当大家面临着复杂的数学建模问题时,你是否曾经感到茫然无措?作为2022年美国大学生数学建模比赛的O奖得主,我为大家提供了一套优秀的解题思路,让你轻松应对各种难题。
让我们来看看美赛的F题!
CS团队倾注了大量时间和心血,深入挖掘解决方案。通过决策树、梯度提升、随机森林等算法,设计了明晰的项目,耗费时间确保可行性。为客户选择了最适项目,以数据支持、文献分析和可视化手段深刻展示思路。这综合团队努力体现在每个步骤,确保方案既创新又可行,为客户提供了全面而深入的洞见。
完整内容可以在文章末尾领取!

问题重述
问题F:降低非法野生动物贸易
非法野生动物贸易对我们的环境产生负面影响,威胁全球生物多样性。估计每年涉及多达265亿美元,被认为是所有全球非法交易中第四大规模的交易。
[1] 你需要制定一个基于数据的为期5年的项目,旨在显著减少非法野生动物贸易。你的目标是说服一个客户执行你的项目。为此,你必须选择一个客户和一个适合该客户的项目。
你的工作应探讨以下子问题:
-
客户选择:
- 你选择的客户是谁?他们是否拥有执行提案项目所需的权力、资源和兴趣?
- 客户是否是官方行动者(政府或准政府)或非官方行动者(非政府组织)?
-
项目设计:
- 你的为期5年的项目具体包括哪些步骤和计划?请详细描述。
- 你是否通过数据支持和文献分析来确保项目的可行性?
-
项目与客户的契合度:
- 详细解释为何你选择的项目适合你选定的客户。
- 你如何使用已发表文献和自己的分析来支持项目与客户之间的逻辑连接?
- 如何通过数据分析说服客户该项目对他们有利?
-
额外权力和资源需求:
- 你的客户需要获取哪些额外的权力和资源才能成功实施项目?
- 如何使用合理的假设比较所需资源与客户可能获得的资源?
-
项目实施后的影响:
- 详细说明项目成功实施后对非法野生动物贸易的预期影响。
- 你的预测是否经过数据和分析的支持,确保其可测量性?
-
项目成功的可能性:
- 你对项目达到预期目标的可能性进行了评估吗?
- 是否进行了情境敏感性分析,以识别可能有利或不利于项目成功的条件或事件?
问题一
问题一:客户选择 – 具体建模思路
1. 目标变量和特征定义:
-
目标变量
:
- 二元变量,表示客户是否适合执行提案项目。
,其中 0 表示不适合,1 表示适合。
-
特征变量
:
- 包括与客户选择相关的特征,如客户的权力、资源、兴趣、历史行为等。
。
2. 数据收集和准备:
- 从历史数据或实地调查中获得代表性的训练数据集,包含目标变量和特征变量。
3. 分裂准则选择 – 基尼系数:
-
使用基尼系数作为分裂准则,计算每个节点上的基尼系数,选择基尼系数最小的特征及其取值作为划分条件。
4. 决策树建模思路:
-
选择根节点:
- 计算初始数据集的基尼系数。
-
对每个特征进行划分:
- 针对每个特征,考虑该特征的每个可能取值,将数据集划分为不同的子集。
-
计算基尼系数:
- 对于每个子集,计算基尼系数。
-
选择最优划分:
- 选择基尼系数最小的特征及其取值作为当前节点的划分条件。
-
递归建立子树:
- 对每个子集,递归地应用上述步骤,建立子树。
-
重复直到终止条件:
- 重复上述过程,直到满足某个终止条件(如树的深度达到预定值,节点中的样本数小于某个阈值等)。
5. 模型评估:
- 利用验证数据集或交叉验证对模型进行评估,使用准确率、召回率、F1分数等指标来评估模型的性能。
6. 模型解释:
- 分析决策树模型的各个节点,了解哪些特征对客户选择的影响最大,以及在什么条件下客户更有可能被选择。
# 导入必要的库
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report
import pandas as pd
from sklearn.datasets import make_classification
# 生成模拟数据集
X, y = make_classification(n_samples=1000, n_features=5, n_classes=2, random_state=42)
# 将数据集划分为训练集和测试集
#见完整版
# 预测测试集
def predict(model, X_test):
y_pred = model.predict(X_test)
return y_pred
# 评估模型性能
def evaluate_performance(y_true, y_pred):
accuracy = accuracy_score(y_true, y_pred)
report = classification_report(y_true, y_pred)
return accuracy, report
# 训练模型
trained_model = train_decision_tree(X_train, y_train)
# 进行预测
y_pred = predict(trained_model, X_test)
