LAYOUT LM
联合建模文档的layout信息和text信息,预训练文档理解模型。
模型架构
使用BERT作为backbone,加入2-D绝对位置信息,图像信息,分别捕获token在文档中的相对位置以及字体、文字方向、颜色等视觉信息。
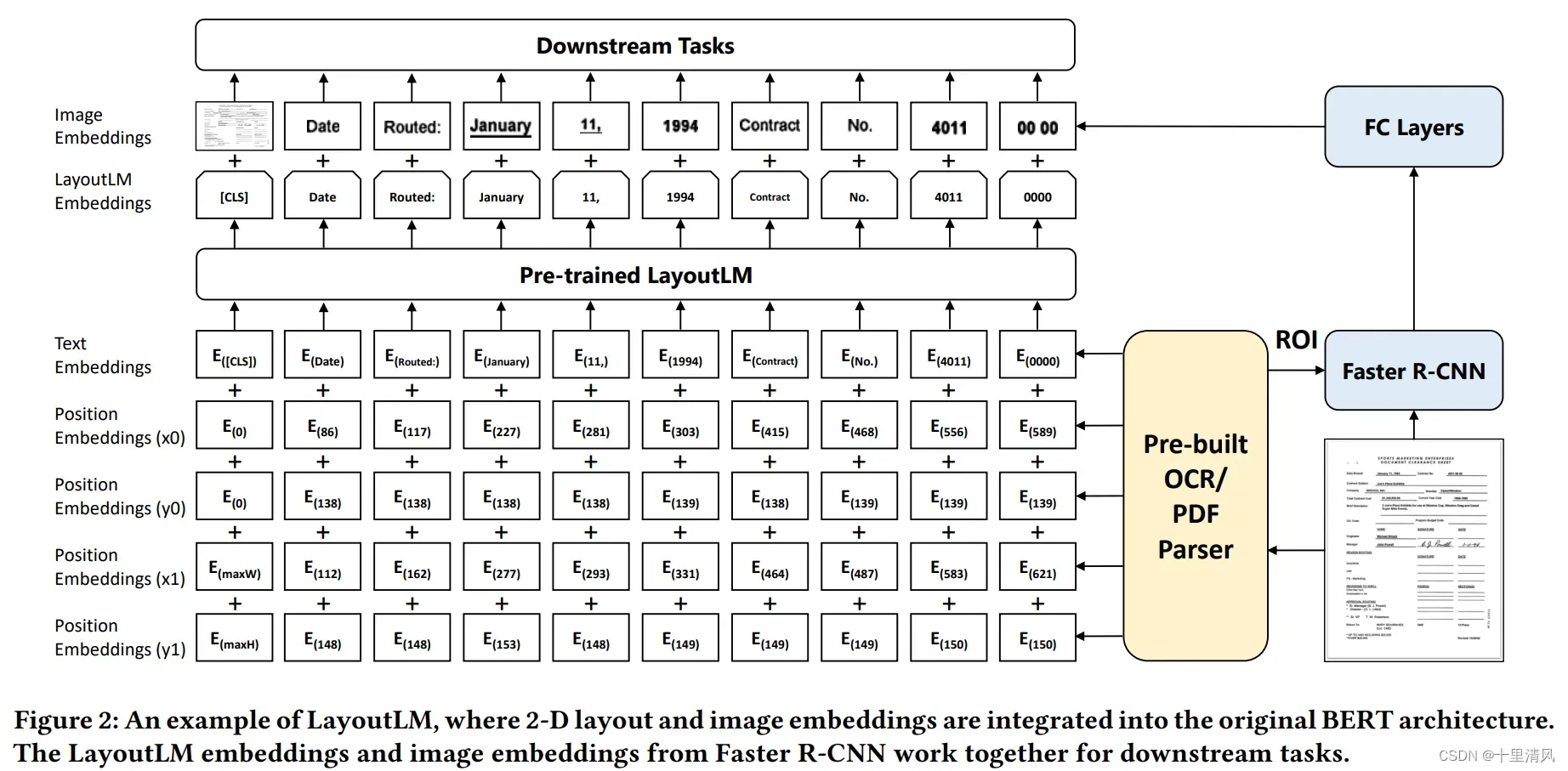
2D位置嵌入
文档页面视为坐标系统(左上为原点), 使用2张embedding table构造4种位置嵌入,横纵轴各使用1张嵌入表;
图像嵌入
将文档页面图像分割成小图片序列,基于Faster R-CNN建模整张图片特征丰富[CLS]token表征;
预训练数据集及任务
预训练集 IIT-CDIP Test Collection 1.0(600万扫描件,含1200万扫描图片,含信件、邮件、表单、发票等)。
- MVLM, Masker Visual-Language Model: 随机掩盖输入tokens,保留2-D信息,预测被掩盖token分布;
- MDC, Multi-label Document Classification: 监督预训练多标签文档分类,促使模型聚类不同文档特征,增强文档级特征表示;
模型预训练细节
- 除2-D positional embeddings之外,其余参数使用bert base初始化;
- 预测15%的token,选其中80%替换为
[MASK],10%随机替换,余下10%不变; - 标准化所有坐标点为0~1000;
