水文频率计算的两个基本内容包括分布线型及参数估计。水文分析计算中使用的概率分布曲线俗称水文频率曲线,习惯上把由实测资料(样本)绘制的频率曲线称为经验频率曲线,而把由数学方程式所表示的频率曲线称为理论频率曲线。连续型随机变量的分布是以概率密度曲线和分布曲线来表示的,这些分布在数学上有很多的类型。我国工程水文学中常用的分布有正态分布、皮尔逊Ⅲ型分布以及对数正态分布等。
根据SL 44—2006《水利水电工程设计洪水计算规范》规定,频率曲线的线型一般选用皮尔逊Ⅲ型。
英国生物学家皮尔逊通过大量的分析研究,提出一种概括性的曲线族,包括13种分布曲线,其中第Ⅲ型被引入水文计算中,成为当前水文计算中常用的频率曲线。
皮尔逊第Ⅲ型曲线是一条一端有限,一端无线的不对称单峰的正偏的曲线,数学上称之为伽马分布,其概率密度函数为:
式中,Γ(α)为α的伽马函数;α,β,a0表征皮尔逊Ⅲ型分布的形状、尺度和位置的三个参数,α>0,β>0。
显然,参数α、β、a0一旦确定,该密度函数随之确定。可以证明,这三个函数与总体的三个统计参数
均值:
离差系数:
偏态系数:
具有下列关系:
水文计算中,一般需要推求指定频率P所对应的随机变量Xp,这要通过对密度曲线进行积分,求出等于或大于Xp的累积频率P值,即
但是由上式直接计算P非常麻烦,美国工程师福斯特通过变量转换,根据拟定的Cs值进行多次积分,并把结果制成专用表格(Φ值表),供水利工作者直接查用。引入变量:
则变量Φ的均值为0,均方差为1,水文学中称为离均系数。这样经过标准化变换后,原被积分的函数中就只含有一个待定参数Cs,即
根据估计的频率分布曲线和样本经验点据分布配合最佳来优选参数的方法叫做适线法(亦叫配线法)。该法自20世纪50年代开始即在我国水文频率计算中得到较为广泛应用,层次清楚,方法灵活,操作容易,目前已是我国水利水电工程设计洪水规范中规定的主要参数估计方法。它的实质是通过样本的经验分布去探求总体的分布。适线法包括传统目估适线法及计算机优化适线法
由此,本节以P—Ⅲ型分布为例,介绍如何使用Python完成适线法。示例分为均匀格纸(未添加海森格纸)的情形和非均匀格纸(添加海森格纸)的情形,并作对比。
示例数据来自某水文站1965年—1995年的年径流,如下表所示(该表格在文件为 shixianshuju.xlsx)。
| Year | Flow(m3/s) |
|---|---|
| 1965 | 1676 |
| 1966 | 601 |
| 1967 | 562 |
| 1968 | 697 |
| 1969 | 407 |
| 1970 | 2259 |
| 1971 | 402 |
| 1972 | 777 |
| 1973 | 614 |
| 1974 | 490 |
| 1975 | 990 |
| 1976 | 597 |
| 1977 | 214 |
| 1978 | 196 |
| 1979 | 929 |
| 1980 | 1828 |
| 1981 | 343 |
| 1982 | 413 |
| 1983 | 493 |
| 1984 | 372 |
| 1985 | 214 |
| 1986 | 1117 |
| 1987 | 761 |
| 1988 | 980 |
| 1989 | 1029 |
| 1990 | 1463 |
| 1991 | 540 |
| 1992 | 1077 |
| 1993 | 571 |
| 1994 | 1995 |
| 1995 | 1840 |
实例1 均匀格纸(未添加海森格纸)
首先导入需要的库:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
读取表格:
df=pd.read_excel('shixianshuju.xlsx')
# print(df)
flow=list(df['Flow(m3/s)'])
flow_sort=sorted(flow,reverse=True)
# print(len(flow_sort))
特征值计算:
mean_flow=np.mean(flow)
std_flow=np.std(flow)
Cv=std_flow/mean_flow
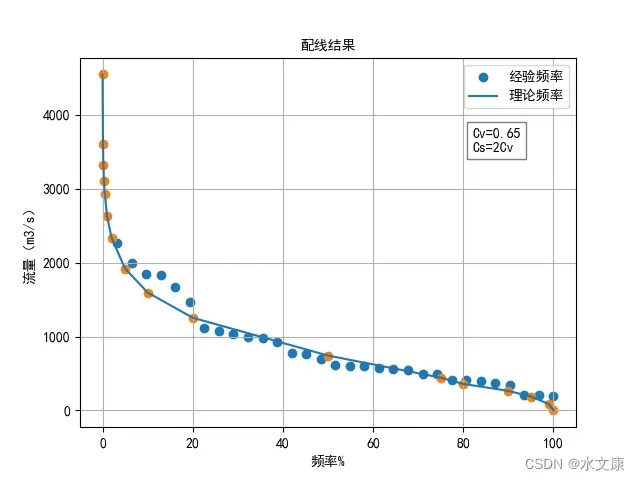
得Cv=0.65,假定Cs=2Cv,查K值表,得出对应于频率P的Kp值乘以平均流量得出相应Qp值。
Kp1=list(df['Kp1'].dropna())
P1=list(df['P%'].dropna())
# print(Kp1)
Qp=[]
