引言
上篇博客讲到了堆是什么,以及堆的基本创建和实现,这次我们再来对堆这个数据结构更进一步的深入,将讲到的内容包括:向下调整建堆,建堆的复杂度计算,堆排序和topk问题。话不多说,开启我们今天的内容吧。
堆排序
在讲堆排序之前,我想讲讲建堆的问题。在上篇博客中,我们建堆的时候是存在一个数组(数组中存储着我们建堆所需要的元素),通过一个个取出数组中的元素并插入新的堆中达到建堆目的。这时我们可以想,如果需要直接在存储元素的数组上建堆,应该怎么处理呢?
向上调整建堆
如果你学会了向上调整,你应该不难想到可以这样写:
//这里是在原数组的基础上建立大堆
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
void AdjustUp(int* a, int child)
{
int parent = (child - 1) / 2;
while (child > 0) {
if (a[parent] < a[child]) {
Swap(&a[parent], &a[child]);
child = parent;
parent = (child - 1) / 2;
}
else break;
}
}
int main()
{
int arr[] = { 6,5,4,3,2,1,8,7,5,4,2 };
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
AdjustUp(arr, i);
}
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
printf("%d ", arr[i]);
}
return 0;
}上面的代码即对堆中每一个元素经行向上调整,最后我们就能成功的得到一个大堆

向下调整建堆
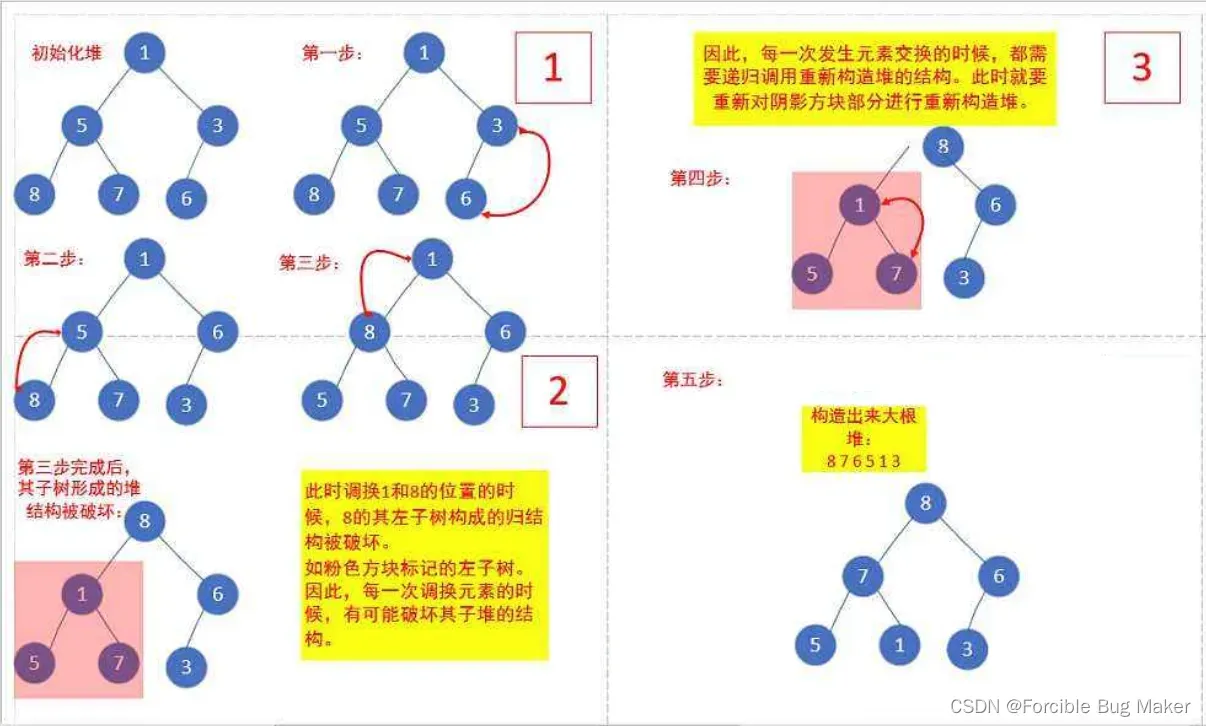
其实有一种比向上调整建堆时间复杂度更优的方式,那就是向下调整建堆,这里要注意的一点就是,向下调整的使用条件:根节点的左右子树都得是堆。数组中的元素开始是无序的,想要向下调整建堆,就需要从下往上建。由于二叉树最后一层不需要向下调整,所以我们可以直接从倒数第二层开始向下调。倒数第二层的末尾元素就是(size – 1 – 1)/ 2
代码实现向下调整建堆就是这样:
//这里是在原数组的基础上建立大堆
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n) {
if (child + 1 < n && a[child + 1] > a[child])child++;
if (a[child] > a[parent]) {
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else break;
}
}
int main()
