前言:本人作为MOT领域新人,目前已经阅读一定量和质量的paper,尽可能的将这些MOT算法按照不同的技术路径进行分类(2016 SORT之后),并且只对论文的方法做一个大概的总结,具体细节请参照原文,如果有理解不到位的地方欢迎指出,同时也希望同方向的小伙伴一起学习交流~~
什么是MOT?
为了完成目标跟踪任务,首先需要将目标定位在一帧中,给每个目标分配一个单独的唯一id,然后在连续帧中的同一个目标将生成一条轨迹。当跟踪多个目标时,称为多目标跟踪。
MOT在应用场景上分为二维多目标跟踪和三维多目标跟踪;其中,三维较二维多增加了深度信息和角度信息。在传感器方面,三维分为单目、双目(图像,伪点云)以及激光雷达(点云),二维为相机。在算法技术方面,多数三维MOT依赖于现有的二维MOT算法进行优化改进。
MOT 是一项关键的视觉感知任务,需要解决不同的问题,例如拥挤场景中的长短时遮挡、相似外观、小目标检测困难、ID切换、速度突变等。为了应对这些挑战,研究人员尝试利用transformer的注意力机制、利用图卷积神经网络获得轨迹的相关性、不同帧中目标与Siamese网络的外观相似性,还尝试了基于简单 IOU 匹配的 CNN 网络、运动预测的 LSTM等方法。
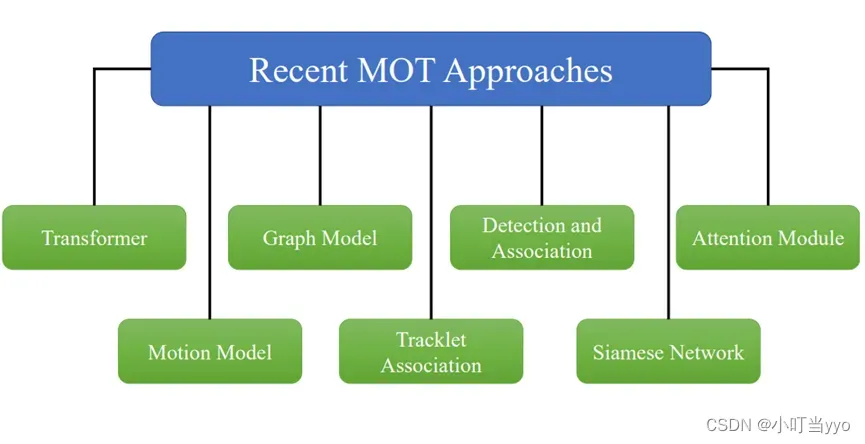
本篇技术总结主要是针对主流的CNN网络这一条脉络,对主流算法进行分类,并按照相关性顺序进行总结。由于大多数二维、三维MOT算法思想大同小异,且可以迁移使用,本文将一并做介绍,为后续研究提供发散性的参考思路。
一、评价指标(目前还没总结完,之后会补充)
1、二维评价指标
MT:Mostly Tracked trajectories,成功跟踪的帧数占总帧数的80%以上的GT轨迹数量
Fragments:碎片数,成功跟踪的帧数占总帧数的80%以下的预测轨迹数量
ML:Mostly Lost trajectories,成功跟踪的帧数占总帧数的20%以下的GT轨迹数量
False trajectories:预测出来的轨迹匹配不上GT轨迹,相当于跟踪了个寂寞
ID switches:因为跟踪的每个对象都是有ID的,一个对象在整个跟踪过程中ID应该不变,但是由于跟踪算法不强大,总会出现一个对象的ID发生切换,这个指标就说明了ID切换的次数,指前一帧和后一帧中对于相同GT轨迹的预测轨迹ID发生切换,跟丢的情况不计算在ID切换中。
FP:总的误报数量,即整个视频中的FP数量,即对每帧的FP数量求和
FN:总的漏报数量,即整个视频中的FN数量,即对每帧的FN数量求和
Fragm(FM):总的fragmentation数量,every time a ground truth object tracking is interrupted and later resumed is counted as a fragmentation,注意这个指标和Fragments有点不一样
IDSW:总的ID Switch数量,即整个视频中的ID Switch数量,即对每帧发生的ID Switch数量求和,这个和Classical metrics中的ID switches基本一致
MOTA:注意MOTA最大为1,由于IDSW的存在,MOTA最小可以为负无穷。
![]()
MOTP:衡量跟踪的位置误差,其中t表示第t帧,Ct表示第t帧中预测轨迹和GT轨迹成功匹配上的数目,dt,i表示t帧中第i个匹配对的距离。这个距离可以用IOU或欧式距离来度量,IOU大于某阈值或欧氏距离小于某阈值视为匹配上了。可以看出来MOTP这个指标相比于评估跟踪效果,更注重检测质量。
![]()
IDP:识别精确度 (Identification Precision) 是指每个行人框中行人 ID 识别的精确度。
![]()
IDR:识别召回率 (Identification Recall) 是指每个行人框中行人 ID 识别的召回率
![]()
IDF1:Identification F1,是IDP和IDR的调和均值,表示的是一条轨迹正确跟踪的时间
![]()
FPS:Frames Per Second,每秒处理的帧数。
HOTA:高阶跟踪精度,它明确地将执行精确检测、关联和定位的效果平衡到一个统一的用于比较跟踪器的度量中。有好几个子度量
2、三维评价指标
二、二维MOT
1、多目标跟踪TBD(tracking by detection)
(1)2016年 ICIP《Simple online and Realtime tracking》(SORT)
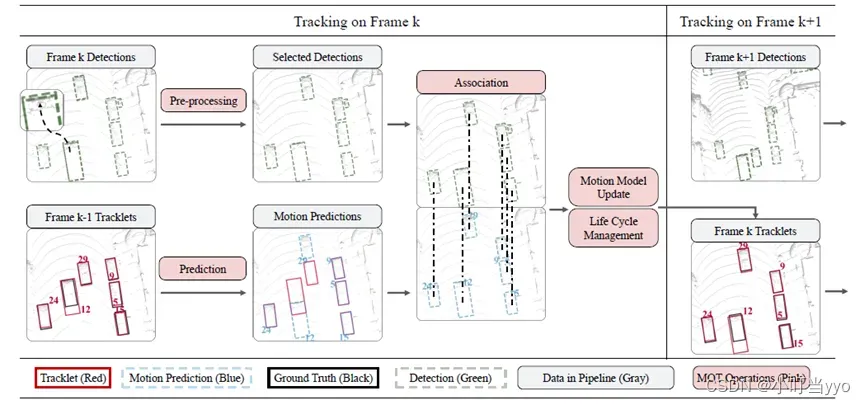
创新点:提出了一种简单、实时的数据关联方法,并可用于在线目标跟踪。
为什么:现有的跟踪算法过分追求算法复杂度以增强跟踪器的鲁棒性,导致检测速度很慢,不能实时进行。
怎么做:根据上一帧的跟踪结果,利用卡尔曼滤波预测当前帧每个目标的状态量(预测值),再利用匈牙利算法与目标检测器的检测结果对当前帧的检测状态(观测值)进行数据关联(IOU),实现跟踪。
总结:该论文沿用了tracking-by-detection框架,且后续TBD范式的MOT多数基于SORT进行改进。但对IDs和轨迹碎片化处理效果不好。
注:主要关注点在高效地实现frame-to-frame associate objects,使其能支持online、realtime的应用,而忽略了其他组件(比如遮挡问题、外观、轨迹重连),避免引入复杂性使模型无法realtime。
(2)2017年 ICIP《Simple online and Realtime tracking with a deep association metric》(DeepSORT)
创新点:在Association阶段,引入了re-ID匹配,并改进了匹配策略(级联匹配)
