动态规划之平衡资源分配问题&生产与存储问题
文章目录
- 动态规划之平衡资源分配问题&生产与存储问题
-
- 1、一维离散平衡资源分配问题
-
- 平衡资源分配经典例题
- 确定输入参数
- 例题python源代码
- 例题输出结果
- 例题结果分析
- 2、生产与存储问题
- 程序参数说明
-
- 例题1——初末仓库存储均为0
-
- 确定输入参数
- 例一python源代码
- 例1输出结果
- 例1结果分析
- 例题2——初始仓库存储不为0&仓库容量有限制
- 确定输入参数
-
- 例二python源代码
- 例2输出结果
- 例2结果分析
- 例题3——生产成本不固定
-
- 确定输入参数
- 例三python源代码
- 例3输出结果
- 例3结果分析
1、一维离散平衡资源分配问题
平衡资源分配经典例题
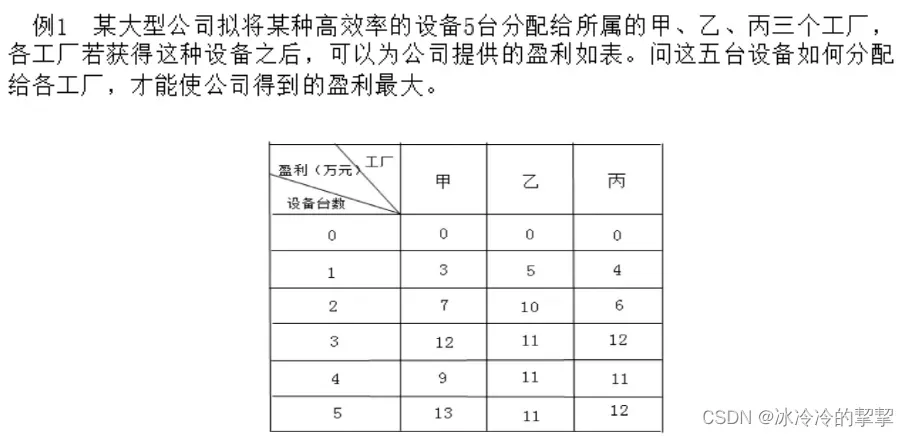
确定输入参数
# 阶段指标表格,按列顺序
stage_indicator_list = [[0, 0, 0],
[3, 5, 4],
[7, 10, 6],
[9, 11, 11],
[12, 11, 12],
[13, 11, 12]]
例题python源代码
import pandas as pd, numpy as np, copy
# 动态规划——离散一维资源分配问题
class Discrete_Resource_Allocation_Problem(object):
# 初始化函数
def __init__(self, stage_indicator_list, fn_1=0):
self.fn_1 = fn_1
self.stage_indicator_list = stage_indicator_list
self.stage_indicator_df = self.get_stage_indicator_df()
# 求解资源分配问题,获得一个列表返回值,列表第一个元素是最后一次迭代的表格,第二个元素是所有迭代的表格字典
self.solve = self.dynamic_program_solve()
# 最后一次迭代的表格
self.first_stage_df = self.solve[0]
# 所有迭代的表格字典
self.stage_df_dict = self.solve[1]
self.writer = pd.ExcelWriter("动态规划——离散一维资源分配问题.xlsx")
for key in self.stage_df_dict.keys():
self.stage_df_dict[key].to_excel(self.writer, sheet_name=f"{key}状态下")
try:
self.writer.save()
except:
self.writer.close()
# 获得阶段性指标表格
def get_stage_indicator_df(self):
stage_indicator_df = pd.DataFrame(data=np.array(self.stage_indicator_list),
index=[i for i in range(len(self.stage_indicator_list))],
columns=[f"department{i + 1}" for i in
range(len(self.stage_indicator_list[0]))])
return stage_indicator_df
# 获取列表中相同元素位置
def get_same_element(selfl, lists, find_value):
index_list = []
k = 0
for value in lists:
if value == find_value:
index_list.append(k)
k += 1
return index_list
# 获取最优指标函数值fk(sk)和决策变量值xk
def get_fs_and_xindex(self, df):
df1 = copy.deepcopy(df)
df1 = df1.fillna(-9999)
fs_list = []
x_list = []
for i in range(len(df1.values.tolist())):
fs_list.append(max(df1.iloc[i, :].tolist()))
x = self.get_same_element(df1.iloc[i, :].tolist(), max(df1.iloc[i, :].tolist()))
x_list.append(f"{x}")
return [fs_list, x_list]
# 求解多阶段决策问题
def dynamic_program_solve(self):
# 记录每次迭代的表格存入字典
stage_df_dict = {}
num = len(self.stage_indicator_list[0])
s_n = f"S{num}"
f_n = f"f{num}"
x_n = f'x{num}'
f = []
for g in self.stage_indicator_df.iloc[:, -1].tolist():
f.append(g + self.fn_1)
last_stage_matrix = np.diag(f)
last_stage_df = pd.DataFrame(data=last_stage_matrix)
# 将0值替换为NaN
last_stage_df = last_stage_df.replace(0, "×")
last_stage_df.iloc[0, 0] = 0
last_stage_df[f_n] = f
last_stage_df[x_n] = [[i] for i in range(len(f))]
strs = "*" * 20
print(f"{strs}状态变量{s_n}下{strs}")
print(last_stage_df)
stage_df_dict.update({s_n: last_stage_df})
print(f"{strs}{strs}{strs}")
for i in range(len(self.stage_indicator_list[0]) - 1):
index = [n for n in range(len(f))]
stage_df = pd.DataFrame(index=index, columns=index)
num -= 1
for j in range(len(f)):
row = j
for k in range(j + 1):
gx = self.stage_indicator_df[f'department{num}'][k]
fx = last_stage_df[f"f{num + 1}"][row]
stage_df.iloc[j, k] = gx + fx
row -= 1
s_n = f"S{num}"
f_n = f"f{num}"
x_n = f'x{num}'
stage_df[f_n] = self.get_fs_and_xindex(stage_df)[0]
stage_df[x_n] = self.get_fs_and_xindex(stage_df.iloc[:, :-1])[1]
# 将NaN值替换为字符”ד
stage_df = stage_df.replace(np.nan, "×")
last_stage_df = stage_df
mm = len(self.stage_indicator_list[0]) - 2
if i >= mm:
continue
print(f"{strs}状态变量{s_n}下{strs}")
print(stage_df)
stage_df_dict.update({s_n: stage_df})
print(f"{strs}{strs}{strs}")
first_stage_df = pd.DataFrame(last_stage_df.iloc[-1, :].values)
first_stage_df = first_stage_df.T
new_index = last_stage_df.index.tolist()[-1]
first_stage_df.index = [new_index]
first_stage_df.columns = last_stage_df.columns.tolist()
print(f"{strs}状态变量{s_n}下{strs}")
print(first_stage_df)
print(f"{strs}{strs}{strs}")
stage_df_dict.update({s_n: first_stage_df})
return [first_stage_df, stage_df_dict]
# 脚本自调试
if __name__ == '__main__':
# 阶段指标表格,按列顺序
stage_indicator_list = [[0, 0, 0],
[3, 5, 4],
[7, 10, 6],
[9, 11, 11],
[12, 11, 12],
[13, 11, 12]]
# 实例化对象
test = Discrete_Resource_Allocation_Problem(stage_indicator_list)
例题输出结果
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\python.exe H:/python学习/Dynamic_Programming/DiscreteResourceAllocationProblem.py
********************状态变量S3下********************
0 1 2 3 4 5 f3 x3
0 0 × × × × × 0 [0]
1 × 4 × × × × 4 [1]
2 × × 6 × × × 6 [2]
3 × × × 11 × × 11 [3]
4 × × × × 12 × 12 [4]
5 × × × × × 12 12 [5]
************************************************************
********************状态变量S2下********************
0 1 2 3 4 5 f2 x2
0 0 × × × × × 0 [0]
1 4 5 × × × × 5 [1]
2 6 9 10 × × × 10 [2]
3 11 11 14 11 × × 14 [2]
4 12 16 16 15 11 × 16 [1, 2]
5 12 17 21 17 15 11 21 [2]
************************************************************
********************状态变量S1下********************
0 1 2 3 4 5 f1 x1
5 21 19 21 19 17 13 21 [0, 2]
************************************************************
进程已结束,退出代码为 0
例题结果分析
将存入excel工作簿的表格截取出来,3个阶段(逆推)结果如下:
| S3 | 0 | 1 | 2 | 3 | 4 | 5 | f3 | x3 |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | × | × | × | × | × | 0 | [0] |
| 1 | × | 4 | × | × | × | × | 4 | [1] |
| 2 | × | × | 6 | × | × | × | 6 | [2] |
| 3 | × | × | × | 11 | × | × | 11 | [3] |
| 4 | × | × | × | × | 12 | × | 12 | [4] |