{
int arr[] = { 6,5,4,3,2,1,8,7,5,4,2 };
int size = sizeof(arr) / sizeof(arr[0]);
for (int i = (size-1-1)/2; i >= 0; i--) {
AdjustDown(arr, size, i);
}
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
printf("%d ", arr[i]);
}
return 0;
}打印结果和向上调整建堆相同

图解分析此过程:
时间复杂度分析
为什么说向下调整建堆的复杂度更低呢?这确实可以用正规的方式来推一下,证明这不是凭空想象出来的结论。
堆是完全二叉树,满二叉树也是完全二叉树,此处为了简化用直接满二叉树来计算建堆的复杂度(这里实际上多几个结点并不影响,时间复杂度实际计算中计算的也只是一个近似值)
1.向上调整时间复杂度计算
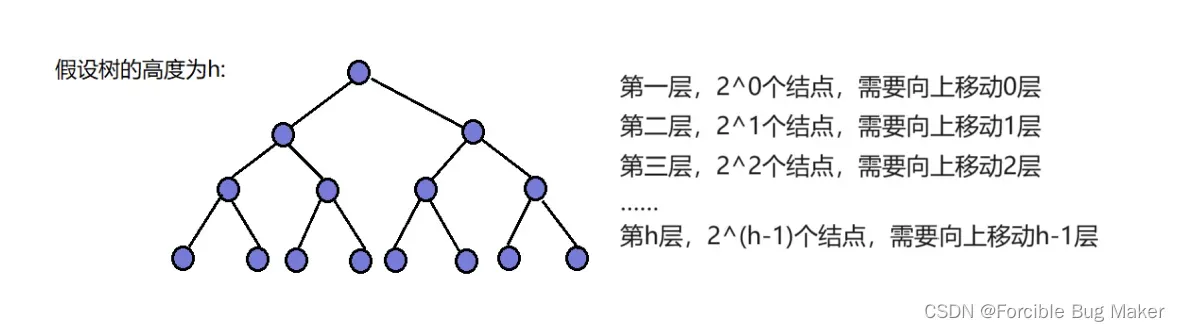 需要移动结点的总步数为:
需要移动结点的总步数为:
F(h) = 2^0 * 0 + 2^1 * 1 + 2^2 * 2 +……+ 2^(h-1) * (h – 1)
会发现这是一个等差乘等比的差比数列前n项之和,大家高中应该学过错位相减吧,这里我们用错位相减求和就可以。
1式: 2 * F(h) = 2^1 * 0 + 2^2 * 1 + 2^3 * 2 +……+ 2^h * (h – 1)
2式:F(h) = 2^0 * 0 + 2^1 * 1 + 2^2 * 2 +……+ 2^(h-1) * (h – 1)
1式 – 2式:
F(h) = -2^1 – 2^2 – 2^3 -……-2^(h-1) + 2^h * (h – 1)
上式的加粗部分是一个等比数列,运用等比数列求和公式即可得:
F(h) = 2^h * (h – 2) + 2
而我们又可以导出节点数N和树的深度h之间的关系
N = 2^h-1 —> h = log(N+1)
带入F(h)中可得
F(N) = (N+1)*[ log(N+1)-2 ] + 2
时间复杂度即为:O(N*logN)
2.向下调整时间复杂度的计算
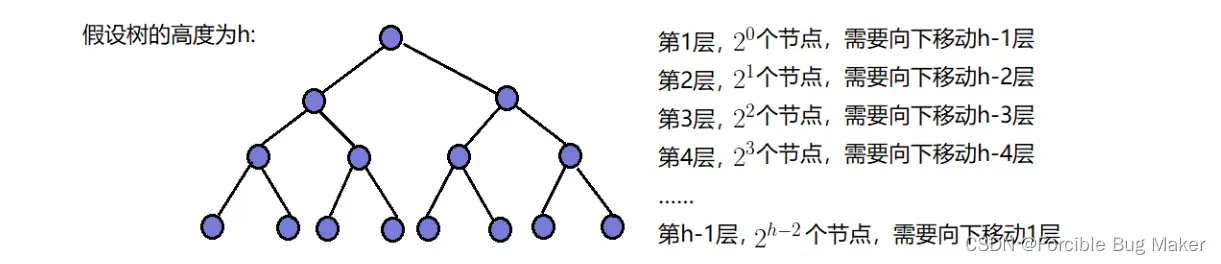
则需要移动的步数为:
F(h) = 2^0 * (h-1) + 2^1 * (h-2) + …… + 2^(h-3) * 2 + 2^(h-2) * 1
这里也是一个差比数列,列两个式子:
1式:F(h) = 2^0 * (h-1) + 2^1 * (h-2) + …… + 2^(h-3) * 2 + 2^(h-2) * 1
2式:2 * F(h) = 2^1 * (h-1) + 2^2 * (h-2) + …… + 2^(h-2) * 2 + 2^(h-1) * 1
1式 – 2式:
F(h) = 1 – h + 2^1 + 2^2 + 2^3 + 2^4 +……+ 2^(h-2) + 2^(h-1)
等比数列公式一套一化简:
F(h) = 2^h – 1 – h
我们已知N和h之间的关系:N = 2^h-1 —> h = log(N+1)
最终可得:
F(N) = N -log(N+1)
时间复杂度即为:O(N)
算到这里,就可以非常轻松的比较出两个方式建堆复杂度的优劣了(向下调整建堆更优)。
堆排序的实现
先放上堆排序代码,再来进行讲解
//堆排序
//交换两个变量
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
//向下调整
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n) {
if (child + 1 < n && a[child + 1] > a[child])child++;
if (a[child] > a[parent]) {
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else break;
}
}
//堆排序
void HeapSort(int* a, int n)
{
//向下调整建堆
for (int i = (n - 1 - 1) / 2; i >= 0; i--) {
AdjustDown(a, n, i);
}
//每次选出一个最大值
int end = n - 1;
while (end > 0) {
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
--end;
}
}
//使用堆排序
int main()
{
int arr[] = { 6,5,4,3,2,1,8,7,5,4,2 };
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
printf("%d ", arr[i]);
}
printf("\n");
HeapSort(arr, sizeof(arr) / sizeof(arr[0]));
for (int i = 0; i < sizeof(arr) / sizeof(arr[0]); i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}可以运行一下看看结果:
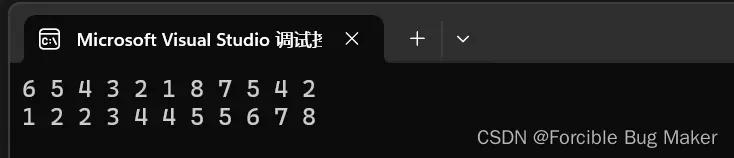
你可能会问,代码中建立的是大堆,是怎么排出了由小到大的效果呢?其实这个过程和堆的删除过程是及其相似的
- 堆顶存储的是整个堆中最大的元素,当与堆末尾的元素交换之后,最大的元素就成功放到数组的末尾
- 通过向下调整之后,堆顶存放的便是堆中第二大的元素
- 每次交换堆底都减1(排好的元素不再参与向下调整的过程),这时堆底(新的堆底)和堆顶再次交换,回到步骤1