为什么:SORT仅仅采用了运动模型并且只关注于帧与帧之间的关联,准确率相对而言不是很高,在发生遮挡的情况下,很容易发生ID变换。
怎么做:具体做法与SORT类似,在关联阶段,引入了re-ID信息,并使用级联匹配;
分配策略:先通过马氏距离过滤掉一些框,再用re-id计算余弦距离进行匈牙利分配。
级联匹配:根据轨迹丢失观测的次数,优先匹配丢失次数少的轨迹
总结:仍然是一种基于检测的跟踪算法,与 SORT 类似,不过改进了匹配策略,加入了外观信息来提高 SORT 的性能。经过改进后,Deep SORT 能够跟踪到遮挡时间更长的目标,并且显著减少了 ID 互换的数量。
注:re-ID(re-identification),利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术,抽取一个低维的embedding向量进行不同帧间的外观匹配
(3)2018年ICME《Real-time Multiple People Tracking with Deeply Learned Candidate Selection and Person Re-Identification》(MOTDT)
创新点:设计一种基于R-FCN的评分函数(检测器),用于在跟踪器和检测器生成的候选框上进行最优选择,并使用外观和空间信息来进行轨迹关联(分层关联)
为什么:现有的方法在数据关联时,与现有轨迹关联的候选框仅有检测结果构成,但作者认为应该将跟踪器和检测器看作两个互相独立的部件,并将其结果均作为候选框(跟踪器解决漏检遮挡等问题,检测器解决漂移问题),同时前人设计候选框基于手工特征费时且精度低。
怎么做:1、评估所有的候选框采用一个统一的评分函数,这个函数由一个判别训练的目标分类器和一个精心设计的轨迹段置信度计算模块构成;2、NMS用来基于候选框的评分进行冗余候选框消除;3、在消除冗余的候选框的基础上,使用外观表示和空间信息来分层关联候选框和已有轨迹。
总结:本文使用的是“轨迹混合匹配”的机制,即将当前帧检测器的检测值和轨迹的kalman滤波预测值进行混合,共同作为当前帧目标状态的检测值,并与前一帧的轨迹进行匹配关联。轨迹由连续帧的candidates关联后生成。
(4)2021年ECCV《ByteTrack: Multi-Object Tracking by Associating Every Detection Box》(ByteTrack)

创新点:提出一种二阶段关联方法,充分利用了低置信度检测框(作者认为可能低分框可能有遮挡的目标产生)。
为什么:目前大部分的做法是关联高置信度的检测框,导致一些由遮挡或模糊等原因产生的弱小目标被过滤掉,导致轨迹消失或碎片化。但直接把第低分检测框当高分来用也不合理。
怎么做:在第一阶段,高置信度的目标先和轨迹进行关联;在第二阶段,通过IoU,将没有匹配上的轨迹和低置信度的弱小目标进行关联
总结:算法核心在于二阶段关联法,因此可以套用在任何检测器上,可以很大程度上改善一些现有算法漏检、轨迹碎片化等情况;
(5)2022年CVPR《StrongSORT: Make DeepSORT Great Again》(StrongSORT++)
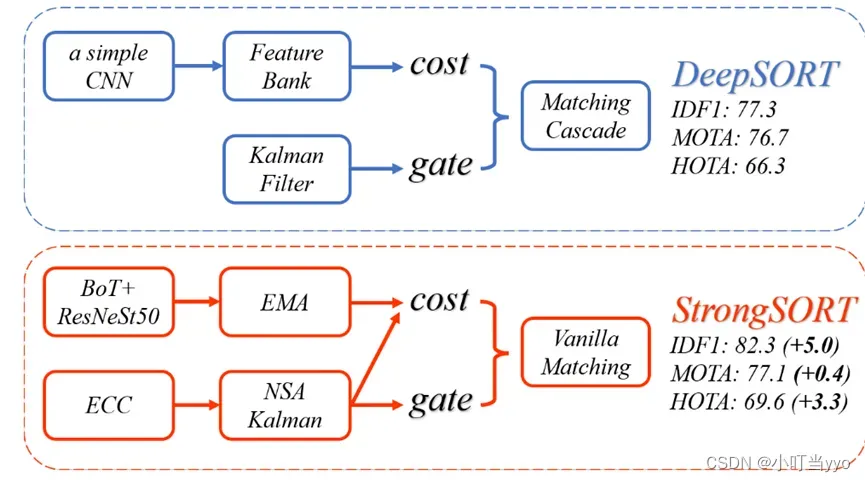
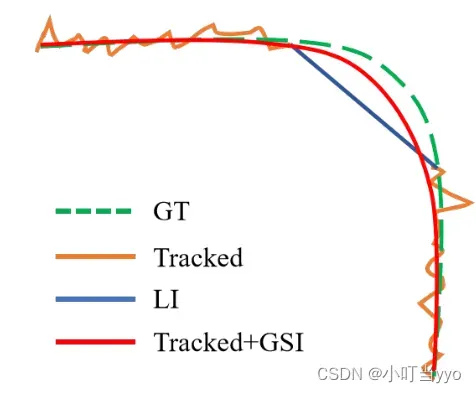
创新点:优化了DeepSORT;提出了一种无外观链接模型 (AFLink),仅用时空信息将短轨迹关联到完整的轨迹中;其次提出了高斯平滑插值 (GSI) 来补偿缺失的检测
为什么:JDE和JDT精度往往不如TBD,DeepSORT表现不佳是因为过时的技术;仅利用运动信息在复杂环境下鲁棒性差
怎么做:StrongSORT:训练更好的检测器;采用指数移动平均EMA(Exponential Moving Average)更新re-id;CMC进行相机位置补偿(两帧图像对齐配准);将传统KF替换为NSA Kalman(能根据目标检测的质量自适应调整噪声尺度);cost matrix是运动模型和re-id的加权;最后用Vanilla全局线性赋值匹配代替匹配级联(没懂这个匹配策略)。
AFLink :由两个轨道的时空信息作为输入,然后预测他们是同一条轨迹的置信度。
GSI(Gaussian-smoothed interpolation):平滑的补偿缺失的轨迹(一种带高斯平滑的插值方式,没懂)
总结:对DeepSORT各模组的优化,新增了AFlink和GSI用于补偿缺失的轨迹,整体来说精度相对上升,但速度较慢,是否可以轻量化具体模块,提升速度?
(6)2022年CVPR《BoT-SORT: Robust Associations Multi-Pedestrian Tracking》(BoT-SORT)
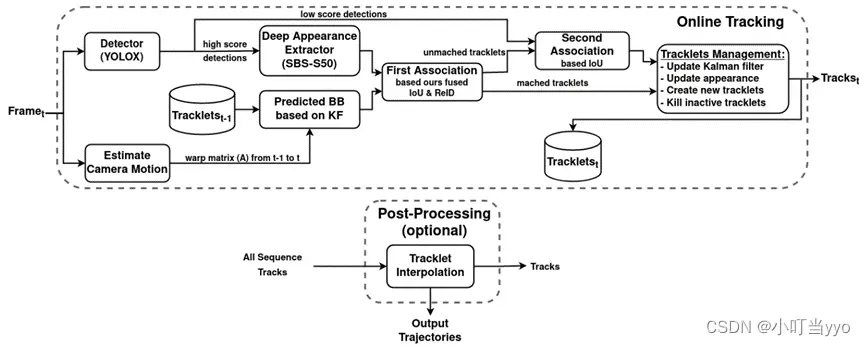
创新点:提出相机运动补偿和更准确的卡尔曼滤波器状态向量实现更好的边界框定位;提出一种基于IoU和re-id的余弦距离新的融合方式;
为什么:SORT中KF使用的状态参数用纵横比和面积导致对宽度的估计不准确,同时IoU匹配是基于预测后的边界框位置,而预测边界框的正确位置可能会由于相机运动而失败,导致跟踪性能低下;由遮挡等引起的外观低得分不适合现有的cost distance加权融合方法
怎么做:1、修改KF的状态参数为[x,y,w,h,x(•),y(•),w(•),h(•)];2、在KF对预测后的轨迹进行更新前,用CMC对预测轨迹进行矫正;3、依然使用EMA更新reid的分数,在cost matrix中使用新的融合方式融合运动信息IoU和外观信息re-id而不是用加权求和的方式
总结:作者针对卡尔曼滤波次优估计、相机运动问题和指标权衡问题提出了新的追踪器,并整合到了ByteTrack
