目标:
- 通过excel的公司名获取对应的公司的url,写入excel。
一、安装chromedriver
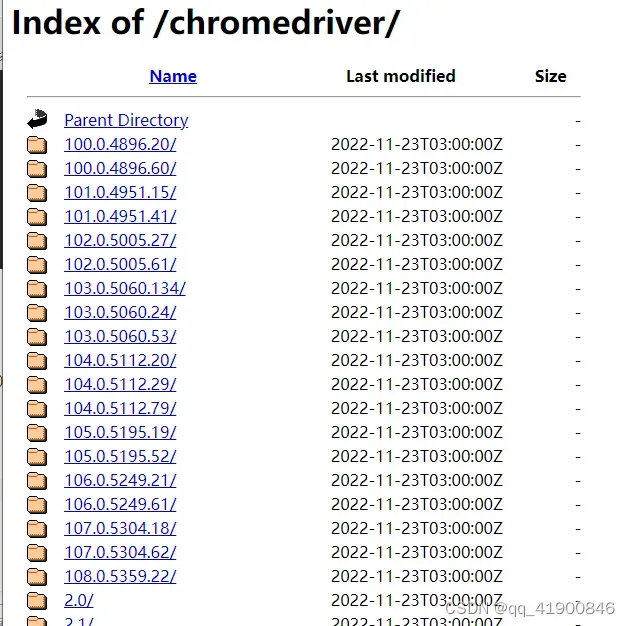
- 在google上输入:chrome://version/,查询自己的版本号,如:97.0.4692.99 (正式版本) (64 位)
- 选择chromedriver版本号下载,要和自己chrome的版本号前三段匹配,下载chromedriver_win32.zip类似这种文件名的文件。
- 下载链接:下载地址1,下载地址2,下载地址3
解压后把驱动文件chromedriver.exe的文件夹路径加到Path环境变量里。
(这里建议用户环境和系统环境的path都加上驱动文件的路径。)
win10 打开环境变量
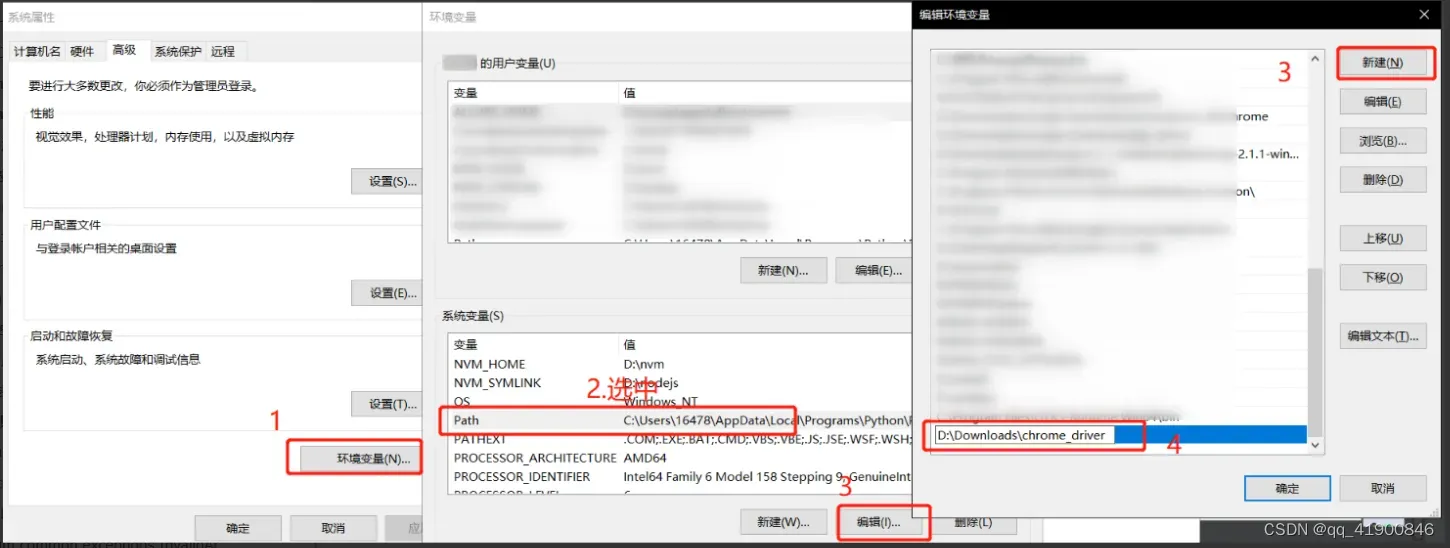
键盘按win+r,输入cmd,打开命令窗口,输入chromedriver,如下图则成功配置。

二、selenium+chromedriver 获取公司信息
1、提前用pip安装库,安装前先确保pip的版本是最新的
在cmd命令窗口输入python -m pip install –upgrade pip
async-generator==1.10
attrs==22.1.0
certifi==2022.9.24
cffi==1.15.1
charset-normalizer==2.1.1
cryptography==38.0.3
et-xmlfile==1.1.0
exceptiongroup==1.0.4
h11==0.14.0
idna==3.4
lxml==4.9.1
numpy==1.23.4
openpyxl==3.0.10
outcome==1.2.0
pandas==1.5.1
pycparser==2.21
pyOpenSSL==22.1.0
PySocks==1.7.1
python-dateutil==2.8.2
pytz==2022.6
requests==2.28.1
selenium==4.2.0
six==1.16.0
sniffio==1.3.0
sortedcontainers==2.4.0
trio==0.22.0
trio-websocket==0.9.2
urllib3==1.26.12
urllib3-secure-extra==0.1.0
wsproto==1.2.0
2、 确定要爬取的字段,输入企查查用户名和密码
import re
import time
from collections import defaultdict
import pandas as pd
import requests
from lxml import etree
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException, WebDriverException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
# 确定要爬取的字段
credit_code = []
registered_capital = []
check_dict = {
"统一社会信用代码": credit_code,
"注册资本": registered_capital,
}
# 企查查用户名和密码
username = "xx"
password = "xx"3、读取excel文件,
path = "company_msg.xlsx"
data = pd.read_excel(
path, sheet_name=0
) # 默认读取第一个sheet的全部数据,int整数用于引用的sheet的索引(从0开始)

4、selenium启动chrome,设置反扒参数
- 开启实验性功能参数:add_experimental_option()
- 读入命令行参数: add_argument()
