本文为博主原创文章,未经博主允许不得转载。
本文为专栏《Python从零开始进行AIGC大模型训练与推理》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。
Stable Diffusion webui的详细安装步骤以及文生图(txt2img)功能详细介绍请参考本专栏前一篇文章,本节将具体介绍 img2img、Extras、PNG Info、Checkpoint Merger、Train、Settings和Extensions等功能的详细使用方式。另外,本专栏具体更新可关注文章下方公众号,也可关注本专栏。所有相关文章会在《Python从零开始进行AIGC大模型训练与推理》中进行更新,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。所有AIGC类模型部署的体验效果将在RdFast小程序中同步上线。
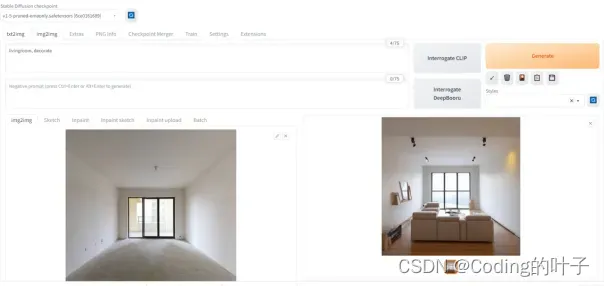
图1 img2img室内设计生成
1 Img2img
Img2img(图生图)是指在已有图片基础之上,通过Stable Diffusion进行修改,从而生成新的图片。如下图所示,img2img包括img2img、Sketch、Inpaint、Inpaint sketch、Inpaint upload和Batch等6个子页面。下面将分别介绍页面中各个参数的使用方式。
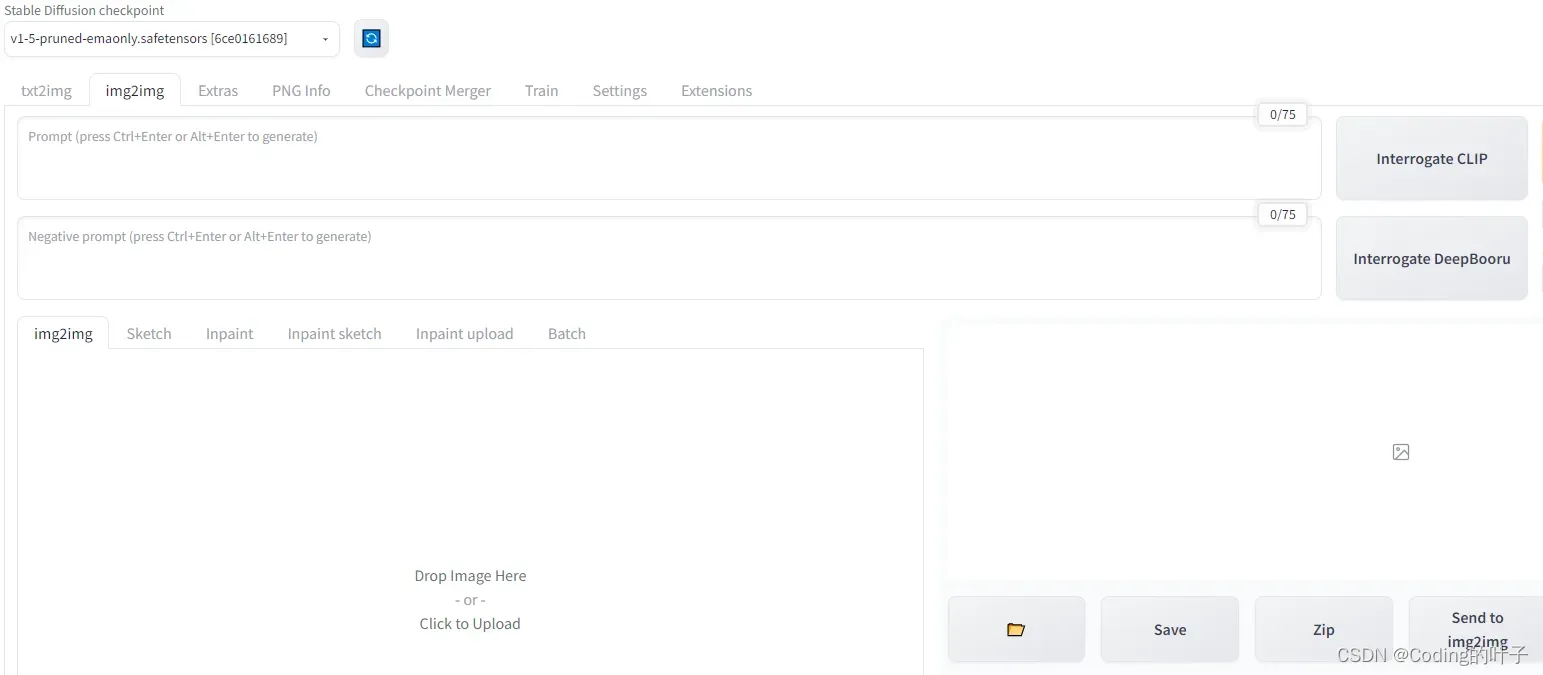
图2 img2img
1.1 img2img
正向提示词(Prompt)和反向提示词(Negative Prompt)与上一篇博文《AI图片生成Stable Diffusion参数及使用方式详细介绍》中的txt2img(文生图)的提示词用法与效果保持一致,地址为“https://blog.csdn.net/suiyingy/article/details/130008913”。
interrogate CLIP / interrogate DeepBooru:自动生成正向提示词,相当于是对现有图片的智能理解。可在自动生成的prompt基础上进行修改。
