目录
Android的音效架构中,将所有的音效算法全部挂载到AudioHAL进程中运行。根据音效算法应用的位置,可以分为三类:Track音效、Stream音效、Device音效。即:针对某一个Track的处理音效、针对某种StreamType的处理音效、针对某个Device的处理音效。在Android13音频子系统分析(一)—整体架构中我们已经看到,Track只是在APP层和AudioServer框架层中的概念,到了AudioHAL层已经没有Track的概念,只有Stream和Device。也就是说AudioFlinger模块中已经将多个Track的数据混合到一起再输出给StreamOut了。所以,可以想到,针对Track的音效处理,必然会跨进程调用,为了跨进程传输Track的音频数据给音效算法处理,然后将算法处理后的数据拿回来,就会导致额外的共享内存的创建开销,增加内存的消耗。这是我认为Android音效架构设计不合理的地方。下面我们一起来看一下Android音效架构的设计原理。
一、Android音效C/S架构
既然Android将所有音效算法运行在AudioHAL进程中,而核心的控制和使用者又是AudioServer进程中的AudioFlinger,所以,必然会通过Binder机制设计成一个C/S架构。在Server端,它提供了两个主要的HIDL接口:IEffectsFactory.hal和IEffect.hal。在AudioHAL进程初始化时(/hardware/interfaces/audio/common/all-versions/default/service.cpp中的源码),会将IEffectsFactory作为一个HIDL服务端,增加到ServiceManager中。客户端通过IEffectsFactory可以获取到指定的某种音效算法引擎:IEffect。以下是EffectHAL架构类图:
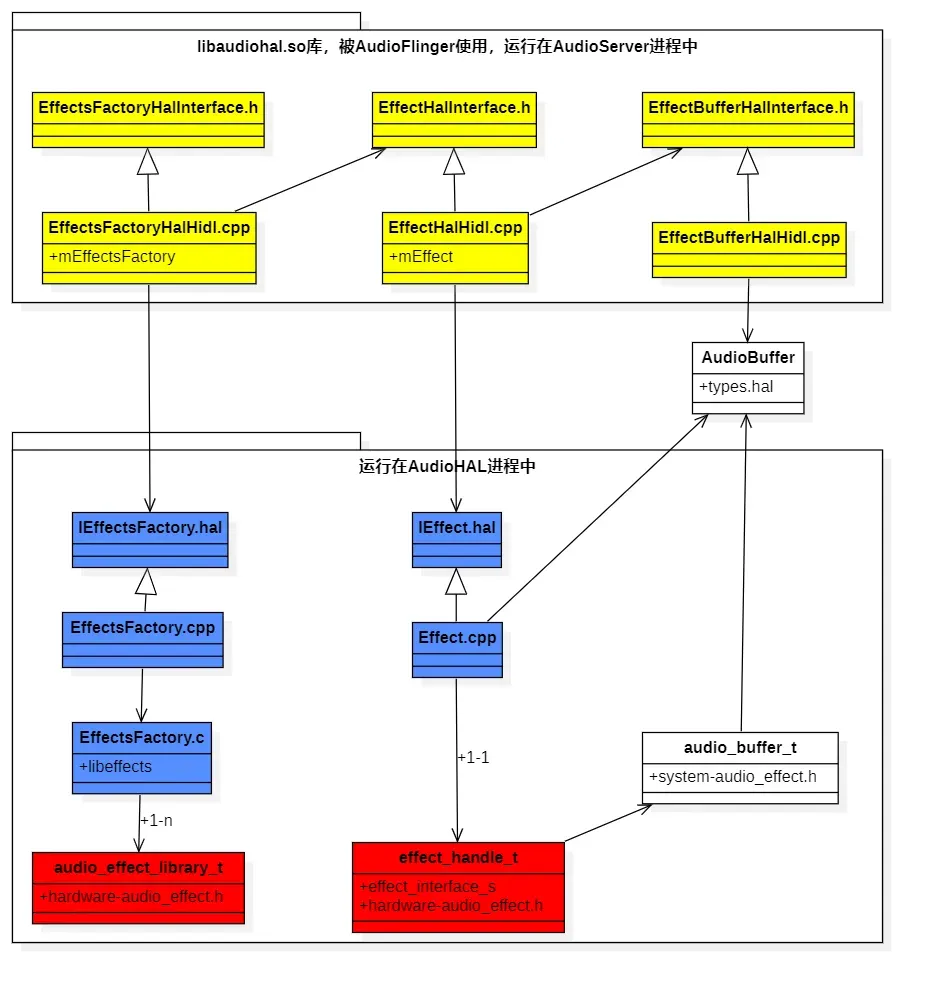
EffectHAL架构分为三层:
- Effect客户端代理层:图中黄色背景的模块。它们编译打包在libaudiohal.so库中,由AudioFlinger调用,运行在AudioServer进程中。源码位置:/frameworks/av/media/libaudiohal/
- Effect服务端实现层:图中蓝色背景的模块。运行在AudioHAL进程中。源码位置:/hardware/interfaces/audio/effect/all-versions/default/。其中EffectsFactory.c是用于解析音效配置文件audio_effects.xml,并加载调用音效算法的模块。其源码位于:/frameworks/av/media/libeffects/factory/。会被编译打包成libeffects.so库。所以,如果我们想让音效算法运行在AudioServer进程中,不跨进程调用,完全可以直接加载这个libeffects.so库,通过调用EffectsFactory.c模块来实现。当然,改动不会小。基于现有的Android音效框架修改的好处是提供了给上层APP的算法控制接口。我们也可以图省事,直接在AudioMixer混音器中新增加一种自定义类型的AudioBufferProvider,这样就可以针对单个AudioTrack进行自定义的音效处理。
- 提供给算法厂商的接口定义层:只有两个主要结构体,audio_effect_library_t和effect_interface_s。effect_handle_t是指向effect_interface_s结构体的指针。它们全部定义在/hardware/libhardware/include/hardware/audio_effect.h文件中。Android音效架构允许算法厂商将自己的多个算法编译打包到一个so库中,所以,audio_effect_library_t结构体中定义的是获取该so库中某个算法引擎的接口。而effect_interface_s结构体定义就是一个具体音效算法需要实现的接口。
- 图中的白色部分:AudioBuffer类(/hardware/interfaces/audio/effect/7.0/types.hal文件中定义)和audio_buffer_t结构体(/system/media/audio/include/system/audio_effect.h文件中定义),都是代表的共享内存块。里面封装了指向共享内存地址的指针。只是AudioBuffer类供C++代码使用,audio_buffer_t结构体供C代码使用。
- 除了上述的几个模块外,还有一个常用的模块在图中没有体现。它就是供C++代码使用的EffectDescriptor类(/hardware/interfaces/audio/effect/7.0/types.hal文件中定义)和供C代码使用的effect_descriptor_t结构体(/system/media/audio/include/system/audio_effect.h文件中定义)。它们都是用于描述某个音效算法的信息,包括typeUUID(由OpenSL ES定义的某种类型的音效算法,比如降噪算法全部定义的是一个TypeUUID,不管是哪家算法厂商实现的)、UUID(代表的是某个具体实现的降噪算法的唯一标识符,不同厂商实现的降噪算法UUID不会相同)、flags(代表此算法支持的能力,详细的解释可以参见/hardware/interfaces/audio/effect/7.0/types.hal文件)。剩下的如cpuLoad和memoryUsage字段,代表的是此算法所占用的CPU和内存情况,但是有些算法实现厂商并不会给出这部分信息描述,比如Android自己实现的多声道转双声道的算法EffectDownmix就没有。AudioPolicyService会基于这两个字段来统计监控所有算法的CPU和内存使用情况,但是显然是不准确的。
Android虽然支持第三方算法厂商基于audio_effect.h->effect_interface_s接口实现自己的算法,同时也自己默认实现了一些音效算法,供上层使用。它们的源码位于/frameworks/av/media/libeffects/目录中。主要包括以下几种:
- EffectDownmix:用于将多声道转换成立体声双声道。
- DynamicsProcessing:动态范围调节音效。
- EffectHapticGenerator:基于音频数据生成震动效果数据。
- LoudnessEnhancer:音量放大音效。
- PreProcessing:音频上行录制通路使用的前处理算法。包含AGC自动增益算法、AEC回声消除算法、NS降噪算法。也就是通话场景下常说的3A算法。因为NS降噪算法有的地方也叫ANS。这三种算法Android都是调用WebRTC中的音效模块实现的。显然,针对通话场景,直接在DSP芯片中运行3A算法会更高效。所以,实践中各个手机厂商也没有人会使用Android提供的这个PreProcessing算法。
- Visualizer:将音频PCM数据转换成可视化的波形图。
- BassBoost:低音增强音效。
- PresetReverb:环境混响音效。主要适用于音乐播放场景。
- EnvironmentalReverb:环境混响音效。提供更多的混响参数设置。适用于游戏播放场景。
- Equalizer:EQ均衡器音效。
- Virtualizer:空间感音效。
- EffectPoxy:Android定义的音效代理接口。对应音效配置文件audio_effects.xml中的<effectProxy>节点,它保存了两种音效子类,一种是<libsw>节点中定义的运行在AudioHAL进程中的普通音效。一种是<libhw>节点中定义的与DSP中运行的音效算法通信的代理音效。也就是说,Android音效架构提供了接口用于控制运行在DSP中的音效算法。但是需要音效算法厂商把控制端基于audio_effect.h->effect_interface_s接口实现,并且在audio_effects.xml文件中配置。
二、EffectHAL音效框架的初始化与使用
前面有提到audio_effects.xml音效配置文件,那么Android音效框架是在什么时候解析加载的这个配置文件中的音效的呢?它采用的是类似”懒加载模式”,并不是在EffectsFactory.cpp创建并添加进HIDL服务端时初始化的,而是在客户端有人调用EffectsFactoryHalInterface.h接口中的函数时,才会初始化。也就是有人使用的时候才会初始化。
下面我将以AudioMixer中的DownmixerBufferProvider为例,呈现音效框架的初始化过程。AudioMixer是供AudioFlinger使用的、用于将AudioTrack的音频数据进行声道数转换、Format采样精度转换、采样率转换的混音器。其中DownmixerBufferProvider是它的一个子模块,用于将多声道转换成双声道,转换算法使用的是音效框架中提供的EffectDownmix。它们的源码位于/frameworks/av/media/libaudioprocessing/目录中。我之所以选择DownmixerBufferProvider为例讲解音效框架的初始化过程,是因为它直接使用的libaudiohal.so库中的EffectsFactoryHalInterface.h接口和EffectHalInterface.h接口,没有经过AudioFlinger。所以,也就没有AudioFlinger中涉及的sessionId、EffectChain、AudioEffect这些概念。可以更加简单清晰的理解如何通过libaudiohal.so库调用Android音效框架。
音效框架的使用流程主要就三步:
- 查询是否存在声道转换音效?