# 使用chrome开发者模式
option = webdriver.ChromeOptions()
# 屏蔽webdriver特征
option.add_experimental_option(
"excludeSwitches", ["enable-automation"]
)
# 禁用启用Blink运行时的功能,关闭网页页面的反扒校验
option.add_argument("--disable-blink-features=AutomationControlled")
option.add_argument("--no-sandbox") # 表示禁用沙盒模式
# 沙盒模式:每一个标签页都是一个沙盒(sandbox),以“防止恶意软体自行执行安装”或“利用一个分页影响其他的分页”
# 关闭web沙盒的命令,有可能导致浏览恶意网站时,被入侵。
option.add_argument("--disable-dev-shm-usage") # 启动浏览器时,添加参数--disable-dev-shm-usage。该参数使用本地local/tmp代替/dev/shm作为 Chrome 的运行空间,local/tmp比/dev/shm有更大的空间,可以使Cypress运行时,不容易因为一个文件的测试用例数多,导致内存溢出的问题。
driver = webdriver.Chrome(options=option)
# Selenium执行cdp命令,没有出现验证框就能登录说明已经成功屏蔽网页对selenium的识别。
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.set_page_load_timeout(25) # 用于设置页面加载超时,指定时间内未加载出页面则会报错
driver.delete_all_cookies() # 删除所有 cookie 信息
url = (
"https://www.qcc.com/weblogin?back=%2F" # https://www.qcc.com/weblogin?back=%2F
)
driver.get(url)
time.sleep(1)5、登录方式
(1)可以选择扫码,如果扫码登录就设置延时,
(2)可以选择输入账号密码,如下
前面的反扒可能失效,如果出现验证码,则需要设置延时,进行手动验证,因为验证码的形式经常变化。
# 点击非扫码登入
driver.find_element(
By.XPATH, "/html/body/div[1]/div[2]/div[2]/div/div[3]/img"
).click()
time.sleep(1)
# 点击密码登录
driver.find_element(
By.XPATH, "/html/body/div[1]/div[2]/div[2]/div/div[1]/div[1]/div[2]/a"
).click()
time.sleep(1)
# 输入账号密码
driver.find_element(
By.XPATH, "/html/body/div[1]/div[2]/div[2]/div/div[1]/div[3]/form/div[1]/input"
).send_keys(username)
driver.find_element(
By.XPATH, "/html/body/div[1]/div[2]/div[2]/div/div[1]/div[3]/form/div[2]/input"
).send_keys(password)
# 点击立即登录
driver.find_element(
By.XPATH, "/html/body/div[1]/div[2]/div[2]/div/div[1]/div[3]/form/div[4]/button"
).click()
time.sleep(20)6、获取公司对应的url进行写入excel
- 读取文件中的公司名称,在浏览器中搜索。
- 判断企查查中的公司名是否和文件中的一致,把对应的公司url写入excel文件