堆排序的过程其实就是这样(图解):
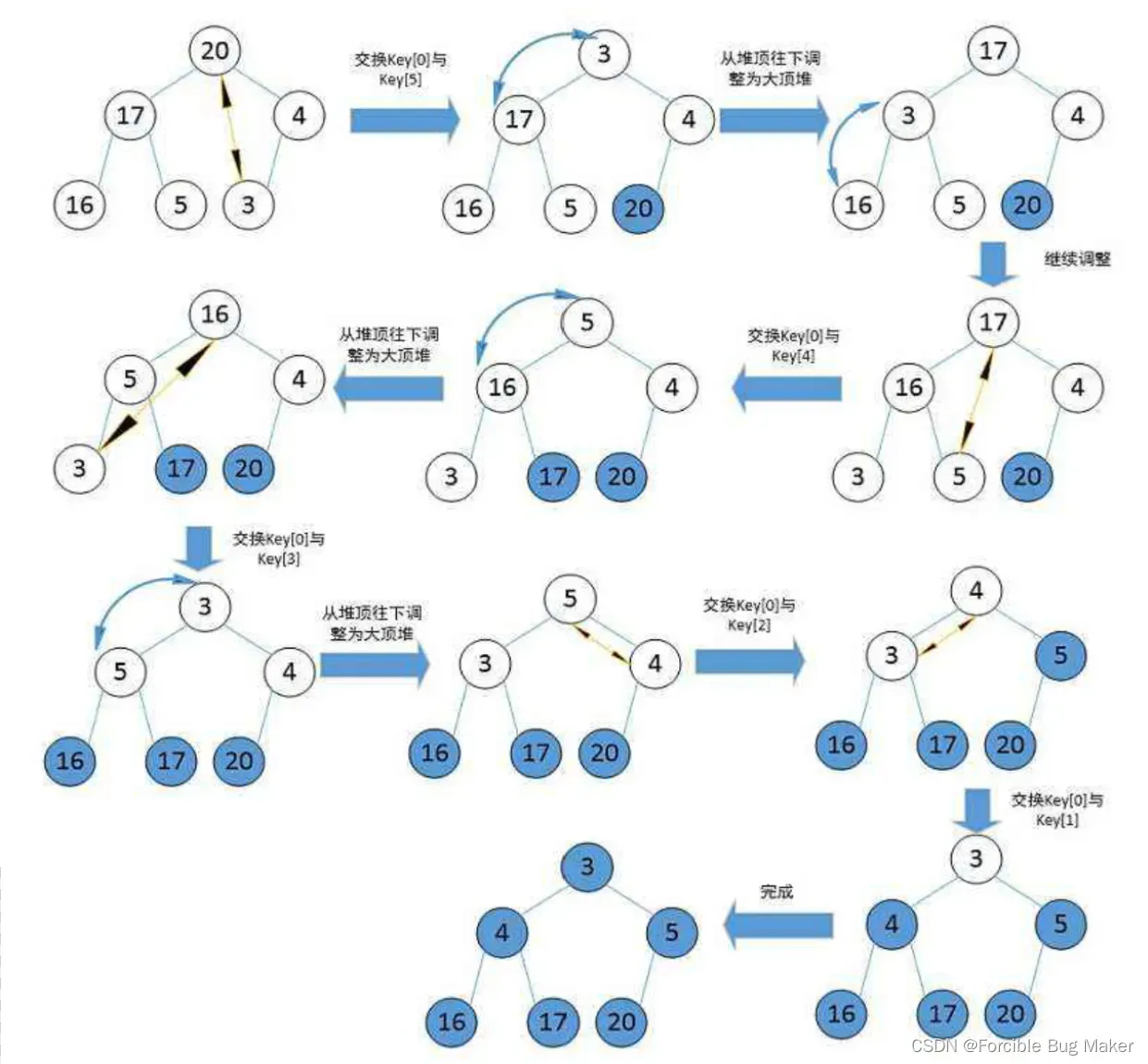
这里再次总结,堆排序即利用堆的思想来进行排序,总共分为两个步骤:
1. 建堆
* 升序:建大堆
* 降序:建小堆
2. 利用删除思想来进行排序
TOP-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:几十个,几百个,几千个甚至上亿个数字中找到最大的前K个数字。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(你甚至无法将数据放入数组)。最佳的方式就是用堆来解决,基本思路如下:
1. 用数据集合中前k个来建堆
* 要找最大的前k个元素,建小堆
* 要找最小的前k个元素,建大堆
2. 用剩余的N – K个元素依次与栈顶元素来比较,不满足则替换堆顶元素向下调整
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素(本topk示例代码中计算的是最大的前K个)。
在这里我们可以用文件操作的方式来试一试,我们先来写一个造数据的函数。
void CreateNDate()
{
// 造数据
int n = 10000;
srand(time(0));
const char* file = "data.txt";
FILE* fin = fopen(file, "w");
if (fin == NULL)
{
perror("fopen error");
return;
}
for (size_t i = 0; i < n; ++i)
{
int x = rand() % 1000000;
fprintf(fin, "%d\n", x);
}
fclose(fin);
}这里将造出来的数据写入到 data.txt 文件中,运行完此函数后,当前目录下会多一个data.txt文件

打开此文本文件:
通过此函数,我们已经成功造出了10000个数据了
接下来就是topk代码的实现:
#include<time.h>
#include<stdio.h>
#include<stdlib.h>
//交换函数
void Swap(int* x, int* y)
{
int tmp = *x;
*x = *y;
*y = tmp;
}
//向下调整
void AdjustDown(int* a, int n, int parent)
{
int child = parent * 2 + 1;
while (child < n) {
if (child + 1 < n && a[child + 1] < a[child])child++;
if (a[child] < a[parent]) {
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else break;
