随着机器学习算法的发展,语音识别中几乎所有的模型和算法都是建立在数学的基础之上,数学最大的作用是将具体问题抽象成公式或数字化表示,便于计算机实现自动化运算。
本章介绍的数学知识主要服务于语音识别的常见模型
表示语音数据——向量、矩阵
揭示数据之间关系——概率、统计
寻找语音数据之间的规律,从而对新数据预测——函数
神经网络中求导方式和建模思想——梯度下降法、数列的特性
2.1向量与矩阵
语音数据的处理和分析往往建立在向量和矩阵的基础上,向量不仅可以用于表示数字化的语音数据,还可以用于特征模型中函数的构建与计算。矩阵则主要参与语音数据转化为频谱图形式的数据表示和计算。
2.1.1向量
在数学上,向量主要用于表示具有大小和方向的量。以图形表示,一个向量对应着一个有向线段。例如有一个向量A->B(箭头应该在AB上面)箭头所指的方向表示向量的方向,如图:由A指向B,线段AB的长度对应着向量的大小。
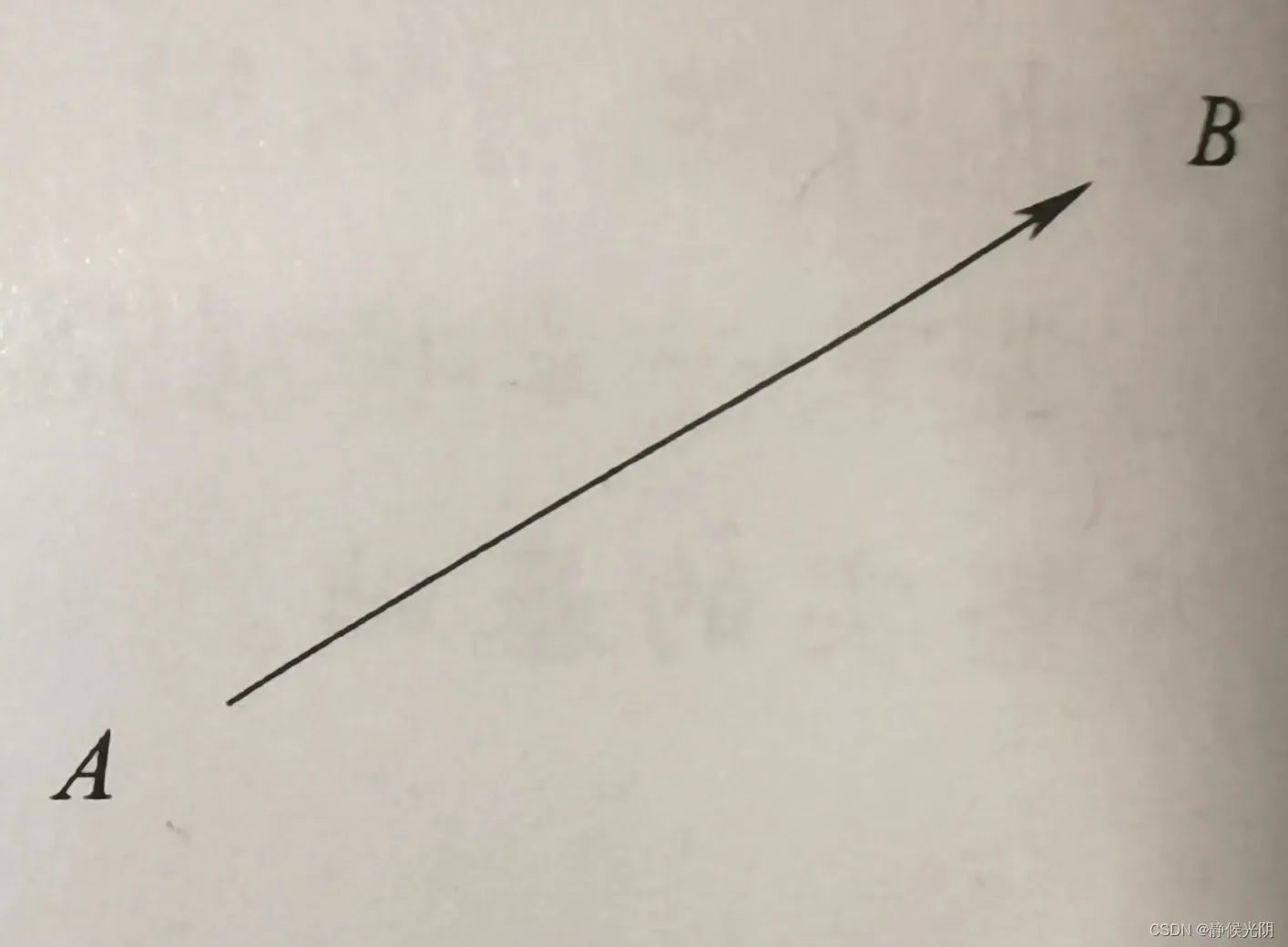
在数学公式中,图2.1所示的向量常常表示为A->B,也可以用不带箭头的黑体小写字幕表示,比如a。本书采用后一种方式。
(1)向量的坐标表示
坐标向量表示法是一种常见的表示向量的方法。在一个几何坐标中,通过几何空间中两个点之间的连线,通过箭头指明向量的方向。
A.二维空间中向量的坐标表示
二维空间中,向量常常表示为:a = (x1, y1),省略了向量的起点,即默认起点为(0 , 0),终点为(x1, y1)。例如现有向量a = (1, 2),在二维坐标系中,可以绘制成如下图所示:
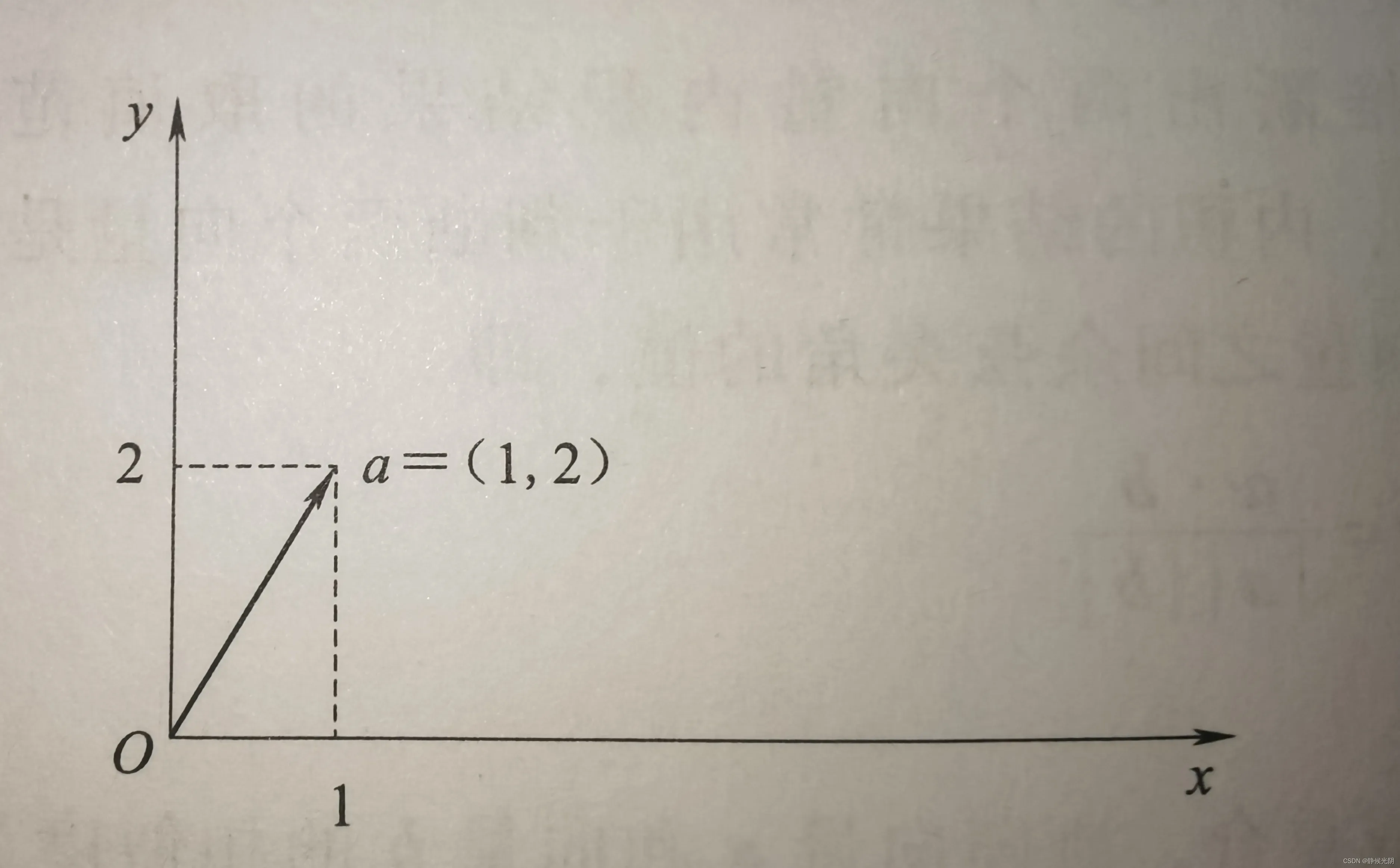
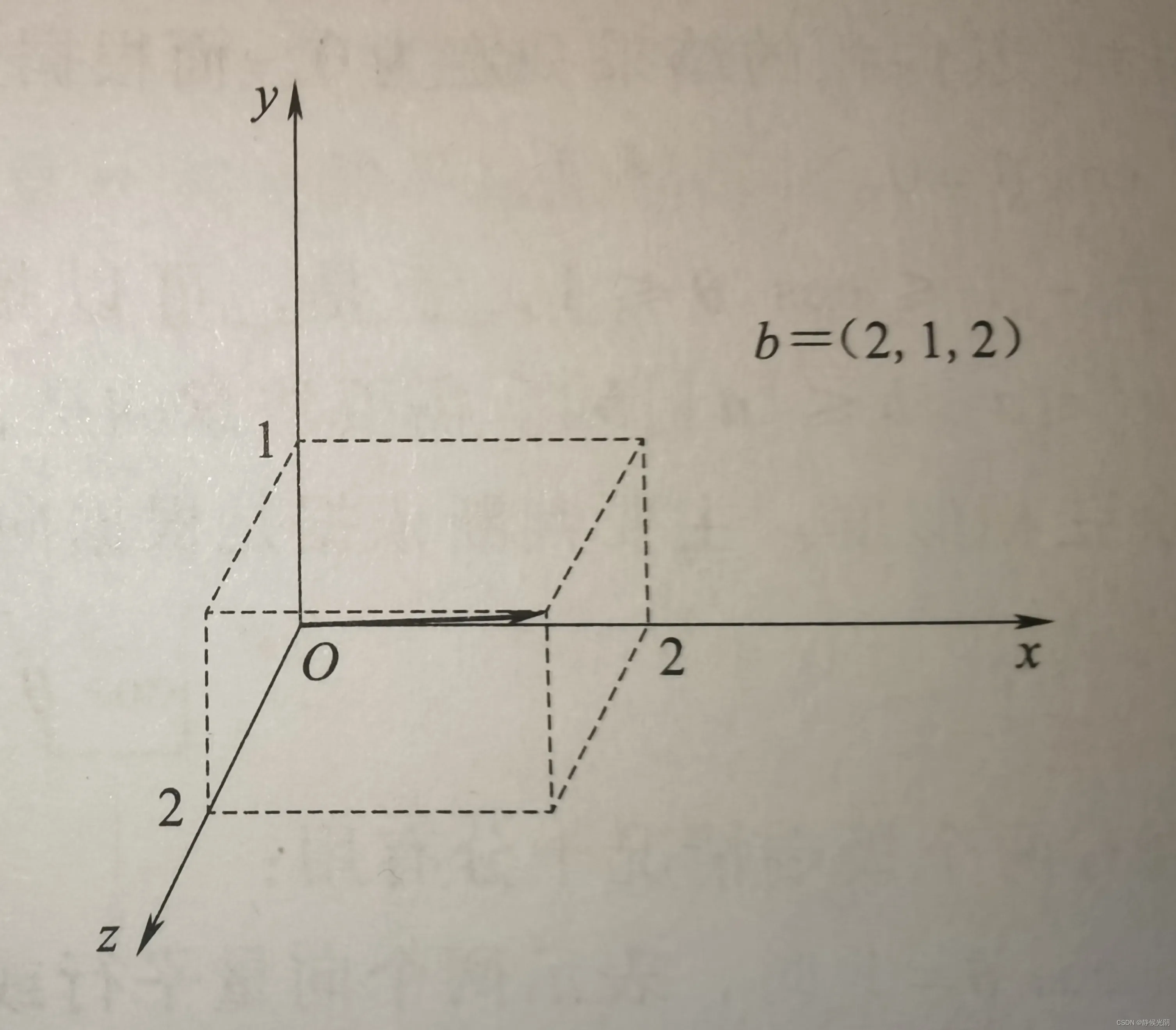
B.三维空间中向量的坐标表示
在三维空间的坐标系中b = (x1, y1, z1), 同样地,向量的起点默认从坐标从坐标原点(0,0,0)出发,终点坐标是(x1, y1, z1)。
例如坐标b = (2, 1, 2),可以如下图所示:
C.多维空间中向量的坐标表示
语音识别中,更常采用的是几何空间中的多为坐标向量表示法,x = (x2, x2, x3, x4,……,xn),其中,xn表示在n维几何空间中投影到对应坐标轴的值,n对应向量的维数。
例如,如图所示的三个列向量为例,它们分别是一个二维列向量,一个三维列向量,和一个n维列向量。
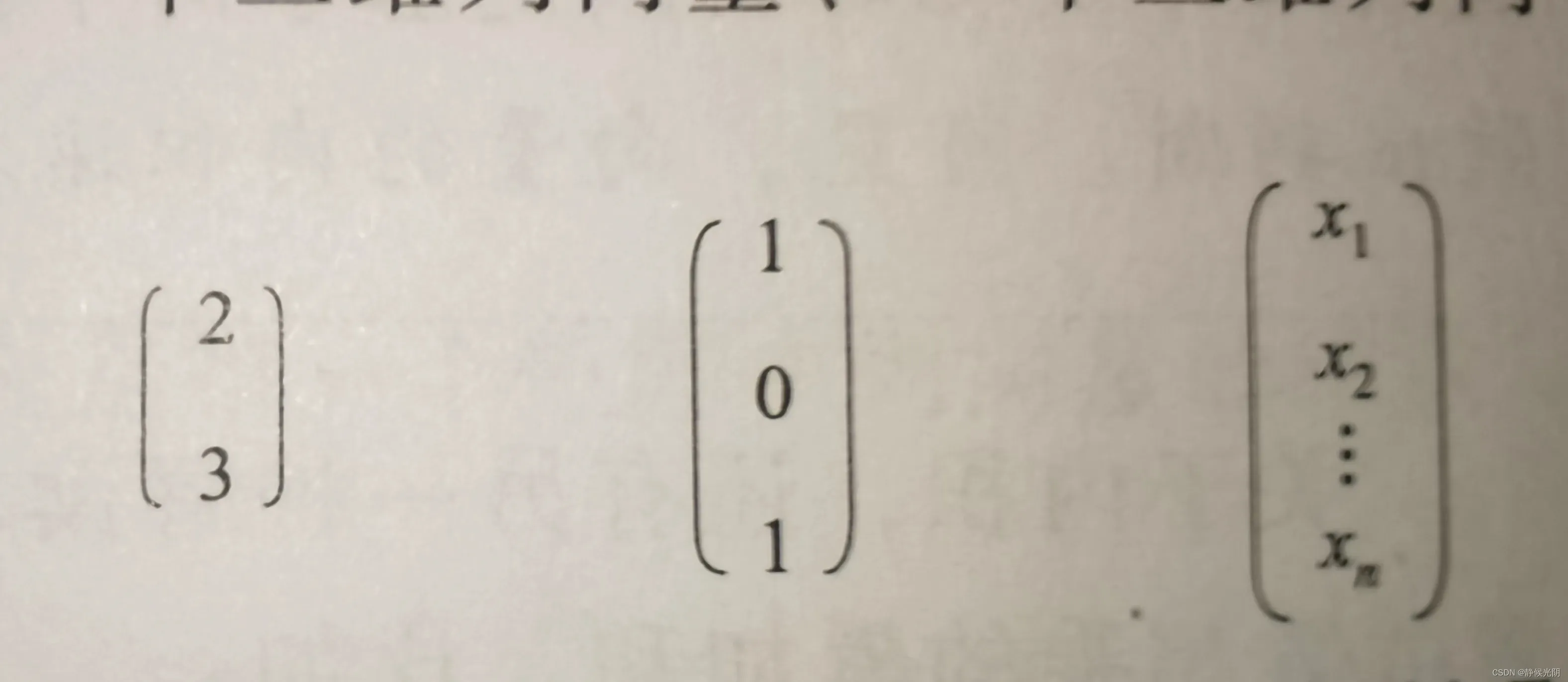
上图的向量还可以通过转置运算变为横向量,比如向量a的转置运算变为横向量,比如向量a的转置运算可以表示为aT = (2, 3)。
(2)向量的内积
基于多维列向量的表示,更重要的是对向量做计算。其中,最基本的运算时两个向量的标量积或数量积,也称内积或点乘运算。向量的内积可以表示为a • b,对应的计算方式为:
a • b = |a| • |b|cosθ
其中,|a|和|b|分别表示向量a和向量b的模,即大小,θ是a和b的夹角,向量a和b的内积就是两个向量的大小与夹角余弦值的乘积。不难发现,当a和b中有一个向量的大小为0时,其内积的结果一定为0。而根据余弦的性质可知,当θ = 0时,cosθ = 1;当θ = 90°时,cosθ = 0。