| 5 | × | × | × | × | × | 12 | 12 | [5] |
| S2 | 0 | 1 | 2 | 3 | 4 | 5 | f2 | x2 |
|---|---|---|---|---|---|---|---|---|
| 0 | 0 | × | × | × | × | × | 0 | [0] |
| 1 | 4 | 5 | × | × | × | × | 5 | [1] |
| 2 | 6 | 9 | 10 | × | × | × | 10 | [2] |
| 3 | 11 | 11 | 14 | 11 | × | × | 14 | [2] |
| 4 | 12 | 16 | 16 | 15 | 11 | × | 16 | [1, 2] |
| 5 | 12 | 17 | 21 | 17 | 15 | 11 | 21 | [2] |
| S1 | 0 | 1 | 2 | 3 | 4 | 5 | f1 | x1 |
|---|---|---|---|---|---|---|---|---|
| 5 | 21 | 19 | 21 | 19 | 17 | 13 | 21 | [0, 2] |
按计算表格的顺序反推,可知最优分配方案有两个:
由于x1*=0,根据s2=s1-x1*=5-0=5,查表知x2*=2,由s3=s2-x2*=5-2=3,故x3*=s3=3。即得甲工厂分配0台,乙工厂分配2台,丙工厂分配3台。
由于x1*=2,根据s2=s1-x1*=5-2=3,查表知x2*=2,由s3=s2-x2*=3-2=1,故x3*=s3=1。即得甲工厂分配2台,乙工厂分配2台,丙工厂分配1台。
以上两个分配方案所得到的总盈利均为21万元。
2、生产与存储问题
程序参数说明
由于该问题需要输入参数较多,故在此做参数说明
需要输入的参数如下:
Production_And_Storage_Problems(demand_table=None,fixed_cost=0,unit_product_cost=None,max_production_lot=np.inf,unit_storage_cost=None,warehouse_volume=np.inf,initial_inventory=0, end_stage_inventory=0, unproduced_charge=0)
<param1> demand_table: 需求表格(二维数组[[a,b,c,d……]]),默认为None
<param2> fixed_cost: 固定成本,默认为0
<param3> unit_product_cost:单位生产费用(一维数组[a,b,c,d……]),默认为None
<param4> max_production_lot: 最大生产批量,默认无上限
<param5> unit_storage_cost: 单位存储费用(一维数组[a,b,c,d……]),默认为0
<param6> warehouse_volume: 仓库容积,默认无穷大
<param7> initial_inventory: 初始库存,默认为0
<param8> end_stage_inventory: 阶段末库存,默认为0
<param9> unproduced_charge:未生产产品收费为多少,默认为0
例题1——初末仓库存储均为0

确定输入参数
选填参数也填入了,便于理解,可以不用填
demand = [[3, 2, 3, 2]] # 二维数组,用来形成表格,对应每个阶段
fixed_cost = 2 # 固定成本
max_production_lot = np.inf # 最大生产批量,默认无上限
unit_storage_cost = [0.2, 0.2, 0.2, 0.2] # 单位存储费用,对应每个阶段
unit_product_cost = [1, 1, 1, 1] # 单位产品费用,对应每个阶段
warehouse_volume = np.inf # 仓库容积,默认无上限
initial_inventory = 0 # 初始仓库库存
end_stage_inventory = 0 # 阶段末仓库库存
unproduced_charge = 0 # 未生产收费,默认为为固定成本
例一python源代码
import sys
import pandas as pd, numpy as np, copy
# 动态规划——生产和存储问题(生产计划问题)
class Production_And_Storage_Problems(object):
# 初始化函数
def __init__(self, demand_table=None, fixed_cost=0, unit_product_cost=None, max_production_lot=np.inf,
unit_storage_cost=None,
warehouse_volume=np.inf, initial_inventory=0, end_stage_inventory=0, unproduced_charge=0):
try:
self.demand_table = pd.DataFrame(data=demand_table, index=['demand'],
columns=[f"{i + 1}" for i in range(len(demand_table[0]))]) # 需求表格
self.fixed_cost = fixed_cost # 固定成本
self.unit_product_cost = unit_product_cost # 单位产品成本
self.warehouse_volume = warehouse_volume # 仓库容积
self.max_production_lot = max_production_lot # 最大生产批量
self.unit_storage_cost = unit_storage_cost # 单位存储费用
self.initial_inventory = initial_inventory # 初始库存,默认为0
self.end_stage_inventory = end_stage_inventory # 阶段末库存,默认为0
self.unproduced_charge = unproduced_charge # 未生产产品收费为多少
self.solve_value = self.back_pushing_solve()
self.stage_Df_dict = self.solve_value[1]
# 建立工作簿
self.writer = pd.ExcelWriter("动态规划——生产和存储问题.xlsx")
strs = "*" * 20
for keys in self.stage_Df_dict.keys():
# 删去inf行
self.stage_Df_dict[keys].drop(
self.stage_Df_dict[keys][self.stage_Df_dict[keys][f"f{keys[-1]}"] == np.inf].index, inplace=True)
self.stage_Df_dict[keys] = self.stage_Df_dict[keys].replace(np.inf, "×")
columnslist0 = self.stage_Df_dict[keys].columns.tolist()[:-2]
df = copy.deepcopy(self.stage_Df_dict[keys])
for i in range(len(columnslist0)):
columnslist = list(set(df.iloc[:, i].tolist()))
if len(columnslist) == 1 and columnslist[0] == "×":
self.stage_Df_dict[keys].drop(columns=i, inplace=True)
# 结果展示
print(f"{strs}状态变量{keys}下{strs}")
print(self.stage_Df_dict[keys])
# 存入工作簿
self.stage_Df_dict[keys].to_excel(self.writer, sheet_name=f"{keys}状态下")
try:
self.writer.save()
except:
self.writer.close()
except:
strs = "*" * 10
print(f"{strs}当前实例对象不具备解决问题功能,仅作为打印类使用说明对象{strs}")
# 类模块说明
def __str__(self):
return ''' 需要输入的参数如下:
<param1> demand_table: 需求表格(二维数组[[a,b,c,d……]])(必填)
<param2> fixed_cost: 固定成本(必填)
<param3> unit_product_cost:单位生产费用(一维数组[a,b,c,d……])(必填)
<param4> max_production_lot: 最大生产批量,默认无上限(选填)
<param5> unit_storage_cost: 单位存储费用(一维数组[a,b,c,d……])(必填)
<param6> warehouse_volume: 仓库容积,默认无穷大(选填)
<param7> initial_inventory: 初始库存,默认为0(选填)
<param8> end_stage_inventory: 阶段末库存,默认为0(选填)
<param9> unproduced_charge:未生产产品收费为多少,默认为0(选填)'''
# 获取第k阶段的生产成本
def get_stage_production_cost(self, stage, xk):
'''
:param xk: 决策变量 表示第k阶段生产量
:return: 第k阶段的生产成本
'''
if self.unproduced_charge == 0:
if xk == 0:
ck_xk = 0
elif xk > self.max_production_lot:
ck_xk = np.inf
else:
ck_xk = self.fixed_cost + self.unit_product_cost[stage - 1] * xk
else:
if xk == 0:
ck_xk = self.unproduced_charge
elif xk > self.max_production_lot:
ck_xk = np.inf
else:
ck_xk = self.fixed_cost + self.unit_product_cost[stage - 1] * xk
return ck_xk
# 获取第k阶段的存储成本
def get_stage_storage_cost(self, sk, xk, dk):
'''
:param sk: 状态变量,第k阶段开始时的库存量
:param xk: 决策变量 表示第k阶段生产量
:param dk: 第k阶段,输入为阶段数字
:return: 第k阶段的存储成本
'''
dk0 = dk
dk = self.demand_table.loc['demand', f"{dk}"]
hk_xk = self.unit_storage_cost[dk0 - 1] * (sk + xk - dk)
return hk_xk
# 获取列表中相同元素位置
def get_same_element(selfl, lists, find_value):
index_list = []
k = 0
for value in lists:
if value == find_value:
index_list.append(k)
k += 1
return index_list
# 获取最优指标函数值fk(sk)和决策变量值xknp.inf
def get_fs_and_xindex(self, df):
df1 = copy.deepcopy(df)