(7)2022年CVPR《Observation-Centric SORT:Rethinking SORT for Robust Multi-Object Tracking》(OC SORT)
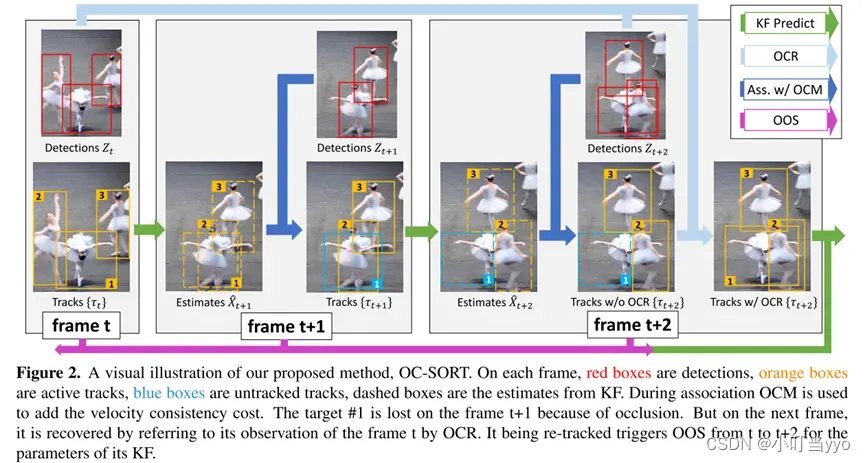
创新点:提出了OC-SORT,适用于在遮挡和非线性运动下进行鲁棒跟踪,针对基于KF的SORT三个局限提出了:OOS、OCM和OCR
为什么:SORT有三个局限性:对状态噪声敏感、随时间累积的误差、以估计为中心
怎么做:OOS(Observation-centric Online Smoothing):结合当前的观测和最后一次匹配的观测构建一条虚拟轨迹,对KF的状态噪声参数做一个平滑处理。
OCM(Observation-Centric Momentum):建立cost matrix的时候除了位置特征和外观特征外,额外增加了速度方向一致性(动量)
OCR(Observation-Centric Recovery):若一条轨迹在正常关联阶段后仍然没有被匹配成功,尝试将这条轨迹的最后一次观测与当前帧最新的观测进行关联,来恢复被中断的轨迹。
总结:目前基于KF的运动模型对遮挡、非线性运动、低帧率视频 的情况并不鲁棒。OC-SORT尝试优化运动模型(即KF滤波),并强调了检测(Observation)对恢复丢失的轨迹和减少丢失期间KF模型的误差累积的作用,提高了对遮挡和非线性运动等情况的鲁棒性。
(8)2023年CVPR《DEEP OC-SORT: MULTI-PEDESTRIAN TRACKING BY ADAPTIVE RE-IDENTIFICATION》(Deep OC-SORT)
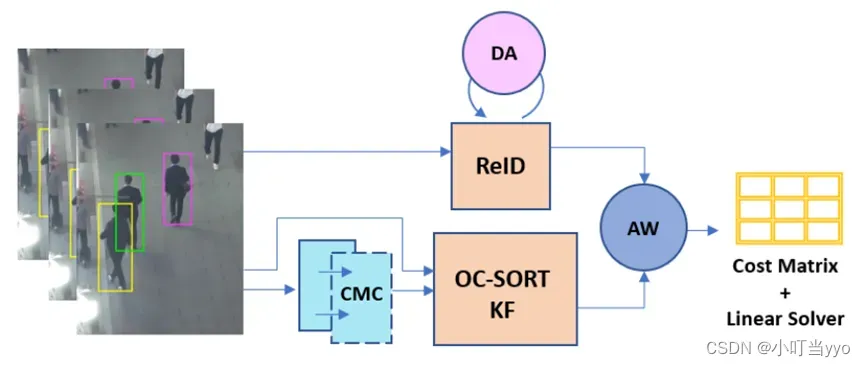
创新点:提出了一种基于动态和自适应启发式的模型,以将视觉外观与基于运动的线索结合在单个阶段中进行轨迹关联,在OC-SORT的基础上新增了CMC,DA,AW三个模块。
为什么:re-id提取器仍然包含由于遮挡、运动模糊或类似外观的对象而产生的显著噪声。
怎么做:CMC(Camera Motion Compensation):在OOS,OCM,OCR中逐帧使用相机运动补偿以提高目标位置精准度(KF更新前)。
DA(Dynamic Appearance):提出一种自适应的加权因子,根据检测结果的置信度,来调整外观的得分。
AW(Adaptive Weighting):提出一种自适应的加权因子,用来平衡cost distance中IoU和re-ID的权重
总结:将动态视觉外观和相机运动补偿引入OC-SORT,并在轨迹关联阶段添加自适应加权因子平衡运动模型和外观模型的权重以此构建合理的cost distance。
(9)2021年《Simpletrack: Understanding and rethinking 3d multi-object tracking》(SimpleTrack)(这篇是讲3D的,但个人觉得放在这里也很合适)
创新点:将TBD范式分为四个模块,并基于目前的基准分析了每个模块目前存在的不足以及改进
为什么:基于TBD范式的哪些组件对性能起着重要作用?如何改进他们以提升MOT性能
怎么做: (1)检测模块:相对于传统设置阈值,作者对detection采用NMS(非极大值抑制),来消除冗余框,并减小漏检的概率
(2)运动预测:高帧率下更适合KF
(3)关联匹配模块:相对于传统基于IOU或距离的关联方式,作者采用了GIOU的关联方式,依然使用匈牙利算法or贪婪算法来匹配轨迹和检测结果
(4)轨迹管理模块:提出两阶段关联,与ByteTrack类似。
总结: 属于是对标准TBD范式进行优化的一篇文章
TBD总结:
two-stage最大缺点就是速度慢,因为将物体检测和轨迹关联分开,而物体检测阶段,生成检测框和re-ID特征提取又分开,导致整体MOT的时间=检测框生成时间+提取re-ID特征时间+轨迹匹配时间,检测速度自然就下去了。
其次,re-id的提出让大家都有这样一个共识,也就是说MOT是主要依靠detection和re-ID信息,大多数论文的performance提升其实主要靠detection和re-id的提升,而motion信息只是作为一个辅助。但实际上,motion信息对遮挡或者说检测器漏检导致的轨迹碎片化,断裂消失等情况往往有很大“弥补”作用,毕竟预测的轨迹是连续且渐进的。
2、多目标跟踪JDE(Jointly learns the Detector and Embedding model)
(1) 2020年 ECCV 《Towards Real-Time Multi-Object Tracking》(JDE)
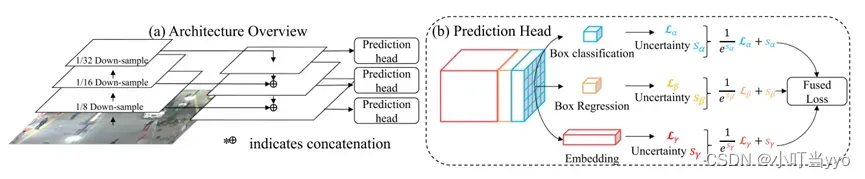
创新点:创新性地将目标检测环节和re-id提取环节两部分融合设计为一个网络
为什么:基于TBD的MOT算法将目标检测和特征提取分开,速度太慢,不适合在线跟踪
怎么做:在检测器的输出(head),多输出一个分支用来学习物体的embedding
总结:JDE只是同时输出了检测框和embedding信息,后面还是要进行目标与轨迹关联。因此还是分为检测和匹配双阶段。
(2)2020年 IJCV 《A Simple Baseline for Multi-Object Tracking》(FairMOT)
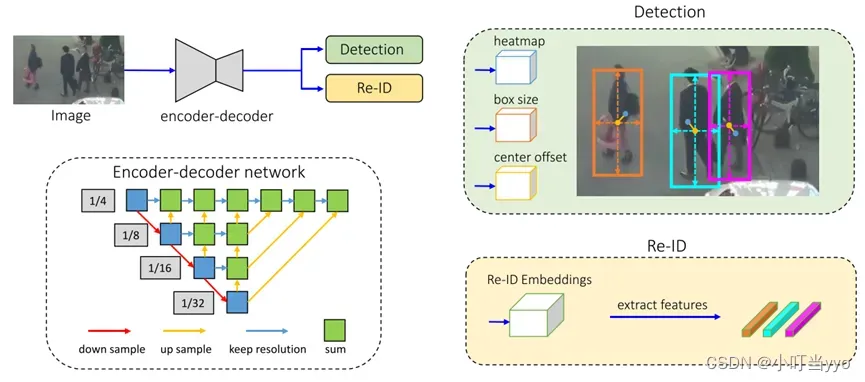
创新点:将JDE应用在anchor-free的检测器下,并采用多层要素聚合的方式融合低维特征
为什么JDE是基于anchor提取re-id特征容易导致ambiguities for the network,并且anchor中心和物体中心有偏差,从而导致精度太低
