类对象模型
- 前言
- 一、如何计算类对象的大小
-
- 问题
- 二、类对象的存储方式猜测
-
- 对象中包含类的各个成员
- 代码只保存一份,在对象中保存存放代码的地址
- 只保存成员变量,成员函数存放在公共的代码段
- 问题
- 总结
- 三、结构体内存对齐规则
- 四、例题
-
- 结构体怎么对齐? 为什么要进行内存对齐?
- 如何让结构体按照指定的对齐参数进行对齐?能否按照3、4、5即任意字节对齐?
- 什么是大小端?如何测试某台机器是大端还是小端,有没有遇到过要考虑大小端的场景
前言
类对象模型是一种编程概念,用于描述和实现面向对象编程(OOP)中的类和对象。在这个模型中,类定义了对象的结构和行为,包括数据成员(属性)和成员函数(方法)。对象是类的实例,具有类的所有属性和方法。类对象模型支持封装、继承和多态等OOP特性,使得代码更加模块化、可重用和易于维护。通过类对象模型,程序员可以创建复杂的软件系统,提高开发效率和代码质量。
一、如何计算类对象的大小
在C++中,可以使用sizeof运算符来计算类对象的大小。sizeof运算符返回指定类型或对象的大小(以字节为单位)。以下是计算类对象大小的示例代码:
#include <iostream>
class MyClass {
int x;
double y;
char z;
};
int main() {
MyClass myObject;
size_t size = sizeof(myObject);
std::cout << "对象的大小为:" << size << " 字节" << std::endl;
return 0;
}
在这个示例中,我们定义了一个名为MyClass的类,它拥有一个int类型的成员变量x,一个double类型的成员变量y,以及一个char类型的成员变量z。然后,我们创建一个名为myObject的对象,并使用sizeof运算符计算myObject对象的大小。最后,将计算出的大小输出到控制台。
需要注意的是,sizeof运算符计算的是对象的静态大小,即编译时确定的对象的大小。它不包括动态分配的内存和对象引用的其他对象的内存。另外,sizeof运算符返回的大小是以字节为单位的无符号整数型,可以使用size_t类型来接收结果。
问题
class A
{
public:
void PrintA()
{
cout << _a << endl;
}
private:
char _a;
};
类中既可以有成员变量,又可以有成员函数,那么一个类的对象中包含了什么?如何计算一个类(含有成员变量和成员函数)的大小?
二、类对象的存储方式猜测
对象中包含类的各个成员
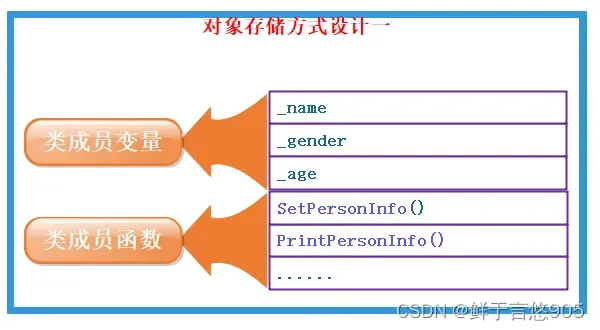
缺陷:每个对象中成员变量是不同的,但是调用同一份函数,如果按照此种方式存储,当一个类创建多个对象时,每个对象中都会保存一份代码,相同代码保存多次,浪费空间。那么如何解决呢?
