目录
- 一 sd安装
- 二 目标
- 三 sd基础
- 3.1 模型
- 3.2 vae(Variational autoencoder,变分自编码器)
- 3.3 embedding
- 3.3.1 安装方式
- 3.3.2 使用方式
- 3.4 Lora
- 3.4.1 lora组成
- 3.4.2 使用:
- 3.4.3 效果
- 3.4.4 测试不同CFG效果
- 3.5 hypernetworks 超网络
- 3.6 补充
- 四 总结
转载请注明出处: 🔗https://blog.csdn.net/weixin_44013533/article/details/130297373
sd玩了很久了,自去年国庆刚出来,引起一片lsp欢呼,我那段时间也沉迷抽卡。
后续一段时间的炼丹潮也就没跟进了,然后又陆续出来一些大模型像anything3啥的,11月份之后又偶尔玩玩。
今年之后各种技术前仆后继,像早先embedding,后来的lora,controlnet,deforum动画,实在有些跟不上,简直就是日新月异。
偶尔进入贤者时间也会想想,自己不想止步于基础抽卡自娱自乐,要形成生产力才行。
直接放图



上面涉及了三个重要元素:画风、模型、场景
这也是我以后开发游戏可能需要的东西,ai让我不学习绘画也能出图成为可能,所以必须精进。
因为之前安装也经常困扰,这里也简单记录下
一 sd安装
还是采用秋葉aaaki大佬的启动器,我这里不用他的整合包了,初次使用直接下载他的也行,目前已更新到4.0版本
下载地址:Stable Diffusion整合包v4发布
可以看秋叶的基础文档:【AI绘画】从零开始的AI绘画入门教程——魔法导论
整合包比较大,想快速尝试的话可以先去官网下载sd,然后用秋叶的启动器(启动器和文件直接解压到sd根目录,启动即可)
stable-diffusion-webui官网
注意事项:
- 错误一

按照提示,下载git,使用git clone方式下载,而非下载压缩包(可能这样丢失sd版本信息)
- 错误二

这里应该事python环境变量没加(没下载python先下载python),安装时勾选add path这个选项
二 目标
界面使用呀,参数含义调整等网上很多,不赘述。
我打算集中于实现上面三个目标来进行学习
- 稳定画风的人物、物品、场景(如人物,道具,环境)
- 输出3d图片,3d图片转3d模型,输出blender等可识别文件
- 大场景背景,过场动画
这些目标目前可能还无法涉及,但我学习ai最终目标就是这些,能带来生产力,有助于我日后的游戏开发。
实际的任务就很明确了,包括control net,lora分层控制,训练自己的lora,分步渲染,三视图,人物模型,道具模型,大场景制作,图片转动画等。
下面就一步步来。
参考:stable diffusion新手福音
三 sd基础
3.1 模型
- 存放大模型的位置:stable-diffusion-webui\models\Stable-diffusion
- 模型下载地方:
- sd启动器
- civitAI
3.2 vae(Variational autoencoder,变分自编码器)
作用:滤镜+微调
感觉某些会增加饱和度,有些模型画面比较灰蒙蒙的,可以利用这个加个滤镜。

大模型本身里面就自带 VAE 的,但是一些融合模型的 VAE 烂掉了 (典型:Anything-v3),需要外置 VAE 的覆盖来救救。有时画面发灰就是因为这个原因。 作者:秋葉aaaki https://www.bilibili.com/read/cv21362202?from=articleDetail 出处:bilibili
如果没有界面没有vae,去设置→用户界面→快捷设置列表
在框里输入sd_model_checkpoint,sd_vae应用后界面即可出现vae

3.3 embedding
embedding,又名 textual inversion,中文名嵌入or文本反转。简单理解就是提示词打包
up给了一个例子,如何在原版sd上生成dva,那就是给一系列promt让人物接近目标

还可以利用这个特性做到特定动作,特定场景等。(所以我理解与lora的分析素材信息进行学习再输出类似图片不同,embedding是一种提示词打包的方式)
3.3.1 安装方式
放入stable-diffusion-webui\embeddings
注意:
如出现如下报错,原因是版本不对,比如下载的embedding是2.1版本,sd是1.5

3.3.2 使用方式
2023年后版本直接点击主界面这个按钮,即可添加对应prompt
这里测试charturnerv2 embedding
masterpiece:1.6, best quality:1.4, real picture:1.2, intricate details:1.2, charturnerv2:1.2, a cute girl
我并没有输入multiple view这种prompt,但还是稳定出多人物图,这就是提示词打包的力量,感觉就是省去了我们反复测试目标提示词的麻烦,如果自己的提示词出图比较稳定,也可以考虑做成embedding,这样能更好理解embedding原理。
3.4 Lora
LoRA,英文全称LoW- Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术
作用:对人物和物品复刻(复刻图像特征),训练画风(如水墨画),固定人物动作特征
lora文件一般几兆~一百兆,远比embedding大,所以存储的信息也会多,还原图像特征效果也会更好。
up作了个比喻:老板让手下做个购物网站,有购物车、付款、排序、浏览等功能,程序员一个一个功能添加,这就是embedding;什么叫lora呢,手下直接跟老板说,你就说抄谁的吧,然后老板直接丢给他淘宝源码,程序员基于源码进行改动。这就是embedding与lora的区别。
3.4.1 lora组成
- lora promt:
<lora:Moxin_10:1>:lora:lora文件名:权重 - triggle prompt:如下墨心lora,有很多种风格

