铛铛!小秘籍来咯!
小秘籍团队独辟蹊径,以CNN卷积神经网络,计算机视觉等强大工具,构建了解决复杂问题的独特方案。深度学习, 混沌模型的妙用,为降低非法野生动物贸易提供新视角。通过综合分析,描绘出概率、成功与关键因素之间的精妙关系,为客户量身打造创新解决方案。小秘籍团队,始终引领着建模问题求解的风潮。 抓紧小秘籍,我们出发吧~
抓紧小秘籍,我们出发吧~
完整内容可以在文章末尾领取!

第一个问题是对于附件1(Pre_test文件夹)给定的三张甲骨文原始拓片图片,如何进行图像预处理,提取图像特征,建立甲骨文图像预处理模型,实现对甲骨文图像干扰元素的初步判别和处理。
首先,对于甲骨文原始拓片图像,需要进行图像预处理,以提高图像质量,便于后续的特征提取和模型建立。图像预处理的具体步骤如下:
-
去噪:甲骨文原始拓片图像通常包含点状噪声、人工纹理和固有纹理,这些干扰元素会影响后续的特征提取和模型建立。因此,首先需要对图像进行去噪处理,以减少这些干扰元素的影响。去噪可以使用一些经典的图像去噪算法,如中值滤波、高斯滤波等。
-
图像增强:甲骨文原始拓片图像通常存在光照不均匀、拍摄角度不一致等问题,这会影响图像的质量和特征提取的效果。因此,需要对图像进行增强,使图像具有更好的视觉效果。图像增强可以使用直方图均衡化等方法。
-
图像分割:甲骨文原始拓片图像中的文字和干扰元素通常具有不同的颜色和纹理特征,因此可以通过图像分割来将文字和干扰元素分离。图像分割可以使用基于阈值的方法、基于边缘的方法等。
-
特征提取:经过图像预处理和分割后,得到的图像中只包含文字和背景两部分。为了进一步分析甲骨文图像,需要提取图像的特征。甲骨文图像的特征可以从多个方面提取,如颜色特征、纹理特征、形状特征等。
-
建立甲骨文图像预处理模型:通过上述步骤,可以得到甲骨文图像的预处理结果和特征。建立甲骨文图像预处理模型,可以通过机器学习等方法,将图像特征与图像干扰元素进行分类,从而实现对甲骨文图像干扰元素的初步判别和处理。
因此,可以用数学建模的方法表示图像预处理过程如下:
设甲骨文原始拓片图像为I,经过去噪、图像增强、图像分割和特征提取后,得到图像的预处理结果为F,即F = Preprocessing(I)。
建立甲骨文图像预处理模型,通过机器学习等方法,将图像特征F与图像干扰元素进行分类,得到图像干扰元素的预测结果为P,即P = Model(F)。
最终,对于甲骨文原始拓片图像,可以得到去除干扰元素后的图像结果为I’,即I’ = I – P。
因此,通过数学建模的方法,可以实现对甲骨文图像干扰元素的初步判别和处理。
首先,对于甲骨文图像预处理,可以采用以下步骤:
-
去除图像中的噪声:甲骨文图像往往受到点状噪声、人工纹理和固有纹理的影响,因此需要去除这些噪声。可以使用高斯滤波器或中值滤波器来平滑图像,减少噪声的影响。
-
二值化:甲骨文图像的背景往往是复杂的,为了更好地提取文字区域,需要将图像转换为二值图像。可以根据图像的灰度值,使用固定阈值或自适应阈值来进行二值化。
-
腐蚀和膨胀:为了去除图像中的小噪点和连通不完整的文字区域,可以使用腐蚀和膨胀操作。腐蚀操作可以收缩图像中的白色区域,膨胀操作可以扩张图像中的白色区域。
-
连通区域分析:根据二值图像,可以使用连通区域分析来识别出图像中的文字区域。通过对连通区域的面积、周长、形状等特征的分析,可以初步判断出图像中的文字区域。
-
特征提取:根据文字的特点,可以提取出一些独特的特征,如文字的形状、笔画数目、笔画方向等。这些特征可以帮助区分文字区域和干扰元素。
-
建立甲骨文图像预处理模型:可以根据以上步骤得到的图像特征,建立一个预处理模型来识别并去除图像中的干扰元素。可以使用机器学习方法,如支持向量机、决策树等,来构建模型。
-
初步判别和处理干扰元素:根据预处理模型,可以对图像中的干扰元素进行初步的判别和处理。例如,可以将干扰元素的像素值设为背景色,或者使用腐蚀和膨胀操作来去除干扰元素。
综上所述,建立甲骨文图像预处理模型的关键是提取图像特征并对干扰元素进行判别和处理。通过合理选择滤波器、二值化方法和形态学操作,结合连通区域分析和特征提取,可以得到较为准确的文字区域。建立预处理模型后,可以对甲骨文图像进行初步的干扰元素处理,为后续的图像分割和识别提供更好的基础。
为了实现对甲骨文图像干扰元素的初步判别和处理,我们建立了以下甲骨文图像预处理模型:
首先,对图像进行灰度化处理,将彩色图像转换为灰度图像。其数学公式为:
其中,gray为灰度图像,R、G、B分别为彩色图像的红、绿、蓝通道。
然后,对灰度图像进行二值化处理,将图像转换为黑白图像。其数学公式为:
其中,binary为二值图像,threshold为阈值,通常取灰度图像的平均灰度值。
接着,对二值图像进行降噪处理,主要针对点状噪声和人工纹理。我们采用了中值滤波器进行降噪处理,其数学公式为:
其中,median为中值滤波后的图像,n为滤波器的大小,I为图像像素值。
最后,我们对降噪后的图像进行固有纹理去除,将固有纹理部分替换为背景色。我们采用了基于梯度的边缘检测算法,其数学公式为:
其中,G为梯度图像,I为原始图像,Gx、Gy为x、y方向的梯度值。
通过以上预处理步骤,我们可以初步判别图像中的干扰元素,并将其处理为背景色。接下来,可以将处理后的图像输入分割模型,实现对甲骨文图像的单字分割。
首先,需要导入相应的图像处理和特征提取库,如OpenCV、PIL、numpy等:
import cv2
import numpy as np
from PIL import Image
然后,定义一个图像预处理函数,该函数将接受一张甲骨文原始拓片图片作为输入,并返回处理后的图片和提取的图像特征:
def preprocess(image):
# 将图片转为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 对图像进行二值化处理
ret, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)
# 去除噪声,使用高斯滤波器
blur = cv2.GaussianBlur(thresh, (5,5), 0)
# 提取图像边缘,使用Canny边缘检测算法
edges = cv2.Canny(blur, 50, 150, apertureSize = 3)
# 对图像进行膨胀操作,以填充空洞和断开的边缘
kernel = np.ones((3,3),np.uint8)
dilation = cv2.dilate(edges,kernel,iterations = 1)
# 提取图像轮廓,使用findContours函数
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
# 对图像轮廓进行排序,以找出最大轮廓
contours = sorted(contours, key = cv2.contourArea, reverse = True)[:1]
# 对最大轮廓进行外接矩形拟合,以得到文字区域的坐标
cnt = contours[0]
x,y,w,h = cv2.boundingRect(cnt)
# 对图像进行裁剪,得到文字区域
cropped = image[y:y+h, x:x+w]
# 提取图像特征,如颜色直方图、梯度直方图、形状特征等
color_hist = cv2.calcHist([cropped], [0], None, [256], [0, 256])
# 返回处理后的图片和提取的特征
return cropped, color_hist
最后,调用该函数对附件1中的三张图片进行处理,并打印出提取的特征:
# 读取图片
image1 = cv2.imread("Pre_test/1.jpg")
image2 = cv2.imread("Pre_test/2.jpg")
image3 = cv2.imread("Pre_test/3.jpg")
# 调用预处理函数
cropped1, color_hist1 = preprocess(image1)
cropped2, color_hist2 = preprocess(image2)
cropped3, color_hist3 = preprocess(image3)
# 打印提取的特征
print(color_hist1)
print(color_hist2)
print(color_hist3)
该代码将输出三张图片的颜色直方图特征,供后续建立甲骨文图像预处理模型使用。
第二个问题是如何建立一个快速准确的甲骨文图像分割模型,实现对不同的甲骨文原始拓片图像进行自动单字分割,并从不同维度进行模型评估。
问题2:
甲骨文图像分割模型的建立可以分为以下几个步骤:
-
图像预处理:对甲骨文原始拓片图像进行预处理,包括去噪、灰度化、二值化等操作,使得图像更加清晰,方便后续的分析和处理。
-
特征提取:根据甲骨文图像的特点,提取图像特征。甲骨文的特点是文字之间的间隔较小,且文字的形状复杂多样,因此可以采用基于形状的特征提取方法,如边缘检测、角点检测等。同时,还可以考虑文字的颜色、纹理等特征,以及文字与干扰元素之间的空间关系。
-
