前言:c++是一门既面向对象又面向过程的语言。 不同于java纯粹的面向对象和c纯粹的面向过程。 造成c++该特性的原因是c++是由本贾尼大佬在c的基础上增添语法创建出来的一门新的语言。 它既兼容了c, 身具面向过程的特性。 又有本身的面向对象的特性。
面向对象和面向过程的区别:
我们可以以将大象关进冰箱为例子。 如果是c语言的话。它只会关注将大象关进冰箱的过程——打开冰箱门, 将大象关进冰箱, 关闭冰箱。但如果是c++的话,它会关注解决这个问题的对象——人, 大象, 冰箱。
然后c语言的函数解决的就是每一步骤如何做才能将大象装进行冰箱。c++的函数就是定义在对象的类里作为成员函数,作为这个对象解决问题的手段, 方法。
目录
命名空间
命名空间解决的是变量重命名的问题。 在c语言中,当我们向定义一个变量, 这个变量的变量名和库中的函数或者其他重复了。
#include<stdlib.h>
int main()
{
int rand;//这时会和stdlib.h中的rand生成随机数函数重复。 c语言除了将变量名改掉没有办法。
return 0;
}可能这个问题你认为只要改一下变量名就好了。但是如果是在公司之中。 那个时候许多人共同开发一个程序。 不可避免地会有变量名重复的问题。 如果事先商量好说“谁谁谁这么取名, 谁谁谁那么取名。”或者说如果两个人定义的变量名冲突后就商议一下谁改掉谁的程序中所有的这个变量的变量名。 这个就太烦了。 所以本贾尼大佬针对这个问题就创建出来了命名空间, 有效的解决了这个问题。
域操作符
namespace name
{
int A()
{
return 1;
}
}
int main()
{
int A = 0;//因为A函数是在命名空间name中定义的。 所以函数A不会和这里的变量A重命名。
cout << A << endl;
return 0;
}
想要使用命名空间内的函数或者变量。 有两种方法:一种是使用“::”作用域操作符, 一种是直接将作用域展开。
namespace name
{
int A()
{
return 1;
}
}
int main()
{
//int A = 0;//因为A函数是在命名空间name中定义的。 所以函数A不会和这里的变量A重命名。
name::A();//::前面加作用域, 如果是全局就不写作用域
return 0;
}
::前面加作用域, 如果是全局就不写作用域

这里打印的A前面加了域操作符。 且查找的是全局
展开命名空间
我们正常情况下直接包含头文件
#include<iostream>
int main()
{
int i = 0;
cout << i << endl;//编译不过
return 0;
}
这样是编译不过的, 因为cout 和 endl都被包含在std命名空间中。 std命名空间就是c++的标准库命名空间。
想要使用cout 和endl必须用与操作符在std中寻找使用。 或者直接将std展开
#include<iostream>
using namespace std;//using 就是展开空间
int main()
{
int i = 0;
cout << i << endl;//此时可以编过
return 0;
}using就是命名空间展开的关键字。 using后面加命名空间就可以将一个命名空间展开。 或者加命名空间中的一个函数或其他成员。 意思就是将其从命名空间中展开到全局。
#include<iostream>
using std::cout;
using std::endl;
int main()
{
int i = 0;
cout << i << endl;//编译不过
return 0;
}
这样也可以, 这样只展开了cout和endl。
c++的输入和输出
从上面我们已经看到了输出 对象”cout“, 它是标准输出对象终端, 或者说是控制台。
然后我们再看一下输入 “cin”,它是标准输入对象。
<< 是流插入操作符。 “cout << 数据” 的意思就是将数据输出到终端, 好处就是自行判断输出数据的类型。
>> 是流提取操作符。”cin >> 内存“的意思就是将流中的数据输入到内存中, 好处也是自行判断格式,不需要自行判断。
endl标识换行输出。
以上都包含在iostream头文件中的std命名空间中。
缺省参数
#include<iostream>
using namespace std;
int Add(int x = 0, int y = 0)
{
return x + y;
}
int main()
{
int a = 1;
int b = 1;
int ret1 = Add();//输出0
int ret2 = Add(a, b);//输出2
cout << ret1 << "\n" << ret2 << endl;
return 0;
}当我们调用函数时没有进行传参时, 函数如果定义了缺省参数, 那么这个被调用的函数就会使用缺省参数。
如图中
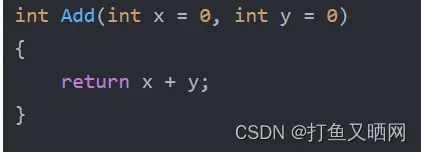
这个int x = 0, int y = 0就是缺省参数定义的方式。
然后, 当我们传参时如果没有传参, 就像图中的第一次调用
这个时候就会使用缺省参数。 x 为0, y 也是0。所以计算出来的就是0。
上面定义的是全缺省参数。 定义缺省参数时, 也可以半缺省 。
#include<iostream>
using namespace std;
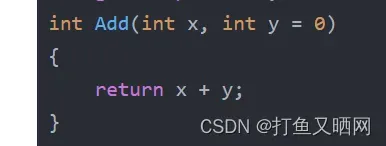
int Add(int x, int y = 0)
{
return x + y;
}
int main()
{
int a = 1;
int b = 1;
int ret1 = Add(a);//输出1
cout << ret1 << endl;
return 0;
}半缺省参数是从右向左定义的 ,向这个图中的Add函数就是定义的y为半缺省。 注意不能定义x为半缺省。定义半缺省要从右向左!