df1 = df1.replace("×", np.inf)
fs_list = []
x_list = []
for i in range(len(df1.values.tolist())):
fs_list.append(min(df1.iloc[i, :].tolist()))
x = self.get_same_element(df1.iloc[i, :].tolist(), min(df1.iloc[i, :].tolist()))
x_list.append(f"{x}")
return [fs_list, x_list]
# 逆推法
def back_pushing_solve(self):
stage_df_dict = {}
# 阶段列表
s_x_list = [i for i in range(len(self.demand_table.values.tolist()[0]))]
# 逆推法第一个阶段
# 第n阶段数
stage = len(s_x_list)
# xk(第k阶段生产量)允许状态列表(为方便起见,默认下限为0,只设定上限为在“从第k阶段往后的需求量之和)-第k阶段的存储量”和最大生产批量之间取最小值)
allowable_state_list = [i for i in range(
min([self.demand_table.loc['demand', f"{stage}":].values.sum(), self.max_production_lot]) + 1)]
# 第n阶段(最后)存储量允许状态列表(只设上限为:在“(最后阶段需求量+最终仓库剩余存储量-第k阶段生产量)的最大值”和“仓库存储容积上限”当中取最小值)
s_allowable_state_list = [i for i in range(
min([self.end_stage_inventory + self.demand_table.loc['demand', f"{stage}"], self.warehouse_volume]) + 1)]
last_stage_df = pd.DataFrame(index=s_allowable_state_list, columns=allowable_state_list)
# 填写逆推法第一阶段表格
for i in range(len(s_allowable_state_list)):
for j in range(len(allowable_state_list)):
# 在满足决策变量xk的约束条件下才能计算表格中数据(xk要满足:(1)xk+dk(第k阶段生产+库存的总量)<=“从第k阶段开始到第n阶段结束所需要的总的需求量”且xk<=“最大生产批量”中最小值,(2)xk>=0且xk>=dk-sk(第k阶段的需求量-第k阶段存储量))
if i + j - self.demand_table.loc['demand', f"{stage}"] >= 0 and max(
[self.demand_table.loc['demand', f"{stage}"] - i, 0]) <= j <= min(
[self.demand_table.loc['demand', f"{stage}":].values.sum() - i, self.max_production_lot]):
# 生产成本
c = self.get_stage_production_cost(stage, j)
# 存储成本
h = self.get_stage_storage_cost(i, j, stage)
# 最终库存存储成本
h_last = self.end_stage_inventory * self.unit_storage_cost[stage - 1]
last_stage_df.iloc[i, j] = c + h + h_last
last_stage_df = last_stage_df.replace(np.nan, "×")
# 添加最优指标函数值fk(sk)和决策变量值xk列
s_n = f"S{stage}"
f_n = f"f{stage}"
x_n = f'x{stage}'
last_stage_df[f_n] = self.get_fs_and_xindex(last_stage_df)[0]
last_stage_df[x_n] = self.get_fs_and_xindex(last_stage_df.iloc[:, :-1])[1]
stage_df_dict.update({s_n: last_stage_df})
# 进入迭代,更新表格
for i in range(len(s_x_list) - 1):
# 阶段-1
stage -= 1
# xk(第k阶段生产量)允许状态列表(为方便起见,默认下限为0,只设定上限为在“从第k阶段往后的需求量之和)-第k阶段的存储量”和最大生产批量之间取最小值)
allowable_state_list = [i for i in range(
min([self.demand_table.loc['demand', f"{stage}":].values.sum(), self.max_production_lot]) + 1)]
# 第k阶段(中间阶段)存储量允许状态列表(只设上限为:在“(从第k阶段往后的需求量之和+最终仓库剩余存储量-第k阶段生产量)的最大值”、“从第1阶段到第k阶段最大生产量之和+初始时仓库存储量-从第1阶段到第k阶段需求量之和”、“仓库存储容积上限”当中取最小值)
s_allowable_state_list = [i for i in
range(min([self.warehouse_volume,
self.demand_table.loc['demand',
f"{stage}":].values.sum() + self.end_stage_inventory,
self.max_production_lot * len(self.demand_table.loc['demand',
:f"{stage - 1}"].values.tolist()) - self.demand_table.loc[
'demand',
:f"{stage - 1}"].values.sum() + self.initial_inventory]) + 1)]
stage_df = pd.DataFrame(index=s_allowable_state_list, columns=allowable_state_list)
for j in range(len(s_allowable_state_list)):
for k in range(len(allowable_state_list)):
# 在满足决策变量xk的约束条件下才能计算表格中数据(xk要满足:(1)xk+dk(第k阶段生产+库存总量)<=“从第k阶段开始到第n阶段结束所需要的总的需求量”且xk<=“最大生产批量”中最小值,(2)xk>=0且xk>=dk-sk(第k阶段的需求量-第k阶段存储量))
if j + k - self.demand_table.loc['demand', f"{stage}"] >= 0 and min(
[self.demand_table.loc['demand', f"{stage}":].values.sum() - j,
self.max_production_lot]) >= k >= max(
[self.demand_table.loc['demand', f"{stage}"] - j, 0]):
row = j + k - self.demand_table.loc['demand', f"{stage}"]
# 生产成本
c = self.get_stage_production_cost(stage, k)
# 存储成本
h = self.get_stage_storage_cost(j, k, stage)
# f
f = last_stage_df[f"f{stage + 1}"][row]
# 最终库存存储成本
h_last = self.end_stage_inventory * self.unit_storage_cost[stage - 1]
stage_df.iloc[j, k] = c + h + f + h_last
s_n = f"S{stage}"
f_n = f"f{stage}"
x_n = f'x{stage}'
# 将缺失值替换"×"
stage_df = stage_df.replace(np.nan, "×")
# 添加最优指标函数值fk(sk)和决策变量值xk列
stage_df[f_n] = self.get_fs_and_xindex(stage_df)[0]
stage_df[x_n] = self.get_fs_and_xindex(stage_df.iloc[:, :-1])[1]
stage_df = stage_df.replace(np.nan, "×")
# 更新前一个表格(迭代)
last_stage_df = stage_df
mm = len(s_x_list) - 2
if i >= mm:
continue
# 存储每一个表格信息,以免迭代过程不断覆盖前一个表格
stage_df_dict.update({s_n: stage_df})
# 获取逆推法得到的第一阶段的表格
last_stage_df = last_stage_df.loc[self.initial_inventory, :]
columns = last_stage_df.index.tolist()
index = [f"{self.initial_inventory}"]
first_stage_df = pd.DataFrame(last_stage_df)
first_stage_df = first_stage_df.T
first_stage_df.index = index
first_stage_df.columns = columns
# 存入字典
stage_df_dict.update({s_n: first_stage_df})
return [first_stage_df, stage_df_dict]
# 顺推法
def forward_pushing_solve(self):
print("该算法暂未实现,敬请期待")
sys.exit()
# 脚本自调试
if __name__ == '__main__':
# 输出类模块参数使用说明
Instructions = Production_And_Storage_Problems()
print(Instructions)
# 输入需求数组
demand = [[3, 2, 3, 2]] # 二维数组,用来形成表格,对应每个阶段
fixed_cost = 2 # 固定成本
max_production_lot = np.inf # 最大生产批量,默认无上限
unit_storage_cost = [0.2, 0.2, 0.2, 0.2] # 单位存储费用,对应每个阶段
unit_product_cost = [1, 1, 1, 1] # 单位产品费用,对应每个阶段
warehouse_volume = np.inf # 仓库容积,默认无上限
initial_inventory = 0 # 初始仓库库存
end_stage_inventory = 0 # 阶段末仓库库存
unproduced_charge = 0 # 未生产收费,默认为为固定成本
# 实例化
test = Production_And_Storage_Problems(demand_table=demand,
fixed_cost=fixed_cost,
unit_storage_cost=unit_storage_cost,
max_production_lot=max_production_lot,
initial_inventory=initial_inventory,
