论文地址:https://arxiv.org/pdf/2201.01293.pdf
项目代码:https://github.com/wgcban/ChangeFormer
发表时间:2022

本文提出了一种基于transformer的siamese网络架构(ChangeFormer),用于一对共配准遥感图像的变化检测(CD)。与最近基于完全卷积网络(ConvNets)的CD框架不同,该方法将分层结构的transformer编码器与多层感知(MLP)解码器统一在siamese网络体系结构中,以有效地呈现精确CD所需的多尺度远程细节。在两个CD数据集上的实验表明,所提出的端到端可训练的结构比以前的结构具有更好的CD性能。
基本解读
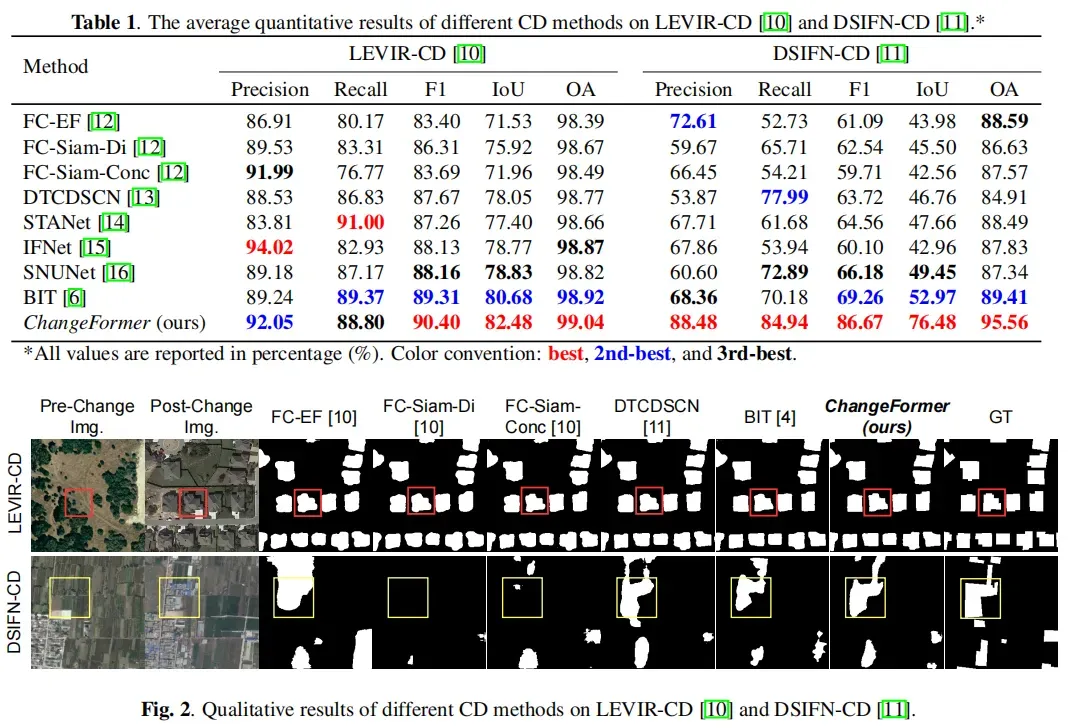
- 1、本文实验中STANet居然没有FC-EF、FC-Siam-Di、FC-Siam-Conc强。这很有可能是backbone性能差异导致的(其所使用的pspnet明显是古董网络)
- 2、非多尺度特征方法(FC*,STANet*)在DSIFN-CD数据集上性能下降明显,在DSIFN-CD上明显是需要大尺度的低级语义才能做判断;(在LEVIR-CD上每一个变化区域都是一个实例[建筑],而在DSIFN-CD上一个变化区域对应着多个变化实例[建筑],依赖高层语义会使区域所对应的特征发生弥散,从而使区域判断不准)
- 3、ChangeFormer的强大主要体现在DSIFN-CD数据集上,很有可能是其他模型没有针对该数据集优化(如STANET只使用随机翻转和随机旋转进行训练,而ChangeFormer使用了色彩抖动 | 此外DSIFN-CD数据集的使用比例不合理)
- 4、除ChangeFormer外的大部分模型在DSIFN-CD上都掉点严重,除DSIFN-CD数据集划分不合理外,或许还有一部分原因是segformer泛化能力强
1、技术背景
目前基于transformer的CD研究较少,现有的CD模型都是基于conv所实现的,为了在变化检测中提取时间和空间的长期依赖,他们提出了卷积层的堆叠、孔洞卷积、attenttion机制。尽管注意力在捕捉全局细节上是有效的,但是无法在时空上将远程细节联系起来。
2、方法与代码
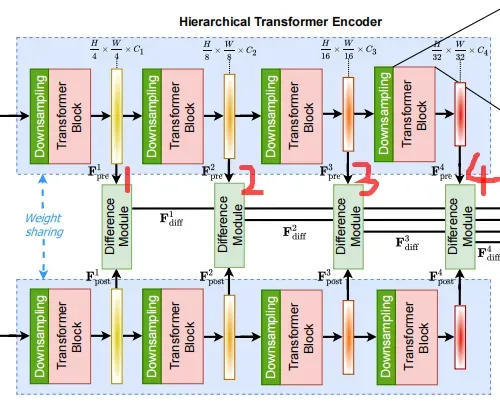
提出ChangeFormer由三个主要模块如图1所示:孪生的transformer编码器网络提取双时间图像的粗糙特征,四个特征差异模块计算特征差异,和一个轻量级MLP解码器融合这些多级特征差异和预测CD掩模。
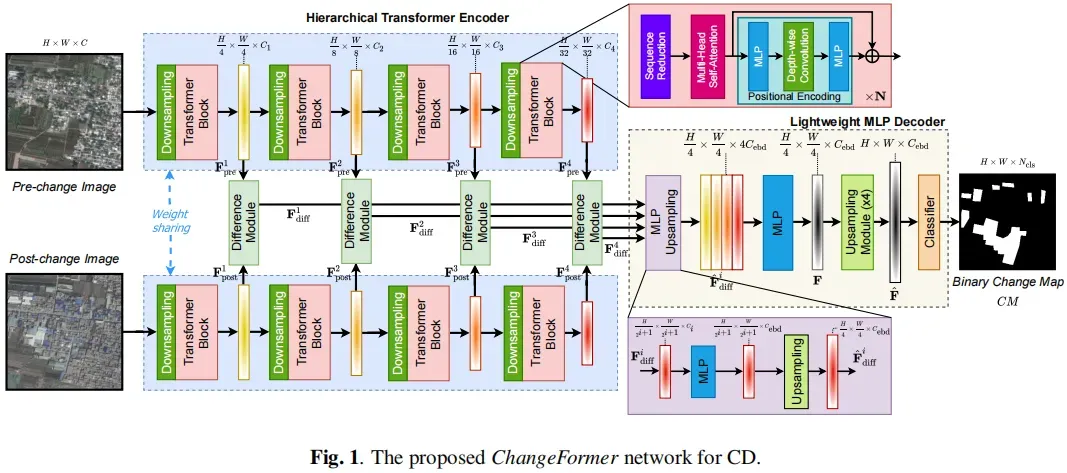
实现代码如下,可见为一个Encoder贡献的孪生网络。完整代码在https://gitee.com/Geoyee/PaddleRS/blob/develop/paddlers/rs_models/cd/changeformer.py
class ChangeFormer(nn.Layer):
def __init__(self,
in_channels,
num_classes,
decoder_softmax=False,
embed_dim=256):
super(ChangeFormer, self).__init__()
# Transformer Encoder
self.embed_dims = [64, 128, 320, 512]
self.depths = [3, 3, 4, 3]
self.embedding_dim = embed_dim
self.drop_rate = 0.1
self.attn_drop = 0.1
self.drop_path_rate = 0.1
self.Tenc_x2 = EncoderTransformer_v3(
img_size=256,
patch_size=7,
in_chans=in_channels,
num_classes=num_classes,
embed_dims=self.embed_dims,
num_heads=[1, 2, 4, 8],
mlp_ratios=[4, 4, 4, 4],
qkv_bias=True,
qk_scale=None,
drop_rate=self.drop_rate,
attn_drop_rate=self.attn_drop,
drop_path_rate=self.drop_path_rate,
norm_layer=partial(
nn.LayerNorm, epsilon=1e-6),
depths=self.depths,
sr_ratios=[8, 4, 2, 1])
# Transformer Decoder
self.TDec_x2 = DecoderTransformer_v3(
input_transform='multiple_select',
in_index=[0, 1, 2, 3],
align_corners=False,
in_channels=self.embed_dims,
embedding_dim=self.embedding_dim,
output_nc=num_classes,
decoder_softmax=decoder_softmax,
feature_strides=[2, 4, 8, 16])
def forward(self, x1, x2):
[fx1, fx2] = [self.Tenc_x2(x1), self.Tenc_x2(x2)]
