
©PaperWeekly 原创 · 作者 | 避暑山庄梁朝伟

背景
随着 ChatGPT 的火爆出圈,大模型也逐渐受到越来越多研究者的关注。有一份来自 OpenAI 的研究报告 (Scaling laws for neural language models) 曾经指出模型的性能常与模型的参数规模息息相关,那么如何训练一个超大规模的 LLM 也是大家比较关心的问题,常用的分布式训练框架有 Megatron-LM 和 DeepSpeed,下面我们将简单介绍这些框架及其用到的技术。

基础知识
在介绍这些和框架和技术之前先介绍一下设计分布式训练的基本知识。
1)通讯原语操作
NCCL 英伟达集合通信库,是一个专用于多个 GPU 乃至多个节点间通信的实现。它专为英伟达的计算卡和网络优化,能带来更低的延迟和更高的带宽。
a. Broadcast: Broadcast 代表广播行为,执行 Broadcast 时,数据从主节点 0 广播至其他各个指定的节点(0~3)。
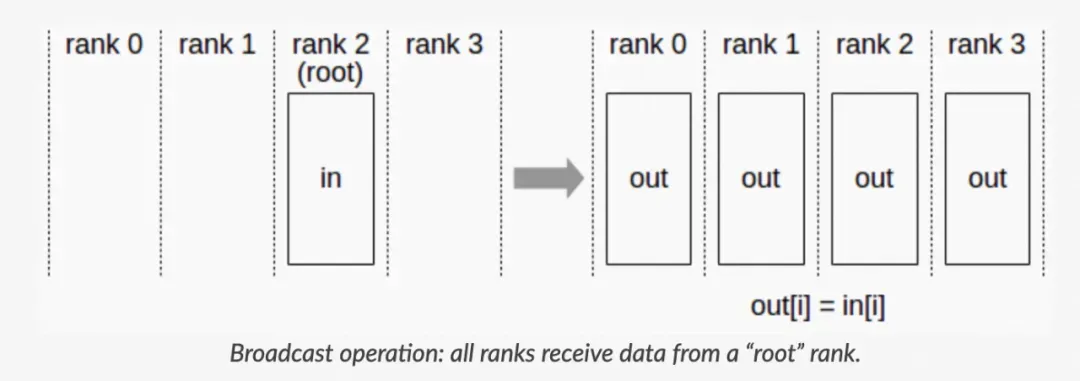
▲ Broadcast
b. Scatter: Scatter 与 Broadcast 非常相似,都是一对多的通信方式,不同的是 Broadcast 的 0 号节点将相同的信息发送给所有的节点,而 Scatter 则是将数据的不同部分,按需发送给所有的节点。
c. Reduce: Reduce 称为规约运算,是一系列简单运算操作的统称,细分可以包括:SUM、MIN、MAX、PROD、LOR 等类型的规约操作。Reduce 意为减少/精简,因为其操作在每个节点上获取一个输入元素数组,通过执行操作后,将得到精简的更少的元素。
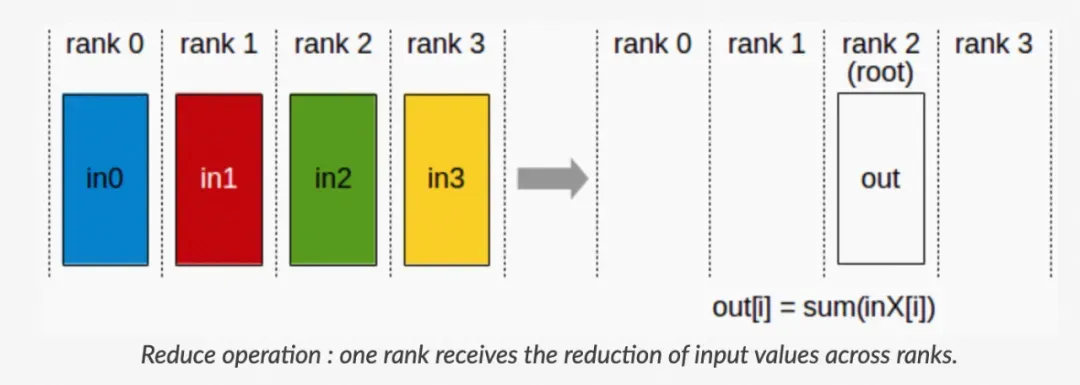
▲ Reduce
d. AllReduce: Reduce 是一系列简单运算操作的统称,All Reduce 则是在所有的节点上都应用同样的 Reduce 操作。
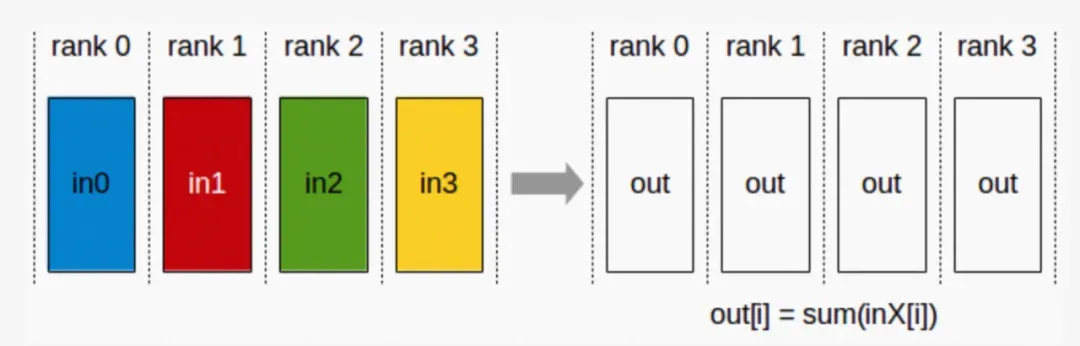
▲ AllReduce
e. Gather: Gather 操作将多个 sender 上的数据收集到单个节点上,Gather 可以理解为反向的 Scatter。
f. AllGather: 收集所有数据到所有节点上。从最基础的角度来看,All Gather 相当于一个 Gather 操作之后跟着一个 Broadcast 操作。
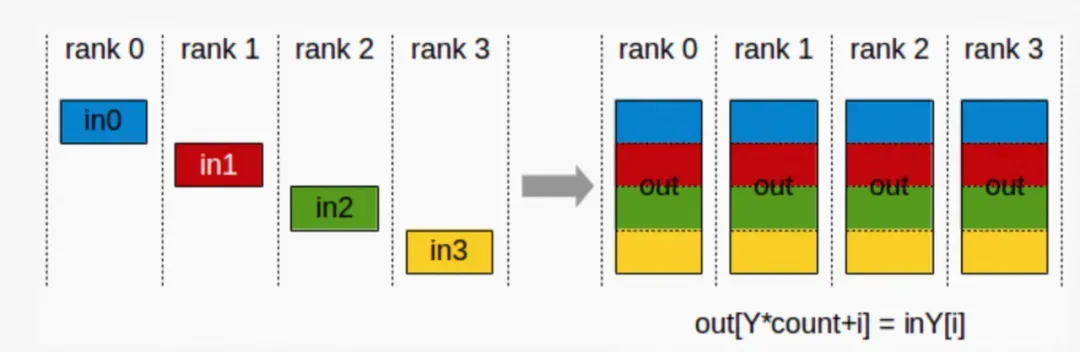
▲ AllGather
g. ReduceScatter: Reduce Scatter 操作会将个节点的输入先进行求和,然后在第0维度按卡数切分,将数据分发到对应的卡上。
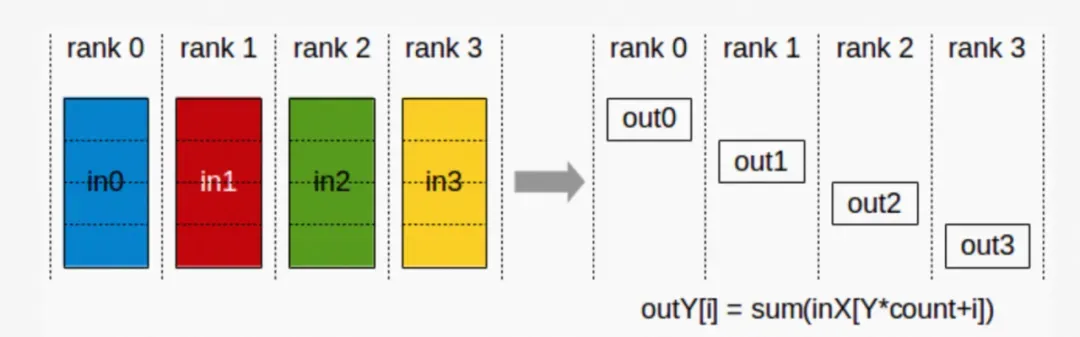
▲ ReduceScatter
这里多说一下 AllReduce 操作,目标是高效得将不同机器中的数据整合(reduce)之后再把结果分发给各个机器。在深度学习应用中,数据往往是一个向量或者矩阵,通常用的整合则有 Sum、Max、Min 等。AllReduce 具体实现的方法有很多种,最单纯的实现方式就是每个 worker 将自己的数据发给其他的所有 worker,然而这种方式存在大量的浪费。
一个略优的实现是利用主从式架构,将一个 worker 设为 master,其余所有 worker 把数据发送给 master 之后,由 master 进行整合元算,完成之后再分发给其余 worker。不过这种实现 master 往往会成为整个网络的瓶颈。
