在本章中,您将:
了解自动编码器的架构设计如何使其完美适用于生成建模
使用 Keras 从头开始构建和训练自动编码器
使用自动编码器生成新图像,但了解这种方法的局限性
了解变分自动编码器的架构以及它如何解决与标准自动编码器相关的许多问题
使用 Keras 从头开始构建变分自动编码器
使用变分自动编码器生成新图像
使用变分自动编码器通过潜在空间算法来处理生成的图像
2013年,Diederik P. Kingma 和 Max Welling发表了一篇论文,为一种称为变分自动编码器(VAE) 的神经网络奠定了基础。现在,这是用于生成建模的最基本和最著名的深度学习架构之一,也是开始我们的生成深度学习之旅的绝佳场所。
在本章中,我们将从构建一个标准的自动编码器开始,然后看看我们如何扩展这个框架来开发一个变分自动编码器。在此过程中,我们将区分这两种类型的模型,以了解它们如何在粒度级别上工作。到本章结束时,您应该完全了解如何构建和操作基于自动编码器的模型,特别是如何从头构建变分自动编码器以根据您自己的数据集生成图像。
让我们从一个简单的故事开始,这将有助于解释自动编码器试图解决的基本问题。
造型师、缝纫机和衣橱
想象一下,在你面前的地板上堆放着你所有的衣服——裤子、上衣、鞋子和外套,款式和尺码各不相同(你可能不需要很努力地想象)。每天你告诉你的造型师你想穿什么,他就会在一堆衣服中翻找,直到找到你要找的东西。然而,他对找到您需要的确切物品需要多长时间感到越来越沮丧,因为那堆东西很大而且完全杂乱无章。所以他设计了一个聪明的计划来解决这个问题……
他为您呈现了一个您前所未见的大衣橱。这个衣柜无限高(同样宽),并配有无限梯子,让您可以轻松到达建筑的任何部分。您的任务是将每件衣服放在衣橱中的特定位置,这样您现在就无需详细描述您需要的物品,您可以简单地指定沿着衣橱走多远以及需要爬到多高的梯子上去寻找物品。
造型师的计划有一个最终条件。可以理解的是,他不想每次你要一件衣服时都爬上无限阶梯,所以他告诉你,一旦你告诉他衣服在衣柜里的位置,他就会用他可靠的缝纫机从头开始缝制每件衣服,缝纫机是安全地在陆地上。
最初,您将衣服随机放入衣橱,希望布赖恩能够使用缝纫机发挥他的魔力。然而,您很快就会从朋友对您服装的严厉评论中看出您需要调整衣橱组织,以便 造型师 可以准确地重新缝合衣服,只要知道它的位置。
几周后,您和造型师已经适应了彼此的工作方式。现在您可以只为布赖恩指定您想要的衣服的位置,他可以准确地重新缝制这件衣服!这给了你一个想法——如果你给造型师一个空着的衣柜位置会发生什么?
令您惊讶的是,您发现布赖恩能够制作出以前不存在的全新衣服!这个过程并不完美,但你现在至少有无限的选择来制作新衣服,只需在无限的衣柜中选择任何位置(即使它是空的),然后让布赖恩用缝纫机施展他的魔法。
现在让我们探讨这个故事与构建自动编码器的关系。
Encoding and Decoding
图2.1 显示了故事描述的过程图。你扮演编码器的角色;取出每件物品并将其移动到衣柜中的某个位置的过程称为编码。造型师扮演解码器的角色;在衣橱中占据一个位置并尝试重新缝合物品的相反过程称为解码。
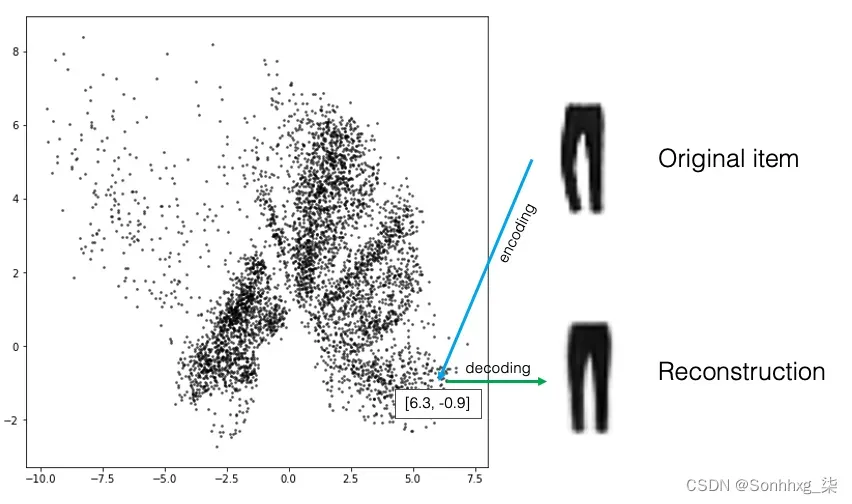
图2.1 无限衣橱里的衣物
故事中的衣柜只是一个二维空间——也就是说,空间中的每个点都只用两个数字表示。你将每件衣服编码成一个二维向量,然后 造型师 将这个位置解码回原始域。例如,图2.1 中的裤子被编码为 [6.3, -0.9] 点。
在图2.2 中,您可以看到其他原始服装项目(顶行)、编码后的二维向量和解码后的重构项目(底行)的示例。
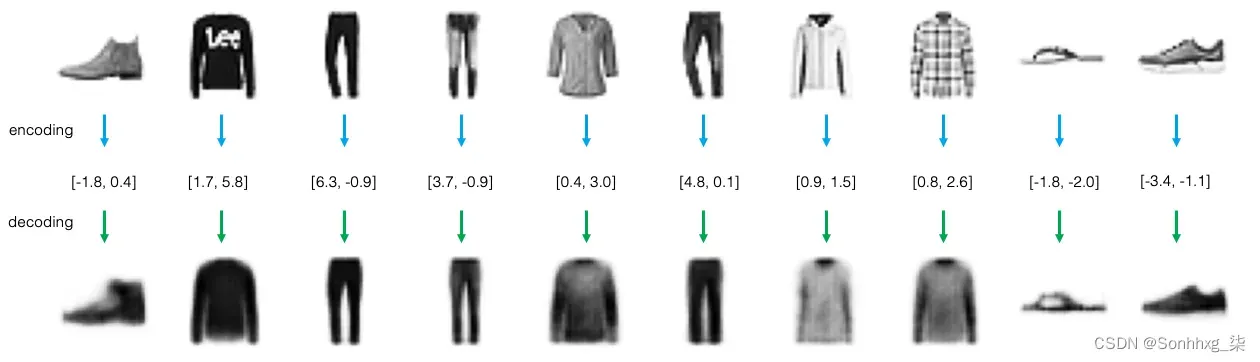
图2.2 服装项目的编码和解码示例
请注意解码是如何不完美的——仍然有一些原始项目的细节没有被解码过程捕获,例如徽标。这是因为通过将每件衣服减少到只有两个数字,我们自然会丢失一些信息。
出于这个原因,二维向量也被称为嵌入( embedding),因为编码器试图将尽可能多的关于原始服装项目的信息嵌入到向量中,以便解码器可以准确地重建它。诀窍是确保信息损失尽可能小。
故事的最后一部分描述了如何生成新的衣服,只需在 2D 空间中指定一个空点即可——也就是说,我们不一定要将一件真实的衣服编码到该特定点。图2.3 显示了这一点。
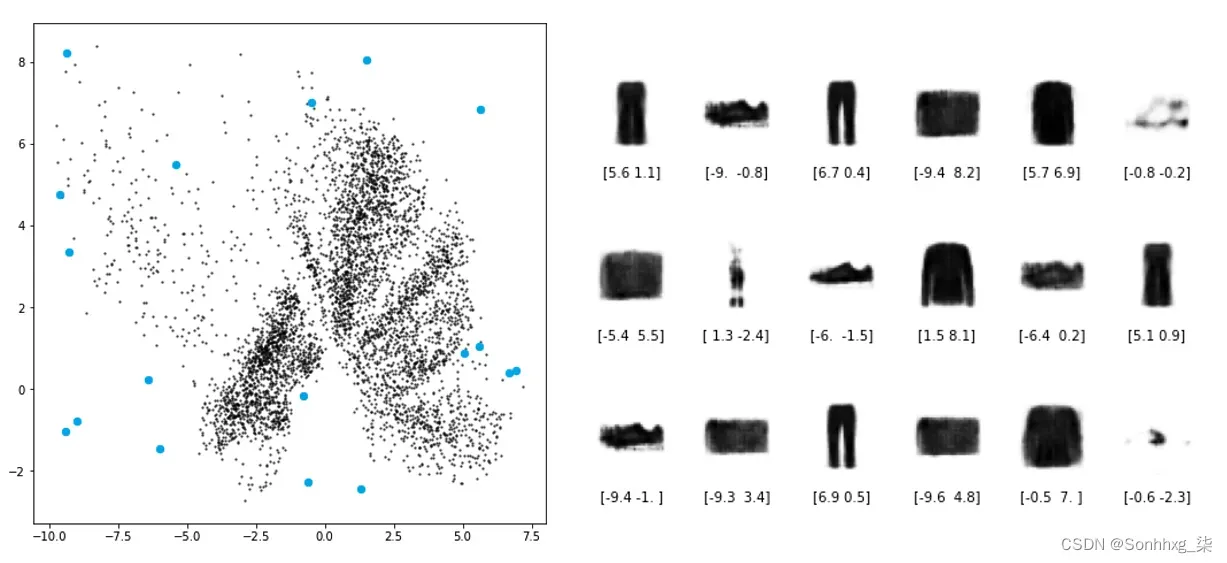
图2.3 生成的服装项目
每个蓝点映射到图表右侧显示的图像之一,嵌入向量显示在下方。请注意一些生成的项目如何比其他项目更逼真。稍后我们将重新讨论这个概念,但现在只需注意最真实的生成图像往往是那些不会偏离原始数据集嵌入太远的图像。
在下一节中,我们将探讨如何使用 Keras 从头开始训练自动编码器,并正式定义此类生成模型。
自编码器
自动编码器是由两部分组成的神经网络:
将高维输入数据(例如图像)压缩为低维嵌入的编码器网络
将给定嵌入解压缩回原始域(例如,返回图像)的解码器网络
自动编码器的架构图如图 2.4 所示。