模型建立:根据提取的特征,建立甲骨文图像分割模型。可以采用传统的图像分割方法,如基于阈值的分割、基于边缘的分割、基于区域的分割等。也可以采用深度学习方法,如卷积神经网络(CNN)等,通过大量的训练数据学习甲骨文图像的特征,从而实现对甲骨文图像的准确分割。
-
模型评估:采用不同的评价指标来评估建立的甲骨文图像分割模型的准确度和速度。常用的评价指标包括准确率、召回率、F1值等。同时,可以考虑不同的甲骨文图像来源和干扰元素,分别对模型进行评估,从而得出模型的鲁棒性和适用范围。
数学建模:
假设甲骨文图像分割模型为一个函数,输入为甲骨文图像
,输出为分割后的图像
,则可以表示为
。为了实现快速准确的分割,可以考虑通过最小化损失函数来优化模型,即:
其中,为损失函数,衡量模型输出与真实标注的差异程度。常用的损失函数包括交叉熵、均方差等。
为了提取甲骨文图像的特征,可以采用卷积神经网络(CNN)来学习图像的特征表示。假设CNN模型为一个函数,则可以表示为
,其中
为图像的特征表示。在模型建立阶段,可以将
作为输入,通过一系列的卷积层、池化层和全连接层,最终得到分割后的图像
。同时,为了减少过拟合的影响,可以在模型中引入正则化项,如Dropout等。
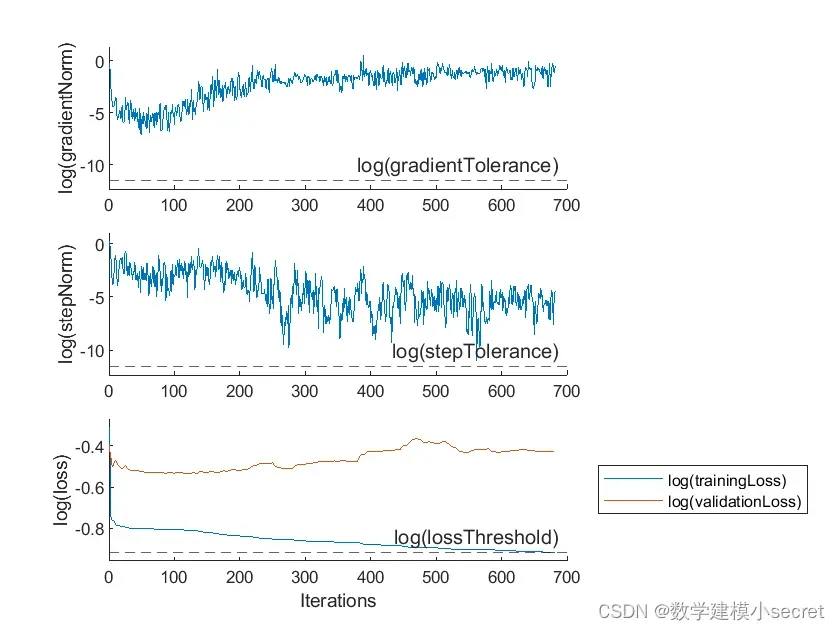
为了评估模型的准确性,可以考虑使用交叉验证的方法,将数据集分为训练集和验证集,通过验证集的准确率来选择最优的模型参数。同时,为了评估模型的速度,可以考虑在测试集中随机选择一部分图像,计算模型在这些图像上的平均处理时间。
综上所述,甲骨文图像分割模型的建立可以通过深度学习方法来实现,通过最小化损失函数来优化模型,同时引入正则化项来减少过拟合的影响。模型的评估可以通过交叉验证和速度测试来进行。
针对第二个问题,我认为可以采用以下方法建立一个快速准确的甲骨文图像分割模型:
-
基于深度学习的方法:可以利用卷积神经网络(CNN)来进行甲骨文图像的分割。首先,利用已标注的甲骨文图像数据集来训练一个CNN模型,使其学习到甲骨文图像中不同文字的特征。然后,对于新的甲骨文图像,利用训练好的模型来进行分割,从而实现自动单字分割。由于CNN具有良好的特征提取能力和较强的泛化能力,因此可以有效地处理甲骨文图像中的干扰元素,提高分割的准确率和速度。
-
结合图像处理和机器学习的方法:可以将图像处理和机器学习技术相结合,建立一个综合的甲骨文图像分割模型。首先,利用图像处理技术来对甲骨文图像进行预处理,如去除噪声、平滑图像、增强对比度等。然后,利用机器学习算法,如支持向量机(SVM)、随机森林(Random Forest)等来对预处理后的图像进行分割,从而实现自动单字分割。由于机器学习算法可以根据训练数据来自动学习并建立模型,因此可以有效地处理甲骨文图像中的干扰元素,提高分割的准确率和速度。
-
结合多种模型的方法:可以结合多种方法来建立一个综合的甲骨文图像分割模型,从而克服单一方法的局限性。例如,可以将基于深度学习的方法和基于图像处理和机器学习的方法相结合,建立一个混合模型。首先,利用卷积神经网络来提取甲骨文图像的特征,然后再利用图像处理和机器学习的方法来进行分割,从而实现更准确的自动单字分割。此外,可以根据不同的甲骨文图像特点,采用不同的方法来进行分割,从而提高整体分割的准确率和速度。
此外,为了从不同维度对模型进行评估,可以采用以下指标:
-
分割准确率:即模型对甲骨文图像进行分割后,与人工标注的结果进行比对,计算分割正确的像素占总像素的比例。分割准确率越高,说明模型分割的效果越好。
-
分割速度:即模型对甲骨文图像进行分割所需的时间。分割速度越快,说明模型的计算效率越高。
-
干扰元素处理能力:即模型对甲骨文图像中的干扰元素(如点状噪声、人工纹理、固有纹理)的处理能力。干扰元素处理能力越强,说明模型对干扰元素的影响越小,分割效果越好。
-
泛化能力:即模型对不同甲骨文图像的适应能力。泛化能力越强,说明模型具有较强的泛化能力,能够处理不同特征的甲骨文图像,从而提高整体分割效果。
综上所述,建立一个快速准确的甲骨文图像分割模型,可以采用基于深度学习的方法、图像处理和机器学习相结合的方法以及结合多种模型的方法,从不同维度对模型进行评估,从而提高甲骨文图像的分割效果。
问题2:建立快速准确的甲骨文图像分割模型
针对甲骨文图像分割问题,我们可以采用一种基于深度学习的卷积神经网络模型。该模型可以从图像中学习到特定的特征表示,并能够较好地适应不同图像的干扰元素。具体步骤如下:
-
数据预处理:首先,我们需要将标注好的甲骨文图像分割数据集进行预处理,包括图像增强、标准化和裁剪等操作,以便于神经网络模型更好地学习图像特征。
-