- 使用ResNet-101作为Fatser R-CNN的backbone;
源码解析
9种embeddings相加,再经layer norm后作为第1层输入:
embeddings = (
words_embeddings
+ position_embeddings
+ left_position_embeddings
+ upper_position_embeddings
+ right_position_embeddings
+ lower_position_embeddings
+ h_position_embeddings
+ w_position_embeddings
+ token_type_embeddings
)
余下结构与BERT一致。
LAYOUT LM V2
与Layout LM的区别:
- 预训练阶段,使用Transformer建模文本、布局、图像多模态信息,而Layout LM是在微调阶段利用图像信息;
- 使用空间相对注意力机制,表征token对,而Layout LM使用绝对2-D位置;
- 新增引入文本、图像对齐策略,文本、图像匹配策略,学习文本与图像是否相关;
模型架构
以文本、布局、图像作为输入,建模交叉模态:
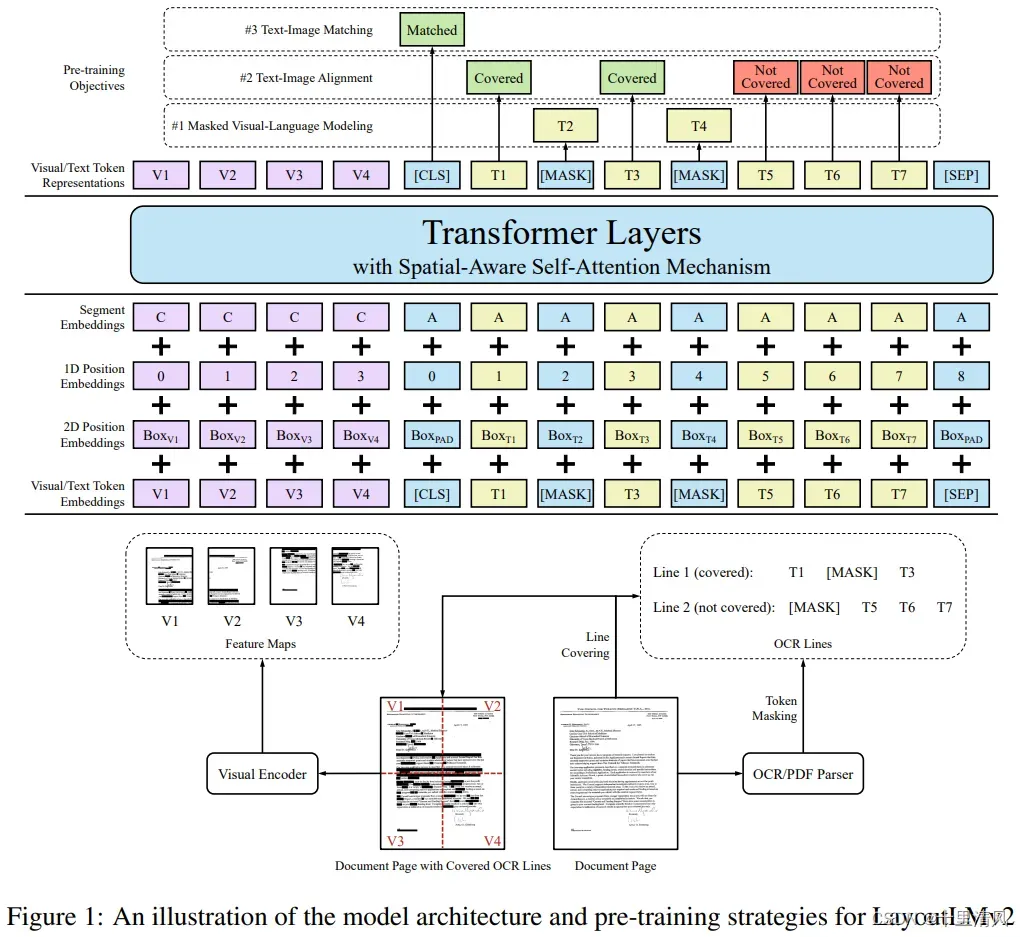
文本嵌入
与BERT一致,
视觉嵌入
将图像缩放至224×224,喂入ResNeXt-FPN编码(参数在预训练时更新),平均池化为的特征图(3维),展开为2维序列;
版面嵌入