AllReduce 还有很多种不同的实现,多数实现都是基于某一些对数据或者运算环境的假设,来优化网络带宽的占用或者延迟。如 Ring AllReduce:
第一阶段,将 N 个 worker 分布在一个环上,并且把每个 worker 的数据分成 N 份。
第二阶段,第 k 个 worker 会把第 k 份数据发给下一个 worker,同时从前一个 worker 收到第 k-1 份数据。
第三阶段,worker 会把收到的第 k-1 份数据和自己的第 k-1 份数据整合,再将整合的数据发送给下一个 worker。
此循环 N 次之后,每一个 worker 都会包含最终整合结果的一份。假设每个 worker 的数据是一个长度为 S 的向量,那么个 Ring AllReduce 里,每个 worker 发送的数据量是 O(S),和 worker 的数量 N 无关。这样就避免了主从架构中 master 需要处理 O(S*N) 的数据量而成为网络瓶颈的问题。
2)并行计算技术
a. 数据并行
DP (Data Parallel):本质上是单进程多线程的实现方式,只能实现单机训练不能算是严格意义上的分布式训练。步骤如下:
首先将模型加载到主 GPU 上,再复制到各个指定从 GPU;
将输入数据按照 Batch 维度进行拆分,各个 GPU 独立进行 forward 计算;
将结果同步给主 GPU 完成梯度计算和参数更新,将更新后的参数复制到各个 GPU。
主要存在的问题:
负载不均衡,主 GPU 负载大
采用 PS 架构通信开销大
分布式数据并行 DDP (Distribution Data Parallel):采用 AllReduce 架构,在单机和多机上都可以使用。负载分散在每个 GPU 节点上,通信成本是恒定的,与 GPU 数量无关。
b. 张量并行:分布式张量计算是一种正交且更通用的方法,它将张量操作划分到多个设备上,以加速计算或增加模型大小。把 Masked Multi Self Attention 和 Feed Forward 都进行切分以并行化,利用 Transformers 网络的结构,通过添加一些同步原语来创建一个简单的模型并行实现。其实比较容易理解,直接上图:
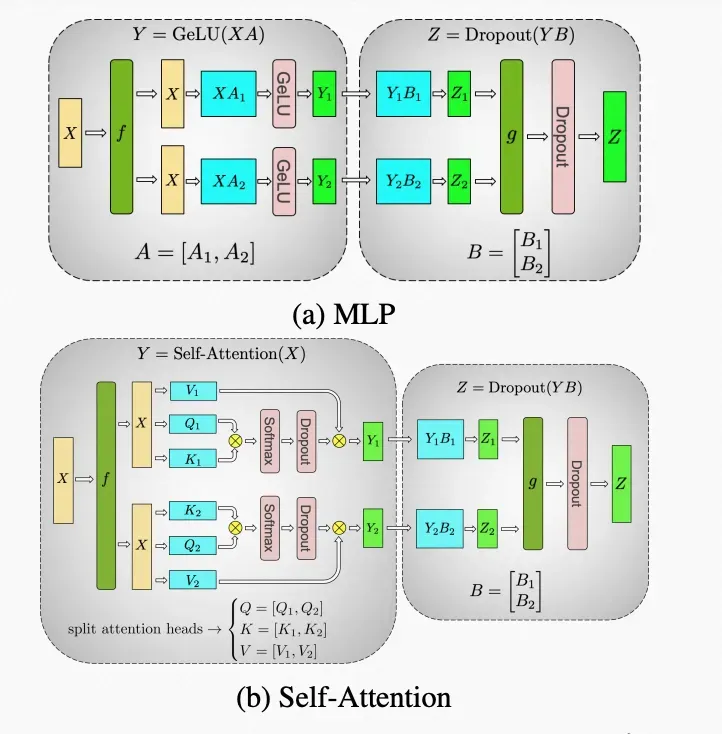
▲ 张量并行图解

▲ 张量并行公式
在 MLP 层中,对 A 采用“列切割”,对 B 采用“行切割”。
的 forward 计算:把输入 X 拷贝到两块 GPU 上,每块 GPU 即可独立做 forward 计算。
的 forward 计算:每块 GPU 上的 forward 的计算完毕,取得 Z1 和 Z2 后,GPU 间做一次 AllReduce,相加结果产生 Z。
的 backward 计算:只需要把 拷贝到两块 GPU 上,两块 GPU 就能各自独立做梯度计算。
的 backward 计算:当当前层的梯度计算完毕,需要传递到下一层继续做梯度计算时,我们需要求得 。则此时两块 GPU 做一次 AllReduce,把各自的梯度 和 相加即可。
为什么我们对 采用列切割,对 采用行切割呢?这样设计的原因是,我们尽量保证各 GPU 上的计算相互独立,减少通讯量。对 A 来说,需要做一次 GELU 的计算,而 GELU 函数是非线形的,也就意味着,如果对 A 采用行切割,我们必须在做 GELU 前,做一次 AlIReduce,这样就会产生额外通讯量。但是如果对 A 采用列切割,那每块 GPU 就可以继续独立计算了。一旦确认好 A 做列切割,那么也就相应定好 B 需要做行切割了。