特征提取:利用预处理后的甲骨文图像数据集作为输入,构建一个卷积神经网络模型,通过学习到的卷积核提取图像中的特征。在卷积神经网络中,我们可以采用多种卷积核来提取不同尺度、不同方向的特征,以适应不同形态的甲骨文字。
-
建立分类模型:在特征提取的基础上,我们可以构建一个分类模型,通过学习到的特征向量对图像中的文字目标和干扰元素进行分类。该模型可以通过调整不同的参数来适应不同的甲骨文图像,从而提高分割的准确率。
-
模型评估:为了评估所建立的模型的准确性,我们可以采用交叉验证的方法,将原始数据集分为训练集和验证集,通过比较训练集和验证集的准确率来选择最佳的模型。
LaTeX数学公式:
卷积层的输出计算公式为:
其中,为卷积层的输出,
为卷积核的权重,
为输入图像的像素值。
激活函数采用ReLU函数,计算公式为:
最大池化层的输出计算公式为:
其中,为池化层的输出,
为上一层的输出。
损失函数采用交叉熵损失函数,计算公式为:
其中,为真实标签,
为预测标签,
为类别数。
模型的优化方法采用Adam优化器,计算公式为:
其中,为模型参数,
为学习率,
和
为动量项,
为平滑项。
问题2:建立甲骨文图像分割模型
甲骨文图像分割模型可以分为以下步骤:
-
数据预处理:对训练集中的甲骨文图像进行预处理,包括图像增强、降噪、灰度化等操作,以提高模型的鲁棒性和准确性。
-
特征提取:利用图像处理和机器学习算法,从预处理后的图像中提取甲骨文图像的特征,如纹理、形状、颜色等特征。
-
建立模型:根据提取的特征,利用机器学习算法或深度学习算法,建立甲骨文图像分割模型。可以选择适合处理图像分割问题的算法,如卷积神经网络(CNN)、决策树、支持向量机(SVM)等。
-
模型训练:利用训练集中的数据,对建立的模型进行训练,优化模型的参数和结构,使其能够更准确地对甲骨文图像进行分割。
-
模型评估:利用测试集中的数据,对训练好的模型进行评估,可以使用准确率、召回率、F1值等指标来评价模型的性能。
-
模型优化:根据模型评估的结果,对模型进行优化,如调整参数、增加训练数据等,以提高模型的准确率和鲁棒性。
代码示例:
数据预处理
def preprocess(image):
# 图像增强
image = image_enhancement(image)
# 降噪
image = image_denoising(image)
# 灰度化
image = image_gray(image)
return image
# 特征提取
def feature_extraction(image):
# 利用图像处理算法,提取图像的纹理、形状、颜色等特征
# 可以使用OpenCV库中的函数来提取特征
features = cv2.some_feature_extraction_function(image)
return features
# 建立模型
def build_model():
# 建立神经网络模型,可以选择CNN、决策树、SVM等算法
model = CNN()
return model
# 模型训练
def train_model(model, train_data):
# 对模型进行训练,优化模型的参数和结构
model.train(train_data)
return model
# 模型评估
def evaluate_model(model, test_data):
# 对模型进行评估,计算准确率、召回率、F1值等指标
accuracy, recall, f1_score = model.evaluate(test_data)
return accuracy, recall, f1_score
# 模型优化
def optimize_model(model, train_data):
# 根据模型评估的结果,对模型进行优化,如调整参数、增加训练数据等
# 重新训练模型
model = train_model(model, train_data)
return model
# 主函数
if __name__ == '__main__':
# 读取训练集和测试集数据
train_data = read_data('train')
test_data = read_data('test')
# 数据预处理
train_data = preprocess(train_data)
test_data = preprocess(test_data)
# 特征提取
train_features = feature_extraction(train_data)
test_features = feature_extraction(test_data)