怎么做:采用了基于anchor-free的框架,用关键点估计目标中心(如centernet)并提取re-id的低维特征(高维容易导致过拟合),并采用多层要素聚合的方式融合特征(浅层特征包含细节特征,深层特征包含语义特征)
总结:优化JDE范式,性能指标很好,但是针对MOT的一些难题比如遮挡、模糊、运动突变等问题依然没有很好的解决办法
(2)2023年TCSVT《Multi-Object Tracking: Decoupling Features to Solve the Contradictory Dilemma of Feature Requirements》
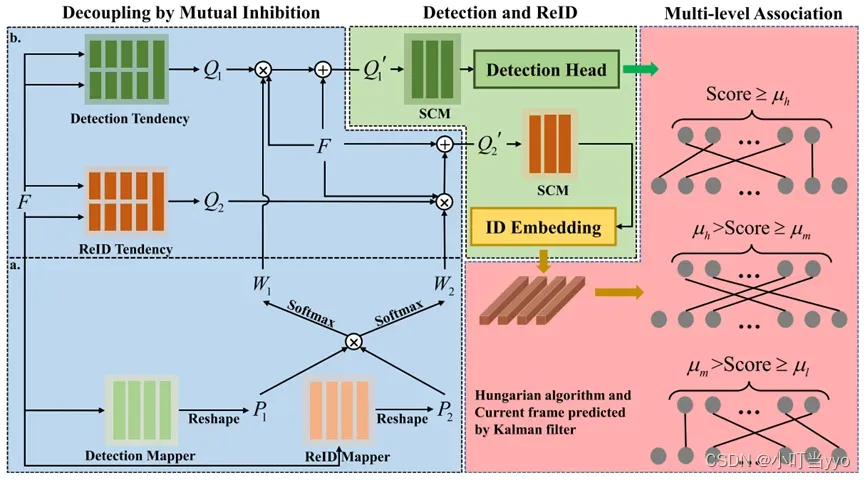
创新点: 本文设计了一个特征解耦模块,相互抑制解耦(DMI)和自约束模块(SCM)有效地解耦共同特征和个体特征,分别用于检测和ID嵌入。提出一个简单的三阶段数据关联。
为什么:检测需要具有较强表达能力的公共特征,re-id则需要具有高分辨率能力的个体特征,因此训练阶段检测和re-id对特征的需求冲突将导致特征提取偏离最优结果
怎么做: 1、FDTrack在骨干网之后增加了特征解耦模块DMI。针对检测与ReID之间的特征矛盾,DMI利用检测与ReID的相互抑制信息权重(即W1和W2)对骨干网中提取的特征进行解耦。2、在Detection Head和ID Embedding之前加入了自约束模块SCM,以弱化去耦引起的特定偏差,稳定检测特征和ReID特征。3、MLA将检测结果分层,并使用三级匹配策略完成数据关联。
总结:三级匹配有一定合理性,选择合适的阈值很重要;对FairMOT改进进一步缓和了Detection和ReID的矛盾。
JDE总结:
实质上任然是双阶段算法,且精度不如TBD,胜在速度
3、目标跟踪JDT(joint tracking and detection)
(1)2019年 ICCV《Tracking without bells and whistles》(Trackor++)
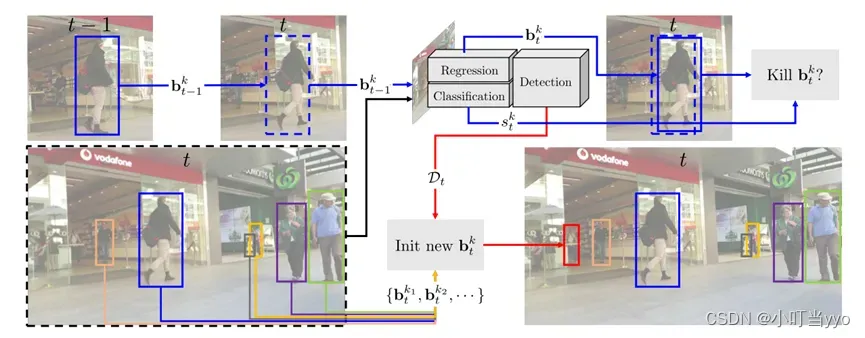
创新点:提出了Tractor,利用一些耦合的检测与判别模块,将track融合进detection;增加了两个extensions,分别是基于Siamese CNN的re-ID网络,以及基于CMC和CVA(constant velocity assumption)的motion model来处理遮挡问题和相机抖动、低帧率下目标高速运动的问题
为什么:TBD速度太慢,且后期id增多时,复杂的关联阶段会产生巨大的计算负担
怎么做:蓝色线:用来对t-1帧已有的框进行重新回归判定,利用Regression模块获取t帧时候的新位置,同时用Classification模块对这个新的位置进行判断目标是否仍然存在;
红色线:用来检测新产生的目标,保留那些与t-1帧没有足够IOU的框,作为新目标参与到下一帧的迭代。
总结:利用现有的目标检测方法、孪生re-id方法和相机运动估计法,重新组合而得到一套可以实现端到端输出的新架构,使detection拥有track功能;有classification模块,是个面向特定类群的跟踪器,要先进行离线训练。(当年达到了SOTA,但毕竟是个tracking的问题,做法是否有点作弊了?)
(2)2020年 ECCV《Tracking Objects as Points》(CenterTrack)

创新点:提出了一个基于点的范式,类似于光流法。它可以将检测和跟踪网络结合一起学习,是一阶段跟踪算法。
为什么:二阶段跟踪算法的关联策略过于复杂和缓慢,导致整个模型推理速度慢。
怎么做:CenterTrack的输入是连续的两帧图像,以及由首帧图像的检测结果高斯渲染出的heatmap,模型会输出一个从当前帧目标中心点到前一帧目标中心的偏移量,heatmap和检测框。同时,在训练中使用了一些激进的数据增强策略,提高训练的准确性,甚至能在静止的单帧图片上预测目标的运动轨迹(通过随机缩放和变换当前图像,来生成先前帧,从而达到模拟目标运动的目的)。
总结:基于Centernet的推广,一阶段加上忽略外观信息,推理速度极快;能扩展到三维空间;缺点是速度预测不适用在低帧率的数据上,并且只适合在连续帧之间传递ID,没有考虑如何给时间上有较大间隔的对象重新建立联系的问题(遮挡)。
4、目标跟踪其他方法
(1)2021年 CVPR《Probabilistic Tracklet Scoring and Inpainting for Multiple Object Tracking》(ArTIST)
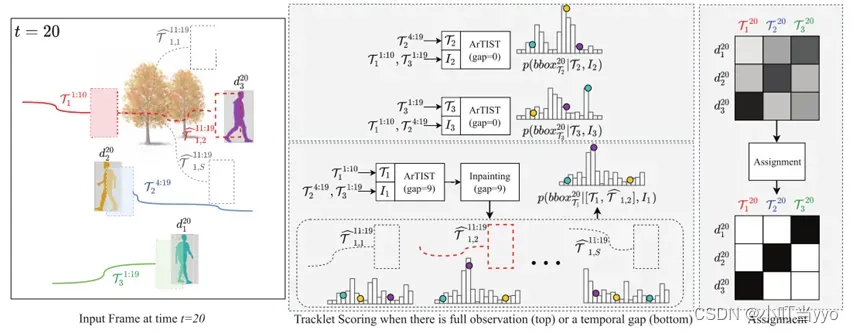
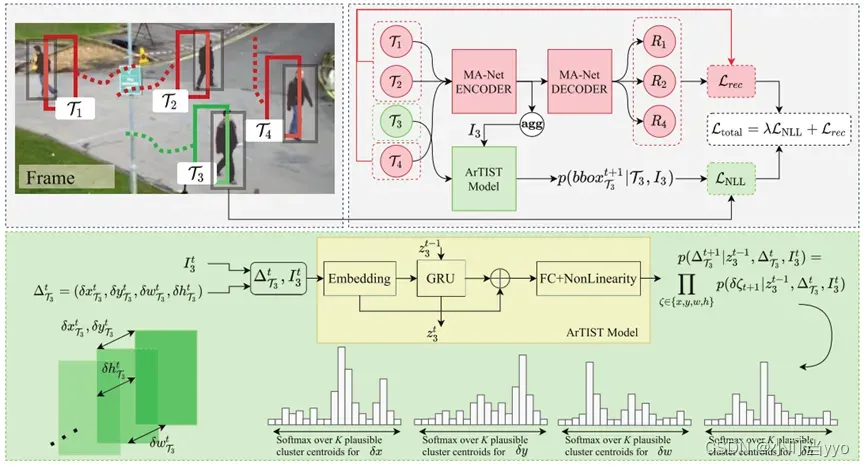
创新点:提出一个概率自回归的运动模型,学习并生成运动轨迹的多模态分布,根据轨迹的似然度对其进行评分并联合检测框匹配。
为什么:过分依赖检测器和re-id并长期忽略运动信息导致无法处理长时间的遮挡等问题
怎么做:通过概率分布,对轨迹运动进行建模,联合当前时刻所求轨迹和同时刻其余轨迹的运动模型(通过MA-Net 重建出一个tracklet motion velocity),通过ArTIST预测出下一时刻轨迹出现概率最大的位置,并和检测器的检测结果进行一个最优匹配,实现对某一轨迹的ID赋予。(Inpainting也是通过这个模型一帧一帧预测,取S个轨迹)
总结:各大数据集上表现很好;不仅可以为现有的轨迹分配新的检测,而且允许在物体丢失很长时间(例如由于遮挡)时通过采样轨迹来Inpainting轨迹,以填补错误检测造成的空白。
(检测器会漏检、误检从而导致轨迹消失和碎片化;真实轨迹一定是连续的,运动预测不会产生轨迹中断,因此运动信息对维持一条轨迹十分必要。人脑是识别不同目标的轨迹的?)
