
link
本文主要是介绍了语音合成中最常见的数据集(包含各个语种),及其格式等
外语数据集
1.LJSpeech
网址 : The LJ Speech Dataset (keithito.com)
数据集描述:
数据集大小:2.6GB
这是一个公共领域的语音数据集,由 13,100 个简短的音频剪辑组成 一位演讲者阅读 7 本非小说类书籍的段落。为每个剪辑提供转录。 剪辑的长度从 1 到 10 秒不等,总长度约为 24小时。
LGSpeech文件格式
数据集描述:
元数据在成绩单.csv中提供。此文件由一条记录组成 每行,由竖线字符 (0x7c) 分隔。这些字段是:
ID:这是对应.wav文件的名称
转录:读者说出的单词 (UTF-8)
规范化转录:使用数字、序数和货币单位进行转录 扩展为完整单词 (UTF-8)。
每个音频文件都是一个单通道 16 位 PCM WAV,采样率为 22050 Hz。
总剪辑数 13,100
总字数 225,715
总字符数 1,308,678
总持续时间 23:55:17
平均剪辑持续时间 6.57 秒
最小剪辑持续时间 1.11 秒
最大剪辑持续时间 10.10 秒
每个剪辑的平均字数 17.23
不同的单词 13,821下载后文件压缩包 : LJSpeech-1.1.tar.bz2
linux解压命令
tar -jxvf LJSpeech-1.1.tar.bz2解压缩后,生成LJSpeech-1.1文件夹:.wav及csv文件
wavs格式如下
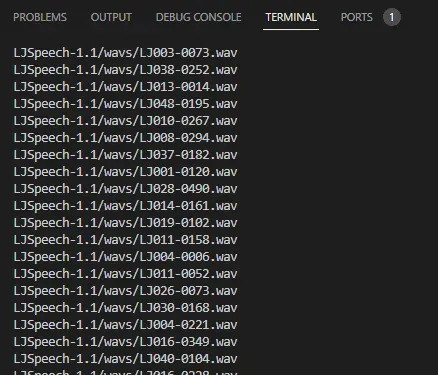
metadata格式如下(text文件)
2.JSUT
网址 :Shinnosuke Takamichi (高道 慎之介) – JSUT (google.com)
数据集描述:
数据集大小:2.7GB
该语料库由日语文本(转录)和阅读式音频组成。音频数据以48kHz采样并记录在消声室。录制了一位以日语为母语的女性的声音。此语料库包含 10 小时的语音,由以下数据组成:
基本5000 …涵盖所有日常使用字符(jouyou汉字)。
ut释义512 …将句子的一部分替换为其释义。
拟声词300 …包括日语的拟声词(拟声词)。
后缀26 …日语的反后缀
借词128 …日语的外来词(例如,ググる [“谷歌”作为动词])
声优100 …对声优语料库的副演讲(专业女性演讲者的免费语料库)
旅行1000 …旅行域语料库
先例130 …先例句
重复500 …重复口语(100句*5次)
3.RUSLAN
网址 :RUSLAN: Russian Spoken Language Corpus For Speech Synthesis
数据集描述:
RUSLAN 是用于文本到语音转换任务的俄语口语语料库。RUSLAN 包含 22,200 个带有文本注释的音频样本——一个人超过 31 小时的高质量演讲——就单个发言者的语音持续时间而言,是最大的带注释的俄语语料库之一。
4.RyanSpeech
网址 :Mohammad H. Mahoor, PhD
数据集描述:
RyanSpeech是用于研究自动文本到语音(TTS)系统的新语音语料库。公开可用的TTS语料库通常嘈杂,由多个说话者录制,或者没有高质量的男性语音数据。为了满足语音识别领域对高质量、公开可用的男性语音语料库的需求,我们设计并创建了 RyanSpeech。我们从现实世界的对话环境中衍生出RyanSpeech的文本材料,这些材料包含超过10个小时的专业男性配音演员的演讲,录制频率为44.1 kHz。这种语料库创建的设计和管道使RyanSpeech成为在实际应用中开发TTS系统的理想选择。为了为未来的研究、协议和基准提供基线,我们在 RyanSpeech 上训练了 4 个最先进的语音模型和一个声码器。结果显示,在我们的最佳模型中,平均意见得分(MOS)为3.36。我们已公开提供经过训练的模型以供下载。
5.VocBench
网址 :https://github.com/facebookresearch/vocoder-benchmark
数据集描述:
VocBench是一个为最先进的神经声码器的性能提供基准的框架。VocBench采用系统的研究方法,在一个共享的环境中评估不同的神经声码器,使它们之间能够进行公平的比较。
6.Arabic Speech Corpus
网址 :http://en.arabicspeechcorpus.com/
数据集描述:
数据集大小:1.5GB
该语音语料库是南安普敦大学Nawar Halabi博士工作的一部分。语料库是使用专业录音室用南黎凡特阿拉伯语(大马士革口音)录制的。使用此语料库合成语音作为输出,产生了高质量、自然的声音。
7.Silent Speech EMG
网址 :Silent Speech EMG | Zenodo
数据集描述:
无声和发声语音期间的面部肌电图记录。
这些数据在EMNLP 2020(https://arxiv.org/abs/2010.02960)的出版物“无声语音的数字发声”中进行了描述。
可以在 https://github.com/dgaddy/silent_speech 中找到用于处理此数据的代码。
每个数据样本有 5 个数据文件:{i}_emg.npy – 一个保存的大小为 (T, 8) 的 numpy 数组,带有原始 EMG 信号;{i}_audio.flac – 原始录音;{i}_audio_clean.flac – 降低背景噪音的音频;{i}_info.json – 包含额外信息的 JSON,例如读取的文本提示;{i}_button.npy – 包含设备按钮状态的 numpy 数组,通常未使用。请注意,某些样本并不代表实际数据点,而是用作参考肌电图或音频信号。这些示例在相关信息文件中标有“sentence_index:-1”。
https://arxiv.org/pdf/2010.02960.pdf
8.Hi-Fi Multi-Speaker English TTS Dataset
网址 :Hi-Fi Multi-Speaker English TTS Dataset
数据集描述:
该数据集是基于LibriVox的公共有声读物和古腾堡计划的文本。
Hi-Fi TTS数据集包含来自10个发言人的约291.6小时的语音,每个发言人至少有17小时的44.1kHz采样。
“Hi-Fi Multi-Speaker English TTS Dataset” Bakhturina, E., Lavrukhin, V., Ginsburg, B. and Zhang, Y., 2021: arxiv.org/abs/2104.01497.