cp = self.TDec_x2(fx1, fx2)
return [cp]
2.1 Transformer Encoder
Transformer Encoder具有CD所需的高分辨率粗特征和低分辨率细粒度特征,共有(4、8、16、32)四种下采样尺度的特征图输出,具体如下图所示。
主体代码如下所示, 与segformer的encoder是基本一致的
class EncoderTransformer_v3(nn.Layer):
def __init__(self,
img_size=256,
patch_size=3,
in_chans=3,
num_classes=2,
embed_dims=[32, 64, 128, 256],
num_heads=[2, 2, 4, 8],
mlp_ratios=[4, 4, 4, 4],
qkv_bias=True,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
norm_layer=nn.LayerNorm,
depths=[3, 3, 6, 18],
sr_ratios=[8, 4, 2, 1]):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.embed_dims = embed_dims
# Patch embedding definitions
self.patch_embed1 = OverlapPatchEmbed(
img_size=img_size,
patch_size=7,
stride=4,
in_chans=in_chans,
embed_dim=embed_dims[0])
self.patch_embed2 = OverlapPatchEmbed(
img_size=img_size // 4,
patch_size=patch_size,
stride=2,
in_chans=embed_dims[0],
embed_dim=embed_dims[1])
self.patch_embed3 = OverlapPatchEmbed(
img_size=img_size // 8,
patch_size=patch_size,
stride=2,
in_chans=embed_dims[1],
embed_dim=embed_dims[2])
self.patch_embed4 = OverlapPatchEmbed(
img_size=img_size // 16,
patch_size=patch_size,
stride=2,
in_chans=embed_dims[2],
embed_dim=embed_dims[3])
# Stage-1 (x1/4 scale)
dpr = [x.item() for x in pd.linspace(0, drop_path_rate, sum(depths))]
cur = 0
self.block1 = nn.LayerList([
Block(
dim=embed_dims[0],
num_heads=num_heads[0],
mlp_ratio=mlp_ratios[0],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[cur + i],
norm_layer=norm_layer,
sr_ratio=sr_ratios[0]) for i in range(depths[0])
])
self.norm1 = norm_layer(embed_dims[0])
# Stage-2 (x1/8 scale)
cur += depths[0]
self.block2 = nn.LayerList([
Block(
dim=embed_dims[1],
num_heads=num_heads[1],
mlp_ratio=mlp_ratios[1],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[cur + i],
norm_layer=norm_layer,
sr_ratio=sr_ratios[1]) for i in range(depths[1])
])
self.norm2 = norm_layer(embed_dims[1])
# Stage-3 (x1/16 scale)
cur += depths[1]
self.block3 = nn.LayerList([
Block(
dim=embed_dims[2],
num_heads=num_heads[2],
mlp_ratio=mlp_ratios[2],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[cur + i],
norm_layer=norm_layer,
sr_ratio=sr_ratios[2]) for i in range(depths[2])
])
self.norm3 = norm_layer(embed_dims[2])
# Stage-4 (x1/32 scale)
cur += depths[2]
self.block4 = nn.LayerList([
Block(
dim=embed_dims[3],
num_heads=num_heads[3],
mlp_ratio=mlp_ratios[3],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[cur + i],