- 初始化声道转换音效。包括创建音效代理接口对象EffectHalInterface、创建共享内存EffectBufferHalInterface、设置音效算法的参数。
- 声道转换音效算法处理。先将准备好的音频数据拷贝到共享内存中,然后通过EffectHalInterface->process()接口通知音效算法进行处理。
2.1音效框架初始化
DownmixerBufferProvider是在它的init()函数中进行查询的,它采用的方法是先通过EffectsFactoryHalInterface->queryNumberEffects()接口,查询目前音效框架中存在的音效算法总数量,然后循环遍历EffectsFactoryHalInterface->getDescriptor(uint32_t index,effect_descriptor_t *pDescriptor)接口,获取每个音效算法的描述对象effect_descriptor_t,最后看一下这些effect_descriptor_t中是否存在Downmix的TypeUUID。下面我们跟踪下它所使用的音效框架的第一个接口queryNumberEffects(),看看是如何触发音效框架初始化的。
BufferProviders.cpp->DownmixerBufferProvider::init()
|->EffectsFactoryHalHidl.cpp->queryNumberEffects()
|->EffectsFactoryHalHidl.cpp->queryAllDescriptors()
|->EffectsFactory.cpp->getAllDescriptors()//Binder跨进程调用
|->EffectsFactory.c->EffectQueryNumberEffects()//libeffects库中的代码
|->EffectsFactory.c->init()可以看出,最终调用的是EffectsFactory.c(/frameworks/av/media/libeffects/factory/)的EffectQueryNumberEffects()接口。EffectsFactory.c对外提供的接口函数中,都会先调用自己的init()函数,用于初始化音效框架。init()函数中使用了一个全局变量gInitDone,所以init()函数只会执行一次。在init()函数中,它会先查询”ro.audio.ignore_effects”系统属性,如果这个系统属性配置为了true,就不会初始化解析audio_effects.xml音效配置文件,也就不会初始化所有的音效算法。我们在Debug设备的音频播放性能时,可以把这个系统属性设置为true,即可bypass掉所有的音效处理。下面接着看下init()函数做了什么事情。
EffectsFactory.c->init()
|->EffectsXmlConfigLoader.cpp->EffectLoadXmlEffectConfig()
|->EffectsConfig.cpp->parse()//解析audio_effects.xml配置文件,保存到EffectsConfig.h->Config结构体中。
|->EffectsXmlConfigLoader.cpp->loadLibraries()//将加载成功的音效so库所对应的libeffects/EffectsFactory.h->lib_entry_t结构体保存到gLibraryList列表中。
|->EffectsXmlConfigLoader.cpp->loadLibrary()//从"/vendor/lib64/soundfx"目录中加载音效so库。获取该so库中的声明为AUDIO_EFFECT_LIBRARY_INFO_SYM的结构体,从而获取到audio_effect_library_t结构体句柄。
|->EffectsXmlConfigLoader.cpp->loadEffects()//将获取的effect_descriptor_t数据保存到lib_entry_t->effects列表中
|->EffectsXmlConfigLoader.cpp->loadEffect()
|->audio_effect.h->audio_effect_library_t.get_descriptor()
|->EffectDownMix.cpp->DownmixLib_GetDescriptor()//实际调用的是音效so库中的函数,用于获取effect_descriptor_t结构体数据
|->EffectsFactory.c->updateNumEffects()//将所有lib中effect_descriptor_t的总数汇总后保存到gNumEffects变量中当这段代码执行完成了,音效框架就完成了audio_effects.xml文件的解析、加载了所有的音效so库、并创建了每个音效对应的描述对象effect_descriptor_t。但是此时并没有创建音效算法对应的处理对象effect_handle_t,要等到有人真正使用时才会创建。
下面看一下audioeffects.xml配置文件,这个配置文件包括了5种节点:
<libraries>节点。里面包含的是所有音效so库的名称。EffectsFactory.c会通过这个名称在”/vendor/lib64/soundfx”目录中加载so库。然后获取该so库中的声明为AUDIO_EFFECT_LIBRARY_INFO_SYM的结构体,从而获取到audio_effect_library_t结构体的句柄。
<libraries>
<library name="downmix" path="libdownmix.so"/>
<library name="proxy" path="libeffectproxy.so"/>
<library name="bundle" path="libbundlewrapper.so"/>
<library name="offload_bundle" path="libqcompostprocbundle.so"/>
</libraries><effects>节点。里面包含了所有的音效算法声明。每个音效算法都需要指定它所属的so库名称和自己的唯一UUID。通过这个UUID,我们就可以通过audio_effect_library_t->get_descriptor(uuid,effect_descriptor_t *pDescriptor)接口获取到该音效对应的描述结构体effect_descriptor_t。也可以通过audio_effect_library_t->create_effect(uuid,effect_handle_t *pHandle)获取到其对应的使用接口effect_handle_t。
<effects>
<effect name="downmix" library="downmix" uuid="93f04452-e4fe-41cc-91f9-e475b6d1d69f"/>
<effectProxy name="bassboost" library="proxy" uuid="14804144-a5ee-4d24-aa88-0002a5d5c51b">
<libsw library="bundle" uuid="8631f300-72e2-11df-b57e-0002a5d5c51b"/>
<libhw library="offload_bundle" uuid="2c4a8c24-1581-487f-94f6-0002a5d5c51b"/>
</effectProxy>
</effects><postprocess>节点。用于为某个streamType绑定多个音效算法。AudioPolicyService会在初始化时解析此节点。下面这个配置,代表的意思是所有申明为AUDIO_STREAM_MUSIC的AudioTrack,在播放时都会加载bassboost低音增强音效和loudness_enhancer音量放大音效。相当于配置了一个全局音效。
<postprocess>
<stream type="music">
<apply effect="bassboost"/>
<apply effect="loudness_enhancer"/>
</stream>
</postprocess><preprocess>节点。用于为某个inputSource绑定多个音效算法。AudioPolicyService会在初始化时解析此节点。下面这个配置,代表的意思是所有申明了AUDIO_SOURCE_VOICE_COMMUNICATION的AudioRecord(即VoIP语聊场景),在录制音频数据时都会加载AEC算法和NS算法。
<preprocess>
<stream type="voice_communication">
<apply effect="aec"/>
<apply effect="ns"/>
</stream>
</preprocess><deviceEffects>节点。用于为某个设备绑定多个音效算法。AudioPolicyService会在初始化时解析此节点。下面这个配置,代表的意思是为内置麦克风绑定一个AGC算法。也就是不管什么场景的录音,都会执行AGC算法。
<deviceEffects>
<devicePort type="AUDIO_DEVICE_IN_BUILTIN_MIC" address="bottom">
<apply effect="agc"/>
</devicePort>
</deviceEffects>从上面可以看出,audioeffects.xml文件包含了两部分配置内容。一部分是配置申明音效算法,由AudioHAL负责解析。一部分是配置全局音效:Stream音效和Device音效,由AudioPolicyService负责解析。在EffectsFactory.c完成初始化后,AudioHAL进程的本地内存中就保存了audio_effect_library_t列表和effect_descriptor_t列表,供上层查询使用。
2.2创建并加载音效算法
在DownmixerBufferProvider的构造函数中,会使用EffectsFactoryHalInterface->createEffect(uuid,sessionId,ioId,deviceId,sp<EffectHalInterface> *effect)接口来创建IEffect.hal的代理对象EffectHalHidl。其中ioId指是PlaybackThread中StreamOutHAL对应的Id。seesionId、ioId、deviceId都可以不指定。它们主要是告诉音效算法自己处理的数据是为谁服务的。必须指定的只有UUID这个。可以猜到,EffectsFactory.c正是通过UUID来查找并创建该音效对应的effect_handle_t接口的。下面简单看一下调用流程:
BufferProviders.cpp->DownmixerBufferProvider::DownmixerBufferProvider()
|->EffectsFactoryHalHidl.cpp->createEffect()//创建EffectHalHidl对象
EffectsFactory.cpp->createEffect()//Binder跨进程调用,获取IEffect对象
|->EffectsFactory.cpp->createEffectImpl()//创建IEffect对象(DownmixEffect对象),生成effectId。并保存到EffectMap集合中。
|->EffectsFactory.c->EffectCreate()//libeffects库中。获取effect_handle_t句柄
|->EffectsFactory.c->doEffectCreate()
|->audio_effect.h->audio_effect_library_t.create_effect()
|->EffectDownMix.cpp->DownmixLib_Create()//返回的是downmix_module_t结构体句柄
|->EffectDownMix.cpp->Downmix_Init()//设置输入源的数据格式为:7.1声道、浮点型、44.1K采样率。输出的数据格式为:双声道、浮点型、44.1K
|->EffectsFactory.cpp->dispatchEffectInstanceCreation()//根据effect_descriptor_t结构体中的type(即OpenSL ES中定义的音效类型UUID),创建对象。new DownmixEffect对象。当这段代码执行完成后,在客户端,EffectsFactoryHalHidl.cpp创建了一个EffectHalHidl对象,供DownmixerBufferProvider调用使用。EffectHalHidl有一个成员变量IEffect(由IEffectFactory返回的),指向的是服务端AudioHAL进程中的DownmixEffect.cpp对象,DownmixEffect有一个成员变量Effect.cpp,Effect有一个成员变量effect_handle_t,effect_handle_t指针指向的是EffectDownMix.cpp的downmix_module_t结构体。这样最终DownmixerBufferProvider就和EffectDownMix算法建立了联系。下面是调用关系图:
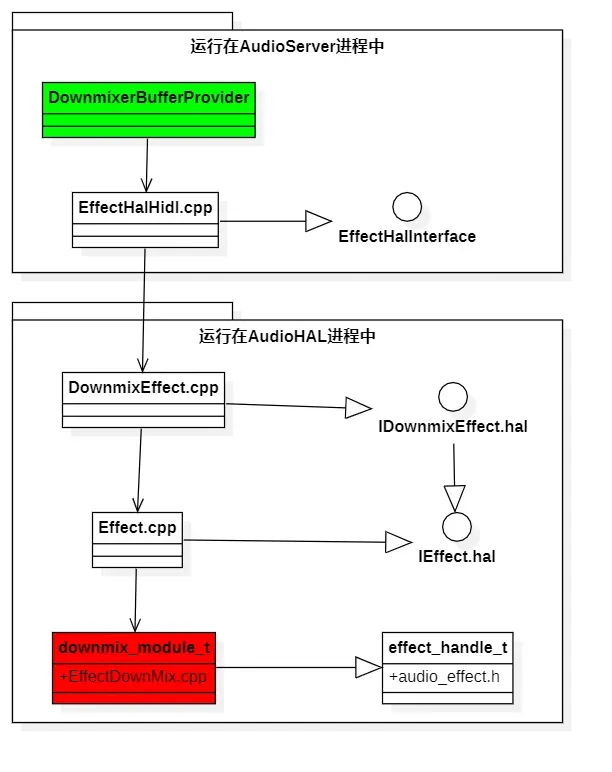
上面图标为绿色的DownmixerBufferProvider代表的是音效算法的使用方。标为红色的downmix_module_t代表的是音效算法的实现方,中间白色部分是前文提到的音效框架。
创建完EffectHalHidl对象后,就需要创建共享内存了。我们从effect_handle_t接口中的音效算法处理函数process(effect_handle_t self,audio_buffer_t *inBuffer,audio_buffer_t *outBuffer)中,可以看出音效算法处理时是需要两块内存空间,一个用于保存输入给音效算法的数据内存块inBuffer,一个用于音效算法处理完成后输出的数据内存块outBuffer。我们可以通过EffectsFactoryHalHidl的mirrorBuffer(void* external,size_t size,sp<EffectBufferHalInterface>* buffer)接口,创建一块共享内存。其中external指针指向的是本地数据内存块。保存在EffectBufferHalHidl对象的mExternalData成员变量中。然后EffectBufferHalHidl会通过IAllocator接口创建一块共享内存,保存在AudioBuffer.data中,它会被传递给Effect服务端。它的调用代码很简单如下:
BufferProviders.cpp->DownmixerBufferProvider::DownmixerBufferProvider()
|->EffectsFactoryHalHidl.cpp->mirrorBuffer(&mInBuffer)//创建输入数据共享内存块
|->EffectBufferHalHidl.cpp->mirror()//创建EffectBufferHalHidl对象
|->EffectBufferHalHidl.cpp->init()//创建共享内存
|->EffectsFactoryHalHidl.cpp->mirrorBuffer(&mOutBuffer)//创建输出数据共享内存块
|->EffectBufferHalHidl.cpp->mirror()//创建EffectBufferHalHidl对象
|->EffectBufferHalHidl.cpp->init()//创建共享内存
|->EffectHalHidl.cpp->setInBuffer(mInBuffer)//为音效绑定输入共享内存块
|->EffectHalHidl.cpp->setOutBuffer(mOutBuffer)//为音效绑定输出共享内存块当上述代码执行完了后,音效使用方就新创建了两个共享内存块。供算法使用。

上图就是当使用音效算法时,音频数据的传递路径:从”本地内存”拷贝到”输入共享内存”,音效算法读取处理完成后,将新数据写入到”输出共享内存”,EffectBufferHalHidl会将”输出共享内存”中的数据拷贝回”本地内存”,供音效调用方后续使用。当然,如果音效处理前后的数据所需的内存大小完全一样,也可以将输入和输出指向同一块共享内存。但是使用Android架构的音效处理时,仍然至少要创建一份共享内存块。所以,这就是我认为Android音效架构设计不合理的地方。因为在Android音效架构中,Track音效的使用方是AudioFlinger。所以,必然会出现因为跨进程通信,需要额外创建共享内存的情况。
新创建完共享内存并传递给了EffectHalHidl后,就需要对算法进行配置,比如说明输入的音频数据的采样率、声道数、Format精度;要求输出的音频数据格式等。调用的是EffectHalHidl->command()接口。因为逻辑比较简单,这里就不列出代码调用流程了。
2.3执行音效算法
DownmixerBufferProvider是通过EffectHalHidl.cpp->process()接口,来通知音效算法执行的,最终通过层层调用,会调用到effect_handle_t.process()接口。EffectDownMix算法针对该接口的实现是EffectDownMix.cpp->Downmix_Process()函数。
查看Downmix_Process()函数源码你会发现,EffectDownMix并没有自己写处理算法,而是调用的/system/media/audio_utils/include/audio_utils/ChannelMix.h->process()接口。并且与DownmixerBufferProvider类似的、提供相同功能的ChannelMixBufferProvider模块,也是使用ChannelMix.h进行处理的。而AudioMixer却把DownmixerBufferProvider作为多声道转双声道处理的首选模块,显然是没有必要的,除非我们自己实现了一个声道转换算法,配置在audioeffects.xml文件中。否则建议大家修改一下AudioMixer代码(AudioMixer.cpp->prepareForDownmix()函数中),将多声道转换双声道处理的模块默认改成ChannelMixBufferProvider模块,效果完全一样,却不需要跨进程调用,也不用创建新的共享内存,系统资源消耗的更少。
BufferProviders.cpp->DownmixerBufferProvider::copyFrames()
|->EffectBufferHalHidl.cpp->setExternalData()//设置本地内存的指针,因为在构造函数中没有指定。
|->EffectBufferHalHidl.cpp->update()//将待处理的数据从本地内存拷贝到共享内存中
|->EffectHalHidl.cpp->process()//通知音效算法处理
|->EffectHalHidl.cpp->processImpl()
|->EffectHalHidl.cpp->prepareForProcessing()
|->DownmixEffect.cpp->prepareForProcessing()//Binder跨进程调用
|->Effect.cpp->prepareForProcessing()//创建并运行"effect"线程
|->EffectHalHidl.cpp->needToResetBuffers()
|->EffectHalHidl.cpp->setProcessBuffers()
|->DownmixEffect.cpp->setProcessBuffers()//Binder跨进程调用
|->Effect.cpp->setProcessBuffers()
|->AudioBufferManager.cpp->wrap()//将创建的AudioBufferWrapper对象保存到mBuffers集合中。
|->new AudioBufferWrapper()
|->AudioBufferManager.cpp->AudioBufferWrapper::init()//构建audio_buffer_t结构体,将audio_buffer_t.raw指针指向AudioBuffer共享内存
|->Effect.cpp->ProcessThread::threadLoop()
|->audio_effect.h->effect_interface_s.process()
|->EffectDownMix.cpp->Downmix_Process()
|->ChannelMix.h->process()
|->EffectBufferHalHidl.cpp->commit()//将共享内存中的数据拷贝给本地内存上面是音效处理的调用流程代码,需要说明的是:
- 在第一次处理数据时,服务端Effect.cpp会新创建一个独立线程名为”effect”。也就是每个音效算法在执行时都运行在自己的独立线程中。
- 客户端EffectHalHidl.cpp与服务端Effect.cpp会基于MessageQueue来实现同步机制,当服务端没有处理完数据时,EffectHalHidl.cpp->process()函数会让当前调用线程休眠等待,当服务端处理完数据,通过MessageQueue唤醒客户端后,EffectHalHidl.cpp->process()函数才会返回。也就是说,EffectHalHidl.cpp->process()函数是阻塞式的。
三、AudioFlinger对音效框架的二次封装
AudioFlinger做为EffectHAL音效框架的核心控制方,为上层APP提供了一个AudioEffect.java接口,让用户可以启动一个音效并控制音效算法的相关参数。然后在自己模块的内部,定义了EffectHandle、EffectModule、EffectChain这三个内部类。
EffectHandle作为AudioEffect的服务端存在,与AudioEffect进行跨进程通信。它们是1:1的关联关系。
EffectModule作为真实音效算法的控制端存在,与EffectHalHidl进行关联,如前文所述,有了EffectHalHidl对象,EffectModule就与EffectHAL层建立了关联关系。能够真正的控制一个音效算法了。EffectModule与EffectHalHidl是1:1的关联关系。EffectModule与EffectHandle是1:n的关联关系。
EffectChain是一个列表集合,里面包含了一组EffectModule对象。也就是说EffectChain列表中包含了多个音效算法。目的是将这一组音效算法绑定到指定数据传输位置上。这样一个AudioTrack,就可以绑定多个音效算法了。同时,每个PlaybackThread里面会包含多个EffectChain对象,让每个EffectChain可以绑定到不同的数据传输位置上。
以下是它们的类图:
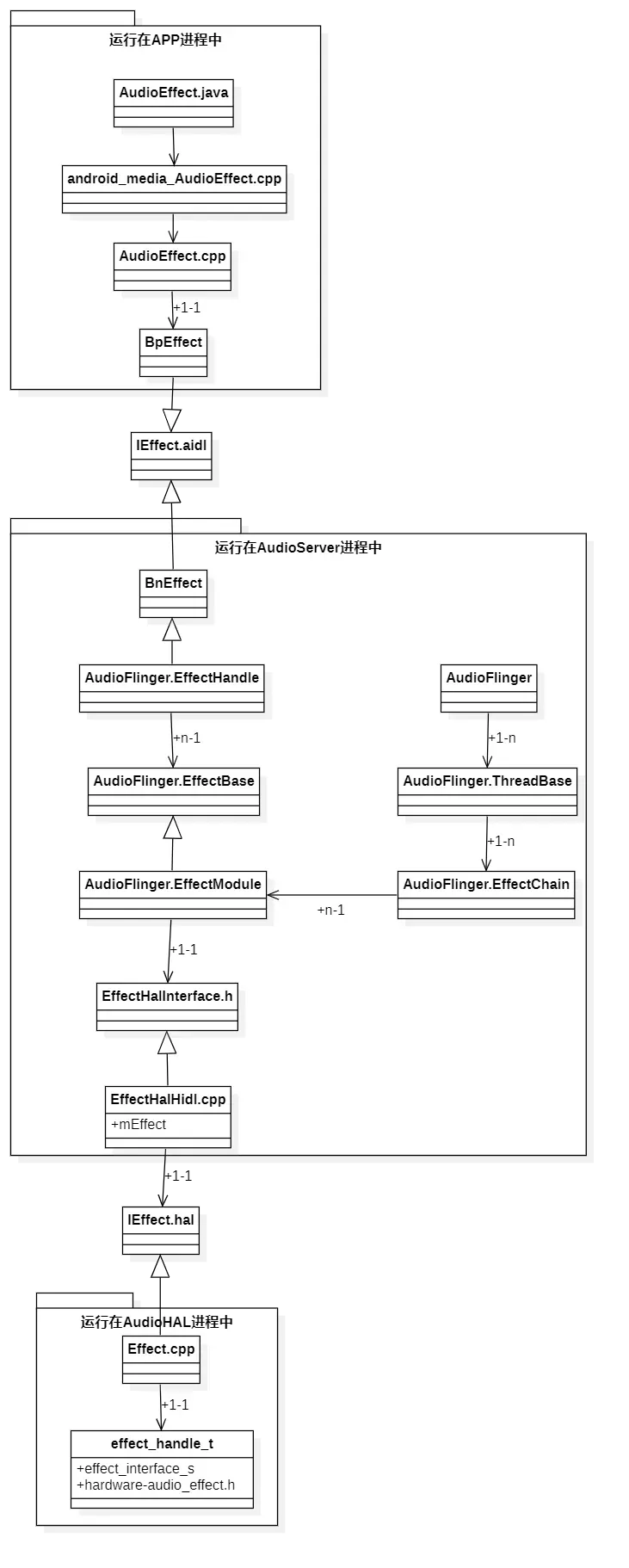
上面的类图因为要体现出继承和真实的关联关系,所以嵌套的层级比较多,不容易直观的看出AudioEffect、EffectHandle、EffectModule、EffectChain它们之间的关联关系。以下是简化后的关系图:
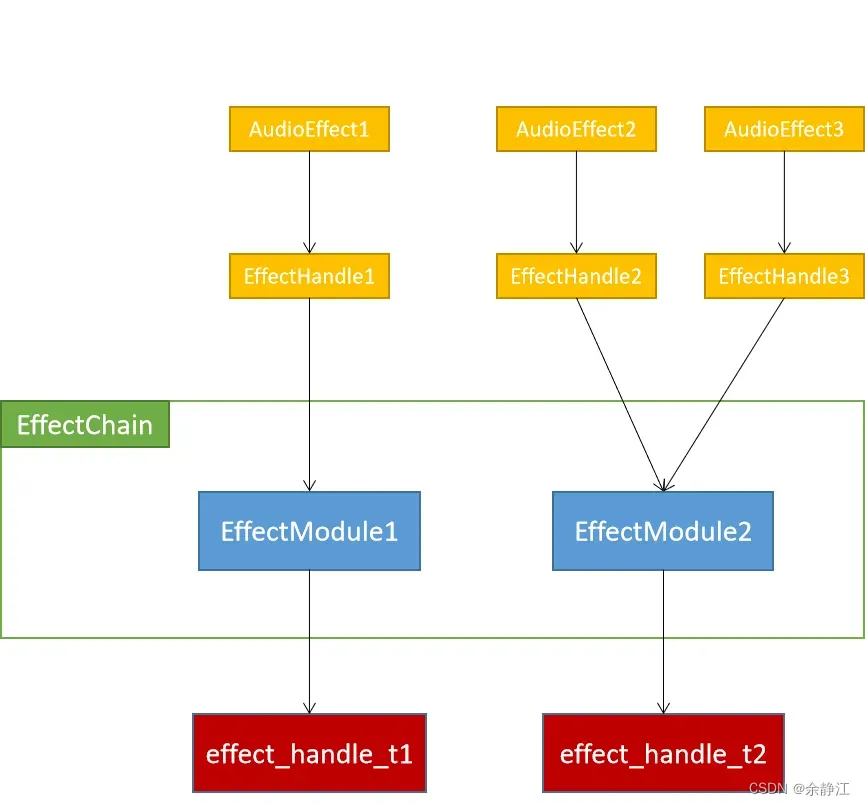
EffectHandle、EffectModule、EffectChain都是在AudioFlinger模块(/frameworks/av/services/audioflinger/目录)中的Effect.h文件中定义,在Effects.cpp文件中实现的。当查看Effect.h文件时,你会发现,Android还定义了一个DeviceEffectProxy类,它和EffectModule一样,都继承自EffectBase。DeviceEffectProxy代表的是绑定到Device的音效。当使用Device音效时,EffectHandle就和DeviceEffectProxy建立的关联关系,而不是直接和EffectModule。同时,在DeviceEffectManager.h文件中,还定义了一个DeviceEffectManager类,用于管理所有的DeviceEffectProxy对象。DeviceEffectProxy类有一个成员变量mHalEffect,它关联的是EffectModule对象。也就说做,DeviceEffectProxy最终还是通过EffectModule去控制真实的音效算法。下面是Device音效情况下的关系图,图中标红的是有变化的部分。
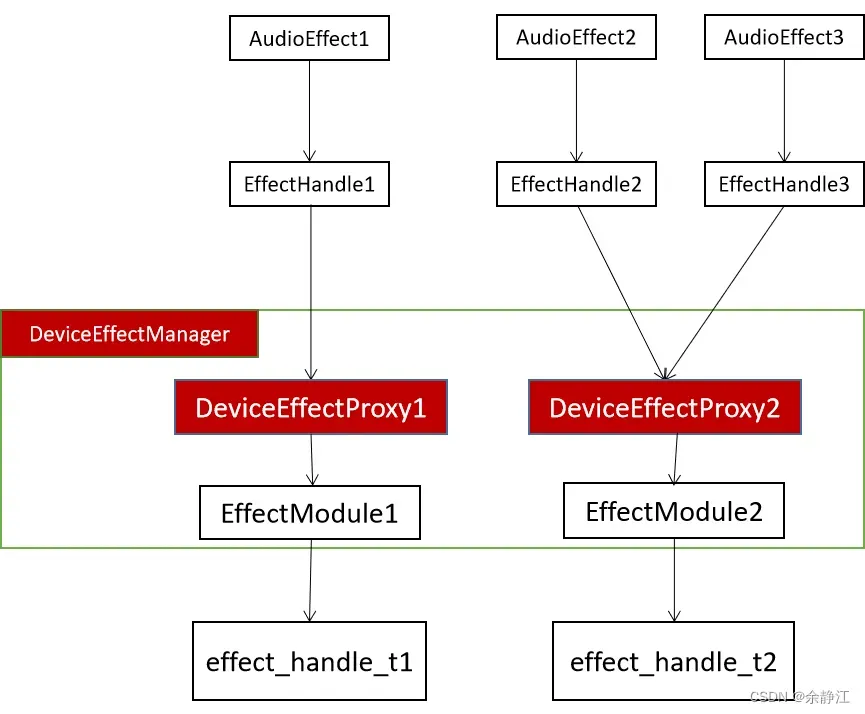
了解完AudioFlinger针对音效二次封装的架构,我们再来看一下AudioFlinger是如何绑定音效到指定位置的。为了绑定音效,Android引入了sessionId这个概念。AudioTrack正是通过sessionId与EffectChain进行绑定的。AndroidFlinger在接收到AudioTrack的创建请求时(AudioFlinger.cpp->createTrack()函数中),会为每个Track新分配一个唯一的seesionId,它是一个正整数,根据Track创建的先后顺序递增,也就是说越晚创建的Track,它被分配的seesionId的数值越大。