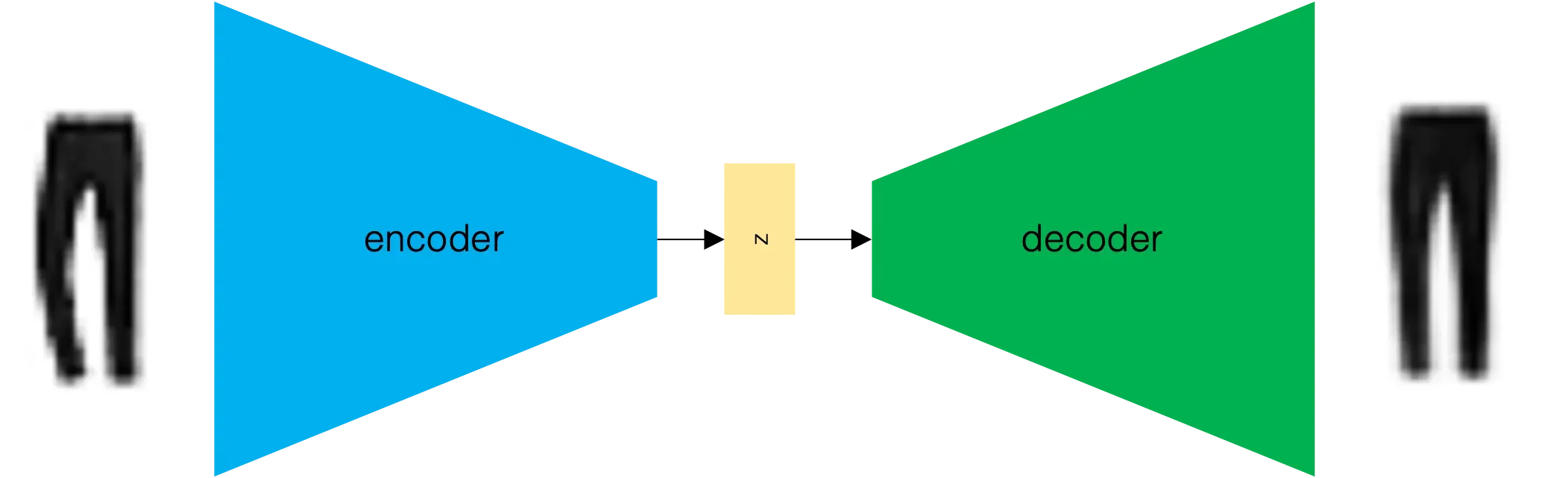
图2.4 自动编码器图
自动编码器经过训练可以在图像通过编码器并通过解码器返回后重建图像。乍一看这可能看起来很奇怪 – 为什么要重建一组您已经可以使用的图像?然而,正如我们将要看到的,嵌入空间是自动编码器的有趣部分,因为从这个潜在(隐藏)空间中采样将使我们能够生成新图像。
让我们首先定义嵌入(embedding)的含义。这嵌入是将原始图像压缩到低维的潜在空间中。这个想法是,通过选择潜在空间中的任何点,我们可以通过将这个点传递给解码器来生成新图像,因为解码器已经学会了如何将潜在空间中的点转换为可行的图像。
在我们的示例中,我们在二维潜在空间中使用了嵌入。这有助于我们可视化潜在空间,因为我们可以轻松地在 2D 中绘制点。在实践中,自动编码器通常有两个以上的维度,以便有更多的自由来捕捉图像中更大的细微差别。
自编码器可用于清除噪声图像,因为编码器了解到捕获潜在空间内随机噪声的位置以重建原始图像是没有用的。对于这样的任务,二维潜在空间可能太小而无法从输入中编码足够的相关信息。然而,正如我们将看到的,如果我们想将自动编码器用作生成模型,增加潜在空间的维数会很快导致问题。
自编码器
让我们现在在 Keras 中构建一个自动编码器。此示例遵循存储库中的Jupyter 笔记本/notebooks/chapter04/autoencoder/fashion/01_train.ipynb 。
我们将使用 Fashion MNIST 数据集,可以按如下方式下载:
示例2.1 Fashion MNIST 数据集
from tensorflow.keras.datasets import fashion_mnist
(x_train,y_train), (x_test,y_test) = fashion_mnist.load_data()这些图像是开箱即用的 28 * 28 灰度(0 到 255 之间的整数),我们需要对其进行预处理以确保图像在 0 到 1 之间缩放并填充到 32 * 32 以便更容易地操作张量形状通过网络。
示例2.2 预处理数据
def preprocess(imgs):
"""
Scale and reshape the images
"""
imgs = np.pad(imgs.astype("float32") / 255.0, ((0,0), (2,2), (2,2)), constant_values= 0.0)
return imgs
# Preprocess the data
x_train = preprocess(x_train)
x_test = preprocess(x_test)现在我们有了数据集,我们现在可以构建自动编码器的两个部分——编码器和解码器。
编码器
在一个自动编码器,编码器的工作是获取输入图像并将其映射到潜在空间中的嵌入向量。我们将构建的编码器的架构如图2.5 所示。

图2.5 编码器的架构
为实现这一点,我们首先为图像创建一个输入层,然后按顺序将其传递给四个Conv2D层,每个层都捕获越来越高级的特征。我们使用 2 的步幅到每层输出大小的一半,同时增加通道的数量。最后一个卷积层被展平并连接到一个Dense大小为 2 的层,它代表我们的二维潜在空间。
示例2.3 展示了如何构建这个在凯拉斯。
示例2.3 编码器
# Building the encoder
encoder_input = layers.Input(shape=(32, 32, 1), name = "encoder_input")
x = layers.Conv2D(32, (3, 3), strides = 2, activation = 'relu', padding="same")(encoder_input)
x = layers.Conv2D(64, (3, 3), strides = 2, activation = 'relu', padding="same")(x)
x = layers.Conv2D(128, (3, 3), strides = 2, activation = 'relu', padding="same")(x)
shape_before_flattening = K.int_shape(x)[1:]
x = layers.Flatten()(x)
encoder_output = layers.Dense(2, name="encoder_output")(x)
encoder = Model(encoder_input, encoder_output)
encoder.summary()定义Input编码器层(图像)。
Conv2D层层依次堆叠。
Flatten最后一个卷积层到一个向量。
Dense将该向量连接到 2D 嵌入的层。
定义编码器的Keras——Model一种获取输入图像并将其编码为 2D 嵌入的模型。
我强烈建议您试验卷积层和过滤器的数量,以了解架构如何影响模型参数的总数、模型性能和模型运行时间.