Resize mode:缩放模式。(1)Just resize 只调整图片大小,如果输入与输出长宽比例不同,图片会被拉伸。如果比例与原图不同,那么图片将会发生变形。(2)Crop and resize裁剪与调整大小,如果输入与输出长宽比例不同,会以图片中心向四周,将比例外的部分进行裁剪。这种模式属于等比例缩放,但是会将超出范围的部分进行裁剪。(3)Resize and fill 调整大小与填充,如果输入与输出分辨率不同,会以图片中心向四周,将比例内多余的部分进行填充。这种模式也属于等比例缩放,但是会将多余部分进行填充。
Denoising strength:重绘幅度,取值范围是0-1,默认设置0.75。取值越大,说明图片变化越大,0表示图片几乎不变,1表示可能严重偏离原图。一般将该参数设置在0.6~0.8范围。
其它参数与上一篇博文中txt2img的参数完全一致,详细说明请前往《AI图片生成Stable Diffusion参数及使用方式详细介绍》,地址为“https://blog.csdn.net/suiyingy/article/details/130008913”。
1.2 Sketch
Sketch是对整张图片进行调整,即对整张图进行重绘。Sketch英文原始意思是草图。这里如果我们输入一张手绘的草图,那么模型会基于草图重绘整个图片。
1.3 Inpaint
Inpaint是指局部重绘,即对指定区域进行修改。很多去水印的软件也以Inpaint作为命名或关键词。去水印也属于一种局部重绘,因而也可以在该功能页面中实现。
Mask blur:蒙版模糊度,值越大表示绘图区域与原图边缘的过度越平滑,越小则边缘越锐利。
Mask mode:蒙版模式,Inpaint masked表示只重绘涂色部分,Inpaint not masked表示重绘除了涂色的部分。涂色可通过在图片上长按并拖动鼠标左键来实现。涂色过程记为蒙版制作过程。
Masked Content:蒙版内容。fill表示用其他内容填充,original是在原来的基础上重绘,适合去水印模式。Latent noise和latent nothing是另外两种模式,主要是从模型中间过程来生成蒙版区域的图像。
Inpaint area:重绘区域,Whole picture表示重绘整个图像区域,Only masked表示只在蒙版区域内重绘。
Only masked padding, pixels:个人理解为蒙版区域向外围扩展的像素数量,相当于对模板区域进行了一定程度放大。
Denoising strength:重绘幅度,取值范围是0-1,默认设置0.75。取值越大,说明图片变化越大,0表示图片几乎不变,1表示可能严重偏离原图。一般将该参数设置在0.6~0.8范围。
