目前开源的多智能体强化学习项目都是需要在特定多智能体环境下交互运行,为了更好的学习MARL code,需要先大致了解一些常见的MARL环境以及库
文章目录
- 1.Farama Foundation
- 2.PettingZoo库
- 3.PySC2库
- 4.SMAC环境
1.Farama Foundation
Farama网站维护了来自github和各方实验室发布的各种开源强化学习工具,在里面可以找到很多强化学习环境,如多智能体PettingZoo等,还有一些开源项目,如MAgent2,Miniworld等。
(1)核心库
- Gymnasium:强化学习的标准 API,以及各种参考环境的集合
- PettingZoo:一个用于进行多智能体强化学习研究的Python库
- Minari:一个用于进行离线强化学习研究的 Python 库
(2)开源项目
- Minigrid:包含简单且易于配置的网格世界环境来进行强化学习研究,也就是gym-minigrid
- SuperSuit:Gymnasium 和 PettingZoo 环境的包装器集合(合并到 gymnasium.wrappers 和 pettingzoo.wrappers 中)
- Gymnasium-robotics:用于强化学习的机器人仿真环境集合
- MAgents:用于具有大量智能体的高性能多智能体环境的引擎,以及一组参考环境
- Miniworld:用于强化学习的简单且易于配置的 3D FPS 类游戏环境
- Tinyscaler:支持 SIMD 的小型快速图像缩放库
- AutoROM:为 Arcade 学习环境自动安装 Atari ROM 的工具
- Jumpy:Jax 和 NumPy 张量之间的即时转换
2.PettingZoo库
PettingZoo: Gym for Multi-Agent Reinforcement Learning
Terry, J., Black, B., Grammel, N., Jayakumar, M., Hari, A., Sullivan, R., … & Ravi, P. (2021). Pettingzoo: Gym for multi-agent reinforcement learning. Advances in Neural Information Processing Systems, 34, 15032-15043.
PettingZoo是一个用于进行多智能体强化学习研究的Python库,类似于 Gym的多智能体版本。包括以下几类环境:
- Atari(雅达利):多人 Atari 2600 游戏(合作、竞争和混合)
- Butterfly:作者开发的合作图形游戏,需要高度的配合
- Classic:一些经典游戏如纸牌游戏、桌游等
- MPE:一组简单的非图形交流任务,openAI开发
- SISL:3个合作环境
用法和Gym类似,首先重新创建一个虚拟环境,终端安装以下版本的库。本人亲测运行时总是出错,后来在一个单独环境里安装指定版本运行成功。
SuperSuit==3.6.0
torch==1.13.1
pettingzoo==1.22.3
初始化环境
from pettingzoo.butterfly import pistonball_v6
env = pistonball_v6.env()
测试运行
env.reset()
for agent in env.agent_iter():
obs, reward, termination, truncation, info = env.last()
action = None if termination or truncation else env.action_space(agent).sample()
env.step(action)
Process finished with exit code 0
比较常用的方法
agent_iter(max_iter=2**63):返回一个迭代器,该迭代器产生环境的当前智能体。当环境中的所有智能体都到达done状态或 max_iter(已执行步骤)时,训练终止。last(observe=True):返回当前能够采取行动的智能体的观察、奖励、done和信息。 返回的奖励是智能体自上次行动以来收到的累计奖励。 如果将 observe 设置为 False,则不会计算观察值,并返回 None 代替它。 完成单个智能体并不意味着环境已完成。reset():重置环境并将其设置为在第一次调用。step(action):采取并执行环境中智能体的动作,自动将控制权切换到下一个智能体
额外的环境API