由于 -1<= cosθ<= 1,于是,可以推断出两个向量内积结果的取值范围就是-|a||b| <= a • b <= 1,需要注意的时,内积的结果常常用于判断两个向量是否相似,又称之为余弦相似度。主要判断依据时根据向量之间余弦夹角的值,即
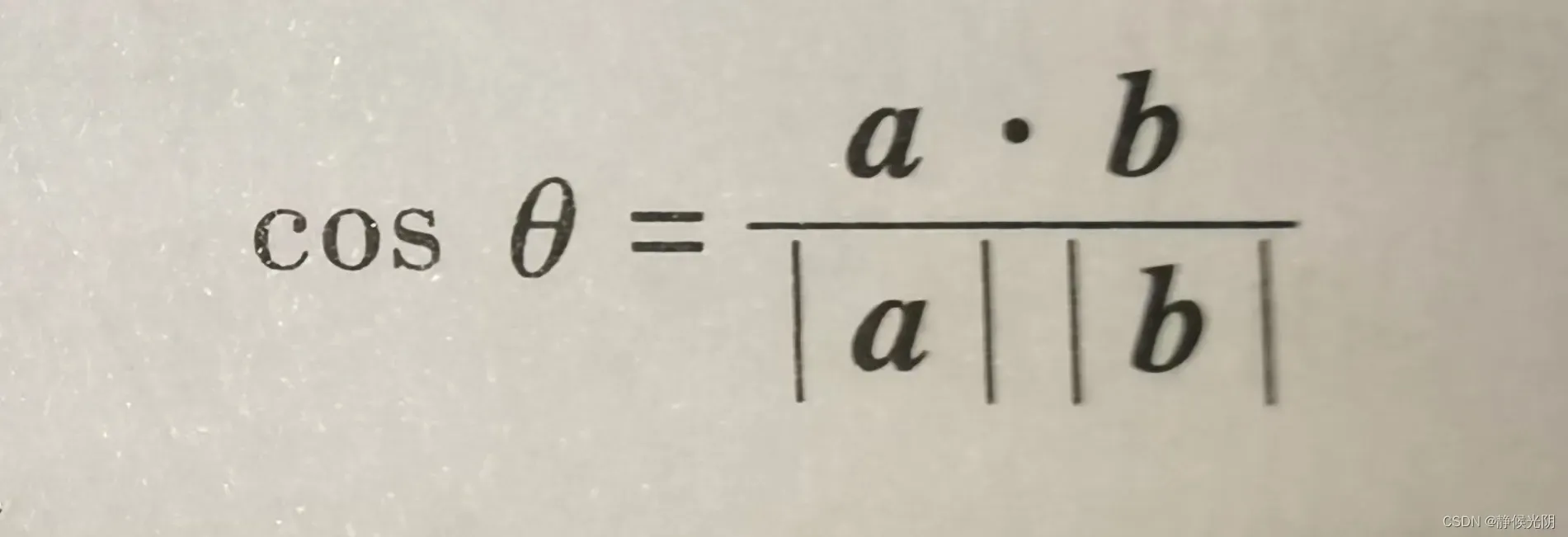
该值有两个极端情况十分有用:
当cosθ = 1时,表示两个向量平行或重合,判断向量a和向量b的相似度为100%
当cosθ = 0时,表示两个向量正交,判断向量a和向量b没有相似性,可以认为它们相互独立。
关于内积,还有另一种解读,即对两个n维向量做内积运算,等价于两个向量对应位置的数相乘的累加和,比如:
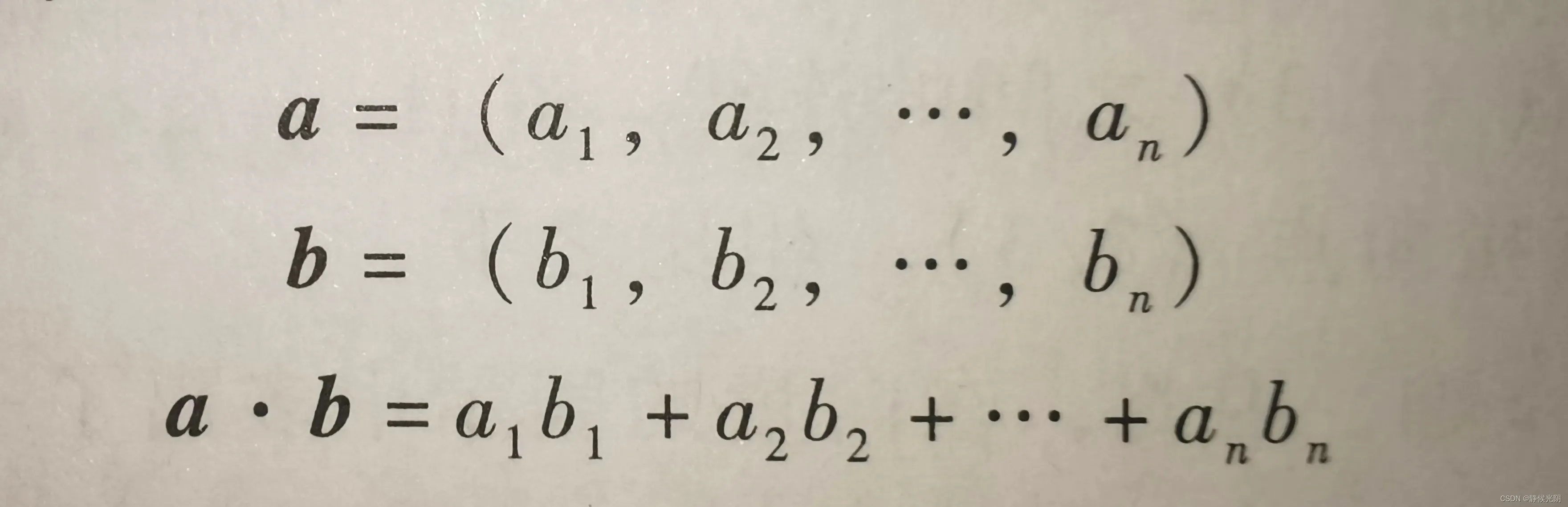
其中,向量a和向量b的维数必须相同才可以计算,即a与b中的n必须相等。
在语音识别中有一个常见的神经网络模型,经常要计算神经元的输入信息z,其一般表示公式为:
z = w1 x1 + w2 x2 + ……+ wn xn +b
其中x1, x2, x3,…,xn对应着输入的神经元的值,他是可变的未知量, w1, w2, …..,wn为每个神经元占据的权重,b为偏置常量。在程序中,W = (w1, w2,…,wn),表示权重,向量x = (x1, x2, … ,xn),表示神经元的值。最终,z可以表示为向量之间的运算关系,即
