Java基础教程之IO操作 · 上
- 🔹本节学习目标
- 1️⃣ 文件操作类:File
- 2️⃣ 字节流与字符流
- 2.1 字节输出流:OutputStream
- 2.2 字节输入流:InputStream
- 2.3 字符输出流:Writer
- 2.4 字符输入流:Reader
- 2.5 字节流与字符流的区别
- 🌾 总结

🔹本节学习目标
- 掌握 java.io包中类的继承关系 ;
- 掌握 File类的使用,并且可以通过File类进行文件的创建、删除以及文件夹的列表等操作;
- 掌握字节流或字符流操作文件内容,字节流与字符流的区别;
1️⃣ 文件操作类:File
在 java.io 包中,如果要进行文件自身的操作 (例如:创建、删除等), 只能依靠 java.io.File 类完成。File 类常用操作方法如下表所示。
| 方法 | 类型 | 描述 |
|---|---|---|
public File(String pathname) | 构造方法 | 传递完整文件操作路径 |
public File(File parent, String child) | 构造方法 | 设置父路径与子文件路径 |
boolean createNewFile() throws IOException | 普通方法 | 创建新文件 |
boolean exists() | 普通方法 | 判断给定路径是否存在 |
boolean delete() | 普通方法 | 删除指定路径的文件 |
File getParentFile() | 普通方法 | 取得当前路径的父路径 |
boolean mkdirs() | 普通方法 | 创建多级目录 |
long length() | 普通方法 | 取得文件大小,以字节为单位返回 |
boolean isFile() | 普通方法 | 判断给定路径是否是文件 |
boolean isDirectory() | 普通方法 | 判断给定路径是否是目录 |
long lastModified() | 普通方法 | 取得文件的最后一次修改日期时间 |
String[] list() | 普通方法 | 列出指定目录中的全部内容 |
File[] listFiles() | 普通方法 | 列出所有的路径以File类对象包装 |
通过上表可以发现 File类中提供的方法并不涉及文件的具体内容,只是针对文件本身的操作。在 File类中的 length()及 lastModified()方法返回的数据类型都是 long 型,这是因为 long数据类型可以描述内存(或文件)大小、日期时间数字等等。
下面演示一个文件基本操作。任意给定一个文件路径,如果文件不存在则创建一个新的文件,如果文件存在则将文件删除。文件操作流程如下所示:
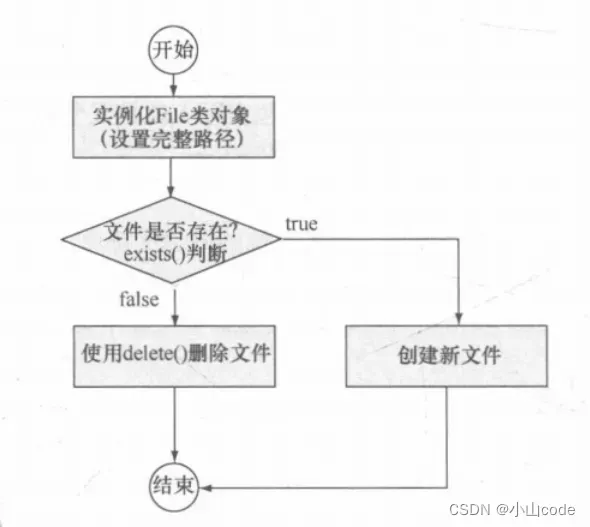 图1 文件操作流程
图1 文件操作流程
// 范例1
package com.xiaoshan.demo;
import java.io.File;
public class TestDemo {
public static void main(String[] args) throws Exception{ //此处直接抛出
File file = new File("d:\\test.txt"); //设置文件的路径
if (file.exists()){ //判断文件是否存在
file.delete(); //删除文件
}else{ //文件不存在
System.out.println(file.createNewFile()); //创建新文件
}
}
}
此程序首先定义了文件的操作路径 “e:\\test.txt”(“\\”是“\”的转义字符,也是路径分隔符), 然后利用 exists()方法判断该路径的文件是否存在,如果存在则使用 delete()删除,否则使用 createNewFile()创建新文件。
注意在操作系统中,如果要定义路径则一定会存在路径分隔符的问题,因为程序运行在 Windows系统下,所以范例1的程序中使用了“\\”(本质为“\”)作为了分隔符。但是如果程序运行在 Linux系统中,则路径分隔符为”/“。而Java本身属于跨平台的操作系统,总不能针对每一个不同的操作系统手工去修改路径分隔符,这样的操作实在是不智能。因此在 java.io.File 类里面提供有一个路径分隔符常量:
public static final String separator;
利用此常量就可以在不同的操作系统中自动转化为适合于该操作系统的路径分隔符。所以在实际开发中,如果要定义 File类对象往往会使用如下形式的操作代码。
File file = new File("d:" + File.separator + "test.txt"); //设置文件的路径
为了保证代码开发的严格性,在使用文件操作中都会利用此常量定义路径分隔符。 同时可能大家也发现了一个问题,虽然 separator 是一个常量,但是这个常量并没有遵守字母全部大写的原则,而造成这样的问题是在JDK 1.0 时常量与变量的定义规则相同,而这一问题也属于历史遗留问题。
另外需要提醒大家的是,在进行 java.io 操作文件的过程中,会出现延迟情况。因为 Java程序是通过JVM间接地调用操作系统的文件处理函数进行的文件处理操作,所以中间可能会出现延迟情况。
如果给定的路径为根路径,则文件可以直接利用 createNewFile() 方法进行创建;如果要创建的文件存在目录,那么将无法直接进行创建。所以合理的做法应该是在创建文件前判断父路径 (getParent()取得父路径) 是否存在,如果不存在则应该先创建目录 (mkdirs() 创建多级目录),再创建文件。包含路径的文件创建如下图所示:
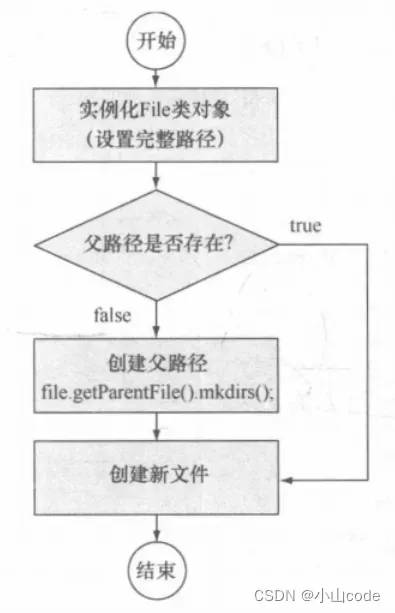 图2 包含路径的文件创建流程
图2 包含路径的文件创建流程
// 范例 2: 创建带路径的文件
package com.xiaoshan.demo;
import java.io.File;
public class TestDemo {
