Value Iteration Adaptive Dynamic Programming for Optimal Control of Discrete-Time Nonlinear Systems ,2016. Qinglai Wei, Member, IEEE, Derong Liu, Fellow, IEEE, and Hanquan Lin
对离散时间非线性系统,采用值迭代ADP算法,求解无限时域无折扣因子最优控制问题。初始值函数为任意半正定。提出新的收敛性分析方法,保证迭代值函数收敛到最优值函数。初始化不同值函数,可证明迭代值函数为单调不增,单调不减或不单调。由于迭代控制策略的可容许性不能仅靠收敛终止判据来保证,因此第一次提出值迭代算法的迭代控制策略的容许性,确定新的终止标准以保证迭代控制策略的有效性。神经网络近似迭代值函数和计算迭代控制策略。最后比较了与Policy Iteration Adaptive Dynamic Programming Algorithm for Discrete-Time Nonlinear Systems,策略迭代PI需要可容许的初始控制,本篇文章选取任意半正定初始值函数更具优势。
与传统的VI算法比较,如Discrete-Time Nonlinear HJB Solution Using Approximate Dynamic Programming: Convergence Proof 2008。实际系统中初始的值函数不为0,迭代算法必须在有限次结束,且传统的VI算法得到的控制策略不能保证稳定。
对初始值函数为任意半正定函数,不能采取上面文章的分析。
Theorem123分别以假定的不同常数δ,给出值函数与最优值函数的不等式关系。
Theorem4给出在上述的常数下都可使得迭代值函数收敛到最优值函数。不同初始值函数有不同的迭代值函数的收敛过程。
Theorem5给出,则迭代值函数为单调不增
,同理Theorem6给出
,则迭代值函数为单调不减
Corollary3给出迭代值函数和迭代控制策略,当迭代值函数单调不增时,满足迭代值函数大于等于最优值函数。同理Corollary4给出当迭代值函数单调不减时,满足迭代值函数小于等于最优值函数。
但仅根据任意初始值函数与最优值函数关系,不能得出迭代值函数的单调性。需要两个初始条件,Lemma1给出初始值函数恒为0时,迭代值函数单调不减收敛到最优值函数。Definition1给出可容许控制,使得系统稳定,且代价函数有界。
Theorem7给出迭代值函数和迭代控制策略下,初始半正定函数满足
![]()
传统的VI算法,收敛标准
Theorem8给出满足收敛终止条件,有系统是一致最终有界UUB。由于迭代控制策略只能使非线性系统UUB,则迭代控制不能代替最优控制,算法也不能仅由上述终止条件收敛。Theorem9给出新的终止条件得到迭代控制策略是可容许的,称为可容许终止条件。Theorem10给出在有限次N迭代的可容许终止条件。
Theorem11给出迭代次数增加时,迭代控制的可容许性
VI值迭代算法的公式
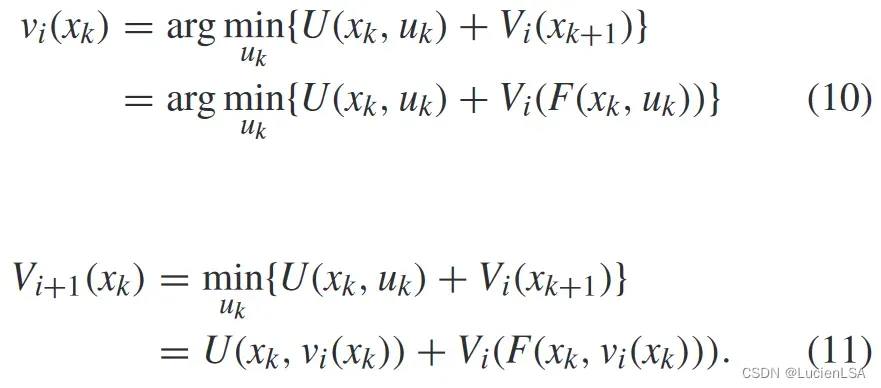

matlab仿真:检验在任意半正定初始值函数下的VI值迭代的可行性
线性系统
function x_next = vi_controlled_system(x,u,A,B)
%--------------------------- controlled system linear----------------------------
x_next = A*x + B*u;
end
代价函数
function y = vi_cost_function(x,u,Q,R)
%----------------------------- cost function ------------------------------
y = (diag(x'*Q*x) + diag(u'*R*u))';
end
评价网络和动作网络
% 动作网络的输入
function y = vi_pf_actor(x)
y = [ x(1,:); x(2,:) ];
end
% 评价网络的输入
function y = vi_pf_critic(x)
y = [ x(1,:).^2; x(1,:).*x(2,:); x(2,:).^2; ];
end
随机函数生成预训练数据
%-------------------------- generate training data ------------------------
clear; close all; clc;
A = [0,0.1; 0.3, -1]; B = [0;0.5];
Q = 1*eye(2); R = 1;
control_dim = 1;
state_dim = 2;
x0 = [1;-1];
Jcompression = 1; % ?