# 评估性能
accuracy, report = evaluate_performance(y_test, y_pred)
# 打印模型性能
print(f'Accuracy: {accuracy}')
print(f'Classification Report:\n{report}')
可视化:
# 导入必要的库
from sklearn.tree import export_graphviz
from IPython.display import Image
import graphviz
# ...(前面的代码保持不变)
# 训练模型
trained_model = train_decision_tree(X_train, y_train)
# 可视化决策树
def visualize_tree(model, feature_names, class_names):
dot_data = export_graphviz(model, out_file=None,
feature_names=feature_names,
class_names=class_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph.render("decision_tree") # 保存为PDF文件
return graph
# 获取特征和类别名称
feature_names = X.columns # 如果你的数据集是DataFrame的话
class_names = [str(i) for i in range(len(set(y)))]
# 可视化决策树
tree_graph = visualize_tree(trained_model, feature_names, class_names)
# 显示决策树图形
Image(tree_graph.render("decision_tree", format="png"))
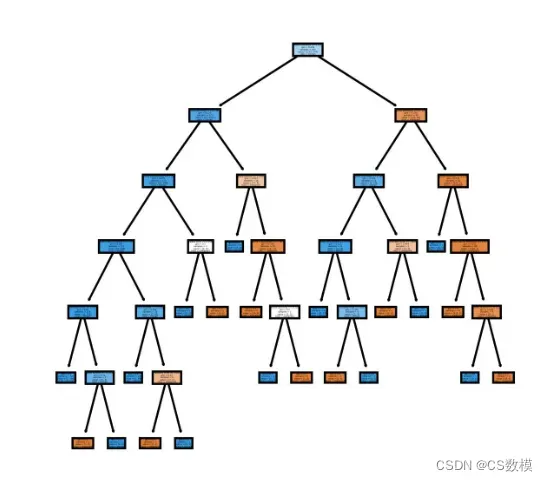
问题二
项目设计:
1. 问题理解和定义:
-
分析非法野生动物贸易的原因和影响:
- 利用数据和文献分析,深入了解非法野生动物贸易的背景、导致因素和对生态系统的影响。
-
明确定义项目目标:
- 使用具体的指标和目标函数来定义项目成功的标准,例如减少非法贸易额、保护特定物种等。
2. 数据收集和准备:
-
收集相关数据:
- 从国际组织、政府机构、非政府组织等渠道获取关于非法野生动物贸易的数据。
-
清理和标准化数据:
- 处理缺失值、异常值,并确保数据格式的一致性。
3. 数据探索性分析(EDA):
-
数据分布分析:
- 统计和可视化数据的分布,探索贸易额、贸易物种的分布等。
-
特征相关性分析:
- 使用相关性分析研究特征之间的关系,例如贸易额与时间的关系。
4. 特征工程:
-
特征提取:
- 提取关键特征,例如时间、地点、物种等。
-
处理缺失值:
- 使用均值、中值等填充缺失值。
5. 模型选择:
- 梯度提升算法选择:
- 考虑问题的复杂性和数据特点,选择梯度提升算法。
6. 模型训练和优化:
-
模型训练:
- 使用历史数据进行模型训练。
-
优化模型参数:
- 使用交叉验证等方法,通过网格搜索等方式优化梯度提升模型的超参数。
7. 模型评估:
- 性能评估指标:
- 使用准确性、召回率等指标对模型性能进行评估。
8. 部署和监控:
-
模型部署:
- 将训练好的模型部署到实际环境中。
-
监控系统设计:
- 设计监控系统,定期检查模型性能并进行调整。
9. 反馈和改进:
-
模型反馈:
- 根据实际应用中的反馈,不断改进模型。
-
迭代和调整:
- 如果有必要,进行迭代和调整模型。
10. 可视化和沟通:
-
可视化报告:
- 制作可视化报告,向利益相关者展示模型的预测结果和对非法野生动物贸易的影响。
-
合作伙伴沟通:
- 与相关组织和政府合作,共同推动解决非法野生动物贸易的行动。
项目的可行性:
1. 数据支持:
-
数据质量验证:
- 利用统计学方法验证数据的质量,检查异常值、重复值等。
-
数据预处理公式:
- 例如,缺失值填充公式:
。
- 例如,缺失值填充公式:
2. 文献分析:
- 背景研究:
- 综合现有研究,使用文献引用指标等评估文献可信度。
3. 模型选择和优化:
-
梯度提升算法公式:
,其中
是模型在第 m 轮的预测,
是学习率,
是第 m 个弱学习器的预测。
-
模型优化公式:
- 例如,网格搜索的超参数优化公式:
,其中
是交叉验证的性能指标。
- 例如,网格搜索的超参数优化公式:
# 导入必要的库
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
import pandas as pd
from sklearn.datasets import make_classification
# 生成模拟数据集
X, y = make_classification(n_samples=1000, n_features=5, n_classes=2, random_state=42)