norm_layer=norm_layer,
sr_ratio=sr_ratios[3]) for i in range(depths[3])
])
self.norm4 = norm_layer(embed_dims[3])
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_op = nn.initializer.TruncatedNormal(std=.02)
trunc_normal_op(m.weight)
if isinstance(m, nn.Linear) and m.bias is not None:
init_bias = nn.initializer.Constant(0)
init_bias(m.bias)
elif isinstance(m, nn.LayerNorm):
init_bias = nn.initializer.Constant(0)
init_bias(m.bias)
init_weight = nn.initializer.Constant(1.0)
init_weight(m.weight)
elif isinstance(m, nn.Conv2D):
fan_out = m._kernel_size[0] * m._kernel_size[1] * m._out_channels
fan_out //= m._groups
init_weight = nn.initializer.Normal(0, math.sqrt(2.0 / fan_out))
init_weight(m.weight)
if m.bias is not None:
init_bias = nn.initializer.Constant(0)
init_bias(m.bias)
def reset_drop_path(self, drop_path_rate):
dpr = [
x.item() for x in pd.linspace(0, drop_path_rate, sum(self.depths))
]
cur = 0
for i in range(self.depths[0]):
self.block1[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[0]
for i in range(self.depths[1]):
self.block2[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[1]
for i in range(self.depths[2]):
self.block3[i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[2]
for i in range(self.depths[3]):
self.block4[i].drop_path.drop_prob = dpr[cur + i]
def forward_features(self, x):
B = x.shape[0]
outs = []
# Stage 1
x1, H1, W1 = self.patch_embed1(x)
for i, blk in enumerate(self.block1):
x1 = blk(x1, H1, W1)
x1 = self.norm1(x1)
x1 = x1.reshape(
[B, H1, W1, calc_product(*x1.shape[1:]) // (H1 * W1)]).transpose(
[0, 3, 1, 2])
outs.append(x1)
# Stage 2
x1, H1, W1 = self.patch_embed2(x1)
for i, blk in enumerate(self.block2):
x1 = blk(x1, H1, W1)
x1 = self.norm2(x1)
x1 = x1.reshape(
[B, H1, W1, calc_product(*x1.shape[1:]) // (H1 * W1)]).transpose(
[0, 3, 1, 2])
outs.append(x1)
# Stage 3
x1, H1, W1 = self.patch_embed3(x1)
for i, blk in enumerate(self.block3):
x1 = blk(x1, H1, W1)
x1 = self.norm3(x1)
x1 = x1.reshape(
[B, H1, W1, calc_product(*x1.shape[1:]) // (H1 * W1)]).transpose(
[0, 3, 1, 2])
outs.append(x1)
# Stage 4
x1, H1, W1 = self.patch_embed4(x1)
for i, blk in enumerate(self.block4):
x1 = blk(x1, H1, W1)
x1 = self.norm4(x1)
x1 = x1.reshape(
[B, H1, W1, calc_product(*x1.shape[1:]) // (H1 * W1)]).transpose(
[0, 3, 1, 2])
outs.append(x1)
return outs
def forward(self, x):