下图是仅对地面进行重绘的示例。
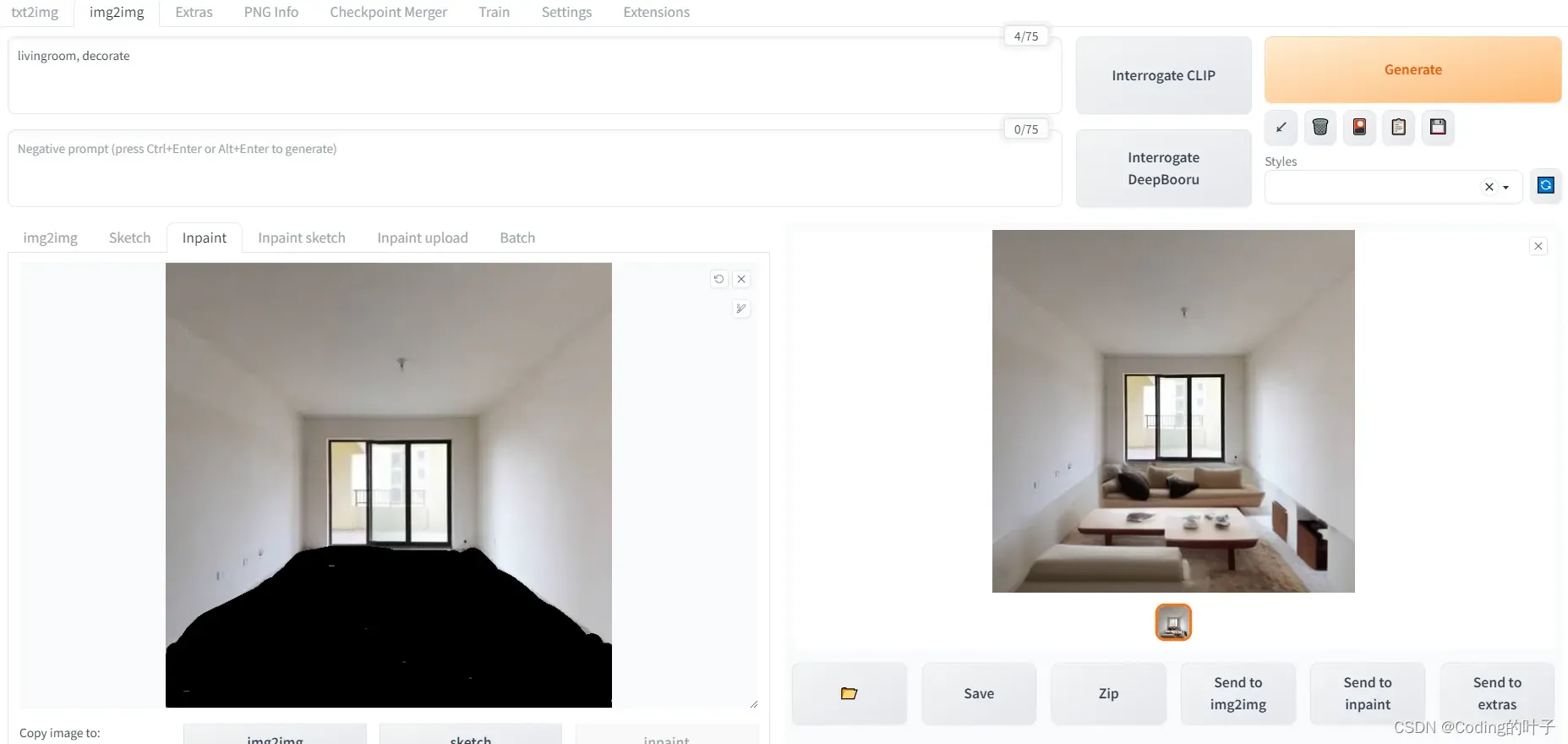
图3 Inpaint地面重绘
1.4 Inpaint Sketch
Sketch是结合输入完整图像进行重绘,而Inpaint Sketch主要是基于蒙版区域内的图像进行重绘。
1.5 Inpaint upload
这里仍然是Inpaint模式,蒙版不再是通过鼠标绘制,而是可上传一张蒙版图片。Crop to fit则相当于前面的Crop and resize。
1.6 Batch
指定输入和输出文件夹目录,批量进行img2img操作。
2 Extras
Extras主要是对图片大小进行调整,比如进行等比例高清放大。
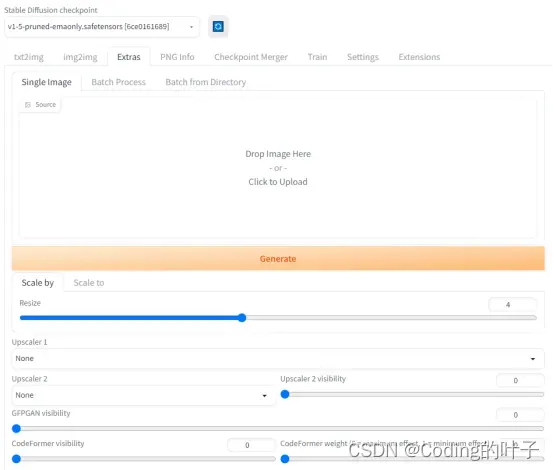
图4 Extras
Scale by:图片放大倍数,默认为4。放大倍数越大,分辨率尺寸越大,图片越清晰,所需时间也会相应有所增加。
Scale to:将图片尺寸调整为指定宽高,类似于前文的Resize mode。
Upscaler 1:上采样模型。默认为None,其中LDSR耗时长;ScuNET PSNR适用于动漫效果;SwinIR_4x效果较好。
Upscaler 2:上采样模型,默认为None,模型选项与Upscaler 1的一致。相当于可同时有两种模型来共同进行上采样,第二个模型的权重由Upscaler 2 visibility决定。
同样地,上采样模型还可以加入GFPGAN和CodeFormer,并可以设置其相应权重。Batch Process和Batch from Directory是用于多张图片的批量操作。
3 PNG info
PNG info用于查看Stable Diffusion所生成的图片的图像信息,包括提示词、反向提示词、步骤数、采样器、种子等参数。通常情况下,图片文件中含有图片说明的头文件,称为exif信息。该信息可通过图片工具或python等读取出来。Stable Diffusion会将图像生成相关的信息写入exif中。如果我们在网上看到比较感兴趣的Stable Diffusion生成图像,那么可以在PNG info中看到相关参数设置信息,从而复现或微调相应图片。
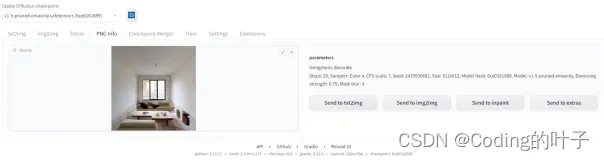
图5 PNG info
4 Checkpoint Merger