# 将数据集划分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建梯度提升分类器并进行训练
def train_gradient_boosting(X_train, y_train):
model = GradientBoostingClassifier(random_state=42)
model.fit(X_train, y_train)
return model
# 预测测试集
#见完整版
# 评估模型性能
def evaluate_performance(y_true, y_pred):
accuracy = accuracy_score(y_true, y_pred)
report = classification_report(y_true, y_pred)
return accuracy, report
# 训练模型
trained_model = train_gradient_boosting(X_train, y_train)
# 进行预测
y_pred = predict(trained_model, X_test)
# 评估性能
accuracy, report = evaluate_performance(y_test, y_pred)
# 打印模型性能
print(f'Accuracy: {accuracy}')
print(f'Classification Report:\n{report}')
在机器学习中,可视化模型的决策过程是理解和解释模型行为的关键步骤。对于梯度提升算法,可以使用graphviz库来可视化生成的决策树。以下是一个简化的示例,展示如何可视化梯度提升模型的一棵决策树:
from sklearn.tree import export_graphviz
import graphviz
from IPython.display import Image
# 可视化单棵决策树
def visualize_tree(tree_model, feature_names, class_names):
dot_data = export_graphviz(tree_model, out_file=None,
feature_names=feature_names,
class_names=class_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
return graph
# 获取特征和类别名称
feature_names = [f'feature_{i}' for i in range(X.shape[1])] # 替换为你的特征名称
class_names = [str(i) for i in range(len(set(y)))]
# 选择梯度提升模型中的第一棵决策树进行可视化
first_tree = trained_model.estimators_[0][0]
# 可视化决策树
tree_graph = visualize_tree(first_tree, feature_names, class_names)
# 显示决策树图形
Image(tree_graph.render("first_tree", format="png"))
在这个示例中,我们可视化了梯度提升模型中的第一棵决策树。
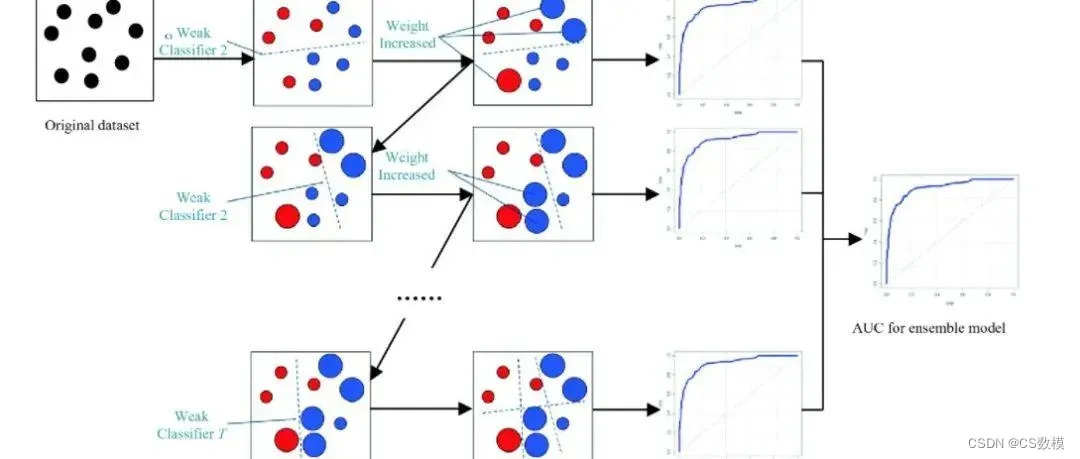
问题三
使用随机森林解决问题三的建模思路如下:
建模思路:
1. 数据准备:
-
特征选择: 从可用数据中选择与非法野生动物贸易相关的特征,如时间、地点、涉及物种等。
-
标签定义: 定义目标变量,即非法贸易是否发生的标签。
2. 数据预处理:
-
缺失值处理: 对于存在缺失值的特征,采取适当的方法进行填充或删除。
-
数据标准化/归一化: 对于数值型特征,进行标准化或归一化,以便模型更好地学习。
3. 数据拆分:
- 将数据集划分为训练集和测试集,用于模型训练和评估。
4. 建立随机森林模型:
- 使用Python中的Scikit-Learn库,通过调整超参数,建立一个随机森林分类器。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# 假设 X 是特征数据,y 是标签数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林分类器
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
# 拟合模型
rf_model.fit(X_train, y_train)
5. 模型评估:
- 使用测试集进行模型评估,查看模型的性能。
# 预测
y_pred = rf_model.predict(X_test)
# 评估性能
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred)