agents:所有当前智能体的名称列表,通常是整数。 这些可能会随着环境的运行而改变(可以添加或删除智能头)。num_agents:agents list的长度。agent_selection:与当前选择的智能体相对应的环境属性,可以对其采取动作。observation_space(agent):检索特定智能体的观察空间的函数。 对于特定的智能体 ID,此空间永远不会更改。action_space(agent):检索特定智能体的动作空间的函数。 对于特定的智能体 ID,此空间永远不会更改。terminations:决策点时每个当前智能体的终止状态的字典,按名称键入。 last() 访问此属性。 可以从该字典中添加或删除智能体。 返回的字典如:terminations = {0:[first agent's termination state], 1:[second agent's termination state] ... n-1:[nth agent's termination state]}truncations:决策点时每个当前智能体的截断状态的字典,按名称键入。 last() 访问此属性。 可以从该字典中添加或删除智能体。 返回的字典如:truncations = {0:[first agent's truncation state], 1:[second agent's truncation state] ... n-1:[nth agent's truncation state]}infos:每个当前智能体的信息字典,按名称键入。 每个智能体的信息也是一个字典。可以从该属性中添加或删除智能体。 last() 访问此属性。 返回的字典如:infos = {0:[first agent's info], 1:[second agent's info] ... n-1:[nth agent's info]}observe(agent):返回智能体当前可以进行的观察。 last() 调用此函数。rewards:每个当前智能体在决策点时刻的奖励的字典,按名称键入。 为上一步动作后产生的瞬时奖励。 可以从该属性中添加或删除智能体。 last() 不直接访问此属性,而是将返回的奖励存储在内部变量中。 奖励结构如下:{0:[first agent's reward], 1:[second agent's reward] ... n-1:[nth agent's reward]}
官方案例:PPO on the Pistonball env
3.PySC2库
PySC2是DeepMind的星际争霸II学习环境 (SC2LE) 的Python组件。它将暴雪娱乐的星际争霸II(StarCraft II )机器学习API公开为Python RL环境。 这是DeepMind和暴雪之间的合作,旨在将星际争霸II开发为供RL研究的丰富环境。PySC2为RL智能体提供了一个与星际争霸2交互的接口,能够获取观察结果并发送动作。
4.SMAC环境
SMAC是WhiRL(牛津大学AI实验室)用于在合作多智能体强化学习领域的实验环境,基于StarCraft II RTS(星际争霸)游戏。SMAC使用StarCraft II API接口和DeepMind的PySC2为自治智能体提供与星际争霸 II 的交互界面,方便获取观察结果并执行操作。和PySC2不同的是,SMAC专注于分散的微观管理场景,其中游戏的每个单元都由单独的 RL 智能体控制。基于SMAC,该团队发布了PyMARL,用于MARL实验的pytorch框架,包括很多种算法如QMIX,COMA,VDN,IQL,QTRAN。之后在PyMARL基础上扩展发布了EPyMARL,又实现了很多其它算法IA2C, IPPO, MADDPG, MAA2C,MAPPO,功能更为丰富。
【SMAC介绍文档】
在星际争霸 II 中,一个或多个人相互竞争或与内置游戏 AI 竞争,以收集资源、建造建筑物和组建军队以击败对手。与大多数 RTS(即时战略游戏) 类似,星际争霸有两个主要的游戏组件:宏观管理和微观管理。
- 宏观管理(macro)是指高层次的战略考虑,例如经济和资源管理
- 微观管理(micro)是指对个体单位进行细粒度的控制
(1)游戏场景
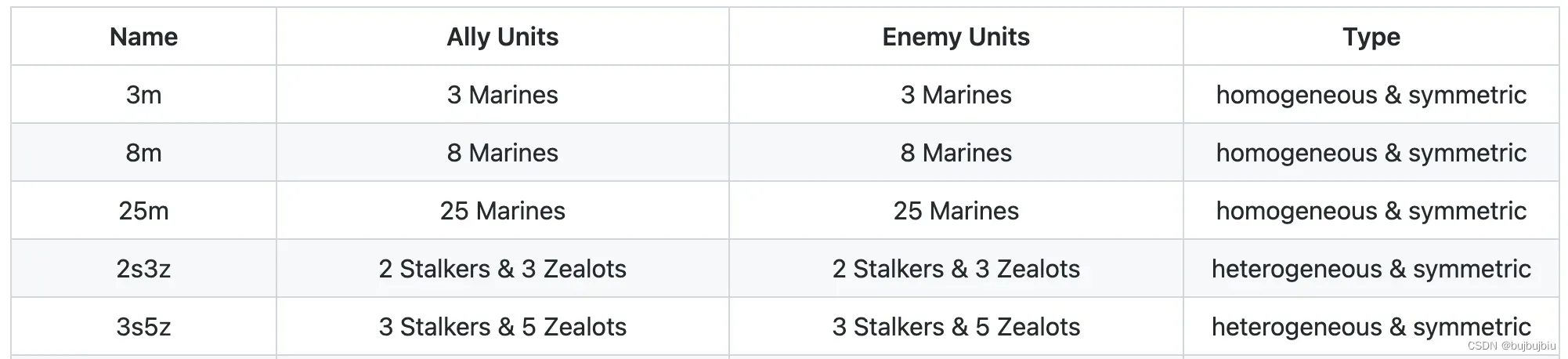
SMAC包括一系列StarCraft II微观场景,用于评价独立智能体如何能协同学习解决复杂问题。这些场景经过精心设计,需要学习一种或多种微观管理技术来击败敌人。 每个场景都是两支军队之间的对抗。 每支军队的初始位置、数量和单位类型因场景而异。
第一支军对由学习的联合智能体控制, 第二支军队由内置游戏 AI 控制的敌方单位组成,该 AI 使用精心设计的非学习启发式算法。 在每个episode的开始,游戏 AI 会指示其单位使用其脚本策略攻击联合智能体军队。 当任一军队的所有单位都死亡或达到预先指定的时间限制时,episode结束(在这种情况下,游戏被视为联合智能体的失败)。 每个场景的目标是最大化学习策略的获胜率,即获胜游戏与玩游戏的预期比率。具体的围观场景设置可见官方介绍,下面是一些场景的例子
(2)状态和观测值
每个智能体只能接受局部信息,也就是地图上其视线范围为半径的周围圆形区域。每个智能体观察到的特征向量包含视线范围内友军和敌方的以下属性:distance, relative x, relative y, health, shield, and unit_type
(3)动作空间
每个智能体的离散动作包括:move[direction](四个方向移动:东南西北),attack[enemy_id](攻击敌人),stop(停止),no-op,只有死亡的智能体能执行no-op
(4)奖励函数
稀疏奖励:胜利+1或失败-1
塑形奖励:比如杀死一个敌人获得奖励
安装SMAC环境需要三个部分,具体见SMAC
- 安装SMAC :
pip install git+https://github.com/oxwhirl/smac.git - 安装StarCraft II:官网下载
- 安装SMAC地图:SMAC Maps
文章出处登录后可见!