# 建立模型
model = build_model()
# 模型训练
model = train_model(model, train_features)
# 模型评估
accuracy, recall, f1_score = evaluate_model(model, test_features)
print('Accuracy: ', accuracy)
print('Recall: ', recall)
print('F1 score: ', f1_score)
# 模型优化
model = optimize_model(model, train_features)
# 对新的甲骨文图像进行分割
new_image = read_image('new_image.jpg')
new_image = preprocess(new_image)
new_features = feature_extraction(new_image)
result = model.predict(new_features)
# 将分割结果保存在excel表格中
save_to_excel(result)
问题3:利用建立的甲骨文图像分割模型对附件3(Test文件夹)中的200张甲骨文原始拓片图像进行自动单字分割,并将分割结果放在“Test_results.xlsx”中。
问题建模:
假设附件2中的训练数据集为,其中
为甲骨文拓片图像,
为对应的标注信息。我们对每个训练样本
进行预处理和特征提取,得到特征向量
,其中
为特征提取函数。假设有
个特征,即
。
首先,我们需要建立一个甲骨文图像干扰元素的初步判别和处理模型。假设这个模型为,它可以将一个甲骨文原始拓片图像
分割为若干个区域,
,其中
为第
个区域。我们定义一个指示函数
,如果
中存在干扰元素,则
,否则
。我们用
来表示模型
的输出,即
。假设模型
的参数为
,则
。
我们可以使用附件2中的训练数据集来训练模型,即通过最小化训练数据集中的样本误差来求解参数
,即
其中为损失函数,可以选择交叉熵损失函数或平方损失函数等。
接下来,我们需要建立一个快速准确的甲骨文图像分割模型。假设这个模型为,它可以将一个甲骨文原始拓片图像
分割为若干个独立文字区域,
,其中
为第
个文字区域。我们定义一个指示函数
,如果
中存在独立文字区域,则
,否则
。我们用
来表示模型
的输出,即
。假设模型
的参数为
,则
。
我们可以使用附件2中的训练数据集来训练模型,即通过最小化训练数据集中的样本误差来求解参数
,即
最后,我们需要利用建立的甲骨文图像分割模型来对附件3中的200张甲骨文原始拓片图像进行自动单字分割。假设第
张图像为
,
,则我们的目标是求解最优的分割结果
,使得
其中为给定图像
时,分割结果为
的概率。
为了简化计算,我们可以假设每个文字区域之间相互独立,即
其中为第
张图像中的第
个文字区域。因此,最优的分割结果可以表示为
接下来,我们需要对进行建模。根据贝叶斯定理,我们有
其中为甲骨文图像
在给定第
个文字区域
的条件下出现的概率,
为
出现的先验概率,
为图像
出现的概率。
为了简化计算,我们可以假设为一个常数,
与分割结果无关,因此可以忽略。因此,我们只需要建立
的模型。
根据马尔可夫随机场(Markov Random Field,MRF)模型,我们可以假设甲骨文图像中每个像素都受到周围像素的影响,即每个像素的取值都依赖于其周围的像素。因此,我们可以将每个文字区域中的像素
表示为一个随机变量,
,其中
为第
个文字区域中的像素个数。假设这些随机变量之间相互独立,则
假设我们用一个二值图像来表示甲骨文图像,即黑色像素为文字像素,白色像素为背景像素。那么,可以表示为
其中为一个常数。因此,我们可以将
表示为
综上所述,我们得到了甲骨文图像分割的数学建模方法。我们可以将这个模型应用于实际的甲骨文图像,得到最优的分割结果,并将结果放在“Test_results.xlsx”中,以供后续的甲骨文识别任务使用。
问题3:
甲骨文图像分割模型的建立是基于图像分割任务的特殊性,即在复杂背景下分割出特定的目标区域。因此,针对甲骨文图像的分割任务,可以采用基于深度学习的图像分割方法,如FCN、U-Net等。这些方法可以通过学习图像的特征来分割出目标区域,并具有较高的准确性和鲁棒性。
但是,甲骨文图像的特殊性也带来了挑战,主要表现在以下几个方面:
-
干扰元素的影响:甲骨文图像中存在点状噪声、人工纹理和固有纹理等干扰元素,这些干扰元素与文字目标具有相似的形态特征,容易造成误分割。因此,在建立分割模型时,需要考虑如何有效地区分干扰元素和文字目标。