解码器
这解码器是编码器的镜像,除了不是卷积层,我们使用卷积转置层,如图2.6 所示。
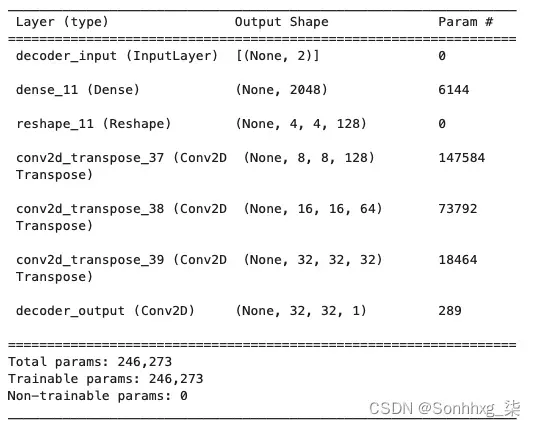
图2.6 解码器的架构
笔记解码器不必是编码器的镜像。它可以是任何你想要的,只要解码器最后一层的输出与编码器的输入大小相同(因为我们的损失函数将逐像素比较这些)。
卷积转置层
标准卷积层允许我们通过设置将输入张量的高度和宽度减半strides = 2。
卷积转置层使用与标准卷积层相同的原理(在图像上传递过滤器),但不同之处在于设置将输入张量的高度和宽度大小strides = 2 加倍。
在卷积转置层中,该strides参数确定图像中像素之间的内部零填充,如图2.7 所示。
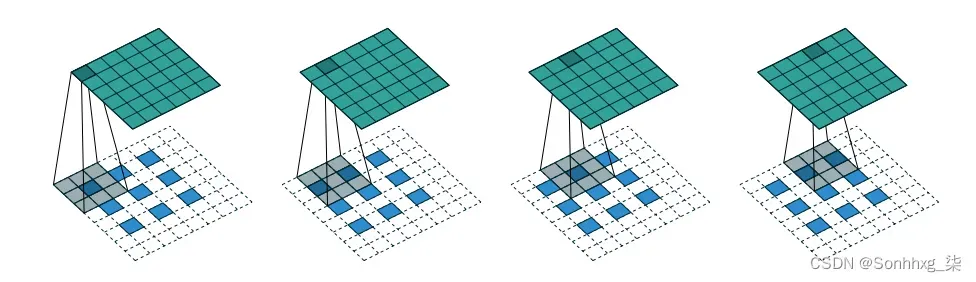
图2.7 卷积转置层示例——此处,一个 3 × 3 × 1 滤波器(灰色)以 strides = 2 穿过 3 × 3 × 1 图像(蓝色),产生 6 × 6 × 1 输出张量(绿色)
在Keras,该Conv2DTranspose层允许我们对张量执行卷积转置操作。通过堆叠这些层,我们可以逐渐扩大每一层的尺寸,使用步长 2,直到我们回到原始图像尺寸32 × 32。
示例2.4 显示了如何我们在 Keras 中构建解码器。
示例2.4 解码器
# Building the decode
decoder_input = layers.Input(shape=(2,), name="decoder_input")
x = layers.Dense(np.prod(shape_before_flattening))(decoder_input)
x = layers.Reshape(shape_before_flattening)(x)
x = layers.Conv2DTranspose(128, (3, 3), strides=2, activation = 'relu', padding="same")(x)
x = layers.Conv2DTranspose(64, (3, 3), strides=2, activation = 'relu', padding="same")(x)
x = layers.Conv2DTranspose(32, (3, 3), strides=2, activation = 'relu', padding="same")(x)
decoder_output = layers.Conv2D(1, (3, 3), strides = 1, activation="sigmoid", padding="same", name="decoder_output")(x)
decoder = Model(decoder_input, decoder_output)
decoder.summary()为解码器定义Input层(嵌入)。
将输入连接到一个Dense层。
Reshape这个向量变成一个张量,可以作为第一Conv2DTranspose层的输入。
Conv2DTranspose层层叠叠。
定义解码器的Keras——Model一种在潜在空间中嵌入并将其解码到原始图像域的模型。
将编码器连接到解码器
到要同时训练编码器和解码器,我们需要定义一个模型来表示图像通过编码器并通过解码器返回的流。幸运的是,Keras 使这件事变得非常容易,如示例 2.5 所示。请注意我们指定自动编码器的输出只是编码器通过解码器后的输出的方式。
示例2.5 完整的自动编码器
# Building the autoencoder
autoencoder = Model(encoder_input, decoder(encoder_output))
autoencoder.summary()定义完整自动编码器的 Keras 模型——一种获取图像并将其传递通过编码器并通过解码器返回以生成原始图像的重建的模型。
现在我们已经定义了模型,我们只需要使用损失函数和优化器对其进行编译,如示例2.6 所示。损失函数通常选择为原始图像和重建图像的各个像素之间的均方根误差 (RMSE) 或二进制交叉熵。
示例2.6 编译(Compilation)
#Compile the autoencoder
autoencoder.compile(optimizer="adam", loss="binary_crossentropy")选择损失函数
针对 RMSE 进行优化意味着您生成的输出将围绕平均像素值对称分布(因为高估与低估等同地受到惩罚)。
另一方面,二元交叉熵损失是不对称的——它对极端误差的惩罚比对中心误差的惩罚更大。例如,如果真实像素值很高(例如 0.7),则生成值为 0.8 的像素比生成像素值为 0.6 的像素受到更严重的惩罚。如果真实像素值较低(例如 0.3),则生成值为 0.2 的像素比生成像素值为 0.4 的像素受到更严重的惩罚。
这具有二元交叉熵损失产生比 RMSE 损失稍微模糊的图像的效果(因为它倾向于将预测推向 0.5),但有时这是可取的,因为 RMSE 会导致明显的像素化边缘。