MLP 层做 forward 时产生一次 AllReduce,做 backward 时产生一次 AllReduce。AllReduce 的过程分为两个阶段,Reduce-Scatter 和 All-Gather,每个阶段的通讯量都相等。现在我们设每个阶段的通讯量为 ,则一次 AllReduce 产生的通讯量为 。MLP 层的总通讯量为 。
c. 流水并行:无论是数据并行还是模型并行,都会在相应的机器之间进行全连接的通信,当机器数量增大时,通信开销和时延会大到难以忍受。而流水并行既解决了超大模型无法在单设备上装下的难题,又很好解决了机器之间的通信开销的问题,每个阶段(stage) 和下一个阶段之间仅有相邻的某一个 Tensor 数据需要传输,每台机器的数据传输量跟总的网络大小、机器总数、并行规模无关。
G-pipe
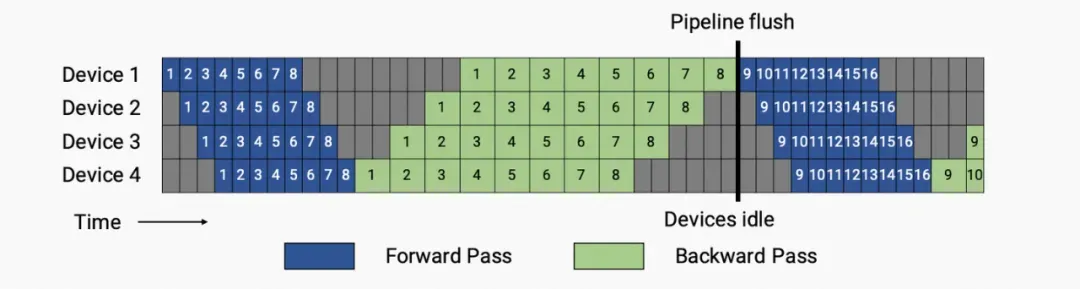
▲ G-pipe
以图为例,将 transformer layer 按层切分放到 Device1-4 上,并将一个 batch 切分成 8 个 mini-batch。前向时,每个 mini-batch 从 Device 1 流向 Device 4;反向时,在 Device 4 上算出梯度并更新 Device4 对应层的参数,将梯度传向 Device 3,Device 3 做梯度计算和参数更新后传给 Device 2 等。
这么做的劣势之一是空泡率比较高。 代表 time of pipeline bubble, 代表 micro-batch 数量, 代表 pipeline stages, 代表 time of ideal iteration,令 表示前向时间, 表示反向时间,图从的 pipeline 的 bubble 共有 个前向和反向,故 ,而理想时间 ,就有空泡比率。
bubble time fraction (pipeline bubble size ) 若要降低空泡比率,需要 ,但接着会带来第二个问题,峰值内存占用高。可以看出, 个 micro-batch 反向算梯度的过程,都需要之前前向保存的激活值,所以在 个 mini-batch 前向结束时,达到内存占用的峰值。Device 内存一定的情况下, 的上限明显受到限制。
G-pipe 提出解决该问题的方法是做重计算(叫 Re-Materialization,实际上很多会叫 activationcheckpointing),以释放前向激活值,只保留模型切段的部分激活值和种子信息,需要反向时再重来一遍;前提重计算出来的结果和之前得一样,并且前向的时间不能太长,否则流水线会被拉长太多。
PipeDream

▲ PipeDream
PipeDream 的方案如上图所示,其相对与 G-pipe 的改进在内存方面, 空泡时间 t p b 和 G-pipe 一致,但通过合理安排前向和反向过程的顺序,在 step 中间的稳定阶段,形成 1前向1反向 的形式,称为 1F1B 模式,在这个阶段,每个 Device 上最少只需要保存 1 份 micro-batch 的激活值,最多需要保存 p 份激活值。可以看到,激活值份数的上限从 micro-batch 数量 m 变成了 pipeline stage 阶段 p ,这样就可以依据 m >> p 的原则有效降低空泡占比。
virtual pipeline
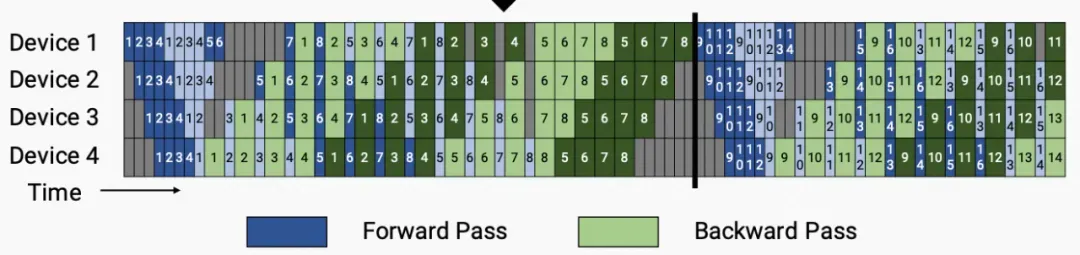