Checkpoint Merger是指模型合并不同的模型,生成新的模型。我们可能会根据基础模型微调得到不同生成风格的新模型。合并不同的微调模型可能能够同时获得两种模型的生成特点。合并完成之后,新的模型也会保存在models/Stable Diffusion文件目录下,并且可以在网页页面直接选择调用。
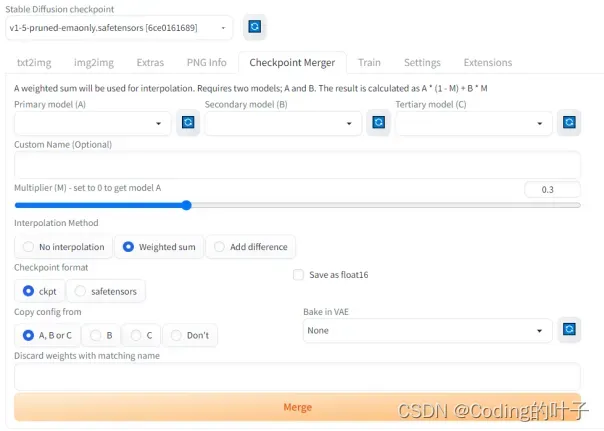
图6 Checkpoint Merger
Primary model (A)、Secondary model (B)、Tertiary model (C)用于选择将要合并的模型。需要注意,这些模型最好来自于同一类基础模型,具有相同的结构参数。如果模型结构不同,那么会出现参数不匹配的错误。
Custom Name (Optional):自定义合并后的模型名称。
Multiplier (M) – set to 0 to get model A:模型合并时,A模型所占权重比例。
Interpolation Method:三种模型合并方法。
(1)No interpolation:不进行模型合并,仅对模型A进行转换。它可实现模型类型格式转换(ckpt/safetensors)或者增加VAE(人脸修复等特定功能的编码优化算法)。
(2)Weighted sum,模型A和模型B合并,合并方式为 A * (1 – M) + B * M。
(3)Add difference,模型A与模型B、C之间的偏差进行合并,即A + (B – C) * M。
Checkpoint format:模型保存格式。Ckpt是以字典格式保存,可以存储额外的脚本信息。Safetensors则是纯粹保存tensors,不含额外的信息。因此,safetensors格式更加安全。
Save sa float16:保存为float16(FP16)精度的模型,可以降低模型显存占用。
Copy config from:复制模型的配置文件。
Bake in VAE:增加VAE(人脸修复等特定功能的编码优化算法)。
Discard weights with matching name:设置不参与合并的参数权重。
5 Train
Train用于自己训练或微调Stable Diffusion,以在某些特定领域达到更好的结果。这里不进行介绍,下一节将单独详细介绍Stable Diffusion的训练模式。
图7 Train
6 Settings