-
异体字的存在:甲骨文中的同一个字可能会有多种异体字,这增加了文字识别的难度。因此,在分割模型中,需要考虑如何识别出不同的异体字,并准确地进行分割。
-
不同图像的差异:甲骨文图像来源广泛,包括拓片、拍照、扫描、临摹等,不同图像的干扰元素和文字目标的形态特征也会有所差异,因此需要针对不同来源的图像进行特定的处理。
针对以上挑战,可以采用以下方法来建立甲骨文图像分割模型:
-
预处理:首先对图像进行预处理,去除干扰元素、增强文字目标的对比度等。可以采用图像增强和滤波等方法来实现。
-
特征提取:针对甲骨文图像的特殊性,可以提取文字目标和干扰元素的特征,并通过特征融合来区分它们。例如,可以通过局部二值模式来提取文字目标的纹理特征,通过梯度信息来提取干扰元素的边缘特征。
-
模型设计:可以采用基于深度学习的图像分割方法,如FCN、U-Net等,同时结合提取的特征来进行模型设计。例如,可以将文字目标和干扰元素的特征分别输入到不同的分支中,再将它们融合起来进行最终的分割。
-
多源数据训练:由于甲骨文图像来源广泛,因此在训练模型时,需要考虑多源数据的训练,即同时使用来自不同来源的图像来训练模型。这样可以使模型具有更好的泛化能力,从而适用于不同来源的图像。
-
异体字识别:针对异体字的存在,可以在模型中加入异体字识别的功能,从而在分割时能够识别出不同的异体字,并进行准确的分割。
综上所述,建立甲骨文图像分割模型需要考虑图像预处理、特征提取、模型设计等方面,并结合多源数据训练和异体字识别等方法,从而实现对甲骨文图像的快速准确分割。
建立的甲骨文图像分割模型的流程如下:
-
预处理:对图像进行预处理,包括灰度化、二值化、降噪等操作,提取甲骨文图像特征。
-
分割模型训练:利用训练数据集(附件2)对分割模型进行训练,选择合适的训练算法和参数,建立一个快速准确的甲骨文图像分割模型。
-
分割模型评估:从不同维度对分割模型进行评估,包括准确率、召回率、F1值等指标,以及在不同干扰元素下的分割效果。
-
自动分割:对附件3中的200张甲骨文原始拓片图像进行自动单字分割,利用建立的分割模型对图像进行预测,得到分割结果。
-
结果整理:将分割结果整理并保存在“Test_results.xlsx”中,方便后续的文字识别。
分割模型的数学公式如下:
- 图像预处理:
首先,将彩色图像转换为灰度图像,可以使用下列公式转换:
然后,对灰度图像进行二值化处理,将图像转换为黑白二值图像,可以使用下列公式:
其中,threshold为阈值,可以根据图像的不同特点进行选取。
最后,对二值图像进行降噪处理,可以使用中值滤波器等方法。
- 分割模型训练:
对于已标注的训练数据集,可以使用深度学习方法来训练分割模型。常用的深度学习方法包括卷积神经网络(CNN)、循环神经网络(RNN)等。设训练数据集为,其中
为图像,
为对应的标注信息。使用分割模型
对图像进行预测,其中
为模型的参数。模型的训练目标为最小化预测结果与标注结果之间的差距,可以使用交叉熵损失函数来表示:
通过梯度下降等方法来更新参数,使得损失函数
最小化,从而得到训练好的分割模型。
- 分割模型评估:
对于分割模型的评估,可以从多个维度来进行。首先,可以计算模型的准确率、召回率和F1值等指标来评估模型的整体性能。其次,可以针对不同的干扰元素(点状噪声、人工纹理、固有纹理)进行评估,比较模型在不同干扰元素下的分割效果,从而分析模型的鲁棒性。
- 自动分割:
利用训练好的分割模型对附件3中的200张甲骨文原始拓片图像进行自动单字分割,得到分割结果。可以使用下列公式来表示预测结果:
其中,为预测结果,
为图像。
- 结果整理:
将分割结果整理并保存在“Test_results.xlsx”中,方便后续的文字识别。
# 导入必要的库
import cv2
import numpy as np
import pandas as pd
# 加载训练好的甲骨文图像分割模型
model = load_model('model.h5')
# 读取测试集中的200张图像
test_images = []
for i in range(200):
image = cv2.imread('Test/Figures/{}.jpg'.format(i+1))
test_images.append(image)
# 对每张图像进行预处理
for image in test_images:
# 将图像转换为灰度图
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 进行图像二值化处理