我反正没看出来这几个画家风格差异,但对其他lora可能差异就很大了,比如不同时期汉服等。

3.4.2 使用:
- 将lora文件下载到stable-diffusion-webui\models\Lora文件夹下,以墨心lora为例
- 选择lora作者推荐的大模型,然后点击插件选择lora标签,选择对应的lora添加lora标签并设置权重,按照lora作者提示添加触发词
shukezouma, negative space, <lora:Moxin_Shukezouma11:1>, shuimobysim , <lora:Moxin_10:1> , portrait of a woman standing , willow branches, (masterpiece, best quality:1.2), traditional chinese ink painting,, modelshoot style, peaceful, (smile), looking at viewer, wearing long hanfu, hanfu, song, willow tree in background, wuchangshuo,
- 生成图片:
3.4.3 效果
无lora:
shukezouma, negative space, , shuimobysim , portrait of a woman standing , willow branches, (masterpiece, best quality:1.2), traditional chinese ink painting,, modelshoot style, peaceful, (smile), looking at viewer, wearing long hanfu, hanfu, song, willow tree in background, wuchangshuo,

单墨心lora:
shukezouma, negative space, shuimobysim , <lora:Moxin_10:1> , portrait of a woman standing , willow branches, (masterpiece, best quality:1.2), traditional chinese ink painting,, modelshoot style, peaceful, (smile), looking at viewer, wearing long hanfu, hanfu, song, willow tree in background, wuchangshuo,

墨心+疏可走马lora:
shukezouma, negative space, <lora:Moxin_Shukezouma11:1>, shuimobysim , <lora:Moxin_10:1> , portrait of a woman standing , willow branches, (masterpiece, best quality:1.2), traditional chinese ink painting,, modelshoot style, peaceful, (smile), looking at viewer, wearing long hanfu, hanfu, song, willow tree in background, wuchangshuo,

测试无触发词:
<lora:Moxin_Shukezouma11:1>, <lora:Moxin_10:1> , portrait of a woman standing , willow branches, (masterpiece, best quality:1.2), traditional chinese ink painting,modelshoot style, peaceful, (smile), looking at viewer, wearing long hanfu, hanfu, song, willow tree in background,

3.4.4 测试不同CFG效果
原作者提到
“CFG范围将会改变风格,1-3 : 大小写意,3-7 : 逐渐工笔”
根据自己的喜好选择
negative space, shuimobysim, girl, woman,bare shoulders, (ecchi0.5), lips, water splash, (trees:0.5), (flowers:0.6) ,(birds:0.2), (bamboo0.1), lakes, Hangzhou, bonian, bonian in background ,shukezouma, <lora:Moxin_10:0.7> ,<lora:Moxin_Shukezouma11:0.8>,(ultra high res,16k UHD,1920x1080, best quality, masterpiece),




我只想说,老祖宗牛逼。看到这我突然想哭又想笑,老祖宗留给我们的东西竟用了新的方式去继承了。
3.5 hypernetworks 超网络
低配版lora
以Pixel art为例,下载到stable-diffusion-webui\models\hypernetworks文件夹下
类似使用,添加<hypernet:LuisapPixelArt_v1:1>prompt,看原作者是否需要触发词(像素超网络不需要)
不同权重效果,感觉取1比较像古早像素画风,越小越清晰,看个人喜好

3.6 补充
如果不知道自己下载的一堆东西属于哪个,可以进这个网站[Stable Diffusion 法术解析],即可判断(https://spell.novelai.dev/)
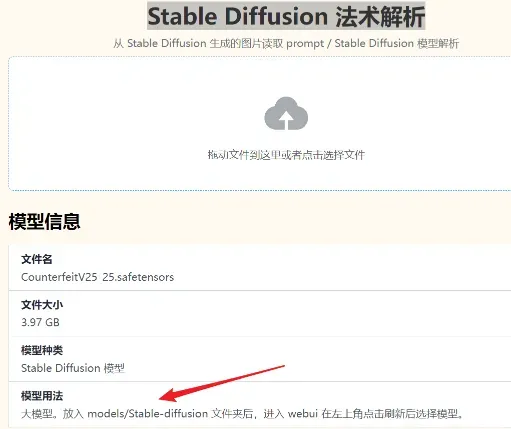
注:从文件尾缀不能判断它是什么类型。

模型发展历程:
checkpoint大概分为CHECKPOINT TRAINED以及CHECKPOINT MERGE,分别是别人训练好的和融合好的,它是大型模型,里面集合了模型参数、权重等,因此出图的的风格、画风已经相对固定。
好处就是可以直接拿来用,缺点就是想要再去微调十分麻烦,于是有了后面的lora、embedding等模型。这些属于附加模型,应用在checkpoint模型上,可以轻易对其进行微调,而且容易训练,十分方便。 作者:没啥用的芝士 https://www.bilibili.com/read/cv22559071 出处:bilibili
四 总结
简单过了下不同文件类型和使用方法,着重尝试了Lora,毕竟是当前阶段最火的东西。
接下来会逐步深入学习其他技术。
文章出处登录后可见!