ucompression = 1;
x_train = zeros(state_dim,1);
u_train = zeros(control_dim,1);
for i = 1:30
x_train = [x_train, zeros(state_dim,1)];
x_train = [x_train,4*(rand(state_dim,1)-0.5)]; % [-2 2]
x_train = [x_train,2*(rand(state_dim,1)-0.5)]; % [-1 1]
x_train = [x_train,1*(rand(state_dim,1)-0.5)]; % [-0.5 0.5]
x_train = [x_train,0.2*(rand(state_dim,1)-0.5)]; % [-0.1 0.1]
u_train = [u_train,zeros(control_dim,1)];
u_train = [u_train,4*(rand(control_dim,1)-0.5)]; % [-2 2]
u_train = [u_train,2*(rand(control_dim,1)-0.5)]; % [-1 1]
u_train = [u_train,1*(rand(control_dim,1)-0.5)]; % [-0.5 0.5]
u_train = [u_train,0.2*(rand(control_dim,1)-0.5)]; % [-0.1 0.1]
end
r = randperm(size(x_train,2)); % 随机选取状态数据的某列
x_train = x_train(:,r); % 得到随机的两行训练数据,x1和x2
[~,n] = find(x_train == zeros(state_dim,1)); % 返回训练数据x1和x2中为0元素的索引
zeros_index = [];
for i = 1:size(n,1)/state_dim % 62/2
zeros_index = [zeros_index, n(state_dim*i)]; % 0元素索引
end
ru = randperm(size(u_train,2)); % 随机选取状态数据的某列
u_train = u_train(:,ru); % 设定初始的状态和控制矩阵,用于存放训练的数据
xu_train = [x_train; u_train]; % 状态和控制输入训练数据
x_next_train = A*x_train + B*u_train; % 代入系统,得下一次的训练数据
save state_data x_train u_train xu_train x_next_train zeros_index x0 control_dim state_dim A B Q R
VI算法
加载预训练数据,给出初始任意值函数的权值矩阵,将其转化为二次型。
% This demo checks the feasibility value iteration adaptive dynamic
% programming using an arbitrary positive semi-definite function as
% the initial value function
%-------------------------------- start -----------------------------------
clear; close all; clc;
% utilize vi_state_data.m to generate training data and then run this file
load state_data
% the value function of linear systems can be approximated using quadratic
% form and eigenvalues of its corresponding matrix are 3.9645 and 11.0355
weights_critic_ini = 10*[1;-0.5;0.5]; % 评价网络的任意初始权重
% 线性系统的值函数可近似为二次型
% eigenvalues can be computed by 计算初始的值函数权函数的特征值
P_ini = [ weights_critic_ini(1) weights_critic_ini(2)/2; weights_critic_ini(2)/2 weights_critic_ini(3) ]
eig(P_ini)
weights_critic = weights_critic_ini;
weights_actor = zeros(2,1);
xV = vi_pf_critic(x_train);
xV_minus = vi_pf_critic(-x_train);
xu = vi_pf_actor(x_train);
% 选取值函数和动作策略的输入
epoch = 20;
performance_index = zeros(1,epoch + 1);
performance_index(1) = weights_critic'*vi_pf_critic(x0); % 第一次迭代值函数得到性能指标函数
weights_critic_set = weights_critic;
weights_actor_set = [];
% 存放评价网络和动作网络更新数据
figure(1),plot(0,performance_index(1),'*'),hold on;
h = waitbar(0,'please wait');
for i = 1:epoch
% update action network
% by optimal tool
if i ~= 1 % 当非第1次迭代
actor_target = zeros(control_dim,size(x_train,2));
for j = 1:size(x_train,2)
x = x_train(:,j);
if x == zeros(state_dim,1)
ut = zeros(control_dim,1); % 离线数据为0时,控制输入为0
else
objective = @(u) vi_cost_function(x,u,Q,R) + ...
weights_critic'*vi_pf_critic(vi_controlled_system(x,u,A,B)); % 构造性能指标函数的更新
u0 = weights_actor'*vi_pf_actor(x); % 计算迭代控制策略
ut = fminunc(objective,u0); % 根据性能指标求最优控制策略
end
actor_target(:,j) = ut; % 更新最优控制序列
end
weights_actor = xu'\actor_target'; % 更新动作网络的权重
end
% update critic network
if i == 1
critic_target = vi_cost_function(x_train,0,Q,R)'; % 第一次迭代得到目标值函数V_0
else
x_next = vi_controlled_system(x_train,weights_actor'*xu,A,B);
critic_target = vi_cost_function(x_train,weights_actor'*xu,Q,R)'+ ...