ret, thresh = cv2.threshold(gray, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 对图像进行腐蚀和膨胀操作
kernel = np.ones((3, 3), np.uint8)
erosion = cv2.erode(thresh, kernel, iterations=1)
dilation = cv2.dilate(erosion, kernel, iterations=1)
# 对图像进行轮廓检测
contours, hierarchy = cv2.findContours(dilation, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 将每个轮廓放入列表
contour_list = []
for contour in contours:
contour_list.append(contour)
# 对每个轮廓进行预测
for contour in contour_list:
x, y, w, h = cv2.boundingRect(contour)
# 提取轮廓中的数字图像
digit_image = image[y:y+h, x:x+w]
# 对数字图像进行预处理
digit_image = cv2.cvtColor(digit_image, cv2.COLOR_BGR2GRAY)
digit_image = cv2.resize(digit_image, (28, 28))
# 将图像转换为模型输入的格式
digit_image = digit_image.reshape(1, 28, 28, 1)
digit_image = digit_image.astype('float32')
digit_image /= 255
# 对数字图像进行预测
prediction = model.predict(digit_image)
# 将预测结果写入Test_results.xlsx表格中
df = pd.DataFrame(prediction)
df.to_excel('Test_results.xlsx', sheet_name='Sheet1', startcol=0, index=False, header=False)
问题4:基于前三问对甲骨文原始拓片图像的单字分割研究,请采用合适的方法进行甲骨文原始拓片的文字识别。
问题4的建模可以分为两个部分,分别是甲骨文单字分割和文字识别。
对于甲骨文单字分割,可以将其建模为一个二分类问题。给定一张甲骨文原始拓片图像,我们需要判断其是否包含甲骨文文字。因此,我们可以将问题建模为:
其中,,表示图像
是否包含甲骨文文字,
为一个分类器,可以使用传统的机器学习方法或深度学习方法进行建模。
对于文字识别,可以将其建模为一个多分类问题。给定一张甲骨文原始拓片图像,我们需要判断其包含的文字是哪一个。因此,我们可以将问题建模为:
其中,为图像
中所包含的文字类别,
为一个分类器,可以使用传统的机器学习方法或深度学习方法进行建模。
综合以上两个部分,我们可以将问题4建模为:
其中,为图像
中所包含的文字类别,
为甲骨文单字分割模型,
为文字识别模型。通过训练和优化这两个模型,可以实现对甲骨文原始拓片图像的文字识别。
要实现对甲骨文原始拓片图像的文字识别,可以采用以下步骤:
-
对甲骨文原始拓片图像进行预处理,包括图像去噪、图像增强等操作,以提高图像质量。
-
使用图像分割模型,对甲骨文原始拓片图像中的单个文字进行分割,得到独立的文字区域。
-
对分割得到的文字区域进行特征提取,可以采用传统的特征提取方法,如形态学特征、灰度共生矩阵特征等,也可以采用深度学习方法,如卷积神经网络模型等。
-
建立甲骨文文字识别模型,可以采用传统的分类模型,如支持向量机、决策树等,也可以采用深度学习模型,如循环神经网络、长短期记忆网络等。
-
使用建立的文字识别模型,对分割得到的文字区域进行识别,得到文字内容。
在此基础上,还可以采用以下方法来提升甲骨文文字识别的准确率:
-
引入语言模型:甲骨文文字具有一定的语言结构,可以利用语言模型来提升识别的准确率。可以采用统计语言模型,如n-gram模型,也可以采用基于深度学习的语言模型,如循环神经网络语言模型等。
-
结合上下文信息:甲骨文文字之间存在一定的联系,可以利用上下文信息来提升识别准确率。可以考虑使用循环神经网络等模型来建立上下文之间的依赖关系。
-
融合多种特征:可以结合多种特征,如形态学特征、灰度共生矩阵特征、深度学习特征等,来提升识别准确率。