函数重载
c++函数重载是很重要的一个知识点。就是说可以同时存在多个同名的函数。只要他们的参数个数不同或者参数的类型不同,或类型顺序不同。这时, 这些函数就构成函数重载。
#include<iostream>
using namespace std;
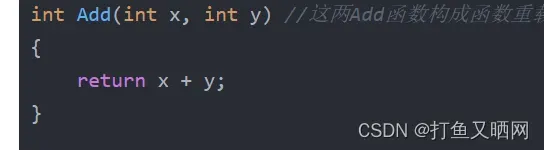
int Add(int x, int y) //这两Add函数构成函数重载
{
return x + y;
}
double Add(double x, double y) //
{
return x + y;
}
int main()
{
int ret1 = Add(1, 2);
double ret2 = Add(1.1, 2.2);
cout << ret1 << " " << ret2 << endl;
return 0;
}这串代码中两个Add函数就构成了函数重载。 因为他们的参数类型不同。
注意:编译器这里分辨不同函数不是通过返回类型。 而是通过参数类型, 参数个数, 不同类型参数顺序。它的分辨本质就是将函数转函数一种符号表的形式。
假如
转化后就类似于:Addii ,这里的Add是函数名。 ii是标识两个类型。i是int首字母。

这个就转换为Adddd, Add同样是函数名, dd是两个类型。 d是double首字母
这里的具体转换规则是什么我并不清楚。 只是意思就是这个意思。 有兴趣的话可以去查找相关资料
引用
大件来了!
引用, 为了避免使用指针而创造出来的一个类似于指针的语法。
引用就是一个变量的别名。
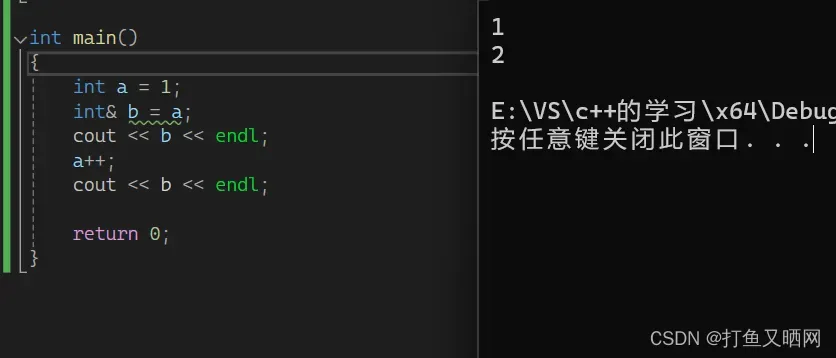
引用是变量的别名。 我们可以想象a 和 b共同代表着一个空间。 a的数据改变。 b也就改变了。
有了引用后, 我们交换函数就有了另一种定义方法:
这里形参x 是a的别名,语法上x就是a。 y是b的别名,语法上y就是b。所以交换x和y的值, 就交换了a和b的值。
内联函数
内联函数inline + 函数定义
内联函数和宏定义函数对应。
宏定义在预处理阶段通过代码替换。来达到简单的函数的作用,提高行能。但是宏也有没有类型检查, 无法调试等缺点。
内敛函数在拥有着宏定义的优点:同样不用调用函数,直接将代码在原调用位置展开,提高性能。
内联函数是在编译阶段,将函数体在原调用位置展开。
内联函数不能将声明和定义定义在不同的文件之中。 否则可能报错。
对于内联函数, 一般建议函数规模较小,不是递归且不是频繁调用。 否则编译器可能不会将内联函数展开, 而是直接调用内联函数。
空指针nullptr
空指针nullptr是为了弥补NULL的错误。
NULL可能标识空地址。 但是也有可能标识0.但是nullptr只有一种含义:无类型的地址0。
注:nullptr是c++11引入的关键字。 不需要包含头文件。
版权声明:本文为博主作者:打鱼又晒网原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/strive_mianyang/article/details/136518440