传统的 pipeline 并行通常会在一个 Device 上放置几个 block,是为了扩展效率考虑,在计算强度和通信强度中间取一个平衡。但 virtual pipeline 的却反其道而行之,在 device 数量不变的情况下,分出更多的 pipeline stage,以更多的通信量,换取空泡比率降低,减小了 step e2e 用时(step e2e 上直观的改善可以看文章题图)。
virtual pipeline 是怎么做到的呢?对照示例图举例说明,若网络共 16 层(编号 0-15),4 个 Device,前述 Gpipe 和 PipeDream 是分成 4 个stage,按编号 0-3 层放 Device1,4-7 层放 Device2 以此类推。
virtual pipeline 则是按照文中提出的 virtual_pipeline_stage 概念减小切分粒度,以 virtaul_pipeline_stage 为例,将 0-1 层放 Device1,2-3 层放在 Device2,…,6-7 层放到 Device4,8-9 层继续放在 Device1,10-11 层放在 Device2,…,14-15 层放在 Device4。在 steady 的时候也是 1F1B 的形式,叫做 1F1B-interleaving。
按照这种方式,Device 之间的点对点通信次数(量)直接翻了 virtual_pipeline_stage 倍,但空泡比率降低了,若定义每个 Device 上有 个 virtual stages,或者论文中也叫做 model_chunks,这个例子中 ,所以现在前向时间和反向时间分别是 ,空泡时间是 ,int. 是为了表示一个约束条件,即 micro-batch 数量需是 Device 数量整数倍。这样一来,空泡比率:
Bubble time fraction (pipeline bubble size)
现在,空泡比率和 也成反比了。
d. 梯度累加:Gradient Accumulation 就是把一个大 Batch 拆分成多个 micro-batch,每个 micro-batch 前后向计算后的梯度累加,在最后一个 micro-batch 累加结束后,统一更新模型。
micro-batch 跟数据并行有高度的相似性:数据并行是空间上的,数据被拆分成多个 tensor,同时喂给多个设备并行计算,然后将梯度累加在一起更新;而 micro-batch 是时间上的数据并行, 数据被拆分成多个 tensor,按照时序依次进入同一个设备串行计算,然后将梯度累加在一起更新。
当总的 batch size 一致,且数据并行的并行度和 micro-batch 的累加次数相等时,数据并行和 Gradient Accumulation 在数学上完全等价。Gradient Accumulation 通过多个 micro-batch的梯度累加使得下一个 micro-batch 的前向计算不需要依赖上一个 micro-batch 的反向计算,因此可以畅通无阻的进行下去(当然在一个大 batch 的最后一次 micro-batch 还是会触发这个依赖)。
Gradient Accumulation 解决了很多问题:
在单卡下,Gradient Accumulation 可以将一个大的 batch size 拆分成等价的多个小 micro-batch ,从而达到节省显存的目的。