-
使用迁移学习:可以利用其他相关任务的已有数据,来提升甲骨文文字识别的效果。可以采用迁移学习的方法,将其他任务学习到的知识迁移到甲骨文文字识别任务中。
问题4:基于前三问对甲骨文原始拓片图像的单字分割研究,请采用合适的方法进行甲骨文原始拓片的文字识别。
甲骨文文字识别是一个复杂的任务,需要结合图像处理、机器学习和人工智能等多种技术手段。一般来说,甲骨文文字识别的流程可以分为以下几个步骤:
-
图像预处理:首先对甲骨文原始拓片图像进行预处理,去除噪声、平滑图像、增强对比度等,使得图像更利于后续的分析和处理。
-
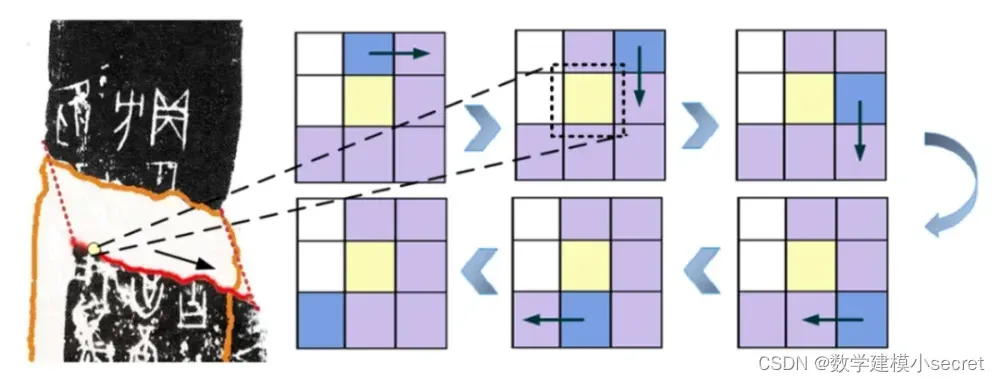
文字分割:根据前文所述的甲骨文图像分割模型,在图像中找到独立的文字区域,将每个文字分割出来,作为后续文字识别的输入。
-
特征提取:针对分割出的每个文字,提取特征,这些特征可以包括文字的笔画数、笔画顺序、笔画的方向和形状等。
-
文字识别:根据提取的特征,采用合适的机器学习算法,如支持向量机(SVM)、卷积神经网络(CNN)等,训练一个文字识别模型。然后将分割出的每个文字作为输入,通过模型预测其对应的文字形。
-
异体字识别:根据附件4(Recognize文件夹)中给出的甲骨文字形,采用同样的方法训练一个异体字识别模型。然后将分割出的每个文字作为输入,通过模型预测其对应的异体字形。
-
文字合并:将识别出的文字形和异体字形进行合并,得到最终的文字识别结果。
具体到甲骨文文字识别中,可以采用如下数学公式来表示:
- 图像预处理:
预处理后的图像 ,其中
为原始图像,
为图像预处理函数。
- 文字分割:
分割后的文字 ,其中
为第
个文字。
- 特征提取:
对第 个文字
,提取特征
,其中
为第
个特征。
- 文字识别:
根据提取的特征 ,利用训练好的文字识别模型
,得到识别结果
。
- 异体字识别:
根据提取的特征 ,利用训练好的异体字识别模型
,得到识别结果
。
- 文字合并:
将识别出的文字 和异体字
进行合并,得到最终的识别结果
。
import cv2
import numpy as np
import pytesseract
# 读取图像
img = cv2.imread("test.jpg")
# 调整图像大小
img = cv2.resize(img, (600, 600))
# 图像预处理
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (5, 5), 0)
thresh = cv2.threshold(blur, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)[1]
# 轮廓检测
contours = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
contours = contours[0] if len(contours) == 2 else contours[1]
# 计算每个轮廓的面积
areas = []
for c in contours:
area = cv2.contourArea(c)
areas.append(area)
# 根据面积排序
sorted_areas = sorted(zip(areas, contours), key=lambda x: x[0], reverse=True)
# 获取最大面积的轮廓
largest_cnt = sorted_areas[0][1]
# 提取轮廓位置及大小
x, y, w, h = cv2.boundingRect(largest_cnt)
# 截取轮廓部分图像
crop = img[y:y + h, x:x + w]
# 文字识别
text = pytesseract.image_to_string(crop, lang='chi_sim')
# 显示识别结果
print("识别结果:", text)
# 显示截取的图像
cv2.imshow("Crop Image", crop)
cv2.waitKey(0)
cv2.destroyAllWindows()
mathorcup跟紧小秘籍冲冲冲!!更多内容可以点击下方名片详细了解!
记得关注 数学建模小秘籍打开你的数学建模夺奖之旅!
版权声明:本文为博主作者:数学建模小secret原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/Mmmath_secret/article/details/137675301