一、neo4j介绍
随着社交、电商、金融、零售、物联网等行业的快速发展,现实社会织起了了一张庞大而复杂的关系网,传统数据库很难处理关系运算。大数据行业需要处理的数据之间的关系随数据量呈几何级数增长,急需一种支持海量复杂数据关系运算的数据库,图数据库应运而生。 世界上很多著名的公司都在使用图数据库,比如:社交领域:Facebook, Twitter,Linkedin用它来管理社交关系,实现好友推荐
二、图数据库neo4j安装
-
下载镜像:
docker pull neo4j:3.5.0 -
运行容器:
docker run -d -p 7474:7474 -p 7687:7687 --name neo4j-3.5.0 neo4j:3.5.0 -
停止容器:
docker stop neo4j-3.5.0 -
启动容器:
docker start neo4j-3.5.0 -
浏览器 http://localhost:7474/ 访问 neo4j 管理后台,初始账号/密码 neo4j/neo4j,会要求修改初始化密码,我们修改为 neo4j/123456
三、简单CQL入门
就像我们平常使用关系型数据库中的SQL语句一样,neo4j中可以使用Cypher查询语言(CQL)进行图形数据库的查询,我们简单来看一下增删改查的用法。
添加节点
在CQL中,可以通过CREATE命令去创建一个节点,创建不含有属性节点的语法如下:
CREATE (<node-name>:<label-name>)在CREATE语句中,包含两个基础元素,节点名称node-name和标签名称lable-name。标签名称相当于关系型数据库中的表名,而节点名称则代指这一条数据。 以下面的CREATE语句为例,就相当于在Person这张表中创建一条没有属性的空数据。
CREATE (索尔:Person)而创建包含属性的节点时,可以在标签名称后面追加一个描绘属性的json字符串:
CREATE (
<node-name>:<label-name>
{
<key1>:<value1>,
…
<keyN>:<valueN>
}
)用下面的语句创建一个包含属性的节点:
CREATE (洛基:Person {name:"洛基",title:"诡计之神"})查询节点
在创建完节点后,我们就可以使用MATCH匹配命令查询已存在的节点及属性的数据,命令的格式如下:
MATCH (<node-name>:<label-name>)通常,MATCH命令在后面配合RETURN、DELETE等命令使用,执行具体的返回或删除等操作。 执行下面的命令:
MATCH (p:Person) RETURN p查看可视化的显示结果: 可以看到上面添加的两个节点,分别是不包含属性的空节点和包含属性的节点,并且所有节点会有一个默认生成的
可以看到上面添加的两个节点,分别是不包含属性的空节点和包含属性的节点,并且所有节点会有一个默认生成的id作为唯一标识。
删除节点
接下来,我们删除之前创建的不包含属性的无用节点,上面提到过,需要使用MATCH配合DELETE进行删除。
MATCH (p:Person) WHERE id(p)=100
DELETE p在这条删除语句中,额外使用了WHERE过滤条件,它与SQL中的WHERE非常相似,命令中通过节点的id进行了过滤。 删除完成后,再次执行查询操作,可以看到只保留了洛基这一个节点
添加关联
在neo4j图数据库中,遵循属性图模型来存储和管理数据,也就是说我们可以维护节点之间的关系。 在上面,我们创建过一个节点,所以还需要再创建一个节点作为关系的两端:
CREATE (p:Person {name:"索尔",title:"雷神"})创建关系的基本语法如下:
CREATE (<node-name1>:<label-name1>)
- [<relation-name>:<relation-label-name>]
-> (<node-name2>:<label-name2>)当然,也可以利用已经存在的节点创建关系,下面我们借助MATCH先进行查询,再将结果进行关联,创建两个节点之间的关联关系:
MATCH (m:Person),(n:Person)
WHERE m.name='索尔' and n.name='洛基'
CREATE (m)-[r:BROTHER {relation:"无血缘兄弟"}]->(n)
RETURN r添加完成后,可以通过关系查询符合条件的节点及关系:
MATCH (m:Person)-[re:BROTHER]->(n:Person)
RETURN m,re,n可以看到两者之间已经添加了关联: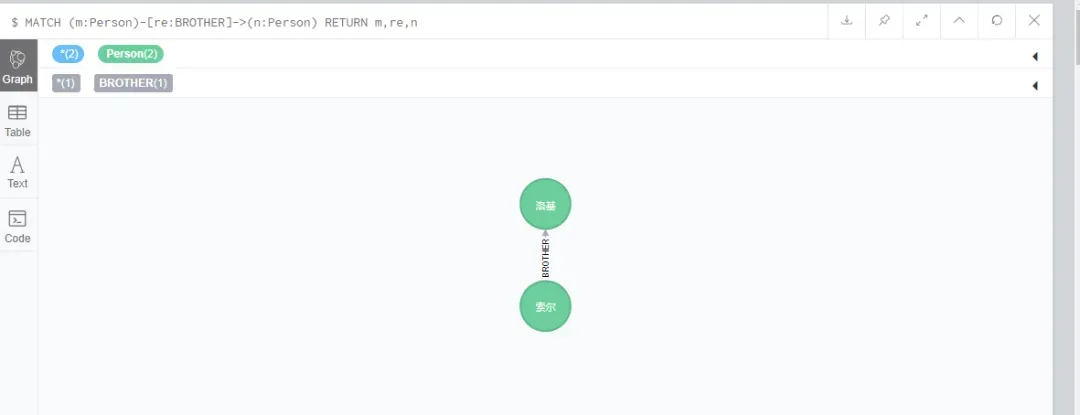 需要注意的是,如果节点被添加了关联关系后,单纯删除节点的话会报错,:
需要注意的是,如果节点被添加了关联关系后,单纯删除节点的话会报错,:
Neo.ClientError.Schema.ConstraintValidationFailed
Cannot delete node<85>, because it still has relationships. To delete this node, you must first delete its relationships.这时,需要在删除节点时同时删除关联关系:
MATCH (m:Person)-[r:BROTHER]->(n:Person)
DELETE m,r执行上面的语句,就会在删除节点的同时,删除它所包含的关联关系了。 那么,简单的cql语句入门到此为止,它已经基本能够满足我们的简单业务场景了,下面我们开始在springboot中整合neo4j。