标准化点位至,
点位各使用一个嵌入层,对于边界框
,
使用,表示特殊token
[CLS]、[SEP]和[PAD]。
空间感知多模态编码器
拼接视觉嵌入和文本嵌入,并加上版面嵌入,生成第一层输入
第一层输入只考虑到绝对位置,为建模版面局部不变性,引入空间感知相对注意力,
预训练任务
数据集与LayoutLM使用的一致
- MVLM, Masker Visual-Language Model: 随机一些掩盖文本tokens,促使模型利用版面信息对其复原,为避免模型利用视觉线索,掩盖tokens对应的图像区域也应该掩盖;
- TIA, Text-Image Alignment: 随机选择一些文本行,覆盖对应的图像区域,使模型预测token对应的图像区域是否被掩盖,即
[Covered]或[Not Covered],促使模型学习边界框坐标与图像之间的关系; - TIM, Text-Image Matching: 粗粒度的模态对齐任务,预测文本和图像的来源是否一致(当前文本是否来自于当前图像)。通用随机替换或删除图像构造负样本,负样本对应TIA任务的所有标签均为
[Covered]
TIA任务为什么要整行覆盖?
文档中某些元素(signs, bars)看起来很像是覆盖区域,图像中寻找词级别的覆盖区域噪音较大,整行覆盖可避免噪音。
实验细节
- 使用UniLMv2模型初始化网络参数;
- ResNeXt-FPN的backbone: MaskRCNN,基于PubLayNet训练;