}
}
//topk代码
void PrintTopK(int k) //这里的k是选出最大的前k个数
{
//打开需要查找前K大数据的文件---data.txt
FILE* file = fopen("data.txt", "r");
if (file == NULL) {
perror("fopen fail:");
exit(1);
}
//创建存放堆数据的空间
int* arr = (int*)malloc(sizeof(int) * (k + 1));
if (arr == NULL) {
perror("malloc fail:");
exit(1);
}
//输入文件中前k个数据
for (int i = 0; i < k; i++) {
fscanf(file, "%d", &arr[i]);
}
//将放入的前k个数字调整建堆
for (int i = (k - 1 - 1) / 2; i >= 0; i--) {
AdjustDown(arr, k, i);
}
//这里是topk的重点,遍历K - N的数字,将符合的数字插入堆中
for (int i = k; i < 10000; i++) {
int tmp = 0;
fscanf(file, "%d", &tmp);
//如果tmp比堆顶的数据大,则放入堆顶向下调整
if (tmp > arr[0]) {
arr[0] = tmp;
AdjustDown(arr, k, 0);
}
}
//打印前K个最大的数字
for (int i = 0; i < k; i++) {
printf("%d ", arr[i]);
}
}
int main()
{
//输入选前多少大数字
int digit = 10;
scanf("%d", &digit);
PrintTopK(digit);
return 0;
}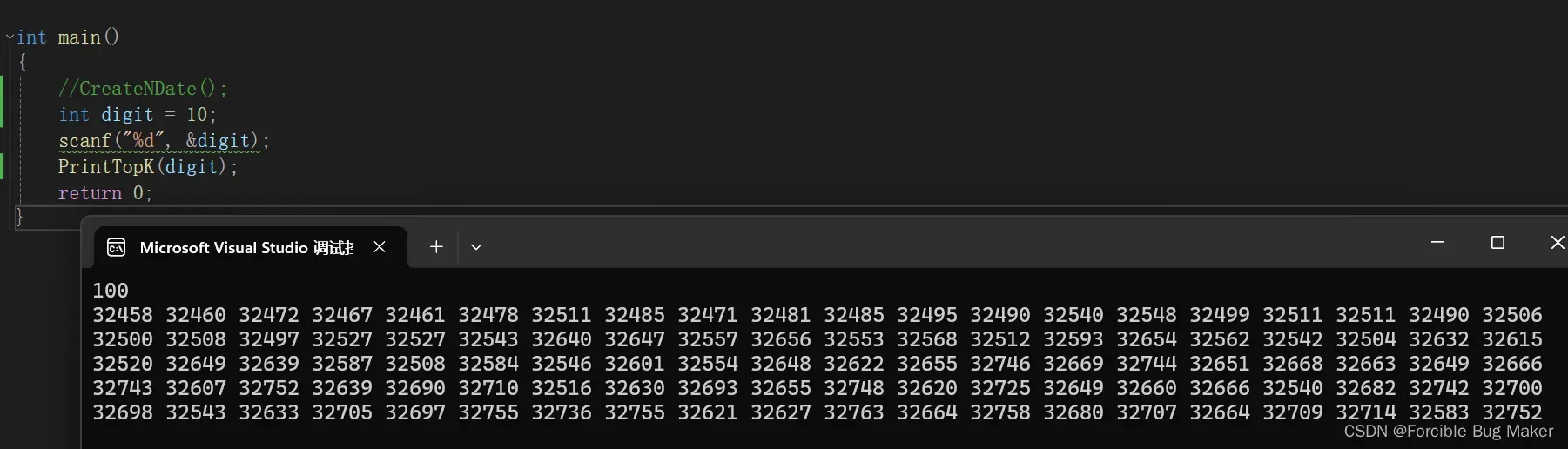
这里,程序成功选出了文件中前100大的数字,如果觉得这样不够严谨,你也可以添加几个位数较高的数据到文件中,看看你的程序能否选出你写入文件的几个特殊的大数字即可。相信在这些测试过后你可以成功感受到topk算法的魅力。
结语
到这里,基本上就是二叉树顺序结构堆的全部内容了,本篇博客带大家学习了解了堆排序,计算了向上调整建堆向下调整建堆的时间复杂度,最后还说到了topk算法。这些内容其实并不难,只要肯下功夫,肯动手,一定能学下来。后面博主还会带大家了解关于二叉树链式结构的内容,欢迎大家多多关注和支持我,比心-♥
版权声明:本文为博主作者:Forcible Bug Maker原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/2303_79329831/article/details/136645527