没有正确或错误的选择——您应该在试验后选择最适合您的用例的那个。
我们现在可以通过传入输入图像作为输入和输出来训练自动编码器,如示例2.7 所示。
示例2.7 训练自动编码器
autoencoder.fit(
x_train,
x_train,
epochs=3,
batch_size=100,
shuffle=True,
validation_data=(x_test, x_test),
)自编码器分析
现在我们的自动编码器已经过训练,我们可以开始研究它如何在潜在空间中表示图像。相关代码包含在本资源库的chapter04/autoencoders/fashion/02_generate.ipynb notebook 中。
让我们首先为图 2.2 所示的潜在空间嵌入添加一些颜色。时尚 MNIST 数据集带有描述每个图像中项目类型的标签。共10组,如表2-1所示。
表 2-1 Fashion MNIST
ID | 服装标签 |
0 | T-shirt/top |
1 | Trouser |
2 | Pullover |
3 | Dress |
4 | Coat |
5 | Sandal |
6 | Shirt |
7 | Sneaker |
8 | Bag |
9 | Ankle boot |
我们可以通过相应图像的标签为每个点着色,以生成图2.8 中的图表。现在结构变得非常清晰了!即使在训练期间从未向模型显示过服装标签,自动编码器也会自然地将看起来相似的项目分组到潜在空间的同一部分。例如,潜在空间右下角的深蓝色点云都是裤子的不同图像,而靠近中心的红色点云都是踝靴。
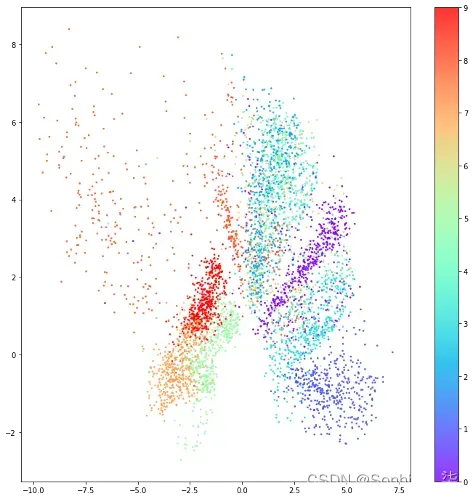
图2.8 潜在空间图,按服装标签着色
我们还可以对潜在空间中点的总体分布进行以下观察:
一些服装项目在非常小的区域中展示,而另一些则在更大的区域中展示。
分布不是关于点 (0, 0) 对称的,也不是有界的。例如,y 轴值为正的点比负的要多得多,有些点甚至延伸到 y 轴值 > 8。
包含少量点的颜色之间存在较大差距。
请记住,我们的目标是能够在潜在空间中选择一个随机点,将其传递给解码器,并获得看起来真实的一件衣服的图像。如果我们多次这样做,我们也希望获得大致相等的不同种类衣服的混合(即,它不应该总是生产相同类型的物品)。
如果我们用网格上的解码点图像覆盖潜在空间,如图2.9 所示,我们就可以开始理解为什么自动编码器可能无法始终生成令人满意的图像标准。
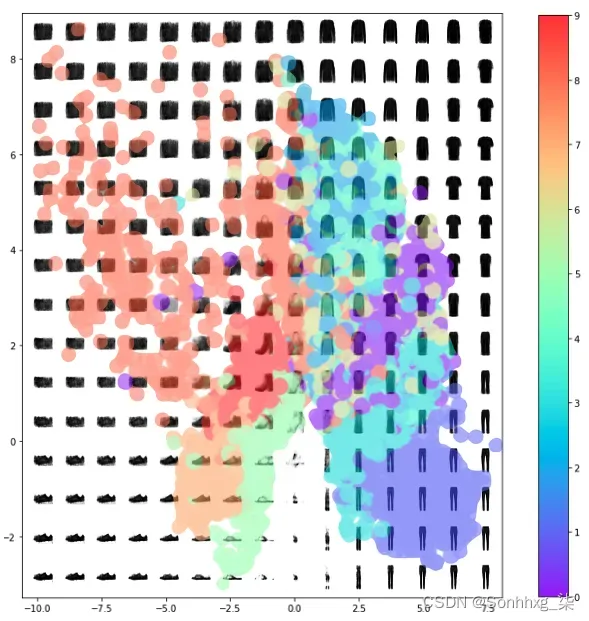
图2.9 解码嵌入的网格,覆盖数据集中原始图像的嵌入,按项目类型着色。
首先,我们可以看到,如果我们在我们定义的有界空间中均匀地选取点,我们更有可能对解码为看起来像包(id 8)而不是踝靴(id 9)的东西进行采样,因为为包包(橙色)开出的潜在空间比脚踝靴区域(红色)大。
其次,我们应该如何在潜在空间中选择一个随机点并不明显,因为这些点的分布是不确定的。从技术上讲,我们有理由选择 2D 平面中的任何点!甚至不能保证点将以 (0,0) 为中心。这使得从我们的潜在空间中采样成为问题。
最后,我们可以在未对原始图像进行编码的潜在空间中看到漏洞。例如,域的边缘有大片空白——自动编码器没有理由确保此处的点被解码为可识别的服装项目,因为训练集中很少有图像在这里编码。
即使是中心点也可能无法解码为格式正确的图像 – 例如 x = 0.0 和 y = -1.0。在这些区域中,采样嵌入解码为格式不正确的图像。这是因为自动编码器没有被强制确保空间是连续的。例如,即使点 (-1, –1) 可能被解码以给出令人满意的凉鞋图像,但没有适当的机制来确保点 (-1.1, –1.1) 也产生令人满意的凉鞋图像一双凉鞋
在二维中,这个问题很微妙;自动编码器只有少量维度可供使用,因此它自然必须将服装组挤压在一起,从而导致服装组之间的空间相对较小。然而,当我们开始在潜在空间中使用更多维度来生成更复杂的图像(例如人脸)时,这个问题变得更加明显。如果我们让自动编码器自由控制它如何使用潜在空间对图像进行编码,那么相似点组之间将存在巨大的差距,而不会激励它们之间的空间生成格式良好的图像。
那么我们如何解决这三个问题,以便我们的自动编码器框架可以用作真正的生成模型呢?为了解释,让我们重新审视无限衣橱并做一些改变……
重温无限衣橱
现在假设,您决定分配一个更容易找到该物品的一般区域,而不是将每件衣服都放在衣柜中的一个点。您的理由是,这种更轻松的物品定位方法将有助于解决当前衣橱中局部不连续的问题。
此外,为了确保您不会对新的放置系统过于粗心,您也同意造型师 的观点,即您将尝试将每件物品的区域中心放置在尽可能靠近衣柜中间的位置,并且偏离距离中心的项目应尽可能接近 1m(不小也不大)。你越偏离这条规则,你就越需要付钱给你的造型师。
经过几个月的这两个简单更改操作后,您退后一步,欣赏新的衣橱布局图2.10 ,以及造型师 生成的一些新服装示例。
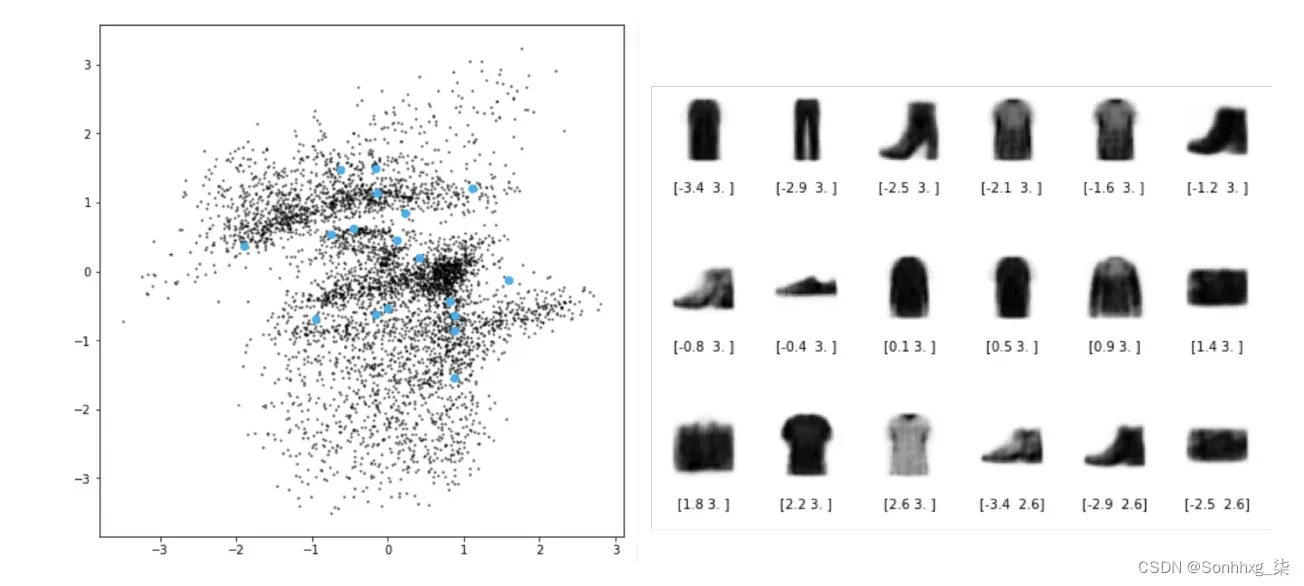
图2.10 从新衣橱中生成时尚
好多了!生成的项目有很多多样性,这次没有劣质服装的例子。看来这两个变化已经完全不同了!