(weights_critic'*vi_pf_critic(x_next))'; % 第2次迭代开始计算迭代值函数
end
weights_critic = [ xV xV_minus]'\[ critic_target; critic_target]; % 评价网络的权重更新
weights_actor_set = [weights_actor_set weights_actor]; % 记录动作网络的权重
weights_critic_set = [weights_critic_set weights_critic]; % 记录评价网络的权重
performance_index(i+1) = weights_critic'*vi_pf_critic(x0); % 性能指标或值函数更新
figure(1),plot(i,performance_index(i+1),'*'),hold on;
waitbar(i/epoch,h,['Training controller...',num2str(i/epoch*100),'%']);
end
close(h);
save actor_critic weights_actor_set weights_actor weights_critic_set weights_critic
figure(1),
xlabel('Iterations');
ylabel('Iterative $V(x_0)$','Interpreter','latex');
set(gca,'FontName','Times New Roman','FontSize',14,'linewidth',1);
grid on;
hold off;
figure(2),
plot((1:length(weights_critic_set))-1,weights_critic_set,'linewidth',1)
xlabel('Iterations');
ylabel('Critic NN weights');
set(gca,'FontName','Times New Roman','FontSize',14,'linewidth',1);
grid on;
figure(3),
plot((1:length(weights_actor_set))-1,weights_actor_set,'linewidth',1)
xlabel('Iterations');
ylabel('Action NN weights');
set(gca,'FontName','Times New Roman','FontSize',14,'linewidth',1);
grid on;
验证VI algorithm with positive semi definite initial value function
% check results
clear; close all; clc;
% 加载系统和成本函数的信息(A、B、Q、R)以及训练过程中保存的状态数据和训练结果。
% information of system & cost function
load state_data.mat % 训练数据
load actor_critic.mat % 训练后的网络的数据
[Kopt, Popt] = dlqr(A,B,Q,R) % 最优增益和最优值函数矩阵(黎卡提方程的解)
Fsamples = 50;
% 设置参数,包括采样数 Fsamples 和初始状态 x0。
x = x0;
x_net = x0;
xx = x.*ones(length(x0),Fsamples+1);
xx_net = x_net.*ones(length(x0),Fsamples+1);
uu_opt = zeros(control_dim,Fsamples);
uu_net = zeros(control_dim,Fsamples);
Jreal = 0;
for k = 1:Fsamples
u_opt = -Kopt*x; % 最优控制
x = vi_controlled_system(x,u_opt,A,B);
uu_opt(:,k) = u_opt;
xx(:,k+1) = x;
u_net = weights_actor'*vi_pf_actor(x_net); % 将初始状态代入动作网络输出控制
Jreal = Jreal + x_net'*Q*x_net + u_net'*R*u_net;
x_net = vi_controlled_system(x_net,u_net,A,B); % 系统状态
uu_net(:,k) = u_net;
xx_net(:,k+1) = x_net;
end
Jopt = x0'*Popt*x0
Jnet = weights_critic'*vi_pf_critic(x0) % 将初始状态代入评价网络输出值函数
Jreal % 动作网络更新的迭代控制代入代价函数
figure(1)
subplot(2,1,1)
plot(0:Fsamples,xx(1,:),'r',0:Fsamples,xx_net(1,:),'b--','linewidth',1)
legend('Optimal','Action network');
ylabel('$x_1$','Interpreter','latex');
set(gca,'FontName','Times New Roman','FontSize',14,'linewidth',1);
grid on;
subplot(2,1,2)
plot(0:Fsamples,xx(2,:),'r',0:Fsamples,xx_net(2,:),'b--','linewidth',1)
legend('Optimal','Action network');
xlabel('Time steps');
ylabel('$x_2$','Interpreter','latex');
set(gca,'FontName','Times New Roman','FontSize',14,'linewidth',1);
grid on;
figure(2)
plot(0:Fsamples-1,uu_opt,'r',0:Fsamples-1,uu_net,'b--','linewidth',1)
legend('Optimal','Action network');
xlabel('Time steps');
ylabel('Controls');
set(gca,'FontName','Times New Roman','FontSize',14,'linewidth',1);
grid on;
% P_ini = [ weights_critic_ini(1) weights_critic_ini(2)/2; weights_critic_ini(2)/2 weights_critic_ini(3) ]
% K_final = -weights_actor' % 迭代控制增益
% P_final = [ weights_critic(1) weights_critic(2)/2; weights_critic(2)/2 weights_critic(3) ] % 迭代值函数
第一次迭代时只计算无控制输入下预训练数据的代价函数(值函数)。
动作网络更新
后续迭代中,状态数据为0时,控制输入设为0,不为0时则计算迭代性能指标函数,并求出迭代控制策略,计算使得迭代性能指标函数最小化时的控制策略,更新动作网络权重。
评价网络更新
每一次迭代动作网络更新完后,更新评价网络,计算下个时间状态和迭代值函数,并更新评价网络权重。
将每次更新权重记录下来。绘出迭代值函数更新过程。
比较该VI法与lqr下求解最优增益和黎卡提方程的解。
亦可选择非线性系统实现
Matlab代码优化改进,采用matlab自带的神经网络工具实现,改进于VI algorithm with initial zero value function
版权声明:本文为博主作者:LucienLSA原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/DarlingLSA/article/details/136787808