public static void main(String[] args) throws Exception { //此处直接抛出
File file = new File("d:" + File.separator + "demo" + File.separator + "hello" + File.separator + "xiaoshan" + File.separator + "test.txt"); //设置文件的路径
if (!file.getParentFile().exists()){ //现在父路径不存在
file.getParentFile().mkdirs(); //创建父路径
}
System.out.println(file.createNewFile()); //创建新文件
}
}
此程序所要创建的文件保存在目录中,所以在创建文件前需要首先判断父路径是否存在,如果不存在则一定要先创建父目录 (否则会出现 “java.io.IOException: 系统找不到指定的路径。”)。由于目录会存在多级子目录的问题,所以需要使用 mkdirs()方法进行创建。
当用户在开发中使用 Struts、Spring MVC的 MVC开发框架时,都会面临接收文件上传及保存的操作。在文件保存操作中,往往只会提供一个父目录(例如:upload), 而具体的子目录有可能需要根据实际的使用情况进行动态创建,这样就需要使用上边范例2的方式创建目录。
// 范例 3: 取得文件或目录的信息
package com.xiaoshan.demo;
import java.io.File;
import java.math.BigDecimal;
import java.text.SimpleDateFormat;
import java.util.Date;
public class TestDemo {
public static void main(String[] args) throws Exception { // 此处直接抛出
File file = new File("d:" + File.separator + "mypicture.png"); // 设置文件的路径
if (file.exists()){
System.out.println("是否是文件:" + (file.isFile()));
System.out.println("是否是目录:" + (file.isDirectory()));
//文件大小是按照字节单位返回的数字,所以需要将字节单元转换为兆(M) 的单元
//但是考虑到小数点问题,所以使用 BigDecimal处理
System.out.println("文件大小:" +
( new BigDecimal((double)file.length()/1024 /1024)
.divide(new BigDecimal(1),2,BigDecimal.ROUND_HALF_UP)) + "M");
//返回的日期是以long 的形式返回,可以利用SimpleDateFormat 进行格式化操作
System.out.println("上次修改时间:" + new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date(file.lastModified())));
}
}
}
程序执行结果:
是否是文件:true
是否是目录:false
文件大小:6.28M
上次修改时间:2023-07-19 06:24:28
此程序利用 File类中提供的方法进行操作,其中最为重要的就是关于数字的四舍五入处理以及 long 与 Date 类型间的转换操作。
范例 3 的所有操作都是围绕文件进行的,但是在整个磁盘上除了文件之外,还会包含使用的目录。对于目录而言,最为常用的功能就是列出目录组成,可 以使用 listFiles() 方法完成。
// 范例 4: 列出目录信息
package com.xiaoshan.demo;
import java.io.File;
public class TestDemo {
public static void main(String[] args) throws Exception { // 此处直接抛出
File file = new File("d:" + File.separator);
if (file.isDirectory()){ //判断当前路径是否为目录
File result[] = file.listFiles();
for (int x=0; x<result.length; x++){
System.out.println(result[x]); //调用 toString()
}
}
}
}
程序执行结果:
d:\\demo
d:\\devtools
d:\\JSP
d:\\MailMasterData
d:\\MyApp
...
在进行目录列出之前首先要判断给定的路径是否是目录,如果是目录则利用 listFiles() 方法列出当前目录中所有内容 (文件以及子目录) 的文件对象,这样就可以采用循环的方式直接输出 File 类对象(默认输出的是完整路径);如果有需要也可以继续利用数组中的每一个 File类对象进行操作。
下面演示如何列出指定目录下的所有文件及子目录信息。在每一个目录中有可能还会存在其他子目录,并且还可能有更深层次的子目录,所以为了可以列出所有的内容,应该判断每一个给定的路径是否是目录。如果是目录则应该继续列出,这样的操作最好使用递归的方式完成。列出完整目录结构操作流程如下图所示。
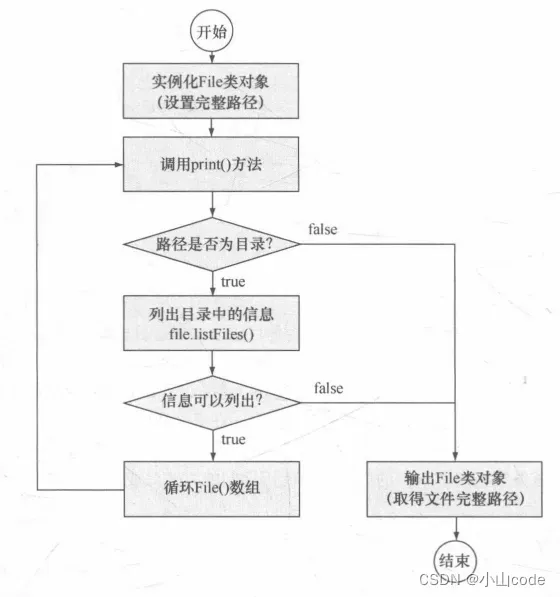 图3 列出完整目录结构流程
图3 列出完整目录结构流程
// 范例 5: 列出完整目录结构
package com.xiaoshan.demo;
import java.io.File;
public class TestDemo {
public static void main(String[] args) throws Exception{
File file = new File("c:" + File.separator); //定义操作路径