构建变分自编码器
这之前的故事展示了如何通过两个简单的更改将自动编码器转变为成功的生成过程。现在让我们尝试从数学上理解我们需要对自动编码器做些什么才能将其转换为变分自动编码器,从而使其成为更复杂的生成模型。
我们需要改变的两个部分是编码器和损失函数。
编码器
在自动编码器中,每个图像都直接映射到潜在空间中的一个点。在变分自动编码器中,每个图像都被映射到潜在空间中一个点周围的多元正态分布,如图2.11 所示。
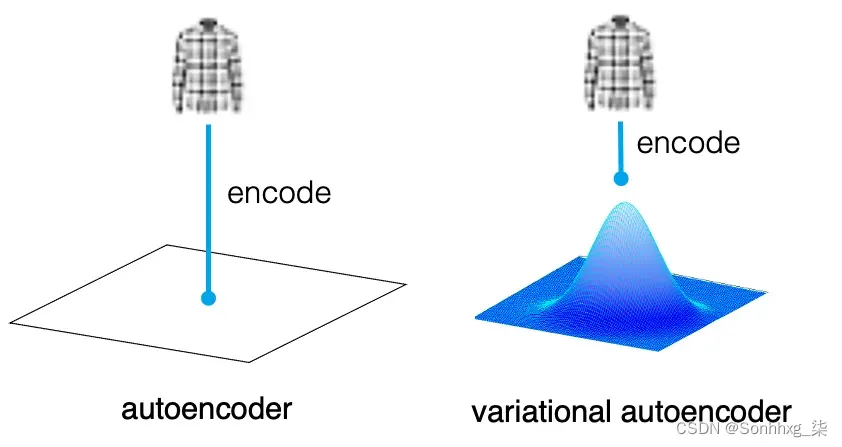
图 2.11 自编码器中编码器与变分自编码器的区别
正态分布
A正态分布是以独特的钟形曲线形状为特征的概率分布。在一维中,它由两个变量定义:均值( μ ) 和方差( σ 2 )。标准偏差( σ ) 是方差的平方根。
这一维正态分布的概率密度函数为:
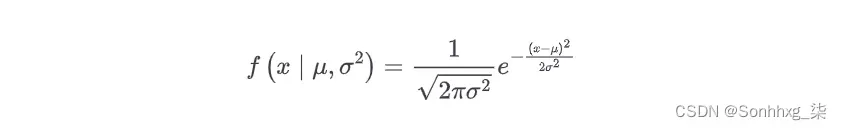
图2.12 显示了一维的几个正态分布,均值和方差的不同值。这红色曲线是标准正态分布——均值为 0、方差为 1 的正态分布。
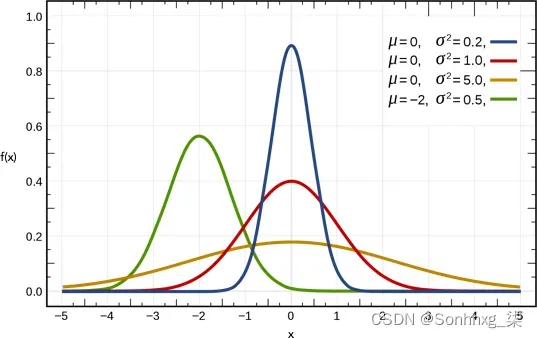
图2.12 一维正态分布
我们可以使用以下等式从均值μ和标准差σ 的正态分布中采样点z :
z = μ + σε
其中ε从标准正态分布中采样。
正态分布的概念扩展到不止一维——k 维的一般多元正态分布的概率密度函数如下:
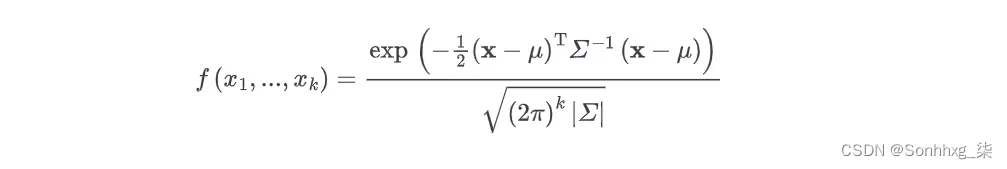
在 2D 中,均值向量μ和对称协方差矩阵Σ定义为:
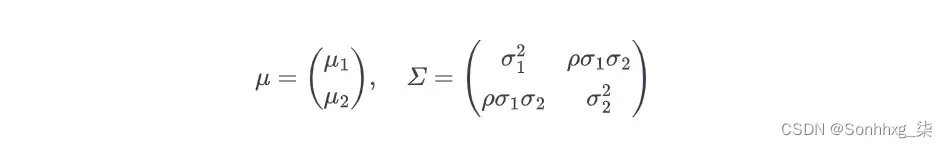
其中ρ是两个维度x 1和x 2之间的相关性。
变分自动编码器假定潜在空间中的任何维度之间都没有相关性,因此协方差矩阵是对角矩阵。这意味着编码器只需要将每个输入映射到一个均值向量和一个方差向量,而不需要担心维度之间的协方差。我们实际上选择映射到方差的对数,因为这可以取范围 (–∞, ∞) 中的任何实数,与神经网络单元的自然输出范围相匹配,而方差值始终为正。
总而言之,编码器将获取每个输入图像并将其编码为两个向量,z_mean它们z_log_var共同定义了潜在空间中的多元正态分布:
z_mean:分布的平均点。
z_log_var:每个维度的方差的对数。
要将图像编码到z潜在空间中的特定点,我们可以使用以下等式从该分布中采样:
z = z_mean + z_sigma * epsilon
其中z_sigma = exp(z_log_var * 0.5)
epsilon是从标准正态分布中采样的点。
那么为什么编码器的这个小改动会有帮助呢?
之前,我们看到了如何不要求潜在空间是连续的——即使点 (–2, 2) 解码为凉鞋的格式正确的图像,也不需要 (–2.1, 2.1) 到看起来很相似。现在,由于我们从 周围的区域采样随机点z_mean,解码器必须确保同一邻域中的所有点在解码时产生非常相似的图像,以便重建损失保持较小。这是一个非常好的属性,它确保即使我们在解码器从未见过的潜在空间中选择一个点,它也可能解码为格式正确的图像。
让我们现在看看我们如何在 Keras 中构建这个新版本的编码器(示例2.9)。您可以通过运行存储库中的笔记本chapter04/vae/fashion/01_train.ipynb在时尚 MNIST 数据集上训练您自己的变分自动编码器。
首先,我们需要创建一种新型Sampling层,它允许我们从z_mean和定义的分布中采样,如示例2.8 z_log_var所示。
示例 2.8 采样层
# The Sampling layer
class Sampling(Layer):
"""Uses (z_mean, z_log_var) to sample z, the vector encoding an item of clothing."""
def call(self, inputs):
z_mean, z_log_var = inputs
batch = tf.shape(z_mean)[0]
dim = tf.shape(z_mean)[1]
epsilon = K.random_normal(shape=(batch, dim))
return z_mean + tf.exp(0.5 * z_log_var) * epsilon 1.我们通过对 keras 基类进行子类化来创建一个新层Layer
2.我们使用重新参数化技巧从参数化为和的正态分布构建样本z_log_var。
Layer子类化
Layer您可以通过子类化抽象类并定义描述call层如何转换张量的方法来在 Keras 中创建新层。
例如,在变分自动编码器中,我们可以创建一个层来处理正态分布Sampling的采样z,参数由z_mean和z_log_var
当您想要将转换应用于尚未作为开箱即用的 Keras 层类型之一包含的张量时,这很有用。
重新参数化技巧
z_mean我们不是直接从参数为和的正态分布中采样z_log_var,而是从标准正态分布 ( ) 中采样epsilson,然后手动调整样本以获得正确的均值和方差。
这被称为重新参数化技巧并且很重要,因为它意味着梯度可以通过层自由反向传播。通过保持层的所有随机性包含在变量中epsilon,层输出相对于其输入的偏导数可以显示为确定性的(即独立于随机epsilon),这对于通过层的反向传播是必不可少的可能的。
编码器的完整代码(包括新层)如示例2.9 Sampling所示。
示例2.9 编码器
# The encoder
encoder_input = Input(shape=(IMAGE_SIZE, IMAGE_SIZE, 1), name="encoder_input")
x = Conv2D(32, (3, 3), strides=2, activation="relu", padding="same")(encoder_input)
x = Conv2D(64, (3, 3), strides=2, activation="relu", padding="same")(x)
x = Conv2D(128, (3, 3), strides=2, activation="relu", padding="same")(x)
shape_before_flattening = K.int_shape(x)[1:] # the decoder will need this!