在数据并行下,Gradient Accumulation 解决了反向梯度同步开销占比过大的问题(随着机器数和设备数的增加,梯度的 AllReduce 同步开销也加大),因为梯度同步变成了一个稀疏操作,因此可以提升数据并行的加速比。
在流水并行下, Gradient Accumulation 使得不同 stage 之间可以并行执行不同的 micro-batch, 从而让各个阶段的计算不阻塞,达到流水的目的。如果每个 micro-batch 前向计算的中间结果(activation)被后向计算所消费,则需要在显存中缓存 8多份(梯度累加的次数)完整的前向 activation。这时就不得不用另一项重要的技术:激活检查点(activation checkpointing)。
e. 激活检查点:Checkpointing 的核心思想 是在前向网络中标记少量的 Tensor (被 Checkpointing 的 Tensor ),前向计算就只会保留这些被标记的 Tensor, 其余的前向的 activation,会通过在反向传播中根据 Checkpointing 的 Tensor 临时重新计算一遍前向得到。这样就使得大量的 activation 不需要一直保存到后向计算,有效减少了大量 Tensor 的生命周期,使得内存复用效率大幅提升。
f. ZeRO:混合精度训练(mixed precision training)[1] 和 Adam [2] 优化器基本上已经是训练语言模型的标配,我们先来简单回顾下相关概念。Adam 在 SGD 基础上,为每个参数梯度增加了一阶动量(momentum)和二阶动量(variance)。混合精度训练,字如其名,同时存在 fp16 和 fp32 两种格式的数值,其中模型参数、模型梯度都是 fp16,此外还有 fp32 的模型参数,如果优化器是 Adam,则还有 fp32 的 momentum 和 variance。
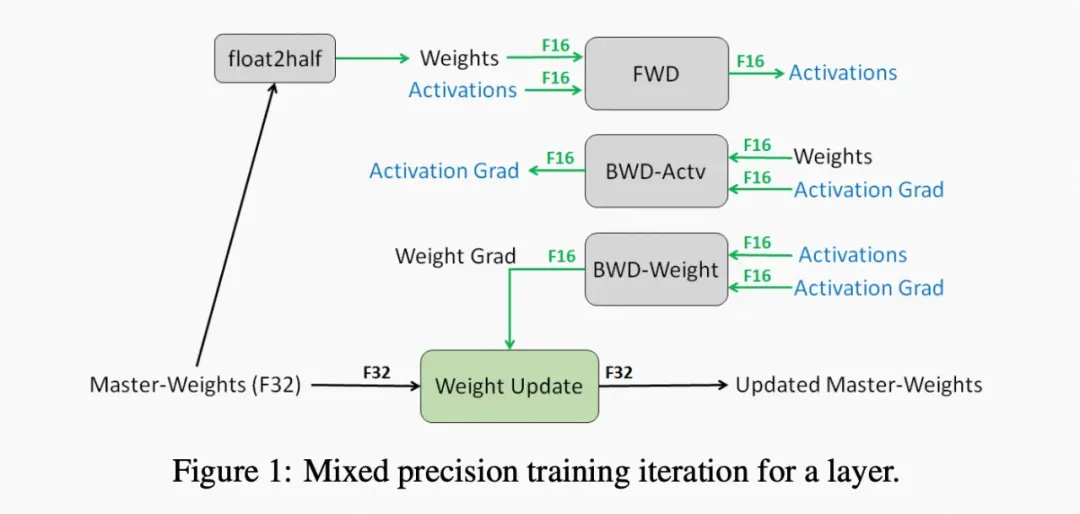
ZeRO 将模型训练阶段,每张卡中显存内容分为两类:
1. 模型状态 (model states):模型参数 (fp16) 、模型梯度 (fp16) 和Adam状态 (fp32 的模型参数备份, 的 momentum 和 fp32 的 variance) 。假设模型参数量 ,则共需要 字节存储,可以看到,Adam 状态占比 。
2. 剩余状态 (residual states) :除了模型状态之外的显存占用,包括激活值 (activation) 、各种临时缓冲区(buffer)以及无法使用的显存碎片(fragmentation)。
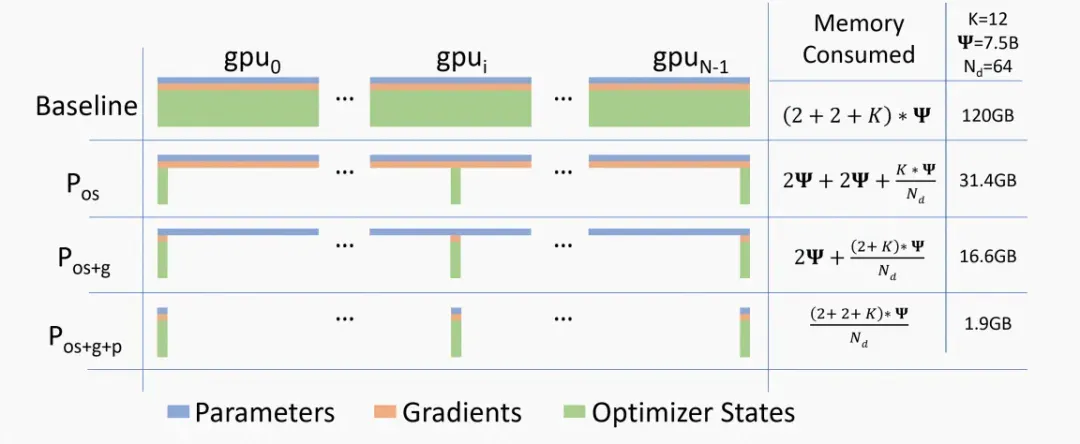
针对模型状态的存储优化(去除冗余),ZeRO 使用的方法是分片 (partition),即每张卡只存 的模型状态量,这样系统内只维护一份模型状态。
首先进行分片操作的是模型状态中的 Adam,也就是下图中的 ,这里 os 指的是 optimizer states。模型参数 (parameters) 和梯度 (gradients) 仍旧是每张卡保持一份,此时,每张卡的模型状态所需显存是 字节,当 比较大时,趋向于 ,也就是原来 的 。
如果继续对模型梯度进行分片,也就是下图中的 ,模型参数仍旧是每张卡保持一份,此时,每张卡的模型状态所需显存是 字节,当 比较大时,趋向于 ,也即是原来 的 。
如果继续对模型参数进行分片,也就是下图中的 ,此时每张卡的模型状态所需显存是 字节,当 比较大时,趋向于 0。
