斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多·斐波那契(Leonardo Fibonacci)以兔子繁殖为例子而引入,故又称“兔子数列”,其数值为:1、1、2、3、5、8、13、21、34……在数学上,这一数列以如下递推的方法定义:
F(0)=1,F(1)=1, F(n)=F(n – 1)+F(n – 2)(n ≥ 2,n ∈ N*)。
本文将介绍 Fibonacci 数列的动态规划与矩阵快速幂解法。
前置代码
本文中所用的都是long long,大概在90多会溢出,出现错误。你也可以改成 unsigned long long。
#include <stdio.h>
long long fibonacci(int n);
int main(int argc, char const *argv[])
{
int n;
scanf("%d", &n);
long long result = fibonacci(n);
printf("\nresult: %lld\n", result);
return 0;
}递归解法
这是思路最简单的方式,直接根据Fibonacci数列的递推定义完成。
long long fibonacci(int n)
{
if(n<=2) return 1;
long long result = fibonacci(n-1)+fibonacci(n-2);
// printf("The %2dth :%lld\t", n, result);
return result;
}但它显然不是好的方法,你可以试着输入 50甚至90,它的运行时间让人无法接受。50的话还能在几十秒后出来结果,90恐怕就停摆了。(从此处开始运行到文章写完,又过了好久还没有结果,不相等了,有兴趣的朋友自己试一试

这是以 10 为例的运行结果,可以看出它会重复输出一些结果,次序越小计算的次数越多,这些重复的运算严重影响了性能。
可以看到这个程序形成了高度为 n-1 的二叉树,时间复杂度高达 2^n 级别。

那么如何改进呢?
改进一
我们很自然地想到,既然这些数据要重复用到,那么为什么不把它记录下来,避免重复计算呢?这就是动态规划的思想。
此代码使用了数组 dp[n+1]来存储每一步的值,通过一个额外的数组开销来节省时间。只需一次从前往后的计算即可得到结果。将时间复杂度从 2^n 降到了线性,同时空间复杂度也是 O(n).
long long fibonacci(int n)
{
long long dp[n + 1];
dp[0] = 0; dp[1] = 1;
for (int i = 2; i <= n; ++i)
dp[i] = dp[i - 1] + dp[i - 2];
// for (int i = 1; i <= n; ++i)
// printf("The %2dth :%lld\t", i, dp[i]);
return dp[n];
}
改进二
进一步思考,例如 f(4) 和 f(5) ,在计算得到 f(6) 和 f(7)之后就用不着了,接下来的计算只需使用f(6) 和 f(7)。同样的,得到 f(8) 和 f(9)后,f(6) 和 f(7) 也用不着了。所以我们不需要记录完整的过程,只需记录上一个和上上个结果即可。这样,时间复杂还是 O(n),而空间复杂度只有O(1)。
long long fibonacci(int n)
{
long long dp0 = 0, dp1 = 1;
// if (n == 1) printf("The 1th :1\t");
for (int i = 2; i <= n; ++i)
{
long long temp = dp0 + dp1;