print(file); //列出目录
}
/**
*列出目录结构,此方法采用递归调用形式
*@param file 要列出目录的路径
*/
public static void print(File file){
if (file.isDirectory()){ //路径为目录
File result[] = file.listFiles(); //列出子目录
if (result != null){
for (int x=0; x<result.length; x++){
print(result[x]); //递归调用
}
}
}
System.out.println(file); //直接输出完整路径
}
}
此程序会列出指定目录中的全部内容 (包括子目录中的内容)。由于不确定要操作的目录层级数,所以使用递归的方式,将列出的每一个路径继续判断;如果是目录则继续列出。
2️⃣ 字节流与字符流
使用 java.io.File 类虽然可以操作文件,但是却不能操作文件的内容。如果要进行文件内容的操作,就必须依靠流的概念来完成。流在实际中分为输入流与输出流两种。输入流与输出流是一种相对的概念,关键是要看参考点,以下图所示为例:数据从数据源流向目标程序,以Java作为参考点来说,那么这就属于输入流;如果以数据源为参考点,那么这就属于输出流;同样以数据从Java程序流向目标一样,对目标而言就属于输入流,对于Java程序来说就是输出流。
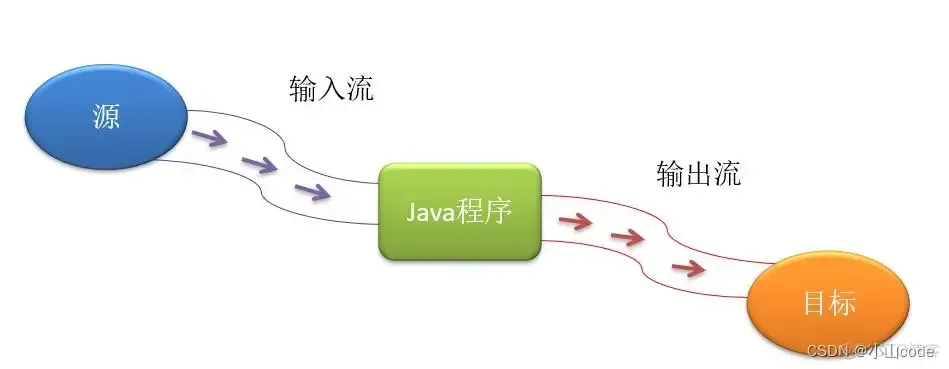 图4 流的概念
图4 流的概念
在Java 中针对数据流的操作分为输入与输出两种方式,而且针对此操作提供了以下两类支持。
- 字节流 (JDK 1.0开始提供):
InputStream(输入字节流)、OutputStream(输出字节流); - 字符流 (JDK 1.1开始提供):
Reader(输入字符流)、Writer(输出字符流)。
在 java.io 包中提供的4个操作流的类是其核心的组成部分,但是这些类本质上的操作流程区别不大。以文件读、写操作为例,其基本流程为以下四步。
(1)第一步:通过File类定义一个要操作文件的路径;
(2)第二步:通过字节流或字符流的子类对象为父类对象实例化;
(3)第三步:进行数据的读(输入)、写(输出)操作;
(4)第四步:数据流属于资源操作,资源操作必须关闭。
其中第四步是很重要的,一定要记住,不管何种情况只要是资源操作(例如: 网络、文件、数据库的操作都属于资源操作),必须要关闭连接(几乎每种类都会提供 close()方法)。
在 java.io 包中,四个操作流的类 (OutputStream、InputStream、Writer、Reader) 全部都属于抽象类,所以在使用这些类时,一定要通过子类对象的向上转型来进行抽象类对象的实例化操作。在整个 IO 流的操作中最麻烦的并不是这四个基础的父类,而是一系列子类。每种子类代表着不同的输入流、输出流位置。
2.1 字节输出流:OutputStream
字节流是在实际开发中使用较多的一种流操作,而 java.io.OutputStream 是一个专门实现字节输出流的操作类。OutputStream 类的常用方法如下表所示。
| 方法 | 类型 | 描述 |
|---|---|---|
void close() throws IOException | 普通方法 | 关闭字节输出流 |
void flush() throws IOException | 普通方法 | 强制刷新 |
abstract void write(int b) throws IOException | 普通方法 | 输出单个字节 |
void write(byte[] b) throws IOException | 普通方法 | 输出全部字节数组数据 |
void write(byte[] b, int off, int len) throws IOException | 普通方法 | 输出部分字节数组数据 |
可以发现,在 OutputStream 类中提供了3个输出( write()) 方法,这3个 write()方法分别可以输出单个字节(使用 int 接收)、全部字节数组和部分字节数组。
OutputStream是一个抽象类,而这个抽象类的定义如下。
public abstract class OutputStream extends Object implements Closeable, Flushable
在类定义中可以发现OutputStream类同时实现了Closeable与 Flushable 两个父接口,而这两个父接口的定义组成如下。
// Closeable接口:JDK 1.5之后才提供
public interface Closeable extends AutoCloseable {
public void close() throws IOException;
}
// Flushable接口:JDK 1.5之后才出现
public interface Flushable {
public void flush() throws IOException;
}
通过两个父接口提供的方法可以发现,close() 与 flush() 方法都已经在 OutputStream 类中明确定义过了,这是因为在JDK 1.0时并没有为OutputStream 类设计继承的接口, 而从JDK 1.5之后考虑到标准的做法,才增加了两个父接口,不过由于最初的使用习惯,这两个接口很少被关注到。
到了JDK 1.7版本之后,对于接口的定义又发生了改变,在 Closeable 接口声明时继承了 AutoCloseable父接口,这个接口就是JDK 1.7中新增的接口,此接口定义如下。
public interface AutoCloseable {
public void close() throws Exception;
}
通过定义可以发现,在AutoCloseable 接口中也定义了一个 close()方法,那么为什么在JDK 1.7中又需要提供这样的 AutoCloseable() 自动关闭)接口呢?