代码只保存一份,在对象中保存存放代码的地址
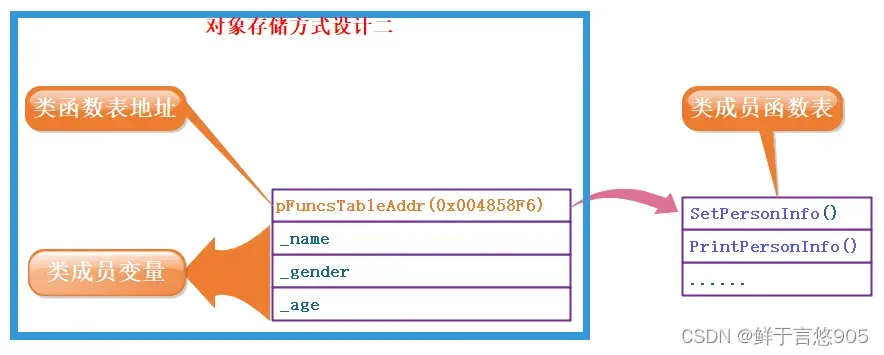
只保存成员变量,成员函数存放在公共的代码段
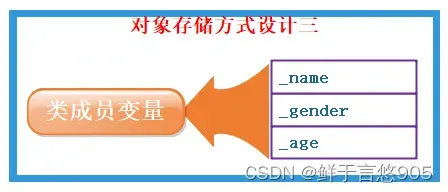
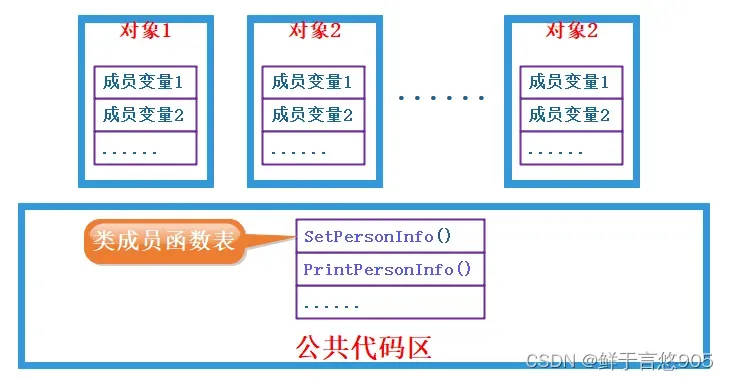
问题
对于上述三种存储方式,那计算机到底是按照那种方式来存储的?
我们再通过对下面的不同对象分别获取大小来分析看下
class A1 {
public:
void f1() {}
private:
int _a;
};
// 类中仅有成员函数
class A2 {
public:
void f2() {}
};
// 类中什么都没有---空类
class A3
{};
sizeof(A1) : ______ sizeof(A2) : ______ sizeof(A3) : ______
4 1 1
总结
-
类对象的存储方式是按照只保存成员变量,成员函数存放在公共的代码段
-
一个类的大小,实际就是该类中”成员变量”之和,须要注意内存对齐
-
注意空类的大小,空类比较特殊,编译器给了空类一个字节来唯一标识这个类的对象。
三、结构体内存对齐规则
结构体内存对齐是编译器为了提高执行效率和访问速度而进行的一种优化手段。
结构体内存对齐规则如下:
- 第一个成员在与结构体偏移量为0的地址处。
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
注意:对齐数 = 编译器默认的一个对齐数与该成员大小的较小值。
VS中默认的对齐数为8 - 结构体总大小为:最大对齐数(所有变量类型最大者与默认对齐参数取最小)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
为了满足这些对齐规则,编译器在结构体中可能会插入一些填充字节,以确保成员变量按照规则排列。
例如,考虑以下结构体:
struct example {
char c; // 1字节
int i; // 4字节
double d; // 8字节
};
根据对齐规则,编译器可能会在char c和int i之间插入3个填充字节,使得int类型的成员变量按照4字节对齐。同样地,在int i和double d之间可能会插入4个填充字节,使得double类型的成员变量按照8字节对齐。
因此,这个结构体的总大小可能是16字节。
需要注意的是,结构体对齐规则可能因编译器和编译选项的不同而有所不同,可以使用sizeof操作符来查看结构体的实际大小,也可以使用offsetof 计算结构体相较于起始位置的偏移量
四、例题
结构体怎么对齐? 为什么要进行内存对齐?
在C语言中,结构体是一种用户自定义的数据类型,它可以包含多个不同类型的数据成员。当结构体中的数据成员存储在内存中时,编译器会根据对齐规则对其进行对齐。
内存对齐是指将数据在内存中的地址对齐到特定的边界。对齐规则可以是不同的,但通常遵循以下原则:
-
数据类型对齐:基本数据类型如
int、float等有固定的对齐要求,通常是按照类型大小对齐。比如,int通常是按照4字节对齐,float按照4字节对齐。 -
结构体对齐:结构体的对齐方式是基于其最大成员的对齐要求。结构体的对齐要求是成员中对齐要求最高的,即按照最大成员的对齐要求进行对齐。不会计算结构体内存空间的可以看这篇文章——C语言从入门到实战——结构体与位段
内存对齐的目的主要有以下几点:
-
提高存取效率:对齐后的数据在读取和存储时速度更快,因为对齐的数据可以直接读到正确的内存地址,而非对不齐的数据可能会涉及额外的操作。
-
优化缓存性能:计算机内存通常按块存储,以缓存行为单位。对齐可以保证数据成员在同一缓存行中,减少缓存行的读取次数,提高缓存命中率。
-
兼容其他系统:在跨平台开发中,不同的硬件和操作系统可能对内存对齐有不同的要求。通过对齐,可以确保结构体在不同的系统上具有相同的内存布局,提高代码的可移植性。
需要注意的是,内存对齐可能会导致结构体的大小增加,因为编译器在成员之间插入填充字节以满足对齐要求。可以使用编译器的指令或者预处理指令来调整对齐方式,以优化内存使用。
如何让结构体按照指定的对齐参数进行对齐?能否按照3、4、5即任意字节对齐?
