一、前言
回顾AI绘画的历史,GAN(Generative Adversarial Nets)是比较出众的一个。GAN的出现让AI绘画成为可能,当时GAN给AI绘画提供了一种新的思路,现在回顾当时的绘画可以算是相当粗糙。

gan-results.jpg
初代GAN出现后,出现了大量GAN的变种,比如StyleGAN、CycleGAN、DCGAN等。而StyleGAN已经可以生成非常逼真的图像了,下面是StyleGAN的一些结果。

stylegan-results.jpg
GAN提出已经过去十年,AI绘画也得到了颠覆性的进步。Diffusion Model(DM)逐渐取代了GAN在AI绘画领域的地位。在此基础上,AI绘画领域还融合了其它深度学习方法,比如Controlnet、LoRA等。如今,AI绘画达到了以假乱真的地步,同时给与用户极高的可控性,对资源的要求也逐步降低,每个人都可以在自己的电脑上运行AI绘画模型。
今天我们的主角是Stable Diffusion,它是如今最流行的开源DM。基于Stable Diffusion,开源社区涌现了繁多的开源项目和模型。比如Stable Diffusion Webui、Comfyui、Fooocus等集成应用;分享模型的Civitai网站;HuggingFace提供的Diffusers模块。
今天我们将介绍Stable Diffusion的整体架构,分解每个部件,最后借助Diffusers模块实现AI绘画。
二、网络结构
Stable Diffusion由多个子网络组成,包括文本编码器、UNet和VAE三大部分。组合在一起可以看做一个接收文本输入,输出图像的模型。下面我们将从整体出发,而后拆分每个部件。
2.1 整体架构
Stable Diffusion的架构如图所示:
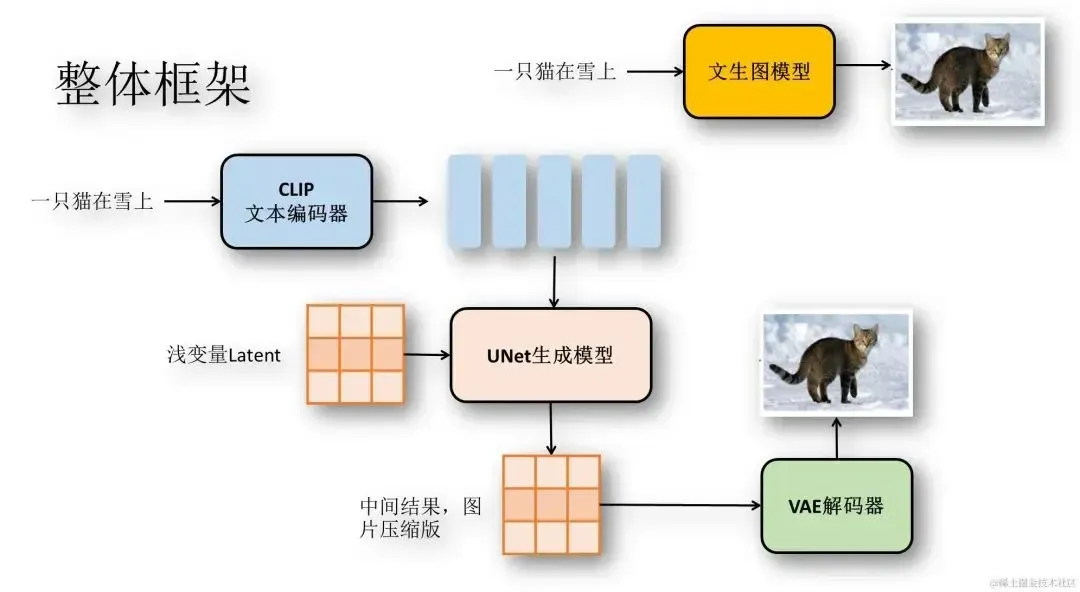
stable-diffusion-structure.jpg
整体上看是一个接收文本输入,并输出图像的模型。Stable Diffusion处理的过程如下:
-
输入文本,使用CLIP模型对文本进行编码,获得文本Embedding
-
从潜空间生成噪声Latent
-
将文本Embedding和Latent输入UNet模型,预测Latent中的噪声
-
将去除Latent中的噪声,去除噪声后的结果重新赋值为Latent
-
重复步骤3、4
-
将Latent传入VAE解码器,得到最终图片