z = W • x + b
可以方便地使用python中的Numpy对向量做内积计算。
2.1.2 矩阵
向量无论包含多少个值,从矩阵角度来说,他们都可以看作矩阵的特例,即一维矩阵。因此向量常常被看作数据的一维表示法,而在语音识别中,二维矩阵更为常见。
从分解的角度来看,二维矩阵可以看作由若干个行向量或若干个列向量组成的。矩阵的形状(或维度)可以描述为行向量的个数乘以列向量的个数。
一个m x n 的矩阵,其中m为行数,n为列数,注意m和n并不总是相等的。
在语音识别中,矩阵最重要的作用是以二维数组的形式将语音表示为二维灰度图像,该图像在计算机中对应着一个二维矩阵。另外,矩阵还可以用于对数据的分析处理,比如状态转移矩阵的表示、矩阵之间的乘积计算,以及一个矩阵和一个标量(可以看作一个数值)。
(1)矩阵的乘法计算
根据矩阵的乘法定理可知,两个矩阵之间做乘法的前提是第一个矩阵中列向量的维数必须等于第二个矩阵中行向量的维数,否则无法进行乘法运算。
矩阵中常见的两种乘法计算
A. 两个矩阵的乘积:AB
以下面这一对矩阵为例讲解:
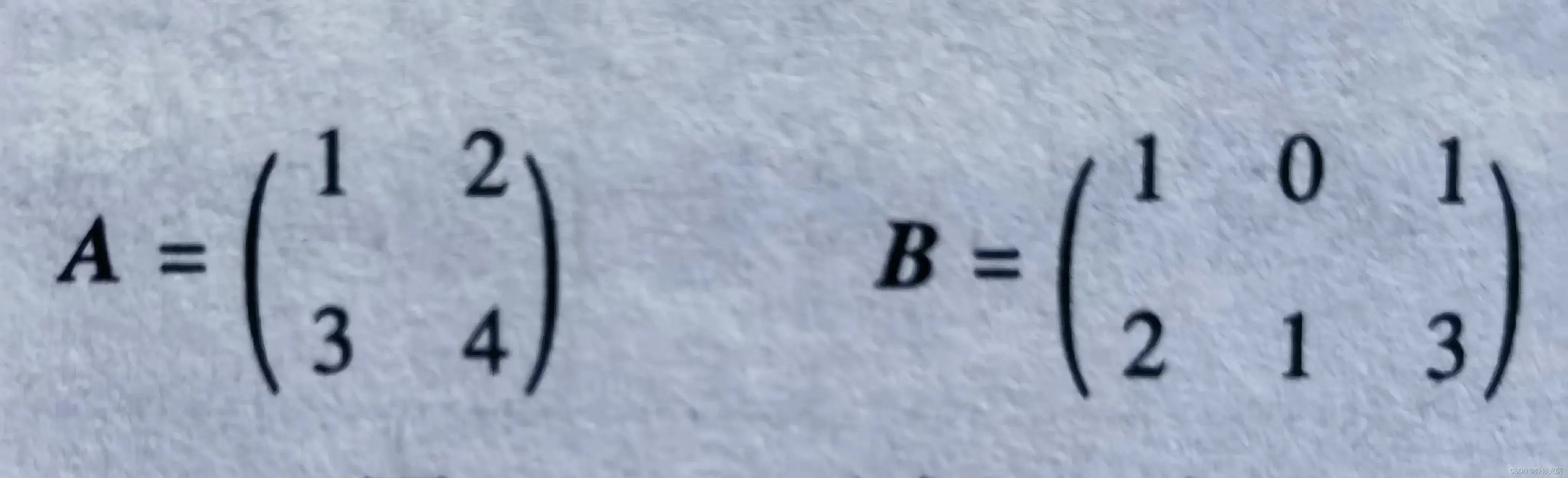
矩阵的成绩计算,过程是A矩阵中的行向量依次与B矩阵中对应的列向量中的分量做乘积,其累加和为结果矩阵C中的对应分量,并且结果矩阵的维数等于A的第一维数乘以B的第二维数。具体计算为:
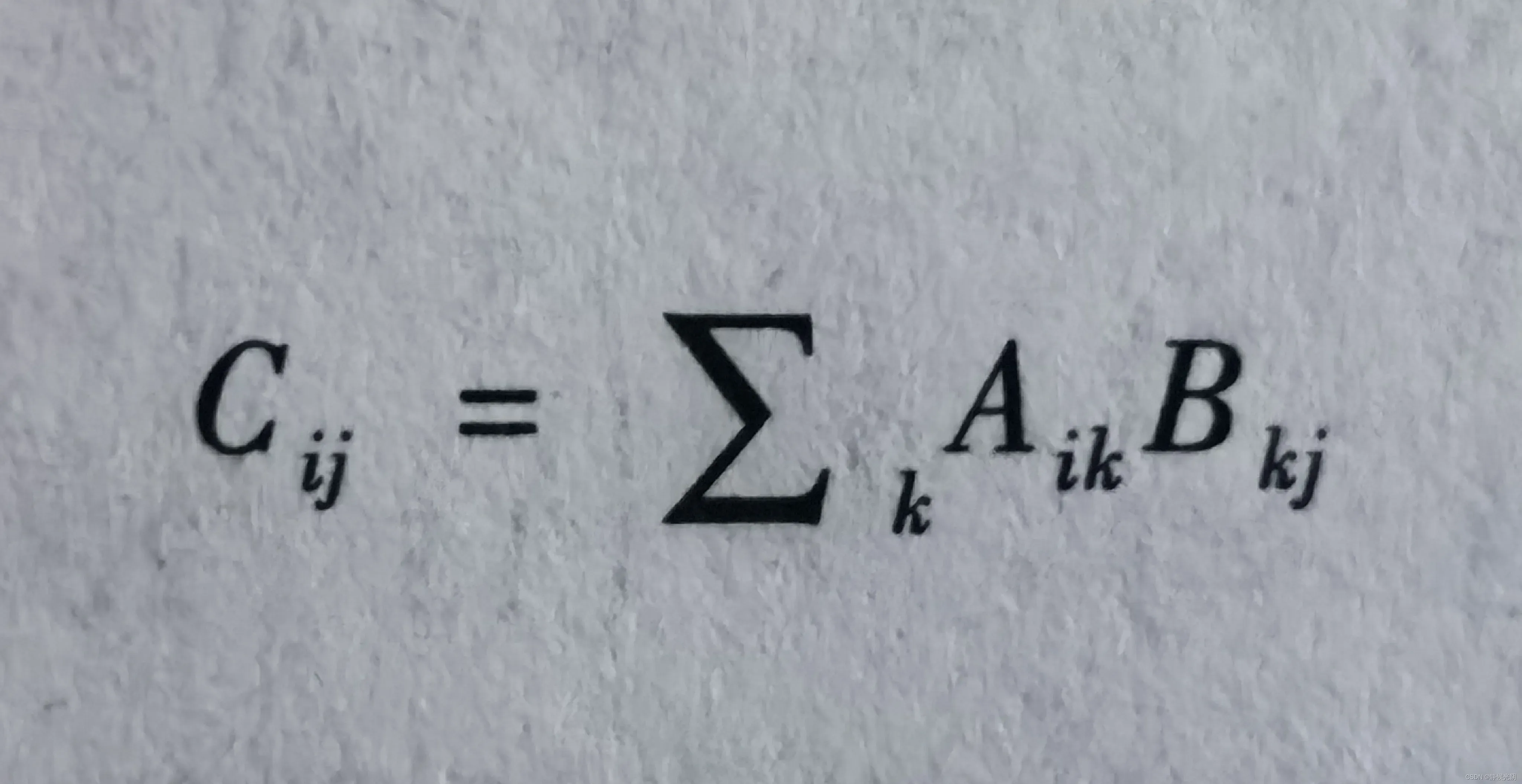
其中,i,j,k都是正数。
