SD由三大组件组成:VAE,CLIP,Unet。
一VAE:
VAE是Variational Autoencoder的缩写,中文名变分自编码器,是一种基于深度学习的生成模型。
1潜空间图片与像素图片:
像素图片是正常使用的图片,通常包含主体的物体人物角色,和多余的部分空白背景等与主体无关的噪声。
潜空间图片可以理解为是像素图片在高维空间的另一种表达,是像素图片的一种压缩表示。
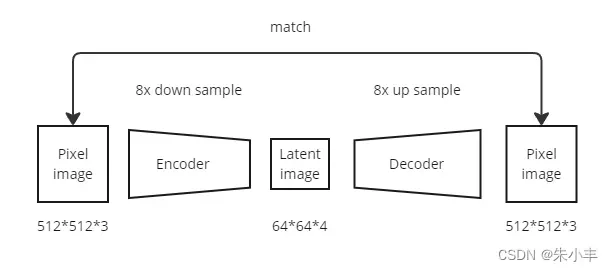
SD生成的图片是潜空间图片(Latent image)而不是直接使用的图片(Pixel image)。
2VAE编码和解码的过程
VAE编码器的部分作用是将像素图片编码转为潜空间图片,SD在此潜空间图片上进行迭代生成,迭代后的图片再由VAE解码器部分转换成像素级图片。
编码过程进行了8倍下采样操作,图片尺寸由512变为64,缩小8倍。
解码过程进行了8倍上采样操作,图片尺寸变为512,与目标的原始尺寸一致。
即编码前的图片尺寸与解码后的图片尺寸是match的。
3其他:
潜空间图片通道数目为4是先人实验结论得出的。
4 VAE编码过程:
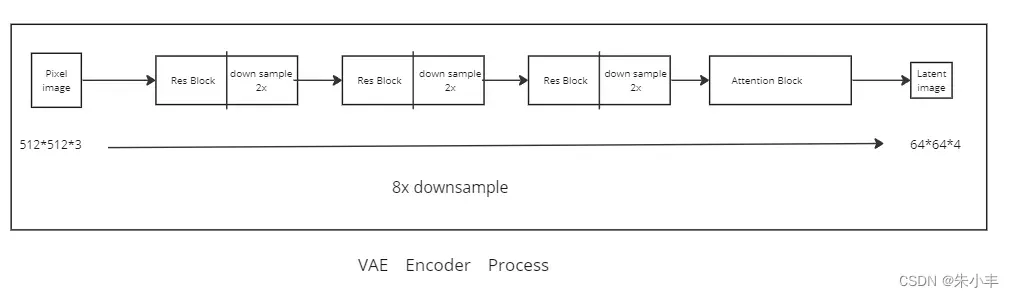
原始像素图片经过3个 ResidualBlock+DownSample 进行了8倍下采样操作。
再经注意力部分(Attention Block)转换为潜空间图片。
VAE主要的结构是这个注意力模块,存疑?
这个地方也是耗费大量显存的部分。
解码的过程是这个流程反过来。
二CLIP
CLIP的将promt转换成可以用于SD用于生成图片的词向量格式。
1 流程:
文字输入到SD的提示词如:a girl in white dress,