// printf("The %2dth :%lld\t", i, temp);
dp0 = dp1;
dp1 = temp;
}
return dp1;
}改进三
Fibonacci 数列 也可以用矩阵的形势式表述。它的递推公式如下: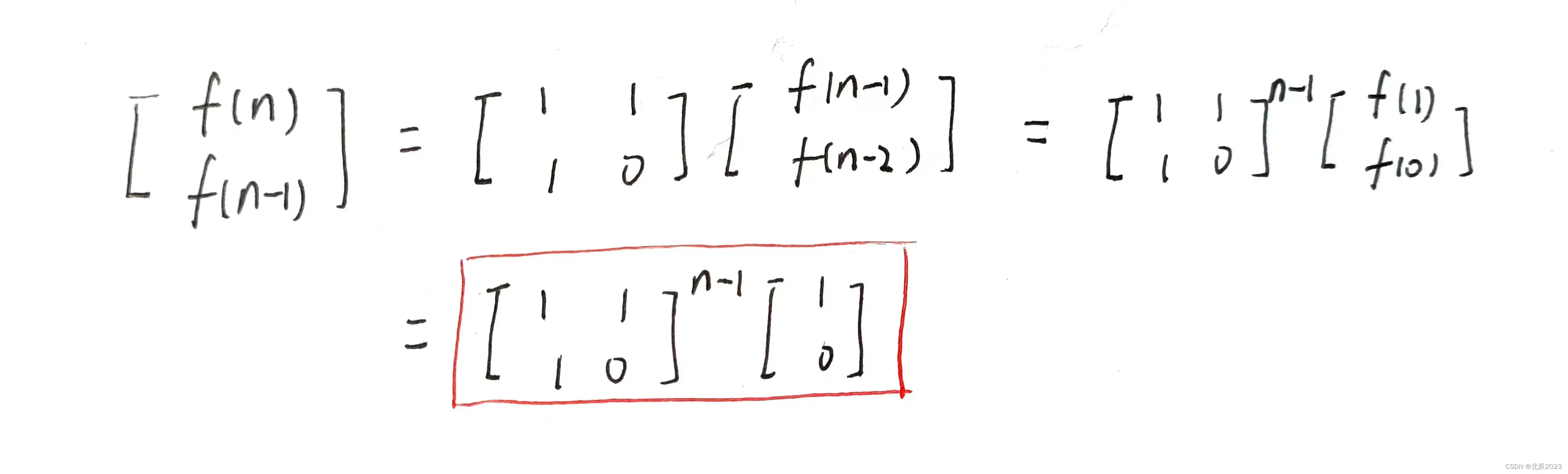
需要的结果被表达成了一个 系数矩阵 右乘 初始向量{0,1},所以现在的关键是求系数矩阵。这里使用的是矩阵快速幂,它和快速幂的原理相同,只不过底数变成了矩阵,用的是矩阵乘法。
快速幂示例:
- a^15, a^25 用普通乘法需要连乘14、24次。但你也可以如下改写:
- a^15 = a^8 * a^4 * a^2 * a^1.对应着 15 的二进制 1111
- a^25 = a^16 * a^8 * a^1.对应着25的二进制 11001
而 a^16 由 a^8 做一次乘法,a^8 由 a^4 做一次乘法……。至多有 log n 个因子,每个因子只需做一次乘法,再把它们乘起来,这样至多有 log n + log n 次乘法。
while (n > 0)
{//快速幂
if (n & 1) //n % 2
ans *= a;
n >>= 1; //n /= 2;
a *= a;
}结合代码,以 a^25 为例分析:
- 11001,末位1,需要 a^1,ans *=a 表示取用a^1;右移1位,成1100, a 自乘,接着求 (a^2)^12;
- 1100,末位0,不需要,直接继续右移变成110,a 自乘。接下来求(a^4)^6;
- 110,末位0,不需要,右移成11,a自乘,接着求(a^8)^3;
- 11,末位1,ans*=a,取用a^8;右移成1,接着求(a^16)^1
- 1,末位1,ans*=a,取用a^16。继续右移成0,计算终止。
取用的数字与我们分解的式子对应。矩阵同理。
这样递推地求解无疑节省了运算次数,将复杂度降到了O(logn)级别。
void multiply(long long f[], int a[][2])
{//系数*向量
long long t0 = f[0] * a[0][0] + f[1] * a[0][1];
long long t1 = f[0] * a[1][0] + f[1] * a[1][1];
f[0] = t0;
f[1] = t1;
}
void power(int m[][2])
{//幂运算
int i, j, k;
int tmp[2][2] = {0};
for (i = 0; i < 2; ++i)
{
for (j = 0; j < 2; ++j)
for (k = 0; k < 2; ++k)
tmp[i][j] += m[i][k] * m[k][j];
}
for (i = 0; i < 2; ++i)
for (j = 0; j < 2; ++j)
m[i][j] = tmp[i][j];
}
long long fibonacci(int n)
{
long long f[2] = {1, 0};
int matrix[2][2] = {{1, 1}, {1, 0}};
while (n > 1)
{//矩阵快速幂
if (n & 1) //n % 2
multiply(f, matrix);
n >>= 1; //n /= 2;
power(matrix);
}
multiply(f, matrix);
return f[1];
}版权声明:本文为博主作者:北辰2023原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_68393125/article/details/134530049