传统数据数据并行在每一步 (step/iteration) 计算梯度后,需要进行一次 AllReduce 操作来计算梯度均值,目前常用的是 Ring AllReduce,分为 ReduceScatter 和 AllGather 两步,每张卡的通信数据量(发送+接受)近似为 。
我们直接分析 ,每张卡只存储 的优化器状态和梯度,对于 来说,为了计算它这 梯度的均值,需要进行一次 Reduce 操作,通信数据量是 ,然后其余显卡则不需要保存这部分梯度值了。实现中使用了 bucket 策略,保证 的梯度每张卡只发送一次。
当 计算好梯度均值后,就可以更新局部的优化器状态(包括 的参数),当反向传播过程结束,进行一次 Gather 操作,更新 的模型参数,通信数据量是 。
从全局来看,相当于用 Reduce-Scatter 和 AllGather 两步,和数据并行一致。
使得每张卡只存了 的参数,不管是在前向计算还是反向传播,都涉及一次 Broadcast 操作。
综上, 和 的通信量和传统数据并行相同, 会增加通信量。
▲ Zero通信量

Megatron-LM
1). Megatron-LM-1
利用了张量并行和数据并行。
2). Megatron-LM-2
Megatron 2 在 Megatron 1 的基础上新增了 pipeline 并行,提出了 virtual pipeline:1F1B-interleaving,成为和 DeepSpeed 类似的 3D 并行的训练框架,新增的 pipeline 并行就是本文主要所阐述的内容。另外 Megatron-2 论文中还提及了一些通信优化的小 trick,本质是增加本地的 io 操作和通信,从而降低低带宽网络的通信量。
内存占用角度:主要是 G-pipe 到 PipeDream 的进化完成的,通过及时安排反向过程,将前向激活值释放掉,避免积累太多激活值占用内存,提高了模型并行的能力。
空泡比率角度:空泡比率的提升主要从 1F1B 到 1F1B-interleaving 的进化得来。pipeline 并行的一个基本规律就是 pipeline 流水的级数越多,overhead 就越小。
3). Megatron-LM-3
增加了 Sequence Parallelism、Selective Activation Recomputation 和 Checkpointing Skipping 三个 feature。
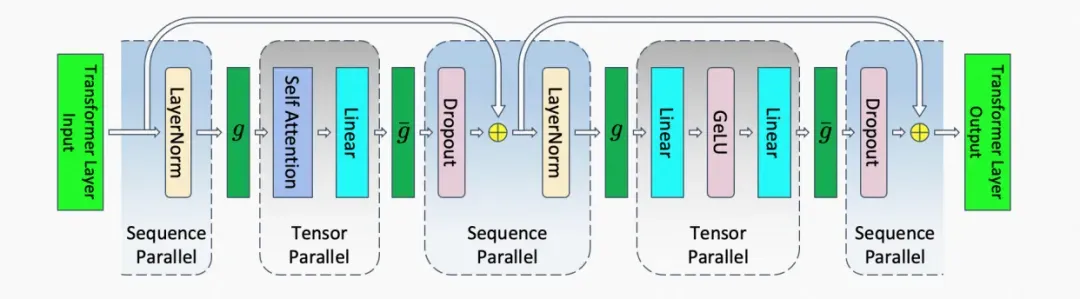
a. Sequence Parallelism: 在 Tensor Parallelism 的基础上,将 Transformer 核的 LayerNorm 以及 Dropout 层的输入按 Sequence Length 维度进行了切分,使得各个设备上面只需要做一部分的 Dropout 和 LayerNorm。
这样做的好处有两个:1)LayerNorm 和 Dropout 的计算被平摊到了各个设备上,减少了计算资源的浪费;2)LayerNorm 和 Dropout 所产生的激活值也被平摊到了各个设备上,进一步降低了显存开销。
在 Megatron1, 2 中,Transformer 核的 TP 通信是由正向两个 Allreduce 以及后向两个 Allreduce 组成的。Megatron 3 由于对 sequence 维度进行了划分,Allreduce 在这里已经不合适了。为了收集在各个设备上的 sequence parallel 所产生的结果,需要揷入 Allgather 算子;而为了使得 TP 所产生的结果可以传入 sequence parallel 层,需要揷入 reduce-scatter 算子。