x = Flatten()(x)
z_mean = Dense(EMBEDDING_DIM, name="z_mean")(x)
z_log_var = Dense(EMBEDDING_DIM, name="z_log_var")(x)
z = Sampling()([z_mean, z_log_var])
encoder = Model(encoder_input, [z_mean, z_log_var, z], name="encoder")
encoder.summary()1.我们不是将Flatten图层直接连接到 2D 潜在空间,而是将其连接到图层z_mean和z_log_var。
2.该层从参数z_mean和z_log_var定义的正态分布中Sampling采样潜在空间中的一个点z。
3.定义编码器的Keras——一种通过从z_mean和z_log_varModel定义的正态分布中采样点来获取输入图像并将其编码到二维潜在空间的模型。
一个编码器框图如图2.13 所示。

图2.13 VAE 编码器示意图
如前所述,变分自动编码器的解码器与普通自动编码器的解码器相同,整体架构如图2.14 所示。
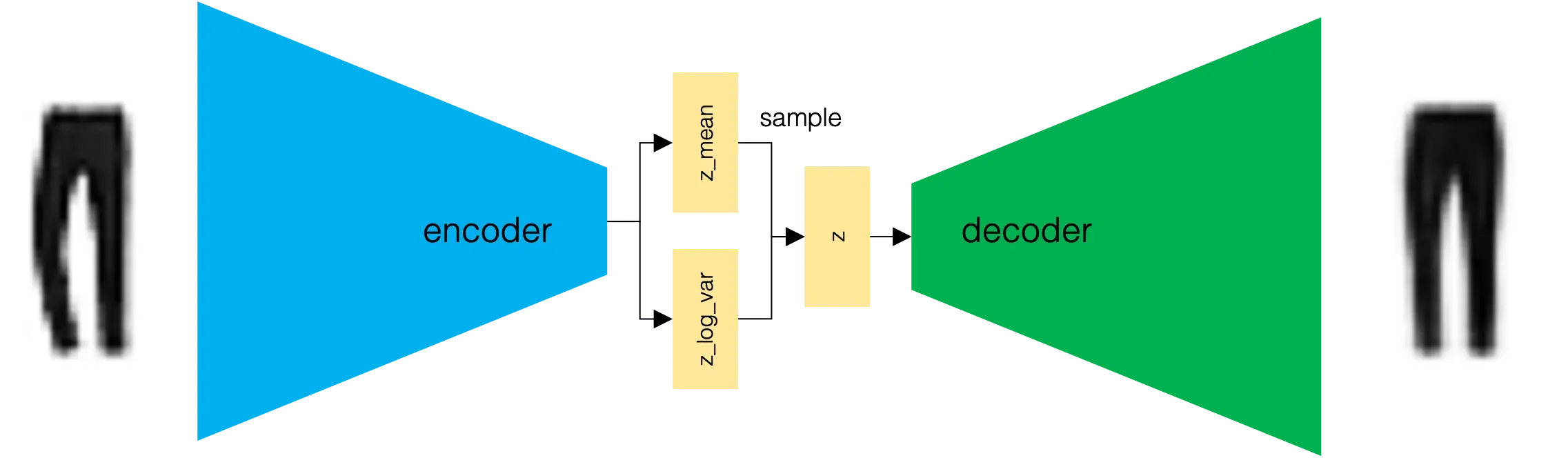
图2.14 VAE 示意图
我们需要更改的原始自动编码器的唯一其他部分是损失函数。
损失函数
以前,我们的损失函数仅包括图像与其尝试通过编码器和解码器后的副本之间的重建损失。重建损失也出现在变分自动编码器中,但我们需要一个额外的组件: Kullback–Leibler (KL) 散度。
KL 散度是一种衡量一个概率分布与另一个概率分布差异程度的方法。在 VAE 中,我们想要衡量我们的参数正态分布与z_mean标准z_log_var正态分布的差异程度。在这种特殊情况下,KL 散度具有封闭形式:
kl_loss = -0.5 * sum(1 + z_log_var – z_mean ^ 2 – exp(z_log_var))
或者用数学符号:
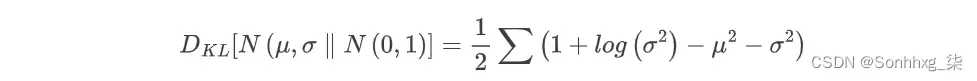
总和接管潜在空间中的所有维度。对于所有维度kl_loss,最小化为 0 。随着z_mean = 0和z_log_var = 0这两项开始不同于 0,kl_loss增加。
总之,KL 散度项惩罚网络将观察值编码为与z_mean标准z_log_var正态分布的参数显着不同的变量,即z_mean = 0和z_log_var = 0。
为什么这个附加到损失函数有帮助?
首先,我们现在有一个定义明确的分布,我们可以使用它来选择潜在空间中的点——标准正态分布。如果我们从这个分布中采样,我们知道我们很可能得到一个位于 VAE 习惯看到的范围内的点。其次,由于该术语试图将所有编码分布强制为标准正态分布,因此点簇之间形成大间隙的可能性较小。相反,编码器将尝试对称且有效地使用原点周围的空间。
在最初的 VAE 论文中,VAE 的损失函数只是将重建损失和 KL 散度损失项相加。这个 (the \beta-VAE) 的一个变体包括一个对 KL 分歧进行加权的因素,以确保它与重建损失很好地平衡。如果我们对重建损失的权重过高,KL 损失将不会产生预期的调节效果,我们将看到与普通自动编码器相同的问题。如果 KL 散度项权重过大,KL 散度损失将占主导地位,重建的图像将很差。这个加权项是您训练 VAE 时要调整的参数之一。
示例2.10 显示了我们如何将整个 VAE 模型构建为抽象 KerasModel类的子类。这允许我们在自定义方法中包含损失函数的 KL 散度项的计算train_step。
示例2.10 在损失函数中包含KL散度
# The VAE class
class VAE(Model):
def __init__(self, encoder, decoder, **kwargs):
super(VAE, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
self.total_loss_tracker = Mean(name="total_loss")
self.reconstruction_loss_tracker = Mean(name="reconstruction_loss")
self.kl_loss_tracker = Mean(name="kl_loss")
@property
def metrics(self):
return [
self.total_loss_tracker,
self.reconstruction_loss_tracker,
self.kl_loss_tracker,
]
def call(self, inputs):
"""Call the model on a particular input."""
z_mean, z_log_var, z = encoder(inputs)
reconstruction = decoder(z)
return z_mean, z_log_var, reconstruction
def train_step(self, data):
"""Step run during training."""