原因是JDK 1.7中针对异常处理产生了新的支持。在以往的开发中,如果是资源操作,用户必须手工关闭资源(方法名称几乎都是 close() ),但是实际上会有许多开发者忘记关闭资源,就经常导致其他线程无法打开资源进行操作,所以Java提供了以下一种新的异常处理格式。
try (AutoCloseable接口子类 对象 = new AutoCloseable接口子类名称()){
//调用方法(有可能会出现异常);
catch(异常类型对象){
//异常处理;
}..[finally {
//异常处理的统一出口;
}]
只要使用此种格式,在操作完成后用户就没有必要再去调用 close() 方法了,系统会自动帮助用户调用 close() 方法以释放资源。
// 范例 6: 自动执行 close()操作
package com.xiaoshan.demo;
class Net implements AutoCloseable{
@Override
public void close() throws Exception{
System.out.println("*** 网络资源自动关闭,释放资源。");
}
public void info() throws Exception{ //假设有异常抛出
System.out.println("*** 欢迎访问: https://lst66.blog.csdn.net");
}
}
public class TestDemo{
public static void main(String[] args){
try (Net n = new Net()){
n.info();
}catch (Exception e){
e.printStackTrace();
}
}
}
程序执行结果:
*** 欢迎访问: https://lst66.blog.csdn.net
*** 网络资源自动关闭,释放资源。
此程序按照 AutoCloseable 的使用原则使用异常处理格式,可以发现程序中并没有明确调用 close()方法的语句,但是在整个资源操作完成后会自动调用 close() 释放资源。
虽然 Java 本身提供了这种自动关闭操作的支持,不过从开发习惯上讲,仍有不少开发者还是愿意手工调用 close()方法,所以可以由读者自己来决定是否使用此类操作。
OutputStream 本身是一个抽象类,这样就需要一个子类。如果要进行文件操作,则可以使用 FileOutputStream 子类完成操作,此类定义的常用方法如下表所示。
| 方法 | 类型 | 描述 |
|---|---|---|
public FileOutputStream(File file) throws FileNotFoundException | 构造方法 | 将内容输出到指定路径,如果文件已存在,则使用新的内容覆盖旧的内容 |
public FileOutputStream(File file,boolean append) throws FileNotFoundException | 构造方法 | 如果将布尔参数设置为true,表示追 加新的内容到文件中 |
由于输出操作主要以OutputStream 类为主,所以对于 FileOutputStream 只需要关注其常用的两个构造方法即可。大家可以通过下图理解 FileOutputStream 类的继承结构。
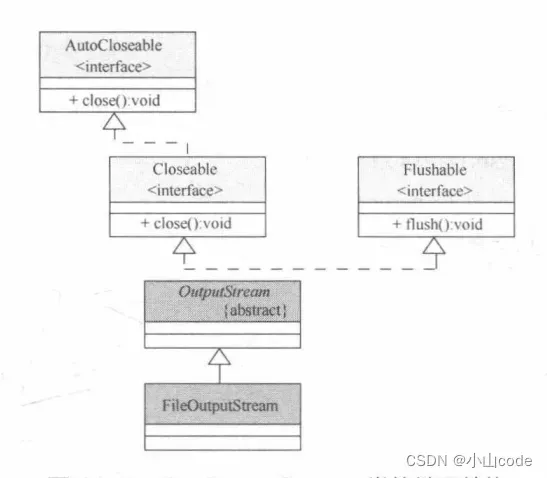 图5 FileOutputStream 类的继承结构
图5 FileOutputStream 类的继承结构
其实大家可以发现,在OutputStream类中定义的方法都使用了 throws 抛出了异常,因为流属于资源操作,所以任何操作都不一定确保可以正常完成,不仅是流操作,而且在后面文章中我会讲解的网络操作、数据库操作里面所使用的方法绝大部分也都会抛出异常。
需要注意的是,我写的演示案例程序中会在主方法上直接使用 throws抛出异常,而在实际开发中,主方法一定要处理异常,不能抛出。
// 范例 7: 文件内容的输出
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileOutputStream;
import java.io.OutputStream;
public class TestDemo {
public static void main(String[] args) throws Exception{ // 直接抛出
//1.定义要输出文件的路径
File file = new File("d:" + File.separator + "demo" + File.separator + "案例文本.txt");
//此时由于目录不存在,所以文件不能输出,应该首先创建目录
if (!file.getParentFile().exists()){ //文件目录不存在
file.getParentFile().mkdirs(); //创建目录
}
//2.应该使用 OutputStream和其子类进行对象的实例化,此时目录存在,文件还不存在
OutputStream output = new FileOutputStream(file);
//字节输出流需要使用byte类型,需要将String类对象变为字节数组
String str = "更多知识请访问:https://lst66.blog.csdn.net";
byte data[] = str.getBytes(); //将字符串变为字节数组
//3.输出内容
output.write(data);
//4.资源操作的最后一定要进行关闭
output.close();
}
}
程序执行结果:
此程序严格按照流的操作步骤进行,并且在程序执行前指定的文件路径并不存在,为了保证程序可以正常执行,需要先创建对应的父路径,再利用 FileOutputStream 类对象为 OutputStream 父类实例化,这样 write() 方法输出时就表示向文件中进行输出。由于 OutputStream 只适合输出字节数据,所以需要将定义的字符串利用 getBytes() 方法转换为字节数组后才可以完成操作。
如果重复执行上边范例 7的代码会发生文件内容的覆盖,而如果要实现文件的追加可以使用另外一个 FileOutputStream() 类的构造方法(public FileOutputStream(File file, boolean append))。
// 范例 8:文件追加
...
//2.应该使用OutputStream和其子类进行对象的实例化,此时目录存在,文件还不存在
OutputStream output = new FileOutputStream(file, true);
...
此程序使用了追加模式,这样每次执行完程序都会向文件中不断追加新的操作。
范例 7的程序是将整个字节数组的内容进行了输出。同时可以发现一个问题:利用 OutputStream 向文件输出信息时如果文件不存在,则会自动创建(不需要用户手工调用 createNewFile() 方法)。对于输出操作在整个 OutputStream 类里面一共定义了三个方法,下面来看一下其他两种输出方法(为方便操作,本处只列出代码片断)。
// 范例 9: 采用单个字节的方式输出(此处可以利用循环操作输出全部字节数组中的数据)
...
for (int x=0; x<data.length; x++){
output.write(data[x]); //内容输出
}
...
// 范例 10: 输出部分字节数组内容(设置数组的开始索引和长度)
...
output.write(data, 6, 6); //内容输出
...