end_stage_inventory=end_stage_inventory,
unit_product_cost=unit_product_cost,
unproduced_charge=unproduced_charge,
warehouse_volume=warehouse_volume)
例1输出结果
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\python.exe H:/python学习/Dynamic_Programming/ProductionAndStorageProblems.py
**********当前实例对象不具备解决问题功能,仅作为打印类使用说明对象**********
需要输入的参数如下:
<param1> demand_table: 需求表格(二维数组[[a,b,c,d……]])(必填)
<param2> fixed_cost: 固定成本(必填)
<param3> unit_product_cost:单位生产费用(一维数组[a,b,c,d……])(必填)
<param4> max_production_lot: 最大生产批量,默认无上限(选填)
<param5> unit_storage_cost: 单位存储费用(一维数组[a,b,c,d……])(必填)
<param6> warehouse_volume: 仓库容积,默认无穷大(选填)
<param7> initial_inventory: 初始库存,默认为0(选填)
<param8> end_stage_inventory: 阶段末库存,默认为0(选填)
<param9> unproduced_charge:未生产产品收费为多少,默认为0(选填)
********************状态变量S4下********************
0 1 2 f4 x4
0 × × 4 4.0 [2]
1 × 3 × 3.0 [1]
2 0 × × 0.0 [0]
********************状态变量S3下********************
0 1 2 3 4 5 f3 x3
0 × × × 9 9.2 7.4 7.4 [5]
1 × × 8 8.2 6.4 × 6.4 [4]
2 × 7 7.2 5.4 × × 5.4 [3]
3 4 6.2 4.4 × × × 4.0 [0]
4 3.2 3.4 × × × × 3.2 [0]
5 0.4 × × × × × 0.4 [0]
********************状态变量S2下********************
0 1 2 3 4 5 6 7 f2 x2
0 × × 11.4 11.6 11.8 11.6 12 10.4 10.4 [7]
1 × 10.4 10.6 10.8 10.6 11 9.4 × 9.4 [6]
2 7.4 9.6 9.8 9.6 10 8.4 × × 7.4 [0]
3 6.6 8.8 8.6 9 7.4 × × × 6.6 [0]
4 5.8 7.6 8 6.4 × × × × 5.8 [0]
5 4.6 7 5.4 × × × × × 4.6 [0]
6 4 4.4 × × × × × × 4.0 [0]
7 1.4 × × × × × × × 1.4 [0]
********************状态变量S1下********************
3 4 5 6 7 8 9 10 f1 x1
0 15.4 15.6 14.8 15.2 15.6 15.6 16.2 14.8 14.8 [5, 10]
进程已结束,退出代码为 0
例1结果分析
将存入excel工作簿的表格截取出来,4个阶段(逆推)结果如下:
| S4 | 0 | 1 | 2 | f4 | x4 |
|---|---|---|---|---|---|
| 0 | × | × | 4 | 4 | [2] |
| 1 | × | 3 | × | 3 | [1] |
| 2 | 0 | × | × | 0 | [0] |
| S3 | 0 | 1 | 2 | 3 | 4 | 5 | f3 | x3 |
|---|---|---|---|---|---|---|---|---|
| 0 | × | × | × | 9 | 9.2 | 7.4 | 7.4 | [5] |
| 1 | × | × | 8 | 8.2 | 6.4 | × | 6.4 | [4] |
| 2 | × | 7 | 7.2 | 5.4 | × | × | 5.4 | [3] |
| 3 | 4 | 6.2 | 4.4 | × | × | × | 4 | [0] |
| 4 | 3.2 | 3.4 | × | × | × | × | 3.2 | [0] |
| 5 | 0.4 | × | × | × | × | × | 0.4 | [0] |
| S2 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | f2 | x2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | × | × | 11.4 | 11.6 | 11.8 | 11.6 | 12 | 10.4 | 10.4 | [7] |
| 1 | × | 10.4 | 10.6 | 10.8 | 10.6 | 11 | 9.4 | × | 9.4 | [6] |
| 2 | 7.4 | 9.6 | 9.8 | 9.6 | 10 | 8.4 | × | × | 7.4 | [0] |
| 3 | 6.6 | 8.8 | 8.6 | 9 | 7.4 | × | × | × | 6.6 | [0] |
| 4 | 5.8 | 7.6 | 8 | 6.4 | × | × | × | × | 5.8 | [0] |
| 5 | 4.6 | 7 | 5.4 | × | × | × | × | × | 4.6 | [0] |
| 6 | 4 | 4.4 | × | × | × | × | × | × | 4 | [0] |
| 7 | 1.4 | × | × | × | × | × | × | × | 1.4 | [0] |
| S1 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | f1 | x1 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 15.4 | 15.6 | 14.8 | 15.2 | 15.6 | 15.6 | 16.2 | 14.8 | 14.8 | [5, 10] |
故最小费用是:14.8万元
最优策略为:(10,0,0,0),(5,0,5,0)
例题2——初始仓库存储不为0&仓库容量有限制

确定输入参数
demand = [[3, 4,3]] # 二维数组,用来形成表格,对应每个阶段
fixed_cost = 8 # 固定成本
max_production_lot = 6 # 最大生产批量,默认无上限
unit_storage_cost = [2,2,2] # 单位存储费用,对应每个阶段
unit_product_cost = [2,2,2] # 单位产品费用,对应每个阶段
warehouse_volume = 4 # 仓库容积,默认无上限
initial_inventory = 1 # 初始仓库库存
end_stage_inventory = 0 # 阶段末仓库库存
unproduced_charge = 8 # 未生产收费,默认为为固定成本
例二python源代码
import sys
import pandas as pd, numpy as np, copy
# 动态规划——生产和存储问题(生产计划问题)
class Production_And_Storage_Problems(object):
# 初始化函数
def __init__(self, demand_table=None, fixed_cost=0, unit_product_cost=None, max_production_lot=np.inf,
unit_storage_cost=None,
warehouse_volume=np.inf, initial_inventory=0, end_stage_inventory=0, unproduced_charge=0):
try:
self.demand_table = pd.DataFrame(data=demand_table, index=['demand'],
columns=[f"{i + 1}" for i in range(len(demand_table[0]))]) # 需求表格
self.fixed_cost = fixed_cost # 固定成本
self.unit_product_cost = unit_product_cost # 单位产品成本
self.warehouse_volume = warehouse_volume # 仓库容积
self.max_production_lot = max_production_lot # 最大生产批量
self.unit_storage_cost = unit_storage_cost # 单位存储费用
self.initial_inventory = initial_inventory # 初始库存,默认为0
self.end_stage_inventory = end_stage_inventory # 阶段末库存,默认为0
self.unproduced_charge = unproduced_charge # 未生产产品收费为多少
self.solve_value = self.back_pushing_solve()
self.stage_Df_dict = self.solve_value[1]
# 建立工作簿
self.writer = pd.ExcelWriter("动态规划——生产和存储问题.xlsx")
strs = "*" * 20
for keys in self.stage_Df_dict.keys():
# 删去inf行
self.stage_Df_dict[keys].drop(
self.stage_Df_dict[keys][self.stage_Df_dict[keys][f"f{keys[-1]}"] == np.inf].index, inplace=True)
self.stage_Df_dict[keys] = self.stage_Df_dict[keys].replace(np.inf, "×")
columnslist0 = self.stage_Df_dict[keys].columns.tolist()[:-2]
df = copy.deepcopy(self.stage_Df_dict[keys])
for i in range(len(columnslist0)):
columnslist = list(set(df.iloc[:, i].tolist()))
if len(columnslist) == 1 and columnslist[0] == "×":
self.stage_Df_dict[keys].drop(columns=i, inplace=True)
# 结果展示
print(f"{strs}状态变量{keys}下{strs}")
print(self.stage_Df_dict[keys])
# 存入工作簿
self.stage_Df_dict[keys].to_excel(self.writer, sheet_name=f"{keys}状态下")
try:
self.writer.save()
except:
self.writer.close()
except:
strs = "*" * 10
print(f"{strs}当前实例对象不具备解决问题功能,仅作为打印类使用说明对象{strs}")
# 类模块说明
def __str__(self):
return ''' 需要输入的参数如下:
<param1> demand_table: 需求表格(二维数组[[a,b,c,d……]])(必填)
<param2> fixed_cost: 固定成本(必填)
<param3> unit_product_cost:单位生产费用(一维数组[a,b,c,d……])(必填)
<param4> max_production_lot: 最大生产批量,默认无上限(选填)
<param5> unit_storage_cost: 单位存储费用(一维数组[a,b,c,d……])(必填)
<param6> warehouse_volume: 仓库容积,默认无穷大(选填)
<param7> initial_inventory: 初始库存,默认为0(选填)
<param8> end_stage_inventory: 阶段末库存,默认为0(选填)
<param9> unproduced_charge:未生产产品收费为多少,默认为0(选填)'''
# 获取第k阶段的生产成本
def get_stage_production_cost(self, stage, xk):
'''
:param xk: 决策变量 表示第k阶段生产量
:return: 第k阶段的生产成本
'''
if self.unproduced_charge == 0:
if xk == 0:
ck_xk = 0
elif xk > self.max_production_lot:
ck_xk = np.inf
else:
ck_xk = self.fixed_cost + self.unit_product_cost[stage - 1] * xk
else:
if xk == 0:
ck_xk = self.unproduced_charge
elif xk > self.max_production_lot:
ck_xk = np.inf
else:
ck_xk = self.fixed_cost + self.unit_product_cost[stage - 1] * xk
return ck_xk
# 获取第k阶段的存储成本
def get_stage_storage_cost(self, sk, xk, dk):
'''
:param sk: 状态变量,第k阶段开始时的库存量
:param xk: 决策变量 表示第k阶段生产量
:param dk: 第k阶段,输入为阶段数字
:return: 第k阶段的存储成本
'''
dk0 = dk
dk = self.demand_table.loc['demand', f"{dk}"]
hk_xk = self.unit_storage_cost[dk0 - 1] * (sk + xk - dk)
return hk_xk
# 获取列表中相同元素位置
def get_same_element(selfl, lists, find_value):
index_list = []
k = 0
for value in lists:
if value == find_value:
index_list.append(k)
k += 1
return index_list
# 获取最优指标函数值fk(sk)和决策变量值xknp.inf
def get_fs_and_xindex(self, df):
df1 = copy.deepcopy(df)
df1 = df1.replace("×", np.inf)
fs_list = []
x_list = []
for i in range(len(df1.values.tolist())):
fs_list.append(min(df1.iloc[i, :].tolist()))
x = self.get_same_element(df1.iloc[i, :].tolist(), min(df1.iloc[i, :].tolist()))
x_list.append(f"{x}")
return [fs_list, x_list]
# 逆推法
def back_pushing_solve(self):
stage_df_dict = {}
# 阶段列表
s_x_list = [i for i in range(len(self.demand_table.values.tolist()[0]))]
# 逆推法第一个阶段
# 第n阶段数
stage = len(s_x_list)
# xk(第k阶段生产量)允许状态列表(为方便起见,默认下限为0,只设定上限为在“从第k阶段往后的需求量之和)-第k阶段的存储量”和最大生产批量之间取最小值)
allowable_state_list = [i for i in range(
min([self.demand_table.loc['demand', f"{stage}":].values.sum(), self.max_production_lot]) + 1)]
# 第n阶段(最后)存储量允许状态列表(只设上限为:在“(最后阶段需求量+最终仓库剩余存储量-第k阶段生产量)的最大值”和“仓库存储容积上限”当中取最小值)
s_allowable_state_list = [i for i in range(
min([self.end_stage_inventory + self.demand_table.loc['demand', f"{stage}"], self.warehouse_volume]) + 1)]
last_stage_df = pd.DataFrame(index=s_allowable_state_list, columns=allowable_state_list)
# 填写逆推法第一阶段表格
for i in range(len(s_allowable_state_list)):
for j in range(len(allowable_state_list)):
# 在满足决策变量xk的约束条件下才能计算表格中数据(xk要满足:(1)xk+dk(第k阶段生产+库存的总量)<=“从第k阶段开始到第n阶段结束所需要的总的需求量”且xk<=“最大生产批量”中最小值,(2)xk>=0且xk>=dk-sk(第k阶段的需求量-第k阶段存储量))
if i + j - self.demand_table.loc['demand', f"{stage}"] >= 0 and max(
[self.demand_table.loc['demand', f"{stage}"] - i, 0]) <= j <= min(
[self.demand_table.loc['demand', f"{stage}":].values.sum() - i, self.max_production_lot]):
# 生产成本
c = self.get_stage_production_cost(stage, j)
# 存储成本
h = self.get_stage_storage_cost(i, j, stage)
# 最终库存存储成本
h_last = self.end_stage_inventory * self.unit_storage_cost[stage - 1]
last_stage_df.iloc[i, j] = c + h + h_last
last_stage_df = last_stage_df.replace(np.nan, "×")
# 添加最优指标函数值fk(sk)和决策变量值xk列
s_n = f"S{stage}"
f_n = f"f{stage}"
x_n = f'x{stage}'
last_stage_df[f_n] = self.get_fs_and_xindex(last_stage_df)[0]
last_stage_df[x_n] = self.get_fs_and_xindex(last_stage_df.iloc[:, :-1])[1]
stage_df_dict.update({s_n: last_stage_df})
# 进入迭代,更新表格
for i in range(len(s_x_list) - 1):
# 阶段-1
stage -= 1
# xk(第k阶段生产量)允许状态列表(为方便起见,默认下限为0,只设定上限为在“从第k阶段往后的需求量之和)-第k阶段的存储量”和最大生产批量之间取最小值)
allowable_state_list = [i for i in range(
min([self.demand_table.loc['demand', f"{stage}":].values.sum(), self.max_production_lot]) + 1)]
# 第k阶段(中间阶段)存储量允许状态列表(只设上限为:在“(从第k阶段往后的需求量之和+最终仓库剩余存储量-第k阶段生产量)的最大值”、“从第1阶段到第k阶段最大生产量之和+初始时仓库存储量-从第1阶段到第k阶段需求量之和”、“仓库存储容积上限”当中取最小值)
s_allowable_state_list = [i for i in
range(min([self.warehouse_volume,
self.demand_table.loc['demand',
f"{stage}":].values.sum() + self.end_stage_inventory,
self.max_production_lot * len(self.demand_table.loc['demand',
:f"{stage - 1}"].values.tolist()) - self.demand_table.loc[
'demand',
:f"{stage - 1}"].values.sum() + self.initial_inventory]) + 1)]
stage_df = pd.DataFrame(index=s_allowable_state_list, columns=allowable_state_list)
for j in range(len(s_allowable_state_list)):
for k in range(len(allowable_state_list)):
# 在满足决策变量xk的约束条件下才能计算表格中数据(xk要满足:(1)xk+dk(第k阶段生产+库存总量)<=“从第k阶段开始到第n阶段结束所需要的总的需求量”且xk<=“最大生产批量”中最小值,(2)xk>=0且xk>=dk-sk(第k阶段的需求量-第k阶段存储量))
if j + k - self.demand_table.loc['demand', f"{stage}"] >= 0 and min(
[self.demand_table.loc['demand', f"{stage}":].values.sum() - j,
self.max_production_lot]) >= k >= max(
[self.demand_table.loc['demand', f"{stage}"] - j, 0]):
row = j + k - self.demand_table.loc['demand', f"{stage}"]
# 生产成本
c = self.get_stage_production_cost(stage, k)
# 存储成本
h = self.get_stage_storage_cost(j, k, stage)
# f
f = last_stage_df[f"f{stage + 1}"][row]
# 最终库存存储成本
h_last = self.end_stage_inventory * self.unit_storage_cost[stage - 1]
stage_df.iloc[j, k] = c + h + f + h_last
s_n = f"S{stage}"
f_n = f"f{stage}"
x_n = f'x{stage}'
# 将缺失值替换"×"
stage_df = stage_df.replace(np.nan, "×")
# 添加最优指标函数值fk(sk)和决策变量值xk列
stage_df[f_n] = self.get_fs_and_xindex(stage_df)[0]