x = self.forward_features(x)
return x
Transformer Block设计
原始的self-attention定义如下,其计算复杂度为,在分辨率越大的情况下,所需内存更大,无法推广大高分影像中。

class Block(nn.Layer):
def __init__(self,
dim,
num_heads,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop=0.,
attn_drop=0.,
drop_path=0.,
act_layer=nn.GELU,
norm_layer=nn.LayerNorm,
sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
proj_drop=drop,
sr_ratio=sr_ratio)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity(
)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
为了减少计算复杂度,对QK的输入进行压缩,压缩过程中保持C不变,使下一步的attention map变为,V的size变为
,则相应的计算复杂度也被缩小了R倍。
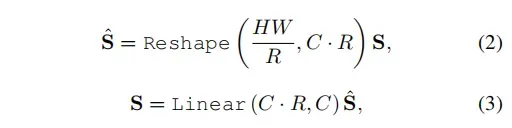
class Attention(nn.Layer):
def __init__(self,
dim,
num_heads=8,
qkv_bias=False,
qk_scale=None,
attn_drop=0.,
proj_drop=0.,
sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.q = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2D(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
self.apply(self._init_weights)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape([B, N, self.num_heads,
C // self.num_heads]).transpose([0, 2, 1, 3])
if self.sr_ratio > 1:
x_ = x.transpose([0, 2, 1]).reshape([B, C, H, W])
x_ = self.sr(x_)
x_ = x_.reshape([B, C, calc_product(*x_.shape[2:])]).transpose(
[0, 2, 1])
x_ = self.norm(x_)
kv = self.kv(x_)
kv = kv.reshape([
B, calc_product(*kv.shape[1:]) // (2 * C), 2, self.num_heads,
C // self.num_heads
]).transpose([2, 0, 3, 1, 4])
else:
kv = self.kv(x)
kv = kv.reshape([
B, calc_product(*kv.shape[1:]) // (2 * C), 2, self.num_heads,
C // self.num_heads
]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @v).transpose([0, 2, 1, 3]).reshape([B, N, C])
x = self.proj(x)
x = self.proj_drop(x)
return x
为了提供transformer的位置信息,我们使用了两个MLP层和一个3×3的深度卷积如下:
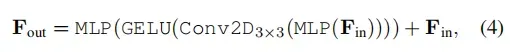
class Mlp(nn.Layer):
def __init__(self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def forward(self, x, H, W):
x = self.fc1(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
Downsampling Block
使用conv2D进行下采样,第一个下采样block的ksize为7×7,padding=3,stride为4(进行4倍下采样);其余下采样block的ksize为3×3,padding=1,stride为2(进行2倍下采样)。
其本质是PatchEmbed,只是在进行特征编码的时候同时进行了下采样,具体代码如下
class OverlapPatchEmbed(nn.Layer):
"""
Image to Patch Embedding
"""
def __init__(self,
img_size=224,
patch_size=7,
stride=4,
in_chans=3,
embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.H, self.W = img_size[0] // patch_size[0], img_size[