虽然在 OutputStream 类中定义了3种操作,但是从实际的开发来讲,输出部分字节数组操作 (public void write(byte[] b, int off, int len)) 是实际工作中使用较多的方法。
2.2 字节输入流:InputStream
在程序中如果要进行文件数据的读取操作,可以使用 java.io.InputStream 类完成,此类可以完成字节数据的读取操作。InputStream 类的常用方法如下表所示。
| 方法 | 类型 | 描述 |
|---|---|---|
void close() throws IOException | 普通方法 | 关闭字节输入流 |
abstract int read() throws IOException | 普通方法 | 读取单个字节 |
int read(byte[] b) throws IOException | 普通方法 | 将数据读取到字节数组中,同时返回读取长度 |
int read(byte[] b, int off, int len) throws IOException | 普通方法 | 将数据读取到部分字节数组中,同时返回读取的数据长度 |
通过 InputStream 类提供的3个 read()方法可以发现,其操作的数据类型与 OutputStream 类中的3个 write()方法对应。但是 OutputStream 类中的 write() 中的参数包含的是要输出的数据,而 InputStream 类中的 read() 方法中的参数是为了接收输入数据准备的。
InputStream 依然属于一个抽象类,此类的定义如下。
public abstract class InputStream extends Object implements Closeable
通过定义可以发现 InputStream类实现了 Closeable 接口(其继承AutoCloseable接口),所以利用自动关闭的异常处理结构可以实现自动的资源释放。与 OutputStream类一样,由于 Closeable 属于后加入的接口,并且在 InputStream 类中存在 close()方法,所以用户可以忽略此接口的存在。
在 InputStream 类中最为重要的就是3个 read() 方法,这三个方法的详细作用如下。
public abstract int read() throws IOException:读取单个字节,返回读取的字节内容,如果已经没有内容,则读取后返回 “-1”,如下图所示;public int read(byte[] b) throws IOException:将读取的数据保存在字节数组里 (一次性读取多个数据),返回读取的数据长度,如果已经读取到结尾,则读取后返回 “-1”;public int read(byte[] b, int off, int len) throws IOException:将读取的数据保存在部分字节数组里,读取的部分数据的长度,如果已经读取到结尾,则读取后返回 “-1”,如下图所示。
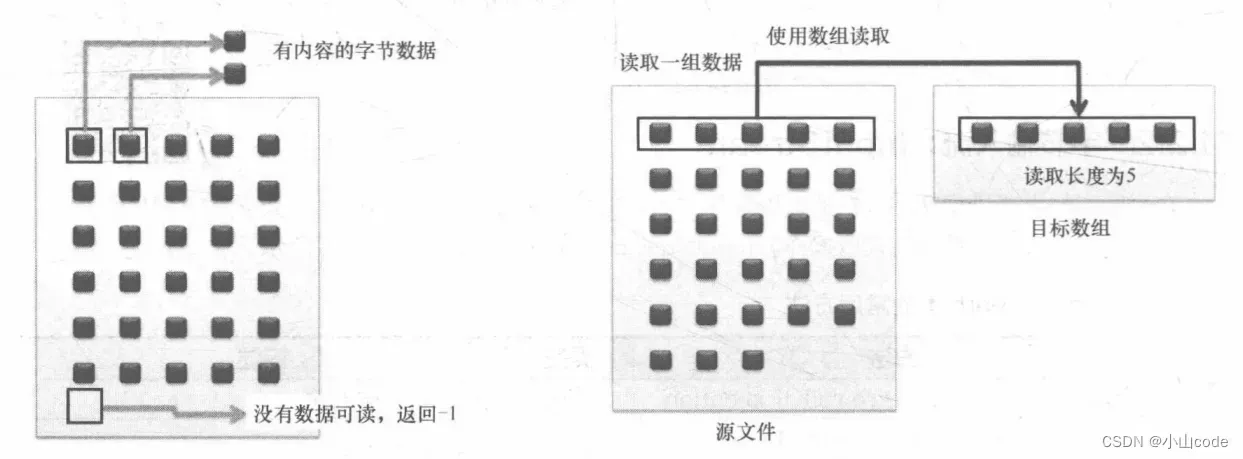 图6 读取单个字节与读取一组字节
图6 读取单个字节与读取一组字节
一些朋友在学习到此处时都会不太理解 read() 方法的作用,为了帮助大家更好地理解此操作,举一个生活中的例子:办公室有一个饮水机,现在小李口渴了(身体需要输入水分) 需要喝水,他的喝水操作就可能有以下3种情况。
- 第一种情况(
public int read()):小李没有带杯子,所以只能够用手接着喝,每次喝掉 1mL的水,并且一直重复这个动作, 一直到饮水机中的水被喝干,但是很明显这样喝水花费时间较长,如果水全被喝完了,就相当于数据没有了,此时程序的处理做法是返回“-1”; - 第二种情况(
public int read(byte[] b)):小李拿了一个水杯去接水 (假设水杯容量为300mL,这就相当于每使用水杯接一次水,就可以喝掉300mL的水,接水的次数少了),此时存在两种情况:- 饮水机里的水还剩余1L,很明显即便杯子接满了,也只能接出300mL,但这样每次接300mL的水,相比每次接1mL的水操作次数有大幅减少。当饮水机中没有水的时候,水杯将无法接到水,最终就会返回一个“-1” 的长度标记;
- 饮水机里的水还剩余200mL,这样无法接满300mL的水杯,于是返回的总数量就是200mL,而再次要接水时将无法接到水,这样就会返回一个“-1”的长度标记;
- 第三种情况(
public int read(byte[] b, int off, int len)):小李拿了一个300mL 的杯子要去接饮水机里的水,但是他只要求杯子接150mL的水,这样就会要求设置一个接水的量。
java.io.InputStream 是一个抽象类,所以如果要想进行文件读取,需要使用 FileInputStream 子类,而这个子类的构造方法如下所示。
// 设置要读取文件数据的路径
public FilelnputStream(File file) throws FileNotFoundException
与 OutputStream 的使用规则相同,所有的子类要向父类对象转型,所以 FileInputStream 类中只需要关注构造方法即可,而 FileInputStream 类的继承结构如下图所示。
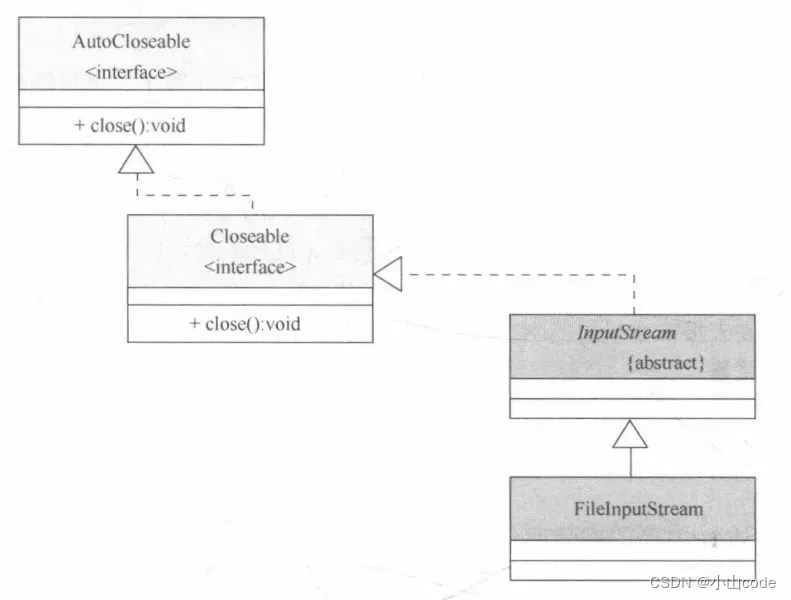 图7 FileInputStream 类的继承结构
图7 FileInputStream 类的继承结构
// 范例 11: 数据读取操作
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
public class TestDemo{
public static void main(String[] args) throws Exception { // 直接抛出