四、springboot整合neo4j
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>springboot-demo</artifactId>
<groupId>com.et</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>neo4j</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-neo4j</artifactId>
</dependency>
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.2.4</version>
</dependency>
<dependency>
<groupId>edu.stanford.nlp</groupId>
<artifactId>stanford-parser</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
</project>属性文件
server:
port: 8088
spring:
data:
neo4j:
uri: bolt://127.0.0.1:7687
username: neo4j
password: 123456文本SPO抽取
在项目中构建知识图谱时,很大一部分场景是基于非结构化的数据,而不是由我们手动输入确定图谱中的节点或关系。因此,我们需要基于文本进行知识抽取的能力,简单来说就是要在一段文本中抽取出SPO主谓宾三元组,来构成图谱中的点和边。 这里我们借助Git上一个现成的工具类,来进行文本的语义分析和SPO三元组的抽取工作,
项目地址:https://github.com/hankcs/MainPartExtracto
package com.et.neo4j.hanlp;
import com.et.neo4j.util.GraphUtil;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;
import edu.stanford.nlp.ling.Word;
import edu.stanford.nlp.parser.lexparser.LexicalizedParser;
import edu.stanford.nlp.trees.*;
import edu.stanford.nlp.trees.international.pennchinese.ChineseTreebankLanguagePack;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.Collection;
import java.util.LinkedList;
import java.util.List;
/**
* 提取主谓宾
*
* @author hankcs
*/
public class MainPartExtractor
{
private static final Logger LOG = LoggerFactory.getLogger(MainPartExtractor.class);
private static LexicalizedParser lp;
private static GrammaticalStructureFactory gsf;
static
{
//模型
String models = "models/chineseFactored.ser";
LOG.info("载入文法模型:" + models);
lp = LexicalizedParser.loadModel(models);
//汉语
TreebankLanguagePack tlp = new ChineseTreebankLanguagePack();
gsf = tlp.grammaticalStructureFactory();
}
/**
* 获取句子的主谓宾
*
* @param sentence 问题
* @return 问题结构
*/
public static MainPart getMainPart(String sentence)
{
// 去掉不可见字符
sentence = sentence.replace("\\s+", "");
// 分词,用空格隔开
List<Word> wordList = seg(sentence);
return getMainPart(wordList);
}
/**
* 获取句子的主谓宾
*
* @param words HashWord列表
* @return 问题结构
*/
public static MainPart getMainPart(List<Word> words)
{
MainPart mainPart = new MainPart();
if (words == null || words.size() == 0) return mainPart;
Tree tree = lp.apply(words);
LOG.info("句法树:{}", tree.pennString());
// 根据整个句子的语法类型来采用不同的策略提取主干
switch (tree.firstChild().label().toString())
{
case "NP":
// 名词短语,认为只有主语,将所有短NP拼起来作为主语即可