之所以说明seesionId的数值,是因为AudioFlinger模块会根据sessionId的大小来对EffectChain进行排序,按照从大到小的顺序排序。同时,/system/media/audio/include/system/audio.h的audio_session_t枚举中,定义了三种全局音效:AUDIO_SESSION_OUTPUT_MIX(值为0)、AUDIO_SESSION_OUTPUT_STAGE(值为-1)、AUDIO_SESSION_DEVICE(值为-2)。这样经过排序后,就可以得到多个EffectChain之间的执行先后顺序,EffectChain-Track最先执行,然后是EffectChain-Mix,然后是EffectChain-Stage、最后是EffectChain-Device。以下是执行顺序图:
EffectChain-Track2---》EffectChain-Track1---》EffectChain-Mix---》EffectChain-Stage---》EffectChain-DeviceAUDIO_SESSION_OUTPUT_MIX这个seesionId会被用于Aux音效的绑定。
AUDIO_SESSION_OUTPUT_STAGE这个seesionId会被用于空间音频(Spatializer)相关音效的绑定。
AUDIO_SESSION_DEVICE这个sessionId会被用于Device音效的绑定。
上层应用APP在创建自己的AudioTrack时,也可以指定一个已知的seesionId,通过已有的AudioTrack对象的AudioTrack.java->getAudioSessionId()函数获取,然后在创建新AudioTrack对象时通过AudioTrack.java->Builder.setSessionId()函数设置。这样,就把多个AudioTrack绑定到同一个sessionId上了。也就实现了AudioTrack与sessionId的n:1关系。但是,AudioTrack不能指定负数的sessionId。也就是说AudioTrack不能绑定到全局音效中。因为在AudioTrack.java->Builder.setSessionId()函数、AudioTrack.java的构造函数、AudioFlinger.cpp->createTrack()函数中都做了检查校验。
那么sessionId又是如何与Effect关联上的呢?我们在新创建一个AudioEffect对象时,需要指定一个sessionId。然后会通知AudioFlinger模块去创建该AudioEffect对应的AudioHandle(AudioFlinger.cpp->createEffect()函数中)。AudioFlinger模块会先根据seesionId查找与之对应的Track,找到了Track,也就找到了播放Track对应的PlaybackThread。然后从PlaybackThread的mEffectChains列表中,根据此sessionId找到对应的EffectChain对象。如果没有,就新创建一个EffectChain对象。所以,sessionId和EffectChain是1:1的对应关系。最后,为这个AudioEffect创建对应的EffectModule对象,并将它添加到EffectChain列表中。至此,AudioTrack就和EffectModule基于sessionId建立起了n:n的关联关系。以下是关系图:

从图中可以看出,同一个音效,它绑定到不同的seesionId时,会被重新创建一个新的EffectModule对象。比如BassBoost低音增强音效,它被分别绑定到QQ音乐和酷狗音乐的sessionId时,就会创建两个不同的BassBoost对象。这样两个音效处理就会各不干扰。
前面讲了多个EffectChain之间的执行顺序,那么在EffectChain中的多个EffectModule,它们的执行顺序是什么呢?AudioFlinger是根据effect_descriptor_t结构体(音效算法描述类)中的flags来控制的。在你实现的音效算法指定的flags中可以指定下面flag的任意一种:
EFFECT_FLAG_INSERT_FIRST:表示将自己这个音效算法插入到EffectChain最前面。即:最先执行。如果有多个音效算法指定了这个flag,就按照创建EffectModule的时间先后排序,后创建的放在后面执行。
EFFECT_FLAG_INSERT_LAST:表示将这个音效算法插入到EffectChain的最后面执行。如果有多个音效算法声明此flag,后创建的EffectModule会插入到上次那个的前面。
EFFECT_FLAG_INSERT_ANY:表示将这个音效算法插入到INSERT_FIRST和INSERT_LAST之间。有多个时,按照加入的时间依次向后插入。
EFFECT_FLAG_INSERT_EXCLUSIVE:表示排它。意思是插入的EffectChain中,只能包含这一个音效算法。
以下就是EffectChain中多个EffectModule的执行顺序:
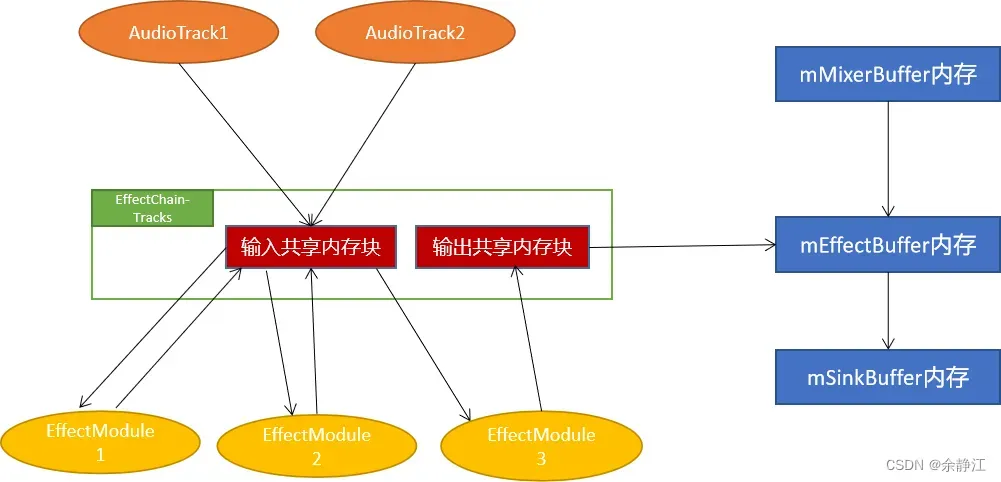
INSERT_FIRST1--》INSERT_FIRST2--》INSERT_ANY1--》INSERT_ANY2--》INSERT_LAST2--》INSERT_LAST1当AudioFlinger中的PlaybackThread在执行时,会创建三个本地内存块:mMixerBuffer、mEffectBuffer、mSinkBuffer。
mMixerBuffer内存块中保存的是所有没有绑定任何音效算法的Track的音频数据。
mEffectBuffer内存块中保存的是所有经过音效算法处理后的Track的音频数据。
mSinkBuffer内存块中保存的是最终需要输出给AudioHAL进程中StreamOut的音频数据。
所有的Track数据,都会先传递给AudioMixer混音器进行多声道转换、采样精度调整、重采样后,才会传递给绑定的音效算法处理或传递给mMixerBuffer内存块。
当此次PlaybackThread播放时所有的Track都没有绑定音效算法,PlaybackThread会将mMixerBuffer中的数据直接拷贝到mSinkBuffer中。
当此次PlaybackTread播放时所有的Track都绑定的有音效算法,mMixerBuffer内存块中就没有数据,就不会将其拷贝搬运到任何地方。
当此次PlaybackTread播放时即有绑定音效算法的Track,又有没有绑定的Track,PlaybackThread就会先将mMixerBuffer中的数据拷贝到mEffectBuffer中,再将mEffectBuffer的数据拷贝到mSinkBuffer中。
以下是音频数据传输流程图:

四、Device音效的绑定过程
Android中支持两种方式,将一个音效算法绑定到Device上处理。一种是动态创建一个AudioEffect对象,并给该对象指定的seesionId为AUDIO_SESSION_DEVICE。另一种是在audio_effects.xml文件的<deviceEffects>节点中申明,然后由AudioPolicyService解析后,通知AudioFlinger进行绑定。下面我将说明一下通过audio_effects.xml配置文件的绑定方式。
AudioPolicyService在它的初始化函数onFirstRef()中,会创建AudioPolicyEffects对象,AudioPolicyEffects在其构造函数中就会进行audio_effects.xml文件的解析,然后通知AudioFlinger绑定音效。以下是代码调用流程:
AudioPolicyService.cpp->onFirstRef()
|->new AudioPolicyEffects()
|->AudioPolicyEffects.cpp->loadAudioEffectXmlConfig()//mInputSources集合中保存的是<preprocess>节点中的配置。mOutputStreams集合中保存的是<postprocess>节点中的配置。mDeviceEffects集合中保存的是<deviceEffects>节点中的配置。
|->EffectsConfig.cpp->parse()//libeffectsconfig
|->AudioPolicyEffects.cpp->initDefaultDeviceEffects()AudioPolicyEffects与EffectHAL一样,也是调用EffectsConfig.cpp->parse()来进行audio_effects.xml文件的解析,它会将<deviceEffects>节点中的配置保存到mDeviceEffects集合中,将<preprocess>节点中的配置保存到mInputSources集合,将<postprocess>节点中的配置保存到mOutputStreams集合中。
然后会调用initDefaultDeviceEffects()函数,通知AudioFlinger进行Device音效绑定。在该函数中,会为每个待绑定的音效算法,创建一个AudioEffect.cpp对象,并将sessionID设置为AUDIO_SESSION_DEVICE,将待绑定的DeviceType设置到AudioEffect对象中。然后调用AudioEffect->setEnabled(true)函数。这样做之后,AudioEffect对象在它的初始化时就会通知AudioFlinger绑定Device音效。以下是代码调用流程:
AudioPolicyEffects.cpp->initDefaultDeviceEffects()//绑定Device音效。为每个Device对应的所有Effect,都分别创建一个包名为android的客户端AudioEffect对象。并初始化它。
|->AudioEffect.cpp->set(AUDIO_SESSION_DEVICE)
|->AudioFlinger.cpp->createEffect()//Binder跨进程调用
|->DeviceEffectManager.cpp->AudioFlinger::DeviceEffectManager::createEffect_l()
|->new DeviceEffectProxy()//从mDeviceEffects列表中找不到此音效时,新创建一个。
|->new EffectHandle()//mEffect引用的是DeviceEffectProxy对象
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::init()
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::onCreatePatch()
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::checkPort()//为当前Device绑定音效
|->AudioEffect.cpp->setEnabled(true) 从上面的代码流程可以看出,AudioFlinger通过自己的成员变量DeviceEffectManager创建了一个DeviceEffectProxy对象。而实现Device音效绑定的地方,是在DeviceEffectProxy::checkPort()函数中。这个函数为Device音效实现了两种绑定方式:
- 一种是让AudioHAL进程中的DeviceHAL直接处理音效数据。通过调用audio.h->audio_hw_device_t.add_device_effect(audio_port_handle_t device, effect_handle_t effect)接口实现。这种方式在音效算法处理过程中,就不会出现跨进程调用和共享内存创建的情况了。也就是说会由AudioHAL进程处理音效算法生成的数据,而不是AudioFlinger处理。AudioFlinger只负责控制音效算法的参数。
- 另一种方法是找到这个Device对应的PlaybackThread,由PlaybackThread去创建EffectModule对象,并插入到AUDIO_SESSION_DEVICE这个sessionId对应的EffectChain中,最终由PlaybackThread在传输音频数据时调用EffectChain->process_l()函数去处理音效算法生成的数据。也就是说由AudioServer进程负责处理音效数据。这种方式会出现跨进程调用和额外的共享内存创建。
4.1 DeviceHAL处理音效数据的方式
采用这种方式,加载的音效算法必须声明为前处理音效类型(EFFECT_FLAG_TYPE_PRE_PROC)或后处理音效类型(EFFECT_FLAG_TYPE_POST_PROC)。并且声明EFFECT_FLAG_HW_ACC_TUNNEL这个flag。它们都是通过在音效算法的实现代码中,设置effect_descriptor_t->flags来声明的。
在DeviceEffectProxy::checkPort()函数中,判断待绑定的音效算法如果包含EFFECT_FLAG_HW_ACC_TUNNEL flag,就会新创建一个EffectModule对象,将其保存到自己的DeviceEffectProxy::mHalEffect变量中。