with tf.GradientTape() as tape:
z_mean, z_log_var, reconstruction = self(data)
reconstruction_loss = tf.reduce_mean(BETA * binary_crossentropy(data, reconstruction, axis=(1, 2, 3)))
kl_loss = tf.reduce_mean(tf.reduce_sum(-0.5 * (1 + z_log_var - tf.square(z_mean) - tf.exp(z_log_var)), axis = 1))
total_loss = reconstruction_loss + kl_loss
grads = tape.gradient(total_loss, self.trainable_weights)
self.optimizer.apply_gradients(zip(grads, self.trainable_weights))
self.total_loss_tracker.update_state(total_loss)
self.reconstruction_loss_tracker.update_state(reconstruction_loss)
self.kl_loss_tracker.update_state(kl_loss)
return {
"loss": self.total_loss_tracker.result(),
"reconstruction_loss": self.reconstruction_loss_tracker.result(),
"kl_loss": self.kl_loss_tracker.result(),
}
# Create a variational autoencoder
vae = VAE(encoder, decoder)
# Compile the variational autoencoder
optimizer = Adam(learning_rate = 0.0005)
vae.compile(optimizer=optimizer)
# Train the VAE
history = vae.fit(
train,
epochs=300
)变分自编码器分析
以下所有分析都可以在笔记本chapter04/vae/fashion/02_generate.ipynb 的书籍存储库中找到。
参考回到图2.10 ,我们可以看到潜在空间的组织方式发生了一些变化。黑点显示z_mean每个编码图像的值。KL 散度损失项确保 和z_mean值z_log_var永远不会偏离标准正态太远。因此,我们可以从标准正态分布中采样以在要解码的空间中生成新点(蓝点)。
其次,由于编码器现在是随机的而不是确定性的,潜在空间现在是局部连续的,所以生成的衣服没有那么多形状不佳。
最后,通过按服装类型对潜在空间中的点进行着色(图2.15 ),我们可以看到任何一种类型都没有优先处理。右手边的图显示了转换为p值的空间,我们可以看到每种颜色的表现大致相同。同样,重要的是要记住,在训练期间根本没有使用标签——VAE 自己学习了各种形式的衣服,以帮助最大限度地减少重建损失。
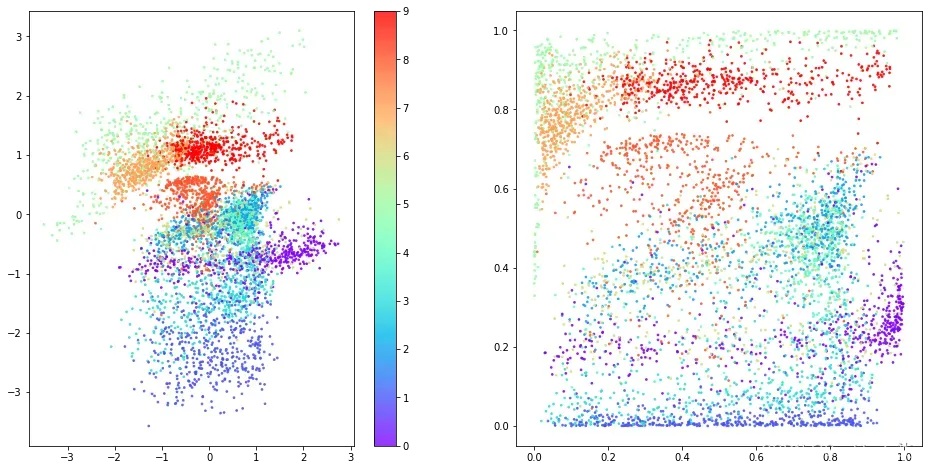
图2.15 按服装类型着色的 VAE 的潜在空间
到目前为止,我们关于自动编码器和变分自动编码器的所有工作都仅限于二维潜在空间。这有助于我们在页面上可视化 VAE 的内部工作原理,并理解为什么我们对自动编码器架构所做的小调整有助于将其转变为可用于生成建模的更强大的网络类别。
现在让我们将注意力转移到一个更复杂的数据集上,看看当我们增加潜在空间的维度时,变分自动编码器可以实现的令人惊奇的事情。
使用 VAE 生成人脸
此示例的代码包含在图书存储库的chapter04/autoencoders/vae/faces/01_train.ipynb笔记本中。
我们应使用CelebFaces 属性 (CelebA) 数据集来训练我们的下一个变分自动编码器。这是一个包含超过 200,000 张名人面孔彩色图像的集合,每张图像都带有不同的标签(例如,戴帽子、微笑等)。图2.16 中显示了一些示例。

图2.16 来自 CelebA 数据集的一些示例
当然,我们不需要标签来训练 VAE,但稍后当我们开始探索如何在多维潜在空间中捕获这些特征时,这些标签会很有用。一旦我们的 VAE 得到训练,我们就可以从潜在空间中采样以生成新的名人面孔示例。
下载数据
CelebA 数据集也可以通过 Kaggle 获得,因此您可以通过运行图书存储库中的 Kaggle 数据集下载程序脚本来下载该数据集,如示例2.11 所示。这会将图像和附带的元数据本地保存到/data文件夹中。
示例2.11 下载 CelebA 数据集
bash scripts/download_kaggle_data.sh jessicali9530 celeba-dataset预处理数据
我们使用 Keras 函数image_dataset_from_directory创建一个直接指向图像存储位置的 TensorFlow 数据集,如示例2.12 所示。这允许我们仅在需要时(例如在训练期间)将成批图像读入内存,这样我们就可以处理大型数据集,而不必担心必须将整个数据集放入内存。它还将图像调整为 64×64,在像素值之间进行插值。
示例2.12 预处理 CelebA 数据集
train_data = image_dataset_from_directory(
"/app/data/celeba-dataset/img_align_celeba/img_align_celeba",
labels=None,
color_mode="rgb",
image_size=(64, 64),
batch_size=128,
shuffle=True,
seed=42,
interpolation="bilinear",
)原始数据在 [0, 255] 范围内缩放以表示重新缩放到范围 [0, 1] 的像素强度。
示例2.13 预处理 CelebA 数据集
train_data = image_dataset_from_directory(
"/app/data/celeba-dataset/img_align_celeba/img_align_celeba",
labels=None,
color_mode="rgb",
image_size=(64, 64),
batch_size=128,
shuffle=True,
seed=42,
interpolation="bilinear",
)训练 VAE
这面部模型的网络架构类似于时尚 MNIST 示例,但有一些细微差别:
我们的数据现在具有三个输入通道 (RGB) 而不是一个(灰度)。这意味着我们需要将解码器的最终卷积转置层中的通道数更改为 3。
我们将使用 200 维而不是 2 维的潜在空间。由于人脸比时尚 MNIST 图像复杂得多,我们增加了潜在空间的维数,以便网络可以从图像中编码出令人满意的细节量。
每个卷积层之后都有批量归一化层来稳定训练。尽管每个批次需要更长的时间来运行,但达到相同损失所需的批次数量大大减少。
我们将 β 因子增加到 2000。这是一个需要调整的参数;对于这个数据集和架构,这个值被发现可以产生很好的结果。
这编码器和解码器的完整架构如图 2.17 和 图2.18 所示。
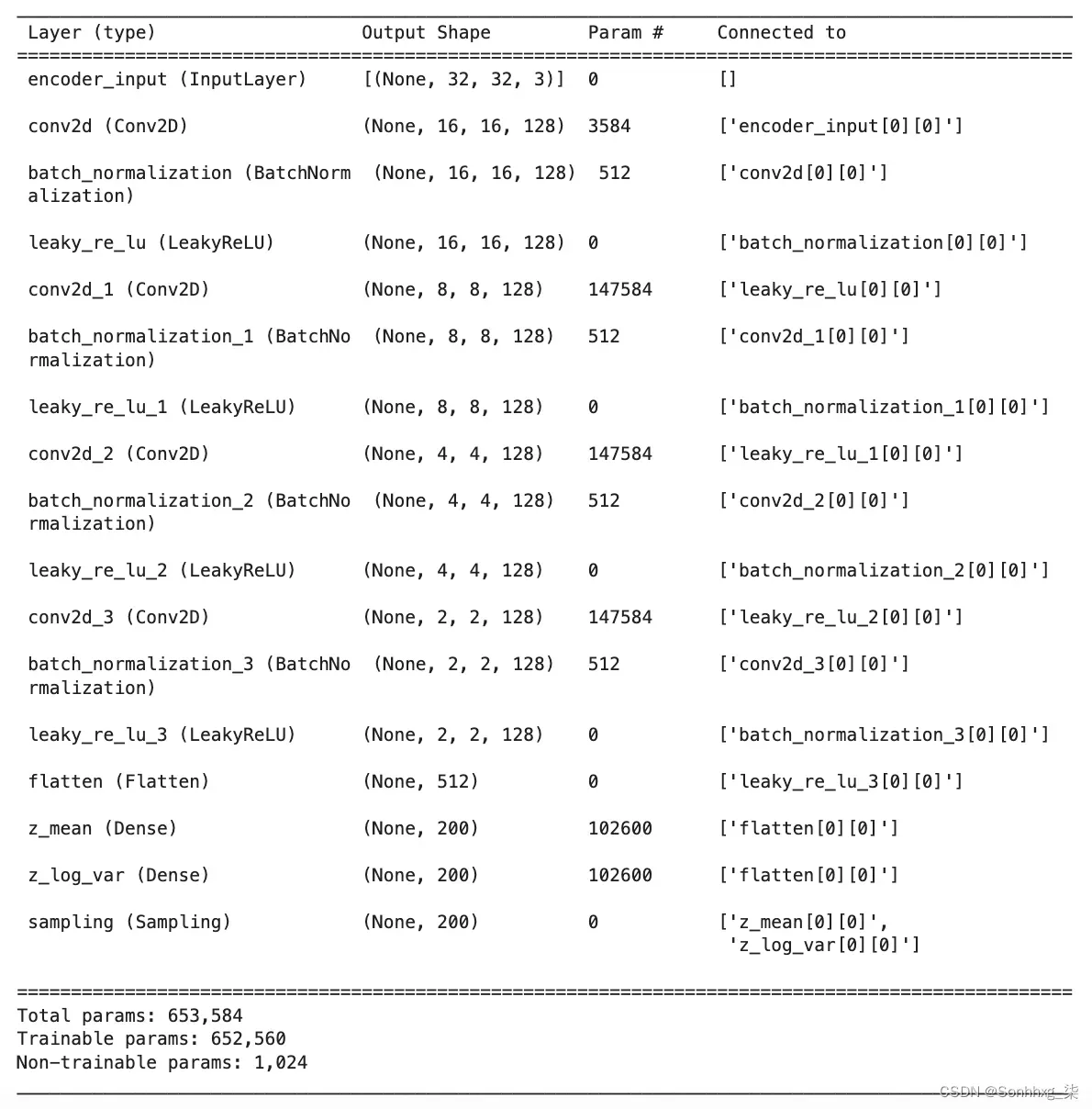
图2.17 CelebA 数据集的 VAE 编码器

图2.18 CelebA 数据集的 VAE 解码器
经过大约五个 epoch 的训练后,您的 VAE 应该能够生成新颖的名人面孔图像!