for q in Kp1:
qi=q*mean_flow
Qp.append(qi)
最后绘图:
x=P
y=flow_sort
plt.scatter(x,y,label='经验频率')
plt.scatter(P1,Qp)
plt.plot(P1,Qp,label='理论频率')
plt.text(x= 81,y= 3500,s="Cv=0.65\nCs=2Cv", bbox=dict(facecolor="white" ,alpha=0.5) )
plt.title('配线结果',fontsize=10)
plt.xlabel('频率%',fontsize=10)
plt.ylabel('流量(m3/s)',fontsize=10)
plt.legend()
plt.grid()
plt.show()
适线结果如下图所示:
完整代码如下:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
df=pd.read_excel('shixianshuju.xlsx')
# print(df)
flow=list(df['Flow(m3/s)'])
flow_sort=sorted(flow,reverse=True)
# print(len(flow_sort))
xuhao=[]
P=[]
for i in range(1,32):
p=100*(i/(len(range(1,31))+1))
xuhao.append(i)
P.append(p)
# print(len(P))
mean_flow=np.mean(flow)
std_flow=np.std(flow)
Cv=std_flow/mean_flow
# 得Cv=0.65,假定Cs=2Cv,查K值表,得出对应于频率P的Kp值乘以平均流量得出相应Qp值
Kp1=list(df['Kp1'].dropna())
P1=list(df['P%'].dropna())
# print(Kp1)
Qp=[]
for q in Kp1:
qi=q*mean_flow
Qp.append(qi)
# print(Qp)
import matplotlib
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
# 为了坐标轴负号正常显示。matplotlib默认不支持中文,设置中文字体后,负号会显示异常。需要手动将坐标轴负号设为False才能正常显示负号。
matplotlib.rcParams['axes.unicode_minus'] = False
x=P
y=flow_sort
plt.scatter(x,y,label='经验频率')
plt.scatter(P1,Qp)
plt.plot(P1,Qp,label='理论频率')
plt.text(x= 81,y= 3500,s="Cv=0.65\nCs=2Cv", bbox=dict(facecolor="white" ,alpha=0.5) )
plt.title('配线结果',fontsize=10)
plt.xlabel('频率%',fontsize=10)
plt.ylabel('流量(m3/s)',fontsize=10)
plt.legend()
plt.grid()
plt.show()
实例2 非均匀格纸(添加海森格纸)
导入需要的库:
from scipy.special import gdtrix, ndtri #引入伽马累积分布函数的反函数与正态分布的分位数,
import matplotlib.pylab as plt
import numpy as np
import pandas as pd
定义概率密度计算函数与统计参数计算函数:
def xtrans(plist): # plist传入的是一个p值列表数据,plist必须是概率值,返回的xplist也是一个列表数据
xzero = ndtri(0.0001)
xplist = []
for i in range(len(plist)):
xplisti = ndtri(plist[i] / 100)
xplisti -= xzero
xplist.append(xplisti)
return xplist
def jlxs(plist, cs):
aa = 4 / cs ** 2 #即公式中的阿尔法值
tp = [] # 为求离均系数fp,tp是过渡
fp = []
for i in range(len(plist)): # 离均系数fp