下面我们看看AudioEffect.cpp->setEnabled(true)函数做了什么事?
AudioPolicyEffects.cpp->initDefaultDeviceEffects()
|->AudioEffect.cpp->setEnabled(true)
|->Effects.cpp->AudioFlinger::EffectHandle::enable()//对应的是DeviceEffectProxy
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::setEnabled()
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled()//执行的是DeviceEffectProxy对象的方法
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled_l()//mState = STARTING,设置的是DeviceEffectProxy对象状态
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::ProxyCallback::onEffectEnable(sp<EffectBase>& effectBase)//传入的是DeviceEffectProxy对象,所以直接返回null
|->Effects.cpp->AudioFlinger::EffectHandle::enable()//执行的DeviceEffectProxy的mEffectHandles集合中保存的EffectHandle对象,对应的是EffectModule对象
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled()//执行的是EffectModule对象的方法
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled_l()//mState = STARTING,设置的是EffectModule对象状态
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::ProxyCallback::onEffectEnable(sp<EffectBase>& effectBase)传入的是EffectModule对象
|->Effects.cpp->AudioFlinger::EffectModule::start()
|->Effects.cpp->AudioFlinger::EffectModule::start_l()
|->EffectHalHidl.cpp->command(EFFECT_CMD_ENABLE)//通知EffectHAL层enable
|->Effects.cpp->AudioFlinger::EffectModule::addEffectToHal_l()//只有EFFECT_FLAG_TYPE_PRE_PROC或EFFECT_FLAG_TYPE_POST_PROC才执行下面的代码
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::ProxyCallback::addEffectToHal()
|->Effects.cpp->AudioFlinger::DeviceEffectProxy::addEffectToHal()
|->DeviceEffectManager.h->DeviceEffectManagerCallback::addEffectToHal()
|->DeviceEffectManager.h->DeviceEffectManager::addEffectToHal()
|->AudioFlinger.cpp->addEffectToHal()
|->DeviceHalHidl.cpp->addDeviceEffect()
|->Device.cpp->addDeviceEffect()//Binder跨进程调用
|->EffectMap.cpp->EffectMap::getInstance().get(effectId)//源码在/hardware/interfaces/audio/common/all-versions/default/目录
|->audio.h->audio_hw_device_t.add_device_effect() 从上面这份代码调用流程可以看出,Effects.cpp文件中Effect和Callback之间的嵌套关系还是挺深的,最终通过层层调用,终于调用到了audio.h->audio_hw_device_t.add_device_effect(audio_port_handle_t device, effect_handle_t effect)接口。成功将此音效算法的effect_handle_t 句柄传递给DeviceHAL的audio_hw_device_t进行关联绑定。
4.2 AudioFlinger处理音效数据的方式
在DeviceEffectProxy::checkPort()函数中,会通过PatchPanel::Patch对象,找到需要绑定音效的Device对应的PlaybackThread,然后调用createEffect_l(AUDIO_SESSION_DEVICE)函数,进行音效加载。
Effects.cpp->AudioFlinger::DeviceEffectProxy::checkPort()
|->Threads.cpp->AudioFlinger::ThreadBase::createEffect_l(AUDIO_SESSION_DEVICE)
|->Threads.cpp->AudioFlinger::PlaybackThread::checkEffectCompatibility_l()//FAST线程要求AUDIO_SESSION_DEVICE只能应用EFFECT_FLAG_TYPE_POST_PROC音效。
|->new EffectChain()
|->Threads.cpp->AudioFlinger::PlaybackThread::addEffectChain_l()//初始化EffectChain
|->EffectsFactoryHalHidl.cpp->mirrorBuffer()
|->EffectBufferHalHidl.cpp->mirror()//创建共享内存,mExternalData指向的是PlaybackThread的mEffectBuffer
|->halOutBuffer = halInBuffer;//输入和输出共享内存都指向的是mEffectBuffer
|->Effects.h->EffectChain::setInBuffer(halInBuffer)
|->Effects.h->EffectChain::setOutBuffer(halOutBuffer)
|->mEffectChains.insertAt(chain, i)//按照sessionId从大到小插入。全局session都是负数,所以在最后。顺序:track-EffectChain、MIX-EffectChain、STAGE-EffectChain、DEVICE-EffectChain
|->Effects.cpp->AudioFlinger::EffectChain::createEffect_l()//创建EffectModule
|->new EffectModule()
|->Effects.cpp->AudioFlinger::EffectChain::EffectCallback::createEffectHal()
|->EffectsFactoryHalHidl.cpp->createEffect()//通知EffectHAL去创建真正的音效算法对象
|->Effects.cpp->AudioFlinger::EffectChain::addEffect_ll(){
effect->setInBuffer(mInBuffer);
if (idx_insert == previousSize) {
if (idx_insert != 0) {
mEffects[idx_insert-1]->setOutBuffer(mInBuffer);
}
effect->setOutBuffer(mOutBuffer);
} else {
effect->setOutBuffer(mInBuffer);
}
}从上面的调用代码流程可以看出,在PlaybackThread中新创建了一个EffectChain,并创建了EffectChain的输入和输出共享内存块,它们都指向的是mEffectBuffer本地内存块。而此EffectChain中包含的所有EffectModule对象,它们的输入和输出共享内存块都使用的是EffectChain的输入内存块,只有最后一个EffectModule的输出内存块使用的是EffectChain的输出内存块。但是AUDIO_SESSION_DEVICE对应的这个EffectChain在创建共享内存块时,输入和输出是同一个,所以,也就无所谓了。以下是音频数据传输流程图:

五、Stream音效的绑定过程
Stream音效的绑定方式,也支持两种。一种是在audio_effects.xml文件的<postprocess>节点中申明,这样AudioPolicyEffects模块解析后就会将配置信息保存到mOutputStreams集合中。
另一种动态绑定的方式,是通过创建StreamDefaultEffect.java对象,并在该类的构造函数中指定待绑定音效的TypeUUID、UUID、AudioAttributes.Usage。在其构造函数中,会通过层层调用,最终调用到AudioPolicyEffects的addStreamDefaultEffect()函数,AudioPolicyEffects就会通过AudioPolicyManager查找AudioAttributes.Usage对应的StreamType,然后根据UUID从EffectHAL中找到对应的音效描述对象effect_descriptor_t。最终将StreamType和effect_descriptor_t一起保存到mOutputStreams集合中。
下面看一下AudioPolicyEffects如何通过mOutputStreams集合来进行Stream音效绑定的。
在AudioTrack.java的play()函数中,会调用到PlaybackThread的addTrack_l()函数,addTrack_l()函数又会调用到AudioPolicyService::startOutput()函数,startOutput()函数最终会调用到AudioPolicyEffects::addOutputSessionEffects()函数。所以,进行绑定的是addOutputSessionEffects()函数。
AudioTrack.java->play()
|->Threads.cpp->AudioFlinger::PlaybackThread::addTrack_l()
|->AudioPolicyInterfaceImpl.cpp->AudioPolicyService::startOutput()
|->AudioPolicyEffects.cpp->AudioPolicyEffects::addOutputSessionEffects(
audio_io_handle_t output,
audio_stream_type_t stream,
audio_session_t audioSession)
|->new AudioEffect()
|->AudioEffect.cpp->set()
|->AudioPolicyEffects.cpp->AudioPolicyEffects::EffectVector::setProcessorEnabled(true)
|->AudioEffect.cpp->setEnabled(true)
|->Effects.cpp->AudioFlinger::EffectBase::setEnabled_l()//mState = STARTING
addOutputSessionEffects()函数中传入的三个参数,分别是此AudioTrack对应的PlaybackThread的Id(output)、此AudioTrack对应的StreamType(stream)、此AudioTrack的seesionId(audioSession)。这样,addOutputSessionEffects()函数就可以根据StreamType从mOutputStreams集合中找到它需要绑定的音效算法描述对象effect_descriptor_t,也就找到了音效算法的UUID。然后addOutputSessionEffects()函数会创建一个AudioEffect.cpp对象,并向该对象指定Effect的UUID和AudioTrack的seesionId。