File file = new File("d:" + File.separator + "demo" + File.separator + "案例文本.txt"); //1.定义要输出文件的路径
if (file.exists()){ // 需要判断文件是否存在后才可以进行读取
InputStream input = new FileInputStream(file); //2.使用InputStream 进行读取
byte data []= new byte [1024]; //准备出一个1024的数组
int len = input.read(data); //3.进行数据读取,将内容保存到字节数组中
input.close(); //4.关闭输入流
//将读取出来的字节数组数据变为字符串进行输出
System.out.println("【" + new String(data, 0, len)+" 】");
}
}
}
程序执行结果:
【更多知识请访问:https://lst66.blog.csdn.net】
此程序利用 InputStream 实现了文件的读取操作,为了确保可以正确读取,首先要对文件是否存在进行判断。在进行数据读取时,首先要开辟一个字节数组空间以保存读取的数据,但是考虑到要读取的数据量有可能小于数组大小,所以在将字节数组转换为字符串时设置了数组可用数据的长度 (该长度为 input.read(data)方法返回结果)。
范例11是将数据一次性读取到字节数组中,但是在 InputStream 类中定义了3个 read()方法,其中有一个 read()方法可以每次读取一个字节数据,如果要使用此方法操作,就必须结合循环一起完成。
// 范例 12: 采用 while 循环实现输入流操作
package com.xiaoshan.demo;
import java.io.File;
import java.io.FilelnputStream;
import java.io.InputStream;
public class TestDemo(
public static void main(String[] args) throws Exception{ // 直接抛出
File file =new File("d:"+ File.separator + "demo" + File.separator + "案例文本.txt"); //1.定义要输出文件的路径
if (file.exists()){ //需要判断文件是否存在后才可以进行读取
InputStream input = new FilelnputStream(file); //2.使用InputStream 进行读取
byte data[] = new byte[1024]; //准备出一个1024的数组
int foot=0; //表示字节数组的操作脚标
int temp=0; //表示接收每次读取的字节数据
//第一部分:(temp= input.read()),表示将read()方法读取的字节内容给temp 变量
//第二部分:((temp = input.read()) != -1, 判断读取的 temp 内容是否是-1
while((temp = input.read()) != -1){ //3.读取数据
//有内容进行保存
data[foot++] = (byte)temp;
}
input.close(); //4.关闭输入流
System.out.println("【" + new String(data, 0, foot) + "】");
}
}
}
}
程序执行结果:
【更多知识请访问:https://lst66.blog.csdn.net】
此程序采用了循环的方式进行数据读取操作,每次循环时都会将读取出来的字节数据保存给 temp 变量,如果读取出来的数据不是“-1”就表示还有数据需要继续进行读取。循环读取字节数据的执行流程如下图所示。
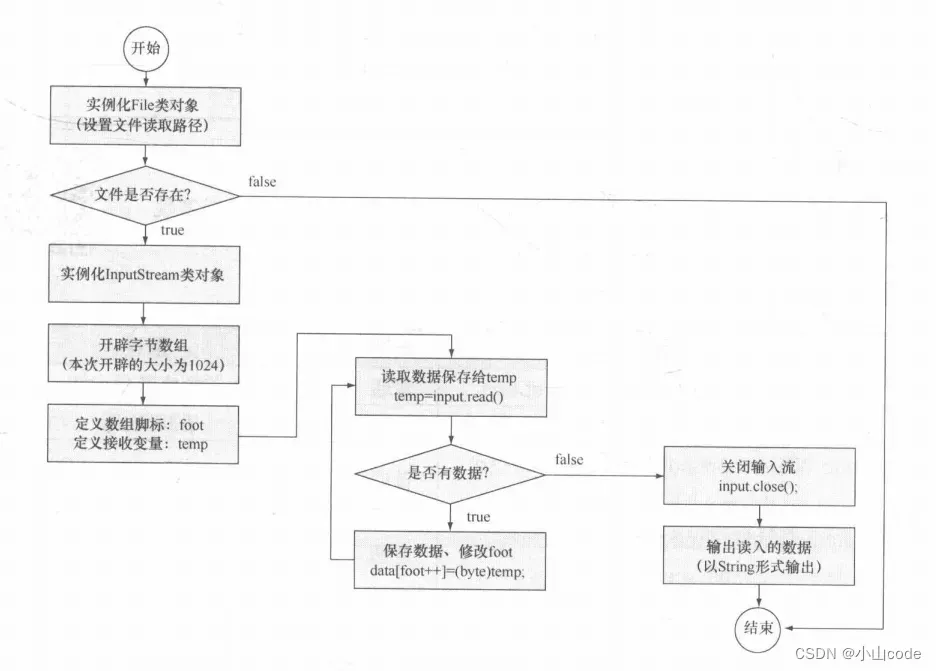 图8 循环读取字节数据
图8 循环读取字节数据
关于“while((temp = input.read()) != -1)” 语句,一些朋友第一次接触此类语法会有一些不习惯,而实际上这样的语法在进行 I0 操作时是最好用的。按照程序中的注解,此语法分为以下两个执行步骤:
(1)第一步(temp = input.read()):表示将read()方法读取的字节内容给temp变量,同时此代码由于是在“()”中编写的,所以运算符的优先级高于赋值运算符;
(2)第二步((temp = input.read()) != -1):表示判断 temp 接收数据返回的是否是”-1“, 如果不是-1表示当前已经读取到数据,如果是“-1“表示数据已经读取完毕,不再需要读了。
2.3 字符输出流:Writer
java.io.Writer 类是从JDK 1.1 版本之后增加的,利用 Writer 类可以直接实现字符数组 (包含了字符串) 的输出。 Writer类的常用方法如下表所示。
| 方法 | 类型 | 描述 |
|---|---|---|
void close() throws IOException | 普通方法 | 关闭字节输出流 |
void flush() throws IOException | 普通方法 | 强制刷新 |
Writer append(CharSequence csq) throws IOException | 普通方法 | 追加数据 |
void write(String str) throws IOException | 普通方法 | 输出字符串数据 |
void write(char[] cbuf) throws IOException | 普通方法 | 输出字符数组数据 |
通过 Writer 类定义的方法可以发现,Writer 类中直接提供了输出字符串数据的方法,这样就没有必要将字符串转成字节数组后再输出了。
与OutputStream的定义类似,Writer类本身也属于一个抽象类,此类的定义结构如下。