模型的核心是一个UNet噪声预测网络。不同于GAN直接从噪声中生成图片,Stable Diffusion会进行多次预测噪声并降噪,最终生成图片。
2.2 文本编码器
Stable Diffusion是一种带条件的图像生成模型,可以根据输入的文本生成与文本相符的图片。我们可以直接使用训练良好的Bert模型作为文本编码器,但是这样生成的文本向量和图像的关系不太密切,为了图像生成能更遵循文本条件,Stable Diffusion使用了CLIP模型。
CLIP模型的提出是为了更好的解决视觉任务,CLIP可以在zero-shot的情况下在ImageNet上与ResNet50有同等的表现。
下面是OpenAI提供的CLIP工作图:
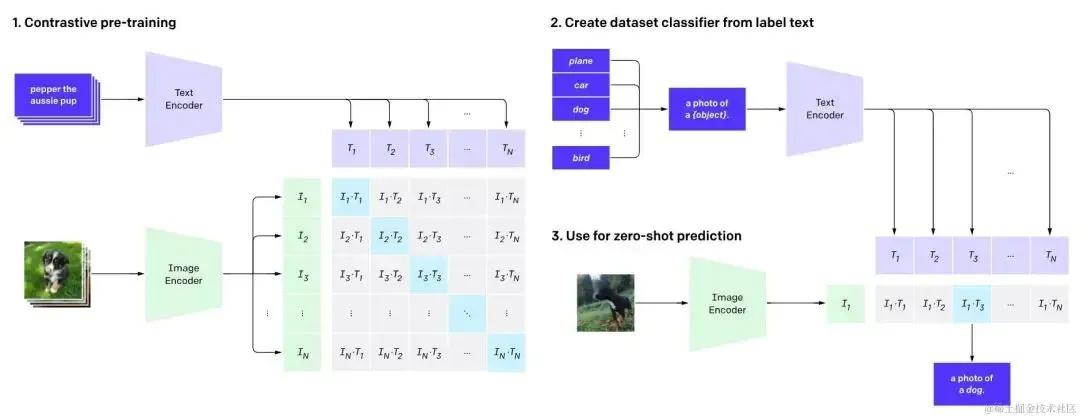
clip-training-steps.jpg
从结构上来看,CLIP模型由两个Encoder构成,分别是用来编码文本的TextEncoder和用来编码图片的ImageEncoder。CLIP的训练数据是一堆“图片-文本”对形式,其工作模式如下:
-
训练TextEncoder和ImageEncoder,最大化ItTt(图片向量与响应的文本向量相似度)
-
利用分类标签生成句子,“a photo of a {object}”
-
输入图片获得It,找到最相似的句子向量Tk,改句子对应的标签就是图片标签 在完成训练后就可以得到比较出色的文本编码器,而后两步则是为图像分类做准备。
2.3 VAE模型
VAE模型在Diffusion Model里面并非必要的,VAE在Stable Diffusion中作为一种有效利用资源的方法,减少了图片生成的资源需求。下图是VAE的结构,其中c是一个可选的条件。
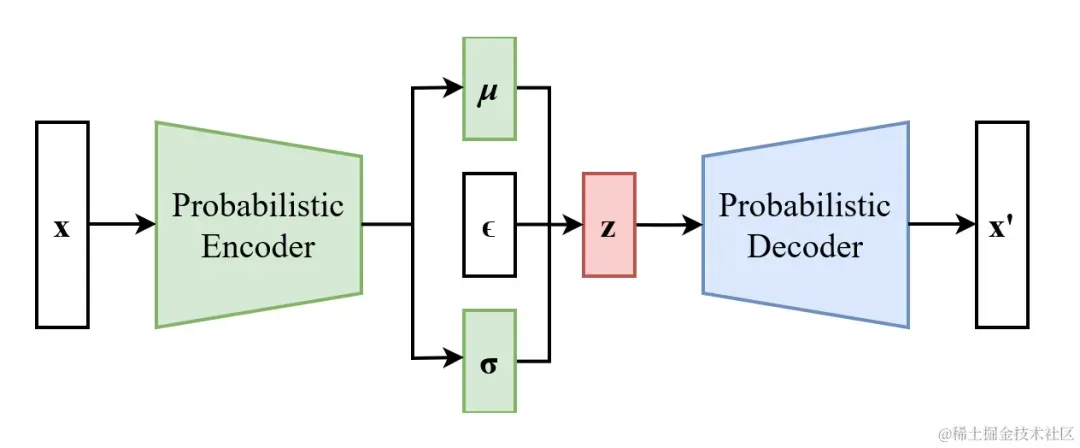
vae-structure.png
VAE由Encoder和Decoder两个部分组成,首先需要输入x,经过Encoder编码后,得到(μ,σ),分别表示均值和方差,这两个变量可以确定一个分布,然后在当前分布中采样出样本z。z通常是一个比x维度更低的向量。
采样出来的z输入Decoder,我们希望Decoder的输出与输入的x越接近越好。这样我们就达到了图像压缩的效果。
在训练Stable Diffusion时,我们会把图片输入VAE的Encoder,然后再拿来训练UNet,这样我们就可以在更低的维度空间训练图像生成模型,这样就可以减少资源的消耗。
2.4 UNet模型