可以看出,Android绑定Stream音效的方法和绑定Track音效没有区别。即:在此StreamType对应的每个AudioTrack准备播放时,为它们关联的seesionId都新创建一个AudioEffect。
之所以这样设计,我认为的原因是同一种StreamType对应的多个AudioTrack,可以指定到不同的PlaybackThread中去处理,这样两个AudioTrack就没法放在同一个线程对应的mEffectBuffer内存块中去处理了。
从上面可以看出,Stream音效严格意义来说其实是StreamType音效。它并不是直接绑定到一个StreamOut流中的。
<preprocess>节点的绑定过程类似,这里就不再赘述了。
六、StreamHAL处理音效数据的方式
当我查看/hardware/libhardware/include/hardware/audio.h接口文件时,发现audio_stream_t结构体定义了一个函数:audio_stream_t->add_audio_effect(effect_handle_t effect)。意思是可以为StreamOut流绑定音效?即:像DeviceHAL处理音效数据那样,让StreamHAL直接处理音效数据,不进行共享内存的创建和搬运?答案是肯定的。但是,当我下面分析完AudioFlinger中的设置流程后,我们就会发现,这个流程设计的很不合理,而且有漏洞。如果我理解的不对,欢迎各位指正!
如果想让一个音效算法绑定到StreamHAL中处理。只需在自己的音效算法中声明为前处理音效类型(EFFECT_FLAG_TYPE_PRE_PROC)或后处理音效类型(EFFECT_FLAG_TYPE_POST_PROC)就可以了。AudioFlinger最终就会调用到StreamHAL层的audio_stream_t->add_audio_effect(effect_handle_t effect)接口进行绑定。
AudioFlinger模块调用的入口是在PlaybackThread的音频数据处理函数threadLoop()中。即播放线程的循环执行函数中。
AudioFlinger::PlaybackThread::threadLoop()
|->Effects.cpp->AudioFlinger::EffectChain::process_l()
|->Effects.cpp->AudioFlinger::EffectModule::process()
|->Effects.h->EffectBase::isProcessImplemented()//判断effect_descriptor_t->flags是否包含EFFECT_FLAG_NO_PROCESS
|->Effects.cpp->AudioFlinger::EffectModule::updateState()
|->Effects.cpp->AudioFlinger::EffectModule::start_l()
|->AudioFlinger::EffectModule::addEffectToHal_l()//只有EFFECT_FLAG_TYPE_PRE_PROC或EFFECT_FLAG_TYPE_POST_PROC才执行下面的代码
|->AudioFlinger::EffectChain::EffectCallback::addEffectToHal()
|->StreamHalHidl.cpp->addEffect()
|->Stream.cpp->addEffect(effectId)//Binder跨进程调用
|->EffectMap.cpp->EffectMap::getInstance().get(effectId)//源码在/hardware/interfaces/audio/common/all-versions/default/目录
|->audio.h->audio_stream_t.add_audio_effect()
从上面的代码流程可以看出,EffectModule在它的start_l()函数中,会调用StreamHAL的绑定接口。是否调用的唯一判断条件就是该音效算法是否声明了前处理音效类型(EFFECT_FLAG_TYPE_PRE_PROC)或后处理音效类型(EFFECT_FLAG_TYPE_POST_PROC)。
只要音效算法申明了,就会进行绑定。根本不管此音效算法关联的seesionId是什么类型,也就是说关联到AudioTrack sessionId、AUDIO_SESSION_OUTPUT_MIX、AUDIO_SESSION_OUTPUT_STAGE,都可以。
只有AUDIO_SESSION_DEVICE不行,因为AUDIO_SESSION_DEVICE对应的EffectModule,它的EffectModule::mCallback变量指向的是DeviceEffectProxy::ProxyCallback,而不是EffectChain::EffectCallback,所以最终绑定到的是DeviceHAL。
这样简单粗暴的设计,我能想到的漏洞有两个:
- 同一个StreamHAL,会绑定多次相同类型的音效算法。比如我在同一个PlaybackThread中被处理的AudioTrack1的sessonId1中绑定了低音增强算法,在AudioTrack2的seesionId2中又绑定了低音增强算法。它们两个算法的UUID完全一样,但会有两个不同的EffectModule对象,所以最终audio_stream_t->add_audio_effect(effect_handle_t effect)接口会被执行两次。而且effect_handle_t的句柄是不相同的对象。补救办法是修改/hardware/interfaces/audio/core/all-versions/default/Stream.cpp->addEffect()函数。增加一个相同算法UUID的判断,同一个UUID的音效算法如果已绑定过,就不再调用audio_stream_t->add_audio_effect(effect_handle_t effect)接口。
- AudioFlinger和StreamHAL会同时处理音效数据。因为在EffectModule::process()函数中,没有进行音效处理类型(EFFECT_FLAG_TYPE_PRE_PROC或EFFECT_FLAG_TYPE_POST_PROC)的判断,只判断了此音效算法是否声明了EFFECT_FLAG_NO_PROCESS flag。只有声明了EFFECT_FLAG_NO_PROCESS flag,才不会处理音效数据。也就是说没有声明EFFECT_FLAG_NO_PROCESS flag的音效算法所生成的数据,会被AudioFlinger和StreamHAL同时处理。而Device音效不会出现这种情况的原因是绑定到DeviceHAL的EffectModule,它的mInBuffer和mOutBuffer都是null,即:没有创建共享内存数据。也就无法处理。补救办法有两种:一种是在音效算法的实现代码中声明一下EFFECT_FLAG_NO_PROCESS flag,但是需要确保SoC厂商实现的StreamHAL不会根据这个flag来判断是否让音效算法处理。另一种方法是修改EffectModule::process()函数,添加音效处理类型(EFFECT_FLAG_TYPE_PRE_PROC或EFFECT_FLAG_TYPE_POST_PROC)的判断,包含这两种flag的EffectModule,就不要通知音效算法处理数据了。
七、Track音效的绑定过程
通过前面的介绍,为一个AudioTrack绑定音效的方法,基本可以猜到了。只需执行两步:
- 创建一个AudioEffect.java对象。在其构造函数中,指定从AudioTrack.java->getAudioSessionId()获取到的AudioTrack sessionId、指定音效算法的UUID或TypeUUID。但是AudioEffect.java的构造函数是@hide类型的,不支持3rd APP调用。而Android将系统支持的音效算法都创建了一个java文件,比如BassBoost.java。这些音效类都是继承的AudioEffect.java。并默认将自己的TypeUUID指定到了AudioEffect.java父类中。所以,普通的3rd APP可以直接new BassBoost对象就可以了,只需指定seesionId。也就是说,普通的3rd APP无法绑定设备厂商自己扩展的音效算法类型。除非通过Java反射机制直接创建AudioEffect.java对象。
- 调用AudioEffect.java->setEnabled(true)函数,启动音效算法。
下面我以BassBoost低音增强算法举例,来看看它与AudioTrack的绑定过程。
new BassBoost(AudioTrackSessionId)
|->AudioEffect.java->AudioEffect(EFFECT_TYPE_BASS_BOOST,AudioTrackSessionId)
|->AudioEffect.java->native_setup()
|->android_media_AudioEffect.cpp->android_media_AudioEffect_native_setup()
|->new AudioEffect(attributionSource)
|->AudioEffect.cpp->set()
|->AudioFlinger.cpp->createEffect()//Binder跨进程调用
|->Threads.cpp->AudioFlinger::ThreadBase::createEffect_l()
|->Threads.cpp->AudioFlinger::PlaybackThread::checkEffectCompatibility_l()
|->Threads.cpp->AudioFlinger::PlaybackThread::addEffectChain_l()
|->EffectsFactoryHalHidl.cpp->mirrorBuffer()//mExternalData指向的是PlaybackThread的mEffectBuffer
|->halOutBuffer = halInBuffer
|->halInBuffer=EffectsFactoryHalHidl.cpp->allocateBuffer()//新创建共享内存块
|->PlaybackTracks.h->Track::setMainBuffer()//设置所有关联此seesionId的track的mMainBuffer,设置的是halInBuffer中的共享内存。
|->Effects.h->EffectChain::setInBuffer()
|->Effects.h->EffectChain::setOutBuffer()//halOutBuffer::mExternalData指向的是PlaybackThread的mEffectBuffer
|->Effects.cpp->AudioFlinger::EffectChain::createEffect_l()
|->Effects.cpp->AudioFlinger::EffectChain::addEffect_ll(){
effect->setInBuffer(mInBuffer);
if (idx_insert == previousSize) {
if (idx_insert != 0) {
mEffects[idx_insert-1]->setOutBuffer(mInBuffer);
}
effect->setOutBuffer(mOutBuffer);
} else {
effect->setOutBuffer(mInBuffer);
}
}执行完上面的代码流程后,AudioFlinger会为EffectChain创建一个新的输入共享内存块halInBuffer和输出共享内存块halOutBuffer。halOutBuffer的mExternalData指向的是PlaybackThread的mEffectBuffer。EffectChain中包含的所有EffectModule对象,它们的输入和输出共享内存块都使用的是EffectChain的输入内存块,只有最后一个EffectModule的输出内存块使用的是EffectChain的输出内存块。
绑定到该sessionId上的所有AudioTrack,它们的mMainBuffer全部指向的是EffectChain的输入共享内存halInBuffer。AudioMixer混音器处理完每个AudioTrack的数据后,会将数据拷贝到mMainBuffer指向的内存块中。
这样就成功建立了音频数据传输通道。以下是传输流程图:
那么,当有两个运行在不同PlaybackThread的AudioTrack,绑定到同一个sessionId上时,会如何处理呢?