1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2D(
in_chans,
embed_dim,
kernel_size=patch_size,
stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
self.norm = nn.LayerNorm(embed_dim)
self.apply(self._init_weights)
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose([0, 2, 1])
x = self.norm(x)
return x, H, W
Difference Module
这是与原始segformer论文中不一样的部分(新增),其实也就是一个CRB模块,希望能在训练过程中学习到每个尺度下的最优距离度量(以往都是使用绝对差值)。
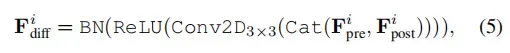
在使用代码中,为了更好的复用(使用segformer的部分),Difference Module并未出现在encoder中,而是将Difference Module需要的输入都进行了输出。然后在Decoder中实现了Difference Module。其在Decoder中对应的实现部分如下:
# Difference Layer
def conv_diff(in_channels, out_channels):
return nn.Sequential(
nn.Conv2D(
in_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.BatchNorm2D(out_channels),
nn.Conv2D(
out_channels, out_channels, kernel_size=3, padding=1),
nn.ReLU())
#---------------------------------------------
# MLP decoder heads
self.linear_c4 = MLP(input_dim=c4_in_channels,
embed_dim=self.embedding_dim)
self.linear_c3 = MLP(input_dim=c3_in_channels,
embed_dim=self.embedding_dim)
self.linear_c2 = MLP(input_dim=c2_in_channels,
embed_dim=self.embedding_dim)
self.linear_c1 = MLP(input_dim=c1_in_channels,
embed_dim=self.embedding_dim)
# Convolutional Difference Layers
self.diff_c4 = conv_diff(
in_channels=2 * self.embedding_dim, out_channels=self.embedding_dim)
self.diff_c3 = conv_diff(
in_channels=2 * self.embedding_dim, out_channels=self.embedding_dim)
self.diff_c2 = conv_diff(
in_channels=2 * self.embedding_dim, out_channels=self.embedding_dim)
self.diff_c1 = conv_diff(
in_channels=2 * self.embedding_dim, out_channels=self.embedding_dim)
所对应的forword代码如下:
x_1 = self._transform_inputs(inputs1) # len=4, 1/2, 1/4, 1/8, 1/16
x_2 = self._transform_inputs(inputs2) # len=4, 1/2, 1/4, 1/8, 1/16
# img1 and img2 features
c1_1, c2_1, c3_1, c4_1 = x_1
c1_2, c2_2, c3_2, c4_2 = x_2
############## MLP decoder on C1-C4 ###########
n, _, h, w = c4_1.shape
outputs = []
# Stage 4: x1/32 scale
_c4_1 = self.linear_c4(c4_1).transpose([0, 2, 1])
_c4_1 = _c4_1.reshape([
n, calc_product(*_c4_1.shape[1:]) //
(c4_1.shape[2] * c4_1.shape[3]), c4_1.shape[2], c4_1.shape[3]
])
_c4_2 = self.linear_c4(c4_2).transpose([0, 2, 1])
_c4_2 = _c4_2.reshape([
n, calc_product(*_c4_2.shape[1:]) //
(c4_2.shape[2] * c4_2.shape[3]), c4_2.shape[2], c4_2.shape[3]
])
_c4 = self.diff_c4(pd.concat((_c4_1, _c4_2), axis=1))