在下图中, 所代表的就是前向 Allgather,反向 reduce scatter, 则是相反的操作。这么一来,我们可以清楚地看到,Megatron-3 中,一共有 4 个 Allgather 和 4 个 reduce-scatter 算子。乍一看,通信的操作比 Megatron-1 2 都多得多,但其实不然。
因为一般而言,一个 Allreduce 其实就相当于 1 个 Reduce-scatter 和 1 个 Allgather,所以他们的总通信量是一样的。Megatron-3 在总通信量一样的基础上,在后向代码的实现上,还把 reduce-scatter 和权重梯度的计算做了重叠,进一步减少了通信所占用的时间,使得提高设备的 FLOPs Utilization 成为了可能。
▲ Sequence Parallelism
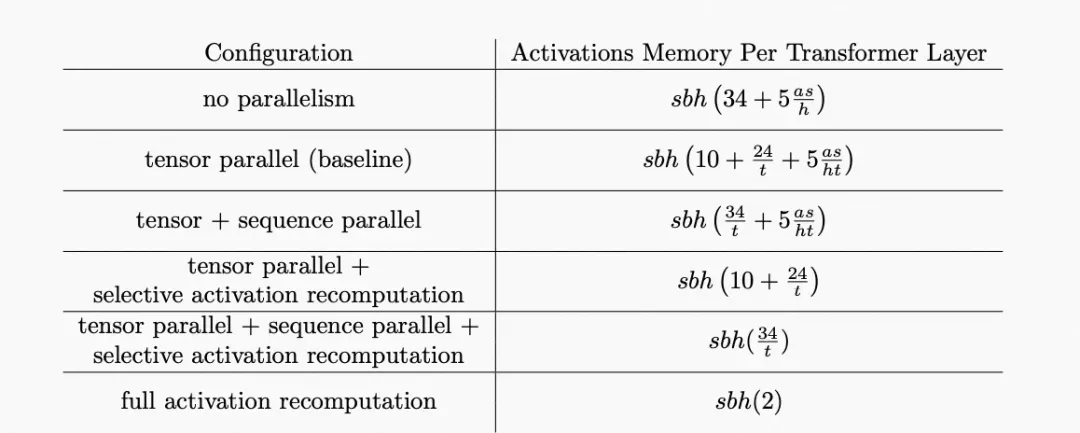
b. Selective Activation Recomputation: Megatron-3 把 Transformer 族模型的所有 activation 消耗算了一遍,然后发现在 Transformer 核里有一些操作是产生的激活值又大,但是计算量又小的。所以他们就考虑干掉这一部分的激活值,然后其他的激活值我们就通通存下来,以节省我们的重计算量。
▲ Selective Activation Recomputation
c. Checkpointing Skipping: Megatron-3 提出,在 GPU 的显存没占满的时候,我们可以不做 checkpointing,这么一来重计算所带来的额外计算代价会进一步减小。
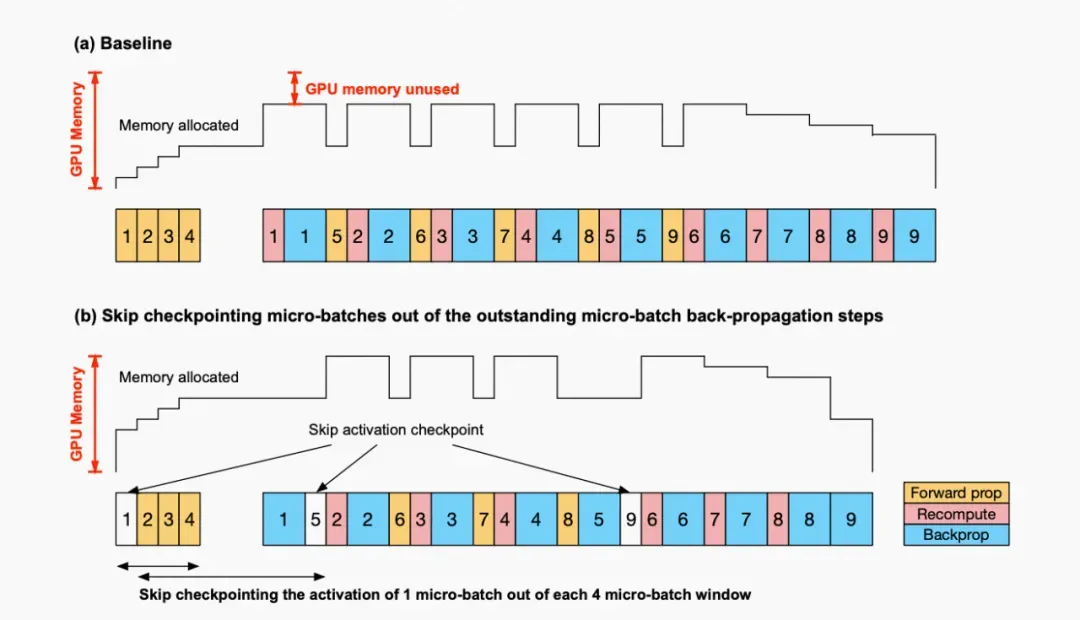
▲ Checkpointing Skipping

DeepSpeed
1). 3D 并行化实现万亿参数模型训练:DeepSpeed 实现了三种并行方法(数据并行训练,模型并行训练和流水线并行训练)的灵活组合:ZeRO 支持的数据并行,流水线并行和张量切片模型并行。3D 并行性适应了不同工作负载的需求,以支持具有万亿参数的超大型模型,同时实现了近乎完美的显存扩展性和吞吐量扩展效率。此外,其提高的通信效率使用户可以在网络带宽有限的常规群集上以 2-7 倍的速度训练有数十亿参数的模型。
2). ZeRO-Offload 使 GPU 单卡能够训练 10 倍大的模型:为了同时利用 CPU 和 GPU 内存来训练大型模型,扩展了 ZeRO-2。在使用带有单张英伟达 V100 GPU 的机器时,可以在不耗尽显存的情况下运行多达 130 亿个参数的模型,模型规模扩展至现有方法的10倍,并保持有竞争力的吞吐量。此功能使数十亿参数的模型训练更加大众化,并为许多深度学习从业人员打开了一扇探索更大更好的模型的窗户。
3). 通过 DeepSpeed Sparse Attention 用 6 倍速度执行 10 倍长的序列:DeepSpeed 提供了稀疏 attention kernel ——一种工具性技术,可支持长序列的模型输入,包括文本输入,图像输入和语音输入。与经典的稠密 Transformer 相比,它支持的输入序列长一个数量级,并在保持相当的精度下获得最高 6 倍的执行速度提升。它还比最新的稀疏实现快 1.5–3 倍。此外,稀疏 kernel 灵活支持稀疏格式,使用户能够通过自定义稀疏结构进行创新。