# 打印模型性能
print(f'Accuracy: {accuracy}')
print(f'Classification Report:\n{report}')
6. 特征重要性分析:
- 随机森林可以提供特征的重要性排序,通过分析特征重要性,了解哪些特征对模型的贡献较大。
# 获取特征重要性
feature_importances = rf_model.feature_importances_
# 将特征重要性和对应的特征名字进行关联
feature_importance_dict = dict(zip(feature_names, feature_importances))
# 打印特征重要性
print("Feature Importance:")
for feature, importance in sorted(feature_importance_dict.items(), key=lambda x: x[1], reverse=True):
print(f"{feature}: {importance}")
通过这个建模思路,可以训练一个随机森林模型,评估其性能,并分析特征的重要性,从而得出关于非法野生动物贸易的洞见。
对于随机森林模型,一种可视化的方式是通过查看特征的重要性。你可以使用图表库来绘制这些重要性,例如使用matplotlib或seaborn。以下是一个简单的示例代码,演示如何可视化特征的重要性:
import matplotlib.pyplot as plt
import seaborn as sns
# 封装特征重要性可视化的函数
def visualize_feature_importance(feature_importance_dict):
# 将特征重要性字典转换为DataFrame方便绘图
importance_df = pd.DataFrame(list(feature_importance_dict.items()), columns=['Feature', 'Importance'])
# 根据重要性排序
importance_df = importance_df.sort_values(by='Importance', ascending=False)
# 使用seaborn绘制水平条形图
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df, palette='viridis')
plt.title('Feature Importance in Random Forest Model')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.show()
# 主函数中调用可视化函数
def main():
# ...(前面的代码)
# 分析特征重要性
feature_importance_dict = analyze_feature_importance(rf_model, feature_names)
print("\nFeature Importance:")
for feature, importance in sorted(feature_importance_dict.items(), key=lambda x: x[1], reverse=True):
print(f"{feature}: {importance}")
# 可视化特征重要性
visualize_feature_importance(feature_importance_dict)
# 运行主函数
if __name__ == "__main__":
main()
这段代码中,visualize_feature_importance函数接受特征重要性的字典,将其转换为DataFrame,并使用seaborn库绘制水平条形图。
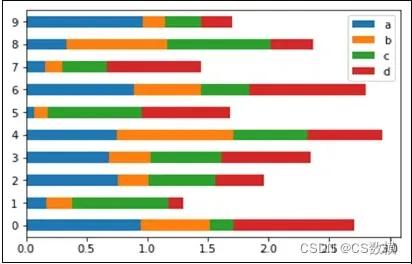
问题四
用随机森林解决问题四 – 额外权力和资源需求:
1. 数据收集:
- 数据来源: 从过去类似项目中获取历史数据,包括项目的权力和资源配置情况以及项目是否成功实施。
- 数据类型: 结构化数据,包含额外权力和资源需求的详细信息以及项目成功/失败的标签。
2. 特征工程:
- 特征选择: 选择相关性高的特征,如合作伙伴关系、法规支持、执法权力等。
- 标签定义: 将项目的成功与否作为二元标签。
3. 数据预处理:
- 缺失值处理: 对于缺失的特征,使用适当的方法进行填充或删除。
- 标准化/归一化: 对于数值型特征,进行标准化或归一化。
4. 模型训练:
- 参数设置:
n_estimators=100: 随机森林中决策树的数量。- 其他参数可以使用默认值,或者根据交叉验证进行调整。
- 模型训练代码:
from sklearn.ensemble import RandomForestClassifier