p_c4 = self.make_pred_c4(_c4)
outputs.append(p_c4)
_c4_up = resize(
_c4, size=c1_2.shape[2:], mode='bilinear', align_corners=False)
# Stage 3: x1/16 scale
_c3_1 = self.linear_c3(c3_1).transpose([0, 2, 1])
_c3_1 = _c3_1.reshape([
n, calc_product(*_c3_1.shape[1:]) //
(c3_1.shape[2] * c3_1.shape[3]), c3_1.shape[2], c3_1.shape[3]
])
_c3_2 = self.linear_c3(c3_2).transpose([0, 2, 1])
_c3_2 = _c3_2.reshape([
n, calc_product(*_c3_2.shape[1:]) //
(c3_2.shape[2] * c3_2.shape[3]), c3_2.shape[2], c3_2.shape[3]
])
_c3 = self.diff_c3(pd.concat((_c3_1, _c3_2), axis=1)) + \
F.interpolate(_c4, scale_factor=2, mode="bilinear")
p_c3 = self.make_pred_c3(_c3)
outputs.append(p_c3)
_c3_up = resize(
_c3, size=c1_2.shape[2:], mode='bilinear', align_corners=False)
# Stage 2: x1/8 scale
_c2_1 = self.linear_c2(c2_1).transpose([0, 2, 1])
_c2_1 = _c2_1.reshape([
n, calc_product(*_c2_1.shape[1:]) //
(c2_1.shape[2] * c2_1.shape[3]), c2_1.shape[2], c2_1.shape[3]
])
_c2_2 = self.linear_c2(c2_2).transpose([0, 2, 1])
_c2_2 = _c2_2.reshape([
n, calc_product(*_c2_2.shape[1:]) //
(c2_2.shape[2] * c2_2.shape[3]), c2_2.shape[2], c2_2.shape[3]
])
_c2 = self.diff_c2(pd.concat((_c2_1, _c2_2), axis=1)) + \
F.interpolate(_c3, scale_factor=2, mode="bilinear")
p_c2 = self.make_pred_c2(_c2)
outputs.append(p_c2)
_c2_up = resize(
_c2, size=c1_2.shape[2:], mode='bilinear', align_corners=False)
# Stage 1: x1/4 scale
_c1_1 = self.linear_c1(c1_1).transpose([0, 2, 1])
_c1_1 = _c1_1.reshape([
n, calc_product(*_c1_1.shape[1:]) //
(c1_1.shape[2] * c1_1.shape[3]), c1_1.shape[2], c1_1.shape[3]
])
_c1_2 = self.linear_c1(c1_2).transpose([0, 2, 1])
_c1_2 = _c1_2.reshape([
n, calc_product(*_c1_2.shape[1:]) //
(c1_2.shape[2] * c1_2.shape[3]), c1_2.shape[2], c1_2.shape[3]
])
_c1 = self.diff_c1(pd.concat((_c1_1, _c1_2), axis=1)) + \
F.interpolate(_c2, scale_factor=2, mode="bilinear")
2.2 MLP Decoder
采用语义分割的思路,由MLP充当解码器来预测差异图(变化区域)。
完整实现代码如下,可见其仅使用了融合后的diff 图来做预测和训练,并未使用中间diff 图的预测结果做训练。
class DecoderTransformer_v3(nn.Layer):
"""
Transformer Decoder
"""
def __init__(self,
input_transform='multiple_select',
in_index=[0, 1, 2, 3],
align_corners=True,
in_channels=[32, 64, 128, 256],
embedding_dim=64,
output_nc=2,
decoder_softmax=False,
feature_strides=[2, 4, 8, 16]):
super(DecoderTransformer_v3, self).__init__()
assert len(feature_strides) == len(in_channels)
assert min(feature_strides) == feature_strides[0]