比如我先创建一个AudioTrackA,它在DeepBuffer PlayackThread中运行。然后创建一个AudioEffect,将其绑定到TrackA-sessionId中。最后再创建一个AudioTrackB,让其运行在Primary PlaybackThread中,并将TrackA-sessionId指定给AudioTrackB。
这种情况,出现的结果是AudioEffect最终会被绑定到AudioTrackB上执行,AudioTrackA会被解绑掉此AudioEffect音效。关键的处理代码是在AudioFlinger创建AudioTrackB的函数AudioFlinger.cpp->createTrack()中。如下:
// move effect chain to this output thread if an effect on same session was waiting
// for a track to be created
if (lStatus == NO_ERROR && effectThread != NULL) {
// no risk of deadlock because AudioFlinger::mLock is held
Mutex::Autolock _dl(thread->mLock);
Mutex::Autolock _sl(effectThread->mLock);
if (moveEffectChain_l(sessionId, effectThread, thread) == NO_ERROR) {
effectThreadId = thread->id();
effectIds = thread->getEffectIds_l(sessionId);
}
}而AudioFlinger.cpp->moveEffectChain_l()函数最终会调用PlaybackThread::removeEffectChain_l()执行删除EffectChain的操作。代码如下:
size_t AudioFlinger::PlaybackThread::removeEffectChain_l(const sp<EffectChain>& chain)
{
audio_session_t session = chain->sessionId();
ALOGV("removeEffectChain_l() %p from thread %p for session %d", chain.get(), this, session);
for (size_t i = 0; i < mEffectChains.size(); i++) {
if (chain == mEffectChains[i]) {
mEffectChains.removeAt(i);
// detach all active tracks from the chain
for (const sp<Track> &track : mActiveTracks) {
if (session == track->sessionId()) {
ALOGV("removeEffectChain_l(): stopping track on chain %p for session Id: %d",
chain.get(), session);
chain->decActiveTrackCnt();
}
}
// detach all tracks with same session ID from this chain
for (size_t i = 0; i < mTracks.size(); ++i) {
sp<Track> track = mTracks[i];
if (session == track->sessionId()) {
track->setMainBuffer(reinterpret_cast<effect_buffer_t*>(mSinkBuffer));
chain->decTrackCnt();
}
}
break;
}
}
return mEffectChains.size();
}可以从上面的代码看到,PlaybackThread删除了AudioTrackA关联的所有音效,并将AudioTrackA的mainBuffer指向了mSinkBuffer。
八、Aux音效的绑定过程
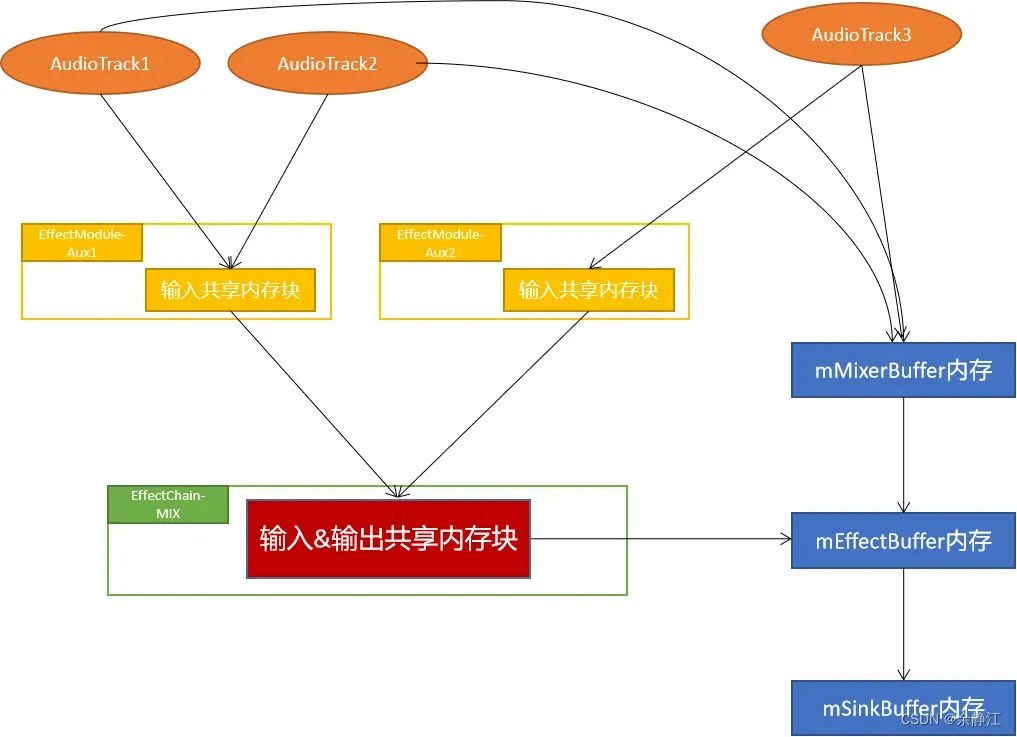
Android中支持AudioTrack绑定一个Aux音效(auxiliary effect),当AudioTrack绑定了Aux音效后,AudioMixer混音器在处理音频数据时,就会将AudioTrack的数据拷贝两份,一份拷贝到它绑定的普通Track音效中处理,另一份拷贝到Aux音效中处理,最后由PlaybackThread进行合并。我认为这是Android的一个Bug,因为源码中,编写Threads.cpp代码的人在AudioTrack绑定到普通Track音效时,会禁用掉它绑定的Aux音效。但是写Effects.cpp代码的人在音效禁用的实现函数中,又明确不禁用Aux音效。所以,最终其实是没有禁用,导致普通Track音效和Aux音效可以同时处理同一个AudioTrack的数据。下面我会详细说明代码逻辑。
定义为Aux音效的算法,必须申明EFFECT_FLAG_TYPE_AUXILIARY flag。否则无法被当做Aux音效绑定给AudioTrack使用。
所有Aux音效的EffectModule都会被放入到MIX sessionId的EffectChain中。也就是说Aux音效只能关联到AUDIO_SESSION_OUTPUT_MIX中。并且MIX sessionId也只能关联Aux音效。
绑定Aux音效的方法,主要分为四步:
- 创建一个Aux音效的控制对象AudioEffect,指定sessionId为AUDIO_SESSION_OUTPUT_MIX。需要APP拥有”android.permission.MODIFY_AUDIO_SETTINGS”权限。
- 启动Aux音效:调用AudioEffect.java->setEnabled(true)接口。
- 为AudioTrack绑定音效:调用AudioTrack.java->attachAuxEffect(int effectId)接口。其中的入参effectId可以通过AudioEffect.java->getId()函数获取到。一个AudioTrack只能绑定一个Aux音效。如果需要取消绑定,在AudioTrack.java->attachAuxEffect(int effectId)函数中传入0即可。
- 设置Aux音效处理的数据音量大小,默认是0,也就是Aux音效不会处理数据。通过调用AudioTrack.java->setAuxEffectSendLevel(float level)接口设置。
以下是Aux音效的数据传输流程图:
下面我以EnvironmentalReverb为例,分析下Aux音效的创建流程。
//创建Aux音效
new EnvironmentalReverb(AUDIO_SESSION_OUTPUT_MIX)
|->AudioEffect.java->AudioEffect(EFFECT_TYPE_ENV_REVERB,AUDIO_SESSION_OUTPUT_MIX)
|->AudioFlinger.cpp->createEffect()//Binder跨进程调用
|->ServiceUtilities.cpp->settingsAllowed()//将Effect绑定到MIX SessionId时,需要APP拥有"android.permission.MODIFY_AUDIO_SETTINGS"权限。没有声明此权限就会直接返回。
|->AudioFlinger.cpp->getEffectDescriptor(uuid,type,EFFECT_FLAG_TYPE_AUXILIARY)//找到声明了EFFECT_FLAG_TYPE_AUXILIARY标识的音效描述对象,没有声明的就会直接返回。
|->AudioSystem.cpp->getOutputForEffect(effect_descriptor_t)//为此音效找到合适的PlaybackThreadId
|->AudioPolicyIntefaceImpl.cpp->AudioPolicyService::getOutputForEffect()
|->AudioPolicyManager.cpp->getOutputForEffect()
|->AudioPolicyManager.cpp->selectOutputForMusicEffects()//查找outputstream的逻辑是先找到STRATEGY_MEDIA现在对应的播放Device,再根据Device找到可播放到该Device的outputStream。有多个outputStream时,按照以下顺序返回:1: An offloaded output. 2: A deep buffer output 3: The primary output 4: the first output in the list
|->Engine.cpp->getOutputDevicesForAttributes(AUDIO_USAGE_MEDIA)
|->mEffects.moveEffects(AUDIO_SESSION_OUTPUT_MIX, mMusicEffectOutput, output);
|->AudioPolicyClientImpl.cpp->AudioPolicyService::AudioPolicyClient::moveEffects(AUDIO_SESSION_OUTPUT_MIX, mMusicEffectOutput, output)
|->AudioFlinger.cpp->moveEffects()
|->AudioFlinger.cpp->moveEffectChain_l(AUDIO_SESSION_OUTPUT_MIX,srcThread,dstThread)//通知AudioFlinger,将AUDIO_SESSION_OUTPUT_MIX对应的EffectChain,从旧的PlaybackThread移动到指定的PlaybackThread中。
|->Threads.cpp->AudioFlinger::ThreadBase::createEffect_l()
|->Threads.cpp->AudioFlinger::PlaybackThread::addEffectChain_l()
|->EffectsFactoryHalHidl.cpp->mirrorBuffer(&halInBuffer)//mExternalData指向的是PlaybackThread的mEffectBuffer
|->halOutBuffer = halInBuffer;
|->Effects.h->EffectChain::setInBuffer(halInBuffer)
|->Effects.h->EffectChain::setOutBuffer(halOutBuffer)
|->Threads.cpp->AudioFlinger::ThreadBase::checkSuspendOnAddEffectChain_l(chain)//检查一下自己这个EffectChain对应的sessionId是否被禁用音效了
|->Effects.cpp->AudioFlinger::EffectChain::createEffect_l()
|->Effects.cpp->AudioFlinger::EffectChain::addEffect_ll(){
mEffects.insertAt(effect, 0);//每次都将新添加的Aux音效插入到队列的最前面。
EffectsFactoryHalHidl.cpp->allocateBuffer(halBuffer)//新创建一块共享内存
effect->setInBuffer(halBuffer);
effect->setOutBuffer(mInBuffer);
}从上面的代码调用流程中可以看出,与Track音效的创建流程主要有三点不同。
一个是创建Aux音效时,AudioFlinger会从AudioPolicyManager那里查询出一个合适的PlaybackThread去绑定。因为此Aux音效对应的是全局MIX-sessionId,而不是像Track音效那样对应的是Track-sessionId,这样就无法根据具体的Track对象找到它关联的PlaybackThread了。
AudioPolicyManager返回的是MUSIC streamType对应的PlaybackThread。等到有AudioTrack绑定此Aux音效时,AudioFlinger会将此Aux音效的EffectModule移动到AudioTrack对应的PlaybackThread中。
第二点不同是创建的音效共享内存块不同。AudioFlinger会为每个Aux音效都新创建一个输入共享内存块。然后将Aux音效的输出内存指向EffectChain-MIX的输入\输出共享内存块。因为EffectChain-MIX的输入内存块与输出内存块是同一个。
第三点不同是AudioFlinger会限制MIX sessionId对应的EffectChain只能存在一个PlaybackThread中。即:MIXsessionId-EffectChain是全局唯一的。也就是说所有的Aux音效,只能在同一个PlaybackThread中处理。以下是相关限制的代码,在AudioFlinger.cpp->createEffect()函数中。
} else if (checkPlaybackThread_l(io) != nullptr
&& sessionId != AUDIO_SESSION_OUTPUT_STAGE) {
// allow only one effect chain per sessionId on mPlaybackThreads.