tpi = round(gdtrix(1, aa, 1 - plist[i] / 100), 3) # 采用了标准伽马分布,a=1
fpi = round(cs * tpi / 2 - 2 / cs, 3)
tp.append(tpi)
fp.append(fpi)
return fp # 返回的fp也是一个列表数据
读取数据:
df=pd.read_excel('shixianshuju.xlsx')
Q=list(df['Flow(m3/s)'])
绘制坐标轴,建立海森格纸:
pstandard = [0.01,0.05, 0.1, 0.2, 0.5, 1.0, 2.0, 3.0, 5.0, 10.0, 20.0,30.0, 40.0, 50.0, 60.0, 70.0,80.0, 90.0, 95.0, 97.0, 99.0, 99.5, 99.9]
x_axis = [str(i) + '' for i in pstandard]
x = xtrans(pstandard)
y_axis = np.linspace(0, round(max(Q) * 1.2, 2), 10, dtype=np.float32)
绘制原始数据的散点图:
qj = np.mean(Q)
qcv = np.std(Q) * np.sqrt(len(Q) / (len(Q) - 1)) / qj # 无偏估计的cv值,标准差除均值
Q.sort(reverse=True)
# print(Q)
pq = [(i + 1) *100/ (len(Q) + 1) for i in range(len(Q))] # Q的经验频率 P=m/(n+1),通过期望公式,见书本P50
# print(pq)
pqx = xtrans(pq)
plt.scatter(pqx, Q)
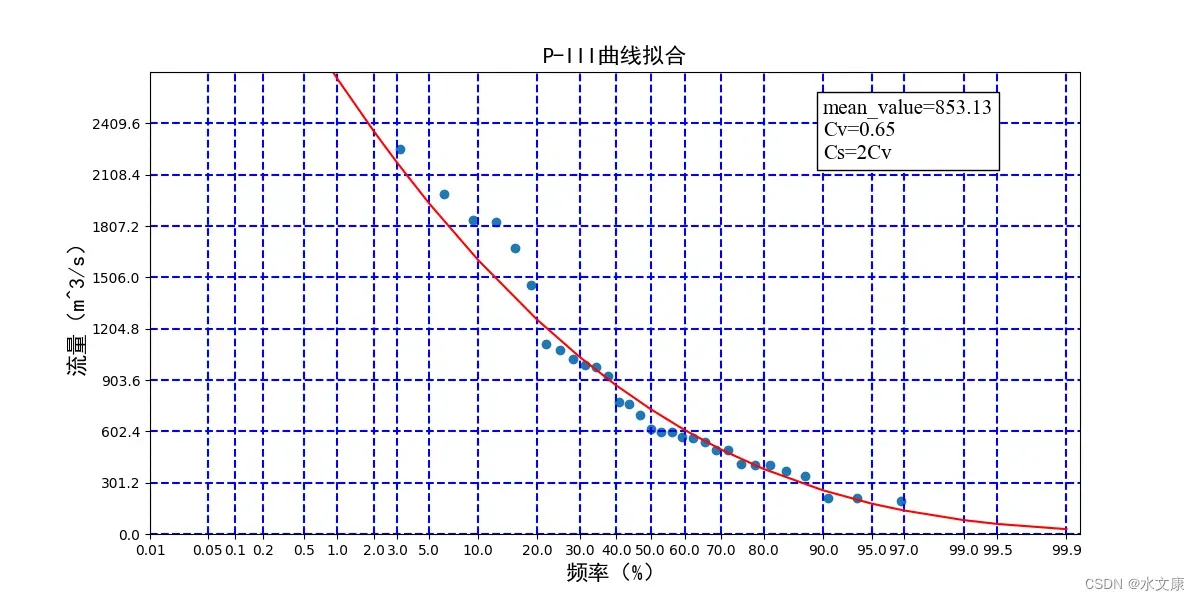
绘制预测的概率曲线,需要知道Cs、Cv以及均值:
n = 2 # 是自定义值
cs = n * qcv
qpredict = [qj * (qcv * m + 1) for m in jlxs(pstandard, cs)]
最后绘图:
plt.plot(x, qpredict, 'r', '-')
font2={'family':'SimHei','size':16,'color':'k'}
plt.title('P-III曲线拟合',fontdict=font2)
plt.xlabel('频率(%)',fontdict=font2)
plt.ylabel('流量(m^3/s)',fontdict=font2)
plt.text(x=5, y=2200, s="mean_value={:.2f}\nCv=0.65\nCs=2Cv".format(qj,cs, qcv), size = 15, family = "Times New Roman", color = "black", weight = "normal",bbox = dict(facecolor = "w", alpha = 1))
plt.show()
结果如下图所示:
完整代码如下:
from scipy.special import gdtrix, ndtri #引入伽马累积分布函数的反函数与正态分布的分位数,
import matplotlib.pylab as plt
import numpy as np
import pandas as pd
def xtrans(plist): # plist传入的是一个p值列表数据,plist必须是概率值,返回的xplist也是一个列表数据
xzero = ndtri(0.0001)
xplist = []
for i in range(len(plist)):
xplisti = ndtri(plist[i] / 100)
xplisti -= xzero
xplist.append(xplisti)
return xplist
def jlxs(plist, cs):
aa = 4 / cs ** 2 #即公式中的阿尔法值
tp = [] # 为求离均系数fp,tp是过渡
fp = []
for i in range(len(plist)): # 离均系数fp
tpi = round(gdtrix(1, aa, 1 - plist[i] / 100), 3) # 采用了标准伽马分布,a=1
fpi = round(cs * tpi / 2 - 2 / cs, 3)
tp.append(tpi)
fp.append(fpi)