# Settings
self.feature_strides = feature_strides
self.input_transform = input_transform
self.in_index = in_index
self.align_corners = align_corners
self.in_channels = in_channels
self.embedding_dim = embedding_dim
self.output_nc = output_nc
c1_in_channels, c2_in_channels, c3_in_channels, c4_in_channels = self.in_channels
# MLP decoder heads
self.linear_c4 = MLP(input_dim=c4_in_channels,
embed_dim=self.embedding_dim)
self.linear_c3 = MLP(input_dim=c3_in_channels,
embed_dim=self.embedding_dim)
self.linear_c2 = MLP(input_dim=c2_in_channels,
embed_dim=self.embedding_dim)
self.linear_c1 = MLP(input_dim=c1_in_channels,
embed_dim=self.embedding_dim)
# Convolutional Difference Layers
self.diff_c4 = conv_diff(
in_channels=2 * self.embedding_dim, out_channels=self.embedding_dim)
self.diff_c3 = conv_diff(
in_channels=2 * self.embedding_dim, out_channels=self.embedding_dim)
self.diff_c2 = conv_diff(
in_channels=2 * self.embedding_dim, out_channels=self.embedding_dim)
self.diff_c1 = conv_diff(
in_channels=2 * self.embedding_dim, out_channels=self.embedding_dim)
# Take outputs from middle of the encoder
self.make_pred_c4 = make_prediction(
in_channels=self.embedding_dim, out_channels=self.output_nc)
self.make_pred_c3 = make_prediction(
in_channels=self.embedding_dim, out_channels=self.output_nc)
self.make_pred_c2 = make_prediction(
in_channels=self.embedding_dim, out_channels=self.output_nc)
self.make_pred_c1 = make_prediction(
in_channels=self.embedding_dim, out_channels=self.output_nc)
# Final linear fusion layer
self.linear_fuse = nn.Sequential(
nn.Conv2D(
in_channels=self.embedding_dim * len(in_channels),
out_channels=self.embedding_dim,
kernel_size=1),
nn.BatchNorm2D(self.embedding_dim))
# Final predction head
self.convd2x = UpsampleConvLayer(
self.embedding_dim, self.embedding_dim, kernel_size=4, stride=2)
self.dense_2x = nn.Sequential(ResidualBlock(self.embedding_dim))
self.convd1x = UpsampleConvLayer(
self.embedding_dim, self.embedding_dim, kernel_size=4, stride=2)
self.dense_1x = nn.Sequential(ResidualBlock(self.embedding_dim))
self.change_probability = ConvLayer(
self.embedding_dim,
self.output_nc,
kernel_size=3,
stride=1,
padding=1)
# Final activation
self.output_softmax = decoder_softmax
self.active = nn.Sigmoid()
def _transform_inputs(self, inputs):
"""
Transform inputs for decoder.
Args:
inputs (list[Tensor]): List of multi-level img features.