备注:没公开源码,很多细节都是靠猜的。。不是很读得懂
(2)2021年CVPR《Multiple People Tracking by Lifted Multicut and Person Re-identificatio》
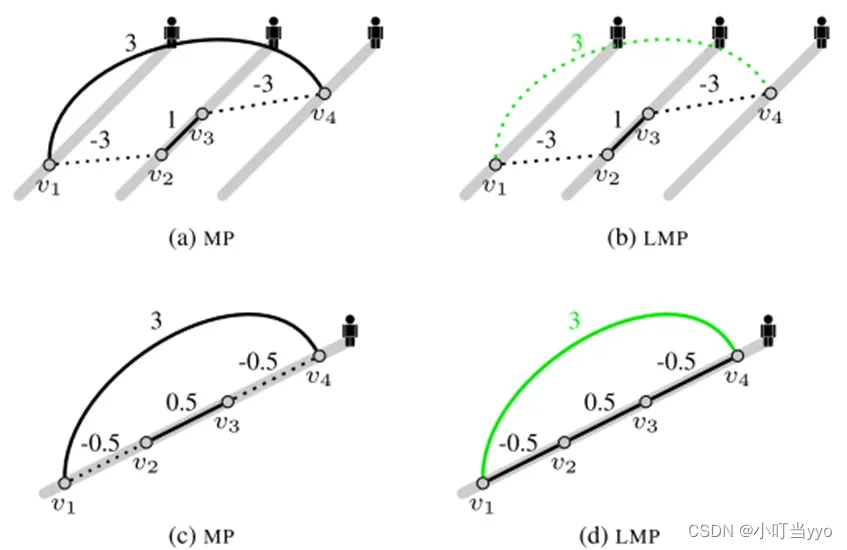
创新点:将multi-persontracking问题看成最小化代价lifted multicut问题。在regular edges的基础上引入lifted edges;设计并训练融合行人人体姿势信息的深度神经网络来进行行人重识别。
为什么:传统的做法将一条单独的轨迹与观测box进行关联,而任何的轨迹的生成所带来的错误很可能会被传播到最终解,用来解决遮挡问题和基于re-id的跨帧间匹配
怎么做:将多人跟踪转换为最小成本提升的多边跟踪问题。为跟踪图引入了两种类型的边(规则边和提升边)。 规则边定义了图中可行解的集合,即哪个节点应该被连接/切割。在不修改可行解集的情况下, 提升的(lifted)边为目标增加了“哪个节点应该被连接/切割”的额外长程信息。新公式对远距信息进行了编码,且通过强制可行解中的有效路径,以统一和严格的方式惩罚了长期的假连接(例如,看起来相似的人)。
总结:不懂multi-cut。。大概就是说通过聚类得到规则边,而lifted edge引入长距离信息,用于加强惩罚cost, regular edges和lifted edge一起决定哪些节点应该被joint or cut。其次引入一个融合了姿态信息的re-id网络(CNNs)。
(3)2015年ICCV《Multiple Hypothesis Tracking Revisited》
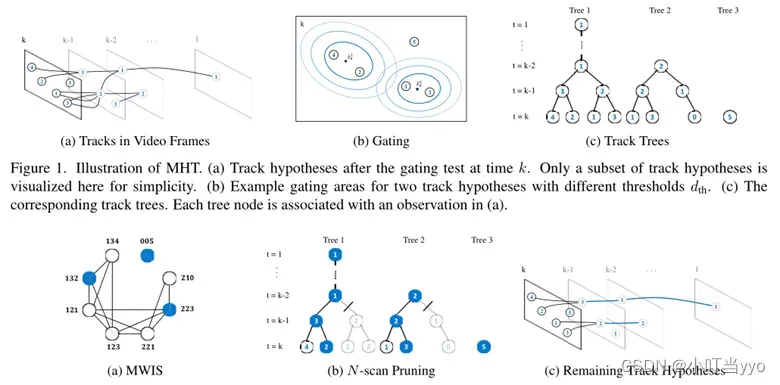
创新点:提出了优化的MHT,一种针对每个轨迹假设训练在线外观模型的方法,且该方法能大幅度削减假设分支的数量,在线训练外观模型的运算量与分支数无关,减少了运算量。
为什么:MHT在视频跟踪中很少应用,原因是运算量太大。作者认为目前检测器的新进展以及用于对象外观有效特征表示的发展为MHT方法创造了新的机会。
怎么做:在每一帧,从观察中更新轨道树,并对树中的每个轨道进行评分(评分规则看论文)。然后可以通过解决最大加权独立集(MWIS,没了解过)问题来找到最佳的非冲突轨迹集(最佳全局假设)。然后,从树中修剪出偏离全局假设太多的分支(标准的N扫描修剪方法,并且算法前进到下一帧。
在线外观训练模型:采用多输出正则化最小二乘框架(multioutput regularized least squares framework, MORLS)来学习场景中目标的外观模型
总结:MHT的性能取决于能否快速可靠地修剪搜索树中的分支,以保持跟踪假设的数量可管理。本文提出的MHT,将每帧中的有效分支数削减到所有分支的约50%,且通过正则化最小二乘框架高效地学习外观模型,该模型的计算成本与假设分支的数量几乎没有依赖性(MHT其实个人不是很了解,有错误欢迎提出)
(4)2021年ICRA《DOT: Dynamic Object Tracking for Visual SLAM》
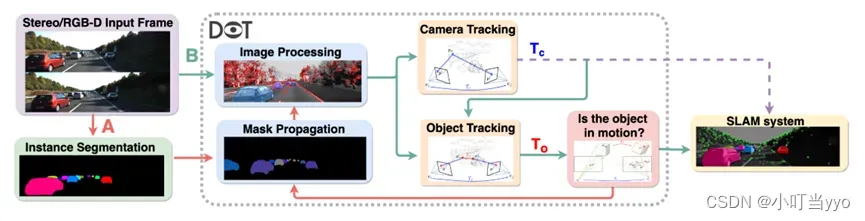

创新点:提出了DOT(动态对象跟踪),结合实例分割和多视图几何学为动态对象生成掩码,使基于刚性场景模型的SLAM系统在优化时避开此类图像区域,提高其在高动态环境中的鲁棒性和准确性。
为什么:通常基于静止环境进行建图和定位,将动态区域作为outliers并将其忽略。通常做法需要通过多帧来进行判断是否为outliers,导致引入误差以及一致性问题;如果将全部潜在动态区域去除也会导致精度较低。
怎么做:1、实例分割出所有潜在的运动目标;
2、image Processing部分提取和分类在静止区域的点和在动态目标上的点,其中相机姿态跟踪仅利用静态区域的信息,依据相机位姿,对每一个潜在动态物体进行单独的估计(object tracking)
3、利用几何原则判断物体是否在运动,物体运动与否的信息将用来更新每一帧的动态区域与静态区域的掩码
4、依据物体运动估计生成新的掩码(传播),因此不需要每一帧都分割
总结:将DOT加入到ORB-SLAM2中发现在静止或者运动的场景,性能都有提升,如果不提出运动目标,那么会造成轨迹的误差,如果将所有目标的掩码区域都抛弃掉,将丢失大量的信息;DOT可以通过掩码的传播校正神经网络的错误分割
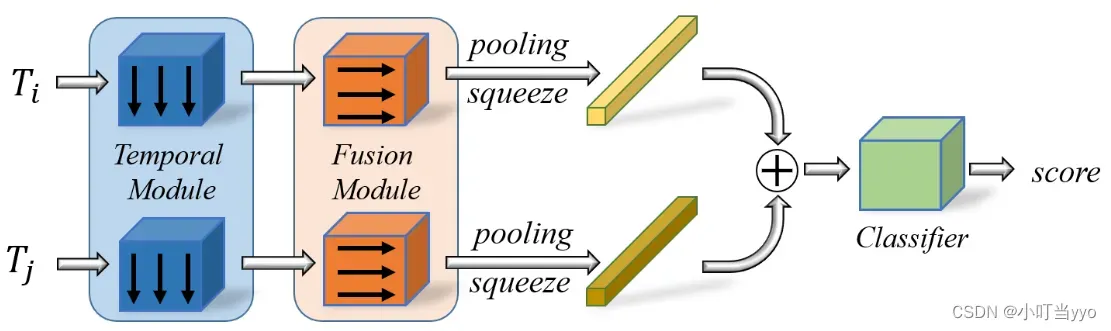
(5)2021年CVPR《Quasi-Dense Similarity Learning for Multiple Object Tracking》(Qdtrack)
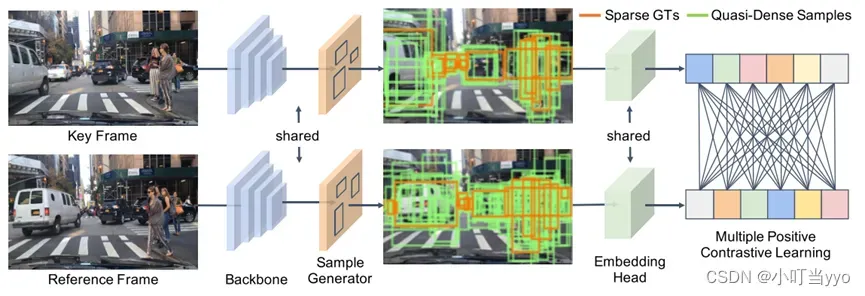
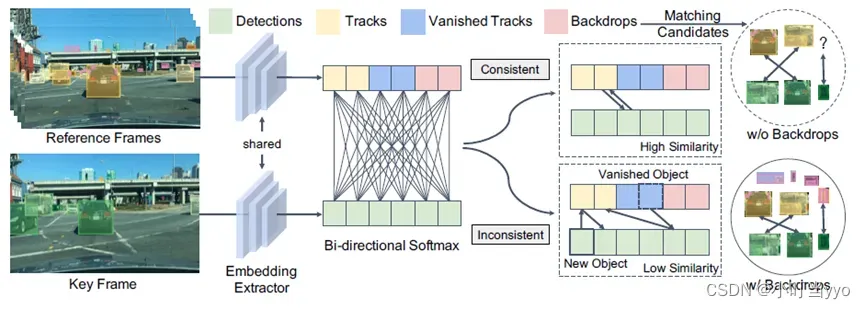
创新点:作者提出了一种基于稠密GT提取re-id特征并用Bi-softmax进行双向匹配的匹配方法,没有使用位置和运动信息
为什么:位置运动匹配只适合一些简单的场景,当目标拥挤遮挡下,位置信息很容易产生误导;之前的Re-id匹配只用稀疏gt样本训练提取embedding特征,没有充分利用可能的gt样本多样性(rigion proposal),作者认为如果能有一堆正样本和负样本参与训练优化的话,这样可能会使提取的embedding特征更具备判别性。
怎么做:训练流程图如上,输入两张图片,使用RPN生成ROI,再进行feature extract,联合正样本和负样本进行损失计算;推理阶段将提取到的特征输入到bi-softmax进行双向匹配