stage_df[x_n] = self.get_fs_and_xindex(stage_df.iloc[:, :-1])[1]
stage_df = stage_df.replace(np.nan, "×")
# 更新前一个表格(迭代)
last_stage_df = stage_df
mm = len(s_x_list) - 2
if i >= mm:
continue
# 存储每一个表格信息,以免迭代过程不断覆盖前一个表格
stage_df_dict.update({s_n: stage_df})
# 获取逆推法得到的第一阶段的表格
last_stage_df = last_stage_df.loc[self.initial_inventory, :]
columns = last_stage_df.index.tolist()
index = [f"{self.initial_inventory}"]
first_stage_df = pd.DataFrame(last_stage_df)
first_stage_df = first_stage_df.T
first_stage_df.index = index
first_stage_df.columns = columns
# 存入字典
stage_df_dict.update({s_n: first_stage_df})
return [first_stage_df, stage_df_dict]
# 顺推法
def forward_pushing_solve(self):
print("该算法暂未实现,敬请期待")
sys.exit()
# 脚本自调试
if __name__ == '__main__':
# 输出类模块参数使用说明
Instructions = Production_And_Storage_Problems()
print(Instructions)
# 输入需求数组
demand = [[3, 4,3]] # 二维数组,用来形成表格,对应每个阶段
fixed_cost = 8 # 固定成本
max_production_lot = 6 # 最大生产批量,默认无上限
unit_storage_cost = [2,2,2] # 单位存储费用,对应每个阶段
unit_product_cost = [2,2,2] # 单位产品费用,对应每个阶段
warehouse_volume = 4 # 仓库容积,默认无上限
initial_inventory = 1 # 初始仓库库存
end_stage_inventory = 0 # 阶段末仓库库存
unproduced_charge = 8 # 未生产收费,默认为为固定成本
# 实例化
test = Production_And_Storage_Problems(demand_table=demand,
fixed_cost=fixed_cost,
unit_storage_cost=unit_storage_cost,
max_production_lot=max_production_lot,
initial_inventory=initial_inventory,
end_stage_inventory=end_stage_inventory,
unit_product_cost=unit_product_cost,
unproduced_charge=unproduced_charge,
warehouse_volume=warehouse_volume)
例2输出结果
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\python.exe H:/python学习/Dynamic_Programming/ProductionAndStorageProblems.py
**********当前实例对象不具备解决问题功能,仅作为打印类使用说明对象**********
需要输入的参数如下:
<param1> demand_table: 需求表格(二维数组[[a,b,c,d……]])(必填)
<param2> fixed_cost: 固定成本(必填)
<param3> unit_product_cost:单位生产费用(一维数组[a,b,c,d……])(必填)
<param4> max_production_lot: 最大生产批量,默认无上限(选填)
<param5> unit_storage_cost: 单位存储费用(一维数组[a,b,c,d……])(必填)
<param6> warehouse_volume: 仓库容积,默认无穷大(选填)
<param7> initial_inventory: 初始库存,默认为0(选填)
<param8> end_stage_inventory: 阶段末库存,默认为0(选填)
<param9> unproduced_charge:未生产产品收费为多少,默认为0(选填)
********************状态变量S3下********************
0 1 2 3 f3 x3
0 × × × 14 14.0 [3]
1 × × 12 × 12.0 [2]
2 × 10 × × 10.0 [1]
3 8 × × × 8.0 [0]
********************状态变量S2下********************
0 1 2 3 4 5 6 f2 x2
0 × × × × 30 32 34 30.0 [4]
1 × × × 28 30 32 34 28.0 [3]
2 × × 26 28 30 32 × 26.0 [2]
3 × 24 26 28 30 × × 24.0 [1]
4 22 24 26 28 × × × 22.0 [0]
********************状态变量S1下********************
2 3 4 5 6 f1 x1
1 42.0 44.0 46.0 48.0 50.0 42.0 [2]
进程已结束,退出代码为 0
例2结果分析
将存入excel工作簿的表格截取出来,3个阶段(逆推)结果如下:
| S3 | 0 | 1 | 2 | 3 | f3 | x3 |
|---|---|---|---|---|---|---|
| 0 | × | × | × | 14 | 14 | [3] |
| 1 | × | × | 12 | × | 12 | [2] |
| 2 | × | 10 | × | × | 10 | [1] |
| 3 | 8 | × | × | × | 8 | [0] |
| S2 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | f2 | x2 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | × | × | × | × | 30 | 32 | 34 | 30 | [4] |
| 1 | × | × | × | 28 | 30 | 32 | 34 | 28 | [3] |
| 2 | × | × | 26 | 28 | 30 | 32 | × | 26 | [2] |
| 3 | × | 24 | 26 | 28 | 30 | × | × | 24 | [1] |
| 4 | 22 | 24 | 26 | 28 | × | × | × | 22 | [0] |
| S1 | 2 | 3 | 4 | 5 | 6 | f1 | x1 |
|---|---|---|---|---|---|---|---|
| 1 | 42 | 44 | 46 | 48 | 50 | 42 | [2] |
最优值为:42
最优策略为:(2,4,3)
例题3——生产成本不固定
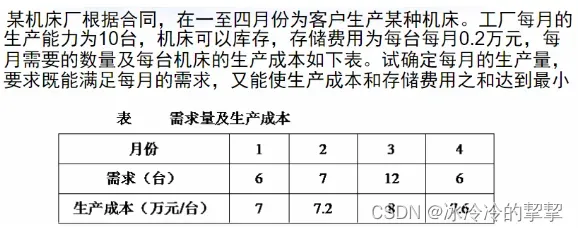
确定输入参数
demand = [[6,7,12,6]] # 二维数组,用来形成表格,对应每个阶段
fixed_cost = 0 # 固定成本
max_production_lot = 10 # 最大生产批量,默认无上限
unit_storage_cost = [0.2, 0.2, 0.2, 0.2] # 单位存储费用,对应每个阶段
unit_product_cost = [7,7.2,8,7.6] # 单位产品费用,对应每个阶段
warehouse_volume = np.inf # 仓库容积,默认无上限
initial_inventory = 0 # 初始仓库库存
end_stage_inventory = 0 # 阶段末仓库库存
unproduced_charge = 0 # 未生产收费,默认为为固定成本
例三python源代码
import sys
import pandas as pd, numpy as np, copy
# 动态规划——生产和存储问题(生产计划问题)
class Production_And_Storage_Problems(object):
# 初始化函数
def __init__(self, demand_table=None, fixed_cost=0, unit_product_cost=None, max_production_lot=np.inf,
unit_storage_cost=None,
warehouse_volume=np.inf, initial_inventory=0, end_stage_inventory=0, unproduced_charge=0):
try:
self.demand_table = pd.DataFrame(data=demand_table, index=['demand'],
columns=[f"{i + 1}" for i in range(len(demand_table[0]))]) # 需求表格
self.fixed_cost = fixed_cost # 固定成本
self.unit_product_cost = unit_product_cost # 单位产品成本
self.warehouse_volume = warehouse_volume # 仓库容积
self.max_production_lot = max_production_lot # 最大生产批量
self.unit_storage_cost = unit_storage_cost # 单位存储费用
self.initial_inventory = initial_inventory # 初始库存,默认为0
self.end_stage_inventory = end_stage_inventory # 阶段末库存,默认为0
self.unproduced_charge = unproduced_charge # 未生产产品收费为多少
self.solve_value = self.back_pushing_solve()
self.stage_Df_dict = self.solve_value[1]
# 建立工作簿
self.writer = pd.ExcelWriter("动态规划——生产和存储问题.xlsx")
strs = "*" * 20
for keys in self.stage_Df_dict.keys():
# 删去inf行
self.stage_Df_dict[keys].drop(
self.stage_Df_dict[keys][self.stage_Df_dict[keys][f"f{keys[-1]}"] == np.inf].index, inplace=True)
self.stage_Df_dict[keys] = self.stage_Df_dict[keys].replace(np.inf, "×")
columnslist0 = self.stage_Df_dict[keys].columns.tolist()[:-2]
df = copy.deepcopy(self.stage_Df_dict[keys])