VAE分析
你一旦您训练了 VAE,就可以通过运行笔记本chapter04/vae/faces/02_generate.ipynb来复制随后的分析。许多本节中的想法灵感来自 2016 年的一篇论文侯先旭等人。
首先,让我们看一下重建面部的样本。图2.19 中的顶行显示原始图像,底行显示通过编码器和解码器后的重建图像。

图 2.19 经过编码器和解码器后重建的人脸
我们可以看到 VAE 已经成功地捕获了每张脸的关键特征——头部的角度、发型、表情等。一些细节丢失了,但重要的是要记住构建变分的目的自动编码器无法实现完美的重建损失。我们的最终目标是从潜在空间中采样以生成新面孔。
为了使这成为可能,我们必须检查潜在空间中点的分布是否大致类似于多元标准正态分布。由于我们无法同时查看所有维度,因此我们可以单独检查每个潜在维度的分布。如果我们看到任何与标准正态分布明显不同的维度,我们可能应该减少重建损失因子,因为 KL 散度项没有足够的效果。
我们的潜在空间中的前 50 个维度如图2.20 所示。没有任何分布明显不同于标准正态分布,因此我们可以继续生成一些面孔!
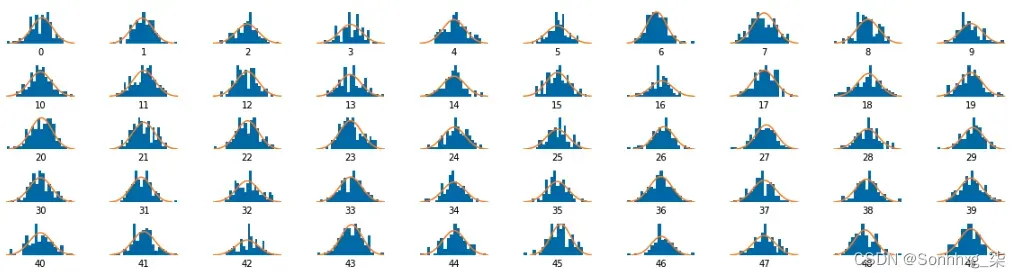
图2.20 潜在空间中前 50 个维度的点分布
生成新面孔
到生成新面孔,我们可以使用示例2.14 中的代码。
示例2.14 从潜在空间生成新面孔
grid_width, grid_height = (10,3)
z_sample = np.random.normal(size=(grid_width * grid_height, 200))
reconstructions = decoder.predict(z_sample)
fig = plt.figure(figsize=(18, 5))
fig.subplots_adjust(hspace=0.4, wspace=0.4)
for i in range(grid_width * grid_height):
ax = fig.add_subplot(grid_height, grid_width, i + 1)
ax.axis("off")
ax.imshow(reconstructions[i, :, :])1.从具有 200 个维度的标准多元正态分布中抽样 30 个点。
2.解码采样点。
3.结果输出是一组我们可以查看的图像。
输出图2.21 所示。

图2.21 新生成的面孔
令人惊讶的是,VAE 能够采用我们采样的一组点并将每个点转换为令人信服的人脸图像。虽然这些图像并不完美,但与我们在第 1 章开始探索的朴素贝叶斯模型相比,它们是一个巨大的飞跃。朴素贝叶斯模型面临着无法捕获相邻像素之间依赖关系的问题,因为它没有太阳镜或棕色头发等高级特征的概念。VAE 不会遇到这个问题,因为编码器的卷积层被设计为将低级像素转换为高级特征,而解码器被训练为执行相反的任务,将潜在的高级特征转换为空间回到原始像素。
潜在空间算法
一将图像映射到低维空间的好处是,我们可以对这个潜在空间中的向量执行算术运算,当解码回原始图像域时,该空间具有视觉模拟。
例如,假设我们想拍一张看起来很悲伤的人的照片,然后给他们一个微笑。为此,我们首先需要在潜在空间中找到一个指向微笑增加方向的向量。将这个向量添加到潜在空间中原始图像的编码将为我们提供一个新点,在解码时,应该为我们提供原始图像的更多笑脸版本。
那么我们怎样才能找到微笑向量呢?CelebA 数据集中的每张图像都标有属性,其中一个是Smiling. 如果我们将具有属性 的编码图像在潜在空间中的平均位置Smiling减去不具有属性 的编码图像的平均位置Smiling,我们将得到指向 方向的向量Smiling,这正是我们需要的。
从概念上讲,我们在潜在空间中执行以下向量运算,其中alpha是一个决定添加或减去多少特征向量的因素:
z_new = z + alpha * feature_vector
让我们看看实际效果。图2.22 显示了几个已编码到潜在空间中的图像。然后,我们添加或减去某个向量的倍数(例如,Smiling, Black_Hair, Eyeglasses, Young, Male, Blond_Hair)以获得图像的不同版本,仅更改相关特征。

图2.22 在人脸中添加和减去特征
值得注意的是,即使我们在潜在空间中将点移动了相当大的距离,核心图像仍然大致相同,除了我们想要操纵的一个特征。这展示了变分自动编码器捕获和调整图像高级特征的能力。
在面孔之间变形
我们可以使用类似的想法在两个面之间变形。想象一下潜在空间中的两个点 A 和 B,它们代表两个图像。如果你从 A 点开始,沿直线走向 B 点,边走边解码直线上的每个点,你会看到从起始面到结束面的逐渐过渡。
从数学上讲,我们正在穿过一条直线,可以用以下等式来描述:
z_new = z_A * (1- alpha) + z_B * alpha
这里,alpha是一个介于 0 和 1 之间的数字,它决定了我们沿着这条线离 A 点有多远。
图2.23 显示了这个过程的实际效果。我们拍摄两张图像,将它们编码到潜在空间中,然后以固定间隔对它们之间的直线上的点进行解码。

图 2.23 在两张脸之间变形
值得注意的是过渡的平滑性——即使有多个特征同时改变(例如,摘掉眼镜、头发颜色、性别),VAE 设法流畅地实现这一点,表明 VAE 的潜在空间是真实的一个连续的空间,可以穿越和探索以产生大量不同的人脸。
概括
在本章中,我们了解了变分自动编码器如何成为生成建模工具箱中的强大工具。我们首先探索了如何使用普通自动编码器将高维图像映射到低维潜在空间,以便可以从单独的无信息像素中提取高级特征。然而,我们很快发现使用普通自动编码器作为生成模型存在一些缺点——出于多种原因,从学习的潜在空间中采样是有问题的。
变分自动编码器通过在模型中引入随机性并限制潜在空间中的点分布方式来解决这些问题。我们看到,通过一些小的调整,我们可以将我们的自动编码器转换为变分自动编码器,从而赋予它成为生成模型的能力。
最后,我们将新技术应用于人脸生成问题,并了解了如何简单地从标准正态分布中选择点来生成新人脸。此外,通过在潜在空间内执行向量运算,我们可以实现一些惊人的效果,例如面部变形和特征操作。有了这些特性,就很容易理解为什么 VAE 近年来成为生成建模的主要技术。
在下一章中,我们将探索另一种引起更多关注的生成模型:生成对抗网络。
文章出处登录后可见!