9.kss
网址 :
数据集描述:
Korean Single speaker SpeechDataset
中文数据集
aidatatang_200zh
网址 :openslr.org
数据集描述:
数据集大小:aidatatang_200zh.tgz [18G]
北京数据堂科技有限公司的中文普通话语音语料库,包含来自 200 名说话者的 600 小时语音数据。每个句子的转录准确率大于 98%。属于演讲类别。
语料库的内容和相应的描述包括:
语料库包含200小时的声学数据,主要是移动记录的数据。
邀请了来自中国不同口音地区的600位演讲者参与录音。
每个句子的转录准确率大于 98%。
录音在安静的室内环境中进行。
数据库按7:1:2的比例分为训练集、验证集和测试集。
语音数据编码和说话人信息等详细信息保留在元数据文件中。
还提供了分段的成绩单。
该语料库旨在支持语音识别、机器翻译、声纹识别和其他语音相关领域的研究人员。因此,语料库完全免费供学术使用。
2.magicdata
网址 :openslr.org
数据集描述:
该语料库由Magic Data Technology Co., Ltd.提供,包含来自755名以中国大陆为母语的普通话母语人士的1080小时的脚本阅读语音数据。句子转录准确率高于98%。
train_set.tar.gz [52G] 训练集语音
dev_set.tar.gz [1.0G] 开发集语音
test_set.tar.gz [2.2G ] 测试集语音
metadata.tar.gz [3.8M] 补充材料信息
MAGICDATA普通话阅读语音语料库由MAGIC DATA开发 科技有限公司,并免费发布用于非商业用途。
语料库的内容和相应的描述包括:
语料库包含 755 小时的语音数据,即 主要是移动记录的数据。
来自中国不同口音地区的1080位发言者是 受邀参与录制。
句子转录准确率高于98%。
录音在安静的室内环境中进行。
数据库分为训练集、验证集和测试 以51:1:2的比例设置。
语音数据编码和说话人信息等详细信息是 保留在元数据文件中。
记录文本的领域是多样化的,包括交互式 问答、音乐搜索、SNS消息、家庭命令和控制等。
还提供了分段的成绩单。
该语料库旨在支持语音识别,机器方面的研究人员 翻译、说话人识别和其他语音相关领域。因此 语料库完全免费供学术使用。
3.aishell3
网址 :openslr.org
数据集描述:
data_aishell3.tgz [19G](语音数据和成绩单 )
AISHELL-3是一款大规模、高保真多说话人普通话语料库 由北京壳牌科技有限公司出版它可用于训练 多扬声器文本到语音转换 (TTS) 系统。语料库包含大约 85 小时 218 位以中文为母语的普通话使用者说的情感中立录音 总共 88035 条话语。他们的辅助属性,如性别、年龄组 本地口音在语料库中明确标记和提供。因此 提供汉字水平和拼音水平的成绩单以及 录音。单词和语气转录准确率在98%以上,通过 专业的语音注释和严格的音调和韵律质量检查。
4.biaobei
网址 :标贝数据集男声版 – 飞桨AI Studio (baidu.com)
数据集描述:
数据集只包含1万的wav文件,采样率为16K,关于语音对应的文本需通过其他途径获取。
5. MozillaCommonVoice
网址 :Common Voice (mozilla.org)
数据集描述:
包含很多语种。
6.data_aishell
网址 :openslr.org
数据集描述:
data_aishell.tgz [15G](语音数据和成绩单 )
resource_aishell.tgz [1.2M ]( 补充资源,包括词典、演讲者信息 )
Aishell是一个开源的中文普通话语料库,由 北京贝壳科技有限公司
邀请来自中国不同口音地区的400人参加 参与录音,在安静的室内进行 环境使用高保真麦克风并下采样至 16kHz。 人工抄录准确率95%以上,通过专业 语音标注和严格的质量检查。数据是免费的 供学术使用。我们希望为新的提供适量的数据 语音识别领域的研究人员。
文章出处登录后可见!