- 使用随机滑窗的方法随机截取长文本中的512个token;
- 视觉编码器平局池化层输出维度W×H=7×7,即总共有49个视觉token;
- MVLM,token mask的概率及方式与LayoutLM一致;
- TIA,15%替换图像;
- TIM,15%替换图像,5%删除图像;
LayoutXLM
文章简介
- 作为LayoutLMv2的扩展,适用于多语言任务;
- 与LayoutLMv2架构相同,参数基于SOTA多语言模型
InfoXLM初始化参数; - 使用IIT-CDIP数据集和开源多语言PDF文件作为数据集;
- 开源多语言(中文、日文、西班牙语、意大利语、德语)信息抽取数据集XFUND
不使用LayoutLMv2初始化参数的原因?
LayoutLMv2不覆盖多语言,词典不一致。
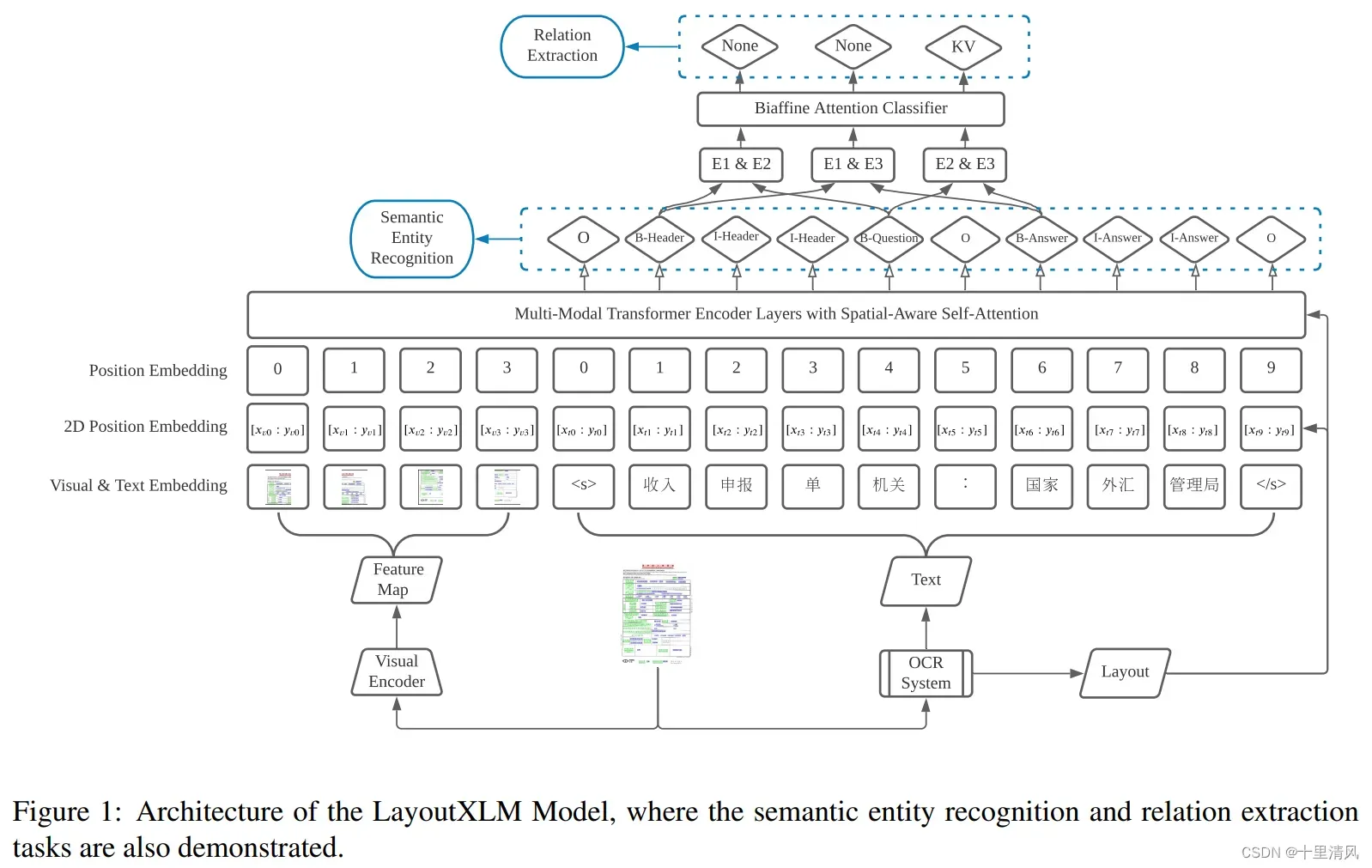
模型架构
与LayoutLMv2一致。
模型预训练
使用与LayoutLMv2一致的三个任务:MVLM、TIA、TIM。
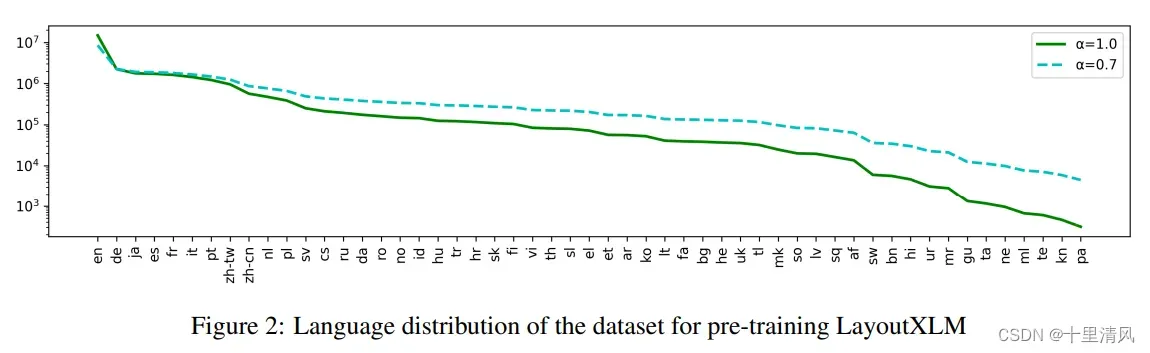
预训练数据
- 含53种语言文件;
- 使用PyMuPDF解析、清洗数据集,获取页面文字、布局、图像;
- 使用BlingFire检测文件语言;
- 以
概率采样某一种语言文件,
,共获得2200w富文档;
XFUND: 多语言票据理解基准数据集
扩充FUNSD至7种语言。

任务描述
语义实体识别任务, 关系抽取任务。
