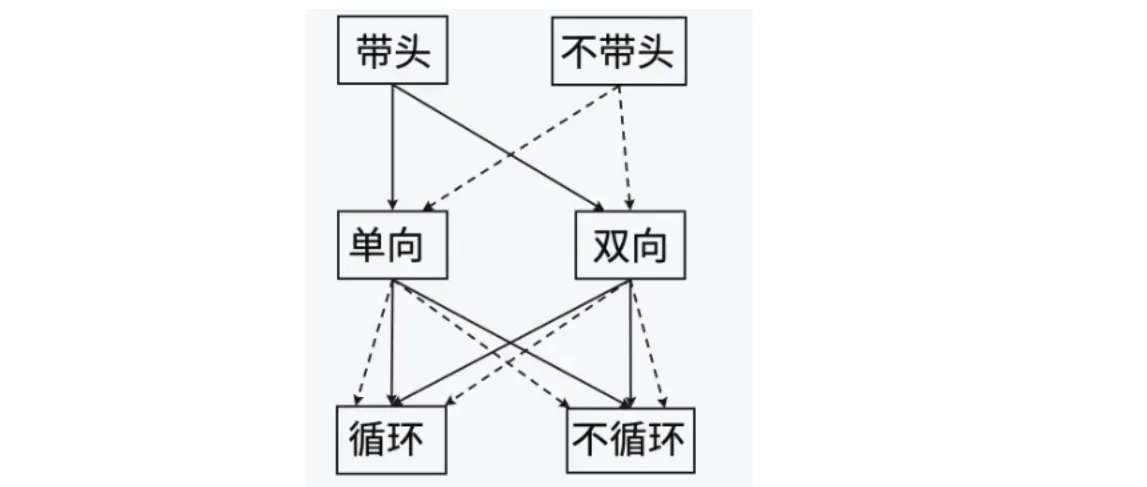
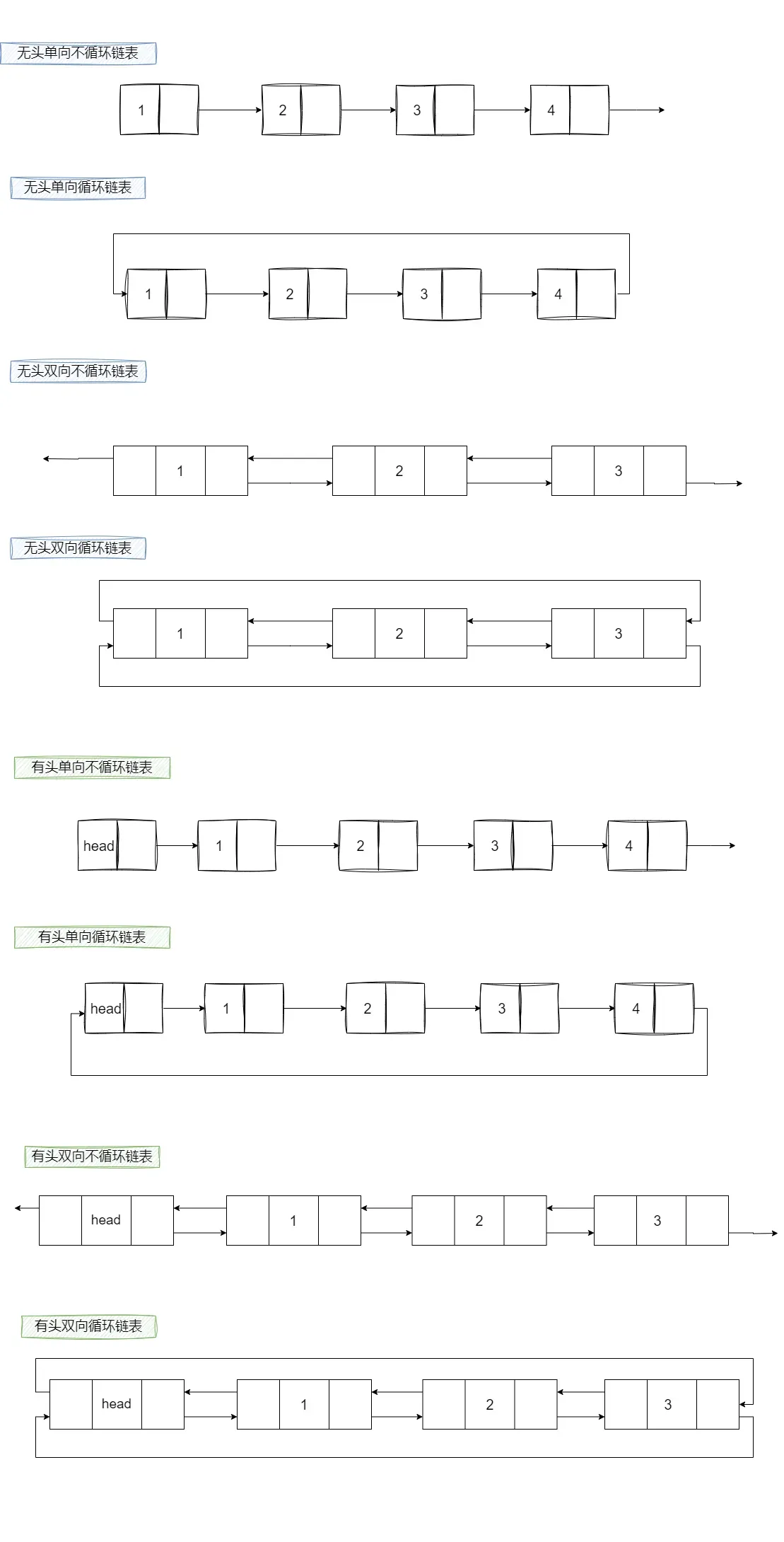
虽然有这么多的链表的结构,但是我们实际中最常用还是两种结构: 单链表和双向带头循环链表
- 无头单向非循环链表:结构简单,⼀般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如哈希桶、图的邻接表等等。另外这种结构在笔试⾯试中出现很多。
- 带头双向循环链表:结构最复杂,⼀般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而简单了
版权声明:本文为博主作者:戴墨镜的恐龙原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_69380220/article/details/136047045