mainPart = getNPPhraseMainPart(tree);
break;
default:
GrammaticalStructure gs = gsf.newGrammaticalStructure(tree);
Collection<TypedDependency> tdls = gs.typedDependenciesCCprocessed(true);
LOG.info("依存关系:{}", tdls);
TreeGraphNode rootNode = getRootNode(tdls);
if (rootNode == null)
{
return getNPPhraseMainPart(tree);
}
LOG.info("中心词语:", rootNode);
mainPart = new MainPart(rootNode);
for (TypedDependency td : tdls)
{
// 依存关系的出发节点,依存关系,以及结束节点
TreeGraphNode gov = td.gov();
GrammaticalRelation reln = td.reln();
String shortName = reln.getShortName();
TreeGraphNode dep = td.dep();
if (gov == rootNode)
{
switch (shortName)
{
case "nsubjpass":
case "dobj":
case "attr":
mainPart.object = dep;
break;
case "nsubj":
case "top":
mainPart.subject = dep;
break;
}
}
if (mainPart.object != null && mainPart.subject != null)
{
break;
}
}
// 尝试合并主语和谓语中的名词性短语
combineNN(tdls, mainPart.subject);
combineNN(tdls, mainPart.object);
if (!mainPart.isDone()) mainPart.done();
}
return mainPart;
}
private static MainPart getNPPhraseMainPart(Tree tree)
{
MainPart mainPart = new MainPart();
StringBuilder sbResult = new StringBuilder();
List<String> phraseList = getPhraseList("NP", tree);
for (String phrase : phraseList)
{
sbResult.append(phrase);
}
mainPart.result = sbResult.toString();
return mainPart;
}
/**
* 从句子中提取最小粒度的短语
* @param type
* @param sentence
* @return
*/
public static List<String> getPhraseList(String type, String sentence)
{
return getPhraseList(type, lp.apply(seg(sentence)));
}
private static List<String> getPhraseList(String type, Tree tree)
{
List<String> phraseList = new LinkedList<String>();
for (Tree subtree : tree)
{
if(subtree.isPrePreTerminal() && subtree.label().value().equals(type))
{
StringBuilder sbResult = new StringBuilder();
for (Tree leaf : subtree.getLeaves())
{
sbResult.append(leaf.value());
}
phraseList.add(sbResult.toString());
}
}
return phraseList;
}
/**
* 合并名词性短语为一个节点
* @param tdls 依存关系集合
* @param target 目标节点
*/
private static void combineNN(Collection<TypedDependency> tdls, TreeGraphNode target)
{
if (target == null) return;
for (TypedDependency td : tdls)
{
// 依存关系的出发节点,依存关系,以及结束节点
TreeGraphNode gov = td.gov();
GrammaticalRelation reln = td.reln();
String shortName = reln.getShortName();
TreeGraphNode dep = td.dep();
if (gov == target)
{
switch (shortName)
{
case "nn":
target.setValue(dep.toString("value") + target.value());