for (size_t i = 0; i < mPlaybackThreads.size(); i++) {
const audio_io_handle_t checkIo = mPlaybackThreads.keyAt(i);
if (io == checkIo) {
if (hapticPlaybackRequired
&& mPlaybackThreads.valueAt(i)
->hapticChannelMask() == AUDIO_CHANNEL_NONE) {
ALOGE("%s: haptic playback thread is required while the required playback "
"thread(io=%d) doesn't support", __func__, (int)io);
lStatus = BAD_VALUE;
goto Exit;
}
continue;
}
const uint32_t sessionType =
mPlaybackThreads.valueAt(i)->hasAudioSession(sessionId);
if ((sessionType & ThreadBase::EFFECT_SESSION) != 0) {
ALOGE("%s: effect %s io %d denied because session %d effect exists on io %d",
__func__, descOut.name, (int) io, (int) sessionId, (int) checkIo);
android_errorWriteLog(0x534e4554, "123237974");
lStatus = BAD_VALUE;
goto Exit;
}
}
}下面看一下Aux音效的绑定流程:
//绑定Aux音效
AudioTrack.java->attachAuxEffect(int effectId)
AudioTrack.cpp->attachAuxEffect()
Tracks.cpp->AudioFlinger::TrackHandle::attachAuxEffect()
Tracks.cpp->AudioFlinger::PlaybackThread::Track::attachAuxEffect()
AudioFlinger.cpp->moveAuxEffectToIo(EffectId,dstThread)//只将此EffectModule从原来PlaybackThread-MIXsessionId-EffectChain中移动到此AudioTrack运行的PlaybackThread的MIXsessionId-EffectChain中。此时就会有两个MIXsessionId-EffectChain
Threads.cpp->AudioFlinger::PlaybackThread::attachAuxEffect()
Tracks.cpp->AudioFlinger::PlaybackThread::Track::setAuxBuffer(effect->inBuffer())//将此AudioTrack的AuxBuffer指向EffectModule的输入共享内存块。
从上面的代码可以看出,AudioFlinger将Track的mAuxBuffer指针指向了Aux音效的输入共享内存块。同时,会将Aux音效EffectModule移动到此AudioTrack对应的PlaybackThread中。
我认为Aux音效绑定流程这样设计会存在漏洞。它假设了一个前提,所有使用Aux音效的AudioTrack都是Music StreamType类型的。因为Music StreamType类型的AudioTrack在创建时,AudioPolicyManager会将其强制绑定到DeepBuffer PlaybackThread中(AudioPolicyManager.cpp->selectOutputForMusicEffects()函数)。所以,根本不会出现Aux音效的移动。因为所有Music AudioTrack都在DeepBuffer PlaybackThread中,而所有Aux音效在创建时也都在DeepBuffer PlaybackThread中。因为Aux音效的AudioEffect在创建时,AudioPolicyManger为它选择的也是DeepBuffer PlaybackThread(AudioPolicyManager.cpp->selectOutputForMusicEffects()函数)。
实际上,Aux音效一般也确实是为Music StreamType场景服务的,这里的场景包括音乐播放、视频播放、游戏播放。
但是,假设已经有一个Music StreamType的AudioTrack绑定到了此Aux音效上,它运行在DeepBuffer PlaybackThread中。现在我们再强制创建一个System StreamType的audioTrack,让其运行在Primary PlaybackThread中,然后也绑定这个Aux音效,就会导致移动产生,EffectModule从DeepBuffer Thread移动到Primary Thread,对应MIX sessionId的EffectChain也移动到了Primary Thread。而之前Music StreamType的AudioTrack就会被解绑此Aux音效,而没有Aux音效处理了。如果此后再新创建一个Aux音效,比如new PresetReverb()对象,AudioFlinger在createEffect()函数中,又会从AudioPolicyManger那获取到DeepBuffer PlaybackThread,然后进行绑定,但是在AudioFlinger.cpp->createEffect()函数中限制了MIX sessionId对应的EffectChain只能存在一个PlaybackThread中(上面第三点),导致PresetReverb音效创建失败了。也就是说后面创建的Aux音效全部会失败,再也无法创建Aux音效。
所以,我认为Android设计的绑定Aux音效流程有漏洞。我觉得简单的修改方法是既然设计者想让MIX sessionId只绑定Aux音效,并且MIX sessionId对应的EffectChain是全局唯一的。那就不如直接new一个EffectChain,绑定到MIX sessionId,然后将这个EffectChain作为AudioFlinger的成员变量保存住。DeepBuffer类型的PlaybackThread在操作Aux音效时,直接从AudioFlinger的成员变量EffectChain中获取,没有必要在各个类型的PlaybackThread之间移动EffectChain对象了。
下面我们再来看一下我发现的另外一个Bug,也就是章节最开始提到的:当有普通Track音效启动,会禁用Aux音效,但是却禁用失败的问题。
我们看一下普通Track音效的启动流程,在AudioEffect.cpp->setEnabled(true)函数中。
//Track音效启动
AudioEffect.cpp->setEnabled(true)
Effects.cpp->AudioFlinger::EffectHandle::enable()
Effects.cpp->AudioFlinger::EffectChain::EffectCallback::checkSuspendOnEffectEnabled(true)
Threads.cpp->AudioFlinger::ThreadBase::checkSuspendOnEffectEnabled(enabled, effect->sessionId())
Threads.cpp->AudioFlinger::ThreadBase::setEffectSuspended_l(NULL, enabled, AUDIO_SESSION_OUTPUT_MIX)//当enable的是Track音效时,通知AUDIO_SESSION_OUTPUT_MIX对应的EffectChain禁用!
Effects.cpp->AudioFlinger::EffectChain::setEffectSuspendedAll_l(true)
desc = new SuspendedEffectDesc();
mSuspendedEffects.add((int)kKeyForSuspendAll, desc);
Effects.cpp->AudioFlinger::EffectChain::getSuspendEligibleEffects()
Effects.cpp->AudioFlinger::EffectChain::isEffectEligibleForSuspend()//绑定到AUDIO_SESSION_OUTPUT_MIX中的Aux音效不会被禁用,直接返回了!
Threads.cpp->AudioFlinger::ThreadBase::updateSuspendedSessions_l(NULL, true, AUDIO_SESSION_OUTPUT_MIX)//向mSuspendedSessions集合中添加kKeyForSuspendAll。SuspendedSessionDesc.mType=0
desc = new SuspendedSessionDesc()//SuspendedSessionDesc.mType=0
sessionEffects.add(kKeyForSuspendAll, desc);
mSuspendedSessions.replaceValueFor(sessionId, sessionEffects)上面代码流程中两个关键的函数是Threads.cpp->AudioFlinger::ThreadBase::checkSuspendOnEffectEnabled(enabled, effect->sessionId())和Effects.cpp->AudioFlinger::EffectChain::isEffectEligibleForSuspend()。以下是这两个函数的关键代码:
void AudioFlinger::ThreadBase::checkSuspendOnEffectEnabled(bool enabled,
audio_session_t sessionId,
bool threadLocked) {
if (mType != RECORD) {
// suspend all effects in AUDIO_SESSION_OUTPUT_MIX when enabling any effect on
// another session. This gives the priority to well behaved effect control panels
// and applications not using global effects.
// Enabling post processing in AUDIO_SESSION_OUTPUT_STAGE session does not affect
// global effects
if (!audio_is_global_session(sessionId)) {
setEffectSuspended_l(NULL, enabled, AUDIO_SESSION_OUTPUT_MIX);
}
}
}
bool AudioFlinger::EffectChain::isEffectEligibleForSuspend(const effect_descriptor_t& desc)
{
// auxiliary effects and visualizer are never suspended on output mix
if ((mSessionId == AUDIO_SESSION_OUTPUT_MIX) &&
(((desc.flags & EFFECT_FLAG_TYPE_MASK) == EFFECT_FLAG_TYPE_AUXILIARY) ||
(memcmp(&desc.type, SL_IID_VISUALIZATION, sizeof(effect_uuid_t)) == 0) ||
(memcmp(&desc.type, SL_IID_VOLUME, sizeof(effect_uuid_t)) == 0) ||
(memcmp(&desc.type, SL_IID_DYNAMICSPROCESSING, sizeof(effect_uuid_t)) == 0))) {
return false;
}
return true;
}也就是说,在PlaybackThread中,发现有Track音效启动后,就会通知MIX sessionId的EffectChain去禁用掉它里面的所有Aux音效。并且还增加了注释来说明禁用的原因:
// suspend all effects in AUDIO_SESSION_OUTPUT_MIX when enabling any effect on
// another session. This gives the priority to well behaved effect control panels
// and applications not using global effects.
// Enabling post processing in AUDIO_SESSION_OUTPUT_STAGE session does not affect
// global effects
而EffectChain在执行禁用操作时,却专门增加了判断,如果是请求禁用MIX sessionID对应的Aux音效,不处理!并且也专门增加了注释说明这一点:
// auxiliary effects and visualizer are never suspended on output mix
所以,最终的结果是一个AudioTrack可以同时绑定Track音效和Aux音效。
九、所有音效处理的数据传输流程图

以上是所有音效类型处理时的数据传输流程图,其中没有包含AUDIO_SESSION_OUTPUT_STAGE的处理,目前AUDIO_SESSION_OUTPUT_STAGE只会与空间音频(Spatializer)关联使用,待我写空间音频的框架设计时,进行说明。
版权声明:本文为博主作者:余静江原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_41004543/article/details/133707142