- 训练reid feature时,多个正样本和多个负样本同时参与计算损失。利用rpn产生的roi,根据roi和gt的iou>0.7就认为是正样本roi,iou<0.5时认为是负样本roi。这样在前后帧的(关键帧和参考帧)图片中,和具有同一个id的gt的正样本之间会计算损失,同时关键帧的正样本和参考帧的负样本之间也会计算损失。
总结:纯用外观特征做匹配,效果不错,BDD100k数据集上top 1,方法也比较简单。而且,2D多目标跟踪对自动驾驶领域帮助不大,但是3D多目标跟踪往往基于点云来做,reid特征做匹配在低帧率或者高速运动条件下还是要优于运动位置信息做匹配的。如果可以把2D的外观表示特征优势和3D的位置运动信息结合起来,或许对3D MOT会有更大的帮助。
(6)2016年 ICCE《Online Multiple Object Tracking with the Hierarchically Adopted GM-PHD Filter using Motion and Appearance》
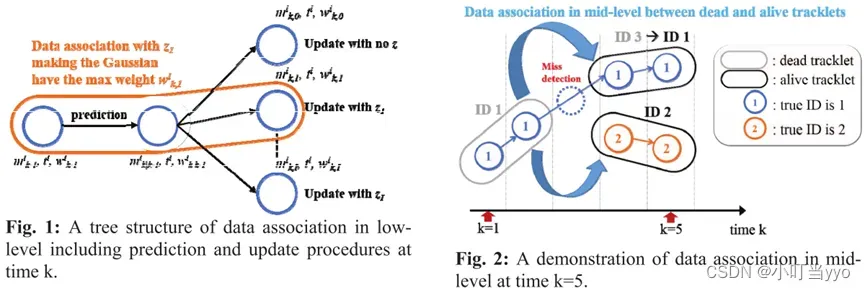
创新点:使用了GM-PHD进行数据关联,并提出了双层关联方法用于处理遮挡漏检等情况。
为什么:传统的MOT方法容易出现IDs和fragmented tracklets,GM-PHD对存在噪声干扰的观测具有鲁棒性。
怎么做:1、GM-PHD:初始化、预测、更新、剪枝、状态估计(label传递);
2、数据关联;
3、双层关联:(1)low-level:无漏检情况,直接用GM-PHD数据关联;
(2)mid-level:第一步将存活时间小于阈值的轨迹删除;第二步,将轨迹分为dead和 alive,将dead最后一帧目标和alive第一帧目标根据颜色直方图和位置大小等信息进行关联
总结:MOT 15表现并不好,将雷达MTT领域的RFS引入visual MOT是一种可尝试的新方法,但还没找到其性能指标不理想的原因(可能是RFS适合处理杂波漏检等情况,但MOT更大的挑战来源于遮挡而非检测器)
(7)2023年Arxiv《Track Anything: Segment Anything Meets Videos》
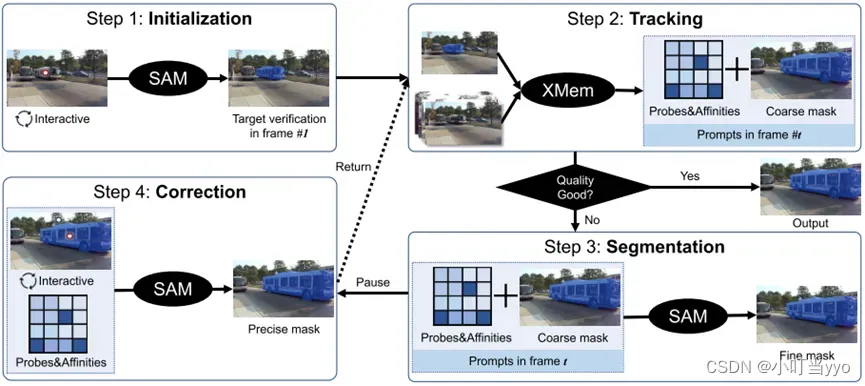
创新点:将SAM推广到video,不是每帧单独使用SAM,而是将SAM集成到时间相关性的架构中(XMem)
为什么:SAM难以对视频进行实时目标分割;Xmem在长视频中需要精确的分割掩码
怎么做:结合SAM和XMEM;先通过交互的方式初始化SAM(通过点击需要跟踪的目标);然后,利用XMEM根据时空信息给出下一帧对象的掩码预测;其次,利用SAM给出更精确的掩码描述;在跟踪过程中,用户可以在发现跟踪失败的情况下立即暂停并及时进行更正
总结:SAM的应用,相当于是一个Detection
三、三维MOT
1、3D多目标跟踪TBD
(1)2020年ECCV《3D Multi-Object Tracking: A Baseline and New Evaluation Metrics》(AB3DMOT)
该论文是3D MOT的baseline和TBD范式。将SORT算法应用在3D场景下,依然是基于KF滤波和匈牙利匹配的目标跟踪算法,同时状态变量增加了偏航角和三维尺寸。具体不展开了
(2)2021年IROS《Score refinement for confidence-based 3D multi-object tracking》
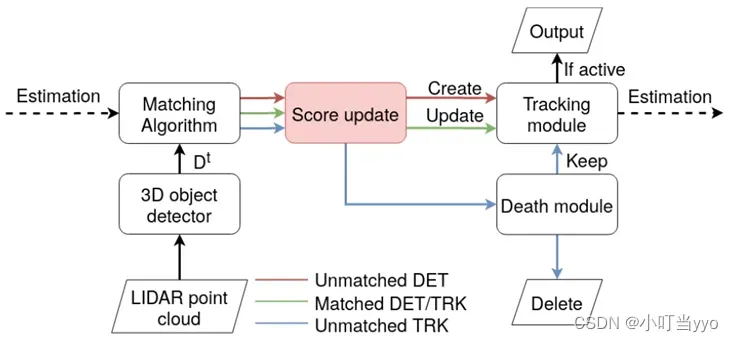
创新点:提出一种confidence-based的方法对轨迹和匹配过程进行生命周期管理。并针对于先前基于检测置信度的轨迹得分的不足,提出了一种新的分数更新函数,使一条轨迹的分数是渐进且连续的。
为什么:目前轨迹管理模块是用count-based方法,但难以设置阈值,容易出现提前死亡或漏检误检等情况。同时作者认为仅仅使用单帧的检测结果为轨迹打分是不合理的,一条轨迹的质量变化是渐进和和连续的,应该考虑该轨迹长期的分数情况进行匹配和终止管理。
怎么做:新生轨迹分数为检测目标的得分。若轨迹没有与目标匹配上,会根据衰减因子不断衰减得分,若实现了匹配,会根据新的分数更新函数更新得分。
总结:整体改变较小,将原本二值化的count平滑为了可微的累加。
(3)2021年ICRA《EagerMOT: 3D Multi-Object Tracking via Sensor Fusion》
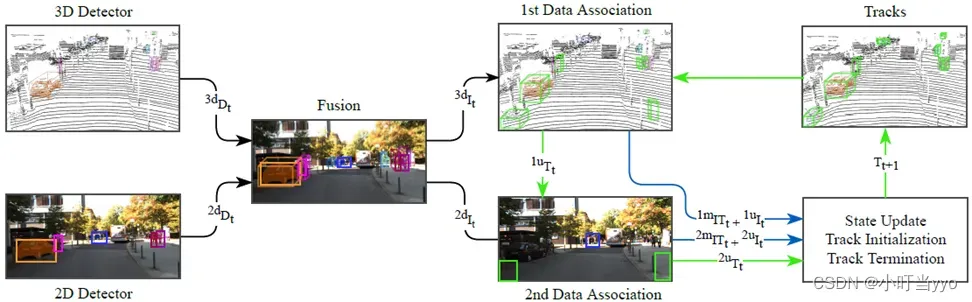
创新点:提出了一个简单而有效的多传感器数据关联方法,可以处理并融合不同目标检测算法的结果,可以处理不同模态的数据。
为什么:2D图像上的检测可以看得更远,而且检测更准,但是缺乏距离信息。3D点云有精确的距离测量,但远距离的点较稀疏,经常出现漏检,故考虑融合3D和2D检测结果,提高3D目标跟踪对遮挡、远距离目标跟踪的效果。
怎么做:(1)首先将3D检测器和2D检测器的检测结果关联(3D_2D、2dIt、3dIt)。(2)第一阶段将3D检测结果和轨迹进行匹配,卡尔曼更新(3)没匹配上的轨迹和2dIt 进行匹配。(4)航迹管理与AB3DMOT类似
总结:效果很好,利用现有的2D检测器和3D检测器就行,无需额外训练模型。利用了2D检测信息提高了精度,相当于跟踪更稳定(无3D检测匹配时)和加强(同时有3D检测和2D检测和跟踪匹配)改善了3D检测失败(距离较远或者遮挡)时的跟踪性能,但是同时也导致IDs比较高(没有相对应的措施)。
(4)2022年《Sensor Fusion Based Weighted Geometric Distance Data Association Method for 3D Multi-object Tracking》(WGDMOT)