UNet模型结构与VAE非常相似,也是Encoder-Decoder架构。在Stable Diffusion中,UNet作为一个噪声预测网络,在绘画过程中需要多次推理。我们先不考虑VAE的介入,来看看UNet在Stable Diffusion中的作用。
实际上UNet在Stable Diffusion中充当噪声预测的功能。UNet接收一张带有噪声的图片,输出图片中的噪声,根据带噪声的图片和噪声我们可以得到加噪前的图片。这个降噪的过程通常会重复数十遍。
知道UNet的作用后,我们就需要创建数据集了。我们只需要图片即可,拿到图片对该图片进行n次加噪,直到原图变成完全噪声。而加噪前的图片可以作为输入,加噪后的数据可以作为输出。如图所示:

noising_step.jpg
在加噪的过程中,噪声逐步增大。因此在降噪的过程中,我们需要有噪声图片,以及当前加噪的step。下图是噪声预测部分的结构:
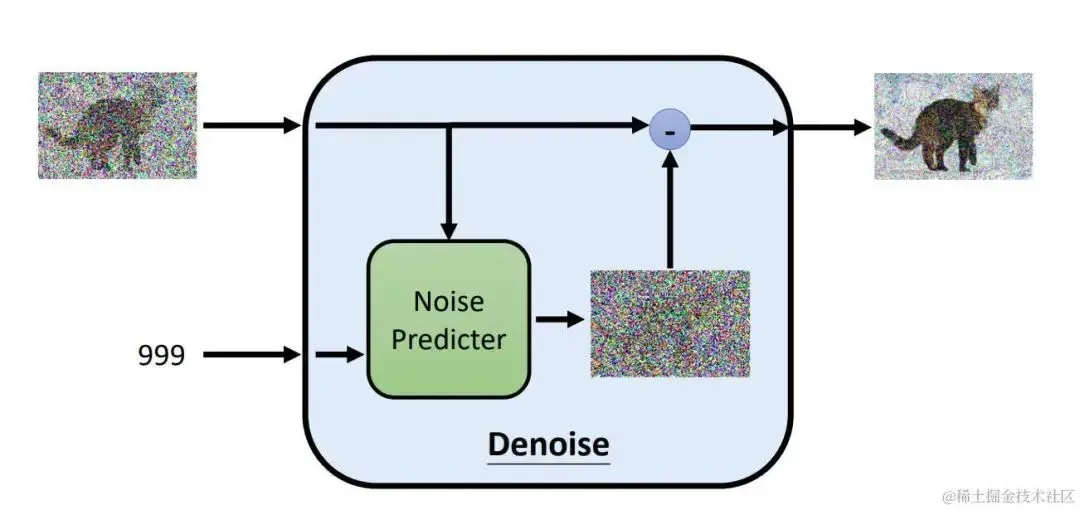
noise-predicter.jpg
最后图像生成的步骤就是不停降噪的步骤:
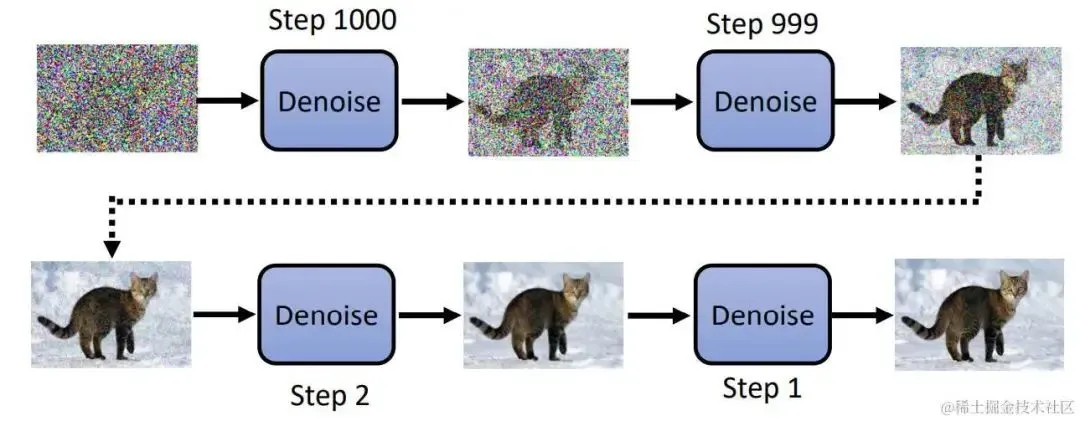
denoising-step.jpg
最后,我们再加入VAE。我们加噪和预测噪声的步骤不再是作用在原图上,而是作用在VAE Encoder的输出上面,这样我们就可以在较小的图像上完成UNet的训练,极大减少资源的消耗。
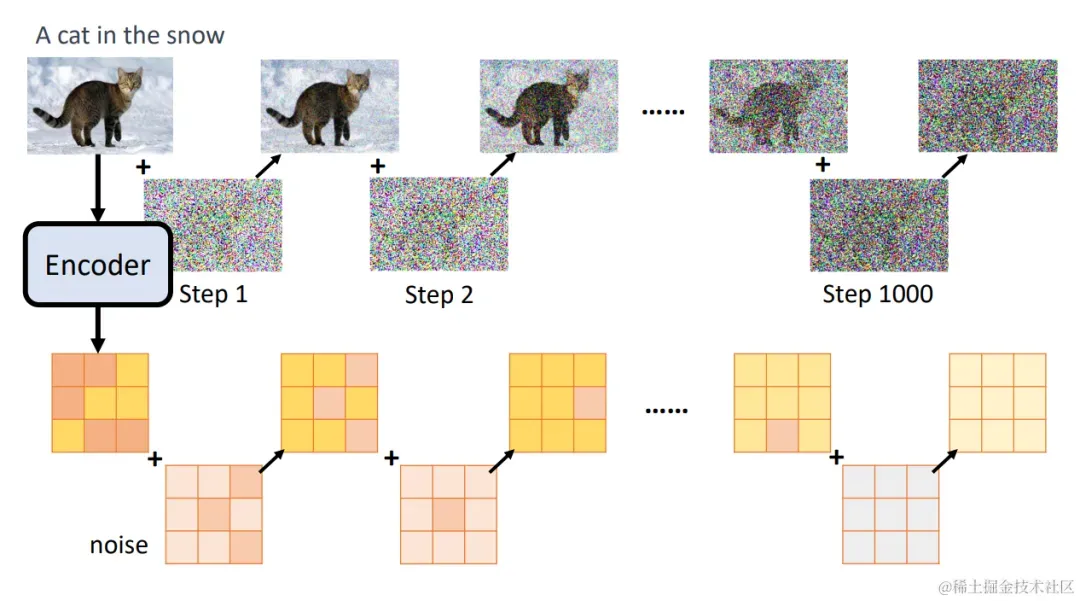
unet-vae.png
现在只需要在UNet的输入中再加入文本变量就是完整的Stable Diffusion了。
三、Diffusers模块
现在我们已经知道Stable Diffusion的原理,为了加深理解,下面使用Diffusers模块实现Stable Diffusion的全过程。下面的代码需要使用到pytorch、transformers和diffusers模块。
3.1 使用pipeline
HuggingFace中的模块提供了许多pipeline用于各种任务,而Stable Diffusion则是Text-to-image类型的任务,我们可以使用下面几句代码完成文生图:
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained(
"runwayml/stable-diffusion-v1-5", torch_dtype=torch.float16, variant="fp16"