public abstract class Writer extends Object implements Appendable, Closeable, Flushable
通过继承结构可以发现,Writer类中除了实现 Closeable与 Flushable接口之外,还实现了一个 Appendable接口。Appendable接口定义如下。
public interface Appendable {
public Appendable append(char c) throws IOException;
public Appendable append(CharSequence csq) throws IOException;
public Appendable append(CharSequence csq, int start, int end) throws I0Exception;
}
在Appendable接口中定义了一系列数据追加操作,而追加的类型可以是 CharSequence(可以保存 String、StringBuffer、StringBuilder类对象)。Writer类的继承结构如图所示。
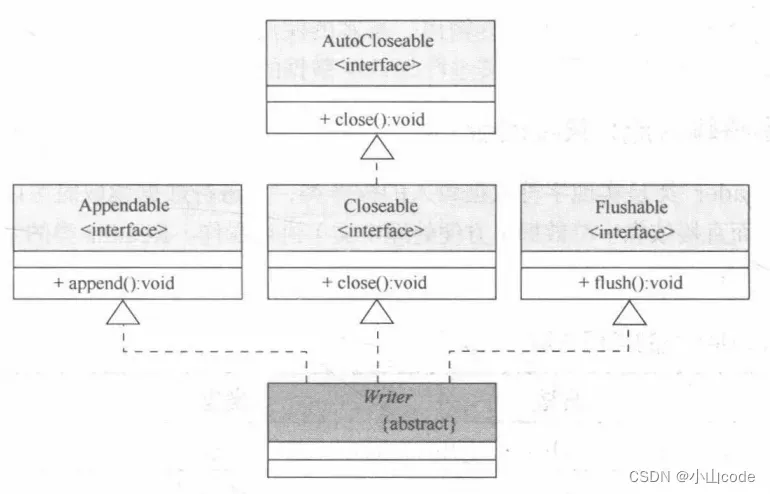 图9 Writer类的继承结构
图9 Writer类的继承结构
Writer 是一个抽象类,要针对文件内容进行输出,可以使用 java.io.FileWriter 类实现 Writer 类对象的实例化操作。 FileWriter类的常用方法如表所示。
| 方法 | 类型 | 描述 |
|---|---|---|
public FileWriter(File file) throws I0Exception | 构造方法 | 设置输出文件 |
public FileWriter(File file, boolean append) throws IOException | 构造方法 | 设置输出文件以及是否进行数据追加 |
// 范例 13: 使用 Writer 类实现内容输出
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class TestDemo {
public static void main(String[] args) throws Exception{ // 此处直接抛出
File file = new File("d:" + File.separator + "demo" + File.separator + "案例文本.txt"); //1.定义要输出文件的路径
if (file.getParentFile().exists()){ //判断目录是否存在
file.getParentFile().mkdirs(); //创建文件目录
}
Writer out = new FileWriter(file); //2.实例化了 Writer类的对象
String str = "更多知识请访问:https://lst66.blog.csdn.net"; //定义输出内容
out.write(str); //3.输出字符串数据
out.close(); //4.关闭输出流
}
}
本程序实现了字符串数据的内容输出,基本的使用流程与 OutputStream 相同,而最方便的是 Writer 类可以直接进行 String 数据的输出。
2.4 字符输入流:Reader
java.io.Reader 类是实现字符数据输入的操作类,在进行数据读取时可以不使用字节数据,而直接依靠字符数据(方便处理中文)进行操作。 Reader 类的常用方法如下表所示。
| 方法 | 类型 | 描述 |
|---|---|---|
void close() throws IOException | 普通方法 | 关闭字节输入流 |
int read() throws IOException | 普通方法 | 读取单个数据 |
int read() throws IOException | 普通方法 | 读取单个字符 |
int read(char[] cbuf) throws IOException | 普通方法 | 读取数据到字符数组中,返回读取长度 |
long skip(long n) throws IOException | 普通方法 | 跳过字节长度 |
通过上表可以发现,在Reader 类中也定义有 read() 方法,但是与 InputStream 最大的不同在于此处返回的数据是字符数据。为了更好地理解Reader类的操作,下面介绍 Reader类的定义结构。
public abstract class Reader extends Object implements Readable, Closeable
通过定义结构可以发现,在Reader类中实现了两个接口:Readable、Closeable,而 Readable接口定义如下。
public interface Readable{
public int read(CharBuffer cb) throws IOException;
}
在Readable接口中定义的 read()方法可以将数据保存在CharBuffer() 字符缓冲,类似于 StringBuffer()对象中,也就是说利用此类就可以替代字符数组的操作。Reader 类的继承结构如下图所示。
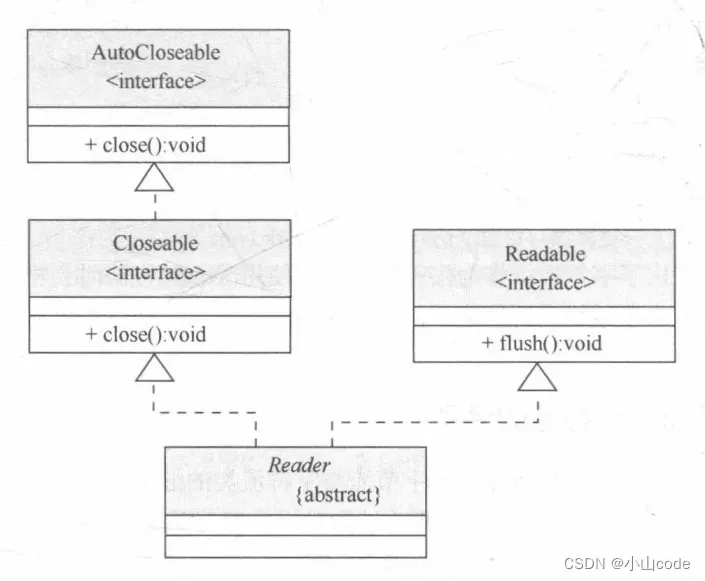 图10 Reader 类的继承结构
图10 Reader 类的继承结构
另外大家可以发现,在 Writer 类中存在直接输出字符串的操作,而 Reader 类中并没有直接返回字符串的操作,这是因为输出数据时可以采用追加的模式,所以随着时间的推移,文件有可能变得非常庞大 (假设现在已经达到了10G)。而如果在Reader类中提供了直接读取全部数据的方式,则有可能造成内存溢出问题。