其他常见的稀疏 Attention 方法:
a. Generating Long Sequences with Sparse Transformers: 大家最容易想到的是每一个元素跳着求和其他元素的相关性,例如只和第 k,2k,3k,4k 的元素求。这里把这种方法叫做 Atrous self-attention (空洞自注意力),但是,大家一般的解决方式是 local self-attention,例子可以见下面的 image transformer,OpenAI 引入了 Sparse self-attention,把两者结合在一块,既可以学习到局部的特性,又可以学习到远程稀疏的相关性。
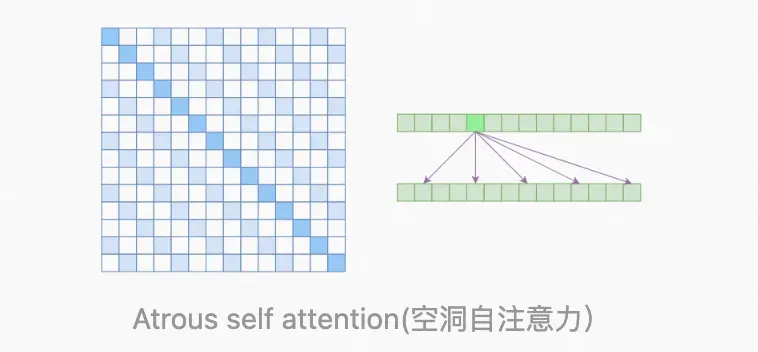
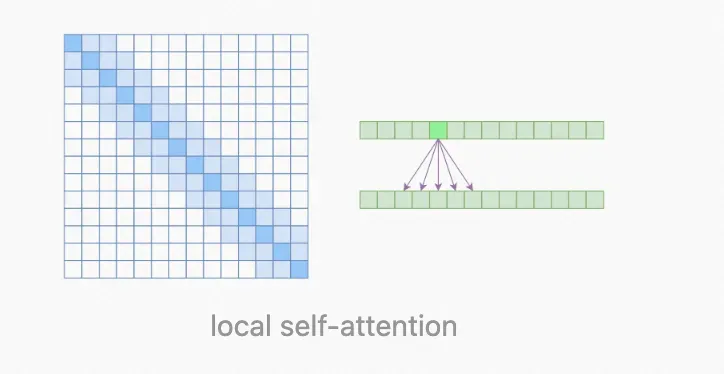
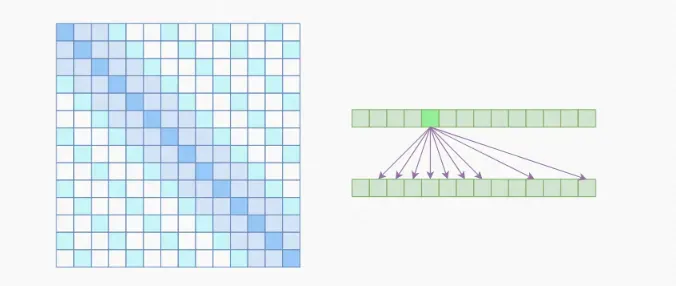
▲ Sparse self-attention
b. Sparse Transformer: Concentrated Attention Through Explicit Selection: 通过 Q 和 K 生成相关性分数 P,然后在 P 上选择最大的相关性元素即可。
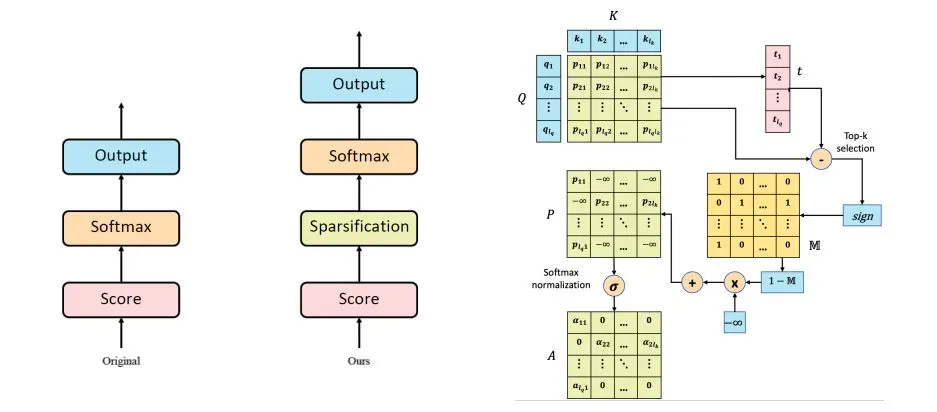
▲ Sparse Transformer
c. Longformer: The Long-Document Transformer: 提出local self-attention、Dilated sliding window 和 Global attention 三种方法。
d. Reformer: 通过 Locality sensitive hashing (LSH) 方法将 attention score 相近的分到一个 bucket 中,因为我们经过 softmax 之后,一个 query 和其他的所有的 token 的计算 attention score 主要是取决于高相似度的几个 tokens,所以采用这种方式将近似算得最终的 attention score。计算了每个桶中的注意力矩阵,并对相应的值进行加权。
由于它们只能注意到给定的中的元素,当选取的桶大小合适时,这样做可以将注意力操作的整体空间复杂度降低。通过 LSH 的方法近似的快速找到最大的 topk 的值。并且 Reformer 构造了可逆的 Feedforward Nateork 来替换掉原来的 Feedforward Network,降低了显存占用。
4). 1 比特 Adam 减少 5 倍通信量:Adam 是一个在大规模深度学习模型训练场景下的有效的(也许是最广为应用的)优化器。然而,它与通信效率优化算法往往不兼容。因此,在跨设备进行分布式扩展时,通信开销可能成为瓶颈。推出了一种 1 比特 Adam 新算法,以及其高效实现。该算法最多可减少 5 倍通信量,同时实现了与Adam相似的收敛率。在通信受限的场景下,观察到分布式训练速度提升了 3.5 倍,这使得该算法可以扩展到不同类型的 GPU 群集和网络环境。

总结
本文总结了深度学习框架技术是如何在硬件条件限制下,通过多年的技术升级,让 AI 模型的规模突破天际的。如果我们从更高的视角看,AI 模型的增长还有硬件,算法等领域的许多突破。整个生态正在飞速的往前发展。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·

文章出处登录后可见!