目录
操作行列所需要的库
import pandas as pd
import numpy as np生成被取用的dataframe对象
df=pd.DataFrame({"a":[1.78,1.8,2.8,2.75,5,5,23],"b":[20.8,10,10,30,43,1,12],"c":[23,15,50,3,343,12,95]})
print(df)生成结果展示:

dataframe取列
1、已知列名取用方法
#语法:dataframe的名字[列名]
#举例 取df的名叫a的列:
df["a"]2、已知列所在位置的取用方法
#语法:dataframe的名字.iloc[:,第几列]
#举例 取df的第几列:
df.iloc[:,0]
3、 以上两段代码生成结果相同
#语法:dataframe的名字[列名],或者dataframe的名字.iloc[:,第几列]
#举例 取df的名叫a的列:
df["a"]
#举例 取df的第几列:
df.iloc[:,0]
#生成结果相同生成结果展示:

dataframe取行
1、已知行名取用方法
#语法:dataframe的名字.loc[行名]
#举例,取df的行名叫0的列:
df.loc[0]2、已知行所在位置的取用方法
#dataframe的名字[想取某行的位置:想取某行的位置+1]
#举例,取df的第0列:
df[0:1]3、 以上两段代码生成结果相同
#语法:dataframe的名字.loc[行名],或者dataframe的名字[想取某行的位置:想取某行的位置+1]
#举例,取df的行名叫0的列:
df.loc[0]
#举例,取df的第0列:
df[0:1]dataframe按照列(列名,列的位置)取该条件下所在行
(行名同理可得)
1、已知列名取行取用方法
#语法:dataframe的名字[dataframe的名字[dataframe的列名]==该列名的值]
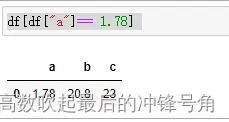
#举例,取df的a列值为1.78的行:
df[df["a"]== 1.78] 2、已知列的位置取行取用方法
#语法:dataframe的名字[dataframe的名字[dataframe的列的位置]==该列名的值]
#举例,取df的a列值为1.78的行:
df[df.iloc[:,0]==1.78]
3、 以上两段代码生成结果相同
文章出处登录后可见!
已经登录?立即刷新