).to("cuda")
image = pipeline(
"stained glass of darth vader, backlight, centered composition, masterpiece, photorealistic, 8k"
).images[0]
image
生成图像如下:

generated01.PNG
上面是一种简单的调用方式,下面我们加载各个部件,手动完成图像生成的过程。
3.2 加载各个部件
除了pipeline直接加载,我们还可以分部件加载,分别加载CLIP、UNet和VAE,代码如下:
from tqdm.auto import tqdm
from PIL import Image
import torch
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, DDPMScheduler
# 加载模型
model_path = "runwayml/stable-diffusion-v1-5"
vae = AutoencoderKL.from_pretrained(model_path, subfolder="vae")
tokenizer = CLIPTokenizer.from_pretrained(model_path, subfolder="tokenizer")
text_encoder = CLIPTextModel.from_pretrained(
model_path, subfolder="text_encoder"
)
unet = UNet2DConditionModel.from_pretrained(
model_path, subfolder="unet"
)
scheduler = DDPMScheduler.from_pretrained(model_path, subfolder="scheduler")
# 使用gpu加速
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
在这里我们还加载了Scheduler,后续会使用Scheduler管理降噪的步骤。
3.3 对文本进行编码
下面我们使用CLIP模型对文本进行编码,这里要使用到tokenizer和text_encoder:
# 对文本进行编码
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 25 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