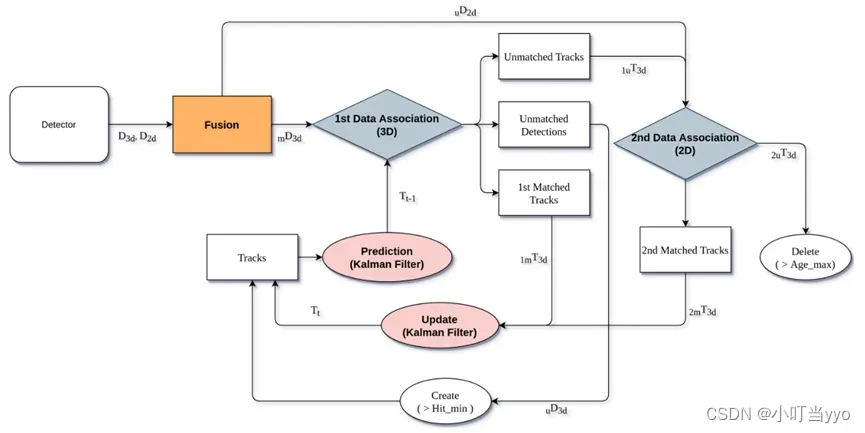
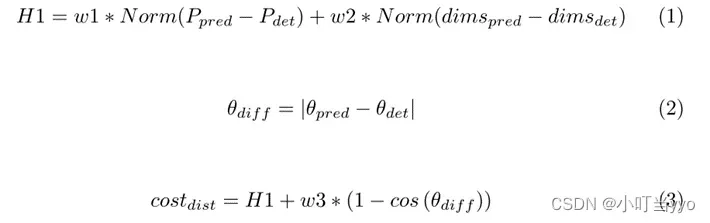
创新点:设计了一种基于加权几何特征的代价距离进行数据关联,利用不同几何特征之间的关系,提高了数据关联的准确性。
为什么:传感器方面与EagerMOT类似,大多数3D MOT框架倾向于使用3D框之间的联合交集(IoU)进行数据关联,但容易出现检测和预测没有重叠的情况影响跟踪效果;同时EagerMOT提出的scaled distance考虑了dimensions和坐标具有相同的权重(重要性),但实际上不同跟踪目标的属性不同,因此dimensions和坐标应不能承受同等的权重。
怎么做:大体技术路径与EagerMOT相似,EagerMOT匹配时使用的是代价距离是scaled distance,而WGDMOT使用的是加权几何特征的代价距离
总结:检测效果优于baseline(EagerMOT)。通过调整w1、w2和w3的大小来调整它们的重要性,这导致小目标跟踪的效果显著改善。总体而言该篇论文只是针对如何优化检测和预测的关联问题上做了改进(且改进不大),整体框架与EagerMOT差不多。
备注:查询不到发表的会议(International Conference on Cognitive Systems and Signal Processing Springer, Singapore)的水平,有大佬可以给我科普一下吗?
(5)2023年《DFR-FastMOT: Detection Failure Resistant Tracker for Fast Multi-Object Tracking Based on Sensor Fusion》(DFR-FastMOT)
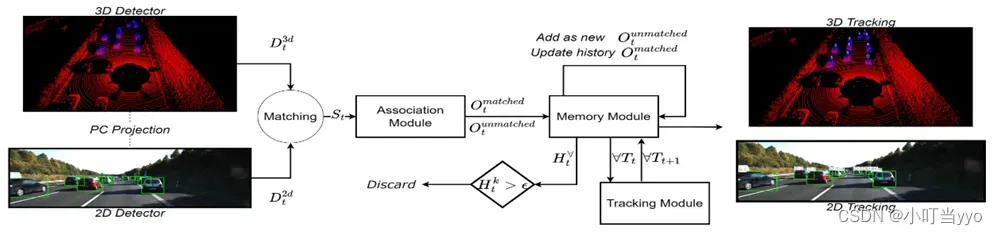
创新点:提出一种代数公式融合来自多传感器的数据并进行数据关联提高了计算时间和允许保留遮挡时的长时记忆;在发生遮挡情况下,用box的质心距离衡量cost distance,更好的关联遮挡的目标和轨迹
为什么:当前的MOT方法将目标信息(如目标的轨迹)存储在记忆中,以在遮挡后恢复目标。然而,它们为了节省算力只保留了短期记忆,这对MOT的跟踪性能会产生影响。
怎么做:1、先进行3D检测和2D检测的匹配融合,保留一些高置信度的框(由于遮挡或远距离的低质量检测框应该被淘汰?)2、保留的框(2D、3D)根据各自的代价函数与经过KF预测后的轨迹(2D、3D)分别构建一个cost matric3、加权融合两个cost matrix进行匈牙利匹配,完成关联4、更新轨迹(3D、2D一起更新,分别生成2D跟踪图和3D跟踪图)
总结:前面的工作使用了目标的短期记忆,处理某些遮挡场景,这最终会影响整体跟踪性能。本文通过引入关联和融合步骤的代数公式来解决这个问题。性能指标在baseline基础上提升了很多,idea有启发性,写作水平额,未开源。
(6)2022 RAL《DeepFusionMOT: A 3D Multi-Object Tracking Framework Based on Camera-LiDAR Fusion With Deep Association》
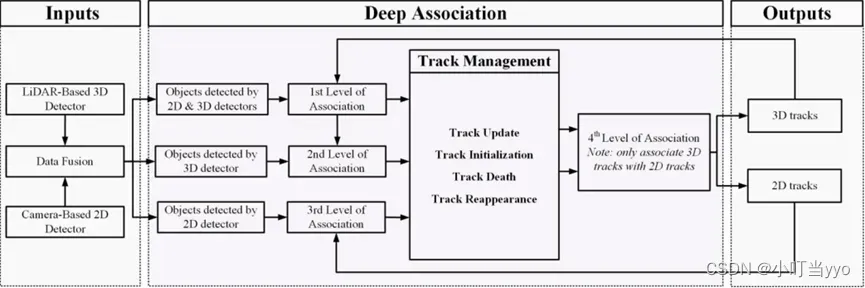
创新点:提出了一种基于LiDAR-相机融合的四级深度匹配策略,并新增了一种轨迹状态
为什么:单传感器有局限性,优化目前的Fusion匹配策略
怎么做:(1)将LiDAR和相机共同检测到的目标优先匹配3D轨迹
(2)将只有3D检测的目标与剩下未匹配的3D轨迹进行匹配(前提连续匹配到三帧,单传感器出现误检概率大)
(3)将只有2D检测的目标跟2D轨迹进行匹配
(4)将第二步骤中的未匹配轨迹(未匹配或待匹配三帧)的3D投影到2D平面,通过box的IOU进行关联融合(并将2D的id、帧数、轨迹替换到3D)
总结:reappearance的设置没有理解,是否可以理解为如何判定一个被遮挡目标是否死亡?引入了一个深度匹配策略,HOTA达到SOTA,速度也不慢(感觉因为四级匹配拉慢了速度)整体思想就是通过融合相机和雷达将范围内的目标做到应检尽检,如何优化关联阶段让尽可能多的目标参与匹配是一个值得思考的问题。
(7)2023 Arxiv《3D Multi-Object Tracking Based on Uncertainty-Guided Data Association》
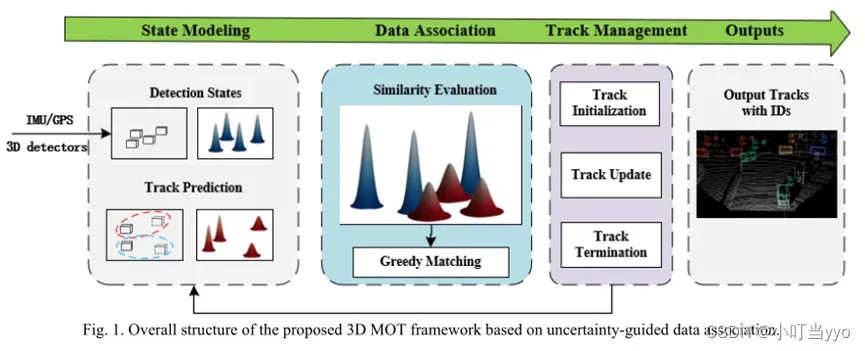
创新点:提出了UG3DMOT,该方法在数据关联阶段摒弃了常用的确定性轨迹和确定性检测,而是将轨迹和检测建模为随机向量进行数据关联。这些随机向量的分量是单独的高斯随机变量,代表不同的轨迹和检测随机性
为什么:大多数基于TBD的MOT方法,在数据关联阶段采用确定性跟踪和检测进行相似度计算,即忽略了轨道和探测中存在的固有不确定性,在复杂环境下(遮挡、漏检)轨迹的不确定性变得相当大,传统关联方法在一定程度上降低了相似度计算的有效性和可靠性。
怎么做:将检测和轨迹建模为单独的高斯随机变量,使用JS散度结合航向惩罚项来测量轨迹和检测之间的相似性,并将跟踪不确定性引入成本函数以消除“多重关联问题”(匹配范围越大,距离惩罚越大)。
JS散度:用于评估两个分布之间的相似程度;惩罚项:轨迹和检测的方向不相似度
总结:将检测和轨迹预测扩展为单个的高斯分量进行数据关联,以此来处理弱小目标、遮挡目标等情况的发生,相当于扩大了匹配范围,效果达到SOTA。Detection的协方差要如何计算?
