简介
官网

单目深度估计的扩散模型和相关的微调协议。核心原理是利用现代生成图像模型中存储的丰富视觉知识。模型源自于稳定扩散和微调合成数据,可以零样本转移到未见过的数据集,提供最先进的单目深度估计结果。
实现流程
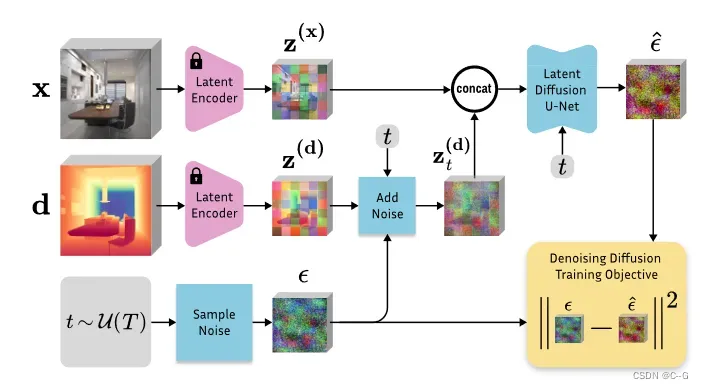
Marigold微调过程。从预训练的稳定扩散开始,使用原始的稳定扩散VAE将图像 x 和深度 d 编码到潜在空间中。通过优化相对于深度潜在代码的标准扩散目标来微调 U-Net。图像调节是通过在将两个潜在代码输入U-Net之前连接它们来实现的。U-Net的第一层被修改为接受连接的潜在码。
Network Architecture
扩散模型的训练通常非常耗费资源。因此,为了提升训练效率,模型基于预训练的文本到图像LDM (Stable Diffusion v2),该LDM从LAION-5B学习了非常好的图像先验。通过对模型组件的最小更改,将其转换为图像条件深度估计器。
depth enconder and decoder
使用冻结的VAE将图像及其相应的深度图编码到一个潜在空间中,用于训练条件去噪器。考虑到为3通道(RGB)输入设计的编码器接收单通道深度图,将深度图复制到三个通道以模拟RGB图像。
此时,深度数据的数据范围在实现仿射不变性方面起着重要作用。
在不改变VAE和潜空间结构的情况下,可以从编码的潜码重构深度图,误差可以忽略不计,即 。在推断时,在扩散结束时对深度潜码进行一次解码,取三个信道的平均值作为预测深度图。
Adapted denoising U-Net
为了实现对输入图像 x 的潜在去噪器 的调节,沿着特征维度将图像和深度潜在代码连接成单个输入
。然后将潜在去噪器的输入通道加倍以适应扩展的输入
。
为了防止第一层的激活量膨胀并保持预训练结构尽可能忠实,复制输入层的权重张量并将其值除以2。
Fine-Tuning Protocol
Affine-invariant depth normalization.
对于真值深度图d,实现了线性归一化,使深度主要落在[−1,1]的值范围内,以匹配VAE的设计输入值范围。这种规范化有两个目的。
- 它是使用原始的稳定扩散VAE的惯例。
- 它强制一个独立于数据统计的标准仿射不变深度表示-任何场景必须由具有极端深度值的近和远平面包围。归一化是通过仿射变换实现的
其中 和
对应于单个深度图的 2% 和 98% 百分位数。这种归一化允许Marigold专注于纯仿射不变深度估计。
Training on synthetic data.
由于捕获设备的物理限制和传感器的物理特性,真实深度数据集存在深度值缺失的问题。具体来说,相机和反射表面之间的差异会导致激光雷达激光束偏离,这是真实噪声和缺失像素不可避免的来源。
这里只使用合成深度数据集进行训练。与深度归一化的理由一样,这一决定有两个客观原因。
- 合成深度本质上是密集和完整的,这意味着每个像素都有一个有效的真值深度值,允许将这样的数据输入VAE,它不能处理无效像素的数据。
- 合成深度是最干净的深度形式,由渲染管道保证。如果我们关于从文本到图像LDM微调可推广深度估计的可能性的假设是正确的,那么合成深度给出了最干净的示例集,并在短微调协议期间减少了梯度更新中的噪声。
因此,剩下的问题是合成数据和真实数据之间的足够多样性或领域差距,这有时会限制泛化能力。正如实验所证明的那样,选择的合成数据集导致了令人印象深刻的零样本转移。
Annealed multi-resolution noise.