Reader 类是一个抽象类,要实现文件数据的字符流读取,可以利用 FileReader子类为 Reader 类对象实例化。FileReader 类的常用方法如下所示。
public FileReader(File file) throws FileNotFoundException:构造方法,定义要读取的文件路径。
// 范例 14: 使用 Reader 读取数据
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileReader;
import java.io.Reader;
public class TestDemo {
public static void main(Stringll args) throws Exception { // 此处直接抛出
File file = new File("d:"+ File.separator + "demo" + File.separator + "案例文本.txt"); //1.定义要输出文件的路径
if (file.exists()){
Reader in = new FileReader(file); //2. 为Reader 类对象实例化
char data[] = new char[1024]; //开辟字符数组,接收读取数据
int len = in.read(data); //3.进行数据读取
in.close(); //4.关闭输入流
System.out.println(new String(data, 0, len));
}
}
}
程序执行结果:
更多知识请访问:https://lst66.blog.csdn.net
此程序首先使用了字符数组作为接收数据,当使用 read() 方法时会将数据保存到数组中,然后返回读取的数据长度,由于数组开辟较大,内容无法全部填充,这样在输出时就可以将部分字符数组转换为字符串后输出。
2.5 字节流与字符流的区别
以上讲解已经为读者详细地分析了字节流与字符流类的继承结构、基本操作流程。这两类流都可以完成类似的功能,那么这两种操作流有哪些区别呢?
以文件操作为例,字节流与字符流最大的区别是:字节流直接与终端文件进行数据交互,字符流需要将数据经过缓冲区处理才与终端文件数据交互。
在使用 OutputStream 输出数据时即使最后没有关闭输出流,内容也可以正常输出,但是反过来如果使用的是字符输出流 Writer, 在执行到最后如果不关闭输出流,就表示在缓冲区中处理的内容不会被强制性清空,所以就不会输出数据。如果有特殊情况不能关闭字符输出流,可以使用 flush()方法强制清空缓冲区。
// 范例 15: 强制清空字符流缓冲区
package com.xiaoshan.demo;
import java.io.File;
import java.io.FileWriter;
import java.io.Writer;
public class TestDemo {
public static void main(String[] args) throws Exception{ //此处直接抛出
File file = new File("d:"+ File.separator + "demo" + File.separator + "案例文本.txt"); //1.定义要输出文件的路径
if (!file.getParentFile().exists()){ //判断目录是否存在
file.getParentFile().mkdirs(); //创建文件目录
}
Writer out = new FileWriter(file); //2.实例化了Writer类的对象
String str = "更多知识请访问:https://lst66.blog.csdn.net"; // 定义输出内容
out.write(str); //3.输出字符串数据
out.flush(); //强制刷新缓冲区
}
}
此程序执行到最后并没有执行流的关闭操作,所以从本质上讲,内容将无法完整输出。在不关闭流又需要完整输出时就只能利用 flush() 方法强制刷新缓冲区。
在开发中,对于字节数据处理是比较多的,例如:图片、音乐、电影、文字。而字符流最大的好处是它可以进行中文的有效处理。在开发中,如果要处理中文时应优先考虑字符流,如果没有中文问题,建议使用字节流。
🌾 总结
在本文中,我们深入探讨了Java文件操作类:File、字节流和字符流。我们首先介绍了File类,它提供了处理文件和目录的基本功能。接着,我们讨论了字节流和字符流,分别涵盖了InputStream、OutputStream、Reader和 Writer。
字节流主要操作字节数据,适用于处理二进制文件和网络数据传输。OutputStream用于写入字节数据到输出源,而InputStream则读取字节数据从输入源。这些流提供了丰富的方法,使我们能够有效地读写字节数据。
字符流则重点处理字符数据,适用于处理文本文件和字符集编码等。Writer用于将字符数据写入输出源,而Reader则从输入源读取字符数据。字符流提供了更高级的字符处理功能,如自动字符集编码转换和缓冲区管理。
此外,我们还探讨了字节流和字符流的区别。字节流是以字节为单位进行读写,而字符流则以字符为单位。字节流适合处理任意类型的数据,而字符流则更适合处理文本数据,并且对于国际化处理提供了更好的支持。在使用时,我们应根据实际需求选择合适的流。
在日常开发中,熟练掌握文件操作类和IO流的知识非常重要。通过正确使用File类和不同类型的流,我们能够高效地读写文件和处理数据。了解字节流和字符流的区别以及它们的适用场景,可以帮助我们更好地选择合适的IO操作方式。
《【Java基础教程】(四十三)多线程篇 · 下:深入剖析Java多线程编程:同步、死锁及经典案例——生产者与消费者,探究sleep()与wait()的差异》
《【Java基础教程】(四十五)IO篇 · 中:转换流、内存流和打印流(探索装饰设计模式与PrintStream类的进阶),文件操作案例实践、字符编码问题~》

文章出处登录后可见!