2、3D多目标跟踪JDT
(1)2021年ICCV 《Exploring Simple 3D Multi-Object Tracking for Autonomous Driving》(SimTrack)
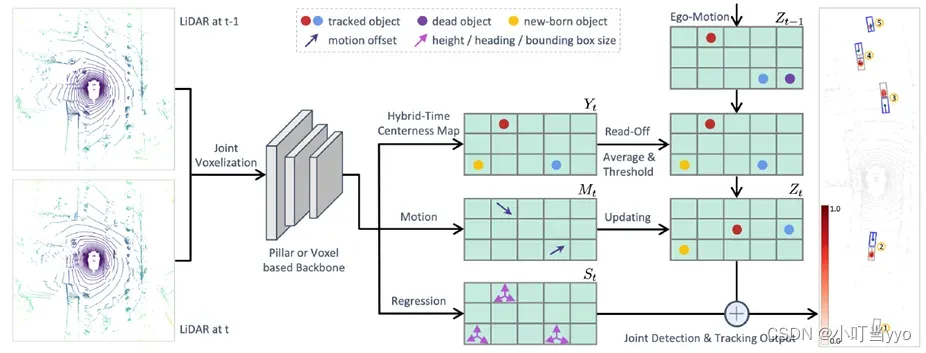
创新点:提出一种新的混合时间中心点映射,直接将检测和轨迹关联起来,并提供一个置信度,取消了传统匹配阶段,能通过阈值将ID传递、新生创建和轨迹删除集成于一体。
为什么:TBD范式需要人工设计匹配规则和调试相关参数,超参数的设置依赖于大量实验和先验经验,费时费力,并且针对特定场景需要重新调参,泛化能力差
怎么做:输入两帧点云数据通过一个backbone,输出三个分支:(1)Hybrid-Time Centerness Map用于记录目标在输入帧中最早出现的位置(若t-1帧出现,t帧消失则视为负样本),并赋予置信度,t-1帧轨迹通过Ego-Motion与Centerness Map融合,通过预先设置的阈值,实现轨迹管理一体化;(2)Motion用于预测t-1帧到t帧目标的运动,并更新融合后Centerness Map Zt-1中目标的位置Zt;(3)Regression 用于回归三维尺寸
总结:将MOT模型实现端到端的训练以及用数据驱动的方式将目标关联,新生目标创建和消失轨迹删除集成于一体,可以提高模型的推理速度并降低模型的训练成本,还有全局信息的引入可以处理遮挡等问题。
Question:ego-motion后将t-1帧目标转换到当前坐标系下与Yt融合,由于ego-motion有误差,会不会出现两个不同的目标位于同一位置,直接读取id的方法导致两个不同的目标共享同一个id?
(2)2023年Arxiv 《You Only Need Two Detectors to Achieve Multi-Modal 3D
Multi-Object Tracking》
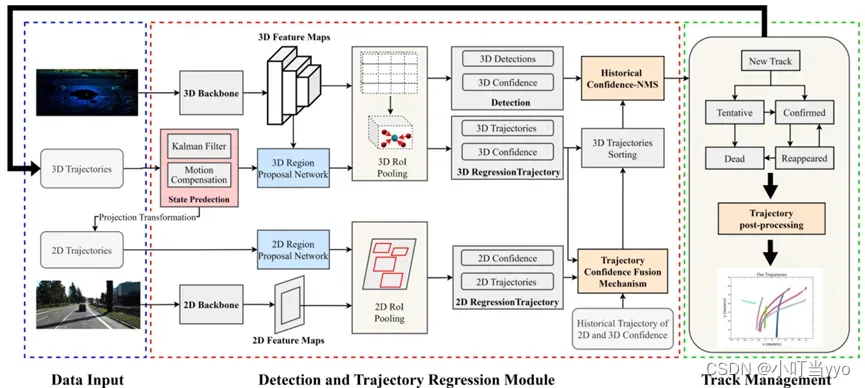
创新点:提出了基于JDT的多传感器融合MOT,通过网络回归出轨迹位置以及置信度,设计了置信度融合模块,分析了当前框架下轨迹的可能状态(弱目标或强目标),用来对轨迹进行NMS和有序关联检测
为什么:作者认为单模态的MOT信息不充分,目前的多模态方法无法有效整合3D和2D信息,同时基于TBD需要设计复杂的数据关联模式(其实就是想将Trackor用在3D上)
怎么做:3D:作者使用two-stage网络用来生成轨迹位置和confidence,其中将上一帧的轨迹通过KF和CMC生成Proposal Rigion 用于产生当前帧的检测结果;
2D:将上一帧的3D轨迹投影到2D平面上生成Proposal Rigion,用来产生当前帧2D的轨迹位置和置信度;
置信度融合:融合2D、3D和轨迹历史置信度(原文中用的是平均,每一个传感器每一帧的置信度权重都一样);
根据置信度融合后的结果,将目标分为强目标和弱目标,强目标先优先进行有序关联检测;
总结:实验结果还可以,没怎么明白NMS和消融实验当中的Ascending排序的意义;其次对于针对confidence fusion中每一帧每一类传感器的confidence权重一样表示有点不合理。
3、3D多目标跟踪其他方法
(1)2023年CVPR 《GeoMAE: Masked Geometric Target Prediction for Self-supervised Point Cloud Pre-Training》
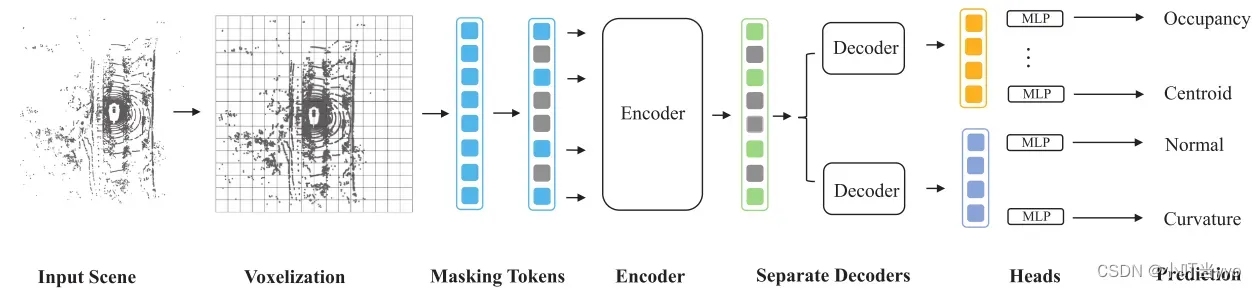
创新点:提出一种基于几何感知的自监督模型用于点云预训练。用细粒度点统计和曲面属性来实现有效的表示学习
为什么:基于点云的三维目标检测和跟踪需要大量标注,较难获得。目前与二维图像处理方法类似的基于pretext task的自监督模型无法为下游任务带来足够的改进。原因是忽略了点云与图像的根本区别:点云提供场景几何,而图像提供亮度。
怎么做:首先,对原始点云进行体素化,将体素转换为对应的特征token,并按照预定义的比例随机屏蔽(mask)部分特征token,类似于MEA的方式,为这些mask token定义一组可学习的标记,将这些可见token(未mask)送入Transformer进行编码。以编码后的未mask token为标签和mask token一起,通过一个分离的解码器处理可学习 mask token,以预测点统计(质心和占用率),和表面属性(法线和曲率)
总结:是一个自监督学习的pretext task模型,关键是几何特征为模型预测对象和场景提供了强大的信息,从而提高了下游识别性能。
注:在自监督学习中,用于预训练的任务被称为前置/代理任务(pretext task),用于微调的任务被称为下游任务(downstream task)。
文章出处登录后可见!