先前的研究已经探索了原始DDPM公式的偏差,如非高斯噪声或非马尔可夫时间表捷径。
建议的设置和上面概述的微调协议允许在微调阶段对噪音时间表进行更改。
确定了多分辨率噪声和退火时间表的组合,以更快地收敛并大大提高标准DDPM配方的性能。
多分辨率噪声是由多个不同尺度的随机高斯噪声图像叠加而成,这些图像都被上采样到U-Net输入分辨率。
所提出的退火调度在 的多分辨率噪声和 t = 0 的标准高斯噪声之间进行插值。
Inference
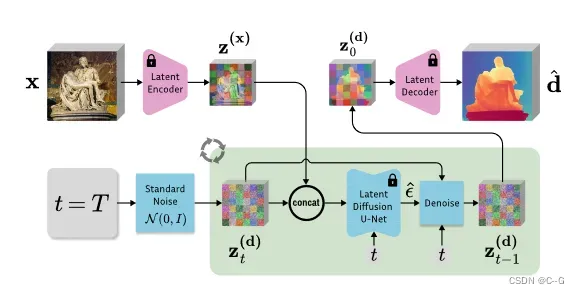
Latent diffusion denoising.
将输入图像编码到隐空间中,将深度隐初始化为标准高斯噪声,并以与微调时相同的调度逐步去噪。
经验发现,使用标准高斯噪声初始化比使用多分辨率噪声初始化效果更好,尽管模型是在后者上训练的。
遵循DDIM的方法,用重新间隔的步骤执行非马尔可夫抽样,以加速推理。最后的深度图是使用VAE解码器从潜码解码,并通过平均信道进行后处理。
Test-time ensembling
推理管道的随机性质导致根据 b中的初始化噪声产生不同的预测。利用这一点,提出了以下测试时间集成方案,能够在相同的输入上组合多个推理传递。
对于每个输入样本,可以运行 N 次推理。
为了汇总这些仿射不变深度预测 ,联合估计相应的尺度
和 移位
,相对于一些标准尺度和范围,以迭代的方式。所提出的目标最小化每对缩放和移位预测
之间的距离,其中
。在每个优化步骤中,通过采用逐像素的中位数 m(x, y) =中位数
来计算合并深度图 m。增加一个额外的正则化项
,以防止坍缩到平凡解,并加强 m 的单位尺度。因此,目标函数可以写为:
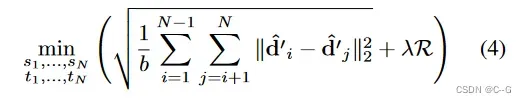
其中二项式系数 表示 N 张图像中图像对可能组合的个数。经过空间对准迭代优化后,将合并深度 m 作为集合预测。
注意,这个集成步骤不需要基本事实来校准独立的预测。该方案通过选择相应的 N,实现了计算效率和预测质量之间的灵活权衡。
Implementation
使用PyTorch实现Marigold,并利用Stable Diffusion v2作为主干,遵循原始的v-objective预训练设置。
禁用文本条件反射,在训练过程中,使用具有1000个扩散步长的DDPM噪声调度器。
在推理时,使用DDIM调度器,只采样50步。对于最终的预测,汇总了具有不同启动噪声的10个推理运行的结果。
训练需要使用批大小为32的18K次迭代。为了适应一个GPU,累积了16步的梯度。使用学习率为 的Adam优化器。此外,对训练数据应用随机水平翻转增强。在单个Nvidia RTX 4090 GPU卡上训练收敛大约需要 2.5 天。

版权声明:本文为博主作者:C–G原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_50973728/article/details/134933916