return fp # 返回的fp也是一个列表数据
df=pd.read_excel('shixianshuju.xlsx')
Q=list(df['Flow(m3/s)'])
# 坐标轴的绘制
# pstandard = [0.01, 0.02, 0.05, 0.1, 0.2, 0.5, 1.0, 2.0, 3.0, 5.0, 10.0, 20.0, 25.0,30.0, 40.0, 50.0, 60.0, 70.0, 75.0, 80.0, 90.0, 95.0, 97.0, 99.0, 99.5, 99.9]
pstandard = [0.01,0.05, 0.1, 0.2, 0.5, 1.0, 2.0, 3.0, 5.0, 10.0, 20.0,30.0, 40.0, 50.0, 60.0, 70.0,80.0, 90.0, 95.0, 97.0, 99.0, 99.5, 99.9]
x_axis = [str(i) + '' for i in pstandard]
x = xtrans(pstandard)
y_axis = np.linspace(0, round(max(Q) * 1.2, 2), 10, dtype=np.float32)
#print(x_axis, y_axis, sep='\n')
# print(x)
# 建立海森图纸张,需要知道Q的最大值来确定横坐标的上限
fig = plt.figure(figsize=(12,6))
ax1 = fig.add_subplot(111)
for i in range(len(x)):
plt.vlines(x[i], 0, round(max(Q) * 1.2, 2), 'blue', '--')
for j in range(len(y_axis)):
plt.hlines(y_axis[j], 0, max(y_axis), 'blue', '--')
plt.xticks(x, x_axis, color='black', rotation=0)
plt.yticks(y_axis, y_axis, color='black', rotation=0)
plt.ylim(0, round(max(Q) * 1.2, 2))
plt.xlim(0, round(max(x) + 0.1, 2))
plt.tick_params(labelsize=10)
# 绘制原始数据的散点图
qj = np.mean(Q)
qcv = np.std(Q) * np.sqrt(len(Q) / (len(Q) - 1)) / qj # 无偏估计的cv值,标准差除均值
Q.sort(reverse=True)
# print(Q)
pq = [(i + 1) *100/ (len(Q) + 1) for i in range(len(Q))] # Q的经验频率 P=m/(n+1),通过期望公式,见书本P50
# print(pq)
pqx = xtrans(pq)
plt.scatter(pqx, Q)
# 绘制预测的概率曲线,需要知道cs,cv,qj(均值)
n = 2 # 是自定义值
cs = n * qcv
qpredict = [qj * (qcv * m + 1) for m in jlxs(pstandard, cs)]
plt.plot(x, qpredict, 'r', '-')
font2={'family':'SimHei','size':16,'color':'k'}
plt.title('P-III曲线拟合',fontdict=font2)
plt.xlabel('频率(%)',fontdict=font2)
plt.ylabel('流量(m^3/s)',fontdict=font2)
plt.text(x=5, y=2200, s="mean_value={:.2f}\nCv=0.65\nCs=2Cv".format(qj,cs, qcv), size = 15,\
family = "Times New Roman", color = "black", weight = "normal",\
bbox = dict(facecolor = "w", alpha = 1))
plt.show()
3.2 水文数据分析——Mann-Kendall(MK)检验
Mann-Kendall
版权声明:本文为博主作者:水文康原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_51956867/article/details/136222006