可以看下这篇文章C语言从入门到实战——结构体与位段
在C语言中,可以使用预处理指令#pragma pack(n)来指定对齐参数。n是对齐的字节数,可以是任意整数。
#pragma pack(3)
struct MyStruct {
// 结构体成员
};
上述代码表示将MyStruct结构体按照3字节对齐。
但是,C标准并没有规定任意字节对齐的方式。通常情况下,对齐参数是2的幂次方。如果需要非2的幂次方的对齐参数,则需要使用特定的编译器扩展或者特定的平台相关特性。
请注意,在设置自定义的对齐参数时,可能会导致不同平台上的兼容性问题,因为结构体的对齐方式由编译器和平台决定。
什么是大小端?如何测试某台机器是大端还是小端,有没有遇到过要考虑大小端的场景
C语言从入门到实战——数据在内存中的存储方式
大小端(Endianness)是一种描述数据存储方式的概念,用于表示一个多字节数据在内存中的存储顺序。在计算机系统中,多字节数据通常被分为若干个字节,而字节是由多个二进制位组成的。在大小端表示法中,主要考虑的是多字节数据的高位和低位的存储顺序。
大端(存储)模式:是指数据的低位字节内容保存在内存的高地址处,而数据的高位字节内容,保存在内存的低地址处。
小端(存储)模式:是指数据的低位字节内容保存在内存的低地址处,而数据的高位字节内容,保存在内存的高地址处。
为了测试某台机器是大端还是小端,可以通过以下方法之一:
- 使用C/C++等编程语言来测试,通过使用联合体(union)的方式来将一个整型数据与一个字符数组关联起来,并检查字符数组的存储顺序。如果数组的第一个字节是最低有效字节,则表示该机器是小端;如果数组的第一个字节是最高有效字节,则表示该机器是大端。
通过使用联合体(union)来将一个整型数据与一个字符数组关联起来,可以检查机器的字节序(即是小端还是大端)。
以下是使用C语言来实现的示例代码:
#include <stdio.h>
// 定义一个联合体,整型数据与字符数组共用同一块内存空间
union Data {
int i;
char c[sizeof(int)];
};
int main() {
union Data data;
// 将整型数据赋值
data.i = 1;
// 判断字节序
if (data.c[0] == 1) {
printf("This machine is little-endian.\n");
} else {
printf("This machine is big-endian.\n");
}
return 0;
}
运行以上代码时,将会输出机器的字节序信息。如果输出" This machine is little-endian.",表示该机器是小端;如果输出" This machine is big-endian.",表示该机器是大端。
注意:上述代码假设sizeof(int)等于4字节,如果在不同的机器上运行,可能会得到不同的结果,因为不同的机器有不同的字节序。
除此之外我们还可以使用指针来判断
#include <iostream>
using namespace std;
int main() {
int num = 1;
char *ptr = (char*)#
if (*ptr == 1) {
cout << "Little Endian" << endl;
} else {
cout << "Big Endian" << endl;
}
return 0;
}
- 使用系统命令或工具来查看机器的字节序。例如,在
Linux系统下可以使用以下命令:
$ lscpu | grep "Byte Order"
如果输出结果是 "Little Endian",则表示该机器是小端;如果输出结果是 "Big Endian",则表示该机器是大端。
在某些场景中,需要考虑大小端的情况,例如在网络传输中,如果通信双方使用的字节序不同,就需要进行字节序的转换。在跨平台数据传输或者数据持久化存储时,也需要考虑大小端的问题。
版权声明:本文为博主作者:鲜于言悠905原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/qq_74013365/article/details/137464795