使用tokenizer跟进词库将单词转换为数字即tokens,如:a girl in white dress, –>[0,21,5,128,64]
再通过embedding将tokens转换成768维的特征向量。每一个数字转换成768维的向量。
最后通过Transformer Block 将向量变换转换成可以输入到后续unet的feature map。
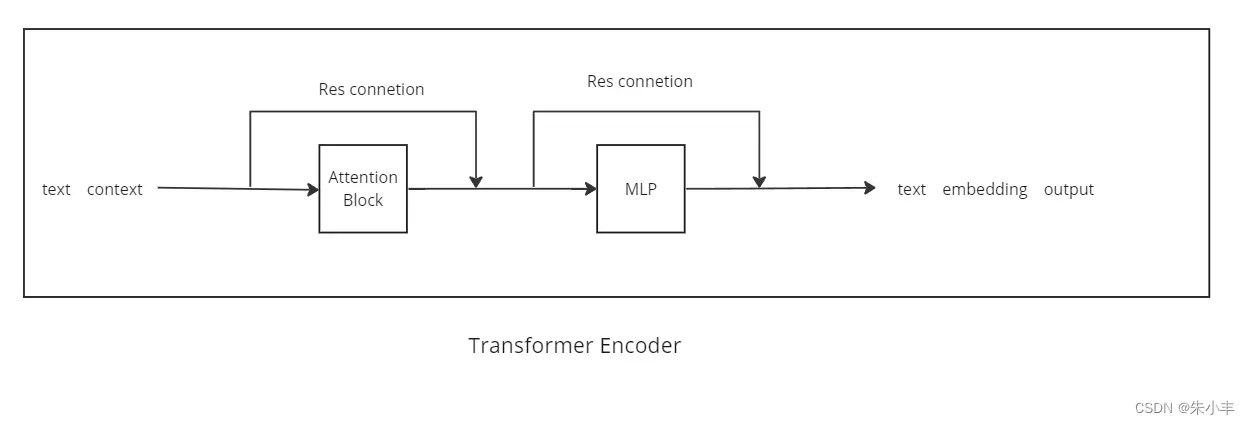
2 Transformer 分为 Transformer Encoder 和 Transformer Decoder
Clip中只使用了Transformer Encoder的结构。
三U-net
1网络结构图:
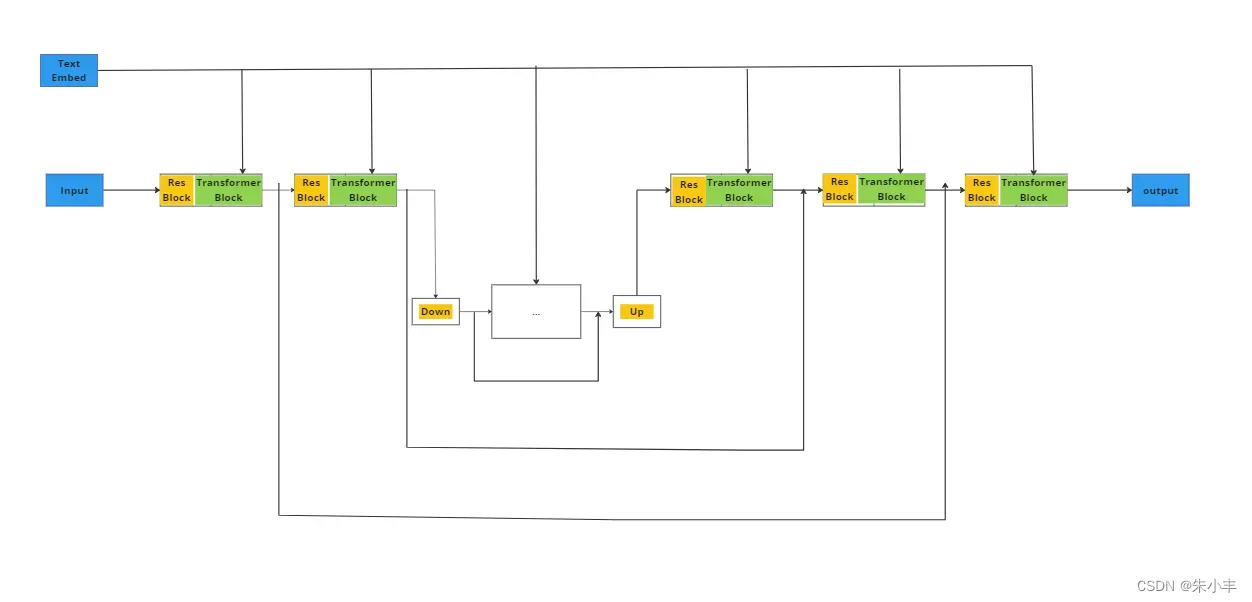
U-net共套了4成这样的网络结构,第4层没有中间的middle Block:Down–>Up的部分。
2注意力模块的两种形式:
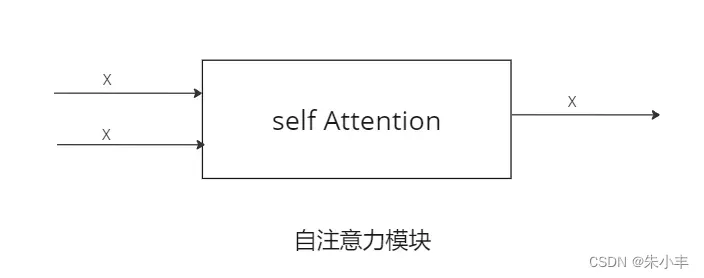

自注意力模块的输入和输出都是自己。
交叉注意力模块的输入一部分是自己,另一部分是其他的一些信息。
3Transformer Block 的encoder和decoder
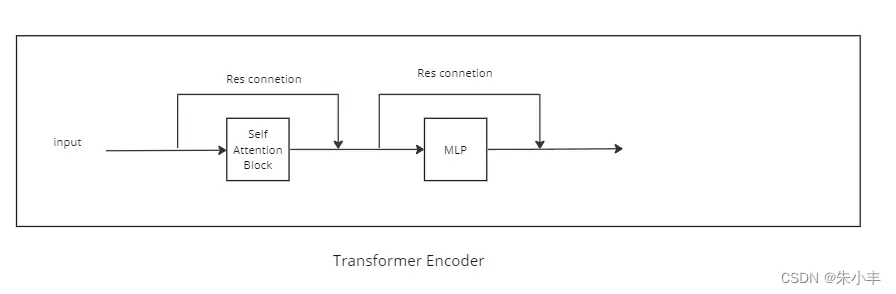
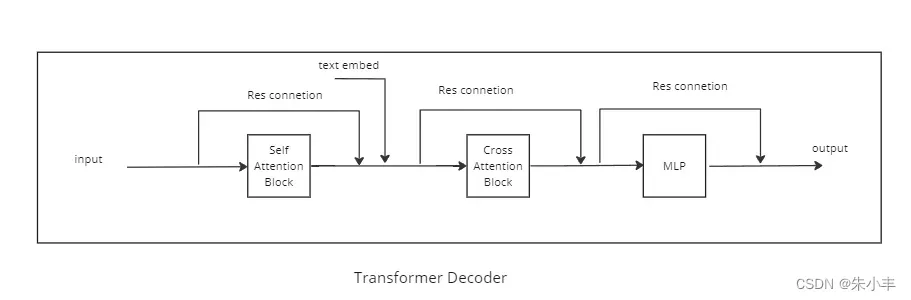
Encoder结构只使用了自注意力模块,Decoder结构使用了两种注意力模块。
Unet里使用的是TransformerDecoder
版权声明:本文为博主作者:朱小丰原创文章,版权归属原作者,如果侵权,请联系我们删除!
原文链接:https://blog.csdn.net/weixin_41866216/article/details/135697778