batch_size = len(prompt)
text_input = tokenizer(
prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt"
)
with torch.no_grad():
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
其中text_embeddings就是文本编码结果。
3.4 获取潜变量
在训练过程中潜变量Latent是由VAE的Encoder得到的,而在生成过程中,Latent则是符合一定分别的随机噪声。代码如下:
# 获取latent
latents = torch.randn(
(batch_size, unet.config.in_channels, height // 8, width // 8),
device=torch_device,
)
latents = latents * scheduler.init_noise_sigma
torch.randn可以得到方差为1的噪声,而latents * scheduler.init_noise_sigma则把方差修改为scheduler.init_noise_sigma。
3.5 降噪
接下来就是重复多次UNet推理,得到降噪后的Latent:
# 降噪
scheduler.set_timesteps(num_inference_steps)
for t in tqdm(scheduler.timesteps):
latent_model_input = latents
latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
with torch.no_grad():
# 预测噪声
noise_pred = unet(
latent_model_input,
t,
encoder_hidden_states=text_embeddings
).sample
# 降噪
latents = scheduler.step(noise_pred, t, latents).prev_sample
最后得到的latents变量就是降噪后的结果,在训练过程中对应VAE Encoder的输出,因此我们还需要使用VAE Decoder还原出图片。
3.6 VAE解码
下面就是使用VAE Decoder解码出原图:
# 使用vae解码
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
image = (image / 2 + 0.5).clamp(0, 1).squeeze()
image = (image.permute(1, 2, 0) * 255).to(torch.uint8).cpu().numpy()
images = (image * 255).round().astype("uint8")
image = Image.fromarray(image)
image.show()
最后生成如下图片:

generated02.PNG
四、总结
今天我们以GAN开始,介绍了AI绘画领域的一些模型,并把Stable Diffusion作为今天的主角,详解介绍了Stable Diffusion的实现原理。
我们还使用Diffusers模块实现了Stable Diffusion生成图像的代码。在Stable Diffusion中,还有诸如LoRA、Controlnet等相关技术,在本文没有详细提到。而这些东西在AI绘画中却非常重要,也让AI绘画可以应用在更多领域。
我们可以使用Stable Diffusion Webui等工具使用LoRA和Controlnet等工具,我们还可以在Diffusers中使用这些根据。后续我们将介绍Diffusers模块如何加载LoRA等附加网络。
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。

AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
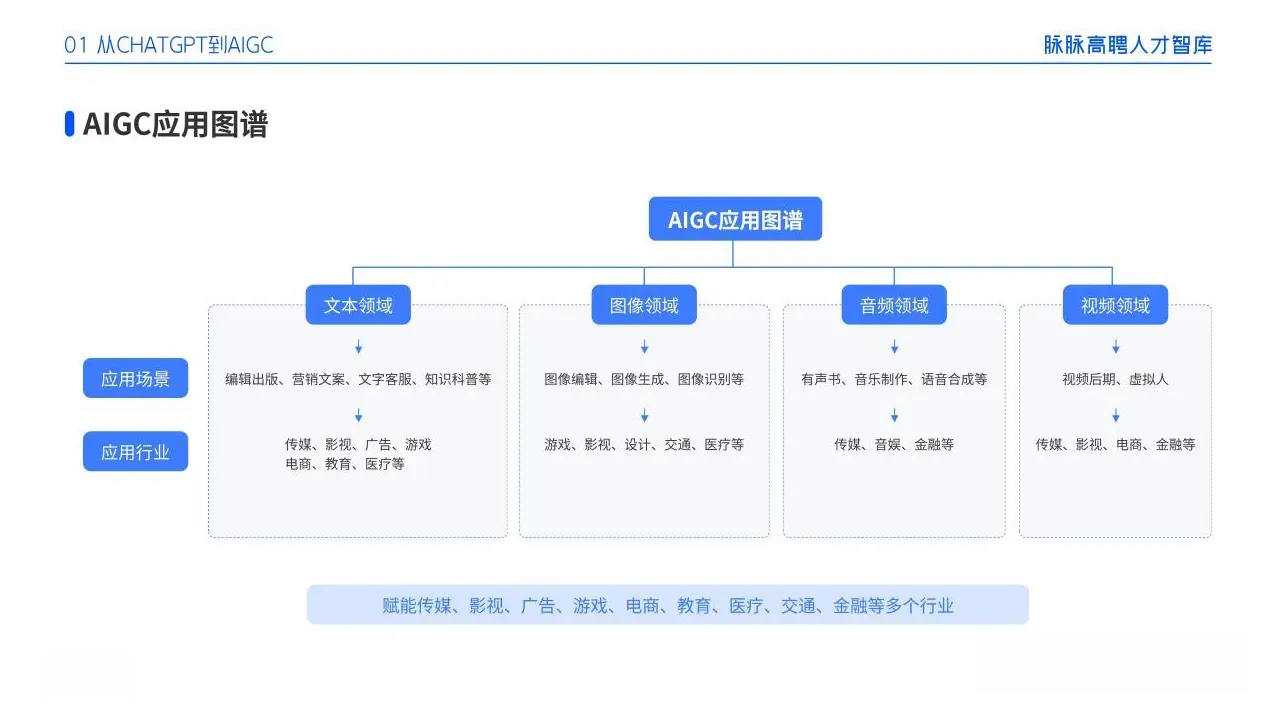
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
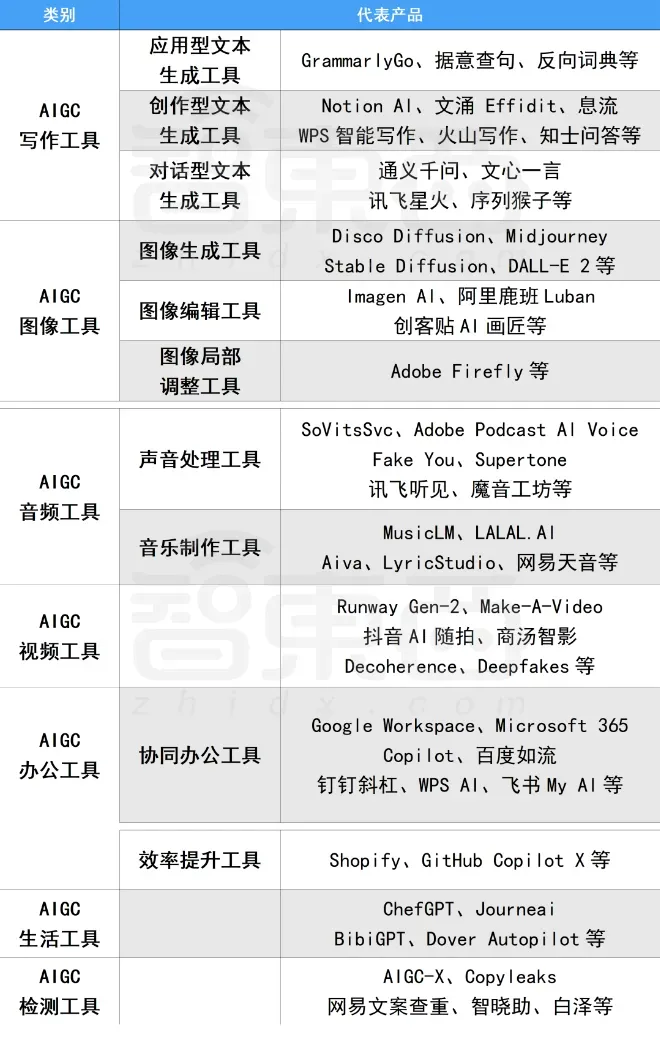
二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。


四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
版权声明:本文为博主作者:程序员晓晓原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/cxyxx12/article/details/136036009