Settings设置内容较多,包括了上述各个功能的部分参数设置。例如,我们可以在Face restoration中选择面部修复所使用的模型。一般设置完成后需要先后分别点击“Apply settings”和“Reload Ul”按钮。
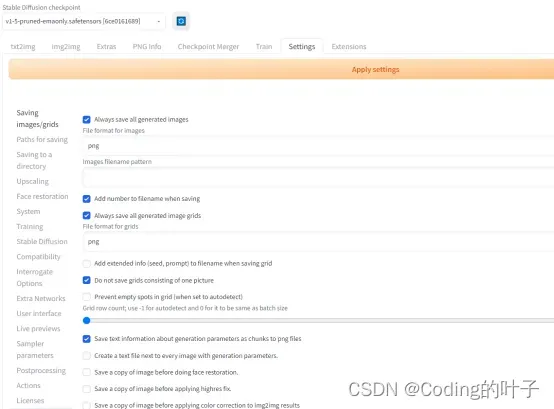
图8 Settings
7 Extensions
Extensions 是一些扩展功能,例如Lora或SwinIR等模型功能。扩展还可以通过Available设置一些额外的展示信息。
图9 Extensions
8 参考资料
(1)《Ai 绘图日常 篇四:Stable Diffusion WebUI中的重绘幅度在提升图片分辨率中的使用》,“https://post.smzdm.com/p/ao957kxr/”。
(2)《超详细!AI 绘画神器 Stable Diffusion 基础教程》,“https://www.uisdc.com/stable-diffusion-2”。
(3)《2023-03-22_5分钟学会Stable Diffusion图生图功能》,“https://zhuanlan.zhihu.com/p/616895208”。
(4)《Stable Diffusion功能介绍之Extras & PNG Info》,“https://scratchina.com/html/aihuihua/aihuihuajiaoxue/83.html”。
(5)《浅谈stable diffusion (三)》,“https://zhuanlan.zhihu.com/p/617026822”
(6)《有没有人能详细介绍一下Stable Diffusion AI绘画?》,“https://www.zhihu.com/question/585008573/answer/2953494275”
9 其它部分
本专栏具体更新可关注文章下方公众号,也可关注本专栏。所有相关文章会在《Python从零开始进行AIGC大模型训练与推理》中进行更新,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。所有AIGC类模型部署的体验效果将在RdFast小程序中同步上线。
本文为博主原创文章,未经博主允许不得转载。
本文为专栏《Python从零开始进行AIGC大模型训练与推理》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/130169592”。
文章出处登录后可见!