Returns:
Tensor: The transformed inputs
"""
if self.input_transform == 'resize_concat':
inputs = [inputs[i] for i in self.in_index]
upsampled_inputs = [
resize(
input=x,
size=inputs[0].shape[2:],
mode='bilinear',
align_corners=self.align_corners) for x in inputs
]
inputs = pd.concat(upsampled_inputs, dim=1)
elif self.input_transform == 'multiple_select':
inputs = [inputs[i] for i in self.in_index]
else:
inputs = inputs[self.in_index]
return inputs
def forward(self, inputs1, inputs2):
# Transforming encoder features (select layers)
#
#---Difference Module forword-----
#
# Linear Fusion of difference image from all scales
outputs =Difference Module forword() 包含了4个尺度下的变化预测结果
_c4_up, _c3_up, _c2_up, _c1 为4个尺度下的变化检测距离图
_c = self.linear_fuse(pd.concat((_c4_up, _c3_up, _c2_up, _c1), axis=1))
# Upsampling x2 (x1/2 scale)
x = self.convd2x(_c)
# Residual block
x = self.dense_2x(x)
# Upsampling x2 (x1 scale)
x = self.convd1x(x)
# Residual block
x = self.dense_1x(x)
# Final prediction
cp = self.change_probability(x)
outputs.append(cp)
if self.output_softmax:
temp = outputs
outputs = []
for pred in temp:
outputs.append(self.active(pred))
return outputs[-1]
MLP & Upsampling
首先通过MLP层对每个多尺度特征差异图进行处理,以统一channel数,然后对每个维度进行上采样到H/4×W/4的大小(以统一size数)。
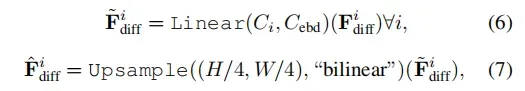
MLP为conv实现,Upsampling为F.interpolate所实现
Concatenation & Fusion
将上采样的特征差异图通过一个MLP层进行连接和融合,如下所示
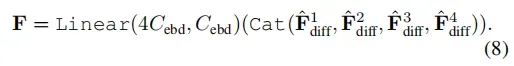
Upsampling & Classification.
我们利用S = 4,K = 3的transposedConv2d,将融合的特征图F上采样到H×W的大小。最后,对上采样的融合特征图通过另一个MLP层进行处理,预测分辨率为的变化掩模CM,其中
(=2)是类的数量,即变化和无变化。此过程可表述如下:
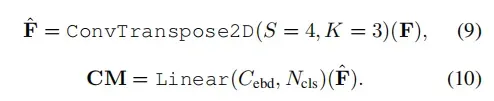
3、实验
3.1 数据集
使用两个公开的CD数据集进行实验,即LEVIR-CD [10]和DSIFN-CD [11]。
- LEVIR-CD是一个构建的CD数据集,它包含分辨率为1024×1024的RS图像对。从这些图像中,我们裁剪大小为256×256的非重叠crop,并将它们随机分成三个部分,train、val、test的样本数分别为7120、1024、2048。
- DSIFN数据集是一个通用的CD数据集,它包含不同陆地覆盖对象的变化。在实验中,我们从512×512图像中创建了大小为256×256的非重叠crop,同时使用作者的默认train、val、test划分(14400/1360/192)。
3.2 实验参数
用PyTorch实现了我们的模型,并使用NVIDIA Quadro RTX 8000 GPU进行训练。
数据增强方法:随机翻转、随机重尺度(0.8-1.2)、随机裁剪、高斯模糊和随机颜色抖动来进行数据增强。
使用交叉熵(CE)损失和AdamW优化器训练模型,权重衰减为0.01,beta值为(0.9,0.999)。学习速率最初被设置为0.0001,然后线性衰减为0,直到训练了200个epoch。我们使用16的批处理大小来训练模型。
评价指标:IOU、F1
3.3 实验效果
对比模型有:
- FC-EF [12]:连接双时间图像,并通过ConvNet处理它们,以检测变化。
- FC-Siam-Di [12]:是一种特征差方法,从Siamese卷积网络中提取双时间图像的多层特征,并利用它们的差来检测变化。
- FC-Siam-Conc [12]:是一种特征连接方法,从Siamese通信网络中提取双时间图像的多层次特征,并采用特征连接方法来检测变化。
- DTCDSCN [13]:是一种基于注意力的方法,它利用双注意模块(DAM)利用ConvNet特征与空间位置之间的相互依赖关系来检测变化。
- STANet [14]:是另一个基于Siamese的时空注意网络。
- IFNet [15]:是一种多尺度特征连接方法,它通过改变change map重建的注意模块的手段将双时态图像的多层次深度特征与图像差异特征相融合
- SNUNet [16]: 是一种多层特征连接方法,其中使用密集连接(NestedUNet,unet++)网络进行变化检测。
- BIT [6]:是一种基于transformer的方法,利用转换器编解码器网络,通过语义标记和特征差异来增强ConvNet特征的上下文信息,从而获得变化图。
其中OA为平均精度,整体来看iou得分要比f1低10~15%
文章出处登录后可见!