company_urls = []
for index, row in data.iterrows():
name = str(row["公司名称"]).strip()
print(f"公司名称:{name}")
if "公司" in name:
name = re.findall("^.*?公司", name)[0] # 正则只提取公司名称
if name == "nan" or not name:
company_urls.append("")
continue
try:
driver.get(
f"https://www.qcc.com/web/search?key={name}"
) # https://www.qcc.com/web/search?key={}
try:
d = driver.find_element(
By.XPATH,
"/html/body/div/div[2]/div[2]/div[3]/div/div[2]/div/table/tr[1]/td[3]/div/div[1]/span[1]/a",
)
txt = driver.find_element(
By.XPATH,
"/html/body/div/div[2]/div[2]/div[3]/div/div[2]/div/table/tr[1]/td[3]/div/div[1]/span[1]/a/span",
)
# 模糊查询,路径改为这个 /html/body/div/div[2]/div[2]/div[4]/div/div[2]/div/table/tr[1]/td[3]/div/div[1]/span[1]/a/span
url = d.get_attribute("href")
print(f"{txt.text}----->>>{url}")
if txt.text == name:
company_urls.append(url)
else:
# 判断爬取的名字和excel文件的公司名字是否一致。
company_urls.append("")
except NoSuchElementException:
# 没有找到名字相同的公司
company_urls.append("")
continue
time.sleep(2)
except:
company_urls.append("")
continue
data["url"] = company_urls
data.to_excel(path, index=None)7、获取对应字段的xpath路径
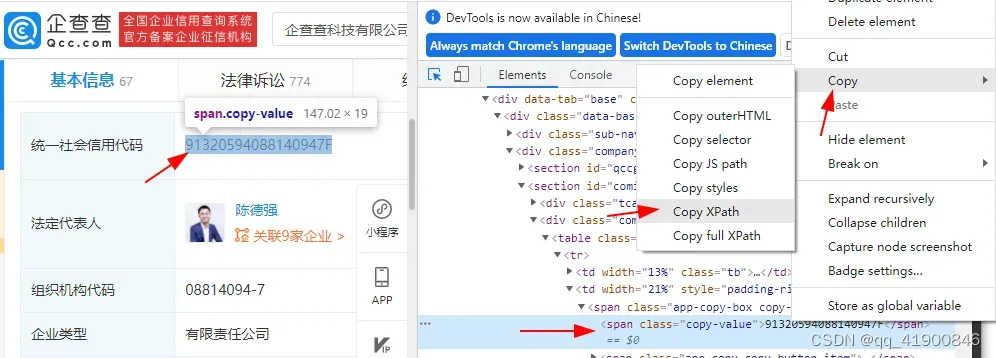
举例,社会信用 复制的xpath如下,
//*[@id="cominfo"]/div[2]/table/tr[1]/td[2]/span/span[1]8、通过公司url获取对应字段
for index, row in data.iterrows():
url = str(row["url"]).strip()
try:
driver.get(url) # https://www.qcc.com/web/search?key={}
try:
shehui_xinyong = driver.find_element(
By.XPATH,
'//*[@id="cominfo"]/div[2]/table/tr[1]/td[2]/div/span[1]'
).text
except:
shehui_xinyong = ""
except WebDriverException:
shehui_xinyong = ""
time.sleep(30)注意:
- 如果不设置延时就会被检测为频繁操作,有一段时间无法登录,可根据需求设置time.sleep
- 代码中的xpath,可能时常有变化,如果爬取的内容为nan,可能需要到页面中重新复制对应字段的xpath
完整代码和数据:企查查爬虫python版本2022年-Python文档类资源-CSDN下载
文章出处登录后可见!
已经登录?立即刷新