return;
}
}
}
}
private static TreeGraphNode getRootNode(Collection<TypedDependency> tdls)
{
for (TypedDependency td : tdls)
{
if (td.reln() == GrammaticalRelation.ROOT)
{
return td.dep();
}
}
return null;
}
/**
* 分词
*
* @param sentence 句子
* @return 分词结果
*/
private static List<Word> seg(String sentence)
{
//分词
LOG.info("正在对短句进行分词:" + sentence);
List<Word> wordList = new LinkedList<>();
List<Term> terms = HanLP.segment(sentence);
StringBuffer sbLogInfo = new StringBuffer();
for (Term term : terms)
{
Word word = new Word(term.word);
wordList.add(word);
sbLogInfo.append(word);
sbLogInfo.append(' ');
}
LOG.info("分词结果为:" + sbLogInfo);
return wordList;
}
public static MainPart getMainPart(String sentence, String delimiter)
{
List<Word> wordList = new LinkedList<>();
for (String word : sentence.split(delimiter))
{
wordList.add(new Word(word));
}
return getMainPart(wordList);
}
/**
* 调用演示
* @param args
*/
public static void main(String[] args)
{
/* String[] testCaseArray = {
"我一直很喜欢你",
"你被我喜欢",
"美丽又善良的你被卑微的我深深的喜欢着……",
"只有自信的程序员才能把握未来",
"主干识别可以提高检索系统的智能",
"这个项目的作者是hankcs",
"hankcs是一个无门无派的浪人",
"搜索hankcs可以找到我的博客",
"静安区体育局2013年部门决算情况说明",
"这类算法在有限的一段时间内终止",
};
for (String testCase : testCaseArray)
{
MainPart mp = MainPartExtractor.getMainPart(testCase);
System.out.printf("%s\t%s\n", testCase, mp);
}*/
mpTest();
}
public static void mpTest(){
String[] testCaseArray = {
"我一直很喜欢你",
"你被我喜欢",
"美丽又善良的你被卑微的我深深的喜欢着……",
"小米公司主要生产智能手机",
"他送给了我一份礼物",
"这类算法在有限的一段时间内终止",
"如果大海能够带走我的哀愁",
"天青色等烟雨,而我在等你",
"我昨天看见了一个非常可爱的小孩"
};
for (String testCase : testCaseArray) {
MainPart mp = MainPartExtractor.getMainPart(testCase);
System.out.printf("%s %s %s \n",
GraphUtil.getNodeValue(mp.getSubject()),
GraphUtil.getNodeValue(mp.getPredicate()),
GraphUtil.getNodeValue(mp.getObject()));
}
}
}动态构建知识图谱
在上面的基础上,我们就可以在项目中动态构建知识图谱了,新建一个NodeServiceImpl,其中实现两个关键方法parseAndBind和addNode 首先是根据句子中抽取的主语或宾语在neo4j中创建节点的方法,这里根据节点的name判断是否为已存在的节点,如果存在则直接返回,不存在则添加:
package com.et.neo4j.service;
import com.et.neo4j.entity.Node;
import com.et.neo4j.entity.Relation;
import com.et.neo4j.hanlp.MainPart;
import com.et.neo4j.hanlp.MainPartExtractor;
import com.et.neo4j.repository.NodeRepository;
import com.et.neo4j.repository.RelationRepository;
import com.et.neo4j.util.GraphUtil;
import edu.stanford.nlp.trees.TreeGraphNode;
import lombok.AllArgsConstructor;
import org.springframework.stereotype.Service;