以![]() 和
和![]() 表示矩阵中的一个具体值。
表示矩阵中的一个具体值。
AB的具体做法如下:
第一步,检查A的列是2,B的行是2,因此A和B可以做乘法运算。
第二步,C表示结果矩阵,由A和B的维数可知,C的第一个维数等于A的第一个维数,C的第二个维数等于B的第二个维数,因此C是一个2×3的矩阵。
第三步,计算C中的每一个值,为了便于看清楚,将A、B和C首先转换成字母形式,然后依次按照如下的步骤计算出C:
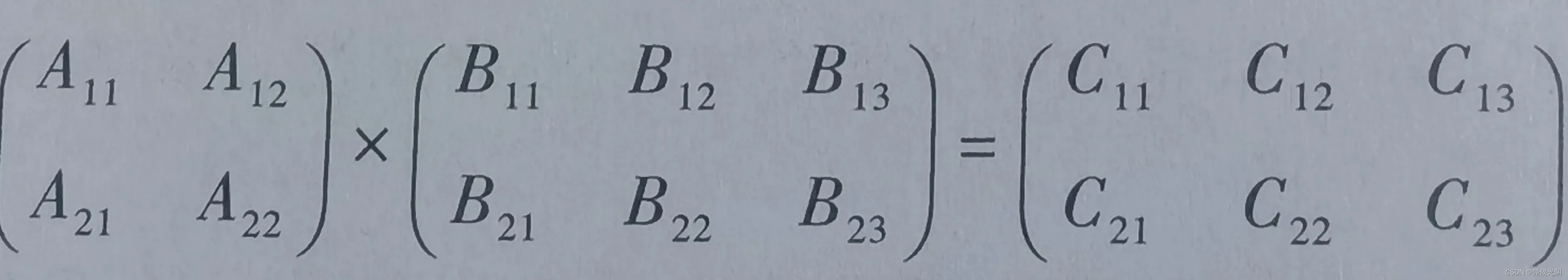 以下是结果矩阵C中各个数值Cij(i<=2, j<=3)的计算该过程。
以下是结果矩阵C中各个数值Cij(i<=2, j<=3)的计算该过程。
C11等于A的第一个行向量与B的第一个列向量的乘积的累加和,即
C11 = A11 x B11 + A12 x B21 = 1 x 1 + 2 x 2 = 5
C12等于A的第一个行向量与B的第二个列向量的乘积的累加和,即
C12 = A11 x B12 + A12 x B22 = 1 x 0 + 2 x 1 = 2
C13等于A的第一个行向量与B的第三个列向量的乘积的累加和,即
C13 = A11 x B13 + A12 x B23 = 1 x 1 + 2 x 3 = 7
C21等于A的第二个行向量与B的第一个列向量的乘积的累加和,即
C21 = A21 x B11 + A 22 x B21 = 3 x 1 + 4 x 2 = 11
C22 等于A的第二个行向量与B的第二个列向量的乘积的累加和,即