for i in range(len(columnslist0)):
columnslist = list(set(df.iloc[:, i].tolist()))
if len(columnslist) == 1 and columnslist[0] == "×":
self.stage_Df_dict[keys].drop(columns=i, inplace=True)
# 结果展示
print(f"{strs}状态变量{keys}下{strs}")
print(self.stage_Df_dict[keys])
# 存入工作簿
self.stage_Df_dict[keys].to_excel(self.writer, sheet_name=f"{keys}状态下")
try:
self.writer.save()
except:
self.writer.close()
except:
strs = "*" * 10
print(f"{strs}当前实例对象不具备解决问题功能,仅作为打印类使用说明对象{strs}")
# 类模块说明
def __str__(self):
return ''' 需要输入的参数如下:
<param1> demand_table: 需求表格(二维数组[[a,b,c,d……]])(必填)
<param2> fixed_cost: 固定成本(必填)
<param3> unit_product_cost:单位生产费用(一维数组[a,b,c,d……])(必填)
<param4> max_production_lot: 最大生产批量,默认无上限(选填)
<param5> unit_storage_cost: 单位存储费用(一维数组[a,b,c,d……])(必填)
<param6> warehouse_volume: 仓库容积,默认无穷大(选填)
<param7> initial_inventory: 初始库存,默认为0(选填)
<param8> end_stage_inventory: 阶段末库存,默认为0(选填)
<param9> unproduced_charge:未生产产品收费为多少,默认为0(选填)'''
# 获取第k阶段的生产成本
def get_stage_production_cost(self, stage, xk):
'''
:param xk: 决策变量 表示第k阶段生产量
:return: 第k阶段的生产成本
'''
if self.unproduced_charge == 0:
if xk == 0:
ck_xk = 0
elif xk > self.max_production_lot:
ck_xk = np.inf
else:
ck_xk = self.fixed_cost + self.unit_product_cost[stage - 1] * xk
else:
if xk == 0:
ck_xk = self.unproduced_charge
elif xk > self.max_production_lot:
ck_xk = np.inf
else:
ck_xk = self.fixed_cost + self.unit_product_cost[stage - 1] * xk
return ck_xk
# 获取第k阶段的存储成本
def get_stage_storage_cost(self, sk, xk, dk):
'''
:param sk: 状态变量,第k阶段开始时的库存量
:param xk: 决策变量 表示第k阶段生产量
:param dk: 第k阶段,输入为阶段数字
:return: 第k阶段的存储成本
'''
dk0 = dk
dk = self.demand_table.loc['demand', f"{dk}"]
hk_xk = self.unit_storage_cost[dk0 - 1] * (sk + xk - dk)
return hk_xk
# 获取列表中相同元素位置
def get_same_element(selfl, lists, find_value):
index_list = []
k = 0
for value in lists:
if value == find_value:
index_list.append(k)
k += 1
return index_list
# 获取最优指标函数值fk(sk)和决策变量值xknp.inf
def get_fs_and_xindex(self, df):
df1 = copy.deepcopy(df)
df1 = df1.replace("×", np.inf)
fs_list = []
x_list = []
for i in range(len(df1.values.tolist())):
fs_list.append(min(df1.iloc[i, :].tolist()))
x = self.get_same_element(df1.iloc[i, :].tolist(), min(df1.iloc[i, :].tolist()))
x_list.append(f"{x}")
return [fs_list, x_list]
# 逆推法
def back_pushing_solve(self):
stage_df_dict = {}
# 阶段列表
s_x_list = [i for i in range(len(self.demand_table.values.tolist()[0]))]
# 逆推法第一个阶段
# 第n阶段数
stage = len(s_x_list)
# xk(第k阶段生产量)允许状态列表(为方便起见,默认下限为0,只设定上限为在“从第k阶段往后的需求量之和)-第k阶段的存储量”和最大生产批量之间取最小值)
allowable_state_list = [i for i in range(
min([self.demand_table.loc['demand', f"{stage}":].values.sum(), self.max_production_lot]) + 1)]
# 第n阶段(最后)存储量允许状态列表(只设上限为:在“(最后阶段需求量+最终仓库剩余存储量-第k阶段生产量)的最大值”和“仓库存储容积上限”当中取最小值)
s_allowable_state_list = [i for i in range(
min([self.end_stage_inventory + self.demand_table.loc['demand', f"{stage}"], self.warehouse_volume]) + 1)]
last_stage_df = pd.DataFrame(index=s_allowable_state_list, columns=allowable_state_list)
# 填写逆推法第一阶段表格
for i in range(len(s_allowable_state_list)):
for j in range(len(allowable_state_list)):
# 在满足决策变量xk的约束条件下才能计算表格中数据(xk要满足:(1)xk+dk(第k阶段生产+库存的总量)<=“从第k阶段开始到第n阶段结束所需要的总的需求量”且xk<=“最大生产批量”中最小值,(2)xk>=0且xk>=dk-sk(第k阶段的需求量-第k阶段存储量))
if i + j - self.demand_table.loc['demand', f"{stage}"] >= 0 and max(
[self.demand_table.loc['demand', f"{stage}"] - i, 0]) <= j <= min(
[self.demand_table.loc['demand', f"{stage}":].values.sum() - i, self.max_production_lot]):
# 生产成本
c = self.get_stage_production_cost(stage, j)
# 存储成本
h = self.get_stage_storage_cost(i, j, stage)
# 最终库存存储成本
h_last = self.end_stage_inventory * self.unit_storage_cost[stage - 1]
last_stage_df.iloc[i, j] = c + h + h_last
last_stage_df = last_stage_df.replace(np.nan, "×")
# 添加最优指标函数值fk(sk)和决策变量值xk列
s_n = f"S{stage}"
f_n = f"f{stage}"
x_n = f'x{stage}'
last_stage_df[f_n] = self.get_fs_and_xindex(last_stage_df)[0]
last_stage_df[x_n] = self.get_fs_and_xindex(last_stage_df.iloc[:, :-1])[1]
stage_df_dict.update({s_n: last_stage_df})
# 进入迭代,更新表格
for i in range(len(s_x_list) - 1):
# 阶段-1
stage -= 1
# xk(第k阶段生产量)允许状态列表(为方便起见,默认下限为0,只设定上限为在“从第k阶段往后的需求量之和)-第k阶段的存储量”和最大生产批量之间取最小值)
allowable_state_list = [i for i in range(
min([self.demand_table.loc['demand', f"{stage}":].values.sum(), self.max_production_lot]) + 1)]
# 第k阶段(中间阶段)存储量允许状态列表(只设上限为:在“(从第k阶段往后的需求量之和+最终仓库剩余存储量-第k阶段生产量)的最大值”、“从第1阶段到第k阶段最大生产量之和+初始时仓库存储量-从第1阶段到第k阶段需求量之和”、“仓库存储容积上限”当中取最小值)
s_allowable_state_list = [i for i in
range(min([self.warehouse_volume,
self.demand_table.loc['demand',
f"{stage}":].values.sum() + self.end_stage_inventory,
self.max_production_lot * len(self.demand_table.loc['demand',
:f"{stage - 1}"].values.tolist()) - self.demand_table.loc[
'demand',
:f"{stage - 1}"].values.sum() + self.initial_inventory]) + 1)]
stage_df = pd.DataFrame(index=s_allowable_state_list, columns=allowable_state_list)
for j in range(len(s_allowable_state_list)):
for k in range(len(allowable_state_list)):
# 在满足决策变量xk的约束条件下才能计算表格中数据(xk要满足:(1)xk+dk(第k阶段生产+库存总量)<=“从第k阶段开始到第n阶段结束所需要的总的需求量”且xk<=“最大生产批量”中最小值,(2)xk>=0且xk>=dk-sk(第k阶段的需求量-第k阶段存储量))
if j + k - self.demand_table.loc['demand', f"{stage}"] >= 0 and min(
[self.demand_table.loc['demand', f"{stage}":].values.sum() - j,
self.max_production_lot]) >= k >= max(