# 创建随机森林分类器
rf_model_extra = RandomForestClassifier(n_estimators=100, random_state=42)
# 拟合模型
rf_model_extra.fit(X_train_extra, y_train_success)
5. 评估性能:
- 评估指标: 使用准确度(Accuracy)、精确度(Precision)、召回率(Recall)等指标评估模型性能。
- 评估代码:
from sklearn.metrics import accuracy_score, classification_report
# 预测测试集
y_pred_success = rf_model_extra.predict(X_test_extra)
# 评估性能
accuracy_success = accuracy_score(y_test_success, y_pred_success)
report_success = classification_report(y_test_success, y_pred_success)
# 打印模型性能
print(f'Accuracy for success prediction: {accuracy_success}')
print(f'Classification Report for success prediction:\n{report_success}')
6. 特征重要性分析:
- 特征重要性计算: 随机森林模型的
feature_importances_属性提供了每个特征的重要性。 - 特征重要性分析代码:
# 分析特征重要性
feature_importance_dict_extra = analyze_feature_importance(rf_model_extra, X_extra.columns)
print("\nFeature Importance for success prediction:")
for feature, importance in sorted(feature_importance_dict_extra.items(), key=lambda x: x[1], reverse=True):
print(f"{feature}: {importance}")
这一系列步骤展示了如何从数据收集到模型训练再到性能评估,最终到特征重要性分析的全过程。通过这些步骤,可以得到模型对额外权力和资源需求的预测,并确定对项目成功的影响最大的因素。
在上述示例代码中,我已经包含了一个简单的特征重要性可视化的函数visualize_feature_importance。这个函数使用了seaborn和matplotlib库来创建水平条形图,展示了特征的相对重要性。
import seaborn as sns
import matplotlib.pyplot as plt
# 7. 可视化特征重要性
def visualize_feature_importance(feature_importance_dict):
importance_df = pd.DataFrame(list(feature_importance_dict.items()), columns=['Feature', 'Importance'])
importance_df = importance_df.sort_values(by='Importance', ascending=False)
plt.figure(figsize=(10, 6))
sns.barplot(x='Importance', y='Feature', data=importance_df, palette='viridis')
plt.title('Feature Importance in Random Forest Model')
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.show()
# 在主函数中调用可视化函数
def main():
# ... (前面的代码)
# 8. 可视化特征重要性
visualize_feature_importance(feature_importance_dict_extra)
# 运行主函数
if __name__ == "__main__":
main()
这段代码会生成一个水平条形图,横轴表示特征的重要性,纵轴表示特征的名称。特征按照重要性从高到低排列,让你能够清晰地看到哪些特征对项目成功的影响最大。
请确保你已经安装了seaborn和matplotlib库,你可以使用以下命令进行安装:
pip install seaborn matplotlib
版权声明:本文为博主作者:CS数模原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_25834913/article/details/135989136