C22 = A21 x B12 + A22 x B22 = 3 x 0 + 4 x 1 = 4
C23 等于A的第二个行向量与B的第三个列向量的乘积的累加和,即
C23 = A21 x B13 + A22 x B23 = 3 x 1 + 4 x 3 = 15
最终结果如图:
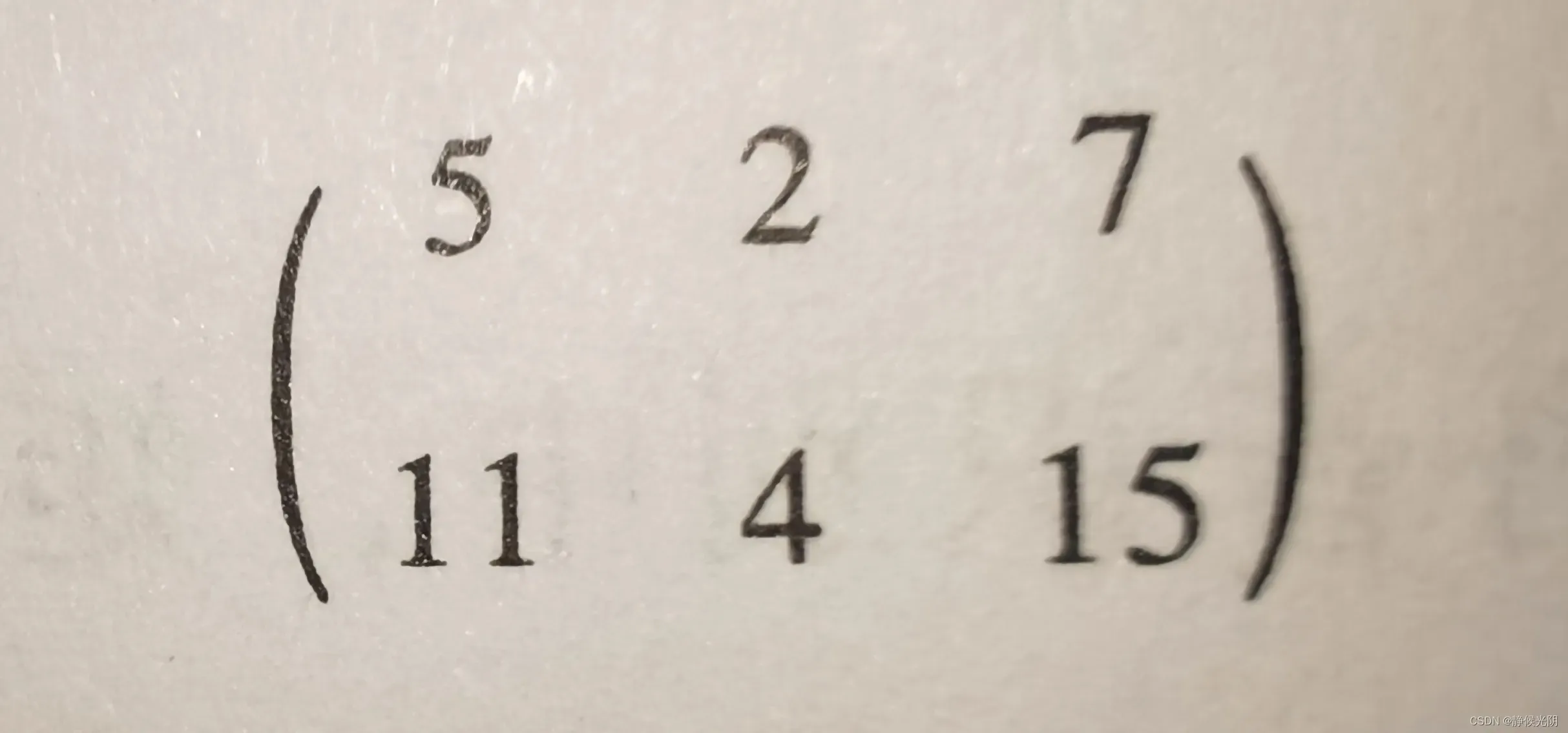
B. 矩阵和标量乘积:A x 5
标量是物理学中的定义,它只有数值大小,没有方向之分。如:数值5就是一个标量,因为它只是一个表示大小的数字。
矩阵乘以标量:就是对矩阵中的每一个值都乘以标量,最终得出一个与矩阵A维数一致的结果矩阵。
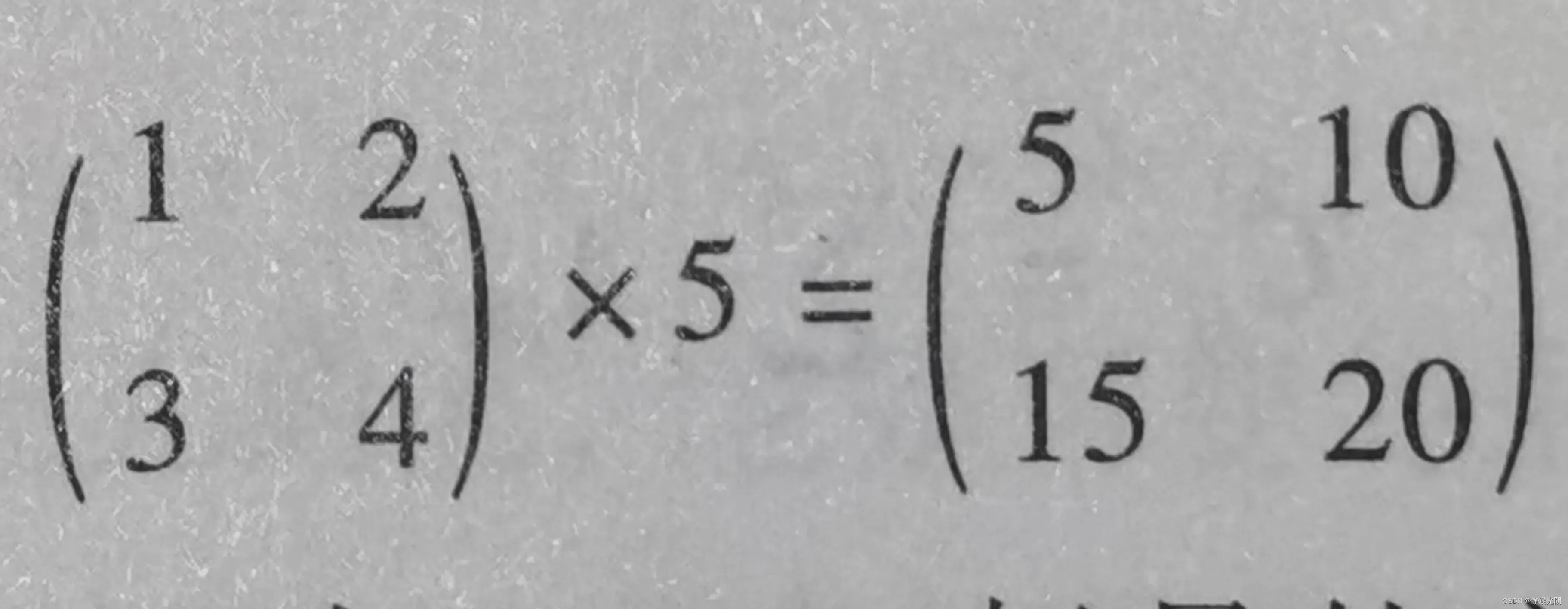
矩阵和标量的计算常用于Python中Numpy标量的广播,即通过一个标量将原始矩阵扩展为一个新的矩阵。
(2)矩阵的卷积运算
卷积原本是数学上的一种运算,它可以表示为“ * ”,在语音识别中,需要重点理解的是以矩阵为核心的卷积运算。
所谓卷积运算,就是用尺寸较小的矩阵在尺寸较大的矩阵上不断滑动,每滑动一次就做一次计算。
接下来,以下图为例:特征矩阵A和卷积核矩阵C,A和C的卷积可以表示为A*C或者Conv(A, B):
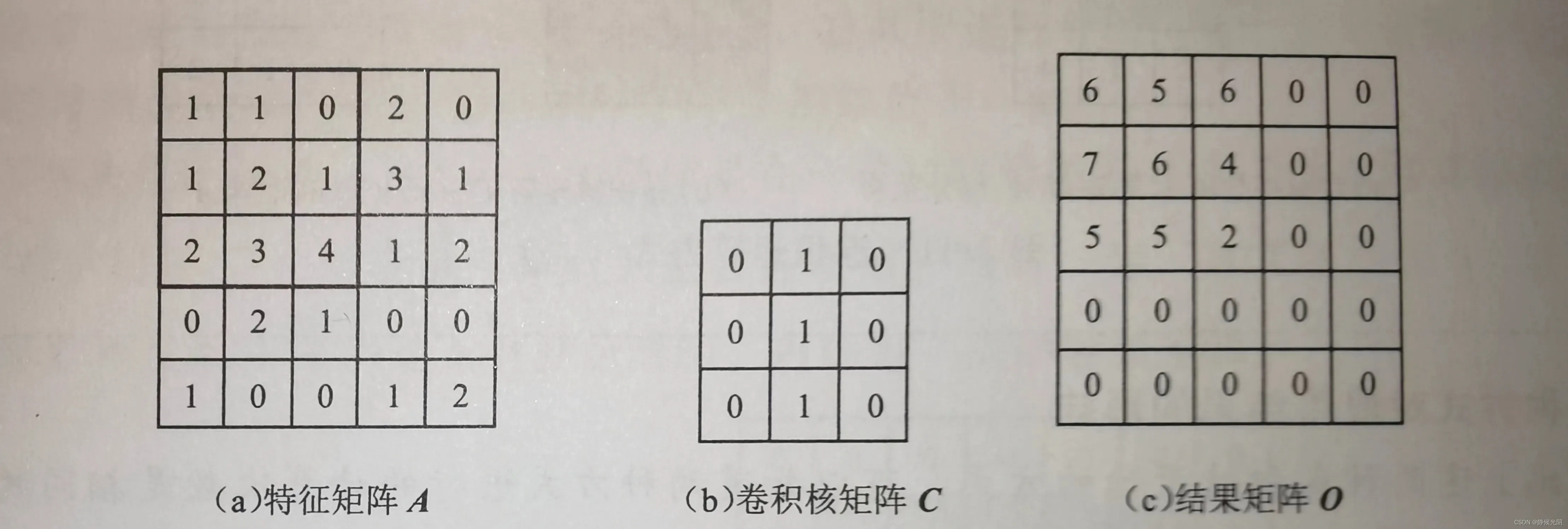