import sun.plugin.dom.core.Attr;
import java.util.Arrays;
import java.util.List;
import java.util.Objects;
@Service
@AllArgsConstructor
public class NodeServiceImpl implements NodeService {
private final NodeRepository nodeRepository;
private final RelationRepository relationRepository;
@Override
public Node save(Node node) {
Node save = nodeRepository.save(node);
return save;
}
@Override
public void bind(String name1, String name2, String relationName) {
Node start = nodeRepository.findByName(name1);
Node end = nodeRepository.findByName(name2);
Relation relation =new Relation();
relation.setStartNode(start);
relation.setEndNode(end);
relation.setRelation(relationName);
relationRepository.save(relation);
}
private Node addNode(TreeGraphNode treeGraphNode){
String nodeName = GraphUtil.getNodeValue(treeGraphNode);
Node existNode = nodeRepository.findByName(nodeName);
if (Objects.nonNull(existNode))
return existNode;
Node node =new Node();
node.setName(nodeName);
return nodeRepository.save(node);
}
@Override
public List<Relation> parseAndBind(String sentence) {
MainPart mp = MainPartExtractor.getMainPart(sentence);
TreeGraphNode subject = mp.getSubject(); //主语
TreeGraphNode predicate = mp.getPredicate();//谓语
TreeGraphNode object = mp.getObject(); //宾语
if (Objects.isNull(subject) || Objects.isNull(object))
return null;
Node startNode = addNode(subject);
Node endNode = addNode(object);
String relationName = GraphUtil.getNodeValue(predicate);//关系词
List<Relation> oldRelation = relationRepository
.findRelation(startNode, endNode,relationName);
if (!oldRelation.isEmpty())
return oldRelation;
Relation botRelation=new Relation();
botRelation.setStartNode(startNode);
botRelation.setEndNode(endNode);
botRelation.setRelation(relationName);
Relation relation = relationRepository.save(botRelation);
return Arrays.asList(relation);
}
}本文只是拿出关键代码作讲解,具体的代码参考代码仓库地址里面neo4j模块
代码仓库
-
https://github.com/Harries/springboot-demo
五、测试
启动java应用,输入以下地址
http://127.0.0.1:8088/parse?sentence=海拉又被称为死亡女神
http://127.0.0.1:8088/parse?sentence= 死亡女神捏碎了雷神之锤
http://127.0.0.1:8088/parse?sentence=雷神之锤属于索尔在图数据库neo4j里面查询
MATCH (p:Person) RETURN p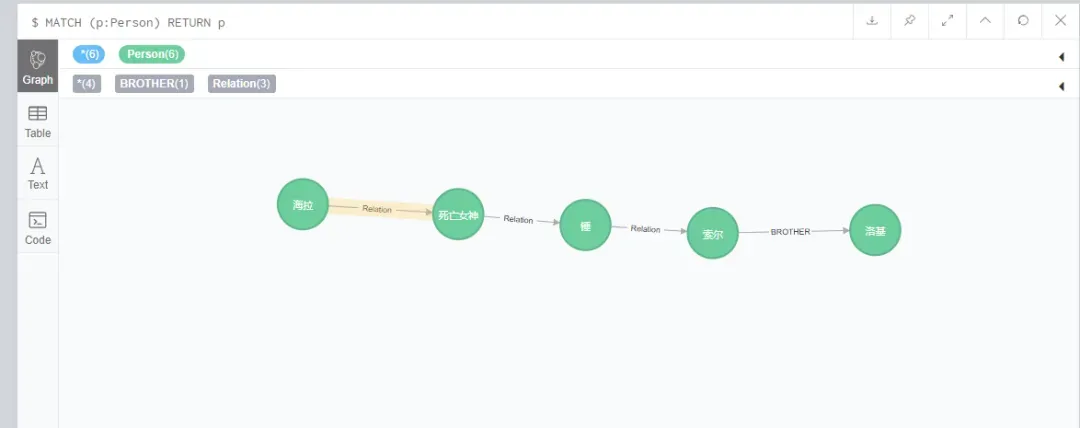
六、引用
-
https://www.cnblogs.com/trunks2008/p/16706962.html
-
http://www.liuhaihua.cn/archives/710286.html
版权声明:本文为博主作者:AskHarries原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/dot_life/article/details/136522194