[self.demand_table.loc['demand', f"{stage}"] - j, 0]):
row = j + k - self.demand_table.loc['demand', f"{stage}"]
# 生产成本
c = self.get_stage_production_cost(stage, k)
# 存储成本
h = self.get_stage_storage_cost(j, k, stage)
# f
f = last_stage_df[f"f{stage + 1}"][row]
# 最终库存存储成本
h_last = self.end_stage_inventory * self.unit_storage_cost[stage - 1]
stage_df.iloc[j, k] = c + h + f + h_last
s_n = f"S{stage}"
f_n = f"f{stage}"
x_n = f'x{stage}'
# 将缺失值替换"×"
stage_df = stage_df.replace(np.nan, "×")
# 添加最优指标函数值fk(sk)和决策变量值xk列
stage_df[f_n] = self.get_fs_and_xindex(stage_df)[0]
stage_df[x_n] = self.get_fs_and_xindex(stage_df.iloc[:, :-1])[1]
stage_df = stage_df.replace(np.nan, "×")
# 更新前一个表格(迭代)
last_stage_df = stage_df
mm = len(s_x_list) - 2
if i >= mm:
continue
# 存储每一个表格信息,以免迭代过程不断覆盖前一个表格
stage_df_dict.update({s_n: stage_df})
# 获取逆推法得到的第一阶段的表格
last_stage_df = last_stage_df.loc[self.initial_inventory, :]
columns = last_stage_df.index.tolist()
index = [f"{self.initial_inventory}"]
first_stage_df = pd.DataFrame(last_stage_df)
first_stage_df = first_stage_df.T
first_stage_df.index = index
first_stage_df.columns = columns
# 存入字典
stage_df_dict.update({s_n: first_stage_df})
return [first_stage_df, stage_df_dict]
# 顺推法
def forward_pushing_solve(self):
print("该算法暂未实现,敬请期待")
sys.exit()
# 脚本自调试
if __name__ == '__main__':
# 输出类模块参数使用说明
Instructions = Production_And_Storage_Problems()
print(Instructions)
# 输入需求数组
demand = [[6,7,12,6]] # 二维数组,用来形成表格,对应每个阶段
fixed_cost = 0 # 固定成本
max_production_lot = 10 # 最大生产批量,默认无上限
unit_storage_cost = [0.2, 0.2, 0.2, 0.2] # 单位存储费用,对应每个阶段
unit_product_cost = [7,7.2,8,7.6] # 单位产品费用,对应每个阶段
warehouse_volume = np.inf # 仓库容积,默认无上限
initial_inventory = 0 # 初始仓库库存
end_stage_inventory = 0 # 阶段末仓库库存
unproduced_charge = 0 # 未生产收费,默认为为固定成本
# 实例化
test = Production_And_Storage_Problems(demand_table=demand,
fixed_cost=fixed_cost,
unit_storage_cost=unit_storage_cost,
max_production_lot=max_production_lot,
initial_inventory=initial_inventory,
end_stage_inventory=end_stage_inventory,
unit_product_cost=unit_product_cost,
unproduced_charge=unproduced_charge,
warehouse_volume=warehouse_volume)
例3输出结果
C:\Users\Administrator\AppData\Local\Programs\Python\Python36\python.exe H:/python学习/Dynamic_Programming/ProductionAndStorageProblems.py
**********当前实例对象不具备解决问题功能,仅作为打印类使用说明对象**********
需要输入的参数如下:
<param1> demand_table: 需求表格(二维数组[[a,b,c,d……]])(必填)
<param2> fixed_cost: 固定成本(必填)
<param3> unit_product_cost:单位生产费用(一维数组[a,b,c,d……])(必填)
<param4> max_production_lot: 最大生产批量,默认无上限(选填)
<param5> unit_storage_cost: 单位存储费用(一维数组[a,b,c,d……])(必填)
<param6> warehouse_volume: 仓库容积,默认无穷大(选填)
<param7> initial_inventory: 初始库存,默认为0(选填)
<param8> end_stage_inventory: 阶段末库存,默认为0(选填)
<param9> unproduced_charge:未生产产品收费为多少,默认为0(选填)
********************状态变量S4下********************
0 1 2 3 4 5 6 f4 x4
0 × × × × × × 45.6 45.6 [6]
1 × × × × × 38 × 38.0 [5]
2 × × × × 30.4 × × 30.4 [4]
3 × × × 22.8 × × × 22.8 [3]
4 × × 15.2 × × × × 15.2 [2]
5 × 7.6 × × × × × 7.6 [1]
6 0 × × × × × × 0.0 [0]
********************状态变量S3下********************
5 6 7 8 9 10 f3 x3
2 × × × × × 125.6 125.6 [10]
3 × × × × 117.6 118.2 117.6 [9]
4 × × × 109.6 110.2 110.8 109.6 [8]
5 × × 101.6 102.2 102.8 103.4 101.6 [7]
6 × 93.6 94.2 94.8 95.4 96.0 93.6 [6]
7 85.6 86.2 86.8 87.4 88 88.6 85.6 [5]
********************状态变量S2下********************
5 6 7 8 9 10 f2 x2
0 × × × × 190.8 190.2 190.2 [10]
1 × × × 183.6 183.0 182.4 182.4 [10]
2 × × 176.4 175.8 175.2 174.6 174.6 [10]
3 × 169.2 168.6 168 167.4 166.8 166.8 [10]
4 162 161.4 160.8 160.2 159.6 159.0 159.0 [10]
********************状态变量S1下********************
6 7 8 9 10 f1 x1
0 232.2 231.6 231.0 230.4 229.8 229.8 [10]
进程已结束,退出代码为 0
例3结果分析
将存入excel工作簿的表格截取出来,4个阶段(逆推)结果如下:
| S4 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | f4 | x4 |
|---|---|---|---|---|---|---|---|---|---|
| 0 | × | × | × | × | × | × | 45.6 | 45.6 | [6] |
| 1 | × | × | × | × | × | 38 | × | 38 | [5] |
| 2 | × | × | × | × | 30.4 | × | × | 30.4 | [4] |
| 3 | × | × | × | 22.8 | × | × | × | 22.8 | [3] |
| 4 | × | × | 15.2 | × | × | × | × | 15.2 | [2] |
| 5 | × | 7.6 | × | × | × | × | × | 7.6 | [1] |
| 6 | 0 | × | × | × | × | × | × | 0 | [0] |
| S3 | 5 | 6 | 7 | 8 | 9 | 10 | f3 | x3 |
|---|---|---|---|---|---|---|---|---|
| 2 | × | × | × | × | × | 125.6 | 125.6 | [10] |
| 3 | × | × | × | × | 117.6 | 118.2 | 117.6 | [9] |
| 4 | × | × | × | 109.6 | 110.2 | 110.8 | 109.6 | [8] |
| 5 | × | × | 101.6 | 102.2 | 102.8 | 103.4 | 101.6 | [7] |
| 6 | × | 93.6 | 94.2 | 94.8 | 95.4 | 96 | 93.6 | [6] |
| 7 | 85.6 | 86.2 | 86.8 | 87.4 | 88 | 88.6 | 85.6 | [5] |
| S2 | 5 | 6 | 7 | 8 | 9 | 10 | f2 | x2 |
|---|---|---|---|---|---|---|---|---|
| 0 | × | × | × | × | 190.8 | 190.2 | 190.2 | [10] |
| 1 | × | × | × | 183.6 | 183 | 182.4 | 182.4 | [10] |
| 2 | × | × | 176.4 | 175.8 | 175.2 | 174.6 | 174.6 | [10] |
| 3 | × | 169.2 | 168.6 | 168 | 167.4 | 166.8 | 166.8 | [10] |
| 4 | 162 | 161.4 | 160.8 | 160.2 | 159.6 | 159 | 159 | [10] |
| S1 | 6 | 7 | 8 | 9 | 10 | f1 | x1 |
|---|---|---|---|---|---|---|---|
| 0 | 232.2 | 231.6 | 231 | 230.4 | 229.8 | 229.8 | [10] |
最优值为:229.8万元
最优策略为:(10,10,5,6)
本程序所有结果均会存入到Excel工作簿中,方便查看结果

版权声明:本文为博主作者:冰冷冷的挈挈原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/m0_69878069/article/details/130555972