将卷积核矩阵C在特征矩阵A上滑动,初始位置为左上角的元素,接着按照从左到右,每次移动一格,知道卷积核矩阵C完全覆盖第一行最右侧的元素。卷积核矩阵C整体向下移动一格做计算,继续向右移动并做卷积运算。其中,每一次的乘法运算是指将框住的特征矩阵A与卷积核矩阵C对应元素相乘再累加,直到扫描完成特征矩阵A中的所有值为止,最终的结果如上图所示的结果矩阵O
卷积核的位置处于滑动状态,它滑动的位置一般是认为设定的。根据卷积核中心元素的位置变化,卷积运算可以有两种不同的方式。:
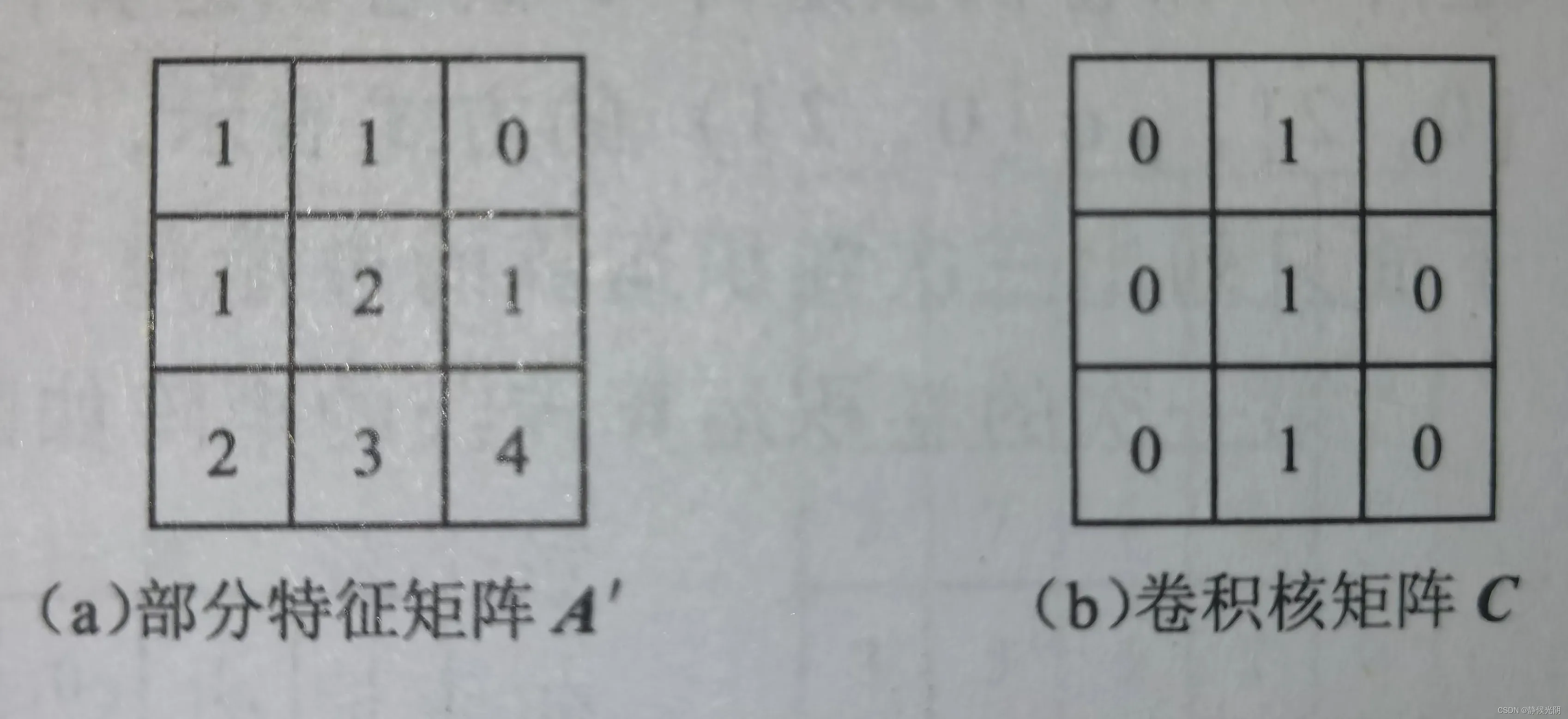
A. 卷积核的第一个元素与矩阵中第一个元素重合
第一种方式是将卷积核矩阵C左上角的值与部分特征矩阵A左上角的值重叠,做第一次卷积运算,如下图所示,以后每次向右移动一格,直到移动到第一行的最后一个元素0,再换到下一行,直到所有元素都运算一遍。
B. 卷积核的中心元素与特征矩阵A中第一个元素重合
第二种方式是将卷积核矩阵C的中心点与特征矩阵A的左上角第一个值重合,开始第一次卷积运算,如下图最右侧的图所示,每次向右移动一格做一次卷积运算,直到移动到第一行的最后一个元素0,再换到下一行。
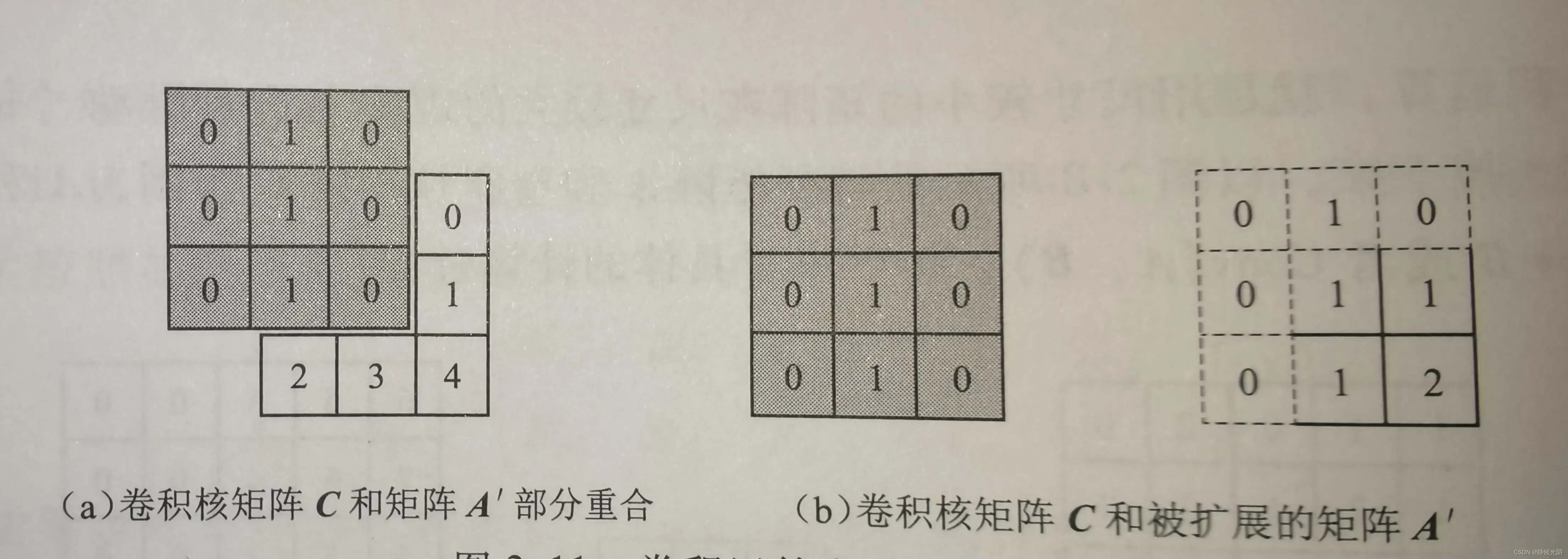
两种方式对最终结果的影响:
计算结果相同,但是结果矩阵中的元素是不完全一致的。
最大的区别就是边缘元素的影响。上述例子矩阵维度数非常小,看上去差别不大;但是对于一个大维数的矩阵,这种差别就会显现出来,尤其是补零的操作会导致四周边缘元素的数值减少。对应到二维图像,就是边缘像素会更加模糊。
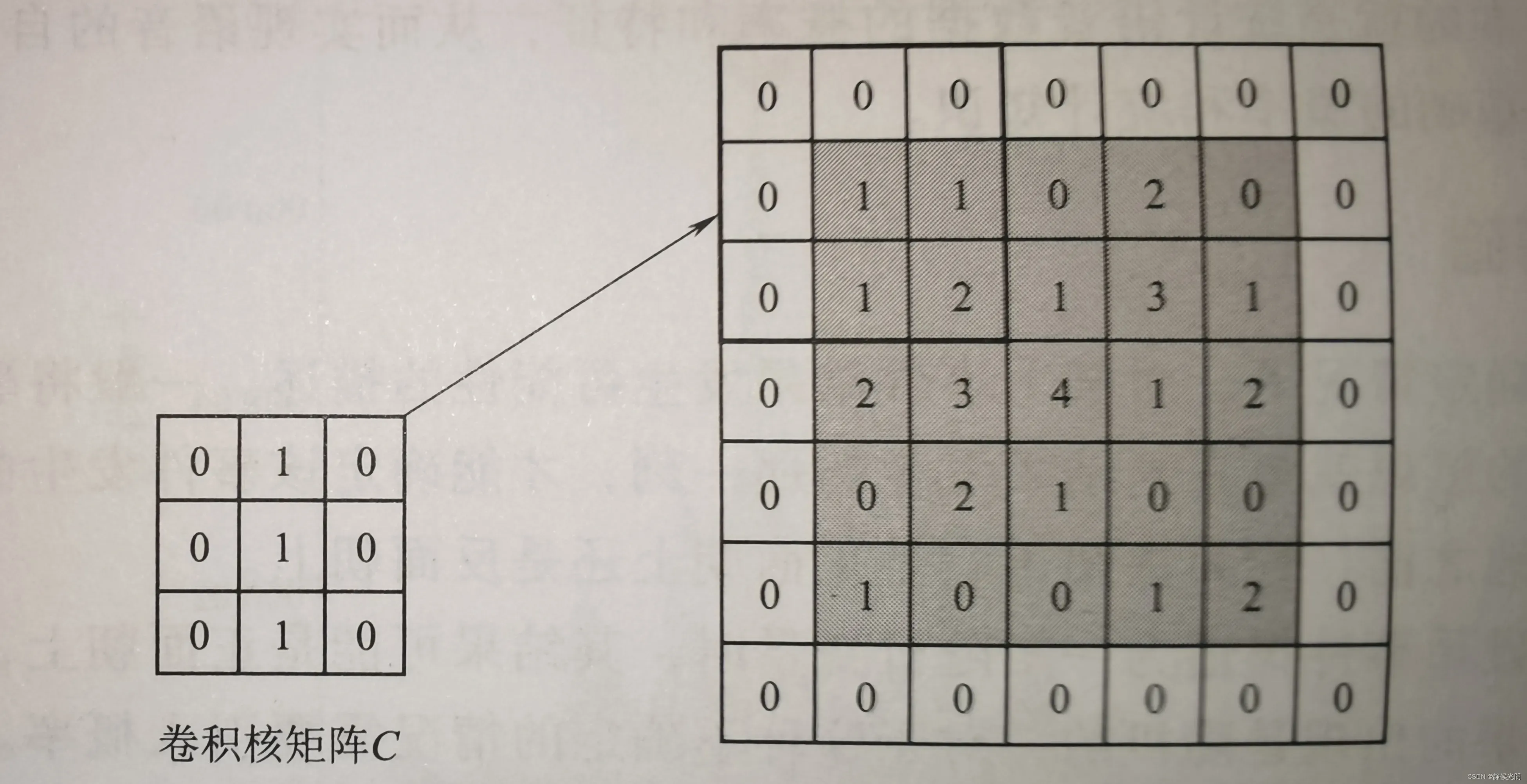