| Semantic Entity Recognition | Relation Extraction |
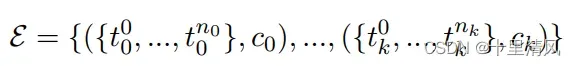 | 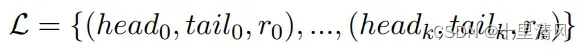 |
Baselines
Semantic Entity Recognition
基于BIO标注模式,构建特定任务层建模LayoutXLM的文本部分。
Relation Extraction
识别所有关系候选实体,对任一实体对,拼接头尾实体第一个token的语义向量,经投影变换、双仿射层,获得关系分类。
实验
- 预训练base和large模型;
- 微调XFUND,验证不同语言迁移学习、零样本学习、多任务微调,并与两种多语言预训练模型(XLM-R、InfoXLM)作对比;
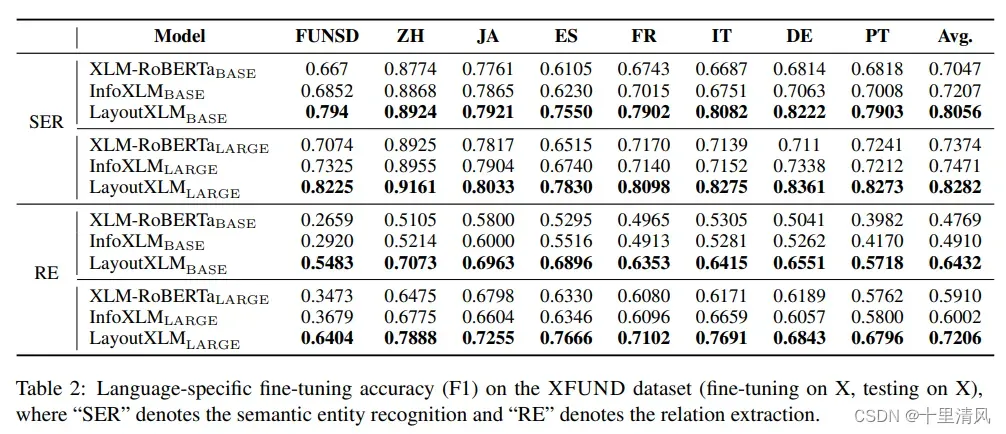
1️⃣language-specific fine-tuning: 语言X上微调,语言X上测试;
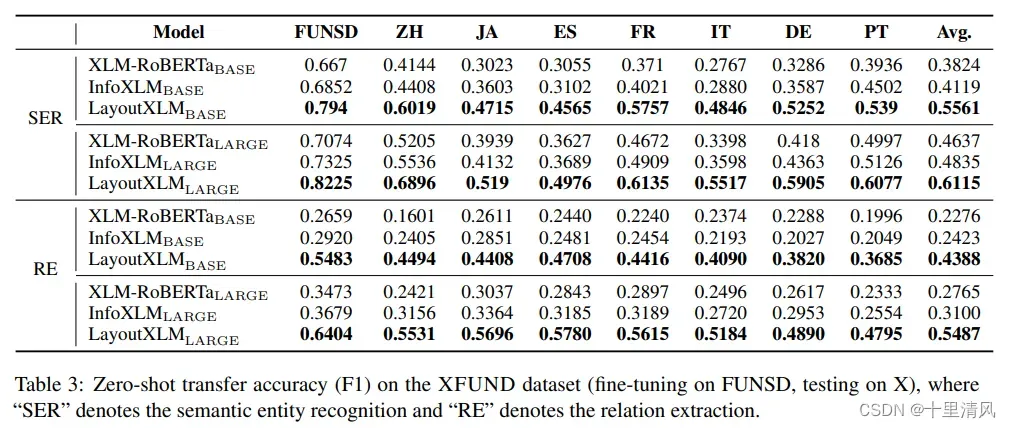
2️⃣Zero-shot transfer learning: 英文上微调,其他语言上测试;
3️⃣Multitask fine-tuning: 所有语言上训练模型
特定语言微调
零样本微调
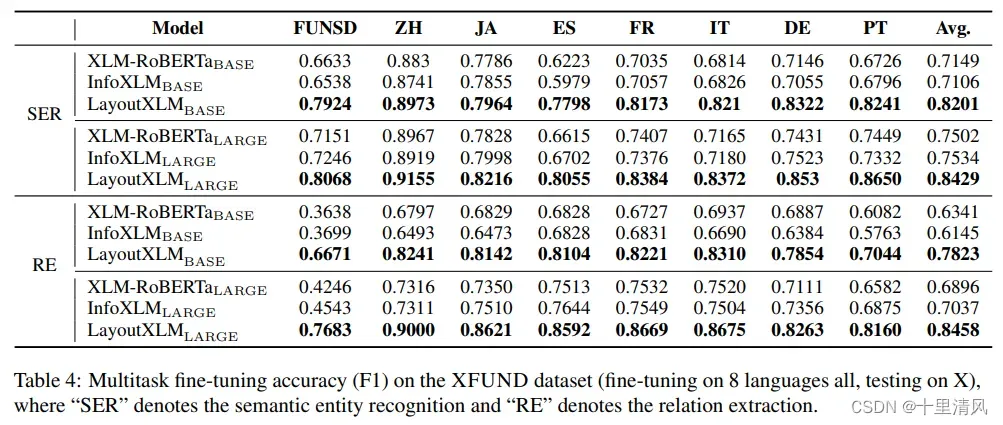
多任务微调
文章出处登录后可见!