由于矩阵A的维数是5X5,而卷积核矩阵C的维数是3X3,为了保证卷积核矩阵能够完全和矩阵A中的元素重合,总共需要进行9次运算,因此这样得出的结果矩阵O的维数只能是3X3,会导致与矩阵A的维数不一致
为了解决这个问题,一种常见的操作是在一开始就给矩阵A人工补0将七位数扩展成下图所示的7X7的矩阵,即上下左右各增加一行和一列,且其值均为0。然后,卷积核矩阵C再从该矩阵的左上角开始滑动,进行每一次的卷积运算。
卷积与矩阵乘法的不同之处
虽然矩阵相乘核卷积运算的结果都是一个矩阵,但是计算过程却存在一些差异,具体来说,不同之处有两个:
a. 矩阵相乘是行向量与列向量的运算,而卷积是两个同等大小的矩阵对应元素的乘积的累加和;
b.矩阵相乘对两个矩阵有维数的严格限制,而卷积运算则要求一个矩阵维数偏大,卷积核矩阵维数一般都偏小。
在语音识别算法中,原始的一维语音信号通常都要转化为一个二维特征矩阵,该特征矩阵非常大,假设维数为30 x 100,它代表该语音信号被分成了100帧(即100列),每一帧由39个特征表示,即39行。而卷积核通常为一个尺寸较小的矩阵,比如神经网络中用于池化操作的2 x 2矩阵,又称卷积核;还有用于去除噪声的3 x 3或5 x 5的矩阵,又称滤波器。这里卷积核和滤波器的名称不同是因为他们的作用不同。卷积核就是单纯地做卷积运算;滤波器的作用可以认为是一种过滤网,目的是允许一些重要信息通过,而其他不重要的信息就应该被抑制。
版权声明:本文为博主作者:静候光阴原创文章,版权归属原作者,如果侵权,请联系我们删除!